
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Аннотация
Табличные данные широко распространены в различных реальных приложениях. Хотя многие широко используемые нейронные компоненты (например, свертки) и расширяемые нейронные сети (например, ResNet) были разработаны сообществом машинного обучения, только немногие из них показали свою эффективность для табличных данных, и лишь немногие проекты были релевантно адаптированы к табличным структурам данных. В этой статье мы предлагаем новый и гибкий нейро-компонент для табличных данных, называемый абстрактным слоем (ABSTLAY - Abstract Layer), который обучаем явно группировать коррелирующие входные объекты и генерировать объекты более высокого уровня семантической абстракции (формализации). Кроме того, мы разрабатываем метод репараметризации структуры для сжатия слоя ABSTLAY, тем самым значительно снижая вычислительную сложность на контрольном слое. Специальный базовый блок строится с использованием ABSTLAY, и мы создаем семейство глубоких абстрактных сетей (DANET - Deep Abstract Networks) для классификации табличных данных и регрессии путем группировки (таксономии) таких блоков. В DANET введен специальный кратчайший путь для извлечения информации из необработанных табличных объектов, способствующий взаимодействию объектов на разных уровнях. Всесторонние эксперименты с семью реальными табличными наборами данных показывают, что наши ABSTLAY и DANET эффективны для классификации и регрессии табличных данных, а их вычислительная сложность не превосходит сложности конкурентных методов. Кроме того, мы оцениваем прирост производительности DANET по мере его углубления, проверяя модифицируемость нашего метода. Наш код доступен по адресу https://github.com/WhatAShot/DANet .
Вступление
Данные, организованные в табличные структуры, например, медицинские (Хассан и др., 2020; Миррошандель и др., 2016) и банковские (Рой и др., 2018; Бабаев и др., 2019; Аддо и др., 2018) широко распространены в повседневной жизни. Однако, в отличие от бума глубокого обучения в области компьютерного зрения и общения на естественном языке, очень немногие нейронные сети были релевантно спроектированы для табличных данных (Арик и Пфистер 2020; Ян и др. 2018; Ке и др. 2018; Рой и др. 2018; Бабаев и др. 2019; Наир и Хинтон 2010; Го, Тан и др. 2017), и, следовательно, производительность таких нейронных сетей, например, в задачах классификации и регрессии, все еще была несколько ниже (Абутбул и др. 2021). Вдохновленный успехом ансамблевого обучения на табличных данных (например, XGBoost) (Фридман 2001; Чен и Гестрин 2016; Ке и др. 2017; Прохоренкова и др. 2018; Хо 1995), некоторые недавние работы прибегли к объединению нескольких нейронных сетей в рамках ансамблевого обучения (Попов и др. 2019; Абутбул и др. 2021; Ке и др. 2019). Хотя ансамблевое обучение может повысить производительность нейронных сетей на табличных данных (за счет увеличения вычислительных мощностей), с помощью таких методов возможности нейронных сетей в автоматическом проектировании табличных объектов еще не используются в полной мере. Кроме того, существует не так много эффективных нейронных компонентов, специально предназначенных для табличных данных (аналогично свертке для компьютерного зрения). Следовательно, известные нейронные сети в основном основывались на различных компонентах и, следовательно, были не очень расширяемыми.
В этой статье мы представляем гибкий нейронный компонент под названием Abstract Layer (ABSTLAY) для абстрактного представления табличных объектов и построения глубоких абстрактных сетей (DANET) на основе ABSTLAY для классификации и регрессии табличных данных. Поскольку табличные объекты, как правило, нерегулярны, трудно ввести фиксированные индуктивные искажения (такие как зависимость между соседними по признаковому пространству объектами на изображениях) при проектировании нейронных сетей для обработки табличных данных (например, классификация и регрессия). С этой целью мы предполагаем, что в табличной структуре данных существуют некоторые базовые группы объектов, а функции в группах коррелируют и могут быть использованы для реализации функций более высокого уровня, соответствующих целям прогнозирования. Мы предлагаем разделить процесс абстракции табличных объектов более высокого уровня на два этапа:
1) группировка коррелирующих объектов;
2) абстракция объектов более высокого уровня из сгруппированных объектов.
Мы используем ABSTLAY для выполнения этих двух шагов, и DANET повторяет эти шаги, применяя ABSTLAY для представления критической семантики табличных данных.
На рис. 1 приведен пример, иллюстрирующий наши идеи. Как показано на рис. 1(а), возможные базовые группы объектов и потенциальные пути абстракции объектов организованы следующим образом. Рост и вес могут быть сгруппированы вместе для идентификации более полных (интегральных) характеристик, которые отражают телосложение. Аналогичным образом, функции, отражающие здоровье печени и почек, могут быть абстрагированы от исходных функций, а функции, представляющие состояние здоровья, могут дополнительно абстрагироваться от трех функций высокого уровня. Напротив, на рис. 1 (б) наш метод учится находить и группировать коррелирующие признаки, а затем абстрагировать их в объекты более высокого уровня. Этот процесс повторяется до тех пор, пока не будет получена глобальная семантика. Табличные объекты более высокого уровня абстрагируются одним нейронным слоем (ABSTLAY), а процесс иерархической абстракции реализуется с помощью сетей глубокого обучения. Вот почему мы называем их Абстрактными слоями и Глубокими абстрактными сетями соответственно.
 Осуществимый семантически-ориентированный процесс абстракции признаков. Существуют три основные группы признаков, которые можно найти для вычисления высокоуровневых признаков, измеряющих телосложение, здоровье печени и здоровье почек; затем эти три функции дополнительно группируются для оценки состояния здоровья. (b) ABSTLAY (1) изучает правильную предвзятость выбора признаков для группировки коррелятивных признаков, а затем (2) реферирует значимые признаки более высокого уровня, а DANET организует ABSTLAY для повторения этого процесса до окончательного получения глобальной семантики для оценки состояния здоровья. Синие прямоугольники обозначают вычисленные высокоуровневые признаки, серые линии обозначают кандидатов на выбор признаков, а черные стрелки отмечают выбранные в конечном итоге признаки.")
При разработке ABSTLAY мы рассматриваем, как группировать объекты и абстрагировать их в объекты более высокого уровня. Поскольку трудно найти метрическое пространство для измерения различий группируемых объектов из-за неоднородности табличных данных, слой ABSTLAY учится находить группы объектов, используя обучаемые маски (например, по прецедентам) разреженного веса для группировки объектов, без введения какого-либо измерения расстояния. Затем последующие обучающие функций (в ABSTLAY) используются для абстрагирования функций более высокого уровня из соответствующих групп функций. Далее, руководствуясь репараметризацией структуры (Ding et al. 2021), мы разрабатываем конкретный метод репараметризации для объединения двухэтапных операций ABSTLAY в один шаг на этапе вывода, уменьшая вычислительную сложность.
Наши Danet строятся в основном путем последовательного интегрирования (свертки) абстрагированных элементов и, таким образом, табличные объекты рекурсивно абстрагируются слой за слоем для получения глобальной семантики. Чтобы пополнить полезные функции и увеличить разнообразие функций, мы также вводим кратчайший путь, аналогичный остаточному ярлыку (He et al. 2016), который непосредственно вводит информацию о необработанных табличных функциях в функции более высокого уровня. В частности, мы находим свертку абстракции объектов более высокого уровня ABSTLAY и операцию извлечения объектов кратчайшего пути в базовый блок (как указано на рис. 2 (b)), и наши наборы данных создаются путем свертки таких блоков (см. рис. 2 (c)). Обратите внимание, что различные эмпирические данные (He et al. 2016; Qi et al. 2017) свидетельствуют о том, что успехи глубоких нейронных сетей (DNN) частично выигрывают от глубины модельного анализа. Таким образом, мы разрабатываем сети с глубокой архитектурой, а обширные эксперименты подтверждают, что увеличение глубины модельного анализа действительно приводит к увеличению производительности.
Вкратце, состав этого документа заключается в следующем:
1) предлагается ABSTLAY, который группирует объекты и обрабатывает их для абстракции объектов более высокого уровня, причем ABSTLAY прост, а его вычислительная сложность может быть уменьшена с помощью нашего метода репараметризации структуры;
2) вводится специальный кратчайший путь, позволяющий извлекать необработанные функции более высоких уровней, способствуя росту разнообразия функций для поиска значимых групп функций;
3) на основе ABSTLAY создается DANET для решения задач классификации табличных данных и регрессии путем рекурсивного абстрагирования объектов с целью получения критической семантики табличных объектов, а DANET превосходит предыдущие методы в нескольких общедоступных наборах данных.
Литературный обзор
Обработка табличных данных. Различные традиционные методы машинного обучения (Он и др. 2014; Брейман и др. 1984; Чен и Гестрин 2016; Чжан, Кан и др. 2006; Чжан и Хонавар 2003) были предложены для классификации табличных данных и обучения ранжированию (регрессии). Моделями дерева решений (Quinlan 1979; Breiman et al. 1984) представимы четкие пути принятия решений, надежные для простых табличных наборов данных. Ансамблевые модели, основанные на деревьях решений, таких как GBDT (Фридман 2001), LightGBM (Ке и др. 2017), XGBoost (Чен и Гестрин 2016) и CatBoost (Прохоренкова и др. 2018), в настоящее время являются лучшим выбором для обработки табличных данных, и их производительность была сопоставим с DANET (Ангель и др. 2018).
В настоящее время исследовательская тенденция направлена на применение DANET (Guo, Tang et al. 2017; Yang et al. 2018) к табличным наборам данных. Некоторые нейронные сети в рамках фреймворков ансамблевого обучения были представлены в (Lay et al. 2018; Feng et al. 2018). Недавно NODE (Popov et al. 2019) объединил нейронные деревья решений, с всюду плотными связями и получил сопоставимые характеристики с GBDT (Friedman 2001). Net-DNF (Abutbul et al. 2021) внедрил программируемые версии логических булевых формул для объединения результатов большого числа неглубоких связанных моделей. Как NODE, так и Net-DNF по существу следовали ансамблевому обучению, используя множество (например, 2048) мелких нейронных сетей, и, таким образом, были вычислительно сложными. В таких стратегиях не изучался потенциал глубоких моделей, а их эффективность следует в значительной степени приписывать количеству подсетей. TabNet (Arik и Pfister 2020) последовательно вычисляли частные решения, чтобы имитировать процедуру последовательного разделения объектов древовидных моделей. Однако было подтверждено, что Tabnet обладает несколько более низкими характеристиками, как отмечено в (Abutbul et al. 2021).
Выбор функции. Поскольку табличные объекты неоднородны и нерегулярны, ранее применялись разнообразные методы выбора объектов. Классические древовидные модели часто использовали информационные меры, критерии определения выбора объектов, такие как прирост информации (Quinlan 1979), темп прироста информации (Quinlan 2014) и индекс Джини (Breiman et al. 1984), которые, по сути, являются «жадными алгоритмами» и могут потребовать применения метода ветвей и границ (Quinlan 2014) или стратегии ранней остановки. Ансамблевые методы анализа дерева решений часто применяли случайную выборку признаков для увеличения разнообразия. Чтобы еще больше облегчить выбор объектов, некоторые методы упаковки использовали оценку типа «из пакета» (Джеймс и др., 2013), а gcForest (Чжоу и Фэн, 2017) использовали скользящие окна для сканирования и группировки необработанных объектов для разных лесов, т.е. временных интервалов с набором значений, используемых в обучающей выборке. Полностью подключенная нейронная сеть (Наир и Хинтон 2010) слепо использовала все функции, а TABNN (Ke et al. 2018) выбрала функции на основе «знаний о структуре данных», полученных GBDT. Большинство древовидных моделей выбирали один-единственный объект за один шаг, игнорируя корреляции базовых объектов.
 Иллюстрация ABSTLAY, которая выполняет три шага: выбор функций, абстрагирование функций и объединение выходных данных. В примере (a) количество масок K установлено равным 3 (см. Формула (3)), размер выходного объекта d установлен равным 2 и указывает на поэлементное умножение. (b) Иллюстрация базовой спецификации блока. (c) Архитектура DANET строится главным образом путем объединения нескольких базовых блоков.")
В настоящее время в некоторых нейронных сетях введены нейронные операции для выбора объектов. NODE (Попов и др., 2019) использовал обучающие матрицы выбора объектов с функциями Хевисайда для жесткого выбора объектов, имитируя обработку забытых деревьев решений. Ключом к NODE является то, что оптимизация обратного распространения используется для замены информационных показателей при обучении «древовидных» моделей. Однако параметры, заданные функциями Хевисайда, трудно обновить с помощью обратного распространения, и, следовательно, узлу может потребоваться много итераций до достижения сходимости за приемлемое время. Net-DNF использовал сквозной трюк (Bengio et al. 2013) для оптимизации этой проблемы, но он требовал дополнительных функций потерь в масках выбора обучающих объектов и был неудобен для пользователей. TabNet (Arik и Pfister 2020) использовали механизм внимания для выбора объектов, но выбирали разные объекты для разных экземпляров; следовательно, трудно было фиксировать стабильные корреляции объектов. Напротив, в этой статье предпринята попытка найти базовые группы функций, представляющие релевантную семантику, и разработать соответствующие операции, которые были бы простыми и удобными для пользователя.
Постановка задачи.
Предположим, что X = (F, X, y) - это один из типов конкретной табличной структуры данных, где F задает пространство типа необработанного объекта, X - допустимое пространство экземпляра, а y - целевое пространство. В табличном наборе данных типа X экземпляр x ∈ Rn в X определяется как вектор из n элементов, представляющий n скалярных необработанных объектов в F (n = |F| ). Примечательно, что объекты табличных данных являются нерегулярными, а перестановка объектов в x определена (задана) заранее. В этой статье мы предполагаем, что в табличной структуре данных существуют некоторые базовые группы объектов, а объекты в группе являются коррелятивными и релевантными для цели. Обратите внимание, что некоторые функции могут не входить ни в одну группу, а некоторые – могут входить в несколько групп одновременно. Мы заинтересованы в изучении значений функций, которые принимают x ∈ X в качестве входных данных, извлекают и рассматривают базовые группы объектов для семантических интересов.
Абстрактный Слой AbstLay
Ключевые функции и операции.
Мы предлагаем абстрактный слой (ABSTLAY), который учится находить некоторые базовые группы объектов и абстрактные объекты более высокого уровня путем обработки сгруппированных объектов. Также желательно, чтобы накладка была гибкой и простой в качестве базового слоя. В нашем проекте, ABSTLAY включает функции выбора объектов для поиска групп объектов, соответствующих функций абстрагирования объектов для абстрагирования объектов более высокого уровня из групп, а также операцию объединения выходных данных для объединения объектов, абстрагированных из различных групп, как показано на рис. 2(а).
Действие выбора функции. Учитывая входной вектор f ∈ Rm, содержащий m скалярных объектов, обучаемая разреженная маска M ∈ Rm выбирает подмножество скалярных объектов из f для одной группы. В частности, эта обучаемая маска определяется как обучаемый вектор параметров Wmask, за которым следует отображение разреженности Entmax (Peters et al. 2019), а объекты выбираются путем поэлементного умножения на разреженную маску M. Entmax - это вариабельная форма (Уэйнрайт и Джордан, 2008) Softmax, которая вносит разреженность в выходную вероятность. Формально выбор объекта определяется (формула 1);
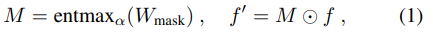
где вектор параметров Wmask ∈ Rm , символ кружочка обозначает поэлементное умножение, а выбранные объекты представлены в f' ∈ Rm. Для параметра α в отображении разреженности Entmax мы используем настройку по умолчанию с α = 1.5. При умножении в f' есть некоторые нулевые значения, а нулевое значение для i-го скалярного признака вектора f' означает, что i-й скалярный признак в f не выбран. Этот выбор функций прост и позволяет выбирать идентичные функции для разных экземпляров.
Возможность абстрагирования функций. Учитывая выбранные объекты в f' ∈ Rm (как определено выше), мы определяем функцию абстрагирования объектов, используя сильно связный слой с простым механизмом внимания (Dauphin et al. 2017). Формально выходной сигнал f∗ функции абстрагирования объектов вычисляется с помощью

где два обучаемых параметра Wc ∈ Rd × m (c = 1,2) имеют одинаковый размер, а q обозначает вычисленный вектор внимания. Поскольку табличные данные часто обучаются с большим размером пакета, мы используем нормализацию призрачных пакетов (Хоффер и др., 2017) для работы с “BN”. Таким образом, выбранные объекты в векторе f' ∈ Rm проецируются на f∗ ∈ Rd, и мы рассматриваем значения d в векторе объектов f∗ как независимые скалярные объекты, представляющие различную семантику. Обратите внимание, что все d-функции f∗ абстрагированы из одной и той же группы (определяются одним и тем же M в уравнении (1)).
Параллельная обработка и объединение выходных данных. Эффект абстрагирования реализуется в первую очередь функцией выбора объектов и функцией абстрагирования объектов. Эти две функции работают последовательно, чтобы абстрагировать объекты более высокого уровня от групп объектов более низкого уровня. Тем не менее, мы считаем, что в заданном векторе признаков f можно найти более одной такой группы. Кроме того, информационные выходные функции обычно получаются путем параллельного применения некоторых единичных операций (например, уровень свертки часто содержит много ядер). Исходя из этого, ABSTLAY предназначен для параллельного поиска и обработки нескольких групп объектов низкого уровня. Формально мы определяем его вычисление с помощью (формула 3),
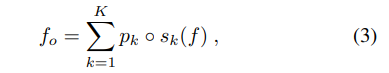
где p ◦ s обозначает сверточную композицию функции выбора объектов s и функции абстрагирования объектов p, а K - количество групп объектов, которые ABSTLAY удается получить, и является гипер-параметром. Мы устанавливаем размеры выходных объектов для всех pk ◦ sk одинаковыми. Выходные характеристики всех составных функций pk ◦ sk добавляются поэлементно, чтобы сформировать выходные характеристики fo от ABSTLAY (см. рис. 2(а)).
Подобно слоям свертки в модели, несколько слоев могут быть интегрированы и работать как единое целое. Таким образом, выходные скалярные функции одного ABSTLAY могут быть дополнительно сгруппированы по его последующему ABSTLAY для дальнейшей абстракции (формализации) информации, а бесполезные выходные функции из предыдущего ABSTLAY могут быть отброшены. В отличие от сложной функции «преобразование объектов» в Tabnet (Arik и Pfister 2020), возможности ABSTLAYs в значительной степени обусловлены их сотрудничеством (например, послойной обработкой).
Уменьшение сложности ABSTLAY.
Чтобы уменьшить вычислительную сложность предлагаемой нами модели абстрагирования, мы разрабатываем следующий метод повторной параметризации (Ding et al. 2021) для перезапуска процесса абстрагирования. Обратите внимание, что W1 ∈ Rd × m и W2 ∈ Rd × m являются весами функции абстрагирования объектов, а M ∈ Rm также является весовым вектором. Подставляя соотношение (1) в соотношение (2), мы имеем

Следовательно, мы можем использовать W 'c ∈ R d × m для замены множителя WCM (c = 1,2) в уравнении (4) на

где j = 1,2,...,m, а m - размер входного объекта. Кроме того, мы можем дополнительно объединить операцию пакетной нормализации с весами W 'c с помощью
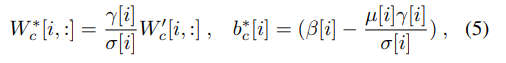
где i = 1,2,..., d и d - размерность выходного признака, γ ∈ Rd и β ∈ Rd являются доступными параметрами пакетной нормализации, за которыми следует Wc (формула z ' = (γ / σ)z + (β − μγ / σ ) для вектора признаков z), а µ ∈ Rd и σ ∈ Rd - вычисленное среднее значение и стандартное отклонение. Затем операция в абстрагировании (см. уравнение (3)) может быть упрощена как

где W∗k,c (c = 1,2) - веса W∗c, повторно параметризованные уравнением (5) для k-й функции абстрагирования объектов в ABSTLAY (см. уравнение (3), ABSTLAY имеет K функций), а b∗k,c - это b∗c в уравнении(5) для k-й функции абстрагирования объектов. Таким образом, более легкая модель может быть использована для вывода путем повторной параметризации.
Глубокие Абстрактные Сети
Основываясь на предложенной модели ABSTLAY, мы вводим глубокие абстрактные сети (DANET - Deep Abstract Networks) для обработки табличных данных. DANET соединяет (итерирует) абстракции, чтобы повторно находить и обрабатывать некоторые значимые группы объектов для абстракции объектов более высокого уровня. Кроме того, мы позволяем группировать функции на разных уровнях, тем самым увеличивая возможности модели. Следовательно, мы разрабатываем новый кратчайший путь, который позволяет высокоуровневому слою извлекать необработанные объекты. В частности, мы предлагаем базовый блок, основанный на абстрагировании, содержащем кратчайший путь, и наши DANET строятся путем последовательной обработки таких объектов (блоков).
Базовый Блок.
Наш базовый блок в основном построен с использованием ABSTLAY, и новый список (ярлык) может добавлять в основной путь модели объекты, абстрагированные от групп необработанных объектов. Рис. 2(б) иллюстрирует спецификацию базового блока в DANET. Формально мы определяем i-й базовый блок fi с помощью

где gi — ярлык, состоящий из слоев ABSTLAY и Dropout (Srivastava et al. 2014) и принимает необработанные функции x в качестве входных данных. Терм Gi находится на основном пути, содержащем несколько ABSTLAY, и его входными данными являются функции, созданные предыдущим базовым блоком (см. рис. 2(c)). Для первого базового блока f1 положим f0 = x. В отличие от остаточного блока в ResNet (He et al. 2016), краткий путь которого приносит функции предыдущих слоев, наш ярлык извлекает необработанные функции.
В DANET с множеством базовых блоков (см. рис. 2(c)) комбинация Gi базовых блоков действует как основной путь модели, который извлекает и пересылает целевую информацию, которая постоянно пополняется с помощью сокращенных терминов gi основных блоков. Из рис. 2(c) видно, что необработанный объект может быть использован базовым блоком высокого уровня напрямую через ярлык, в то время как информация о некоторых необработанных объектах может быть получена на уровне более высокого уровня по основному пути после послойной обработки. Таким образом, разнообразие объектов в слое увеличивается по сравнению со слоем в модели без таких сокращений. Примечательно, что мы включаем операцию удаления блоков кратчайшего пути, что побуждает при последующем абстрагировании сосредоточиться на основной информации, которая требуется базовому блоку.
Сетевые архитектуры и обучение. Мы последовательно объединяем базовые блоки для построения архитектуры DANET, как показано на рис. 2(c). В нашей настройке мы исправляем базовую спецификацию блока, которая содержит три уровня абстрагирования, как показано на рис. 2(b). То есть в уравнении (7) Gi состоит из двух слагаемых, а gi содержит одну. Затем трехслойная MLP (многослойная сеть персептрона) с активацией ReLU используется в конце DANET для классификации с помощью модели Softmax или регрессии. Мы протестировали различные спецификации сетевой архитектуры и наблюдали последовательные закономерности. Здесь мы представляем некоторые конкретные архитектуры 1, такие как DANET-20 и DANET-32, для анализа эффектов DANET.
Подобно предыдущим DNN для табличных данных (Арик и Пфистер 2020; Попов и др. 2019), наши DANET могут решать задачи классификации и обучения ранжированию (регрессии) для табличных данных. DANET обучаются с использованием спецификации функции потерь взаимной энтропии для классификации и обучаются с использованием среднеквадратичной ошибки (MSE) для регрессии. Обратите внимание, что названия объектов в этой статье не используются.
Эксперименты
В этом разделе мы представляем обширные эксперименты для сравнения эффектов наших наборов данных и известных современных моделей. Кроме того, мы представляем несколько эмпирических исследований для анализа влияния некоторых критических компонентов DANET, включая обучаемые разреженные маски, кратчайшие пути, анализ в глубину и ширину модели (значение K в формуле (3)). Кроме того, мы оцениваем влияние предлагаемых нами разреженных масок на корреляцию группировки объектов с использованием трех синтезированных наборов данных.
Экспериментальные установки
Наборы данных. Мы проводим эксперименты с семью табличными наборами данных с открытым исходным кодом: Microsoft (Qin and Liu 2013), YearPrediction (Bertin-Mahieux et al. 2011) и Yahoo (Mohan et al. 2011) для регрессии; типа «лесного покрова», «клик», «эпсилон» и сердечно-сосудистые заболевания для классификации. Подробная информация о наборах данных приведена в таблице 1. Большинство наборов данных содержат разбивку на обучающие тесты. Для набора типа «Клик (Click)» мы следуем разделению обучающих тестов, предоставленному 6-й версией NODE с открытым исходным кодом (Popov et al. 2019). Во всех экспериментах мы фиксируем разделение набора данных и теста для адекватного сравнения. Для задач по обучению ранжированию мы используем регрессию, аналогичную предыдущей работе. Для Click категориальные функции были предварительно обработаны с помощью кодировщика Leave-One-Out библиотеки scikit-learn. Мы использовали официальный набор для тестирования каждого набора данных, если он указан. В наборах данных, которые не предоставляют официальные наборы, мы стратифицировали выборку 20% экземпляров из полных обучающих наборов данных для проверки.

Детали реализации. Мы реализуем наши различные архитектуры DANET с помощью PyTorch на Python 3.7. Все эксперименты выполняются на NVIDIA Tesla V100. При обучении размер пакета составляет 8192 с размером виртуального пакета данных 256 в слоях нормализации пакета, а скорость обучения изначально установлена на 0,008 и уменьшается на 5% каждые 20 периодов (epochs). Оптимизатором является QHAdam optimizer (Ma и Yarats 2019) с конфигурациями по умолчанию, за исключением коэффициента снижения веса 10-5 и коэффициентов скидки (0.8, 1.0). Для других методов характеристики получаются с учетом их конкретных настроек. В отличие от предыдущих методов, требующих тщательной настройки их гипер-параметров, например, NODE (Popov et al. 2019), мы исправляем основную настройку DANET: устанавливаем k0 = 5, d0 = 32 и d1 = 64 по умолчанию (см. рис. 2(b)). Для наборов данных с большим количеством необработанных объектов (например, Yahoo с 699 объектами и Epsilon с 2 тыс. объектов) мы устанавливаем k0 = 8, d0 = 48 и d1 = 96. Мы используем коэффициент отсева 0.1 для всех наборов данных, за исключением типа "лесного покрова", без использования отсева. Характеристики других методов гипер-параметрически настраиваются для достижения наилучших результатов с использованием библиотеки Hyperopt 7 и выполняются 50 шагов алгоритма оптимизации с древовидной структурой Parzen Estimator (TPE), аналогично настройкам в работе (Popov et al. 2019). Мы установили пространства поиска гипер-параметров и алгоритмы поиска XGBoost (Чен и Гестрин 2016), CatBoost (Прохоренкова и др. 2018), NODE (Попов и др. 2019) и FCNN (Наир и Хинтон 2010), как в (Попов и др. 2019), в то время как настройки поиска гипер-параметров Net-DNF (Abutbuletal.2021) и Tabnet (Арик и Пфистер 2020) следовали их оригинальным документам. Гипер-параметры gcForest (Zhou и Feng 2017) соответствовали значениям по умолчанию. Архитектуры FCNN с регуляризацией (методом «лассо») или без нее были построены в соответствии с FCNN в (Popov etal. 2019). Гипер-параметры этих сравниваемых методов выбираются в соответствии с характеристиками проверки, и характеристики являются.
Базовые показатели сравнения. Чтобы оценить производительность, мы сравниваем наши DANET-20 и DANET-32 с несколькими распространенными традиционными методами, включая XGBoost (Чен и Гестрин 2016), GCFOREST (Чжоу и Фенг 2017) и CatBoost (Прохоренкова и др. 2018), а также наиболее известные нейронные сети, в том числе Tabnet (Арик и Пфистер 2020), FCNN (Наир и Хинтон 2010) с регуляризацией «лассо» и без нее, и NODE (Попов и др. 2019).
.")
Сравнение результатов и результатов анализа
Результаты сравнения по семи табличным наборам данных представлены в таблице 2. Можно видеть, что наши методы (т.е. DANET-20 и DANET-32) превосходят или сопоставимы с предыдущими нейронными сетями и GBDT. Обратите внимание, что параметры наших наборов данных заданы заранее, в то время как другие методы специально настроены на гипер-параметр для каждого набора данных. Это означает, что наши DANET не только более производительны, но и просты в использовании. Кроме того, мы ранжируем все методы (кроме GCFOREST (Zhou and Feng 2017) и Net-DNF (Abutbul et al. 2021), поскольку они могут работать только для задачи классификации) на основе усредненных оценок производительности в наборах данных, и наши методы DANET-20 и DANET-32 достигают наилучших результатов среди всех методов. Кроме того, общие характеристики DANET-32 лучше, чем у DANET-20, что обеспечивает прирост производительности за счет увеличения глубины анализа модели.
Последствия коротких путей. Ключевой особенностью наших DANET являются специальные быстрые соединения в базовых блоках. Чтобы проверить влияние предлагаемых нами ярлыков, мы сравниваем DANET и модели с обычными остаточными ярлыками (Res-shortcut), модели без каких-либо ярлыков и модели с плотно связанными ярлыками («Плотный ярлык») (Хуан и др., 2017). Справедливости ради, мы заменяем наши ярлыки лишь другими ярлыками в DANET-8, DANET-20 и DANET-32. Характеристики показаны на рис.3. Очевидно, что DANET с нашими ярлыками значительно превосходят модели с другими ярлыками всех спецификаций глубины модели. Кроме того, можно было заметить, что эффекты предлагаемых нами модификаций более очевидны в большинстве случаев с более глубокими сетями. Например, на рис.3(b), (d), (e), (f) и (g) различия в производительности на DANET-32 более заметны, чем на DANET-8. Это может быть связано с тем, что информация может быть эффективно пополнена с помощью наших ярлыков, что помогает повысить эффективность более глубоких моделей.
, (b), (c) и (d)) чем выше точность, тем лучше. Для регрессии (показанной в (e), (f) и (g)) чем ниже MSE, тем лучше. Очевидно, что наши ярлыки лучше.")

Влияние "глубины" модели. Мы показываем влияние глубины модели DANET на набор данных о типе «лесного покрова» на рис. 4, мы также рассмотрели аналогичные явления в других наборах данных. Из рис. 4 видно, что модели DANET дают лучшие характеристики с увеличением глубины модели. Однако, когда DANET становятся очень глубокими (например, глубже, чем DANET-32), прирост производительности становится незначительным. Мы думаем, что это связано с тем, что табличные данные обычно имеют гораздо меньше возможностей, чем данные изображения/текста, для использования в очень глубоких сетях. Мы наблюдаем, что для DANET глубины 20-32 являются многообещающим выбором.
Влияние "ширины" модели. Количество групп объектов K, в ABSTLAY действует как ширина модели для наборов данных. Чтобы оценить влияние ширины K, мы показываем характеристики DANET-20 с различной шириной по типам: «Клик (Click)» (11 объектов), «лесной покров (Forest Cover Type)» (54 объекта) и «Эпсилон (Epsilon)» (2 тыс. объектов) в таблице 4. DANET-20 обеспечивает значительную производительность при ширине K = 5. Для наборов данных с меньшим количеством функций (например, «Клик» и «Лесной покров») мы видим лишь незначительный прирост при ширине K > 5. Для набора данных с большим количеством функций («Эпсилон») K = 8 кажется разумным выбором, который превосходит K = 5 на 0.13%. Это может быть связано с тем, что набор данных с большим количеством объектов, как правило, имеет больше групп объектов, и, следовательно, большая ширина модели может помочь в таких сценариях.
Эффекты разреженных масок. Мы проверяем влияние масок на три синтезированных набора данных с тремя различными настройками набора данных. Каждый набор данных содержит 7 тыс. входных элементов с 11 скалярными объектами (x={ vi | i =0,...,10}), сгенерированными на основе 11-мерного гауссова распределения без корреляции объектов. Для вычисления целевого значения y в первом столбце таблицы 3 используются четыре формулы. Что касается задач обучения ранжированию, y используется в качестве цели прогнозирования; что касается задач классификации, y дополнительно преобразуется в «0» или «1», используя медиану y в качестве порогового значения. Мы создаем DANET-2 с K = 1 и обучаем его с помощью синтезированных наборов данных. Эта модель имеет только один базовый блок, и есть две маски, входными данными которых являются необработанные объекты (т.е. маска первого ABSTLAY в основном пути модели и маска ABSTLAY в соответствующем ярлыке). В данном исследовании мы проверяем эти две маски только после обучения конвергенции и проверяем, соответствует ли активация маски формулам. Активация маски визуализирована в таблице 3.

Взяв в качестве примера задачи обучения ранжированию, находим ответ на наш первый вопрос: могут ли наши маски различать функции, относящиеся к цели и функции, не относящиеся к ней? Для формулы 1 можно видеть, что только функции v2, v3, v4 и v5 имеют отношение к цели, и соответствующие значения в масках хорошо реагируют на них. Аналогичные результаты можно наблюдать и в других случаях. В частности, мы вводим термин в отношении v10, стремящегося к нулю (Формула 2), можно видеть, что маски на него не реагируют, что показывает, что наша предлагаемая маска основана на данных и надежна. Наш второй вопрос таков: могут ли наши маски группировать коррелятивные признаки? В Формуле 2 мы можем рассматривать v0 и v2 как входящие в одну группу, а v5 и v6 - как входящие в другую группу. Мы можем видеть, что в масках значения, представляющие v0 и v2, имеют близкие значения, как и v5 и v6. В Формуле 3 есть две группы функций: (v6,v7) и (v5,v8). Соответственно, маска «выбирает» v6 и v7, а другая «выбирает» v5 и v8. Что касается кусочно-заданной функции в формуле 4, то v1 (как условие) и все функции, используемые в формулах 1 , 2, рассматриваются масками. Подводя итог, можно видеть, что предлагаемые нами маски не только могут находить объекты, соответствующие цели, но и обладают способностью выявлять взаимосвязи объектов. Аналогичный вывод можно сделать и для задач классификации.


Сравнение вычислительной сложности. Мы сравниваем вычислительные сложности на этапах вывода DANET с нейронными сетями, конкурентоспособными по производительности, TabNet, NODE (Попов и др. 2019) и Net-DNF (Абутбул и др.2021) (см. рис.5). Провалы методов, основанных на ансамблевом обучении (т.е. NODE и Net-DNF), как правило, в несколько раз больше, чем у DANET и TabNet. Кроме того, очевидно, что при некоторых идентичных сложностях наши модели часто являются наиболее эффективными. Видя серую кривую на рис.5, TabNet не может получить прирост производительности при постоянном увеличении размера модели, которая не очень расширяема по сравнению с нашей. После сжатия модели с помощью структурной параметризации, выполненной на ABSTLAY, FLOPS наших наборов данных уменьшаются на 14,8% – 23,0% (по сравнению с красной и зеленой кривыми). Что касается одного отдельного ABSTLAY, то провалы уменьшаются на 49,02% при размерах входных и выходных объектов 32.
Заключения
В этой статье мы предложили семейство новых глубоких нейронных сетей, DANET, для обработки табличных данных. Мы разработали новый нейронный компонент, ABSTLAY, для табличных данных, которые автоматически выбирает корреляционные элементы и рефераты высокого уровня элементы из сгруппированных элементов. Мы также предоставили метод повторной параметризации структуры, который может в значительной степени уменьшить вычислительную сложность ABSTLAY. Мы разработали базовый блок на основе ABSTLAYs и DANET в различные глубины строились путём укладки таких блоков. Специальное предложение был введен ярлык в базовом блоке, увеличив разнообразие групп признаков. Эксперименты над несколькими общественными наборы данных подтвердили, что наши DANET эффективны и действенны при обработке табличных данных, как для классификации, так и для обучения - ранговые задания. Кроме того, используя синтезированные наборы данных, мы показываем, что предлагаемые маски могут находить корреляции признаков.
Ссылки
· Abutbul, A.; et al. 2021. DNF-Net: A neural architecture for tabular data. In ICLR.
· Addo, P. M.; et al. 2018. Credit risk analysis using machine and deep learning models. Risks.
· Anghel, A.; et al. 2018. Benchmarking and optimization of gradient boosting decision tree algorithms. In NeurIPS.
· Arik, S. O.; and Pfister, T. 2020. TabNet: Attentive interpretable tabular learning. In AAAI.
· Babaev, D.; et al. 2019. E.T.-RNN: Applying deep learning to credit loan applications. In KDD.
· Bengio, Y.; et al. 2013. Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432.
· Bertin-Mahieux, T.; et al. 2011. The million song dataset. In ISMIR.
· Breiman, L.; et al. 1984. Classification and Regression Trees. CRC press.
· Chen, T.; and Guestrin, C. 2016. XGBoost: A scalable tree boosting system. In KDD.
· Dauphin, Y. N.; et al. 2017. Language modeling with gated convolutional networks. In ICML.
· Ding, X.; et al. 2021. RepVGG: Making VGG-style ConvNets great again. In CVPR.
· Feng, J.; et al. 2018. Multi-layered gradient boosting decision trees. In NeurIPS.
· Friedman, J. H. 2001. Greedy function approximation: A gradient boosting machine. Annals of Statistics.
· Guo, H.; Tang, R.; et al. 2017. DeepFM: A factorizationmachine based neural network for CTR prediction. In IJCAI.
· Hassan, M. R.; et al. 2020. A machine learning approach for prediction of pregnancy outcome following IVF treatment. Neural Computing and Applications.
· He, K.; et al. 2016. Deep residual learning for image recognition. In CVPR.
· He, X.; et al. 2014. Practical lessons from predicting clicks on Ads at Fackbook. In DMOA Workshop.
· Ho, T. K. 1995. Random decision forests. In ICDAR.
· Hoffer, E.; et al. 2017. Train longer, generalize better: Closing the generalization gap in large batch training of neural networks. In NeurIPS.
· Huang, G.; et al. 2017. Densely connected convolutional networks. In CVPR.
· James, G.; et al. 2013. An Introduction to Statistical Learning. Springer.
· Ke, G.; et al. 2017. LightGBM: A highly efficient gradient boosting decision tree. In NeurIPS.
· Ke, G.; et al. 2018. TabNN: A universal neural network solution for tabular data. In ICLR OpenReview.
· Ke, G.; et al. 2019. DeepGBM: A deep learning framework distilled by GBDT for online prediction tasks. In KDD.
· Lay, N.; et al. 2018. Random hinge forest for differentiable learning. In ICML.
· Ma, J.; and Yarats, D. 2019. Quasi-hyperbolic momentum and Adam for deep learning. In ICLR.
· Mirroshandel, S. A.; et al. 2016. Applying data mining techniques for increasing implantation rate by selecting best sperms for intra-cytoplasmic sperm injection treatment. Computer Methods and Programs in Biomedicine.
· Mohan, A.; et al. 2011. Web-search ranking with initialized gradient boosted regression trees. In Proceedings of the Learning to Rank Challenge.
· Nair, V.; and Hinton, G. E. 2010. Rectified linear units improve restricted Boltzmann machines. In ICML.
· Peters, B.; et al. 2019. Sparse sequence-to-sequence models. In ACL.
· Popov, S.; et al. 2019. Neural oblivious decision ensembles for deep learning on tabular data. In ICLR.
· Prokhorenkova, L.; et al. 2018. CatBoost: Unbiased boosting with categorical features. In NeurIPS.
· Qi, C. R.; et al. 2017. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In NeurIPS.
· Qin, T.; and Liu, T. 2013. Introducing LETOR 4.0 Datasets. CoRR.
· Quinlan, J. R. 1979. Discovering rules by induction from large collections of examples. Expert Systems in the Micro Electronics Age.
· Quinlan, J. R. 2014. C4.5: Programs for Machine Learning. Elsevier.
· Roy, A.; et al. 2018. Deep learning detecting fraud in credit card transactions. In Systems and Information Engineering Design Symposium.
· Srivastava, N.; et al. 2014. Dropout: A simple way to prevent neural networks from overfitting. JMLR.
· Wainwright, M. J.; and Jordan, M. I. 2008. Graphical Models, Exponential Families, and Variational Inference. Now Publishers Inc.
· Yang, Y.; et al. 2018. Deep neural decision trees. In ICML Workshop.
· Zhang, J.; and Honavar, V. 2003. Learning from attribute value taxonomies and partially specified instances. In ICML.
· Zhang, J.; Kang, D.-K.; et al. 2006. Learning accurate and concise na¨ıve Bayes classifiers from attribute value taxonomies and data. Knowledge and Information Systems.
· Zhou, Z.-H.; and Feng, J. 2017. Deep Forest: Towards an alternative to deep neural networks. In IJCAI




