
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
CQM — другой взгляд в глубоком обучении для оптимизации поиска на естественном языке
Краткое описание: Calibrated Quantum Mesh (CQM)— это следующий шаг от RNN / LSTM (Рекуррентные нейронные сети RNN (Recurrent Neural Networks) / Долгая краткосрочная память (Long short-term memory; LSTM) ). Появился новый алгоритм, называемый Calibrated Quantum Mesh (CQM), который обещает повысить точность поиска на естественном языке без использования размеченных данных обучения.
Создан совершенно новый алгоритм поиска на естественном языке (NLS) и понимания естественного языка (NLU), который не только превосходит традиционные алгоритмы RNN / LSTM или даже CNN, но также является самообучающимся и не требует размеченных данных для обучения.
Звучит слишком хорошо, чтобы быть правдой, но первоначальные результаты впечатляют. CQM — разработана Praful Krishna и его командой в Coseer (San Francisco).
Хотя компания еще небольшая, они работают с несколькими компаниями из списка Fortune 500 и начали проводить технические конференции.
Вот где они надеются проявить себя:
Точность: Согласно Krishna, средняя функция NLS в более менее серьезном чат-боте, как правило, имеет точность только около 70%.
Первоначальные применения Coseer достигли точности более 95% в возвращении правильной значимой информации. Ключевые слова не требуются.
Маркированные учебные данные не требуются: Мы все знаем, что маркированные учебные данные — это финансовые и временные затраты, которые ограничивают точность наших чат-ботов.
Несколько лет назад М.Д. Андерсон отказался от своего дорогостоящего и многолетнего эксперимента с IBM Watson для онкологии из-за точности.
То, что сдерживало точность- это необходимость, чтобы очень опытные исследователи рака аннотировали документы в корпусе. Они должны были делать это вместо того, чтобы заниматься своими исследованиями.
Скорость внедрения: Coseer говорит, что без обучающих данных, большинство внедрений может быть запущено в течение 4-12 недель. Это намного меньше того, когда пользователь начинает использовать предварительно обученную систему, работа которой начинается с предварительной загрузки размеченных документов.
Кроме того, в отличие от нынешних крупных поставщиков, использующих традиционные алгоритмы глубокого обучения, Coseer предпочитает внедрять их как в защищенном, так и в частном облаке для обеспечения безопасности данных.
Все «доказательства», использовавшиеся для того, чтобы прийти к какому-либо заключению, хранятся в журнале, который можно использовать для демонстрации прозрачности и соответствия правилам безопасности данных, таким как GDPR.
Как это работает
Coseer говорит о трех принципах, которые определяют CQM:
1. Слова (переменные) имеют разные значения.
Рассмотрим слово «печь», которое может быть существительным или глаголом. Например «стих», что может означать «стихотворение» или глагол «стих ветер» — это слова омонимы.
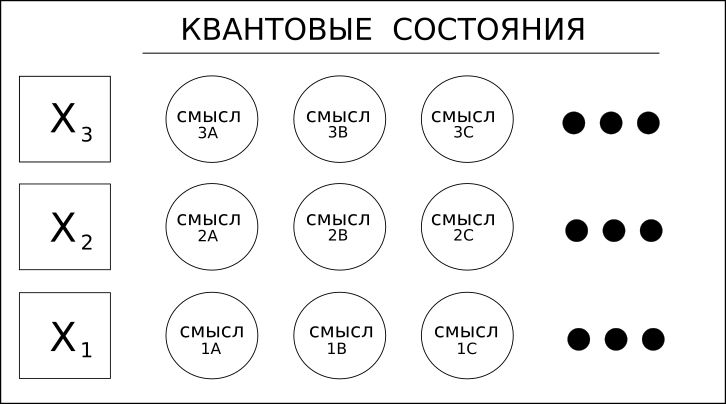
Решения для глубокого обучения, включая RNN / LSTM или даже CNN для текста, могут только смотреть вперед или назад, чтобы определить «контекст» слова и тем самым определить его значение.
Coseer учитывает все возможные значения слова и применяет статистическую вероятность к каждому из них на основе всего документа или корпуса.
Использование термина «квант» в этом случае относится только к возможности множественных значений, а не к более экзотической суперпозиции квантовых вычислений.
2. Все взаимосвязано в сетке значений:
Извлечение из всех доступных слов (переменных) всех их возможных отношений является вторым принципом.
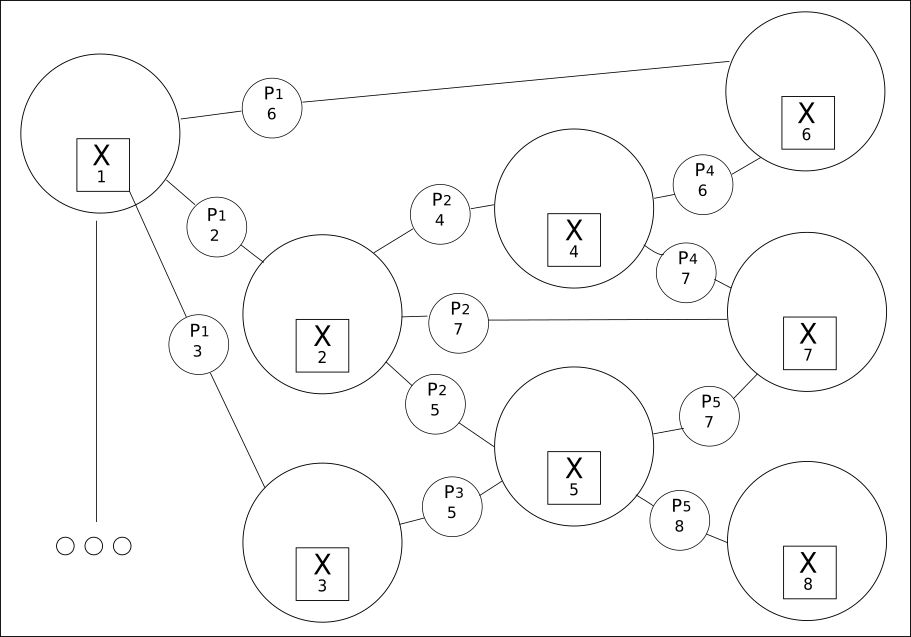
CQM создает сетку возможных значений, среди которых будет найдено реальное значение. Использование этого подхода позволяет выявить гораздо более широкие взаимосвязи между предыдущими или последующими фразами, чем может обеспечить традиционное Deep Learning.
Хотя количество слов может быть ограничено, их взаимосвязи могут исчисляться сотнями тысяч.
3. Используется вся доступная информация последовательно, чтобы объединить сетку в одно значение. Этот процесс калибровки быстро выявляет пропущенные слова или понятия и обеспечивает очень быстрое и точное обучение.
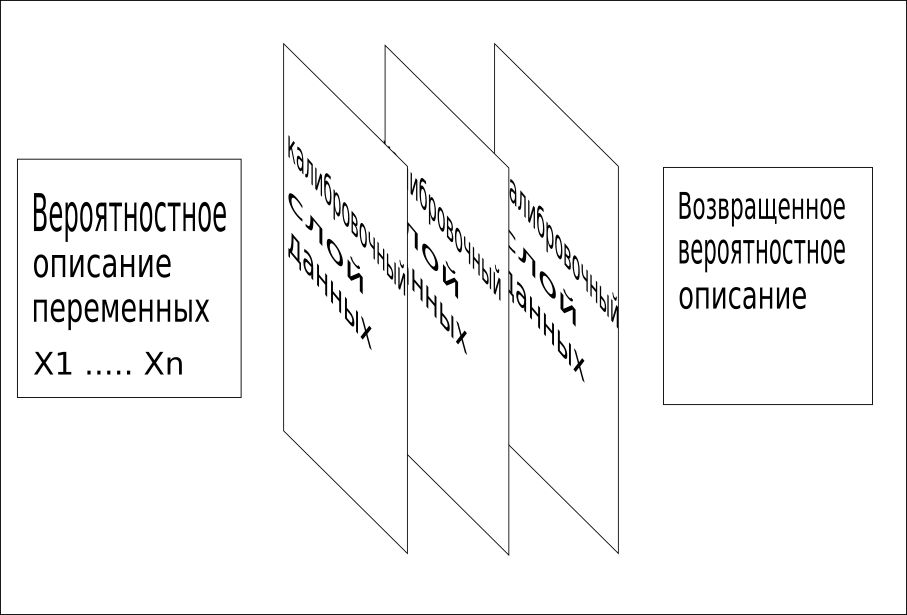
Модели CQM используют данные обучения, контекстные данные, справочные данные и другие факты, известные о проблеме, для определения этих калибровочных слоев данных.
К сожалению, Coseer опубликовал очень мало в открытом доступе, чтобы объяснить технические аспекты алгоритма.
Любой прорыв в устранении помеченных данных при обучении следует приветствовать, и, безусловно, повышение точности приведет к тому, что гораздо больше довольных клиентов будут использовать ваш чат-бот.



