
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

По данным Росстта в среднем житель России имеет доход 35 700 ₽ в месяц. Эта цифра мало что говорит о благосостоянии населения. Если взять двух человек — одного с доходом 70 000 ₽ и 1400 ₽, их средний ежемесячный доход будет равен ровно 35 700 ₽. Чтобы лучше продемонстрировать распределение доходов, я смастерил калькулятор, который позволяет посчитать количество людей с заданным диапазоном дохода и наглядно продемонстрировать их вклад в общий уровень доходов.
В этом посте я расскажу как от довольно скупых данных, которые доступны на сайте Росстата сгенерировать датасет для подробной инфографики.
Обзор существующих решений
Перед тем как приступить к изобретению велосипеда я посмотрел как обычно изображают распределение доходов. Практически все варианты можно разделить на два класса:
1. Гистограммы
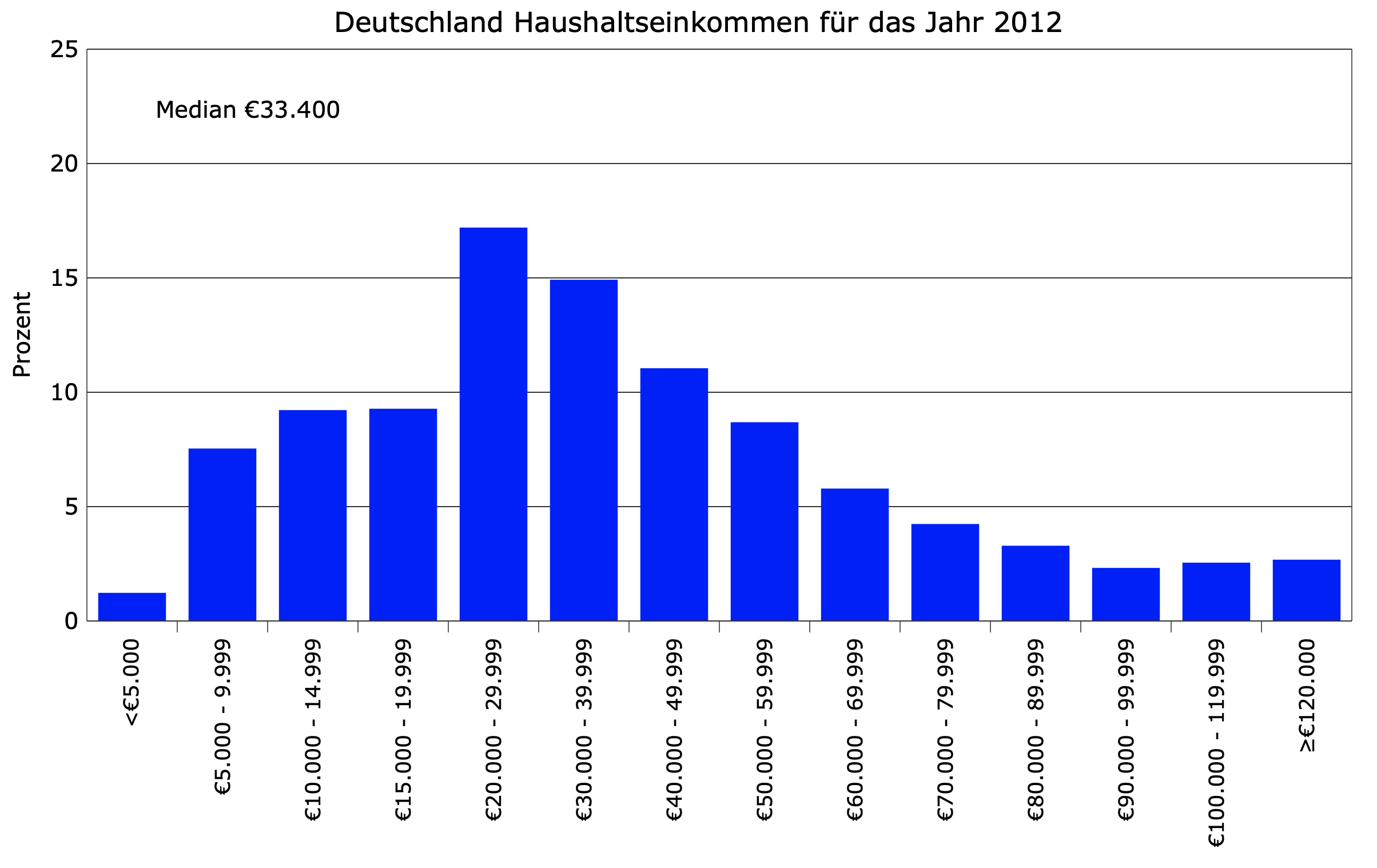
Delphi234, CC0, via Wikimedia Commons
Гистограмма представляет из себя двухмерный график, по горизонтальной оси которого отложен размер дохода, а по вертикальной — количество людей с соответствующим доходом. Этот вариант наиболее точно отражают суть явления, но, к сожалению, понятен он только тем читателям, которые привыкли работать с графиками.
Примеры:
Графики и жизнь
Хабр Карьера
Die Zeit (немецкий)
IW (снова немецкий)
2. Пирамиды

Artist not credited. Published by International Pub. Co., Cleveland, Ohio., Public domain, via Wikimedia Commons
Пирамиды в представлении социального неравенства стары как сама инфографика и очень хорошо понятны всем читателям, но как правило крайне манипулятивны. В зависимости от политического мировоззрения авторов социальные низы представляются либо трудягами-страдальцами, которые сгорбившись несут на своих плечах пирующих бездельников, либо какими-нибудь бомжами, которые по мере своего движения по этажам пирамиды обзаводятся приличной одеждой и довольной улыбкой. Так или иначе, экономику нам пытаются преподнести как некую игру с нулевой суммой, в которой увеличить своё благосостояние можно только отобрав кусок у ближнего. В реальности же, если кто-то из бедняков переберётся с нижнего этажа наверх, то оставшимся беднякам от этого точно тяжелее не станет. А богачи в свою очередь не только не должны будут потесниться, но и могут сами увеличить свой доход, если у бедняков вдруг появятся лишние деньги.
Примеры:
Statista
Die Zeit (немецкий)
Мой вариант
Мне показалась более удачной аналогия с биологическими клетками. У всех есть примерно одинаковое ядро, рост клетки зависит от внешних условий и не обязательно связан с пожиранием соседних клеток:

При этом я посчитал нужным отсортировать эти клетки по их размерам, чтобы отразить характерные социальные пузыри, которые часто мешают людям поверить в правдивость статистики.

Таким образом, чтобы реализовать эту концепцию, мне нужно было поделить население России на произвольное количество групп и иметь возможность посчитать среднедушевой доход для этой группы.
Исходные данные Росстата
Самое близкое из того, что мне нужно на сайте Росстата — это данные по распределению общего объёма доходов по 20-процентным группам населения, а также распределение населения по величине среднедушевых доходов. Только лишь на основе этих данных можно было бы нарисовать четыре кружка, которые не дали бы ровно никакого представления о картине в целом. Для более мелкой дискретизации нужно как-то интерполировать данные. Находим методику, по которой убеждаемся, что в основу модели распределения населения по доходам заложено логнормальное распределение:

где x — ежемесячный доход, а параметры mu и sigma рассчитываются из среднего (xmean) и медианного (xmedian) доходов следующим образом:


На графике это всё выглядит следующим образом:

Теперь, когда у нас есть непрерывная функция, можно перейти к созданию своего датасета.
Генерируем датасет
Чтобы сравнение доходов различных социальных групп имело смысл, нужно разделить всю популяцию на равное число групп nGroups. Для визуализации нам понадобятся следующие характеристики каждой группы:
размер популяции группы,
populationминимальный уровень дохода,
incomeMinсредний уровень дохода,
incomeMeanмаксимальный уровень дохода,
incomeMaxгодовой доход всей группы,
populationIncomeYear

Минимальный доход равен максимальному доходу предыдущей группы. Максимальный доход высчитывается таким образом, чтобы размер популяции группы был равен заданному. Размер популяции получается интегрированием функции распределения населения по доходам от минимального его значения до максимального. Чтобы получить размер дохода всей группы, нужно проинтегрировать ту же функцию, умноженную на текущий размер дохода.
Задачка получается неявная, поэтому размер максимального дохода я считаю методом Ньютона (благо, производная функции известна). Максимальный доход самой богатой группы стремится к бесконечности, поэтому её доход считается по остаточному принципу по известному общему доходу всей популяции. Алгоритм далёк от оптимального в плане количества вычислений, но датасет нужно сгенерировать только один раз, поэтому я подумал, что и так сойдёт...
Кусок кода с расчётом параметров для датасета:
datasetPure = {
function incomeDistribution(nGroups) {
let data = []
let groupPopulation = populationTotal/nGroups
let groupIncomeMin = 1e-12, groupIncomeMax, groupIncomeMean
let groupTotalYearIncome = []
//The function f and its derivative dfdx come in handy for Newtonian iterations
let f = function(groupIncomeMin, groupIncomeMax) {
return integral(populationWithIncome, groupIncomeMin, groupIncomeMax, 1) - groupPopulation
}
let dfdx = function(groupIncomeMax) {
return populationWithIncome(groupIncomeMax)
}
let delta0 = 10000 //initial step
for (let i = 0; i < nGroups; i++) {
if (i < nGroups-1) { //
groupIncomeMax = groupIncomeMin + delta0
let groupIncomeMaxPre = groupIncomeMax
let err = 100
let j = 0
//Newton iterations: Calculating the maximum income difference at which the population size is equal to a given population size.
while (err*err > 0.01) {
groupIncomeMax += -f(groupIncomeMin, groupIncomeMaxPre)/dfdx(groupIncomeMaxPre)
err = groupIncomeMax - groupIncomeMaxPre
groupIncomeMaxPre = groupIncomeMax
j++
if (j>15) {
groupIncomeMax = j + " iterations were not enough, last result: " + groupIncomeMax
groupIncomeMean = j + " iterations were not enough"
break
}
groupTotalYearIncome[i] = integral(incomeOfPopulationGroup, groupIncomeMin, groupIncomeMax, 1)*12
groupIncomeMean = groupTotalYearIncome[i]/12.0/groupPopulation
delta0 = groupIncomeMax - groupIncomeMin
}
} else { //The maximum income can be infinitely large, so we just write that it is very large.
groupTotalYearIncome[i] = incomeTotal
for (let j = 0; j < nGroups - 1; j++) {
groupTotalYearIncome[i] -= groupTotalYearIncome[j]
}
groupIncomeMean = groupTotalYearIncome[i]/12/groupPopulation
groupIncomeMax = "дохрена"
}
data.push({population: groupPopulation, incomeMin: groupIncomeMin, incomeMean: groupIncomeMean, incomeMax: groupIncomeMax, populationIncomeYear: groupTotalYearIncome[i]})
groupIncomeMin = groupIncomeMax
}
return data
}
return incomeDistribution
}Для визуализации я пользовался библиотекой D3.js. Получившийся датасет нужно привести к читаемому библиотекой виду: дать имена группам и назначить "детей" с учётом возможной разбивки на классы, ну и настроить всякие цвета и переключения...
Ресурсы проекта
Программа генерации датасета на Observable. Когда появятся данные по регионам за 2020-й год, можно будет довольно быстро наделать датасетов для каждого региона.
Репозиторий сайта на GitHub.
![Открытые библиотеки для обучения байесовских сетей [BAMT] и идентификации структуры данных [EPDE]](/upload/resize_cache/iblock/49b/105_70_0/49b93580d511fed5817ca87d7495e23f.jpeg "Открытые библиотеки для обучения байесовских сетей [BAMT] и идентификации структуры данных [EPDE]")


