
В Одноклассниках мы регулярно проводим разборы научных конференций и делимся результатами этих разборов. В этот раз хотим поделиться статьями с NeurIPS 2021. NeurIPS – крупнейшая конференция по машинному обучению: в этом году было подано 9000 статей, 2300 из которых попали в основную программу конференции. Охватить такой объем материала сложно, но мы выбрали статьи, которые показались нам самыми интересными, и подготовили для вас их краткое изложение.
Нам помогали ребята из нескольких подразделений VK, и разбор получился слишком длинным для одной статьи на хабре. Поэтому разбор будет состоять из двух статей. Это первая часть, она посвящена рекомендациям.
Вы узнаете:
Как учесть слабые сигналы в нейросетевых рекомендерах (читать);
Как эффективно выбрать эксперта под каждый таргет в модели mixture-of-experts (читать);
Как сделать рекомендации холодного старта для книг, если есть данные о том, какие фильмы нравятся пользователям (читать);
Как измерить эффект эксперимента для всех заинтересованных сторон в маркетплейсе (читать).
Как без онлайн эксперимента оценить эффект от улучшения рекомендаций, когда рекомендации показываются не по одной, а списком (читать).
Примечание. За неимением общепринятого перевода для слова item (как объект рекомендации) в этой статье мы будем употреблять англицизм айтем и склонять его как слово мужского рода.
Curriculum Disentangled Recommendation with Noisy Multi-feedback
ссылка
Автор разбора: Люба Пекша, DS разработчик ВКонтакте (pekshechka)
В большинстве рекомендательных сервисов есть много видов реакции (feedback) пользователей на рекомендации. И помимо очевидно положительной или отрицательной, вроде like и dislike, есть менее очевидные и шумные, например ignore или click. Классно уметь доставать полезный сигнал из этих шумных данных, при этом учитывая, что существуют сложные взаимосвязи между различными видами реакции. Именно эту задачу пытаются решить исследователи из WeChat.
Главной особенностью сферы multi-feedback recommendation является то, что будь у нас достаточное количество данных и вычислительных мощностей, проблем бы не было. Большие и сильные нейросетки получали бы на вход сырые данные и сами бы выучивали способ достать необходимый сигнал наиболее оптимальным образом. Но так как в данных и мощностях мы ограничены, приходится придумывать эвристики и использовать свою интуицию для того, чтобы внедрить в модели нужный inductive bias. Архитектуры из статей обычно представляют из себя нагромождение модулей эвристик, и авторы не утруждают себя сравнением разных подходов в каждом из модулей или объяснением, почему предыдущие подходы хуже. В лучшем случае можно увидеть сравнение бенчмарков с включенным и отключенным модулем, но добавление дополнительных мощностей в модель редко приводит к ухудшению результатов, так что такой подход не совсем честен.
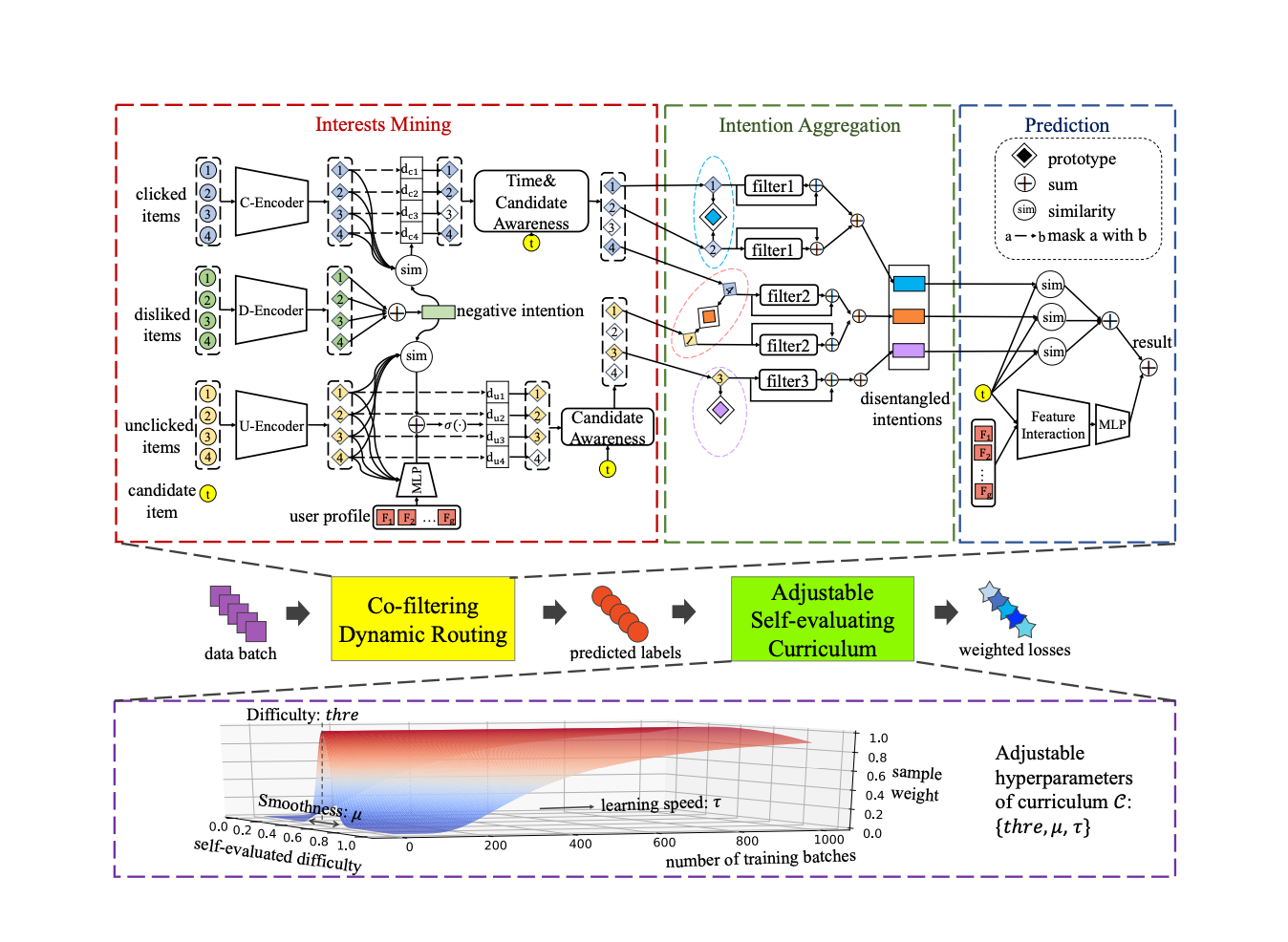
Перейдем к подходу авторов. Он состоит из двух частей: нейросетевой архитектуры и обучения с помощью curriculum learning. Эти две части абсолютно независимы, вы можете использовать любую архитектуру с curriculum или не использовать его с исходной архитектурой, но все равно получить отличные результаты (по бенчмаркам).
Архитектура нейронной сети
Архитектура представляет собой множество эвристик, я не буду слишком подробно на них останавливаться, расскажу кратко идею.
Для каждого пользователя v нужно посчитать K векторов намерений (intentionkv). Эти векторы являются взвешенной суммой истории (после нескольких преобразований) кликов и просмотров пользователя. Веса айтемов для усреднения определяются несколькими аспектами:
Дальность айтема от negative intention (усреднение дизлайков айтема).
Близость айтема к текущему кандидату.
Близость айтема к последнему кликнутому айтему (только для кликов).
Близость айтема к вектору mk, обучаемому центру кластеров интересов, одинаковых для всех пользователей.
В итоге айтемы-кандидаты t ранжируются по убыванию svt:
![s_{vt} = \sum_{k=1}^K <intention_k^v, h_t^v> + MLP([f_1, f_2, \ldots, f_r])](https://habrastorage.org/getpro/habr/upload_files/3c5/45f/79e/3c545f79ec8fc502be5efe42078fb9c1.svg)
Где <> — скалярное произведение, ht — вектор кандидата, fi — признаки кандидата и пользователя, MLP — полносвязная нейросеть.
В качестве функции потерь используется кросс-энтропия и штраф на близость mk друг к другу.
Мое краткое впечатление об архитектуре — она странная. Например, авторы используют блок residuals, где перед сложением добавляют активацию ReLU. Из-за этого все элементы добавляемого вектора неотрицательны. Еще авторы используют вектор кандидата в подсчете intentions (ради вычисления одного из весов, на сами усредняемые векторы кандидат не влияет). При этом финальный скор считается скалярным произведением, которое обычно используется в комбинации с индексом поиска ближайших соседей, но в данной архитектуре это невозможно. В таких архитектурах чаще прибегают к более сложным и из-за этого более мощным способам для подсчета скора. Объяснение таких необычных подходов не представлено.
Оптимизация с помощью Curriculum Learning
Идею curriculum learning легко объяснить на пальцах. Представьте обучение новому языку. Сначала изучают алфавит и простые слова, и далее, по мере обучения, усложняют изучаемые конструкции. Такой же подход можно применить и в deep learning. Будем подавать нейросети на первых эпохах простые примеры, а потом последовательно их усложнять. Но как нам определить сложность примера? Тут все просто: чем меньше значение функции потерь, тем пример легче. Самый простой способ использовать эту идею при обучении модели — умножать сэмплы с высоким лоссом на маленький вес в начале обучения и увеличивать этот вес со временем.
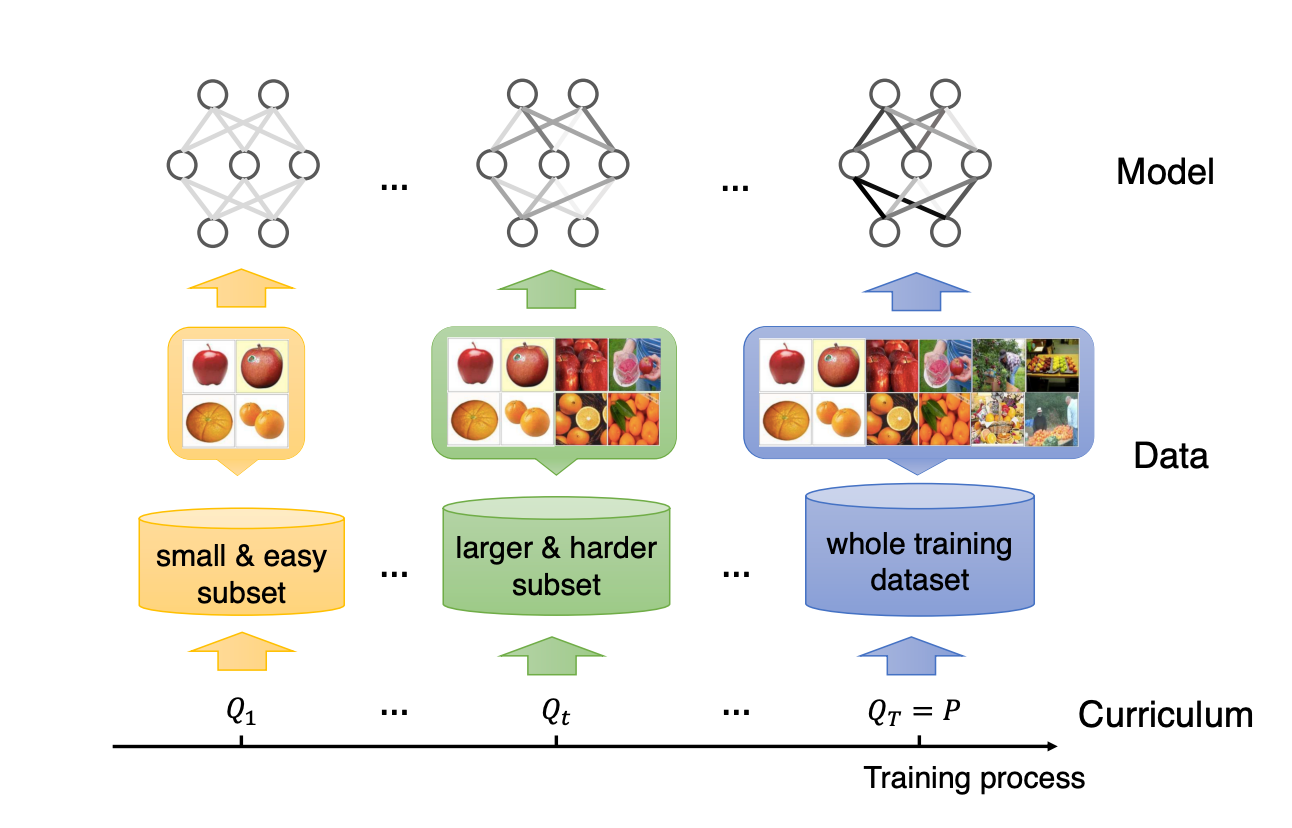
Для curriculum learning авторы тоже придумали свой подход, объяснив это тем, что их подход более гибкий за счет гиперпараметров, и (если гиперпараметры оптимальные) очень быстро работает. Авторы не сравнивают свой подход с общепризнанными, но приводят графики зависимости работы моделей от гиперпараметров.
Результаты
Авторы сравнивают свою модель с бейзлайнами на 4 датасетах: WeChat5D, MovieLens-1M, Amazon Sports and Amazon Beauty. WeChat5D — продуктовый, остальные в открытом доступе. Но в трех открытых датасетах нет данных о просмотрах, поэтому авторы их просто сэмплируют (!) с помощью написанного ими самими симулятора. По всем четырем датасетам авторы отрываются от всех бейзлайнов.
Репозиторий есть, кода нет https://github.com/forchchch/cdr
DSelect-k: Differentiable Selection in the Mixture of Experts with Applications to Multi-Task Learning
ссылка
Автор разбора: Андрей Мурашев, руководитель группы рекомендаций в Пульсе (Nord786)
В данной статье исследователи из Google рассматривают новый подход к обучению Mixture-of-experts (MOE) – использование нового типа gate DSelect-K для выбора экспертов, который дал им на задаче предсказания следующего видео +20% на оффлайн метриках. Сейчас существует два основных типа gate при обучении MOE:
Softmax gate σ(Ax+b) – его проблема в том, что он для всех экспертов возвращает ненулевой вес и приходится активировать их все.
TopK gate, в котором выбирается K лучших экспертов, а для остальных возвращаются нулевые веса и можно оптимизировать вычисления. Проблема этого подхода в том, что он не являются непрерывным – это означает, что градиент не всегда существует.
Для решения проблемы непрерывности в подходе DSelect-K предлагается сделать выбор K экспертов дифференцируемым. Введем обозначения:
z – обучаемый бинарный вектор размерности M=log(N), где N - кол-во экспертов;
r(z) – функция преобразования из М-мерного двоичного кода, в бинарный one-hot вектор, кодирующий номер каждого из N экспертов;
ɑ – обучаемый параметр, вес каждого эксперта;
k – количество активных экспертов.
В случае N=4, M=log(4)=2, функция r(z) выглядит так
![r(z) = [\bar z_1 \bar z_2, z_1 \bar z_2, \bar z_1 z_2, z_1 z_2]^T, \; где \; \bar z_i = 1 - z_i](https://habrastorage.org/getpro/habr/upload_files/a7e/135/724/a7e13572404c6df789b1a0e91178de09.svg)
если вектор z бинарный, то функция r(z) вернет единицу только в одной позиции, а в остальных будет ноль – то есть активируется только один соответствующий эксперт. Если функция z не бинарная, то функция r(z) может вернуть ненулевые веса сразу для нескольких экспертов.
Чтобы данный подход был непрерывным и дифференцируемым нужно уйти от бинарного вектора z к непрерывным функциям. Для этого мы воспользуемся функцией smoothing

Применим ее поэлементно к вектору z, добавим зависимость от входных данных, и получим формулу для gate функции

Важно заметить, что данный gate из-за сглаживающей функции не обеспечивает срабатывание строго K экспертов, но при длительном обучении или специальном подходе к регуляризации и инициализации значений, описанном в статье, можно добиться, чтобы в среднем обеспечивалась активация не более K экспертов.
Результаты применения данного подхода вместо TopK-gate при выборе 2-х экспертов в оффлайне на задаче предсказания следующего видео для Youtube:
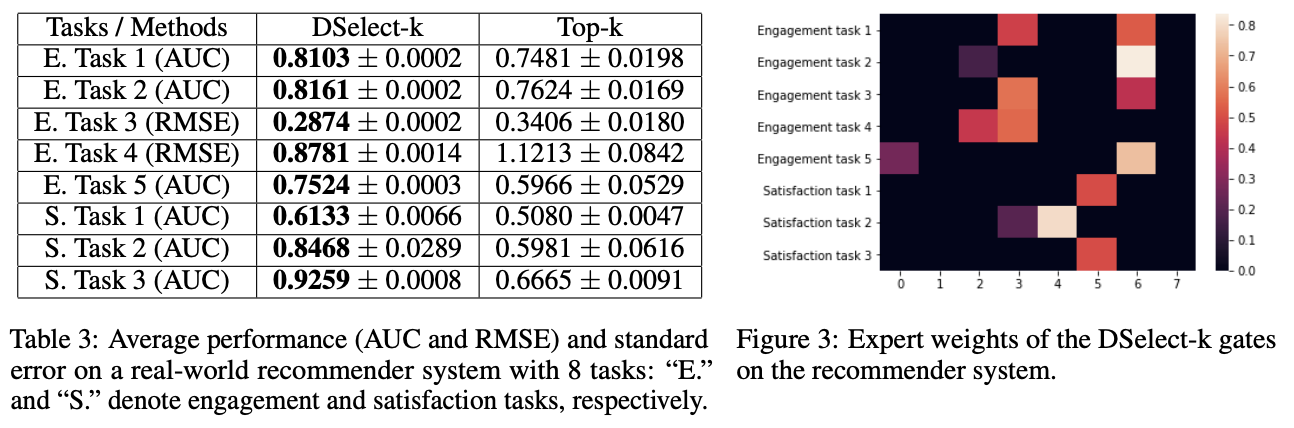
Видно что для всех таргетов (они предсказывают разные метрики вовлеченности и удовлетворенности) получается значительный прирост по офлайн метрике.
Авторы выложили реализацию предложенного механизма на tensorflow:
Комментарий автора разбора
Можно было бы сделать вектор z размерности N и сразу его интерпретировать как вектор для активации экспертов – но авторы статьи решили сэкономить на количестве параметров за счет трюка с логарифмом и бинарным представлением номеров экспертов.
Leveraging Distribution Alignment via Stein Path for Cross-Domain Cold-Start Recommendation
ссылка
Автор разбора: Даша Никанорова, DS разработчик в Одноклассниках (DaryaNikanorova)
Рекомендательные системы используют алгоритмы, основанные на информации о взаимодействии пользователей и айтемов: оценках, рейтингах, реакциях. Однако, история взаимодействия для недавно появившихся в каталоге айтемов отсутствует. Это затрудняет построение рекомендаций. То же самое верно и для новых пользователей – у нас нет данных о том, какие айтемы им нравились в прошлом, следовательно, мы не можем предсказать, что понравится в будущем. Эту проблему называют проблемой холодного старта. Для ее решения можно использовать контентную информация – дополнительную информацию об айтемах и пользователях, на основании которой можно создать рекомендации.
В статье авторы придумали способ рекомендовать холодные айтемы на основе контентной и коллаборативной информации об айтемах, которые уже давно представлены в каталоге (будем называть их “горячие”). Но как рекомендовать “холодные” айтемы, используя информацию о “горячих” айтемах, особенно если они относятся к разным категориям?

Допустим, каталог айтемов онлайн-магазина представлен фильмами разных жанров, для которых у нас собран пользовательский фидбэк. Каталог расширяется, и в нем появляются не только фильмы, но и книги. Книги и фильмы похожи: и в том и в другом есть сюжет, герои, локации. Зная, какие фильмы нравятся пользователю, можно порекомендовать ему книги, похожие по смыслу или жанру.
Для реализации этой идеи авторы статьи предлагают использовать следующий алгоритм:
Выучить коллаборативные эмбеддинги для горячих айтемов (фильмов) и пользователей.
Выучить контентные эмбеддинги горячих и холодных айтемов (книг), используя сиамскую нейронную сеть.
Сблизить векторные пространства эмбеддингов горячих и холодных айтемов, оценив, таким образом "коллаборативные" эмбеддинги для холодных айтемов.
В основе последнего этапа лежит Stein Variational Gradient Descent – алгоритм градиентного спуска, позволяющий итеративно обновлять координаты элементов из исходного векторного пространства, “перемещая” их в целевое векторное пространство, уменьшая расстояние Кульбака-Лейблера.
Этот подход можно оптимизировать, если двигать не все элементы исходного пространства (то есть все айтемы в каталоге), а только некоторые, самые репрезентативные, как показано на рисунке ниже. Авторы назвали этот подход proxy Stein path alignment.

Этот подход позволяет значительно снизить временную сложность алгоритма, не снижая качество модели. Авторы протестировали свой подход на двух датасетах: Douban и Amazon и показали прирост по метрикам ранжирования по сравнению с другими моделями.
Комментарий автора разбора
Сближение эмбеддингов холодных и горячих айтемов основано, в том числе, на схожести контентной информации. Этот подход применим не во всех задачах. Сложно представить, какую семантическую схожесть можно найти между абсолютно разными категориями товаров, например, одеждой и книгами.
Не совсем понятно, как алгоритм работает на граничных случаях. Например, если среди книг есть детективы, а среди фильмов такой категории нет, то эмбеддинги книг-детективов сблизятся с эмбеддингами фильмов другой категории, что приведет в итоге к менее релевантным рекомендациям.
A/B Testing for Recommender Systems in a Two-sided Marketplace
ссылка
Автор разбора: Данила Савенков, старший разработчик в Яндексе (danila_savenkov)
Современные контентные платформы по сути являются маркетплейсами с двумя типами участников: создателями и потребителями контента. Онлайн эксперименты в большинстве случаев проводят в срезе потребителей. Например, чтобы оценить эффект от обновления рекомендаций, обычно проводят A/B-тест, выкатив эту модель на какую-то долю пользователей, которые получают рекомендации. Как проводить онлайн-эксперименты в срезе создателей контента – менее очевидная задача. Как например оценить влияние обновления рекомендаций на пользователей, посты которых мы рекомендуем? В статье предлагается один из способов проведения таких экспериментов.
В качестве примера рассмотрим задачу рекомендации друзей в социальной сети. Разработчики из LinkedIn решили поставить эксперимент, в котором в рекомендациях друзей будут учитывать вероятность того, что пользователь, получив уведомление о заявке в друзья, зайдет на сайт или в приложение. Измерять в этом эксперименте хочется количество сессий на пользователя.
Важный момент: потребитель – пользователь, который видит рекомендации друзей. Создатель – пользователь, профиль которого отображается в рекомендациях. Нам интересен эффект в срезе создателей, потому что эффект в срезе потребителей можно оценить стандартным A/B-тестом.
Как поставить эксперимент в срезе создателей не понятно. Есть старая модель рекомендаций и новая. Нужен способ «смешать» их для каждого конкретного потребителя.
Раньше эту проблему пытались решать выделением не связанных друг с другом кластеров для тестовой группы и контрольной группы. Если в тесте все создатели будут из теста, а в контроле – из контроля, то мы можем на тесте оставить только новую модель, а на контроле – старую. Свойства реальных больших графов не позволяют найти такое разбиение, а значит этот метод имеет ограниченную применимость.
В статье предложен достаточно простой метод постановки такого эксперимента, который:
Не требует никакой информации о графе.
Теоретически оптимален при случайном разбиении на группы.
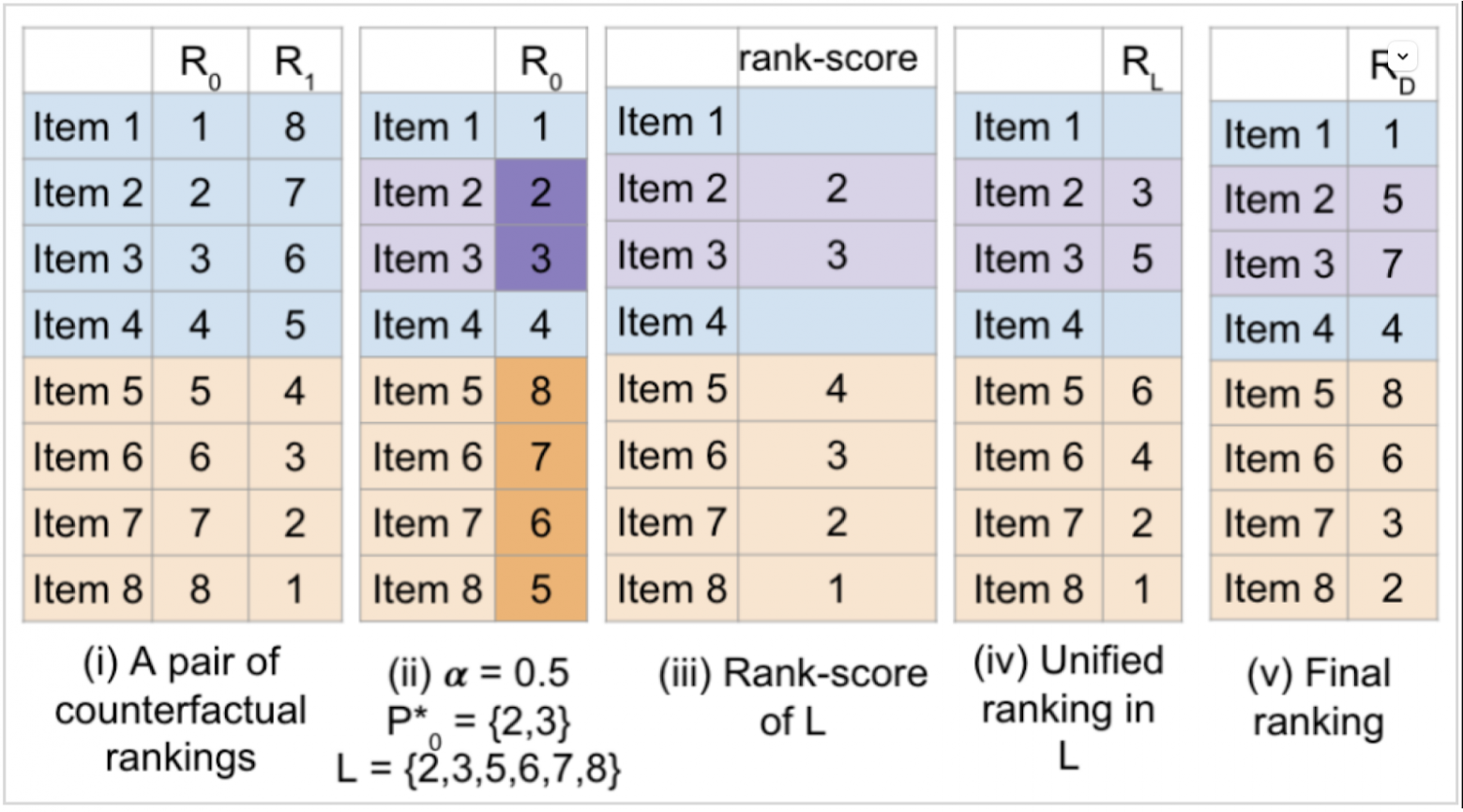
Синие айтемы относятся к контролю, оранжевые – к тесту. Есть ранжирование «как в контроле» R0 и «как в тесте» R1.
Случайно выберем множество айтемов из контроля (P*) с вероятностью α. На картинке в пункте (ii) смотреть на ранги не нужно (кажется, авторы забыли их удалить).
Для P* оставляем ранги из контроля, для оранжевых айтемов берем из теста.
Случайно разрешаем связки. В примере все связки разрешены в пользу теста.
Синие айтемы, не попавшие в P*, ставятся на свои места, согласно ранжированию «из контроля», все образовавшиеся пропуски заполняем «оранжевыми» айтемами и айтемами из P* согласно их рангам с шага 4.
В случае α=0 (именно его используют авторы в онлайн экспериментах) все сводится к тому чтобы переранжировать айтемы из теста в соответствии с новой моделью, при этом айтемы из контроля остаются на своих местах.
В случае α=1 (самый затратный, но самый точный метод: именно для него были получены теоретические гарантии) необходимо смешать ранжирование R0 для синих и R1 для оранжевых айтемов, разрешая связки случайно.
Комментарий автора разбора
Главная проблема этого метода (равно как и других методов решения этой задачи) в том, что они не проверяемы. Рост в 0.5%, который получили разработчики LinkedIn, нельзя ни подтвердить ни опровергнуть. Гарантия оптимальности во-первых относится не к целевой метрике, а к достаточно странному «квадратичному отклонению рангов от идеального, но не реализуемого ранга» и во-вторых не гарантирует нулевое смещение результата в пределе (в отличие от привычных нам A/B-тестов). С другой стороны метод прост в реализации, да еще и с теоретическими гарантиями, пусть и не такими сильными как хотелось бы. Почему бы его не использовать, для того чтобы оценить на какой эффект для создателей контента мы можем рассчитывать при том или ином изменении системы.
Control Variates for Slate Off-Policy Evaluation
ссылка
Автор разбора: Аби Палагашвили, программист-исследователь в Пульсе (archibonk)
Возможность корректно оценить новый рекомендательный или ранжирующий алгоритм является бесценным способом исключения из рассмотрения априори проигрышных вариантов. В данной статье авторы предлагают методику оценки алгоритмов путём off-policy evaluation.
Онлайн сервисы (новостные, музыкальные, стриминговые) часто предлагают контент в форме полок, где каждая позиция может принимать одно из множества значений. Например, новостные издания могут иметь позиции под региональные новости, спорт, политику. Обычно предлагаемый контент персонализируется с помощью ML и A/B тестирования. Однако число кандидатов на каждую позицию в полке может исчисляться сотнями или тысячами, что осложняет оптимизацию и тестирование алгоритмов персонализации. Допустим, у нас есть новая стратегия π и мы хотим оценить ее ожидаемую "награду" (например, прибыль)
![\mathbb{E}_\pi[R],](https://habrastorage.org/getpro/habr/upload_files/abc/826/d56/abc826d561eb239fad6cf76827ffe463.svg)
используя данные, собранные логирующей стратегией μ. В статье авторы рассматривают случай, когда логирующая стратегия факторизуется по позициям в выдаче

Здесь каждое A - вектор действий, представляющий собой набор айтемов, а X – весь наблюдаемый контекст (например, пользовательская история). Это условие справедливо, например, если наша стратегия является эпсилон-жадной по каждой позиции в полке.
Авторы вводят следующие обозначения:

Оценку ожидаемой награды получаем следующим образом:
Случайно делим данные на 3 фолда.
Вычислим веса по каждому фолду, используя данные этого фолда Dj:
![\hat w_{n, k}^{(j)} = \frac{\mathbb{E}_{D_j}[GR(Y_k-1)]}{\mathbb{E}_{D_j}[(Y_k-1)^2]}](https://habrastorage.org/getpro/habr/upload_files/da3/ae2/dee/da3ae2deefc8b8091ae81aff2c1ab182.svg)
Итоговая оценка ожидаемой награды вычисляется как
![\mathbb{E}_{\pi}^*[R] = \mathbb{E}_n[GR] - \sum_k \sum_{j \in \{0, 1, 2\}} \frac{|D_j|}{n} \hat w_{n, k}^{(j + 1 \mod 3)} \mathbb{E}_{D_j}[Y_k-1]](https://habrastorage.org/getpro/habr/upload_files/0c7/fdf/377/0c7fdf3777e7b54f2f014ebdd751eb95.svg)
(не спрашивайте, как они это получили).
В конце авторы проводят эксперимент на датасете MSLR-WEB30k и синтетических данных, показывая, что их оценка приближает ожидаемую награду лучше, чем существующие подходы.
Комментарий автора разбора
Off-policy evaluation представляет собой интересное направление, которое может принести свои плоды. Однако на данный момент отсутствует необходимая база для внедрения этой техники в продакшен сервисы. Стоит ознакомиться со статьей, чтобы понимать, какие существуют подходы к оцениванию стратегий, помимо классических A/B тестов.
Заключение
На этом завершается рекомендательная часть нашего разбора. Нейронные сети закрепились как стандартный подход в рекомендациях, по крайней мере в академии. Архитектуры развиваются, чтобы учитывать больше разных видов данных и точнее решать новые задачи, вроде многоцелевой оптимизации и холодного старта. Ученые придумывают, как лучше оценивать качество рекомендаций, как в "онлайн" так и в "офлайн" режимах.
Во второй части разбора мы расскажем о работах общей тематики: от постановки задач машинного обучения до трансформерных моделей.




