
В заключительной статье о DBT хочу поделиться переводом кейса Стефано Солимито, в котором он рассказал о своем опыте использования этого инструмента в компании The Telegraph.
Предыдущие мои статьи на тему DBT:
Моделирование данных: обзор
Моделирование данных: зачем нужно и как реализовать
Что такое dbt и зачем он нужен маркетинг-аналитику
The Telegraph — это компания с 164-летней историей, в которой данные всегда играли центральную роль. С появлением облака и необходимостью обрабатывать огромное количество данных в 2015 году мы начали создавать нашу платформу на основе Google Cloud и на протяжении многих лет продолжаем ее улучшать.
Задача
В течение последних 4 лет у меня было несколько дискуссий о том, как организовать трансформирмацию данных или, в более широком смысле, процессы извлечения, преобразования и загрузки (ETL). Количество инструментов на рынке огромно, и выбор неправильной технологии может негативно повлиять на качество данных и решений, принимаемых на их основе.
В The Telegraph озеро данных создано на основе Cloud Storage и BigQuery. По мнению Google, естественным выбором для выполнения ETL в таком случае должен быть Dataflow (Apache Beam). Это может быть правдой для большинства компаний. Но если вы выйдете за пределы общих вариантов использования, представленных в справке, и столкнетесь с проблемами реального мира, то выбор может оказаться не таким уж и простым.
В нашем случае внедрение Apache Beam оказалось не самым простым решением по следующим причинам:
Java SDK пользуется гораздо большей поддержкой, чем Python SDK. Большая часть нашей команды имеет опыт работы с Python, а с Java — нет. Кроме того, наши data scientists работают только на Python, а это означает наличие кодовых баз на нескольких языках, что затруднит ротацию инженеров в разных проектах.
Большинство наших потоков данных структурированы так, чтобы быть просто серией запросов, запускаемых в BigQuery. Учитывая это, Apache Beam не добавляет большой ценности процессу ETL.
Dataflow действительно хорошо взаимодействует с продуктами Google, но в 2015 году количество коннекторов было ограничено, и нам нужно было взаимодействовать с AWS, локальными серверами и т.д.
Наши аналитики и специалисты по обработке данных, как правило, говорят на языке SQL, и с ними намного проще сотрудничать, если в инженерии нам не нужно переводить создаваемую ими логику SQL на Java или Python.
Примечание: мы все-таки используем Apache Beam, но только для потоков данных в реальном времени.
Если вы используете Google Cloud Platform (GCP), вторым продуктом, который стоит рассмотреть, может быть Dataproc. Если у вас уже есть кластер Spark или Hadoop и вы хотите перейти на GCP, было бы разумно выбрать этот вариант. Но у нас был только небольшой кластер Hadoop, и переписать логику работающих там потоков данных не составило труда.
Третий продукт, который мы рассматривали и даже какое-то время использовали — это Talend (бесплатная версия). Если ваша компания готова купить его корпоративную версию, это отличный выбор, но если вы решите перейти на бесплатную версию, то можете столкнуться с некоторыми проблемами:
Трудно применить контроль версий к вашим потокам данных.
Вы должны придумать свой собственный CI/CD, а тестируемость ваших артефактов ограничена.
Вы должны полагаться на компоненты, предоставляемые сообществом, которые могут устареть и перестать поддерживаться. Или вы можете разработать свои собственные компоненты, выделив ресурсы на их создание и поддержку в актуальном состоянии.
Вам нужно найти экспертов по Talend, которые смогут управлять разработкой.
Если решение о внедрении инструмента для выполнения ETL не будет доведено до сведения всей компании, вы можете получить разрозненный набор технологий, которые придется поддерживать в течение нескольких лет.
Поэтому мы решили создать собственную Python ETL библиотеку в качестве оболочки для функций, предоставляемых Google и AWS, чтобы облегчить взаимодействие с основными сервисами обоих облаков. Даже этот подход оказался далек от совершенства. Проектирование и разработка собственной библиотеки, техническое обслуживание, необходимое для ее обновления и добавления новых функций, требуют немалых усилий. Мы начали искать что-то, что могло бы хорошо интегрироваться с этим подходом и уменьшить объем библиотеки.
В 2019 году мы начали тестировать DBT для трансформации данных с идеей продолжать выполнять извлечение и загрузку с помощью библиотеки Python и полагаться на Apache Beam для обработки данных в реальном времени.
Что такое DBT
DBT (Data Building Tool) — это инструмент командной строки, который позволяет аналитикам и инженерам данных преобразовывать данные в своих хранилищах, используя операторы выбора.
DBT отвечает за T (трансформацию) в ETL-процессе, но не выполняет операции извлечения (E) и загрузки (L). Он позволяет компаниям трансформировать данные с помощью запросов и более эффективно их организовывать. В настоящее время с DBT работают более 280 компаний, и The Telegraph входит в их число.

Единственная функция DBT — взять код, скомпилировать его в SQL-запрос, а затем выполнить его к вашей базе данных.
Инструмент поддерживает несколько баз данных, в том числе:
Postgres
Redshift
BigQuery
Snowflake
Presto
DBT можно легко установить с помощью pip (установщики пакетов Python). Он доступен в двух версиях: консоль (CLI) и пользовательский интерфейс (UI). Приложение DBT написано на Python и имеет открытый исходный код, что предполагает гибкую настройку под ваш проект.
CLI версия предлагает набор функций для преобразования данных: запуск тестов, компиляция, создание документации и т.д.
UI версия не дает возможности изменить ваши потоки данных и используется в основном для документирования.

На рисунке ниже показано, как в пользовательском интерфейсе DBT проиллюстрировано формирование таблиц. Это помогает быстро понять, какие источники данных участвуют в определенной трансформации. Такая визуализация может облегчить общение с коллегами, которые технически менее подкованы, но хотят получить общее представление.
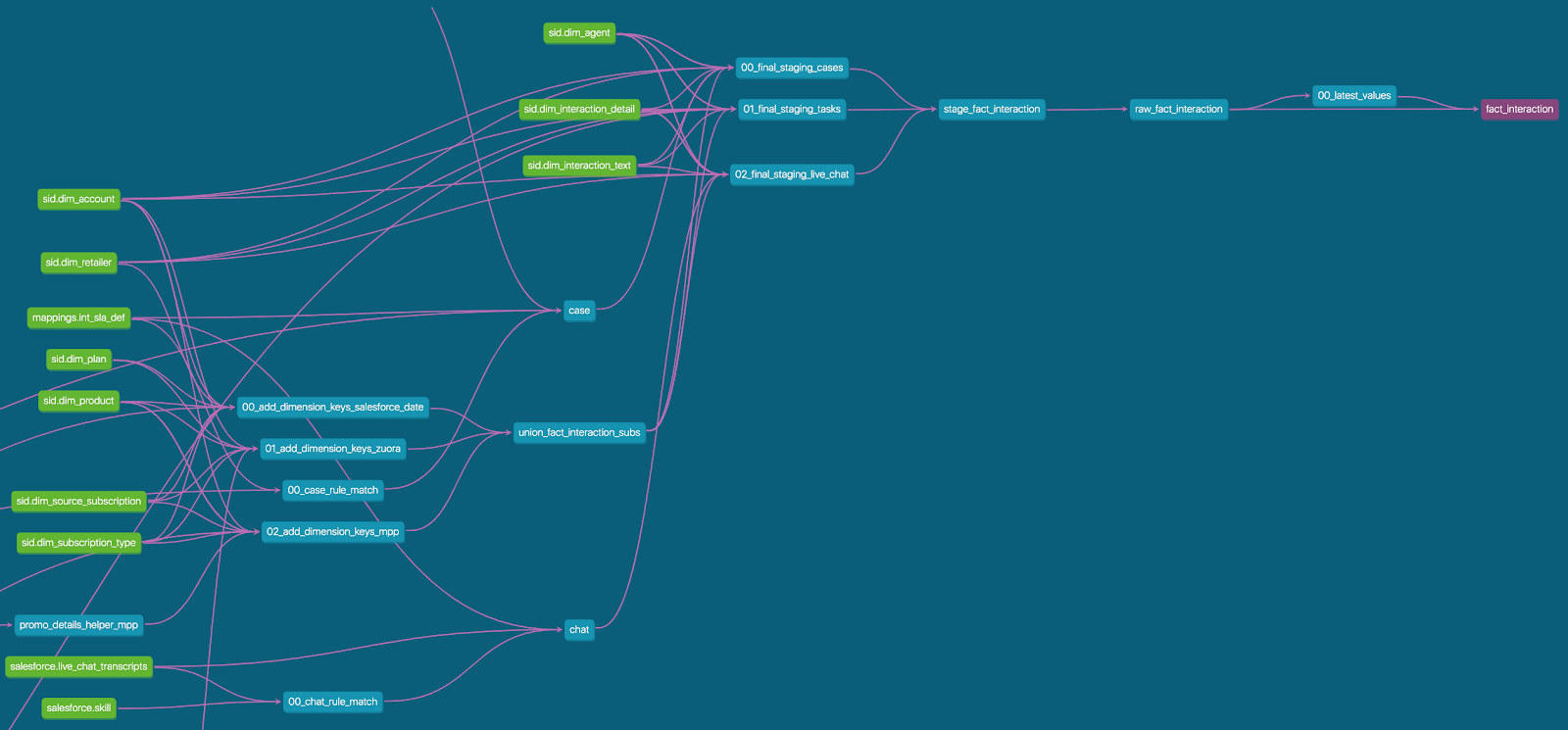
Запустить проект в DBT очень просто: запуск «dbt init» в командной строке автоматически создает для вас структуру проекта. Это гарантирует, что все data-инженеры будут работать с одним и тем же шаблоном.
DBT также предлагает максимальную гибкость. Если созданная структура проекта не соответствует вашим потребностям, можно отредактировать файл конфигурации проекта (dbt_project.yml), чтобы изменить порядок папок по своему усмотрению.
Одним из важных понятий в DBT является модель. Каждая модель — это оператор выбора, который должен быть согласован с другими моделями, чтобы преобразовать данные желаемым образом. Каждая модель написана с помощью языка запросов вашего хранилища данных (DW). Его можно расширить с помощью Jinja2, что позволит вам:
Писать более аккуратные параметризованные запросы.
Прописать повторяющиеся фрагменты SQL в макросах, которые можно использовать в качестве функций в ваших запросах.
Скрыть сложность трансформации, чтобы читатель мог сосредоточиться на самой логике.
Ниже приведен пример модели, использующей синтаксис BigQuery Standard SQL.
В этом случае Jinja используется, чтобы вставить в вывод набор технических строк, которых нет в источнике. Jinja позволяет выполнять итерацию по матрице значений и изменяет форму каждой строки таким образом, чтобы ее можно было включить в основную таблицу, что позволяет сделать ваш запрос более лаконичным.

Каждая модель DBT может быть дополнена описанием. Это означает, что документация находится в том же репозитории, что и ваша кодовая база, что упрощает понимание каждого шага. Кроме того, поскольку документация всегда находится перед инженерами, работающими с данными, и поскольку она создается непосредственно из кодовой базы, требуется минимальное обслуживание, чтобы поддерживать ее в актуальном состоянии.
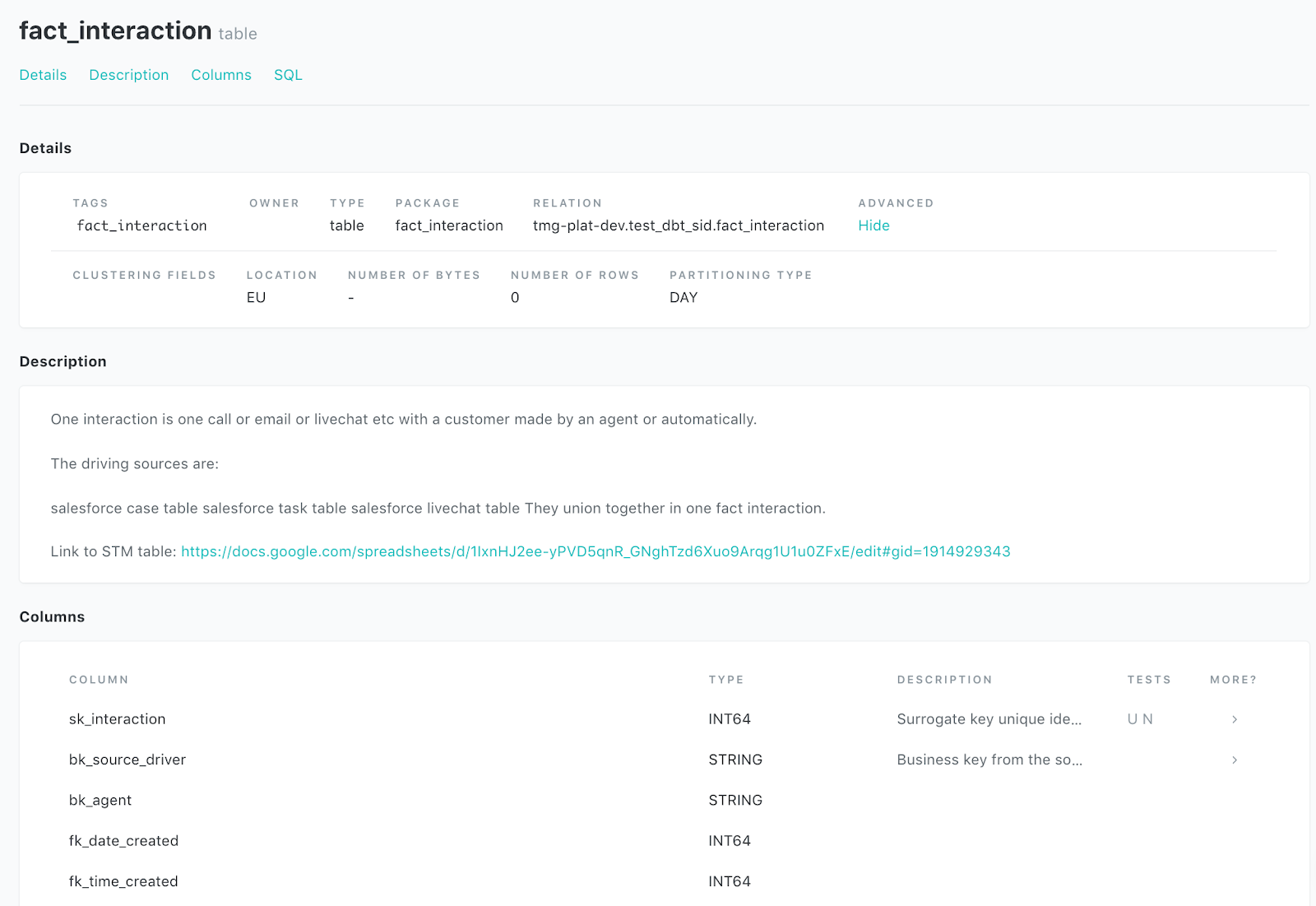
В data-driven компаниях качество данных, используемых для принятия решений, всегда имеет первостепенное значение. DBT позволяет выполнять различные типы тестов, что помогает получить качественные данные.
Простые тесты можно проводить с помощью синтаксиса YAML, поместив тестовый файл в ту же папку, что и ваши модели.
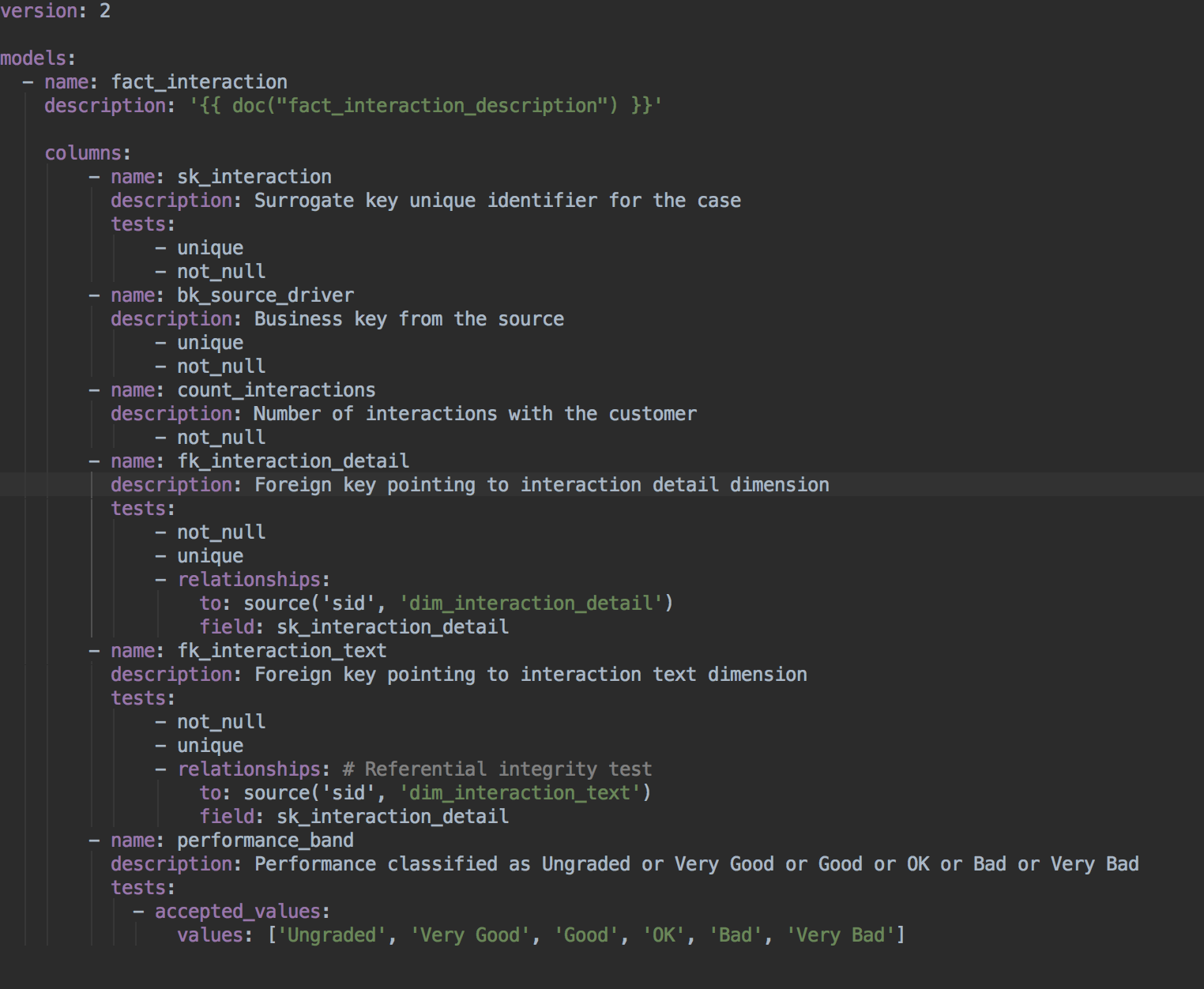
В этом конкретном примере проведены следующие тесты:
sk_interaction, bk_source_driver принимают уникальные значения и никогда не равны нулю.
count_interactions никогда не бывает нулевым
fk_interaction_detail не равно нулю, принимает уникальные значения, и все внешние ключи fk_interaction_detail могут соединяться с суррогатными ключами sk_interaction_detail. Это называется тестом ссылочной целостности и помогает убедиться, что ваша звездообразная схема построена надлежащим образом.
fk_interaction_text имеет аналогичные критерии тестирования.
Performance_band может принимать только определенный массив значений.
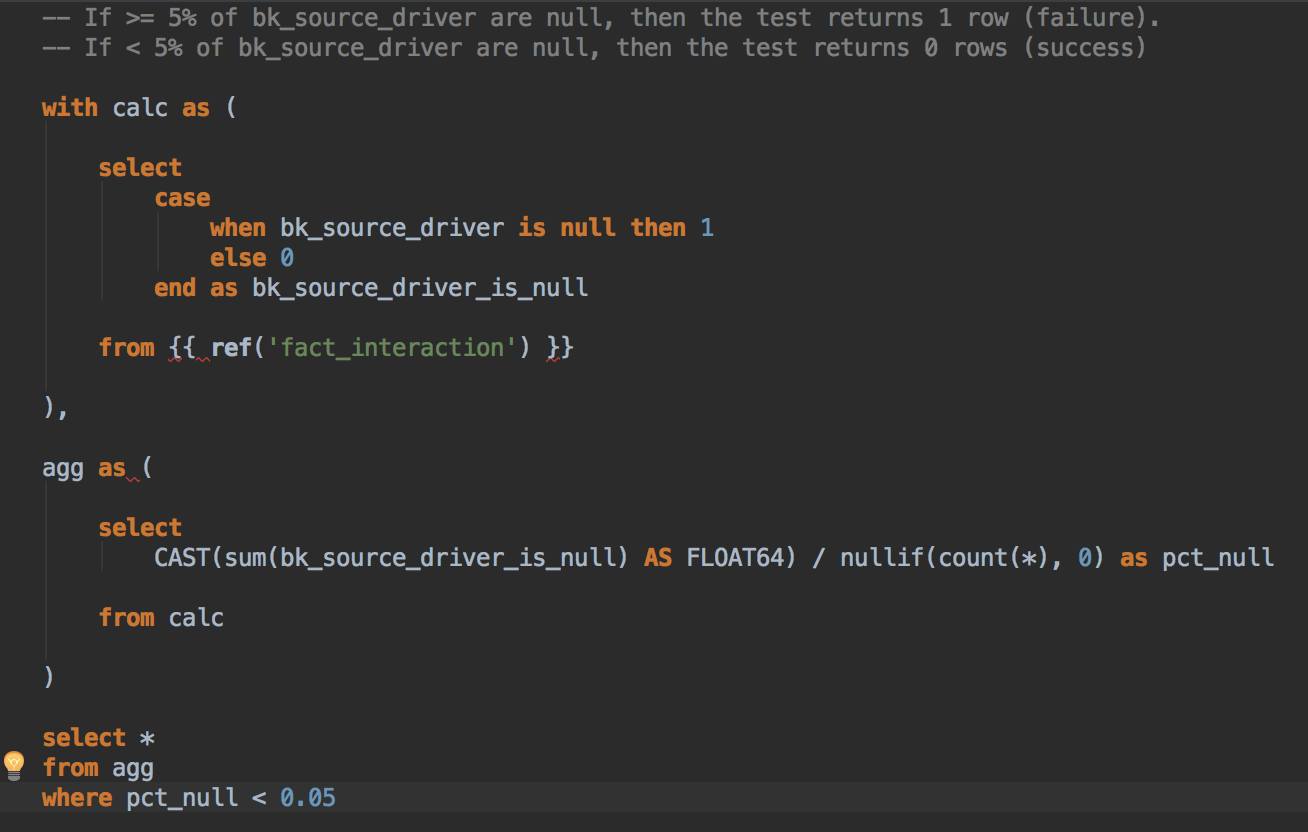
Более продвинутое тестирование может быть реализовано с использованием синтаксиса SQL.
Приведенный ниже запрос гарантирует, что в поле «bk_source_driver» из модели «fact_interaction» не более 5% значений, установленных как NULL.
Модели DBT основаны на результатах других моделей или источниках данных. Источники данных могут быть также определены с помощью синтаксиса YAML и являются повторно используемыми и документируемыми сущностями, которые доступны в моделях DBT.
В примере ниже показано, как можно определить источник в Sharded BigQuery Tables. Также можно использовать переменные для динамического выбора желаемого сегмента. В этом конкретном случае переменная «execution_date» передается на входе в DBT и определяет, какие сегменты используются в процессе трансформации.

DBT также предлагает возможность писать свои собственные функции (макросы), которые можно использовать для упрощения моделей, а также для создания более мощных запросов, добавляющих большую выразительность вашему SQL без ущерба для читабельности.
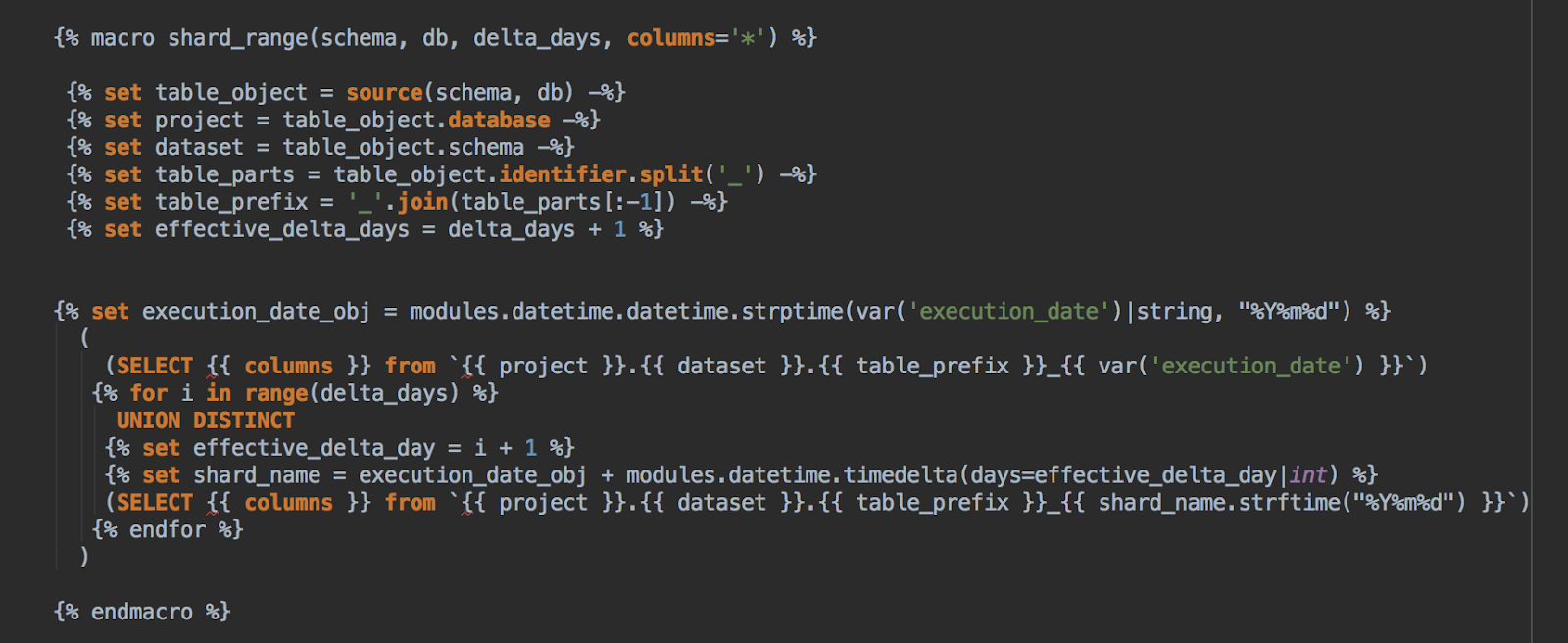
Макрос в примере ниже используется для объединения нескольких ежедневных сегментов одной и той же таблицы в зависимости от переданной переменной «execution_date» и количества прошлых сегментов, которые мы хотим принять во внимание.
Выводы
Команда разработчиков Telegraph тестировала DBT (базовую версию) в течение двух месяцев. Он оказался отличным инструментом для всех проектов, требующих трансформации данных. Подводя итог нашему опыту, вот список плюсов и минусов этого инструмента.
Плюсы:
Это открытый исходный код, доступный для настройки.
Легко применять контроль версий.
Документация живет вместе с вашим проектом DBT и автоматически генерируется из вашей кодовой базы.
Не требуется никаких специальных навыков. Если ваши инженеры знакомы с SQL и имеют базовые знания Python, этого достаточно, чтобы приступить к DBT.
Шаблон каждого проекта создается автоматически при запуске DBT. Это обеспечивает соблюдение стандарта для всех наших потоков данных.
Вся вычислительная работа перекладывается на ваше хранилище данных. Это позволяет достичь высокой производительности при использовании технологий, подобных BigQuery или Snowflake.
Из-за вышеизложенного для организации DBT проекта требуются минимальные ресурсы.
Он позволяет тестировать данные (тесты схемы, тесты ссылочной целостности, пользовательские тесты) и обеспечивает качество данных.
Упрощает отладку сложных цепочек запросов. Их можно разделить на несколько моделей и макросов, которые можно протестировать отдельно.
Это хорошо задокументировано, и кривая обучаемости не очень крутая.
Минусы:
Инструмент на основе SQL: он может предложить меньшую читабельность по сравнению с инструментами с интерактивным пользовательским интерфейсом.
Пользовательский интерфейс предназначен только для документации. Это помогает визуализировать процесс трансформации, но ваши инженеры по обработке данных должны поддерживать аккуратность и понятность проекта DBT. Наличие интерактивного UI, который позволяет визуально видеть поток данных и изменять запросы, может быть полезным, особенно когда речь идет о сложных конвейерах данных.
Создание документации для BigQuery занимает много времени из-за плохой реализации, которая сканирует все сегменты в наборе данных.
DBT охватывает только T в ETL, поэтому вам потребуются другие инструменты для выполнения извлечения и загрузки данных в хранилище.



