
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Если вы когда-нибудь сравнивали данные двух аналитических инструментов на одном и том же сайте или сравнивали аналитику с отчётами и продажах, то, вероятно, замечали, что они не всегда совпадают. В этой статье я объясню, почему в статистике платформ веб-аналитики отсутствуют данные, и насколько крупными эти потери могут быть.
В рамках статьи мы сосредоточимся на Google Analytics, как самом популярном аналитическом сервисе, хотя большинство аналитических платформ, внедряемых on-page, имеют те же проблемы. Сервисы, которые полагаются на журналы сервера, избегают некоторых из этих проблем, но они настолько редко используются, что мы не будем касаться их в этой статье.
Тестовые конфигурации Google Analytics в Distilled
На сайте Distilled.net у нас имеется стандартный ресурс Google Analtics, работающий из HTML-тега в Google Tag Manager. Кроме того, в последние два года я использовал три дополнительные параллельные реализации Google Analytics, предназначенные для того, чтобы измерить расхождения между разными конфигурациями.
Две из этих дополнительных реализаций – одна в GTM, а другая on-page – управляют локально хранимыми, переименованными копиями JavaScript-файла Google Analytics (www.distilled.net/static/js/au3.js вместо www.google-analytics.com/analytics.js), чтобы их было сложнее обнаружить блокировщикам рекламы.
Я также использовал переименованные JavaScript-функции («tcap» и «Buffoon» вместо стандартного «ga») и переименованные трекеры («FredTheUnblockable» и «AlbertTheImmutable»), чтобы избежать проблемы дублирования трекеров (что часто может приводить к проблемам).
Наконец, у нас имеется конфигурация «DianaTheIndefatigable», которая имеет переименованный трекер, но использует стандартный код и реализована на уровне страницы.
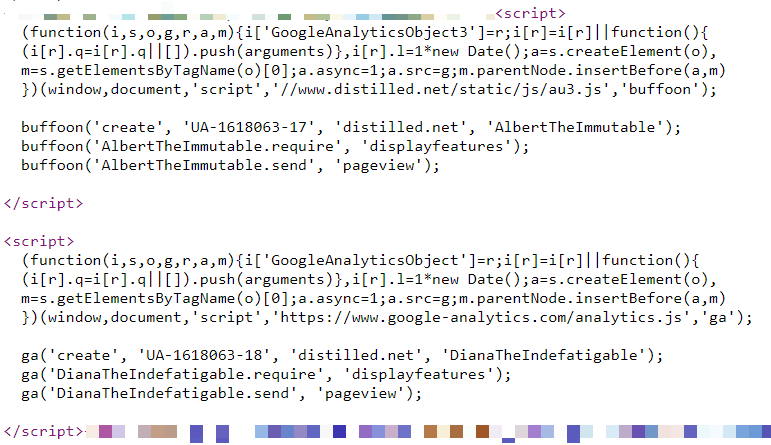
Все наши конфигурации отражены в таблице ниже:

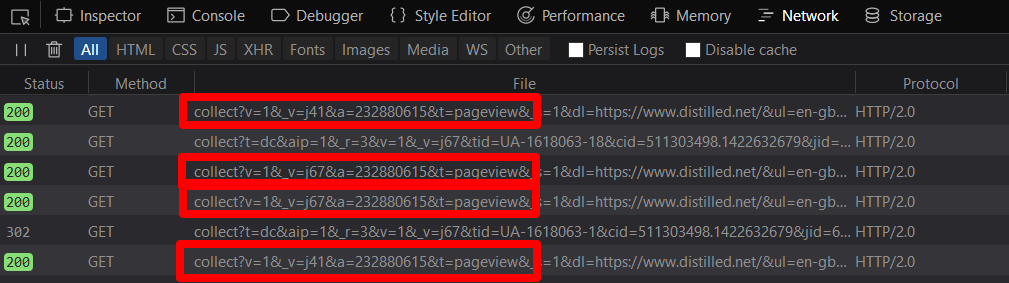
Я протестировал их функциональность в разных браузерах и блокировщиках рекламы, анализируя просмотры страниц, появляющиеся в инструментах разработчика браузера:
Причины потери данных
1. Блокировщики рекламы
Блокировщики рекламы, преимущественно в виде браузерных расширений, получают всё большее распространение. Изначально основной причиной их использования было улучшение производительности и опыта взаимодействия на сайтах с большим количеством рекламы. В последние годы возрос акцент на конфиденциальности данных, что также способствовало росту популярности адблокеров.
Влияние блокировщиков рекламы
Некоторые адблокеры блокируют платформы веб-аналитики по умолчанию, другие могут быть дополнительно настроены для выполнения этой функции. Я протестировал сайт Distilled с помощью Adblock Plus и uBlock Origin – двух самых популярных десктопных браузерных расширений для блокировки рекламы, но стоит отметить, что адблокеры также всё чаще используются и на смартфонах.
Были получены следующие результаты (все цифры относятся к апрелю 2018 года):
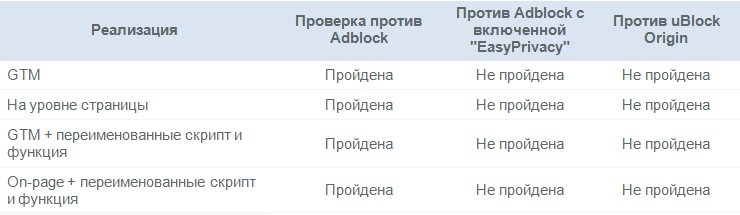
Как видно из таблицы, изменённые настройки GA не сильно помогают противостоять блокировщикам.
Потеря данных из-за блокировщиков рекламы: ~10%
Использование адблокеров может находиться на уровне 15-25% в зависимости от региона, но многие из этих установок – это AdBlock Plus с настройками по умолчанию, при которых, как мы видели выше, отслеживание не блокируется.
Доля AdBlock Plus на рынке блокировщиков рекламы варьируется в диапазоне 50-70%. По последним оценкам, эта цифра ближе к 50%. Поэтому, если допустить, что не более 50% установленных адблокеров блокируют аналитику, то мы получим потерю данных на уровне примерно 10%.
2. Функция «Do Not Track» в браузерах
Это ещё одна функция, использование которой мотивировано защитой конфиденциальности. Но на этот раз речь идёт не о надстройке, а о функции самих браузеров. Выполнение запроса «Не отслеживать» не является обязательным для сайтов и платформ, но, например, Firefox предлагает более сильную функцию под одним и тем же набором параметров, что я также решил протестировать.
Влияние «Do Not Track»
Большинство браузеров теперь предлагают опцию отправки сообщения «Не отслеживать». Я протестировал последние выпуски браузеров Firefox и Chrome для Windows 10.

Опять же, похоже, что здесь изменённые настройки также не сильно помогают.
Потеря данных из-за «Do Not Track»: <1%
Тестирование показало, что только функция Tracking Protection в браузере Firefox Quantum влияет на трекеры. Firefox занимает 5% браузерного рынка, но защита от отслеживания не включена по умолчанию. Поэтому запуск этой функции не оказал влияния на тренды Firefox-трафика на Distilled.net.
Фильтры
Фильтры, которые вы настраиваете в системе аналитики, могут преднамеренно или непреднамеренно занижать объёмы получаемого трафика в отчётности.
Например, фильтр, исключающий определённые разрешения экрана, которые могут являться ботами или внутренним трафиком, явно приведёт к некоторому занижению трафика.
Потеря данных из-за фильтров: N/A
Влияние этого фактора сложно оценить, поскольку эта настройка разнится в зависимости от сайта. Но я настоятельно рекомендую иметь дублированное, «основное» представление (без фильтров), чтобы можно было оперативно увидеть потерю важной информации.
4. GTM vs on-page vs неправильно расположенный код
В последние годы Google Tag Manager становится всё более популярным способом внедрения аналитики из-за его гибкости и лёгкости внесения изменений. Однако я давно замечаю, что этот метод реализации GA может приводить к занижению показателей в сравнении с настройкой на уровне страницы.
Мне также было любопытно, что случится, если не последовать рекомендациям Google касательно настройки кода on-page.
Сочетая собственные данные с данными с сайта моего коллеги Дома Вудмена (Dom Woodman), который использует аналитическое расширение Drupal, а также GTM, я смог увидеть разницу между Диспетчером тегов и неправильно расположенным на странице кодом (помещённым в нижней части тега ). Затем я сопоставил эти данные с моими собственными GTM-данными, чтобы увидеть полную картину по всем 5 конфигурациям.
Влияние GTM и неправильно расположенного on-page кода
Трафик как процент от базовой линии (стандартная реализация с использованием Диспетчера тегов):
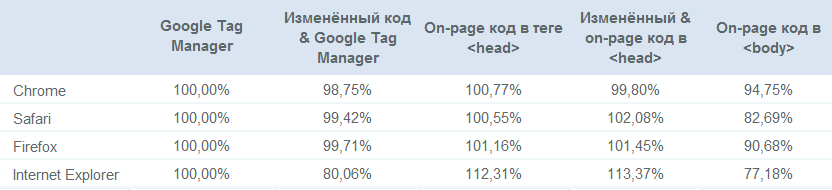
Основные выводы
- On-page код обычно регистрирует больше трафика, чем GTM;
- Изменённый код обычно находится в пределах погрешности, кроме изменённого GTM-кода в Internet Explorer;
- Неправильно расположенный код отслеживания будет стоить вам до 30% вашего трафика по сравнению с правильно реализованным on-page кодом, в зависимости от браузера (!);
- Пользовательские конфигурации, призванные получать больше трафика через уклонение от блокировщиков рекламы, этого не делают.
Также стоит отметить, что пользовательские реализации по факту получают меньше трафика, чем стандартные. В случае on-page кода потери находятся в рамках погрешности, но в случае GTM есть ещё один нюанс, который мог повлиять на итоговые данные.
Поскольку я использовал нефильтрованные профили для сравнения, в главном профиле находилось много бот-спама, который в основном маскировался под Internet Explorer.
На сегодняшний день наш основной профиль является наиболее заспамленным, но также используется в качестве уровня, выбранного для сравнения, поэтому разница между on-page кодом и Диспетчером тегов на самом деле несколько больше.
Потеря данных из-за GTM: 1-5%
Потери, связанные с GTM, варьируются в зависимости от того, какие браузеры и устройства используются посетителями вашего сайта. На сайте Distilled.net разница составляет около 1,7%, наша аудитория активно использует десктопы и является технически продвинутой, Internet Explorer используется редко. В зависимости от вертикали потери могут достигать 5%.
Я также сделал разбивку по устройствам:

Потеря данных из-за неправильно расположенного on-page кода: ~10%
На Teflsearch.com из-за неправильно расположенного кода терялось около 7,5% данных, против GTM. Учитывая, что Диспетчер тегов сам по себе занижает данные, то общие потери могли легко достигать 10%.
Бонус: потери данных из каналов
Выше мы рассмотрели области, в которых вы можете терять данные в целом. Однако есть и другие факторы, ведущие к получению неполных данных. Мы рассмотрим их более кратко. Главными проблемами здесь являются «тёмный» трафик и атрибуция.
«Тёмный» трафик
«Тёмный» трафик – это direct-трафик, которые в действительности не является прямым.
И это становится всё более распространённой ситуацией.
Типичные причины возникновения «тёмного» трафика:
- Непомеченные кампании email-маркетинга;
- Непомеченные кампании в приложениях (особенно в Facebook, Twitter и т.д.);
- Искажённый органический трафик;
- Данные, отправляемые из-за ошибок, допущенных в процессе настройки отслеживания (могут также появляться как self-referrals);
Также стоит отметить тренд в направлении роста истинно прямого трафика, который исторически был органическим. Например, в связи с усовершенствованием функции автозаполнения в браузерах, синхронизации истории поиска на разных устройствах и т.п., люди как бы «вводят» URL, который они искали ранее.
Атрибуция
В целом, сеанс в Google Analytics (и на любой другой платформе) – это довольно произвольный конструкт. Вы можете считать очевидным то, как группа обращений должна объединяться в один или больше сеансов, но в действительности, этот процесс полагается на ряд довольно сомнительных предположений. В частности, стоит отметить, что Google Analytics обычно приписывает прямой трафик (включая «тёмный» трафик) предыдущему не-direct источнику, если таковой существует.
Заключение
Я был несколько удивлен некоторыми из полученных мною результатов, но я уверен, что охватил не всё, и есть и другие пути потери данных. Так что, исследования в этой области можно продолжать и дальше.
Больше подобных статей можно читать на моём телеграм-канале (proroas).



