
Основатель и директор «Otomato Software», один из инициаторов и инструкторов первой в Израиле DevOps-сертификации Антон Вайс рассказал на прошлогоднем DevOpsDays Moscow про теорию хаоса и главные принципы хаосной инженерии, а также объяснил, как устроена идеальная DevOps-организация будущего.
Мы приготовили текстовую версию доклада.
Доброе утро!
DevOpsDays в Москве второй год подряд, я второй раз на этой сцене, многие из вас второй раз в этом зале. А что это значит? Это значит, что DevOps-движение в России растет, множится, а главное, это значит, что пришло время поговорить о том, что же такое DevOps в 2018 году.
Поднимите руки те, кто думает, что в 2018 году DevOps — это уже профессия? Есть такие. Есть в зале DevOps-инженеры, у кого в описании должности написано «DevOps-инженер»? Есть в зале DevOps-менеджеры? Таких нет. DevOps-архитекторы? Тоже нет. Маловато. Что, действительно ни у кого не написано, что он DevOps-инженер?
Значит, большинство из вас думает, что это антипаттерн? Что такой профессии быть не должно? Думать мы можем все, что угодно, а пока мы думаем, индустрия торжественно движется вперед под звуки DevOps-трубы.
Кто слышал про новую тему, которая называется DevDevOps? Это такая новая методика, которая позволяет обеспечить эффективное сотрудничество между разработчиками и девопсами. Причем не такая новая. Если судить по твиттеру, то 4 года назад уже начали об этом разговаривать. И до сих пор интерес к этому растет и растет, то есть проблема есть. Проблему надо решать.

Мы люди творческие, так просто не успокаиваемся. Мы говорим: DevOps — это недостаточно всеобъемлющее слово, там не хватает еще всякого разного, интересных элементов. И мы идем в свои секретные лаборатории и начинаем плодить любопытные мутации: DevTestOps, GitOps, DevSecOps, BizDevOps, ProdOps.
Логика железная, да? У нас система доставки не функциональная, у нас системы нестабильные и пользователи недовольные, мы не успеваем выкатывать ПО вовремя, не укладываемся в бюджет. Как мы будем все это решать? Мы придумаем новое слово! Оно будет заканчиваться на «Ops», и проблема решена.
Так я называю этот подход — «Ops, и проблема решена».
Это все отходит на задний план, если мы напоминаем себе, зачем мы все это придумали. Придумали мы весь этот DevOps, чтобы сделать доставку ПО и собственную работу в этом процессе как можно более беспрепятственной, безболезненной, эффективной, а главное, приятной.
DevOps вырос из боли. И нам надоело страдать. А для того, чтобы это все произошло, мы основываемся на вечнозеленых практиках: эффективное сотрудничество, практики потока, а самое главное, системное мышление, потому что без него никакой DevOps не работает.
И если уж мы заговорили про системное мышление, давайте напомним себе, что такое система.

Если вы хакер-революционер, то для вас система — это однозначное зло. Это туча, которая нависает над вами и заставляет вас делать то, что вы делать не хотите.

С точки зрения системного мышления, система — это некое целое, которое состоит из частей. В этом смысле, каждый из нас — это система. Организации, в которых мы работаем, — это системы. И то, что мы с вами строим, оно так и называется — система.
Всё это — часть одной большой социотехнологической системы. И только если мы поймем, как эта социотехнологическая система вместе работает, только тогда мы сможем что-то в этом деле по-настоящему оптимизировать.
С точки зрения системного мышления, у системы есть разные интересные свойства. Во-первых, она состоит из частей, это значит, что ее поведение зависит от поведения частей. При этом все ее части также взаимозависимы. Получается, что чем больше у системы частей, тем сложнее понять или предсказать ее поведение.
С точки зрения поведения, тут есть еще один интересный факт. Система может делать что-то такое, что ни одна из ее отдельно взятых частей делать не может.
Как говорил доктор Рассел Акофф (один из основоположников системного мышления), это достаточно легко доказать при помощи мыслительного эксперимента. Например, кто в зале умеет писать код? Много рук, и это нормально, потому что это одно из основных требований к нашей профессии. Вы умеете писать, а ваши руки отдельно от вас могут писать код? Есть такие люди, которые скажут: «У меня не руки пишут код, у меня мозг пишет код». А мозг может отдельно от вас писать код? Ну, скорее всего нет.
Мозг — удивительная машина, мы и 10% не знаем о том, как он там работает, но функционировать отдельно от системы, которой является наш организм, он не может. И это легко доказать: откройте себе черепную коробку, достаньте оттуда мозг, положите его перед компьютером, пусть что-нибудь попробует написать простое. «Hello, world» на Python, например.
Если система может сделать нечто такое, чего ни одна из ее частей по-отдельности делать не может, то это значит, что ее поведение не определяется поведением ее частей. А чем оно тогда определяется? Оно определяется взаимодействием между этими частями. И соответственно, чем больше частей, тем сложнее взаимодействия, тем сложнее понять, предсказать поведение системы. И это делает такую систему хаотичной, потому что любое, самое незначительное, невидимое глазу изменение в любой из частей системы может привести к совершенно непредсказуемым результатам.
Эта чувствительность к начальным условиям впервые была обнаружена и исследована американским метеорологом Эдом Лоренцом. Впоследствии она получила название «эффект бабочки» и привела к развитию такого движения научной мысли, которое называется «теория хаоса». Эта теория стала одним из основных сдвигов парадигмы в науке 20 века.
Люди, которые занимаются изучением хаоса, называют себя хаосологи.

Собственно причиной этого доклада стало то, что, работая со сложными распределенными системами и большими международными организациями, в какой-то момент я понял, что это то, кем я себя ощущаю. Я — хаосолог. Это, в общем, такой хитроумный способ сказать: «Я не понимаю, что здесь происходит и не знаю, что с этим делать».
Я думаю, что многие из вас тоже себя так часто ощущают, так что вы тоже хаосологи. Я приглашаю вас в гильдию хаосологов. Системы, которые мы с вами, дорогие коллеги хаосологи, будем изучать, называются «сложные адаптивные системы».
Что такое адаптивность? Адаптивность означает, что индивидуальное и коллективное поведение частей в такой адаптивной системе изменяется и самоорганизуется, реагируя на события или цепочки микрособытий в системе. То есть система адаптируется к изменениям посредством самоорганизации. И вот эта способность к самоорганизации основана на добровольном, полностью децентрализованном сотрудничестве свободных автономных агентов.
Еще одно интересное свойство таких систем заключается в том, что они свободно масштабируемы. Что нас, как хаосологов-инженеров, должно несомненно интересовать. Так вот, если мы сказали, что поведение сложной системы определяется взаимодействием ее частей, то что нас должно интересовать? Взаимодействие.
Есть еще два интересных вывода.

Во-первых, мы понимаем, что сложную систему невозможно упростить путем упрощения ее частей. Во-вторых, единственный способ упростить сложную систему — это за счет упрощения взаимодействий между ее частями.
Как мы взаимодействуем? Мы с вами все — части большой информационной системы, которая называется человеческое общество. Мы взаимодействуем посредством общего языка, если он у нас есть, если мы его находим.
Но язык сам по себе — сложная адаптивная система. Соответственно, для того, чтобы взаимодействовать более эффективно и просто, нам необходимо создание каких-то протоколов. То есть какой-то последовательности символов и действий, которые сделают обмен информацией между нами более простым, более предсказуемым, более понятным.
Я хочу сказать, что тенденции к усложнению, к адаптивности, к децентрализации, к хаотичности прослеживаются во всем. И в тех системах, которые мы с вами строим, и в тех системах, частью которых мы являемся.
И чтобы не быть голословным, давайте посмотрим на то, как изменяются те системы, которые мы с вами создаём.

Вы ждали этого слова, я понимаю. Мы на DevOps-конференции, сегодня это слово прозвучит где-то сто тысяч раз и потом приснится нам ночью.
Микросервисы — первая программная архитектура, которая возникла как реакция на DevOps-практики, которая призвана сделать наши системы более гибкими, более масштабируемыми, обеспечить непрерывную доставку. Каким образом она это делает? За счет сокращения объема сервисов, сокращения границ проблем, которые эти сервисы обрабатывают, сокращения времени доставки. То есть мы уменьшаем, упрощаем части системы, увеличиваем их количество, соответственно, неизменно повышается сложность взаимодействий между этими частями, то есть возникают новые проблемы, которые нам с вами приходится решать.

Микросервисы — это еще не конец, микросервисы это, в общем-то, уже вчерашний день, потому что приходит Serverless. Все серверы сгорели, нет серверов, нет операционных систем, только чистый исполняемый код. Конфигурации отдельно, состояния отдельно, все управляется событиями. Красота, чистота, тишина, нет событий, ничего не происходит, полный порядок.
Где сложность? Сложность, понятное дело, во взаимодействиях. Сколько одна функция может сделать сама по себе? Как она взаимодействует с другими функциями? Очереди сообщений, базы данных, балансировщики. Как воссоздать какое-то событие, когда произошел сбой? Куча вопросов и немного ответов.
Микросервисы и Serverless — это все то, что мы, компьютерные хипстеры, называем Cloud Native. Это все об облаке. Но облако по сути своей тоже ограничено масштабируемо. Мы привыкли думать о нем, как о распределенной системе. На самом деле, где живут сервера облачных провайдеров? В дата-центрах. То есть у нас тут некая централизованная, очень ограниченная, распределенная модель.
Сегодня мы понимаем, что интернет вещей — это уже не только громкие слова о том, что даже по скромным предсказаниям, в ближайшие пять-десять лет нас ждут миллиарды устройств, подключенных к интернету. Огромное количество полезных и бесполезных данных, которые будут сливаться в облако и заливаться из облака.
Облако не выдержит, поэтому мы все больше говорим о том, что называется «периферийные вычисления». Или еще мне нравится замечательное определение «fog computing». Оно подёрнуто мистикой романтизма и загадочности.

Туманные вычисления. Речь идет о том, что облака — это такие централизованные сгустки воды, пара, льда, камней. А туман — это капельки воды, которые рассеяны вокруг нас в атмосфере.
В туманной парадигме большая часть работы выполняется этими капельками совершенно автономно или в сотрудничестве с другими капельками. И они обращаются к облаку, только когда действительно совсем прижмет.
То есть опять децентрализация, автономность, ну и, конечно, многие из вас понимают уже, к чему все это идет, потому что нельзя говорить о децентрализации и не упомянуть о блокчейне.
Есть те, кто верит, это те, кто вложились в криптовалюту. Есть те, кто верят, но боятся, как я, например. А есть те, кто не верит. Тут можно по-разному относиться. Есть технология, новое непонятное дело, есть проблемы. Как любая новая технология она поднимает больше вопросов, чем дает ответов.
Хайп вокруг блокчейна понятен. Даже если отбросить в сторону золотую лихорадку, то сама по себе технология дает замечательные обещания светлого будущего: больше свобода, больше автономия, распределенное глобальное доверие. Чего тут не хотеть?
Соответственно, все больше и больше инженеров по всему миру начинают разрабатывать децентрализованные аппликации. И это сила, от которой невозможно отмахнуться, просто сказав: «Ааа, блокчейн — это просто плохо имплементированная распределенная база данных». Или как скептики любят говорить: «Для блокчейна нет никаких реальных применений». Если вдуматься, то 150 лет назад они говорили то же самое про электричество. И даже в чем-то были правы, потому что то, что электричество делает сегодня возможным, в 19 веке было нереально вообще никак.
Кстати, кто знает, что за лого на экране? Это Hyperledger. Это проект, который разрабатывается под эгидой The Linux Foundation, в него входит набор блокчейн-технологий. Это реально сила нашего комьюнити открытого кода.

Так вот, система, которую мы с вами разрабатываем, становится все сложнее, все хаотичнее, все адаптивнее. Netflix — пионеры микросервисных систем. Они были одними из первых, кто это поняли, они разработали набор инструментов, который назвали Simian Army, самым известным из которых стал Chaos Monkey. Он определили то, что стало известно как «принципы хаосной инженерии».
Кстати, в процессе работы над докладом мы даже перевели этот текст на русский язык, так что заходите по линку, читайте, комментируйте, ругайте.
Вкратце принципы хаосной инженерии говорят о следующем. Сложные распределенные системы по сути своей непредсказуемы, и по сути своей в них есть ошибки. Ошибки неизбежны, а это значит, что нам нужно эти ошибки принять и работать с этими системами совершенно по-другому.
Мы должны сами пытаться вносить эти ошибки в наши продакшн системы, чтобы испытывать наши системы на эту самую адаптивность, на эту самую способность к самоорганизации, к выживаемости.
И это меняет всё. Не только то, как мы запускаем систему в продакшн, но и как мы их разрабатываем, как мы их тестируем. Нет никакого процесса стабилизации, замораживания кода, наоборот, есть постоянный процесс дестабилизации. Мы пытаемся убить систему и увидеть, что она продолжает выживать.

Соответственно, это требует от наших систем, чтобы они тоже как-то поменялись. Для того, чтобы они стали более устойчивы, им нужны некие новые протоколы взаимодействия между их частями. Чтобы эти части могли договариваться и приходить к какой-то самоорганизации. И возникают всякие новые инструменты, новые протоколы, которые я так и называю «протоколы взаимодействия распределенных систем».

О чем я говорю? Во-первых, проект Opentracing. Некая попытка создать общий протокол распределенного отслеживания, который является совершенно незаменимым инструментом для отладки сложных распределенных систем.

Далее — Open Policy Agent. Мы говорим, что мы не можем предсказать то, что произойдет с системой, то есть нам необходимо повысить ее observability, наблюдаемость. Opentracing относится к семье инструментов, которые дают наблюдаемость наших систем. Но наблюдаемость нам нужна для того, чтобы определить, ведет себя система так, как мы от нее ожидаем, или нет. Как нам определить ожидаемое поведение? За счет определения в ней какой-то политики, какого-то свода правил. Проект Open Policy Agent занимается определением этого свода правил по широкому спектру: от доступа до размещения ресурсов.

Как мы сказали, наши системы все более событийно управляемые. Serverless — это замечательный пример событийно управляемых систем. Для того, чтобы мы могли передавать события между системами и отслеживать их, нам нужен некий общий язык, некий общий протокол того, как мы разговариваем о событиях, как мы друг другу их передаем. Этим занимается проект под названием Cloudevents.

Непрерывный поток изменений, который омывает наши системы, постоянно их дестабилизируя, это непрерывный поток программных артефактов. Для того, чтобы мы могли поддерживать этот постоянный поток изменений, нам нужен некий общий протокол, при помощи которого мы сможем разговаривать о том, что такое программный артефакт, как он проверен, какую верификацию он прошел. Этим занимается проект под названием Grafeas. То есть общий протокол метаданных программных артефактов.

И, наконец, если мы хотим, чтобы наши системы были полностью самостоятельные, адаптивные, самоорганизовывались, мы должны дать им право на самоидентификацию. Проект под названием spiffe именно этим и занимается. Это тоже проект под эгидой Cloud Native Computing Foundation.
Все эти проекты молодые, им всем нужна наша любовь, наша проверка. Это все открытый код, наше тестирование, наша имплементация. Они показывают нам, в какую сторону движется технология.
Но DevOps никогда не был в первую очередь о технологии, в первую очередь он всегда был о сотрудничестве между людьми. И, соответственно, если мы хотим, чтобы системы, которые мы разрабатываем, поменялись, то должны поменяться мы сами. На самом деле, мы и так меняемся, у нас нет особенно выбора.
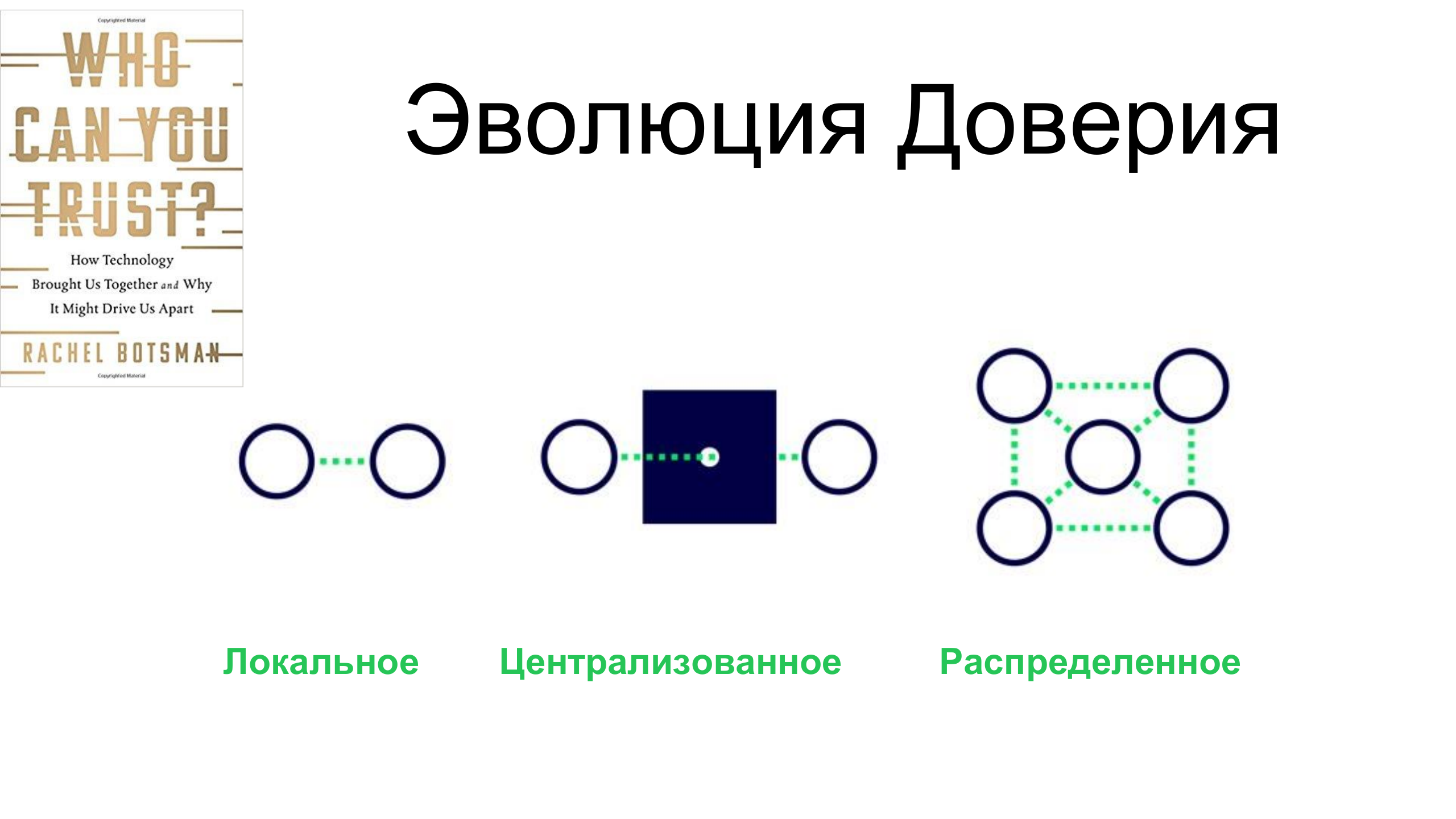
Есть замечательная книга британской писательницы Рэйчел Ботсман, в которой она пишет об эволюции доверия на протяжении человеческой истории. Она говорит, что изначально, в первобытных обществах, доверие было локальным, то есть мы доверяли только тем, кого мы знаем лично.
Дальше был очень долгий период — темное время, когда доверие было централизованно, когда мы стали доверять людям, которых мы не знаем на основании того, что мы с ними принадлежим к одному общественному или государственному институту.
И вот, что мы видим в нашем современном мире: доверие становится все более распределенным и децентрализованным, и основано оно на свободе информационных потоков, на доступности информации.
Если вдуматься, то эту вот самую доступность, которая делает это доверие возможным, мы с вами и осуществляем. Это значит, что должно изменяться и то, как мы сотрудничаем, и то, как мы это делаем, потому что централизованные иерархические IT-организации старого толка перестают работать. Они начинают отмирать.
Идеальная DevOps-организация будущего — это децентрализованная, адаптивная система, состоящая из автономных команд, каждая из которых состоит из автономных индивидуумов. Эти команды разбросаны по всему миру, они эффективно сотрудничают друг с другом при помощи асинхронной коммуникации, при помощи высокопрозрачных протоколов обмена информацией. Очень красиво, правда? Очень красивое будущее.
Конечно, это все невозможно без культурных изменений. У нас должны быть трансформационное лидерство, личная ответственность, внутренняя мотивация.

Вот это основа DevOps-организаций: прозрачность информации, асинхронные коммуникации, трансформационное лидерство, децентрализация.
Системы, частью которых мы являемся, и те, которые мы строим, они все более хаотичны, и нам, людям, тяжело справиться с этой мыслью, тяжело отказаться от иллюзии контроля. Мы пытаемся продолжать их контролировать, и это зачастую приводит к выгоранию. Я это говорю на собственном опыте, я тоже обжегся, тоже инвалид непредвиденных сбоев в продакшне.

Выгорание происходит тогда, когда мы пытаемся контролировать то, что контролю по сути своей не поддается. Когда мы выгораем, то все теряет смысл, потому что мы теряем желание делать что-то новое, мы встаем в защитную позицию и начинаем защищать то, что есть.
Инженерная профессия, как я часто люблю себе напоминать, это в первую очередь творческая профессия. Если мы теряем желание что-то создавать, то мы превращаемся в пепел, превращаемся в золу. Выгорают люди, выгорают целые организации.
На мой взгляд, только принятие созидательной силы хаоса, только построение сотрудничества по его принципам — это то, что поможет нам не растерять то хорошее, что есть в нашей профессии.
Чего я вам и желаю: любить свою работу, любить то, что мы делаем. Этот мир кормится информацией, нам досталась честь его кормить. Так что давайте изучать хаос, будем хаосологами, будем приносить ценность, создавать что-то новое, ну, а проблемы, как мы уже выяснили, неизбежны, и когда они появятся, то мы скажем просто «Ops!», и проблема решена.
Что кроме Chaos Monkey?
На самом деле, все эти инструменты, они такие молодые. Те же Netflix строили инструменты под себя. Стройте инструменты под себя. Читайте принципы хаосной инженерии и соответствуйте этим принципам, а не старайтесь искать другие инструменты, которые кто-то другой уже построил.
Пытайтесь понять, как ваши системы ломаются и начинайте их ломать и смотреть, как они выдерживают удары. Это в первую очередь. А инструменты можно поискать. Всякие есть проекты.
Я не совсем понял момент, когда вы говорили про то, что систему нельзя упрощать, упрощая ее компоненты, и сразу же перешли к микросервисам, которые как раз упрощают систему упрощением самих компонентов и усложняя взаимодействия. Это по сути две части, противоречащие друг другу.
Совершенно верно, микросервисы — очень противоречивая тема вообще. На самом деле, упрощение частей повышает гибкость. Что микросервисы дают? Они дают нам гибкость и скорость, но простоты они нам уж точно не дают никак. Они повышают сложность.
То есть в философии DevOps микросервисы — это не такое уж и благо?
У любого блага есть изнанка. Есть благо: это повышает гибкость, дает нам возможность вносить изменения быстрее, но повышает сложность и, соответственно, хрупкость всей системы.
Все-таки на что больше упор: на упрощение взаимодействия или на упрощение частей?
Упор, несомненно, на упрощение взаимодействия, потому что если мы смотрим на это с точки зрения того, как мы с вами работаем, то, в первую очередь, нужно обращать внимание на упрощение взаимодействий, а не на упрощение работы каждого из нас отдельно. Потому что упрощение работы — это превращение в роботов. Вот в Макдональдсе это нормально работает, когда у тебя предписано: здесь бургер положил, здесь на него соус налил. Это в нашей творческой работе не работает совершенно.
Правда ли, что все, что вы рассказали, живет в мире без конкуренции, и хаос там такой добрый, и нет противоречий внутри этого хаоса, никто никого не хочет съесть, убить? Как конкуренция и DevOps должны жить?
Ну, это смотря о какой конкуренции мы говорим. О конкуренции на рабочем месте или о конкуренции между компаниями?
О конкуренции сервисов, которые существуют, потому что сервисы — это не несколько компаний. Мы создаем новый тип информационной среды, и любая среда не может жить без конкуренции. Везде есть конкуренция.
Те же самые Netflix, берем их за ролевую модель. Они это придумали почему? Потому что им нужно было быть конкурентоспособными. Вот эта гибкость и скорость движения, она является именно тем самым конкурентным требованием, она вносит хаотичность в наши системы. То есть хаос — это не то, что мы сознательно делаем, потому что мы его хотим, это то, что происходит из-за того, что этого требует мир. Нам просто приходится адаптироваться. И хаос, он как раз — результат конкуренции.
Это значит, хаос это отсутствие целей как бы? Или те цели, которые мы не хотим видеть? Мы в домике и не понимаем целей других. Конкуренция, на самом деле, она за счет того, что у нас четкие цели, и мы знаем, куда придем в каждый следующий момент времени. В этом, с моей точки зрения, суть DevOps.
Тоже взгляд на вопрос. Я думаю, что цель у нас всех одна: выживать и делать это с
наибольшим удовольствием. И конкурентная цель у любой организации такая же. Выживание происходит зачастую в конкурентной борьбе, тут уж ничего не поделаешь.
Мы приготовили текстовую версию доклада.
Доброе утро!
DevOpsDays в Москве второй год подряд, я второй раз на этой сцене, многие из вас второй раз в этом зале. А что это значит? Это значит, что DevOps-движение в России растет, множится, а главное, это значит, что пришло время поговорить о том, что же такое DevOps в 2018 году.
Поднимите руки те, кто думает, что в 2018 году DevOps — это уже профессия? Есть такие. Есть в зале DevOps-инженеры, у кого в описании должности написано «DevOps-инженер»? Есть в зале DevOps-менеджеры? Таких нет. DevOps-архитекторы? Тоже нет. Маловато. Что, действительно ни у кого не написано, что он DevOps-инженер?
Значит, большинство из вас думает, что это антипаттерн? Что такой профессии быть не должно? Думать мы можем все, что угодно, а пока мы думаем, индустрия торжественно движется вперед под звуки DevOps-трубы.
Кто слышал про новую тему, которая называется DevDevOps? Это такая новая методика, которая позволяет обеспечить эффективное сотрудничество между разработчиками и девопсами. Причем не такая новая. Если судить по твиттеру, то 4 года назад уже начали об этом разговаривать. И до сих пор интерес к этому растет и растет, то есть проблема есть. Проблему надо решать.
Мы люди творческие, так просто не успокаиваемся. Мы говорим: DevOps — это недостаточно всеобъемлющее слово, там не хватает еще всякого разного, интересных элементов. И мы идем в свои секретные лаборатории и начинаем плодить любопытные мутации: DevTestOps, GitOps, DevSecOps, BizDevOps, ProdOps.
Логика железная, да? У нас система доставки не функциональная, у нас системы нестабильные и пользователи недовольные, мы не успеваем выкатывать ПО вовремя, не укладываемся в бюджет. Как мы будем все это решать? Мы придумаем новое слово! Оно будет заканчиваться на «Ops», и проблема решена.
Так я называю этот подход — «Ops, и проблема решена».
Это все отходит на задний план, если мы напоминаем себе, зачем мы все это придумали. Придумали мы весь этот DevOps, чтобы сделать доставку ПО и собственную работу в этом процессе как можно более беспрепятственной, безболезненной, эффективной, а главное, приятной.
DevOps вырос из боли. И нам надоело страдать. А для того, чтобы это все произошло, мы основываемся на вечнозеленых практиках: эффективное сотрудничество, практики потока, а самое главное, системное мышление, потому что без него никакой DevOps не работает.
Что такое система?
И если уж мы заговорили про системное мышление, давайте напомним себе, что такое система.
Если вы хакер-революционер, то для вас система — это однозначное зло. Это туча, которая нависает над вами и заставляет вас делать то, что вы делать не хотите.
С точки зрения системного мышления, система — это некое целое, которое состоит из частей. В этом смысле, каждый из нас — это система. Организации, в которых мы работаем, — это системы. И то, что мы с вами строим, оно так и называется — система.
Всё это — часть одной большой социотехнологической системы. И только если мы поймем, как эта социотехнологическая система вместе работает, только тогда мы сможем что-то в этом деле по-настоящему оптимизировать.
С точки зрения системного мышления, у системы есть разные интересные свойства. Во-первых, она состоит из частей, это значит, что ее поведение зависит от поведения частей. При этом все ее части также взаимозависимы. Получается, что чем больше у системы частей, тем сложнее понять или предсказать ее поведение.
С точки зрения поведения, тут есть еще один интересный факт. Система может делать что-то такое, что ни одна из ее отдельно взятых частей делать не может.
Как говорил доктор Рассел Акофф (один из основоположников системного мышления), это достаточно легко доказать при помощи мыслительного эксперимента. Например, кто в зале умеет писать код? Много рук, и это нормально, потому что это одно из основных требований к нашей профессии. Вы умеете писать, а ваши руки отдельно от вас могут писать код? Есть такие люди, которые скажут: «У меня не руки пишут код, у меня мозг пишет код». А мозг может отдельно от вас писать код? Ну, скорее всего нет.
Мозг — удивительная машина, мы и 10% не знаем о том, как он там работает, но функционировать отдельно от системы, которой является наш организм, он не может. И это легко доказать: откройте себе черепную коробку, достаньте оттуда мозг, положите его перед компьютером, пусть что-нибудь попробует написать простое. «Hello, world» на Python, например.
Если система может сделать нечто такое, чего ни одна из ее частей по-отдельности делать не может, то это значит, что ее поведение не определяется поведением ее частей. А чем оно тогда определяется? Оно определяется взаимодействием между этими частями. И соответственно, чем больше частей, тем сложнее взаимодействия, тем сложнее понять, предсказать поведение системы. И это делает такую систему хаотичной, потому что любое, самое незначительное, невидимое глазу изменение в любой из частей системы может привести к совершенно непредсказуемым результатам.
Эта чувствительность к начальным условиям впервые была обнаружена и исследована американским метеорологом Эдом Лоренцом. Впоследствии она получила название «эффект бабочки» и привела к развитию такого движения научной мысли, которое называется «теория хаоса». Эта теория стала одним из основных сдвигов парадигмы в науке 20 века.
Теория хаоса
Люди, которые занимаются изучением хаоса, называют себя хаосологи.
Собственно причиной этого доклада стало то, что, работая со сложными распределенными системами и большими международными организациями, в какой-то момент я понял, что это то, кем я себя ощущаю. Я — хаосолог. Это, в общем, такой хитроумный способ сказать: «Я не понимаю, что здесь происходит и не знаю, что с этим делать».
Я думаю, что многие из вас тоже себя так часто ощущают, так что вы тоже хаосологи. Я приглашаю вас в гильдию хаосологов. Системы, которые мы с вами, дорогие коллеги хаосологи, будем изучать, называются «сложные адаптивные системы».
Что такое адаптивность? Адаптивность означает, что индивидуальное и коллективное поведение частей в такой адаптивной системе изменяется и самоорганизуется, реагируя на события или цепочки микрособытий в системе. То есть система адаптируется к изменениям посредством самоорганизации. И вот эта способность к самоорганизации основана на добровольном, полностью децентрализованном сотрудничестве свободных автономных агентов.
Еще одно интересное свойство таких систем заключается в том, что они свободно масштабируемы. Что нас, как хаосологов-инженеров, должно несомненно интересовать. Так вот, если мы сказали, что поведение сложной системы определяется взаимодействием ее частей, то что нас должно интересовать? Взаимодействие.
Есть еще два интересных вывода.
Во-первых, мы понимаем, что сложную систему невозможно упростить путем упрощения ее частей. Во-вторых, единственный способ упростить сложную систему — это за счет упрощения взаимодействий между ее частями.
Как мы взаимодействуем? Мы с вами все — части большой информационной системы, которая называется человеческое общество. Мы взаимодействуем посредством общего языка, если он у нас есть, если мы его находим.
Но язык сам по себе — сложная адаптивная система. Соответственно, для того, чтобы взаимодействовать более эффективно и просто, нам необходимо создание каких-то протоколов. То есть какой-то последовательности символов и действий, которые сделают обмен информацией между нами более простым, более предсказуемым, более понятным.
Я хочу сказать, что тенденции к усложнению, к адаптивности, к децентрализации, к хаотичности прослеживаются во всем. И в тех системах, которые мы с вами строим, и в тех системах, частью которых мы являемся.
И чтобы не быть голословным, давайте посмотрим на то, как изменяются те системы, которые мы с вами создаём.
Вы ждали этого слова, я понимаю. Мы на DevOps-конференции, сегодня это слово прозвучит где-то сто тысяч раз и потом приснится нам ночью.
Микросервисы — первая программная архитектура, которая возникла как реакция на DevOps-практики, которая призвана сделать наши системы более гибкими, более масштабируемыми, обеспечить непрерывную доставку. Каким образом она это делает? За счет сокращения объема сервисов, сокращения границ проблем, которые эти сервисы обрабатывают, сокращения времени доставки. То есть мы уменьшаем, упрощаем части системы, увеличиваем их количество, соответственно, неизменно повышается сложность взаимодействий между этими частями, то есть возникают новые проблемы, которые нам с вами приходится решать.
Микросервисы — это еще не конец, микросервисы это, в общем-то, уже вчерашний день, потому что приходит Serverless. Все серверы сгорели, нет серверов, нет операционных систем, только чистый исполняемый код. Конфигурации отдельно, состояния отдельно, все управляется событиями. Красота, чистота, тишина, нет событий, ничего не происходит, полный порядок.
Где сложность? Сложность, понятное дело, во взаимодействиях. Сколько одна функция может сделать сама по себе? Как она взаимодействует с другими функциями? Очереди сообщений, базы данных, балансировщики. Как воссоздать какое-то событие, когда произошел сбой? Куча вопросов и немного ответов.
Микросервисы и Serverless — это все то, что мы, компьютерные хипстеры, называем Cloud Native. Это все об облаке. Но облако по сути своей тоже ограничено масштабируемо. Мы привыкли думать о нем, как о распределенной системе. На самом деле, где живут сервера облачных провайдеров? В дата-центрах. То есть у нас тут некая централизованная, очень ограниченная, распределенная модель.
Сегодня мы понимаем, что интернет вещей — это уже не только громкие слова о том, что даже по скромным предсказаниям, в ближайшие пять-десять лет нас ждут миллиарды устройств, подключенных к интернету. Огромное количество полезных и бесполезных данных, которые будут сливаться в облако и заливаться из облака.
Облако не выдержит, поэтому мы все больше говорим о том, что называется «периферийные вычисления». Или еще мне нравится замечательное определение «fog computing». Оно подёрнуто мистикой романтизма и загадочности.
Туманные вычисления. Речь идет о том, что облака — это такие централизованные сгустки воды, пара, льда, камней. А туман — это капельки воды, которые рассеяны вокруг нас в атмосфере.
В туманной парадигме большая часть работы выполняется этими капельками совершенно автономно или в сотрудничестве с другими капельками. И они обращаются к облаку, только когда действительно совсем прижмет.
То есть опять децентрализация, автономность, ну и, конечно, многие из вас понимают уже, к чему все это идет, потому что нельзя говорить о децентрализации и не упомянуть о блокчейне.
Есть те, кто верит, это те, кто вложились в криптовалюту. Есть те, кто верят, но боятся, как я, например. А есть те, кто не верит. Тут можно по-разному относиться. Есть технология, новое непонятное дело, есть проблемы. Как любая новая технология она поднимает больше вопросов, чем дает ответов.
Хайп вокруг блокчейна понятен. Даже если отбросить в сторону золотую лихорадку, то сама по себе технология дает замечательные обещания светлого будущего: больше свобода, больше автономия, распределенное глобальное доверие. Чего тут не хотеть?
Соответственно, все больше и больше инженеров по всему миру начинают разрабатывать децентрализованные аппликации. И это сила, от которой невозможно отмахнуться, просто сказав: «Ааа, блокчейн — это просто плохо имплементированная распределенная база данных». Или как скептики любят говорить: «Для блокчейна нет никаких реальных применений». Если вдуматься, то 150 лет назад они говорили то же самое про электричество. И даже в чем-то были правы, потому что то, что электричество делает сегодня возможным, в 19 веке было нереально вообще никак.
Кстати, кто знает, что за лого на экране? Это Hyperledger. Это проект, который разрабатывается под эгидой The Linux Foundation, в него входит набор блокчейн-технологий. Это реально сила нашего комьюнити открытого кода.
Хаосная инженерия
Так вот, система, которую мы с вами разрабатываем, становится все сложнее, все хаотичнее, все адаптивнее. Netflix — пионеры микросервисных систем. Они были одними из первых, кто это поняли, они разработали набор инструментов, который назвали Simian Army, самым известным из которых стал Chaos Monkey. Он определили то, что стало известно как «принципы хаосной инженерии».
Кстати, в процессе работы над докладом мы даже перевели этот текст на русский язык, так что заходите по линку, читайте, комментируйте, ругайте.
Вкратце принципы хаосной инженерии говорят о следующем. Сложные распределенные системы по сути своей непредсказуемы, и по сути своей в них есть ошибки. Ошибки неизбежны, а это значит, что нам нужно эти ошибки принять и работать с этими системами совершенно по-другому.
Мы должны сами пытаться вносить эти ошибки в наши продакшн системы, чтобы испытывать наши системы на эту самую адаптивность, на эту самую способность к самоорганизации, к выживаемости.
И это меняет всё. Не только то, как мы запускаем систему в продакшн, но и как мы их разрабатываем, как мы их тестируем. Нет никакого процесса стабилизации, замораживания кода, наоборот, есть постоянный процесс дестабилизации. Мы пытаемся убить систему и увидеть, что она продолжает выживать.
Distributed System Integration Protocols
Соответственно, это требует от наших систем, чтобы они тоже как-то поменялись. Для того, чтобы они стали более устойчивы, им нужны некие новые протоколы взаимодействия между их частями. Чтобы эти части могли договариваться и приходить к какой-то самоорганизации. И возникают всякие новые инструменты, новые протоколы, которые я так и называю «протоколы взаимодействия распределенных систем».
О чем я говорю? Во-первых, проект Opentracing. Некая попытка создать общий протокол распределенного отслеживания, который является совершенно незаменимым инструментом для отладки сложных распределенных систем.
Далее — Open Policy Agent. Мы говорим, что мы не можем предсказать то, что произойдет с системой, то есть нам необходимо повысить ее observability, наблюдаемость. Opentracing относится к семье инструментов, которые дают наблюдаемость наших систем. Но наблюдаемость нам нужна для того, чтобы определить, ведет себя система так, как мы от нее ожидаем, или нет. Как нам определить ожидаемое поведение? За счет определения в ней какой-то политики, какого-то свода правил. Проект Open Policy Agent занимается определением этого свода правил по широкому спектру: от доступа до размещения ресурсов.
Как мы сказали, наши системы все более событийно управляемые. Serverless — это замечательный пример событийно управляемых систем. Для того, чтобы мы могли передавать события между системами и отслеживать их, нам нужен некий общий язык, некий общий протокол того, как мы разговариваем о событиях, как мы друг другу их передаем. Этим занимается проект под названием Cloudevents.
Непрерывный поток изменений, который омывает наши системы, постоянно их дестабилизируя, это непрерывный поток программных артефактов. Для того, чтобы мы могли поддерживать этот постоянный поток изменений, нам нужен некий общий протокол, при помощи которого мы сможем разговаривать о том, что такое программный артефакт, как он проверен, какую верификацию он прошел. Этим занимается проект под названием Grafeas. То есть общий протокол метаданных программных артефактов.
И, наконец, если мы хотим, чтобы наши системы были полностью самостоятельные, адаптивные, самоорганизовывались, мы должны дать им право на самоидентификацию. Проект под названием spiffe именно этим и занимается. Это тоже проект под эгидой Cloud Native Computing Foundation.
Все эти проекты молодые, им всем нужна наша любовь, наша проверка. Это все открытый код, наше тестирование, наша имплементация. Они показывают нам, в какую сторону движется технология.
Но DevOps никогда не был в первую очередь о технологии, в первую очередь он всегда был о сотрудничестве между людьми. И, соответственно, если мы хотим, чтобы системы, которые мы разрабатываем, поменялись, то должны поменяться мы сами. На самом деле, мы и так меняемся, у нас нет особенно выбора.
Есть замечательная книга британской писательницы Рэйчел Ботсман, в которой она пишет об эволюции доверия на протяжении человеческой истории. Она говорит, что изначально, в первобытных обществах, доверие было локальным, то есть мы доверяли только тем, кого мы знаем лично.
Дальше был очень долгий период — темное время, когда доверие было централизованно, когда мы стали доверять людям, которых мы не знаем на основании того, что мы с ними принадлежим к одному общественному или государственному институту.
И вот, что мы видим в нашем современном мире: доверие становится все более распределенным и децентрализованным, и основано оно на свободе информационных потоков, на доступности информации.
Если вдуматься, то эту вот самую доступность, которая делает это доверие возможным, мы с вами и осуществляем. Это значит, что должно изменяться и то, как мы сотрудничаем, и то, как мы это делаем, потому что централизованные иерархические IT-организации старого толка перестают работать. Они начинают отмирать.
Основы DevOps-организации
Идеальная DevOps-организация будущего — это децентрализованная, адаптивная система, состоящая из автономных команд, каждая из которых состоит из автономных индивидуумов. Эти команды разбросаны по всему миру, они эффективно сотрудничают друг с другом при помощи асинхронной коммуникации, при помощи высокопрозрачных протоколов обмена информацией. Очень красиво, правда? Очень красивое будущее.
Конечно, это все невозможно без культурных изменений. У нас должны быть трансформационное лидерство, личная ответственность, внутренняя мотивация.
Вот это основа DevOps-организаций: прозрачность информации, асинхронные коммуникации, трансформационное лидерство, децентрализация.
Выгорание
Системы, частью которых мы являемся, и те, которые мы строим, они все более хаотичны, и нам, людям, тяжело справиться с этой мыслью, тяжело отказаться от иллюзии контроля. Мы пытаемся продолжать их контролировать, и это зачастую приводит к выгоранию. Я это говорю на собственном опыте, я тоже обжегся, тоже инвалид непредвиденных сбоев в продакшне.
Выгорание происходит тогда, когда мы пытаемся контролировать то, что контролю по сути своей не поддается. Когда мы выгораем, то все теряет смысл, потому что мы теряем желание делать что-то новое, мы встаем в защитную позицию и начинаем защищать то, что есть.
Инженерная профессия, как я часто люблю себе напоминать, это в первую очередь творческая профессия. Если мы теряем желание что-то создавать, то мы превращаемся в пепел, превращаемся в золу. Выгорают люди, выгорают целые организации.
На мой взгляд, только принятие созидательной силы хаоса, только построение сотрудничества по его принципам — это то, что поможет нам не растерять то хорошее, что есть в нашей профессии.
Чего я вам и желаю: любить свою работу, любить то, что мы делаем. Этот мир кормится информацией, нам досталась честь его кормить. Так что давайте изучать хаос, будем хаосологами, будем приносить ценность, создавать что-то новое, ну, а проблемы, как мы уже выяснили, неизбежны, и когда они появятся, то мы скажем просто «Ops!», и проблема решена.
Что кроме Chaos Monkey?
На самом деле, все эти инструменты, они такие молодые. Те же Netflix строили инструменты под себя. Стройте инструменты под себя. Читайте принципы хаосной инженерии и соответствуйте этим принципам, а не старайтесь искать другие инструменты, которые кто-то другой уже построил.
Пытайтесь понять, как ваши системы ломаются и начинайте их ломать и смотреть, как они выдерживают удары. Это в первую очередь. А инструменты можно поискать. Всякие есть проекты.
Я не совсем понял момент, когда вы говорили про то, что систему нельзя упрощать, упрощая ее компоненты, и сразу же перешли к микросервисам, которые как раз упрощают систему упрощением самих компонентов и усложняя взаимодействия. Это по сути две части, противоречащие друг другу.
Совершенно верно, микросервисы — очень противоречивая тема вообще. На самом деле, упрощение частей повышает гибкость. Что микросервисы дают? Они дают нам гибкость и скорость, но простоты они нам уж точно не дают никак. Они повышают сложность.
То есть в философии DevOps микросервисы — это не такое уж и благо?
У любого блага есть изнанка. Есть благо: это повышает гибкость, дает нам возможность вносить изменения быстрее, но повышает сложность и, соответственно, хрупкость всей системы.
Все-таки на что больше упор: на упрощение взаимодействия или на упрощение частей?
Упор, несомненно, на упрощение взаимодействия, потому что если мы смотрим на это с точки зрения того, как мы с вами работаем, то, в первую очередь, нужно обращать внимание на упрощение взаимодействий, а не на упрощение работы каждого из нас отдельно. Потому что упрощение работы — это превращение в роботов. Вот в Макдональдсе это нормально работает, когда у тебя предписано: здесь бургер положил, здесь на него соус налил. Это в нашей творческой работе не работает совершенно.
Правда ли, что все, что вы рассказали, живет в мире без конкуренции, и хаос там такой добрый, и нет противоречий внутри этого хаоса, никто никого не хочет съесть, убить? Как конкуренция и DevOps должны жить?
Ну, это смотря о какой конкуренции мы говорим. О конкуренции на рабочем месте или о конкуренции между компаниями?
О конкуренции сервисов, которые существуют, потому что сервисы — это не несколько компаний. Мы создаем новый тип информационной среды, и любая среда не может жить без конкуренции. Везде есть конкуренция.
Те же самые Netflix, берем их за ролевую модель. Они это придумали почему? Потому что им нужно было быть конкурентоспособными. Вот эта гибкость и скорость движения, она является именно тем самым конкурентным требованием, она вносит хаотичность в наши системы. То есть хаос — это не то, что мы сознательно делаем, потому что мы его хотим, это то, что происходит из-за того, что этого требует мир. Нам просто приходится адаптироваться. И хаос, он как раз — результат конкуренции.
Это значит, хаос это отсутствие целей как бы? Или те цели, которые мы не хотим видеть? Мы в домике и не понимаем целей других. Конкуренция, на самом деле, она за счет того, что у нас четкие цели, и мы знаем, куда придем в каждый следующий момент времени. В этом, с моей точки зрения, суть DevOps.
Тоже взгляд на вопрос. Я думаю, что цель у нас всех одна: выживать и делать это с
наибольшим удовольствием. И конкурентная цель у любой организации такая же. Выживание происходит зачастую в конкурентной борьбе, тут уж ничего не поделаешь.
В этом году конференция DevOpsDays Moscow пройдет 7 декабря в «Технополисе». До 11 ноября мы принимаем заявки на доклады. Напишите нам, если вы хотите выступить.
Регистрация для участников открыта, билет стоит 7000 рублей. Присоединяйтесь!




