
Всем привет! Меня зовут Андрей, я DevOps инженер.
Когда я начинал изучать Kubernetes (K8s), я перечитал много статей, и, что в статьях, что в документации, информация была сильно разрознена, обрывочна. Сложно было скомпоновать информацию в единое целое.
На тот момент, мне бы хотелось найти одну большую статью, пусть и не полностью, но достаточно подробно описывающую процессы управления кластером K8s, деплоя и обслуживания приложений в нём.
Примерно такую статью я постарался написать.
В этой статье не будет:
инструкций по запуску кластера. Эти операции в подробностях описаны во множестве статей по Kubernetes.
базовых инструкций по работе с kubectl, командной строкой и т.д.
В этой статье будет:
обобщение, систематизация знаний о том, как работает Kubernetes.
достаточно подробный разбор конфигураций, необходимых для запуска и управления приложений, запускаемых в K8s.
Итак, приступим. Kubernetes это сложно.
Обычно, в статьях по Kubernetes, предлагают начать знакомство с запуска Minkube или, например, изучить документацию, познакомиться с K8s на https://labs.play-with-k8s.com/, пройти там лабораторные работы.
Это конечно хорошо, но далеко от реальности. На практике всё несколько сложнее.
Повторюсь, описывать процесс запуска кластера здесь не буду, но поговорить о нём, об архитектуре K8s, для понимания принципов его работы, придётся.
Существует масса вариантов запуска кластера, в зависимости от инфраструктуры, в которой он предполагается, потребностей, вызвавших такую необходимость.
Например, ряд облачных провайдеров предлагают managed Kubernetes
Здесь, за определённую плату, как говорят нам провайдеры, “в пару кликов” поднимается кластер, готовый к деплою приложений, но, как правило, это достаточно дорогое удовольствие.
В компаниях, занимающихся разработкой ПО, как правило, существует своя серверная инфраструктура. Это значит, что для целей разработки приложений, можно поднять локальный кластер Kubernetes в ней.
Такой вариант называется Self - Hosted, и тут существует масса решений и инструментов для разворота.
Например kubeadm или kubespray
Наверное, самым популярным инструментом/путём разворота Self - Hosted K8s является kubespray
Но и тут есть масса вариантов. Например, Ingress может работать на базе Nginx или HAProxy, можно регулировать количество master или worker нод, и т.д. и т.п. В общем, все случаи нужно рассматривать в зависимости от потребностей.
Как вы поняли, решений по запуску кластера Kubernetes может быть масса, но архитектура самого кластера, принципы управления, организации доступа, запуска в нём приложений у всех примерно одинаковые.
Сейчас же рассмотрим следующую конфигурацию.
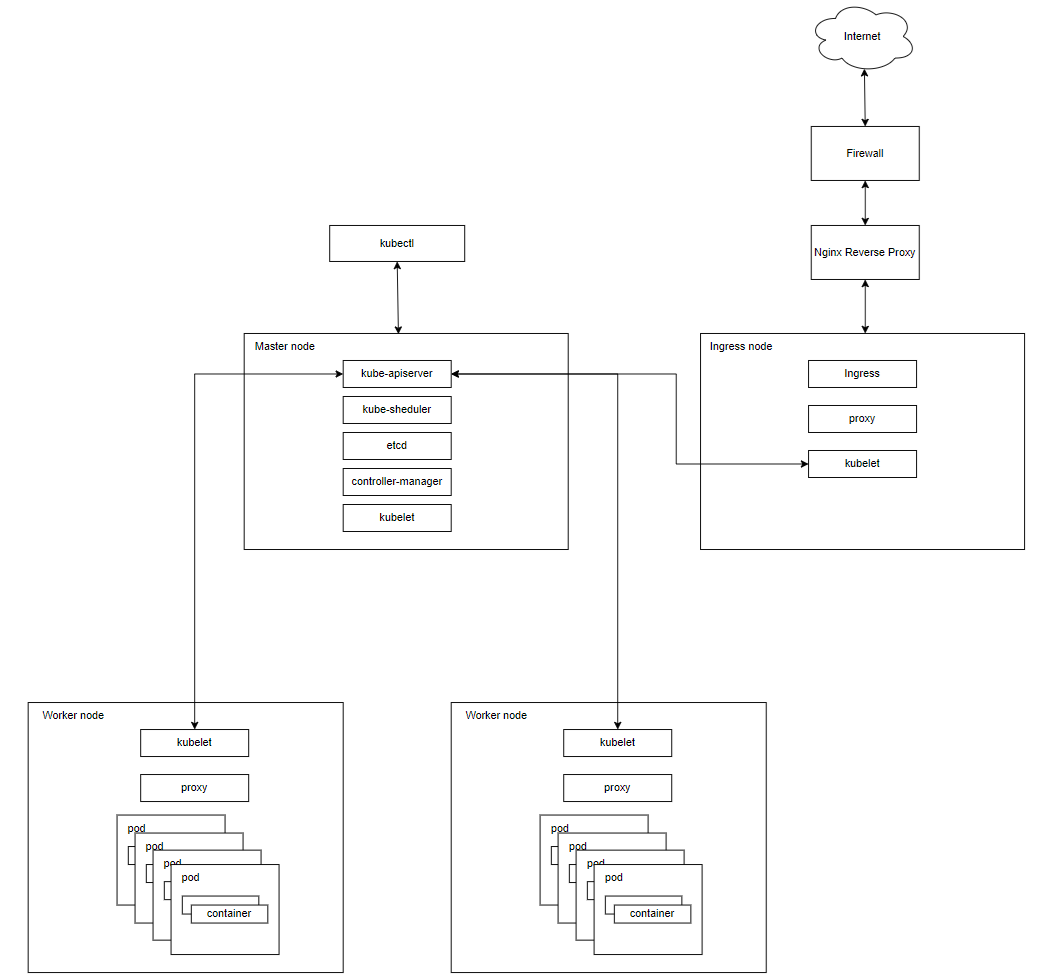
Компоненты и архитектура
Давайте поверхностно коснёмся архитектуры самого Kubernetes и его важных компонентов.
Кластер Kubernetes состоит из рабочих узлов (Node).
Приведённый в примере кластер состоит из ноды с ролью Ingress, master ноды и двух воркер нод. Вне кластера существует ещё сервер Nginx Reverse Proxy. Он необходим для удобства управления доступом, логирования, в целях безопасности, выступает как единая точка входа для клиентов.
Здесь хочется уточнить, что в одном кластере может быть запущено много продуктов, систем, отделённых друг от друга. Доступ к ним организуется через Ingress, по хэдеру “host”, описанном в нём. Но об этом позже.
При взгляде на архитектуру системы, мы можем разбить его на сервисы, которые работают на каждой ноде и сервисы уровня управления кластера. На каждой ноде Kubernetes запускаются сервисы, необходимые для управления нодами мастер нодой и для запуска приложений. Конечно, на каждой ноде запускается Docker. Он обеспечивает загрузку образов и запуск контейнеров.
Рассмотрим из чего состоят ноды в кластере.
Master node (Control plane) управляет рабочими узлами и подами в кластере. Cостоит из:
kube-apiserver - это компонент Kubernetes, который представляет собой API-сервер, обеспечивающий взаимодействие с кластером Kubernetes.
kube-scheduler - планирует размещение подов на узлах кластера. Привязывает незапущенные поды к нодам через вызов /binding API.
etcd - распределенное key-value хранилище для всех данных кластера. Необязательно располагается внутри мастера, может стоять как отдельный кластер. Состояние мастера хранится в экземпляре etcd. Это обеспечивает надёжное хранение конфигурационных данных и своевременное оповещение прочих компонентов об изменении состояния.
controller-manager - запускает контроллеры, состоит из:
Node controller: отвечает за обнаружение и реагирование при выходе узлов из строя.
Job controller: отслеживает объекты заданий, которые представляют собой одноразовые задачи, а затем создает модули для их выполнения.
EndpointSlice controller: отвечает за управление объектами EndpointSlice. Обеспечивает связь между службами и модулями.
ServiceAccount controller: отвечает за управление объектами ServiceAccount. ServiceAccount - это ресурс в Kubernetes, который используется для аутентификации и авторизации приложений и сервисов в кластере.
kubelet - это компонент Kubernetes, который работает на каждом узле в кластере и отвечает за управление жизненным циклом подов.
Worker nodes состоят из компонентов:
kubelet
kube-proxy - на каждой ноде запускается простой proxy-балансировщик. Занимается реализацией виртуальных IP, установкой правил проксирования и фильтрацией трафика.
Pod - это контейнер, либо группа контейнеров с общими разделами, запускаемых как единое целое (общий IP).
Ingress node отличается от worker node тем, что на ней запрещён запуск подов приложений, и на ней запущен Ingress controller, в нашем случае, на Nginx.
Kubectl (Command Line Interface) - это утилита командной строки, которая используется для взаимодействия с кластером Kubernetes. С помощью kubectl можно управлять ресурсами кластера, такими как поды, сервисы, репликации, секреты и многое другое. Команды kubectl позволяют создавать, обновлять, удалять ресурсы Kubernetes, получать информацию о состоянии кластера.
Итак, мы базово обсудили архитектуру Kubernetes, принципы его работы. Далее предлагаю поговорить об объектах Kubernetes, конфигурирование которых позволяет размещать приложения и управлять ими в кластере.
Namespace (пространства имён) - это возможность разделить физический кластер Kubernetes на виртуальные, каждый из которых изолирован от других. Абстрактный объект, который логически разграничивает и изолирует ресурсы между подами. Можно рассматривать как внутренний виртуальный кластер, изолирующий проекты или пользователей между собой. Может применить разные политики квот на свои проекты или выдать права доступа только на определенную область.
Рассмотрим конфигурацию:
apiVersion: v1
kind: Namespace
metadata:
name: test
labels:
name: testkind: NamespaceЗдесь задаётся тип описываемого объекта.
metadata:
name: testЗдесь объекту присваивается имя.
labels:
name: testLabels - это пары ключ/значение которые прикрепляются к объектам, таким как поды, сервисы, репликации и другие ресурсы в кластере. Используются для организации и идентификации ресурсов.
Каждый объект, о котором мы будем говорить далее, можно описать в файле в формате .yaml и отдать утилите kubectl. Например, для Namespace, приведённого выше, это будет выглядеть так:
kubectl apply –f test_namespace.yaml
Выполнение этой команды создаст новый Namespace, в случае его отсутствия. Когда мы конфигурируем любой такой объект, мы говорим кластеру о том, что мы хотим видеть его в определённом состоянии. Kubernetes сверят текущее состояние с желаемым, и, если текущее состояние отличается от желаемого, приводит его к желаемому.
Приведу ещё пример. Допустим у нас есть запущенный под с контейнером, созданным из докер имейджа 1. Нам нужно сделать так, чтобы это контейнер запускался из имейджа 2.
Имейдж для данного контейнера описывается в объекте Deployment. О нём мы поговорим подробнее чуть ниже. Для того, чтобы запустить контейнер из-под нужного имейджа, нужно изменить текущий Deployment, прописать в него новый имейдж и применить изменения, через kubectl. Тогда кластер увидит, что запущенный контейнер не соответствует требуемому состоянию, и приведёт его к желаемому.
Deployment - контроллер, который управляет состоянием развертывания подов, которое описывается в манифесте, следит за удалением и созданием экземпляров подов. Управляет контроллерами ReplicaSet.
С помощью Deployment можно определить желаемое количество реплик пода, образ контейнера, параметры запуска и другие параметры.
Рассмотрим пример:
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-deployment
namespace: test
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
imagePullPolicy: Always
ports:
- containerPort: 80
env:
- name: ENV1
value: "value1"
- name: ENV2
value: "value2"
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
volumeMounts:
- name: frontend
mountPath: /etc/nginx/conf.d/test.conf
subPath: test.conf
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Sample
initialDelaySeconds: 3
failureThreshold: 30
periodSeconds: 3
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
volumes:
- name: frontend
configMap:
name: frontend
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1metadata:
name: test-deployment
namespace: testЗдесь мы привязываем под с контейнером, описываемым ниже, к неймспейсу созданному ранее.
labels:
app: nginxПрисваиваем лейбл описываемому приложению, для возможности ссылаться на него другим сущностям.
spec:
replicas: 1Задаём количество подов, с запущенным контейнером (горизонтальное масштабирование). Это можно сделать при помощи ReplicaSet, но deployments даёт больше возможностей.
spec:
containers:
- name: nginx
image: nginx:1.14.2
imagePullPolicy: Always
ports:
- containerPort: 80Здесь описаны спецификации контейнера, запускаемого в поде.
env:
- name: ENV1
value: "value1"
- name: ENV2
value: "value2"Здесь контейнеру передаются переменные окружения. В данном случае, приведены для примера.
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"Здесь описываются ограничения на использование ресурсов кластера. Это даёт предсказуемость поведения, в разрезе использования ресурсов, в момент больших нагрузок.
volumeMounts:
- name: frontend
mountPath: /etc/nginx/conf.d/test.conf
subPath: test.confК контейнеру можно монтировать volumes разных типов.
livenessProbe:
httpGet:
path: /healthz
port: 80
httpHeaders:
- name: Custom-Header
value: Sample
initialDelaySeconds: 3
failureThreshold: 30
periodSeconds: 3
readinessProbe:
httpGet:
path: /ready
port: 80
initialDelaySeconds: 5
periodSeconds: 5Liveness и Readiness пробы нужны для мониторинга состояния контейнера, его перезапуска в случае неуспешного прохождения проб. Здесь приведены для примера.
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1Описывает стратегию запуска новый подов, при обновлении деплоймента.
Разберём подробнее некоторые параметры:
requests, limits (Запросы и лимиты ресурсов).
Зачем нужно: увеличение стабильности и производительности как отдельных приложений, так и кластера в целом. Предотвращение конкуренции за ресурсы и гарантия того, что приложения не будут неожиданно завершены (terminated) из-за нехватки ресурсов.
Если узел, на котором работает под, имеет достаточно доступных ресурсов, контейнер может (и ему разрешено) использовать больше ресурсов, чем указано в его запросе (requests) на этот ресурс. Однако контейнеру не разрешается использовать больше, чем его лимит ресурсов (limits).
Request бронирует количество ресурсов под контейнер, limits ограничивает использование. memory задаётся в байтах (Gi, Mi, Ki), cpu в единицах цп (1 ядро, 1m).
Volumes. К запущенным в подах контейнерам можно примонтировать volume. Их существует множество видов, они достаточно хорошо описаны в документации.
В моём примере я опишу configMap.
На примере Nginx удобно показать и использовать на практике монтирование файла конфигурации Nginx в контейнер, в директорию /etc/nginx/conf.d.
Для этого нужно сначала описать отдельный объект configMap, затем описать его монтирование в Deployment, как в примере выше.
Пример ConfigMap:
apiVersion: v1
kind: ConfigMap
metadata:
namespace: test
name: frontend
data:
test.conf: |
server {
listen 80;
server_name frontend.sample.ru;
proxy_connect_timeout 300;
proxy_send_timeout 300;
proxy_read_timeout 300;
send_timeout 300;
access_log /var/log/nginx/err.log;
error_log /var/log/nginx/err.log;
client_max_body_size 100m;
location / {
root /opt/app;
index index.html;
try_files $uri $uri/ /index.html;
}
}Kubernetes probes - это проверки, которые осуществляются в течение жизненного цикла пода. Они описываются для каждого контейнера пода. Существуют три вида проверок.
Startup probe - запускается сразу после старта пода и применяется для приложений, которые имеют длительную процедуру инициализации. Пока она не завершена, другие пробы не запускаются.
Readiness probe - проверка готовности пода обрабатывать трафик (под не добавляется в маршрутизацию трафика в service (об этом чуть ниже), если эта проверка не пройдена).
Liveness probe - проверяет, функционирует ли приложение (в случае, если проверка не завершилась успехом, процесс в контейнере пода перезапускается).
Strategy - определяет стратегию замены старых подов новыми.
В Kubernetes, по умолчанию, существует две стратегии: Recreate и RollingUpdate. Если стратегия явным образом не описана в Deployment, будет применяться RollingUpdate.
RollingUpdate заключается в том, что перед удалением старых подов, запускаются новые. Старые поды будут удалены только после успешного запуска новых. В сочетании с применением проб, достигается нулевое время простоя приложений.
При применении стратегии Recreate, сначала завершают работу старые поды, и только после этого запускаются новые.
Итак, на примерах, приведённых выше, можно понять, как оперировать нэймспейсами, запускать приложения в кластере. Далее разберём что нам понадобиться чтобы получить доступ к приложениям вне кластера.
Services - это объект, предназначенный для предоставления доступа к приложению, запущенному в виде пода или набора подов в кластере Kubernetes.
Service выполняет несколько важных функций:
Разрешение DNS имён: сервис предоставляет символьное DNS имя, формирующееся на основе имени сервиса, неймспейса приложения и DNS суффикса кластера для единообразного доступа к приложениям. Плюс сервисы с типом externalName могут описывать произвольные A-записи во внутреннем DNS кластера.
Маршрутизация и балансировка трафика: сервис может предоставлять IP адрес, при обращении к которому, при помощи алгоритма round robin, балансирует трафик на поды приложения, либо выдавать IP адреса подов приложения на запрос к своему DNS имени, для организации балансировки на уровне приложения (режим headless с настройкой clusterIp: no).
Service discovery: на основании описанных в нём меток service ищет поды, которые соответствуют этим меткам, прошли readiness пробу и добавляет их в маршрутизацию трафика.
Публикация приложений: мы можем использовать сервисы для того, чтобы предоставлять внешним пользователям доступ к приложениям в кластере.
Типы сервисов:
Для того чтобы указать, где будет размещен наш сервис, будет ли он доступен снаружи или только внутри кластера, используются разные типы сервисов.
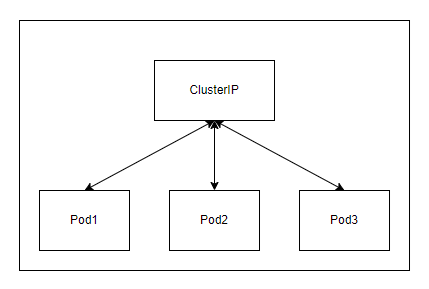
ClusterIP - присваивает IP в сервисной сети, который доступен только внутри кластера. Это значение по умолчанию, которое используется, если вы явно не указываете тип службы. Вы можете предоставить доступ к сервису вне кластера, используя Ingress. Об этом ниже.
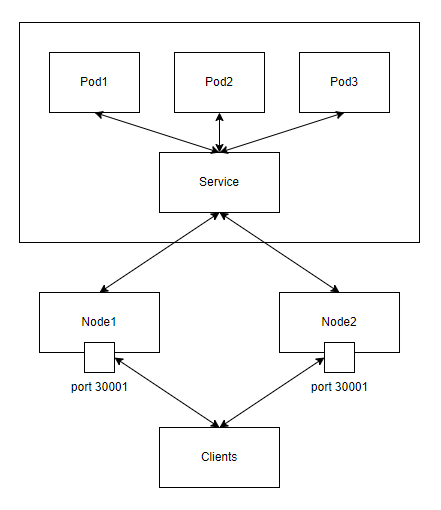
NodePort – предоставляет доступ к приложению по порту/портам на IP адресе каждого узла (ноды). Позволяет использовать свои решения внешней балансировки. При этом, автоматически создается и внутренний сервис ClusterIP.
LoadBalancer - используется у облачных провайдеров, таких как Google Cloud. Сервис будет доступен через внешний балансировщик вашего провайдера, при этом создаются NodePort с портами, куда будет приходить трафик от провайдера и ClusterIP.
ClusterIP
NodePort
Load Ballancer

Пример описания сервиса:
apiVersion: v1
kind: Service
metadata:
namespace: test
name: frontend
spec:
ports:
- protocol: TCP
port: 80
targetPort: 80
selector:
app: nginx
Так как тип сервиса не указан, будет запущен сервис c типом ClusterIP. Для предоставления доступа к приложению вне кластера, нужен Ingress.
В случае запуска сервиса с типом NodePort, можно указать конкретный порт, по которому будет доступно приложение в сервисе. Если порт не будет указан, он будет выбран случайным образом, из диапазона портов от 30000 до 32767.
selector:
app: nginx
Здесь мы указываем какое приложение отдавать сервису.
Ingress служит для организации доступа к приложению вне кластера. Действует как «интеллектуальный маршрутизатор» или точка входа в кластер. Опубликовав его, мы получим возможность доставлять через него трафик приложению внутри кластера, на основе маршрутизации по доменным именам, URL/locations, headers и cookies.
Ingress Controller - обрабатывает трафик. Его конфигурация формируется из всех Ingress внутри одного кластера.

Рассмотрим пример Ingress:
kind: Ingress
metadata:
name: frontend
namespace: test
annotations:
nginx.ingress.kubernetes.io/client-max-body-size: "100m"
nginx.ingress.kubernetes.io/client-body-buffer-size: "100m"
nginx.ingress.kubernetes.io/proxy-body-size: "100m"
nginx.ingress.kubernetes.io/proxy-buffer-size: "100m"
nginx.ingress.kubernetes.io/configuration-snippet: |
proxy_set_header custom-header "my_custom_header";
spec:
ingressClassName: nginx
rules:
- host: product.sample.ru
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: frontend
port:
number: 80
Разберём конфигурацию:
annotations:
nginx.ingress.kubernetes.io/client-max-body-size: "100m"
nginx.ingress.kubernetes.io/client-body-buffer-size: "100m"
nginx.ingress.kubernetes.io/proxy-body-size: "100m"
nginx.ingress.kubernetes.io/proxy-buffer-size: "100m"
nginx.ingress.kubernetes.io/configuration-snippet: |
proxy_set_header custom-header "my_custom_header";
Nginx в Ingress можно достаточно гибко конфигурировать, но это уже предмет отдельной статьи. Здесь описано несколько примеров.
rules:
- host: product.sample.ru
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: frontend
port:
number: 80
Здесь описываются правила обработки траффика. В первую очередь это хэдер "host", location запроса (path) и имя сервиса, куда будет перенаправлен запрос.
Выше я упоминал, что в моей конфигурации кластера, присутствует внешний Nginx Reverse Proxy. Пример простой конфигурации для организации доступа к приложению в кластере:
server {
listen 80;
server_name product.sample.ru;
location / {
client_max_body_size 200M;
proxy_pass http://<ip ingress ноды>:<порт, на котором запущен Ingress> ;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Real-IP $remote_addr;
proxy_pass_request_headers on;
proxy_set_header host $host;
}
}
Как итог
В этой статье я разобрал базовые понятия, которые необходимы для понимания того, как работает Kubernetes, как запускаются в нём приложения и какие сущности для этого необходимы.
Существует огромное количество вариантов конфигураций кластеров, подходов к управлению и размещению приложений в них. Я описал только один из множества вариантов, но базовые принципы работы и управления остаются одинаковыми. Если копать глубже - получится уже не статья, а полноценная книга. Они есть в достаточном количестве.
Надеюсь, моя статья будет вам полезна. Удачи в освоении Kubernetes.




