
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Istio — частный случай «сервисной сетки» (Service Mesh), понятия, о котором наверняка все слышали, и многие даже знают, что это такое. Мой доклад на Kuber Conf 2021 (мероприятие Yandex.Cloud, которое проходило 24 июня в Москве) посвящен возможным проблемам, к которым надо готовиться при внедрении Istio. Среди прочего я рассказал о том, как Istio влияет на трафик, какие есть возможности для его мониторинга, насколько безопасен mTLS.
Доклад отчасти отражает наш опыт работы с Istio как с одним из компонентов Kubernetes-платформы Deckhouse, отчасти основан на результатах внутренних нагрузочных тестов.

Представляю видео с докладом (~30 минут) и основную выжимку в текстовом виде.
Что такое Service Mesh
Для начала синхронизируем понимание, что такое Service Mesh.
Допустим, у вас есть приложение, оно живет своей жизнью, развивается. Вы нанимаете новых программистов, от бизнеса поступают новые задачи. Нормальная эволюция.
При этом объемы сетевого трафика растут, и в этой ситуации вы просто не можете не столкнуться с задачами по его управлению. Разберем эти задачи подробнее.
Типовая сетевая задача №1
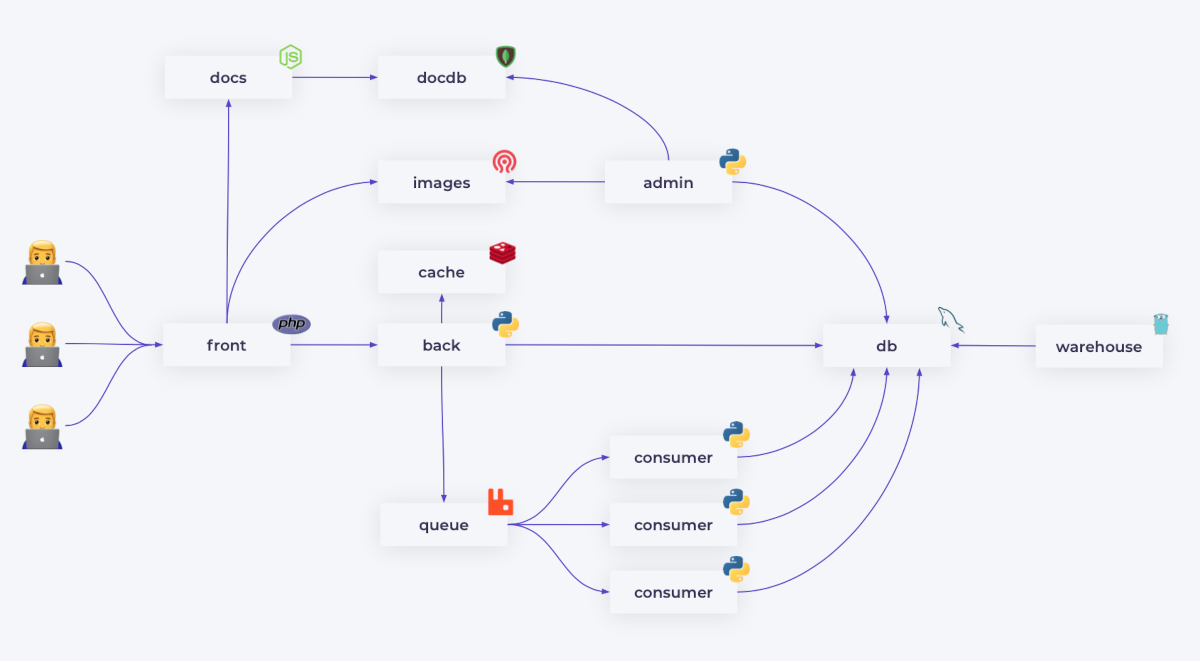
Возьмем небольшой кусочек архитектуры — фронтенд и бэкенд. С точки зрения кластера он выглядит как две группы Pod’ов, которые общаются друг с другом.
Предположим, одному из Pod’ов стало плохо — не терминально, но приложение глючит. Health check'и в Kubernetes этого не замечают: сохраняют Pod в балансировке, и трафик на него продолжает поступать. От этого становится только хуже.
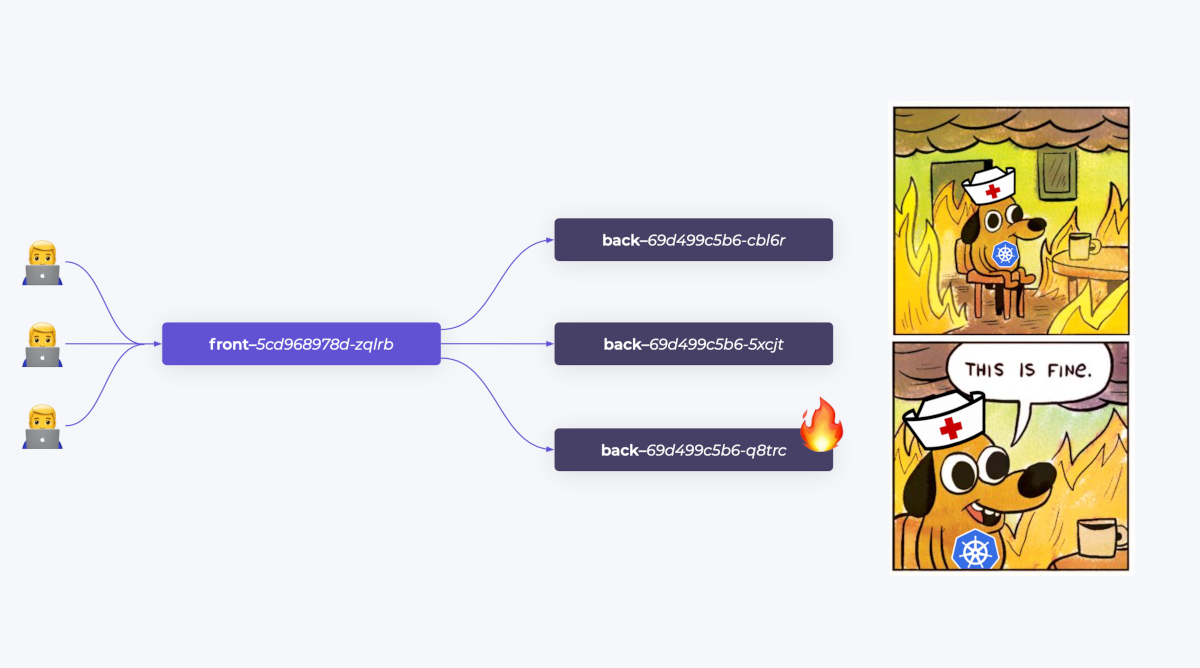
Было бы здорово выявлять эти пограничные состояния, когда вроде бы почти всё окей, но все-таки что-то идет не так. А выявив — дать нашему Pod’у отдохнуть, временно перенаправив трафик на другие Pod’ы. Такой подход называется circuit breaking.

Типовая сетевая задача №2
Вы написали новую версию бэкенда, прошли все тесты, на stage бэкенд показал себя хорошо. Но прежде, чем катить его в production, хорошо бы обкатать на настоящем трафике. То есть выделить группу пользователей для новой версии бэкенда и протестировать его на этой группе.
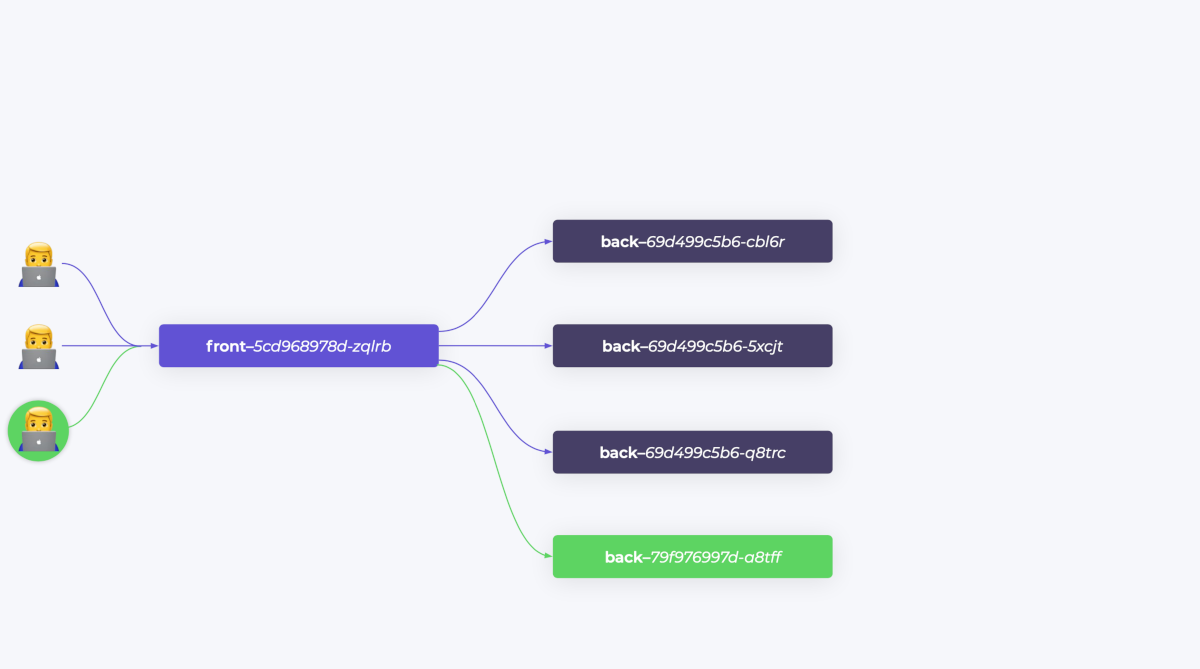
Если тесты прошли успешно — выкатываем бэкенд в production и обновляем все Pod’ы. Такая стратегия деплоя называется canary deployment. (Подробнее о разных стратегиях деплоя в Kubernetes мы писали здесь.)
Типовая сетевая задача №3
Например, ваш кластер развернут в публичном облаке. Из соображений отказоустойчивости вы «размазали» Pod’ы по разным зонам. При этом фронтенд- и бэкенд-Pod’ы общаются друг с другом беспорядочно, не обращая внимание на зоны. В мире облачных платформ такое беспорядочное общение не будет для вас бесплатным. Например, в AWS это выльется в дополнительные финансовые расходы, в Яндекс.Облаке — в дополнительный latency.
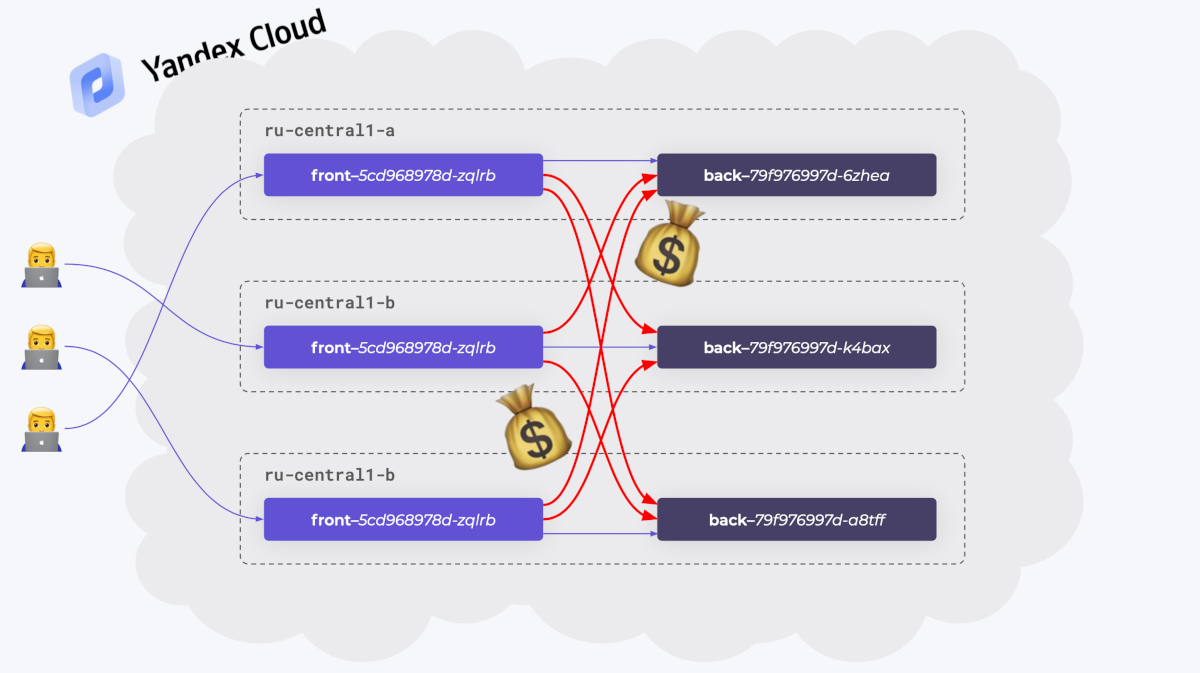
Нужно сделать так, чтобы фронтенды выбирали такие бэкенды, которые находятся в их зоне, а остальные бэкенды оставались бы для них «запасными». Такой способ маршрутизации называется locality load balancing.
Решаем сетевые задачи систематически
Подобные задачи по управлению сетевым трафиком можно перечислять ещё долго и каждый хотя бы раз сталкивался хотя бы с одной из них. Безусловно, у каждой из задач есть решение, которое можно реализовать на уровне приложения. Но проблема в том, что среднестатистическое приложение состоит из множества компонентов, или «шестеренок». И все они разные, к каждой нужен свой подход.
Именно для систематического решения подобных задач и придумали Service Mesh.

Service Mesh дает набор «кирпичей», из которых мы можем собирать собственные паттерны управления сетью. По-другому: Service Mesh — это фреймворк для управления любым TCP-трафиком с собственным декларативном языком. А в качестве бонуса Service Mesh предлагает дополнительные возможности для мониторинга (observability).
Благодаря Service Mesh вам не нужно задумываться о нюансах сетевого взаимодействия на уровне отдельных компонентов.

Вы можете рассматривать ваше приложение просто как дерево компонентов с очень примитивными связями. А все нюансы вынести за скобки и описать их с помощью Service Mesh.

Как это работает
Представим, что мы — большие любители «велосипедов»: мы не ищем готовые решения, потому что любим писать свои. И мы решили написать свой Service Mesh — supermesh.
Предположим, у нас есть приложение. Оно принимает запросы, генерирует новые — вот этим трафиком мы и хотим управлять. Но чтобы им управлять, нам нужно его перехватить. Для этого:
проникаем в сетевое окружение приложения;
внедряем туда наш перехватчик;
DNAT’ом перенаправляем на него входящий и исходящий трафик.

Поскольку мы работаем с Kubernetes, наше приложение «живет» в Pod’e, то есть внутри контейнера. Это значит, что мы для удобства можем «подселить» к приложению наш перехватчик в качестве sidecar-контейнера.
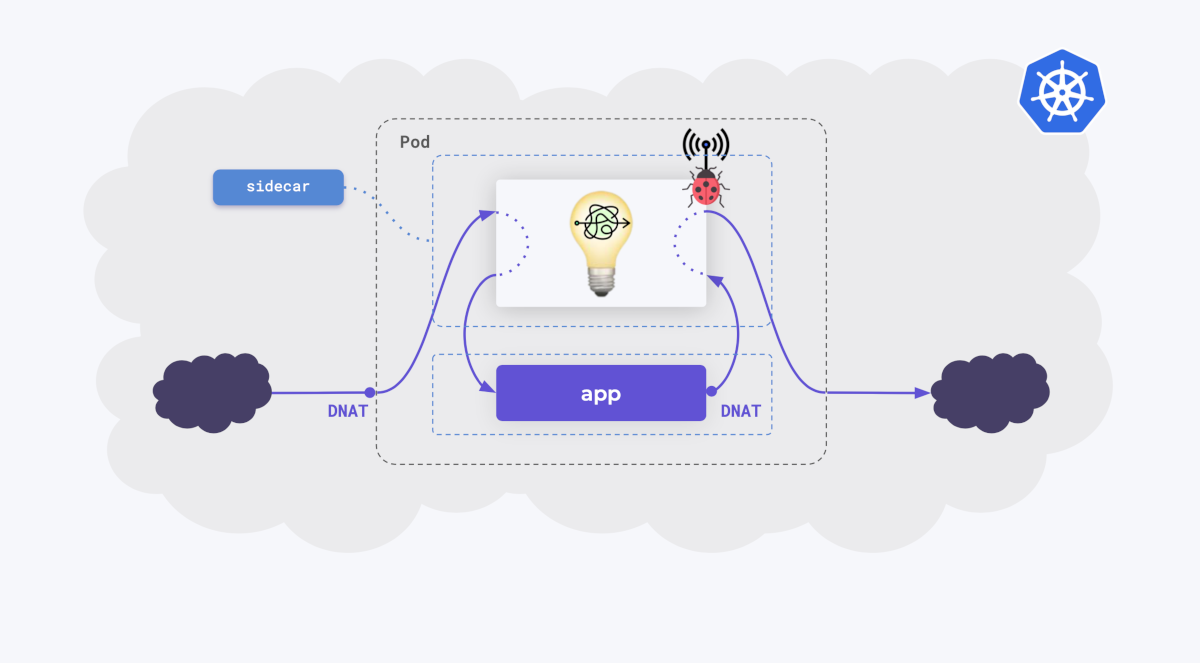
Теперь с этим перехваченным трафиком нужно что-то сделать, как-то его модифицировать. Очевидное решение — использовать прокси (например, nginx, HAProxy или Envoy).
Мы можем написать и свой прокси, но мы не настолько велосипедисты, поэтому остановимся на Envoy. Он хорошо вписывается в эту архитектуру, потому что умеет конфигурироваться удаленно, «на лету», и у него есть множество готовых удобных API.

В итоге мы можем перехватить трафик и влиять на него. Осталось сделать с ним что-то полезное, то есть реализовать какой-то из упомянутых выше паттернов управления — причем не абы какой, а такой, который выберет разработчик нашего приложения.
Мы могли бы передать разработчику «пульт управления» нашими sidecar’ами, чтобы он сам настраивал все нюансы. Но изначально вроде бы не этого хотели: нам нужна систематизация.
Очевидно, что нам не хватает какого-то промежуточного компонента — условного контроллера (supermeshd), который взял бы на себя управление, а разработчику предоставил декларативный язык, с помощью которого тот строил бы свои стратегии.

Теперь мы можем взять от разработчика набор паттернов, которые он хочет, а контроллер будет бегать по sidecar’ам и настраивать их. В мире Service Mesh такой контроллер называется Control Plane, а sidecar’ы с нашим перехватчиком — Data Plane.
Именно по такому принципу — естественно, с большими допущениями — и работает большинство реализаций Service Mesh: Kuma, Istio, Linkerd и пр.
В этом докладе я рассматриваю только Istio и делаю это «без объяснения причин». Кстати, согласно прошлогоднему опросу CNCF, это самое популярное Service Mesh-решение, которое используется в production.

Перед внедрением Istio к нему сразу же возникает ряд вопросов:
Как он повлияет на приложение? А на кластер?
Какие у него возможности по observability?
Надежен ли его Mutual TLS?
Что с федерацией?
Как правильно засетапить Istio? А обновить?
Что, если что-то сломается?
Конечно, вопросов гораздо больше. Постараюсь ответить хотя бы на некоторые из них.
Как Istio влияет на приложение
Раньше, когда не было Istio, всё было просто и прозрачно: пользователь генерирует запрос, фронтенд генерирует дочерний запрос к бэкенду.

Как только появляется Istio, схема усложняется:

По сравнению с чистой инсталляцией «хопов» стало гораздо больше. Понятно, что это не может быть бесплатным. И самая очевидная цена — это latency.
Разработчики Istio обещают, что задержка не будет превышать 2,65 мс. Мне эти цифры показались не очень убедительными, поэтому я решил сделать свои замеры.
Нагрузочное тестирование
Для начала я написал примитивное клиент-серверное приложение. В качестве клиента использовал утилиту для нагрузочного тестирования k6, а в качестве сервера — nginx, который просто отдает статичные файлы. k6 отправляла по 10 тыс. запросов с предварительным прогревом в сторону сервера. Важно: клиент и сервер работали на разных узлах, чтобы не мешать друг другу.
Из этого приложения я собрал несколько вариантов инсталляции:
«чистую» схему, без Istio и всяких sidecar’ов;
сетап с Envoy в качестве sidecar’а;
сетап, в котором просто включен Istio;
еще один сетап с Istio, в котором задействованы 1000 правил авторизации — чтобы понять, влияют ли какие-то дополнительные правила на задержку, и как именно.

Что еще я посчитал важным сделать:
отключил логи на sidecar’ах;
включил сбор метрик sidecar’ах Istio;
использовал разные версии TLS;
включал и выключал HTTP/2;
включал и выключал keepalive на стороне клиента и между sidecar’ами;
использовал JSON-файлы трех размеров: 500Б, 200КБ, 1,7МБ;
экспериментировал с многопоточностью.
В итоге получилось 252 теста. Попробуем оценить собранные метрики.
1. Классический сценарий: примитивный клиент отправляет запросы серверу в один поток и не умеет держать keepalive.
Посмотрим на картину задержек:
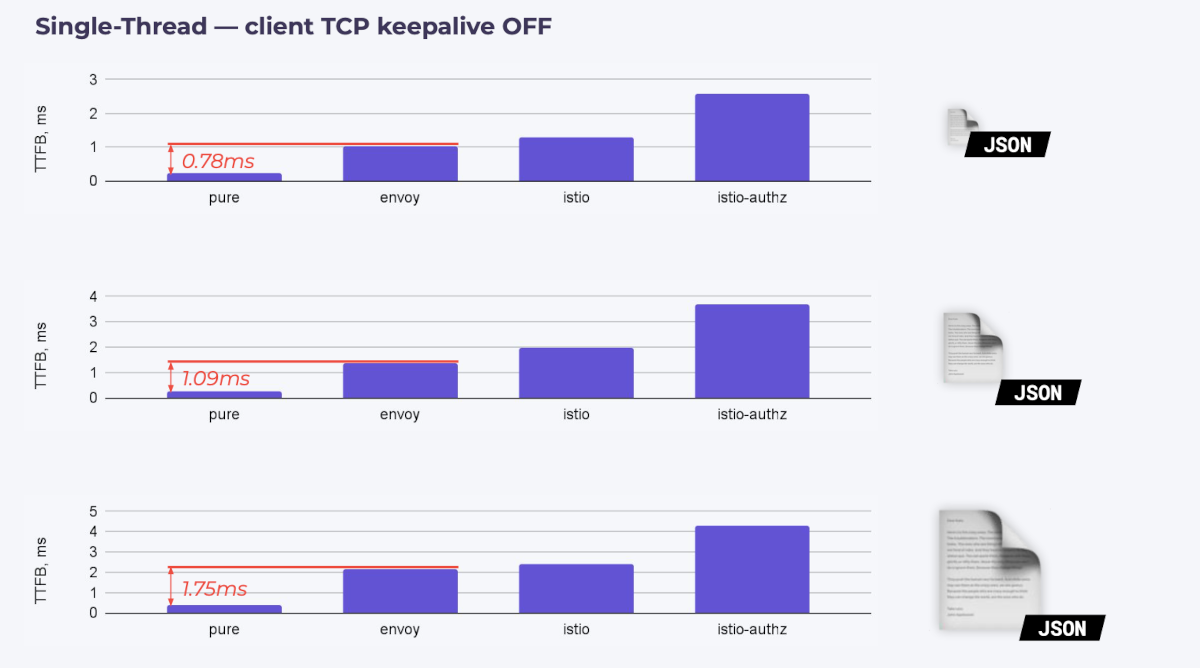
Самый первый и очевидный вывод: действительно, перехват трафика не бесплатен. Причем в случае с Envoy в качестве sidecar’а и «тяжелым» файлом мы видим пятикратный рост задержки.
Уровень драматичности снижается, если мы посмотрим на полный round-trip (RTD) запроса. В самом худшем случае мы увидим троекратный оверхэд. А в некоторых случаях он почти не заметен:

Важно учитывать, что в моем случае естественный фон задержки у бэкенда крайне мал — 0,23 мс. В этом случае прирост в 2 мс кажется огромным — 800%. Но если у вас более сложный бэкенд, у которого задержка составляет десятки мс, то эти лишние 2 мс вы не заметите.
Второй вывод: по сравнению с «голым» Envoy’ем Istio все-таки дает небольшие накладные расходы. Возможно, это связано со сбором метрик и это стоит учитывать.
Третий вывод: правила авторизации, как и любые другие дополнительные настройки Istio, влияют на latency. Но это тоже не должно смущать, т. к. в реальной жизни вряд ли кому-то понадобится тысяча дополнительных правил.
Четвертый вывод: рост задержки при росте размера файла. Здесь задержка растет так же предсказуемо, и все пропорции по сравнению с «голой» инсталляцией сохраняются. То есть можно считать, что объем данных, которые мы прогоняем через Istio, на задержку не влияет.

2. Сценарий с шифрованием Mutual TLS
Результаты оказались везде более-менее одинаковыми, поэтому я покажу их на примере одной инсталляции, когда просто включен Istio:

Да, влияние есть. Но, опять же, это «копейки», которые можно не учитывать. Так что шифрование можно смело включать.
3. Любопытные наблюдения
Они не связаны напрямую с Istio, но я подумал, что ими не помешает поделиться.
Я решил: а что, если включить keepalive на клиентах? Не выиграю ли я в задержке? Потому что, во-первых, handshakes. Во-вторых, sidecar’ам надо будет поменьше думать.
Результаты покажу на примере того же сетапа с Istio:

Выигрыш хоть и небольшой, но есть. Мелочь, а приятно!
А что, если еще включить многопоточность?.. И вот тут я расстроился: при тестах на «средневесе» и «тяжеловесе» задержка выросла.
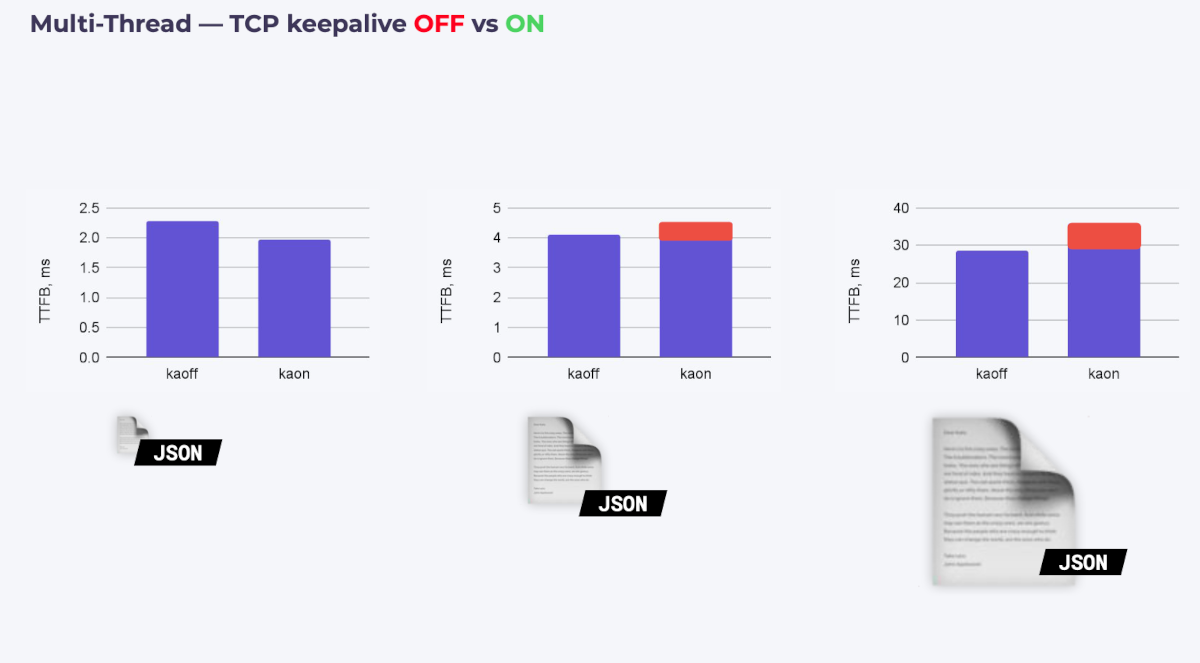
Разбираясь с этой проблемой, я нашел убедительное объяснение в статье блога Cloudflare, почему keepalive — это не всегда хорошо.
Итак, два главных вывода о влиянии Istio на приложение:
перехват трафика не бесплатен — можно смело закладывать накладные расходы по задержке порядка 2,5 мс;
если ваша естественная задержка измеряется в десятках и сотнях мс, лишние 2,5 мс вы не заметите.
Как Istio влияет на кластер
У нашего Istio, как и у supermeshd, который мы ранее реализовали сами, тоже есть Control Plane. Называется он istiod, и это отдельный контроллер, который работает в кластере.
Также у Istio есть свой декларативный язык, с помощью которого можно строить паттерны по управлению сетью. Технически язык представляет собой набор ресурсов Kubernetes, за которыми istiod пристально следит. Еще он следит за набором системных ресурсов: Namespace’ами, Pod’ами, узлами и т. д. В этом смысле контроллер Istio ничем не отличается от любого другого контроллера или оператора. И на практике никаких проблем с ним мы не выявили. Можем идти дальше.
Observability
У Istio есть интеграция со сторонними инструментами для мониторинга. Например, с дашбордом Kiali, с помощью которого можно визуализировать приложение в виде графа, рассмотреть отдельные связи компонентов, как они устроены, что у них «болит» и т. д.
Есть хороший набор дашбордов для графиков Grafana.
Istio также предоставляет базовые возможности для внедрения трассировки на основе Jaeger.
К сожалению, ничего из этого у вас не заработает «из коробки». Для Kiali и Grafana нужно будет установить Prometheus (и саму Grafana). В случае с трассировкой придется, как минимум, установить где-то Jaeger, а как максимум — научить ваше приложение грамотно обрабатывать HTTP-заголовки со служебными данными от трассировки.
Безопасность (Mutual TLS)
Напомню, протокол Mutual TLS (mTLS) — это взаимная, или двусторонняя, аутентификация клиента и сервера. Он нужен, когда мы хотим, чтобы наши клиент и сервер достоверно знали друг друга, не общались со всякими «незнакомцами». Также mTLS нужен, когда мы хотим зашифровать трафик между нашими приложениями. Технически это достигается с помощью обычных SSL-сертификатов.
В мире Istio у каждого Pod’а есть сертификат, который подтверждает подлинность этого Pod’а, а именно — подлинность его идентификатора (ID). В терминологии Istio идентификатор — это principal. Он состоит из трех частей:
ID кластера (Trust Domain),
Namespace’а приложения,
ServiceAccount’а, под которым работает Pod.

За выпуск сертификатов отвечает Control Plane, на основе собственного корневого сертификата. У каждой инсталляции Istio есть собственный корневой сертификат — root CA (его не стоит путать с корневым сертификатом самого кластера). На основе корневого сертификата выпускаются индивидуальные.

Давайте разберём весь жизненный цикл индивидуального сертификата.
Envoy в Istio не общается напрямую с Control Plane: он это делает через посредника, который называется Istio agent — утилита, написанная на Go, которая живет в одном контейнере с Envoy. Этот агент отвечает за ротацию сертификатов.
Istio-agent генерирует CSR с заявкой на ID (principal), который полагается нашему Pod’у. Но сначала этот ID нужно как-то сгенерировать. С Trust Domain всё просто: агент знает, в каком кластере работает Pod (переменная в ENV). С Namespace’ом и ServiceAccount’ом чуть сложнее…
Но вообще: что такое ServiceAccount? Остановимся на этом чуть подробнее.
ServiceAccount
У Kubernetes есть свой API, который подразумевает, что с ним никто анонимно общаться не будет. С другой стороны, API подразумевает, что к нему будут общаться Pod’ы. Рядовым приложениям это, как правило, не нужно: обычно с API Kubernetes общаются контроллеры, операторы и т. п. И чтобы решить этот вопрос, придумали специальные учетные записи, которые называются ServiceAccount.
ServiceAccount — это примитивный ресурс в K8s, который в момент создания никакой информации не несет. Он просто существует в каком-то Namespace’е, с каким-то именем. Как только такой ресурс появляется в кластере, Kubernetes на это реагирует и выпускает JWT-токен. Этот токен целиком описывает появившийся ServiceAccount. То есть Kubernetes подтверждает: «в моем кластере, в таком-то Namespace’е, с таким-то именем есть ServiceAccount» — и выдает специальный токен, который складывает в Secret (mysa-token-123).
Secret привязывается к ServiceAccount’у, который тем самым становится чем-то вроде ресурса со свидетельством о рождении. Данный ServiceAccount можно «привязать» к любому Pod’у, после чего, в ФС Pod’а будет автоматически примонтирован Secret с токеном, причем по заранее известному пути (/run/secret/kubernetes.io/serviceaccount/token). Собственно, данный токен и пригодится нам для того, чтобы узнать Namespace, в котором мы работаем, и ServiceAccount, от имени которого мы работаем.

Мы сгенерировали principal — теперь можем положить его в CSR.
Полученный CSR мы можем отправить в istiod. Но чтобы istiod поверил, что мы — это мы, в дополнение отправляем токен. Далее istiod проверяет этот токен через API K8s (TokenReview). Если K8s говорит, что всё хорошо, istiod подписывает CSR и возвращает в sidecar.

Для каждого Pod’а ротация сертификатов происходит раз в сутки.
Чтобы что-то взломать в этой системе, можно:
украсть сертификат (он будет действовать не более суток);
украсть токен ServiceAccount’а Pod’а, чтобы заказывать сертификаты от имени этого Pod’а;
взломать API Kubernetes — тогда можно заказать сколько угодно токенов, от имени какого угодно Pod’а;
украсть корневой сертификат Control Plane — самый примитивный и опасный взлом.
Всё это на самом деле довольно сложно реализовать. Поэтому можем считать, что mTLS в Istio безопасен.
Другие вопросы к Istio
К сожалению, осталось еще много вопросов, не раскрытых в докладе. И по каждому из этих вопросов достаточно много нюансов. Порой эти нюансы либо очень плохо описаны в документации, либо не описаны вовсе — приходится ковыряться в коде и обращаться к разработчикам Istio.
Множество из этих нюансов мы учли в модуле Istio для нашей платформы Deckhouse. С ее помощью вы можете за 8 минут развернуть готовый к использованию Kubernetes-кластер на любой инфраструктуре: в облаке, на «голом железе», в OpenStack и т. д.
Подробнее познакомиться с функциями, которые решает Istio в рамках Deckhouse, можно в нашей документации.
Видео и слайды
Видео с выступления (~31 минута):
Презентация доклада:
P.S.
Читайте также в нашем блоге:
«Назад к микросервисам вместе с Istio»: часть 1 (знакомство с основными возможностями), часть 2 (маршрутизация, управление трафиком), часть 3 (аутентификация и авторизация);
«Service Mesh: что нужно знать каждому Software Engineer о самой хайповой технологии»;
«Сценарии использования service mesh»;
«Представляем Kubernetes-платформу Deckhouse. Теперь в Open Source и для всех».
Интересные статьи
Интересные статьи



