
Прим. перев.: То, что сегодня принято называть SRE (Site Reliability Engineering — «обеспечение надежности информационных систем»), включает в себя большой спектр мероприятий по эксплуатации программных продуктов, направленных на достижение ими необходимого уровня надежности. Мониторинг — одно из ключевых мероприятий, а «золотые сигналы» образуют главные метрики, которые должны в нём учитываться. Не найдя на Хабре ни одного материала про них, мы решили перевести небольшую заметку от авторов платформы для управления инцидентами (VictorOps), дающую представление общее представление об этом подходе.

Эффективный site reliability engineering (SRE) опирается на глубокое понимание базовой инфраструктуры сервиса и архитектуры. Повышение прозрачности состояния приложения и инфраструктуры — это только начало проактивной работы над созданием надежных систем. При этом наилучшей отправной точкой для мониторинга состояния систем считаются так называемые «четыре золотых сигнала» (four golden signals) SRE. Наладив эти четыре базовых метода мониторинга, можно переходить к дальнейшему повышению прозрачности системы.
Повышение прозрачности вкупе с эффективными методами совместной работы позволяет командам SRE оперативно отслеживать работу систем и принимать меры для устранения последствий инцидентов, повышая общую эффективность методов мониторинга и оповещения. Золотые сигналы SRE помогают командам выявлять любые потенциальные слабые места в надежности, позволяя сосредоточиться над устранением проблем в инфраструктуре. Давайте же исследуем взаимосвязь между методами мониторинга и командами SRE и посмотрим, какое влияние золотые сигналы оказывают на процесс.
В III части нашего DevOps-словаря мы исследовали интернет, пытаясь найти определение SRE. Согласно соответствующей статье в Wikipedia, «Ben Treynor, основатель Site Reliability Team в Google [говорит], что SRE — „это то, что получается, когда software engineer занимается тем, что раньше называлось эксплуатацией“». SRE сочетает задачи и возможности программной инженерии с проблемами эксплуатации IT и помогает находить решения для вопросов, связанных с надежностью. Понятно, что команды SRE должны мониторить свои сервисы для выявления областей, в которых можно повысить надежность.
Именно в этом и заключается задача мониторинга применительно к командам SRE. Он занимает лишь небольшую часть в создании высокопрозрачных систем, однако это важный элемент для понимания состояния приложений и инфраструктуры. Четыре золотых сигнала мониторинга и SRE обеспечивают базовый уровень прозрачности в отношении надежности всего, что вы создаете. Достигнув комфортного уровня наблюдаемости состояния золотых сигналов, можно использовать эту дополнительную информацию для более углубленного анализа с помощью инструментов для мониторинга.
Теперь, когда мы определились с важностью мониторинга золотых сигналов SRE, давайте обратимся к реальным метрикам, составляющим их.
В начале пути по совершенствованию усилий по мониторингу бывает непросто понять, с чего следует начинать. Четыре золотых сигнала SRE и мониторинга впервые были приведены в книге Google о SRE, и в настоящее время активно используются многими командами. С них отлично начинать, поскольку они помогают выделить основные метрики, которые следует отслеживать всегда.
Итак, давайте рассмотрим золотые сигналы и разберемся, почему их мониторинг является неотъемлемым элементом в обеспечении надежности любой системы.
Сколько времени занимает обработка запроса? Определите ориентир для задержек, типичных для успешных запросов, и сравните его с задержками для неуспешных запросов. Отслеживание задержек, вызванных ошибками, позволяет решить любые вопросы, связанные со скоростью выявления инцидента и реакции на него.
Этот сигнал не требует особых пояснений. Какое влияние на систему оказывает количество пользователей или число транзакций, проходящих через сервис? В зависимости от функциональности сервиса измерение трафика может существенно отличаться от компании к компании. Отслеживая взаимодействие с реальными пользователями и трафик, можно лучше понять, как конечные пользователи воспринимают сервис, и получить представление о том, как системы ведут себя в условиях стресса.
Конечно, каждая команда должна следить за ошибками. Независимо от того, вызваны ли ошибки заданной вручную логикой или автономны (вроде неудавшегося HTTP-запроса), SRE-команды должны отслеживать их. Многие SRE-команды используют специальное ПО для управления инцидентами для оповещений о критических ошибках, поиска их причин и проведения работ по устранению последствий.
Каждая команда должна следить за загруженностью своей системы. Важно задать метрику для насыщенности, которая бы означала, что сервис достиг максимума своих возможностей. Большинство сервисов начинают терять производительность еще до того, как загрузка достигнет 100%, поэтому понимание функциональности вашей собственной системы важно для определения ориентира насыщенности, который имеет смысл.
Установив правила мониторинга и оповещений для четырех золотых сигналов, вы охватите большинство ключевых инцидентов в системе. Однако чтобы приступить с созданию проактивной системы для мониторинга и SRE, придется копнуть еще глубже.
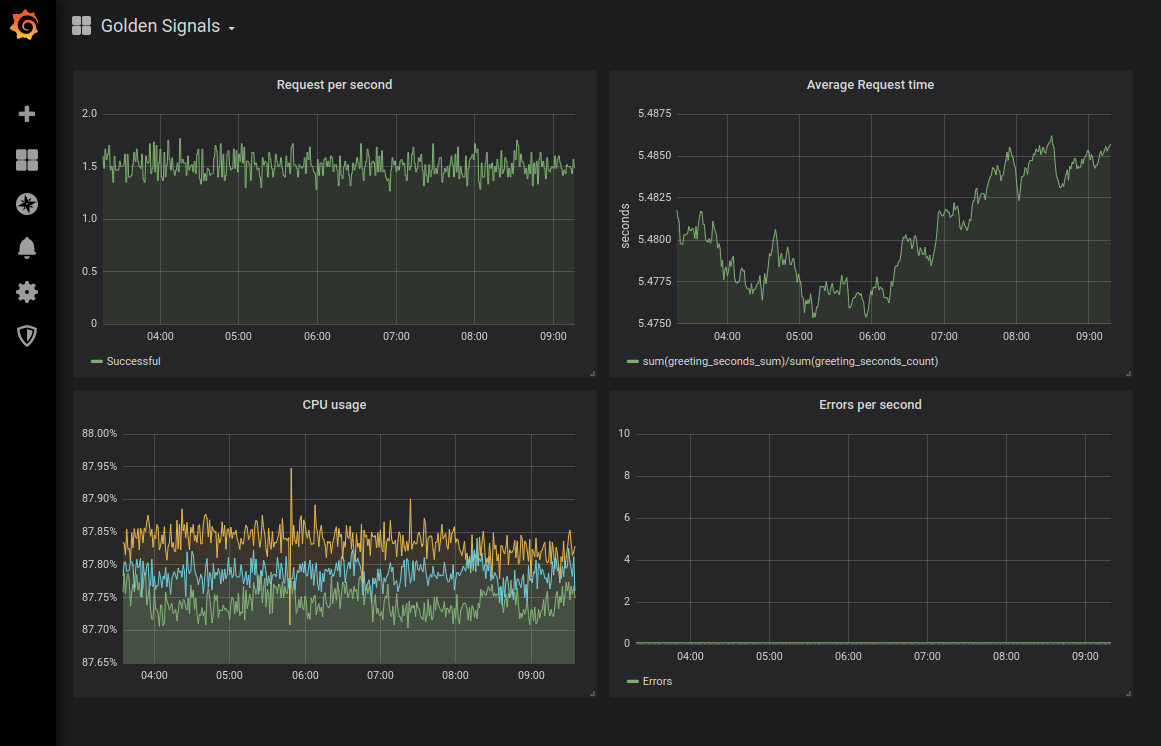
Прим. перев.: Как пример иллюстрации dashboard'а с графиками «золотых сигналов» приведём результат соответствующей конфигурации мониторинга для Kubernetes из этой статьи от Sysdig:
Прим. перев.: А вот более наглядное представление о золотых сигналах от Denise Yu, которую можно использовать как удобную памятку:

Мониторинг золотых сигналов — отличное начало для анализа инцидентов в сервисе, однако его не достаточно. Опытные команды SRE проактивно изучают свои системы с помощью многочисленных дополнительных методов. Проводя организованные испытания на подготовительных этапах и в production, команды SRE активно изучают свои системы и используют получаемую информацию для повышения надежности сервисов.
Хаос-инжиниринг — это дисциплина, применяемая командами для испытания своих систем с целью упреждающего обнаружения слабых мест и уязвимостей. Вручную вводя хаос в сервис, можно посмотреть, как именно система реагирует на различные обстоятельства.
Прим. перев.: Подробнее о таком подходе читайте в статье «Chaos Engineering: искусство умышленного разрушения» (часть 1 и часть 2).
В то время как хаос-инжиниринг направлен на понимание системы, игровые дни помогают понять персонал. Они используются для проверки устойчивости команды, когда речь идет о реагировании на инциденты и устранении их последствий. Результаты игровых дней можно использовать для разработки более эффективных процессов или определения потребности в новых инструментах, повышающих эффективность персонала.
Синтетический мониторинг позволяет командам создавать искусственных пользователей и имитировать их поведение с помощью сервиса. Можно задать определенные поведенческие паттерны и понаблюдать за тем, как система ведет себя в условиях данной нагрузки. Синтетический мониторинг — отличный метод для детального тестирования и определения надежности конкретных сервисов в рамках всей системы.
Любая команда, стремящаяся визуально отслеживать состояние системы, обязана следить за золотыми сигналами SRE. Но представление о состоянии и общей надежности системы — вовсе не то же самое, что работа над повышением ее надежности. В современной экосистеме высокораспределенных систем и стремительного развертывания перед командами SRE стоит непростая задача. Золотые сигналы мониторинга и SRE могут стать той отправной точкой, с которой начнется дальнейшее совершенствование в рамках SRE.
Читайте также в нашем блоге:
Эффективный site reliability engineering (SRE) опирается на глубокое понимание базовой инфраструктуры сервиса и архитектуры. Повышение прозрачности состояния приложения и инфраструктуры — это только начало проактивной работы над созданием надежных систем. При этом наилучшей отправной точкой для мониторинга состояния систем считаются так называемые «четыре золотых сигнала» (four golden signals) SRE. Наладив эти четыре базовых метода мониторинга, можно переходить к дальнейшему повышению прозрачности системы.
Повышение прозрачности вкупе с эффективными методами совместной работы позволяет командам SRE оперативно отслеживать работу систем и принимать меры для устранения последствий инцидентов, повышая общую эффективность методов мониторинга и оповещения. Золотые сигналы SRE помогают командам выявлять любые потенциальные слабые места в надежности, позволяя сосредоточиться над устранением проблем в инфраструктуре. Давайте же исследуем взаимосвязь между методами мониторинга и командами SRE и посмотрим, какое влияние золотые сигналы оказывают на процесс.
Мониторинг и SRE
В III части нашего DevOps-словаря мы исследовали интернет, пытаясь найти определение SRE. Согласно соответствующей статье в Wikipedia, «Ben Treynor, основатель Site Reliability Team в Google [говорит], что SRE — „это то, что получается, когда software engineer занимается тем, что раньше называлось эксплуатацией“». SRE сочетает задачи и возможности программной инженерии с проблемами эксплуатации IT и помогает находить решения для вопросов, связанных с надежностью. Понятно, что команды SRE должны мониторить свои сервисы для выявления областей, в которых можно повысить надежность.
Именно в этом и заключается задача мониторинга применительно к командам SRE. Он занимает лишь небольшую часть в создании высокопрозрачных систем, однако это важный элемент для понимания состояния приложений и инфраструктуры. Четыре золотых сигнала мониторинга и SRE обеспечивают базовый уровень прозрачности в отношении надежности всего, что вы создаете. Достигнув комфортного уровня наблюдаемости состояния золотых сигналов, можно использовать эту дополнительную информацию для более углубленного анализа с помощью инструментов для мониторинга.
Теперь, когда мы определились с важностью мониторинга золотых сигналов SRE, давайте обратимся к реальным метрикам, составляющим их.
Четыре золотых сигнала мониторинга
В начале пути по совершенствованию усилий по мониторингу бывает непросто понять, с чего следует начинать. Четыре золотых сигнала SRE и мониторинга впервые были приведены в книге Google о SRE, и в настоящее время активно используются многими командами. С них отлично начинать, поскольку они помогают выделить основные метрики, которые следует отслеживать всегда.
Итак, давайте рассмотрим золотые сигналы и разберемся, почему их мониторинг является неотъемлемым элементом в обеспечении надежности любой системы.
1. Задержка (Latency)
Сколько времени занимает обработка запроса? Определите ориентир для задержек, типичных для успешных запросов, и сравните его с задержками для неуспешных запросов. Отслеживание задержек, вызванных ошибками, позволяет решить любые вопросы, связанные со скоростью выявления инцидента и реакции на него.
2. Трафик (Traffic)
Этот сигнал не требует особых пояснений. Какое влияние на систему оказывает количество пользователей или число транзакций, проходящих через сервис? В зависимости от функциональности сервиса измерение трафика может существенно отличаться от компании к компании. Отслеживая взаимодействие с реальными пользователями и трафик, можно лучше понять, как конечные пользователи воспринимают сервис, и получить представление о том, как системы ведут себя в условиях стресса.
3. Ошибки (Errors)
Конечно, каждая команда должна следить за ошибками. Независимо от того, вызваны ли ошибки заданной вручную логикой или автономны (вроде неудавшегося HTTP-запроса), SRE-команды должны отслеживать их. Многие SRE-команды используют специальное ПО для управления инцидентами для оповещений о критических ошибках, поиска их причин и проведения работ по устранению последствий.
4. Насыщенность (Saturation)
Каждая команда должна следить за загруженностью своей системы. Важно задать метрику для насыщенности, которая бы означала, что сервис достиг максимума своих возможностей. Большинство сервисов начинают терять производительность еще до того, как загрузка достигнет 100%, поэтому понимание функциональности вашей собственной системы важно для определения ориентира насыщенности, который имеет смысл.
Установив правила мониторинга и оповещений для четырех золотых сигналов, вы охватите большинство ключевых инцидентов в системе. Однако чтобы приступить с созданию проактивной системы для мониторинга и SRE, придется копнуть еще глубже.
Прим. перев.: Как пример иллюстрации dashboard'а с графиками «золотых сигналов» приведём результат соответствующей конфигурации мониторинга для Kubernetes из этой статьи от Sysdig:
Прим. перев.: А вот более наглядное представление о золотых сигналах от Denise Yu, которую можно использовать как удобную памятку:
Проактивный SRE выходит за рамки золотых сигналов
Мониторинг золотых сигналов — отличное начало для анализа инцидентов в сервисе, однако его не достаточно. Опытные команды SRE проактивно изучают свои системы с помощью многочисленных дополнительных методов. Проводя организованные испытания на подготовительных этапах и в production, команды SRE активно изучают свои системы и используют получаемую информацию для повышения надежности сервисов.
Chaos Engineering
Хаос-инжиниринг — это дисциплина, применяемая командами для испытания своих систем с целью упреждающего обнаружения слабых мест и уязвимостей. Вручную вводя хаос в сервис, можно посмотреть, как именно система реагирует на различные обстоятельства.
Прим. перев.: Подробнее о таком подходе читайте в статье «Chaos Engineering: искусство умышленного разрушения» (часть 1 и часть 2).
Игровые дни (Game Days)
В то время как хаос-инжиниринг направлен на понимание системы, игровые дни помогают понять персонал. Они используются для проверки устойчивости команды, когда речь идет о реагировании на инциденты и устранении их последствий. Результаты игровых дней можно использовать для разработки более эффективных процессов или определения потребности в новых инструментах, повышающих эффективность персонала.
Синтетический мониторинг
Синтетический мониторинг позволяет командам создавать искусственных пользователей и имитировать их поведение с помощью сервиса. Можно задать определенные поведенческие паттерны и понаблюдать за тем, как система ведет себя в условиях данной нагрузки. Синтетический мониторинг — отличный метод для детального тестирования и определения надежности конкретных сервисов в рамках всей системы.
…
Любая команда, стремящаяся визуально отслеживать состояние системы, обязана следить за золотыми сигналами SRE. Но представление о состоянии и общей надежности системы — вовсе не то же самое, что работа над повышением ее надежности. В современной экосистеме высокораспределенных систем и стремительного развертывания перед командами SRE стоит непростая задача. Золотые сигналы мониторинга и SRE могут стать той отправной точкой, с которой начнется дальнейшее совершенствование в рамках SRE.
P.S. от переводчика
Читайте также в нашем блоге:
- «Мониторинг и Kubernetes (обзор и видео доклада)»;
- «Устройство и механизм работы Prometheus Operator в Kubernetes»;
- «Флант и Okmeter: симбиоз на благо мониторинга».




