
При разработке чат-ботов и голосовых ассистентов часто возникает задача нахождения семантического сходства слов. Причина тому – наличие в языке большого количества схожих по смыслу слов и выражений. Так, пользователь может задать один и тот же вопрос как минимум двумя способами:
Почему электрические батареи быстрее разряжаются на холоде?
Из-за чего батарейки быстрее садятся на морозе?
Для человека не составит труда понять, что предложения имеют схожий смысл, несмотря на различие в лексике. Мы знаем, что слова электрические батареи и батарейки, разряжаются и садятся, холод и мороз – синонимы, они имеют практически одинаковое значение и могут быть взаимозаменяемы.

Но как компьютеру понять, что под разными словами подразумевается одно и то же? Решение этой задачи состоит в вычислении меры семантического сходства слов: для синонимов она близка к единице, для совершенно непохожих слов – к нулю.
Дистрибутивные модели
Сейчас подавляющее большинство решений основано на моделях дистрибутивной семантики. Идея в следующем: если слова встречаются в похожих контекстах, то они имеют похожие значения. Для этого метода не требуются предварительно подготовленные данные, вся семантическая информация извлекается из неструктурированных текстов на основе совместной встречаемости слов.
Однако вот в чем проблема: подобный подход не учитывает, что отношения между словами из одной семантической области могут иметь различный характер. В качестве "синонимов", то есть близких по смыслу слов, будут определены как синонимы в традиционном понимании, так и противоположные по смыслу слова, хоть и относящиеся к той же семантической области, которые со школы мы привыкли называть антонимами: например, жара для слова холод и заряжаться для слова разряжаться.


Словари с иерархической структурой
Решением проблемы мог бы стать лингвистический ресурс, содержащий: а) большое количество слов и словосочетаний, б) семантические отношения между ними.
Нам повезло, и такие ресурсы придуманы уже давно – они имеют названия тезаурусов. Первый тезаурус (конечно, в бумажном виде) был создан в 1805 году. Наиболее современная и полная лексическая база знаний разработана Принстонским университетом под названием WordNet. Эти тезаурусы включают слова и словосочетания английского языка. Существует также тезаурус для русского языка – RuWordNet.
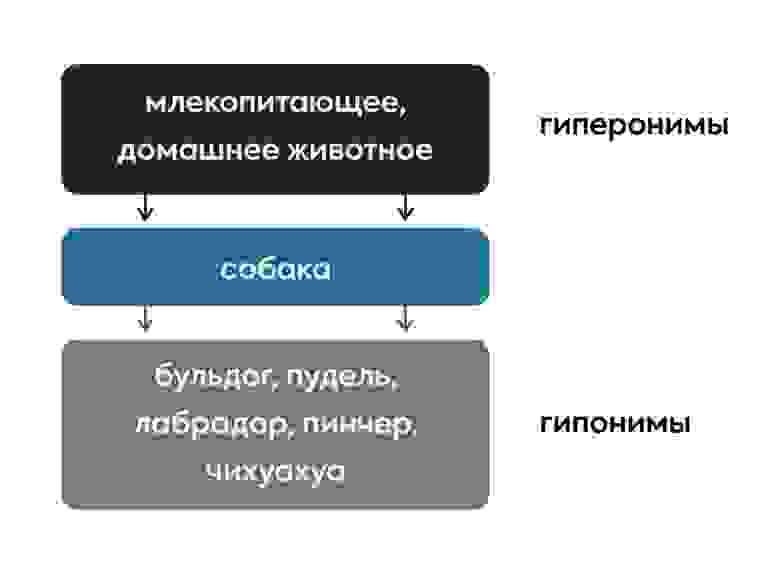
В тезаурусе между словами установлена иерархическая структура: выделены наиболее общие понятия (гиперонимы) и наиболее частные (гипонимы), а также похожие по смыслу слова (синонимы). Например, для слова собака гиперонимами являются слова млекопитающее и домашнее животное, гипонимами – конкретные породы собак, как бульдог, пудель, лабрадор и другие.
Иерархическая структура тезауруса позволяет рассчитывать семантическое сходство между словами. Для этого существуют различные метрики, некоторые из них имеют программную реализацию на основе тезауруса WordNet для английского языка. На примере данного ресурса мы рассмотрим методы нахождения семантического сходства слов по тезаурусу и приведем примеры подсчета метрик с помощью пакета WordNet библиотеки NLTK.
Тезаурус WordNet для английского языка
Доступ к тезаурусу WordNet возможен из библиотеки NLTK на Python, для этого необходимо импортировать соответствующий пакет:
from nltk.corpus import wordnet as wnВ тезаурусе слова представлены в виде так называемых синсетов: это объединение слов с похожими понятиями, их лексические значения вместе формируют лексическое значение самого слова. К примеру, синсет слова hand tool ‘ручной инструмент’ состоит из одного понятия.
wn.synsets('hand_tool')[Synset('hand_tool.n.01')]
Синсет слова hammer ‘молоток’ включает нескольких синонимичных понятий, где malleus переводится как ‘молоточек’, слуховая косточка среднего уха, mallet обозначает ‘молоток для игры в крокет’, а forge имеет значение ‘кузница’.
wn.synsets('hammer')[Synset('hammer.n.01'), Synset('hammer.n.02'), Synset('malleus.n.01'), Synset('mallet.n.02'), Synset('hammer.n.05'), Synset('hammer.n.06'), Synset('hammer.n.07'), Synset('hammer.n.08'), Synset('hammer.v.01'), Synset('forge.v.01')]
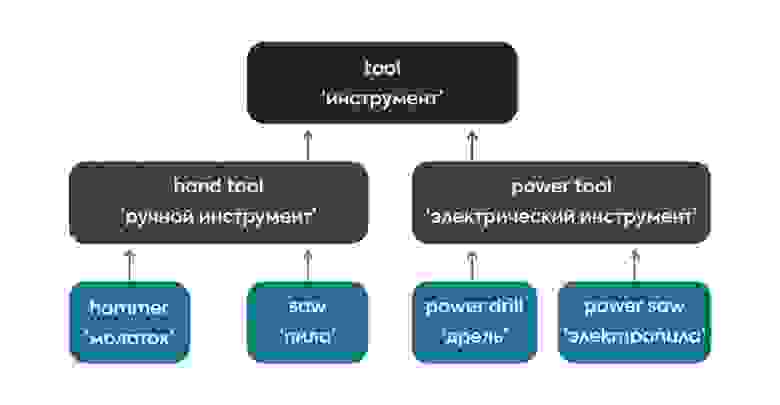
Как мы упоминали ранее, тезаурус имеет иерархическую структуру. Следовательно, для каждого слова можно узнать как более общие понятия – гиперонимы, так и более конкретные понятия – гипонимы. Так, слово hand tool ‘ручной инструмент’ имеет только один гипероним – tool ‘инструмент’ и много гипонимов, среди которых уже знакомый hammer ‘молоток’ с индексом «02», а также awl ‘шило’, saw ‘пила’, wrench 'гаечный ключ' и другие названия ручных инструментов:
hand_tool = wn.synset('hand_tool.n.01')
print(hand_tool.hypernyms())
print(hand_tool.hyponyms())[Synset('tool.n.01')]
[Synset('awl.n.01'), Synset('bevel.n.02'), Synset('bodkin.n.03'), Synset('bodkin.n.04'), Synset('crank.n.04'), Synset('dibble.n.01'), Synset('file.n.04'), Synset('float.n.05'), Synset('graver.n.01'), Synset('gutter.n.04'), Synset('hammer.n.02'), Synset('hand_shovel.n.01'), Synset('marlinespike.n.01'), Synset('miter_box.n.01'), Synset('opener.n.03'), Synset('pallet.n.03'), Synset('pestle.n.03'), Synset('pick.n.06'), Synset('pincer.n.01'), Synset('pipe_cutter.n.01'), Synset('pitchfork.n.01'), Synset('plane.n.05'), Synset('pliers.n.01'), Synset('plumber's_snake.n.01'), Synset('plunger.n.03'), Synset('ravehook.n.01'), Synset('sandblaster.n.01'), Synset('saw.n.02'), Synset('scraper.n.01'), Synset('screwdriver.n.01'), Synset('shovel.n.01'), Synset('soldering_iron.n.01'), Synset('spatula.n.02'), Synset('spreader.n.01'), Synset('square.n.08'), Synset('straightedge.n.01'), Synset('tire_iron.n.01'), Synset('trowel.n.01'), Synset('weeder.n.02'), Synset('wire_stripper.n.01'), Synset('wrench.n.03')]
Несложно догадаться, что гиперонимом для слова hammer ‘молоток’ с индексом «02» будет понятие hand tool ‘ручной инструмент’, а гипонимами – различные виды молотков, как ball-peen hammer ‘шариковый молоток’, maul ‘кувалда’ и другие:
hammer = wn.synset('hammer.n.02')
print(hammer.hypernyms())
print(hammer.hyponyms())[Synset('hand_tool.n.01')]
[Synset('ball-peen_hammer.n.01'), Synset('bricklayer's_hammer.n.01'), Synset('carpenter's_hammer.n.01'), Synset('mallet.n.03'), Synset('maul.n.01'), Synset('plexor.n.01'), Synset('tack_hammer.n.01')]
Интересно, что понятие power tool ‘электрический инструмент’ имеет два гиперонима: это не только слово tool ‘инструмент’, но и слово machine ‘механизм’. Гипонимами этого понятия также являются названия конкретных инструментов: buffer ‘амортизатор’, power drill ‘дрель’, power saw 'электропила', а также снова hammer, только уже в значении ‘электромолоток’, о чем говорит изменившийся индекс «07»:
power_tool = wn.synset('power_tool.n.01')
print(power_tool.hypernyms())
print(power_tool.hyponyms())[Synset('machine.n.01'), Synset('tool.n.01')]
[Synset('buffer.n.05'), Synset('burr.n.04'), Synset('drum_sander.n.01'), Synset('hammer.n.07'), Synset('plane.n.04'), Synset('power_drill.n.01'), Synset('power_saw.n.01'), Synset('router.n.03'), Synset('stamping_machine.n.01')]
Иерархическая структура тезауруса позволяет довольно точно рассчитывать семантическое сходство между понятиями с помощью специальных мер, которые мы рассмотрим в следующем разделе.
Меры семантического сходства по тезаурусу
Попробуем рассчитать семантическое сходство между парами слов, обозначающими различные строительные инструменты: hand tool ‘ручной инструмент’ и power tool ‘электрический инструмент’, hammer ‘молоток’ и saw ‘пила’. Для наглядности представим их иерархическое расположение в тезаурусе в виде графической схемы:
Можно выделить два метода подсчета семантической схожести.
Первая мера сходства основана на длине пути между парой понятий. Интуитивно кажется правильным подсчитывать расстояние между узлами в иерархии для вычисления меры семантической схожести. Данная мера имеет название PATH (с английского ‘путь’) и учитывает длину кратчайшего пути между двумя понятиями А и В (shortest path (А,В)). Отметим, что при подсчете учитываются именно узлы, а не переходы между узлами:

Рассчитаем меру сходства PATH между парами слов hand tool ‘ручной инструмент’ и power tool ‘электрический инструмент’, hammer ‘молоток’ и saw ‘пила’. Кратчайший путь между понятиями для обоих пар равен 3. Автоматический подсчет меры PATH показывает, что семантическое сходство между словами является одинаковым:
hand_tool.path_similarity(power_tool)0.3333333333333333
hammer.path_similarity(saw)0.3333333333333333
При подсчете этой меры предполагается, что все расстояния между узлами имеют одинаковый вес. Однако это не совсем так — понятия, лежащие ниже в иерархии, являются более специфичными, и семантическое расстояние между такими понятиями кажется меньшим, нежели расстояние между более общими понятиями. Поэтому эффективно использовать не только расстояние между узлами, но и глубину узлов в иерархи: PATH + DEPTH (с английского ‘глубина’). Под глубиной подразумевается длина кратчайшего пути между целевым понятием А и корневым понятием.

Данная мера имеет название WUP по фамилиям исследователей Z. Wu и M. Palmer, предложивших использовать ее в статье 1994 года. Она учитывает глубину наименее общего родового понятия, то есть ближайшего понятия, которое является общим для обоих целевых слов (Least Common Subsumer, сокращенно LCS):

Подсчитаем семантическое сходство по мере WUP между уже известными парами слов. Результат показывает, что для слов hammer ‘молоток’ и saw ‘пила’ значение меры сходства оказывается выше, чем для пары hand tool ‘ручной инструмент’ и power tool ‘электрический инструмент’:
hand_tool.wup_similarity(power_tool)0.8888888888888888
hammer.wup_similarity(saw)0.9
Это соответствует нашим интуитивным ожиданиям: конкретные понятия, как названия типов ручных инструментов, кажутся семантически более близкими, чем общие понятия, как названия групп инструментов. Таким образом, мера семантического сходства, учитывающая не только расстояние между узлами, но и глубину вложения, является более показательной и надежной.
Некоторые итоги
В статье мы рассмотрели меры нахождения семантического сходства по тезаурусу. Дистрибутивные методы, так распространенные сейчас, показывают высокое качество в задачах понимания текста, но обладают важным недостатком: они не учитывают семантические отношения между словами, такие как синонимия, антонимия, отношения гипоним-гипероним. Эту проблему решают словари с иерархической структурой – тезаурусы. Мы познакомились с устройством тезауруса WordNet для английского языка и рассчитали семантическое сходство между понятиями с помощью библиотеки NLTK. Оказалось, что более достоверные результаты показывают меры, которые учитывают не только на расстояние между узлами (PATH), но и глубину узлов в иерархии (DEPTH).
В заключение добавим, что семантическое сходство слов по тезаурусу может использоваться во многих задачах понимания текста, среди которых построение вопросно-ответных систем, разрешение неоднозначности слов, нахождении сходства между предложениями, расширение поискового запроса и нахождение связей между частями текста.




