
Kubernetes — это отличный инструмент для запуска контейнеров Docker в кластеризованной производственной среде. Однако существуют задачи, которые Kubernetes решить не в состоянии. При частом развертывании в рабочей среде мы нуждаемся в полностью автоматизированном Blue/Green deployment, чтобы избежать простоев в данном процессе, при котором также необходимо обрабатывать внешние HTTP-запросы и выполнять выгрузку SSL. Это требует интеграции с балансировщиком нагрузки, таким как ha-proxy. Другой задачей является полуавтоматическое масштабирование самого кластера Kubernetes при работе в облачной среде, например, частичное уменьшение масштаба кластера в ночное время.
Хотя Kubernetes не обладает этими функциями прямо «из коробки», он предоставляет API, которым можно воспользоваться для решения подобных задач. Инструменты для автоматизированного Blue/Green развертывания и масштабирования кластера Kubernetes были разработаны в рамках проекта Cloud RTI, который создавался на основе open-source.
В этой статье, расшифровке видео, рассказывается, как настроить Kubernetes вместе с другими компонентами с открытым исходным кодом для получения готовой к производству среды, которая без простоев в продакшене воспринимает код из коммита изменений git commit.

Сегодня мы поговорим о Kubernetes, в частности, о его автоматизации. Мы немного рассмотрим основы этой системы, а затем перейдем к тому, как встраивать Kubernetes в проекты на стадии разработки. Меня зовут Пол, я из Нидерландов, работаю в компании под названием Luminis Technologies и являюсь автором книг «Конструирование облачных приложений с OSGi» и «Модулирование Java 9». То, о чем я буду говорить, сильно отличается от темы этих книг.
В последний год большая часть моего времени была затрачена на работу над инфраструктурной платформой на базе Kubernetes и создание для нее инструментов, преимущественно на Golang. Кроме того, я все еще продолжаю работать над книгой по Java 9. Мое хобби – тяжелая атлетика. Итак, давайте перейдем к делу.
Почему нужно озаботиться Kubernetes? В первую очередь, потому, что он позволяет запускать Docker в кластерах. Если вы не используете Docker, то вы не в теме. Если вы работаете с Docker, то знаете, что он в основном предназначен для запуска контейнеров на вашей собственной машине. Он улучшает работу со множеством сетей, однако все это ограничено одной машиной, поэтому нет никакой возможности запускать контейнеры в кластере.

Создатели Docker постоянно расширяют его возможности, однако если вам действительно нужно запускать контейнеры в продакшене, вам понадобится что-то на подобии Kubernetes, потому что Docker с его командной строкой в этом не поможет.
Поговорим об основах Kubernetes. Прежде чем мы рассмотрим использование API для автоматизации, необходимо понять концепцию работы этой платформы. Типичный кластер включает в себя следующие элементы. Мастер-нод осуществляет управление и контроль работы всего кластера и решает, где будут запланированы контейнеры и каким образом они будут запущены. Он запускает API-сервер, который является важнейшим элементом работы платформы, позже мы подробно рассмотрим этот вопрос.
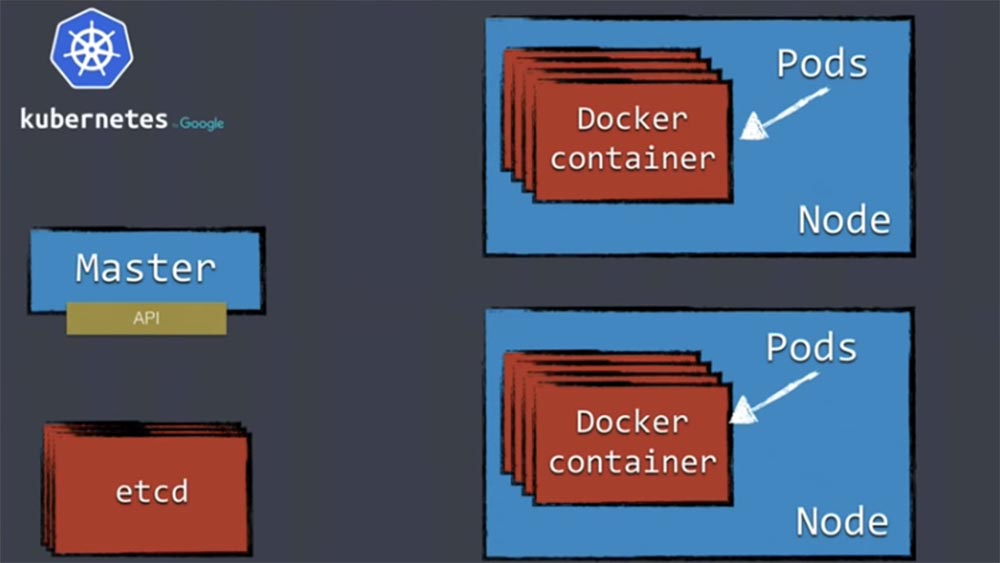
Здесь имеется целая куча рабочих узлов Node, в которых содержаться поды Pods с контейнерами Docker, и распределенное хранилище etcd. Узлы – это место, где будут запускаться ваши контейнеры. Kubernetes не работает с контейнерами Docker непосредственно, а использует для этого абстракцию под названием Pod. Рабочие ноды запускают кучу контейнеров, а Master-node заботится о том, чтобы они работали. Кроме того, здесь имеется распределенное хранилище etcd типа «ключ-значение», в котором хранится вся информация о кластере. Etcd является отказоустойчивым, так что по крайней мере состоит из 3 независимых нодов. Это обеспечивает работу мастера без потери состояния.
После запуска Kubernetes со всеми вышеупомянутыми компонентами начинается развертывание контейнеров scheduling. Развертывание означает, что контейнеры начинают работу в кластере. Для выполнения этой работы в первую очередь вам нужен объект под названием Replication Controller, запускаемый на мастер-сервере, который позволяет создать и отслеживать состояние нескольких экземпляров подов.
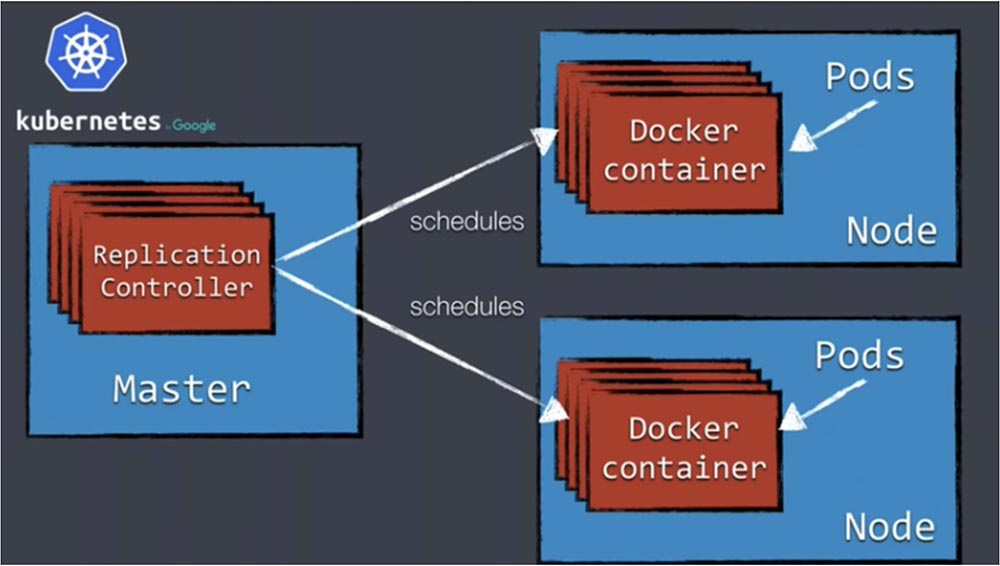
Чтобы настроить контроллер репликации на создание, например, 5 реплик контейнеров в пяти различных рабочих узлах, нужно располагать таким количеством узлов. Кроме того, что контроллер начинает работу этих контейнеров, он отслеживает их состояние. Если из-за нехватки памяти один из контейнеров выйдет из строя, контроллер зафиксирует уменьшение количества с 5 до 4 и запустит новый контейнер на одном из доступных узлов. Это означает, что при работе Kubernetes вы не запускаете контейнеры на каких-то конкретных узлах, а задаете требуемое состояние — настраиваете платформу на развертывание 5 контейнеров и передаете управление контроллеру репликации, который заботится о том, чтобы поддерживать это состояние. Так что Replication Controller является очень важным концептом.
Как я сказал, Kubernetes не работает с контейнерами напрямую. Он делает это через Pod – абстракцию на вершине контейнеров. Важно, что Kubernetes оперирует не только Docker-контейнерами, но и, например, его альтернативой – контейнерами rkt. Это не официальная поддержка, потому что если посмотреть техническую документацию Kubernetes, в ней говорится только о контейнерах Docker. Однако по мере развития платформы в нее добавляется совместимость с контейнерами других форматов.
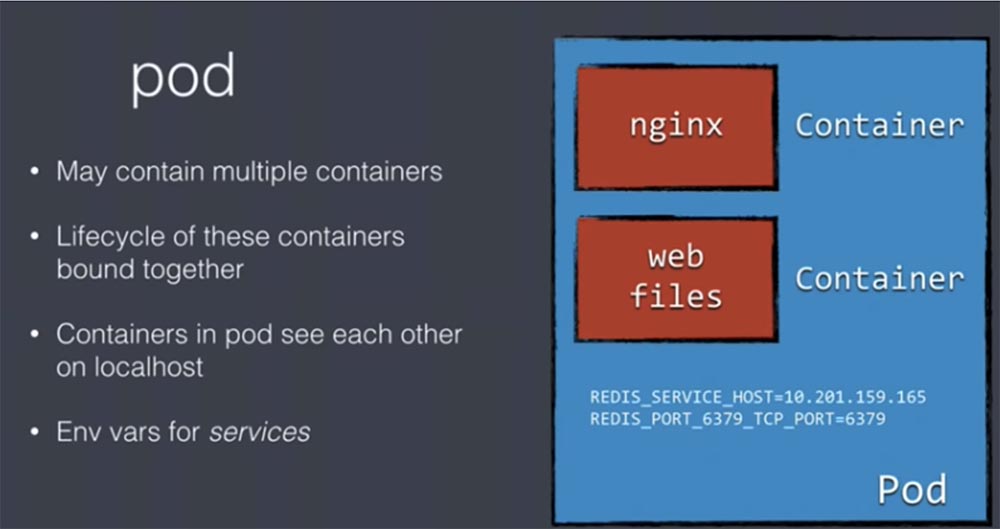
Каждый под может содержать множество контейнеров с одинаковым циклом жизни. Это означает, что мы не сможем запускать в одном поде контейнеры различного назначения, потому что все они могут существовать только в один и тот же период времени. Они запускаются одновременно и одновременно прекращают свою работу. Так что если вы работаете с микросервисами, то не сможете поместить их все в один и тот же под. Контейнеры внутри пода «видят» друг друга на локальном хосте.
Если вы, к примеру, разворачиваете веб-сервис, то pod для этого приложения будет содержать контейнер nginx, причем nginx не модифицированный, а прямо «из коробки». Для того, чтобы этот nginx заработал, мы должны будем добавить свои собственные HTML-файлы и поместить их в отдельный контейнер веб-файлов. Оба эти контейнера помещаются в один общий под и начинают работать совместно, как если бы существовали на одной физической машине, поэтому они видят файлы одной и той же файловой системы, размещенные на одном и том же локальном хосте. Службы services, обеспечивающих взаимодействие компонентов кластера, работают при помощи переменных среды env vars.
Следующее, что обеспечивает под – это сетевое взаимодействие networking. Если вы запускаете несколько контейнеров на одной физической машине, которая также может размещаться в облаке, и все эти контейнеры используют порты, например, мы используем 3 приложения Java, которые работают с одним и тем же портом 8080, то это чревато конфликтом. Чтобы его избежать, вам понадобится разметка портов port mapping, что значительно осложнит процесс развертывания приложений.

Поэтому было бы прекрасно, если бы каждый запускаемый контейнер имел свой собственный виртуальный IP-адрес с доступом ко всем доступным портам, не задумываясь об их возможном конфликте. Это именно то, что обеспечивает Kubernetes.
Каждый раз, создавая pod, он создает для него собственный виртуальный IP-адрес. Порты не делятся между остальными подами, поэтому никакого конфликта не наблюдается. Единственная вещь, работающая по этому IP-адресу – это то, что делает данный контейнер. Это все упрощает.
Однако при этом возникает новая проблема: если ваш виртуальный IP-адрес меняется каждый раз при перезапуске контейнеров, что нередко случается, то как же вы сможете использовать эти контейнеры? Предположим, у нас есть 2 разных пода, которые связываются друг с другом, однако их IP-адреса все время меняются. Для решения этой проблемы Kubernetes использует концепт под названием services. Эти сервисы настраивают прокси на вершине ваших подов и продолжают использовать виртуальные IP-адреса определенного диапазона, но это фиксированные адреса, которые не меняются все время.
Поэтому когда поды хотят связаться друг с другом, они делают это не напрямую, а через services, используя эти фиксированные IP-адреса.
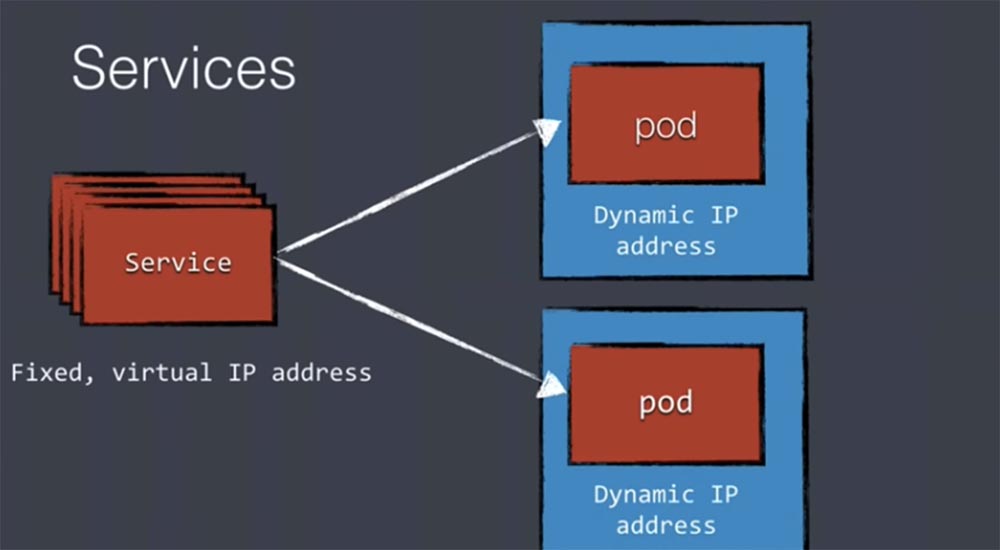
Эти services организуют трафик всех реплик, которым обмениваются между собой компоненты кластера. Поэтому services очень важны для обеспечения коммуникации между компонентами.
Концепция Services значительно облегчает мультикомпонентный процесс развертывания, когда несколько компонентов являются частью более крупного приложения, относящегося, например, к архитектуре микросервисов, хотя лично я не люблю иметь дело с микросервисами.

Каждый имеющийся у вас компонент может быть развернут как отдельный под со своим собственным жизненным циклом. Они не зависят друг от друга и имеют отдельные пространства имен, свои собственные IP-адреса и диапазоны номеров портов, могут независимо обновляться и масштабироваться. Использование services значительно облегчает межкомпонентную коммуникацию. На следующем слайде приведен пример приложения из нескольких компонентов.
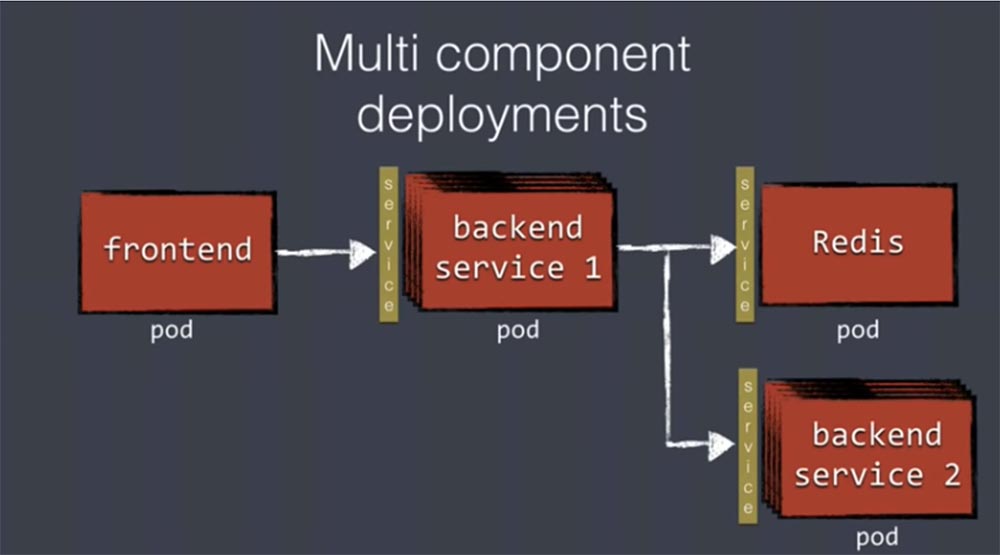
Первый под Frontend представляет собой интерфейс пользователя, который использует несколько бэкенд-сервисов, или реплик бэкенд-сервисов. Вы видите пачку из нескольких таких подов, для взаимодействия с которыми в качестве прокси используются службы services. Вас не должна заботить работоспособность каждого пода, потому что при выходе из строя одного из них Kubernetes автоматически перезапустит новый. Бэкенд-сервис использует ряд других служб, расположенных в разных подах, и все они используют для взаимодействия концепцию services. Все это отлично работает, так что если вы используете такую архитектуру, Kubernetes легко обеспечит ее развертывание. Если архитектура построена по другому принципу, у вас могут быть проблемы.
Следующая важная концепция, с которой нужно познакомиться, это пространство имен Namespaces.
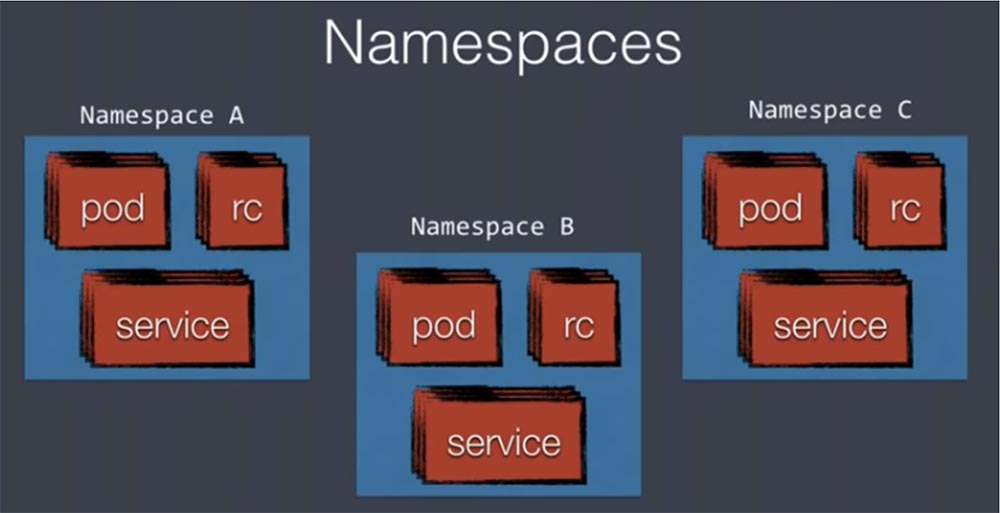
Это изолированные пространства внутри Kubernetes, в которых содержася поды, контроллеры репликации и сервисы. Изоляция означает, например, что когда среда разработки находится в одном пространстве имен, а продакшн – в другом, вы используете services с одинаковым именем для предотвращения конфликта между разными пространствами имен. Таким образом можно легко расположить разные среды в одном физическом кластере Kubernetes.
Развертывание приложения является необходимым шагом перед выпуском приложения в продакшн. В документации Kubernetes указано, что для осуществления развертывания необходимо использовать инструмент командной строки kubectl. Этот инструмент постоянно совершенствуется и прекрасно подходит для развертывания чего-либо.

Вы видите файлы конфигурации yaml, которые необходимо создать для API с помощью команды kubectl. На следующем слайде показано, как выглядит типичный yaml-файл.

В данном файле мы задаем контроллер репликации. Первой важной частью является строка с количеством реплик, которыми мы хотим располагать, replicas:3. Это количество равно числу узлов, которые нужно задействовать. В данном случае число 3 означает, что мы хотим запустить поды на 3 различных машинах нашего кластера. Контроллер репликации проводит мониторинг состояния системы и при необходимости автоматически перезапускает поды, чтобы обеспечить постоянную работу заданного количества реплик.
В нижней части кода расположены строки, представляющие собой спецификацию пода. Здесь описываются порты, узлы хранилищ, имя и образ веб-сервера и прочая информация, необходимая для нашего Docker-контейнера.
Наконец, здесь имеется целая куча метаданных, таких как метки labels. Метки представляют собой пары «ключ-значение» и добавляются к объектам, как поды. Они используются для группировки и выбора подмножеств объектов. Они очень важны для организации API- взаимодействия, связывая вместе контроллеры, поды и сервисы.
Под не знает, какой контроллер репликации его создал, а контролер репликации не знает список подов, которые создает. Но и поды, и контроллер имеют метки, совпадение которых указывает, что конкретный под принадлежит конкретному контроллеру. Это достаточно слабая, но гибкая связь, которая обеспечивает устойчивую работу API и автоматизированных вещей.
Сейчас вы увидите короткое демо, в котором показана работа kubectl, а далее мы углубимся в работу балансировщика нагрузки и использование API. Итак, я ввожу команду kubectl get pods, но система не показывает никаких подов, потому что мы еще ничего не запустили. Далее я ввожу команду ls, чтобы просмотреть список имеющихся файлов.

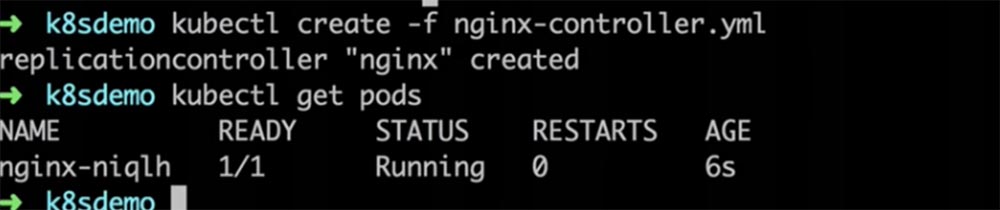
Теперь я ввожу название первого файла из списка и на экран выводится конфигурационный yaml-файл, похожий на тот, который мы только что рассмотрели. Давайте используем этот файл для создания пода, введя команду kubectl create –f nginx-controller.yaml. В результате у нас будет создан под. Повторив команду kubectl get pods можно увидеть, что этот под работает.
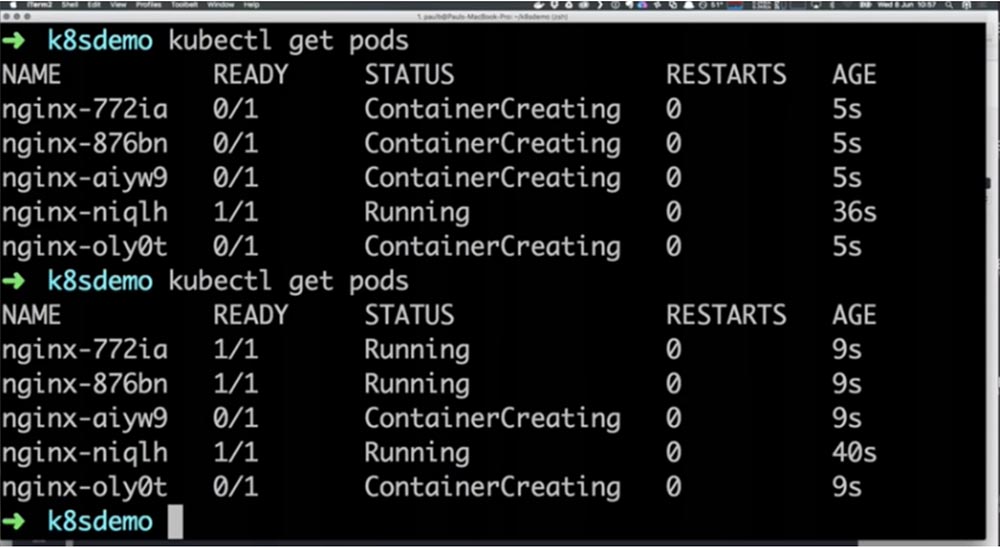
Но это всего лишь один под. Давайте попробуем масштабировать наш контроллер, создав несколько реплик. Для этого я ввожу команду kubectl scale rc nginx – replicas=5, где rc – это контроллер репликации, а 5 – необходимое количество экземпляров, или реплик этого контроллера. Вы видите ход создания контейнеров, и если повторить ввод команды kubectl get pods через пару секунд, видно, что большинство созданных контейнеров уже начали работать.
Таким образом мы увеличили количество подов, или реплик, работающих в нашем кластере, до 5 экземпляров. Также, к примеру, можно взглянуть на IP-адрес, созданный для первой реплики, введя команду kubectl describe pod nginx-772ia. Это виртуальный IP-адрес, который присоединен к данному конкретному контейнеру.

Его работа будет обеспечена упомянутыми выше службами services. Давайте посмотрим, что произойдет, если уничтожить одну из работающих реплик, ведь у нас в любом случае должна быть обеспечена работа заданного количества экземпляров. Я ввожу команду kubectl delete pod nginx-772ia и система сообщает, что под с таким идентификатором был удален. Использовав команду kubectl get pods, мы видим, что у нас снова работает 5 экземпляров контроллера, а вместо удаленной реплики nginx-772ia появилась новая с идентификатором nginx-sunfn.
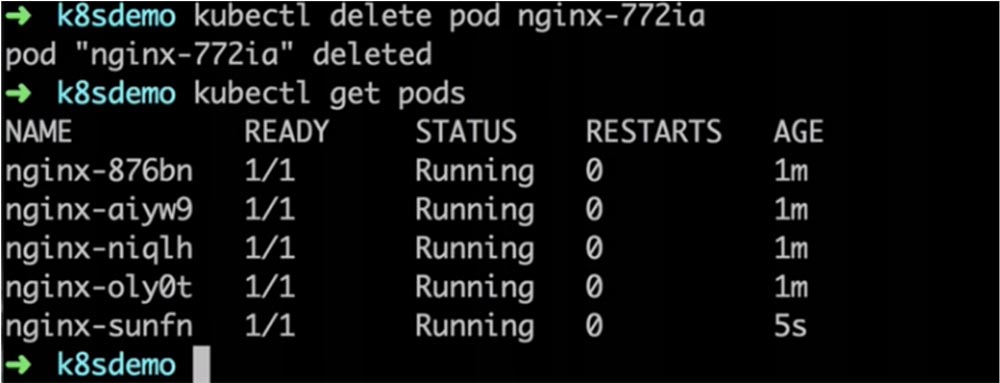
Это произошло потому, что Kubernetes заметил выход из строя одной из реплик. В реальности это была не случайная неполадка, а осознанное действие, постольку я собственноручно ее удалил. Но поскольку число реплик, заданное конфигурацией кластера, осталось неизменным, контроллер репликации отметил исчезновение одного из экземпляров и тут же восстановил требуемое состояние кластера созданием и запуском нового контейнера с новым ID. Конечно, это глупый пример, когда я сам удаляю реплику и жду, что контроллер ее восстановит, но аналогичные ситуации происходят в реальной жизни вследствие сбоя контейнера, например, из-за нехватки памяти. В этом случае контроллер также перезапустит под.
Если у нас имеется несколько продакш-сценариев, в которых приложение Java неправильно настроено, например, установлено недостаточное количество памяти, это может вызвать сбой как через несколько часов, так и спустя недели после запуска программы. В таких случаях Kubernetes позаботиться о том, чтобы рабочий процесс не прерывался.
Еще раз напомню, что все вышесказанное не применимо на этапе продакшн, когда для обеспечения работы продукта вы не должны использовать командную строку kubectl и прочие вещи, вводимые с клавиатуры. Так что перед тем, как мы приступим к автоматизации развертывания, нужно решить еще одну большую проблему. Предположим, у меня прямо сейчас работает контейнер nginx, но я не имею к нему доступа из «внешнего мира». Однако если это веб-приложение, то я могу получить к нему доступ через интернет. Для обеспечения стабильности этого процесса используется балансировщик нагрузки, который располагается перед кластером.
Нам нужно получить возможность управлять сервисами Kubernetes из внешнего мира, причем эта возможность не поддерживается автоматически «прямо из коробки». К примеру, для обеспечения HTTP-балансировки нужно использовать SSL offloading, или выгрузку SSL. Это процесс удаления шифрования на основе SSL из входящего трафика, который получает веб-сервер, выполняемый для того, чтобы освободить сервер от расшифровки данных. Для балансировки трафика можно использовать также Gzip-сжатие веб-страниц.
В последних версиях Kubernetes, например, 1.02, имеется новая функция под названием Ingress. Она служит для конфигурирования балансировщика нагрузки. Это новая концепция в API, при которой вы можете написать плагин, который настроит любой используемый вами внешний балансировщик нагрузки.

К сожалению, на сегодня эта концепция не доработана до конца и предлагается в альфа-версии. Можно продемонстрировать, как она будет работать в будущем, однако это не будет соответствовать тому, как она работает сегодня. Я использую балансировщик, предоставляемый Google Cloud Engine, однако если вы не работаете с этим сервисом, вам придется что-нибудь сделать самим, по крайней мере, в данный момент. В будущем, вероятно, через месяц, это станет намного легче – для балансировки трафика можно будет использовать функцию ingress.
На сегодня эта проблема решается созданием пользовательского балансировщика трафика. В первую очередь можно использовать ha-прокси, расположенный перед кластером Kubernetes. Он работает снаружи кластера на внешней машине или наборе машин. Далее необходимо предусмотреть автоматическое динамическое конфигурирование ha-прокси, чтобы не настраивать его вручную при создании каждого нового пода. Аналогичную работу необходимо выполнить для nginx, Apache и других серверов, и при этом ha-прокси выступает легко интегрируемым инструментом.
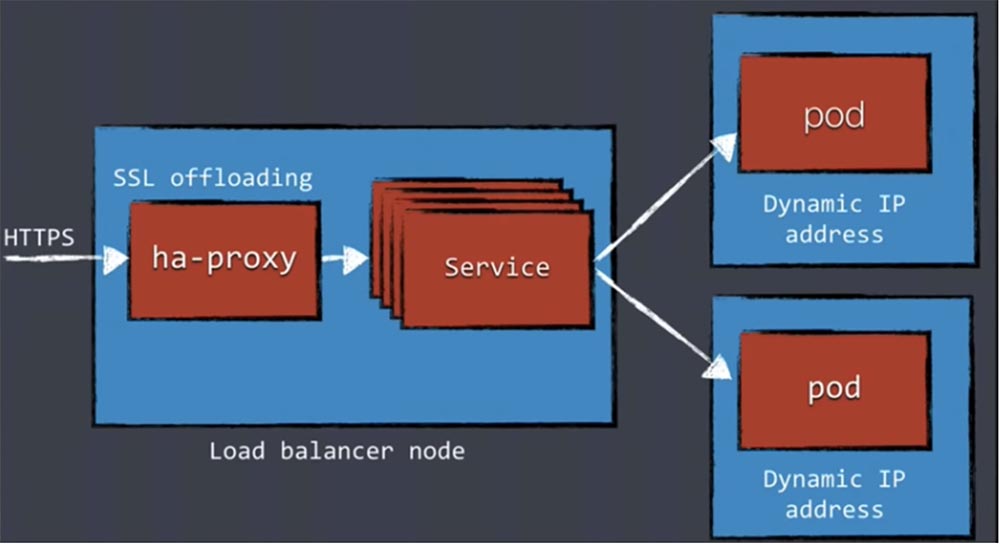
На следующем слайде показано, как узел балансировщика нагрузки обрабатывает входящий HTTPS-трафик, причем ha-прокси расположен на внешней машине или кластере машин, расположенном за пределами кластера Kubernetes. Здесь же располагается выгрузка SSL. Прокси определяет запрашиваемые адреса и затем передает трафик сервисам Kubernetes, не интересуясь тем, что IP-адреса подов могут меняться с течением времени. Далее services передают трафик работающим подам с динамическими IP-адресами.
Если вы применяете сервис AWS, можно использовать концепцию балансировщика нагрузки ELB. Elastic Load Balancing перенаправляет трафик на исправные инстансы Amazon, обеспечивая стабильность работы приложений. Этот механизм особенно хорош, если вам нужна масштабируемость балансировщика нагрузки.
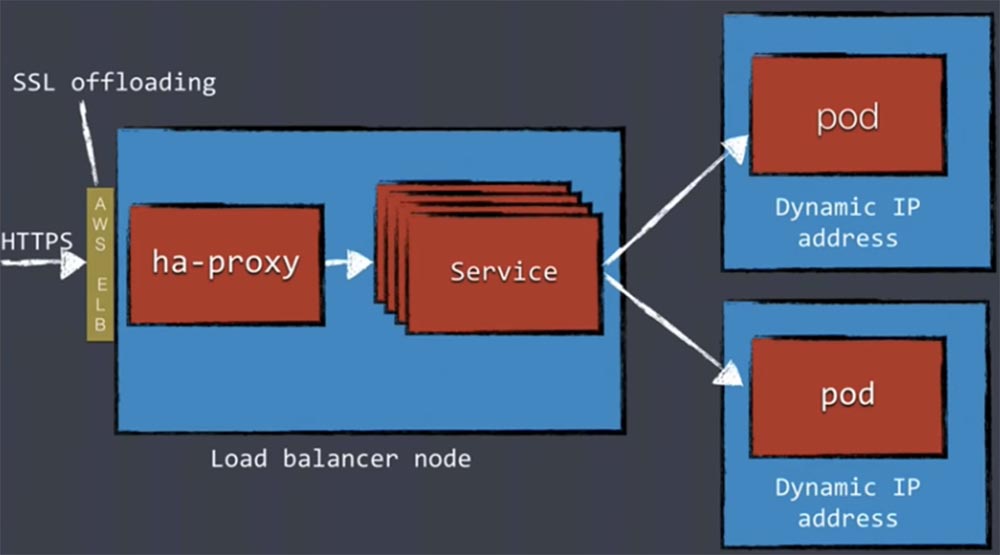
В этом случае трафик сначала направляется на сервис AWS, где и происходит выгрузка SSL, после чего он поступает в узел балансировщика нагрузки ha-прокси.
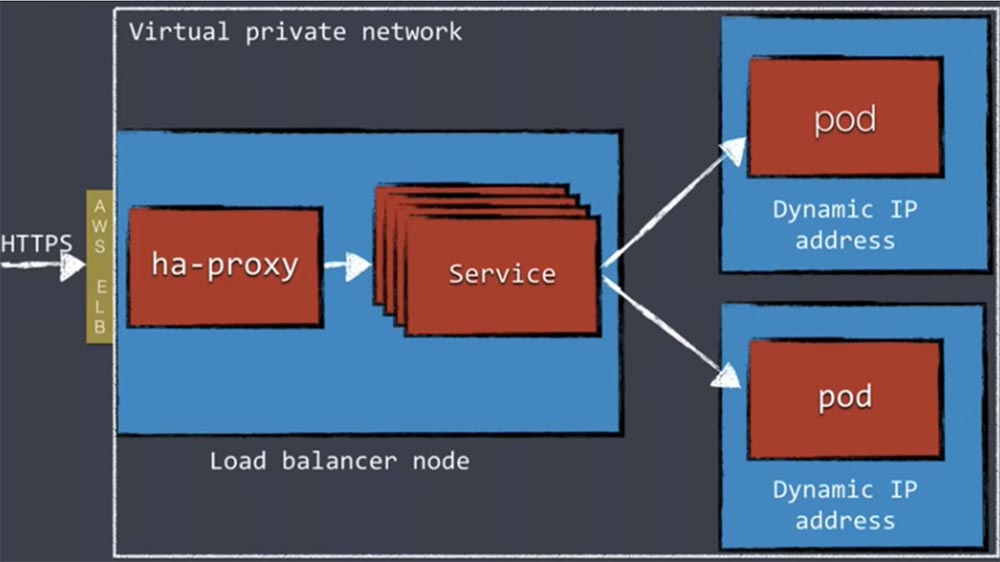
Аналогично можно поступить, если ваши кластеры полностью находятся внутри частной виртуальной сети VPN. В данном случае использование AWS ELB полностью обеспечивает безопасность системы. Вам не нужно осуществлять SSL между различными компонентами за пределами кластера. Единственная вещь, которая будет связана с внешним миром, это наш ha-прокси.
Концептуально это выглядит достаточно просто, но как оно работает в реальности? Как нужно настроить ha-прокси, чтобы он знал о сервисах Kubernetes? Если взглянуть на ha-прокси так же, как мы рассматриваем nginx, можно заметить, что он до сих пор использует статичные файлы конфигурации. Так что если вы хотите добавить к нему новый бэкенд, которым в данном случае являются наши сервисы Kubernetes, нам потребуется изменить файл конфигурации, перегрузить ha-proxy и только после этого все заработает как надо. Разумеется, что мы не хотим выполнять это вручную. Поэтому можно использовать маленький open-source инструмент под названием Confd, который управляет файлами конфигурации локальных приложений с помощью данных etcd. Если в хранилище метаданных etcd происходят изменения, Confd автоматически генерирует конфигурационный шаблон, который перенастраивает ha-прокси в соответствии с новыми условиями работы.
Может показаться, что такой подход требует дополнительных усилий, однако это очень простой инструмент, работающий с шаблонами, поэтому его использование довольно тривиальная задача.
26:00 мин
Продолжение будет совсем скоро…
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Хотя Kubernetes не обладает этими функциями прямо «из коробки», он предоставляет API, которым можно воспользоваться для решения подобных задач. Инструменты для автоматизированного Blue/Green развертывания и масштабирования кластера Kubernetes были разработаны в рамках проекта Cloud RTI, который создавался на основе open-source.
В этой статье, расшифровке видео, рассказывается, как настроить Kubernetes вместе с другими компонентами с открытым исходным кодом для получения готовой к производству среды, которая без простоев в продакшене воспринимает код из коммита изменений git commit.
Сегодня мы поговорим о Kubernetes, в частности, о его автоматизации. Мы немного рассмотрим основы этой системы, а затем перейдем к тому, как встраивать Kubernetes в проекты на стадии разработки. Меня зовут Пол, я из Нидерландов, работаю в компании под названием Luminis Technologies и являюсь автором книг «Конструирование облачных приложений с OSGi» и «Модулирование Java 9». То, о чем я буду говорить, сильно отличается от темы этих книг.
В последний год большая часть моего времени была затрачена на работу над инфраструктурной платформой на базе Kubernetes и создание для нее инструментов, преимущественно на Golang. Кроме того, я все еще продолжаю работать над книгой по Java 9. Мое хобби – тяжелая атлетика. Итак, давайте перейдем к делу.
Почему нужно озаботиться Kubernetes? В первую очередь, потому, что он позволяет запускать Docker в кластерах. Если вы не используете Docker, то вы не в теме. Если вы работаете с Docker, то знаете, что он в основном предназначен для запуска контейнеров на вашей собственной машине. Он улучшает работу со множеством сетей, однако все это ограничено одной машиной, поэтому нет никакой возможности запускать контейнеры в кластере.
Создатели Docker постоянно расширяют его возможности, однако если вам действительно нужно запускать контейнеры в продакшене, вам понадобится что-то на подобии Kubernetes, потому что Docker с его командной строкой в этом не поможет.
Поговорим об основах Kubernetes. Прежде чем мы рассмотрим использование API для автоматизации, необходимо понять концепцию работы этой платформы. Типичный кластер включает в себя следующие элементы. Мастер-нод осуществляет управление и контроль работы всего кластера и решает, где будут запланированы контейнеры и каким образом они будут запущены. Он запускает API-сервер, который является важнейшим элементом работы платформы, позже мы подробно рассмотрим этот вопрос.
Здесь имеется целая куча рабочих узлов Node, в которых содержаться поды Pods с контейнерами Docker, и распределенное хранилище etcd. Узлы – это место, где будут запускаться ваши контейнеры. Kubernetes не работает с контейнерами Docker непосредственно, а использует для этого абстракцию под названием Pod. Рабочие ноды запускают кучу контейнеров, а Master-node заботится о том, чтобы они работали. Кроме того, здесь имеется распределенное хранилище etcd типа «ключ-значение», в котором хранится вся информация о кластере. Etcd является отказоустойчивым, так что по крайней мере состоит из 3 независимых нодов. Это обеспечивает работу мастера без потери состояния.
После запуска Kubernetes со всеми вышеупомянутыми компонентами начинается развертывание контейнеров scheduling. Развертывание означает, что контейнеры начинают работу в кластере. Для выполнения этой работы в первую очередь вам нужен объект под названием Replication Controller, запускаемый на мастер-сервере, который позволяет создать и отслеживать состояние нескольких экземпляров подов.
Чтобы настроить контроллер репликации на создание, например, 5 реплик контейнеров в пяти различных рабочих узлах, нужно располагать таким количеством узлов. Кроме того, что контроллер начинает работу этих контейнеров, он отслеживает их состояние. Если из-за нехватки памяти один из контейнеров выйдет из строя, контроллер зафиксирует уменьшение количества с 5 до 4 и запустит новый контейнер на одном из доступных узлов. Это означает, что при работе Kubernetes вы не запускаете контейнеры на каких-то конкретных узлах, а задаете требуемое состояние — настраиваете платформу на развертывание 5 контейнеров и передаете управление контроллеру репликации, который заботится о том, чтобы поддерживать это состояние. Так что Replication Controller является очень важным концептом.
Как я сказал, Kubernetes не работает с контейнерами напрямую. Он делает это через Pod – абстракцию на вершине контейнеров. Важно, что Kubernetes оперирует не только Docker-контейнерами, но и, например, его альтернативой – контейнерами rkt. Это не официальная поддержка, потому что если посмотреть техническую документацию Kubernetes, в ней говорится только о контейнерах Docker. Однако по мере развития платформы в нее добавляется совместимость с контейнерами других форматов.
Каждый под может содержать множество контейнеров с одинаковым циклом жизни. Это означает, что мы не сможем запускать в одном поде контейнеры различного назначения, потому что все они могут существовать только в один и тот же период времени. Они запускаются одновременно и одновременно прекращают свою работу. Так что если вы работаете с микросервисами, то не сможете поместить их все в один и тот же под. Контейнеры внутри пода «видят» друг друга на локальном хосте.
Если вы, к примеру, разворачиваете веб-сервис, то pod для этого приложения будет содержать контейнер nginx, причем nginx не модифицированный, а прямо «из коробки». Для того, чтобы этот nginx заработал, мы должны будем добавить свои собственные HTML-файлы и поместить их в отдельный контейнер веб-файлов. Оба эти контейнера помещаются в один общий под и начинают работать совместно, как если бы существовали на одной физической машине, поэтому они видят файлы одной и той же файловой системы, размещенные на одном и том же локальном хосте. Службы services, обеспечивающих взаимодействие компонентов кластера, работают при помощи переменных среды env vars.
Следующее, что обеспечивает под – это сетевое взаимодействие networking. Если вы запускаете несколько контейнеров на одной физической машине, которая также может размещаться в облаке, и все эти контейнеры используют порты, например, мы используем 3 приложения Java, которые работают с одним и тем же портом 8080, то это чревато конфликтом. Чтобы его избежать, вам понадобится разметка портов port mapping, что значительно осложнит процесс развертывания приложений.
Поэтому было бы прекрасно, если бы каждый запускаемый контейнер имел свой собственный виртуальный IP-адрес с доступом ко всем доступным портам, не задумываясь об их возможном конфликте. Это именно то, что обеспечивает Kubernetes.
Каждый раз, создавая pod, он создает для него собственный виртуальный IP-адрес. Порты не делятся между остальными подами, поэтому никакого конфликта не наблюдается. Единственная вещь, работающая по этому IP-адресу – это то, что делает данный контейнер. Это все упрощает.
Однако при этом возникает новая проблема: если ваш виртуальный IP-адрес меняется каждый раз при перезапуске контейнеров, что нередко случается, то как же вы сможете использовать эти контейнеры? Предположим, у нас есть 2 разных пода, которые связываются друг с другом, однако их IP-адреса все время меняются. Для решения этой проблемы Kubernetes использует концепт под названием services. Эти сервисы настраивают прокси на вершине ваших подов и продолжают использовать виртуальные IP-адреса определенного диапазона, но это фиксированные адреса, которые не меняются все время.
Поэтому когда поды хотят связаться друг с другом, они делают это не напрямую, а через services, используя эти фиксированные IP-адреса.
Эти services организуют трафик всех реплик, которым обмениваются между собой компоненты кластера. Поэтому services очень важны для обеспечения коммуникации между компонентами.
Концепция Services значительно облегчает мультикомпонентный процесс развертывания, когда несколько компонентов являются частью более крупного приложения, относящегося, например, к архитектуре микросервисов, хотя лично я не люблю иметь дело с микросервисами.
Каждый имеющийся у вас компонент может быть развернут как отдельный под со своим собственным жизненным циклом. Они не зависят друг от друга и имеют отдельные пространства имен, свои собственные IP-адреса и диапазоны номеров портов, могут независимо обновляться и масштабироваться. Использование services значительно облегчает межкомпонентную коммуникацию. На следующем слайде приведен пример приложения из нескольких компонентов.
Первый под Frontend представляет собой интерфейс пользователя, который использует несколько бэкенд-сервисов, или реплик бэкенд-сервисов. Вы видите пачку из нескольких таких подов, для взаимодействия с которыми в качестве прокси используются службы services. Вас не должна заботить работоспособность каждого пода, потому что при выходе из строя одного из них Kubernetes автоматически перезапустит новый. Бэкенд-сервис использует ряд других служб, расположенных в разных подах, и все они используют для взаимодействия концепцию services. Все это отлично работает, так что если вы используете такую архитектуру, Kubernetes легко обеспечит ее развертывание. Если архитектура построена по другому принципу, у вас могут быть проблемы.
Следующая важная концепция, с которой нужно познакомиться, это пространство имен Namespaces.
Это изолированные пространства внутри Kubernetes, в которых содержася поды, контроллеры репликации и сервисы. Изоляция означает, например, что когда среда разработки находится в одном пространстве имен, а продакшн – в другом, вы используете services с одинаковым именем для предотвращения конфликта между разными пространствами имен. Таким образом можно легко расположить разные среды в одном физическом кластере Kubernetes.
Развертывание приложения является необходимым шагом перед выпуском приложения в продакшн. В документации Kubernetes указано, что для осуществления развертывания необходимо использовать инструмент командной строки kubectl. Этот инструмент постоянно совершенствуется и прекрасно подходит для развертывания чего-либо.
Вы видите файлы конфигурации yaml, которые необходимо создать для API с помощью команды kubectl. На следующем слайде показано, как выглядит типичный yaml-файл.
В данном файле мы задаем контроллер репликации. Первой важной частью является строка с количеством реплик, которыми мы хотим располагать, replicas:3. Это количество равно числу узлов, которые нужно задействовать. В данном случае число 3 означает, что мы хотим запустить поды на 3 различных машинах нашего кластера. Контроллер репликации проводит мониторинг состояния системы и при необходимости автоматически перезапускает поды, чтобы обеспечить постоянную работу заданного количества реплик.
В нижней части кода расположены строки, представляющие собой спецификацию пода. Здесь описываются порты, узлы хранилищ, имя и образ веб-сервера и прочая информация, необходимая для нашего Docker-контейнера.
Наконец, здесь имеется целая куча метаданных, таких как метки labels. Метки представляют собой пары «ключ-значение» и добавляются к объектам, как поды. Они используются для группировки и выбора подмножеств объектов. Они очень важны для организации API- взаимодействия, связывая вместе контроллеры, поды и сервисы.
Под не знает, какой контроллер репликации его создал, а контролер репликации не знает список подов, которые создает. Но и поды, и контроллер имеют метки, совпадение которых указывает, что конкретный под принадлежит конкретному контроллеру. Это достаточно слабая, но гибкая связь, которая обеспечивает устойчивую работу API и автоматизированных вещей.
Сейчас вы увидите короткое демо, в котором показана работа kubectl, а далее мы углубимся в работу балансировщика нагрузки и использование API. Итак, я ввожу команду kubectl get pods, но система не показывает никаких подов, потому что мы еще ничего не запустили. Далее я ввожу команду ls, чтобы просмотреть список имеющихся файлов.
Теперь я ввожу название первого файла из списка и на экран выводится конфигурационный yaml-файл, похожий на тот, который мы только что рассмотрели. Давайте используем этот файл для создания пода, введя команду kubectl create –f nginx-controller.yaml. В результате у нас будет создан под. Повторив команду kubectl get pods можно увидеть, что этот под работает.
Но это всего лишь один под. Давайте попробуем масштабировать наш контроллер, создав несколько реплик. Для этого я ввожу команду kubectl scale rc nginx – replicas=5, где rc – это контроллер репликации, а 5 – необходимое количество экземпляров, или реплик этого контроллера. Вы видите ход создания контейнеров, и если повторить ввод команды kubectl get pods через пару секунд, видно, что большинство созданных контейнеров уже начали работать.
Таким образом мы увеличили количество подов, или реплик, работающих в нашем кластере, до 5 экземпляров. Также, к примеру, можно взглянуть на IP-адрес, созданный для первой реплики, введя команду kubectl describe pod nginx-772ia. Это виртуальный IP-адрес, который присоединен к данному конкретному контейнеру.
Его работа будет обеспечена упомянутыми выше службами services. Давайте посмотрим, что произойдет, если уничтожить одну из работающих реплик, ведь у нас в любом случае должна быть обеспечена работа заданного количества экземпляров. Я ввожу команду kubectl delete pod nginx-772ia и система сообщает, что под с таким идентификатором был удален. Использовав команду kubectl get pods, мы видим, что у нас снова работает 5 экземпляров контроллера, а вместо удаленной реплики nginx-772ia появилась новая с идентификатором nginx-sunfn.
Это произошло потому, что Kubernetes заметил выход из строя одной из реплик. В реальности это была не случайная неполадка, а осознанное действие, постольку я собственноручно ее удалил. Но поскольку число реплик, заданное конфигурацией кластера, осталось неизменным, контроллер репликации отметил исчезновение одного из экземпляров и тут же восстановил требуемое состояние кластера созданием и запуском нового контейнера с новым ID. Конечно, это глупый пример, когда я сам удаляю реплику и жду, что контроллер ее восстановит, но аналогичные ситуации происходят в реальной жизни вследствие сбоя контейнера, например, из-за нехватки памяти. В этом случае контроллер также перезапустит под.
Если у нас имеется несколько продакш-сценариев, в которых приложение Java неправильно настроено, например, установлено недостаточное количество памяти, это может вызвать сбой как через несколько часов, так и спустя недели после запуска программы. В таких случаях Kubernetes позаботиться о том, чтобы рабочий процесс не прерывался.
Еще раз напомню, что все вышесказанное не применимо на этапе продакшн, когда для обеспечения работы продукта вы не должны использовать командную строку kubectl и прочие вещи, вводимые с клавиатуры. Так что перед тем, как мы приступим к автоматизации развертывания, нужно решить еще одну большую проблему. Предположим, у меня прямо сейчас работает контейнер nginx, но я не имею к нему доступа из «внешнего мира». Однако если это веб-приложение, то я могу получить к нему доступ через интернет. Для обеспечения стабильности этого процесса используется балансировщик нагрузки, который располагается перед кластером.
Нам нужно получить возможность управлять сервисами Kubernetes из внешнего мира, причем эта возможность не поддерживается автоматически «прямо из коробки». К примеру, для обеспечения HTTP-балансировки нужно использовать SSL offloading, или выгрузку SSL. Это процесс удаления шифрования на основе SSL из входящего трафика, который получает веб-сервер, выполняемый для того, чтобы освободить сервер от расшифровки данных. Для балансировки трафика можно использовать также Gzip-сжатие веб-страниц.
В последних версиях Kubernetes, например, 1.02, имеется новая функция под названием Ingress. Она служит для конфигурирования балансировщика нагрузки. Это новая концепция в API, при которой вы можете написать плагин, который настроит любой используемый вами внешний балансировщик нагрузки.
К сожалению, на сегодня эта концепция не доработана до конца и предлагается в альфа-версии. Можно продемонстрировать, как она будет работать в будущем, однако это не будет соответствовать тому, как она работает сегодня. Я использую балансировщик, предоставляемый Google Cloud Engine, однако если вы не работаете с этим сервисом, вам придется что-нибудь сделать самим, по крайней мере, в данный момент. В будущем, вероятно, через месяц, это станет намного легче – для балансировки трафика можно будет использовать функцию ingress.
На сегодня эта проблема решается созданием пользовательского балансировщика трафика. В первую очередь можно использовать ha-прокси, расположенный перед кластером Kubernetes. Он работает снаружи кластера на внешней машине или наборе машин. Далее необходимо предусмотреть автоматическое динамическое конфигурирование ha-прокси, чтобы не настраивать его вручную при создании каждого нового пода. Аналогичную работу необходимо выполнить для nginx, Apache и других серверов, и при этом ha-прокси выступает легко интегрируемым инструментом.
На следующем слайде показано, как узел балансировщика нагрузки обрабатывает входящий HTTPS-трафик, причем ha-прокси расположен на внешней машине или кластере машин, расположенном за пределами кластера Kubernetes. Здесь же располагается выгрузка SSL. Прокси определяет запрашиваемые адреса и затем передает трафик сервисам Kubernetes, не интересуясь тем, что IP-адреса подов могут меняться с течением времени. Далее services передают трафик работающим подам с динамическими IP-адресами.
Если вы применяете сервис AWS, можно использовать концепцию балансировщика нагрузки ELB. Elastic Load Balancing перенаправляет трафик на исправные инстансы Amazon, обеспечивая стабильность работы приложений. Этот механизм особенно хорош, если вам нужна масштабируемость балансировщика нагрузки.
В этом случае трафик сначала направляется на сервис AWS, где и происходит выгрузка SSL, после чего он поступает в узел балансировщика нагрузки ha-прокси.
Аналогично можно поступить, если ваши кластеры полностью находятся внутри частной виртуальной сети VPN. В данном случае использование AWS ELB полностью обеспечивает безопасность системы. Вам не нужно осуществлять SSL между различными компонентами за пределами кластера. Единственная вещь, которая будет связана с внешним миром, это наш ha-прокси.
Концептуально это выглядит достаточно просто, но как оно работает в реальности? Как нужно настроить ha-прокси, чтобы он знал о сервисах Kubernetes? Если взглянуть на ha-прокси так же, как мы рассматриваем nginx, можно заметить, что он до сих пор использует статичные файлы конфигурации. Так что если вы хотите добавить к нему новый бэкенд, которым в данном случае являются наши сервисы Kubernetes, нам потребуется изменить файл конфигурации, перегрузить ha-proxy и только после этого все заработает как надо. Разумеется, что мы не хотим выполнять это вручную. Поэтому можно использовать маленький open-source инструмент под названием Confd, который управляет файлами конфигурации локальных приложений с помощью данных etcd. Если в хранилище метаданных etcd происходят изменения, Confd автоматически генерирует конфигурационный шаблон, который перенастраивает ha-прокси в соответствии с новыми условиями работы.
Может показаться, что такой подход требует дополнительных усилий, однако это очень простой инструмент, работающий с шаблонами, поэтому его использование довольно тривиальная задача.
26:00 мин
Продолжение будет совсем скоро…
Немного рекламы :)
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?



")
