
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
В больших проектах, состоящих из десятков и сотен взаимодействующих сервисов, всё чаще становится обязательным подход к документации как к коду — docs as code.
Я покажу, как можно применять эту философию в реалиях classified-сервиса, а точнее, начну с первого этапа её внедрения: автоматизации обновления данных в документации.
Набор инструментов
Принцип «документация как код» подразумевает использование при написании документации того же инструментария, что и при создании кода: языков разметки текста, систем контроля версий, code review и авто-тестов. Главная цель: создать условия для совместной работы всей команды над итоговым результатом — полноценной базой знаний и инструкций по использованию отдельных сервисов продукта. Далее я расскажу о конкретных инструментах, выбранных нами для решения этой задачи.
В качестве языка разметки текста мы решили использовать наиболее универсальный — reStructuredText. Помимо большого количества директив, которые предоставляют все основные функции для структурирования текста, этот язык поддерживает ключевые конечные форматы, в том числе необходимый для нашего проекта HTML.
Файлы конвертируются из .rst в .html посредством генератора документации Sphinx. Он позволяет создавать статические сайты, для которых можно делать собственные или использовать уже готовые темы оформления. В нашем проекте используются две готовые темы — stanford-theme и bootstrap-theme. Вторая содержит подтемы, позволяющие задавать разные цветовые схемы для ключевых элементов интерфейса.
Для удобного и быстрого доступа к актуальной версии документации мы используем статический сайт, хостом для которого служит виртуальная машина, доступная из локальной сети команды разработки.
Исходные файлы проекта хранятся в Bitbucket-репозитории, причём сайт генерируется только из файлов, содержащихся в ветке master. Обновить в ней данные можно только через pull-request, что позволяет проверять все новые разделы документации перед тем, как они будут опубликованы в общем доступе.
Поскольку между завершением нового раздела документации и его отправкой на сайт нужно проверять его содержание, ключевым во всей цепочке становится сам процесс сборки сайта и обновления данных на хосте. Эта процедура должна повторяться каждый раз после того, как pull-request с обновлением сливается с главной веткой проекта.
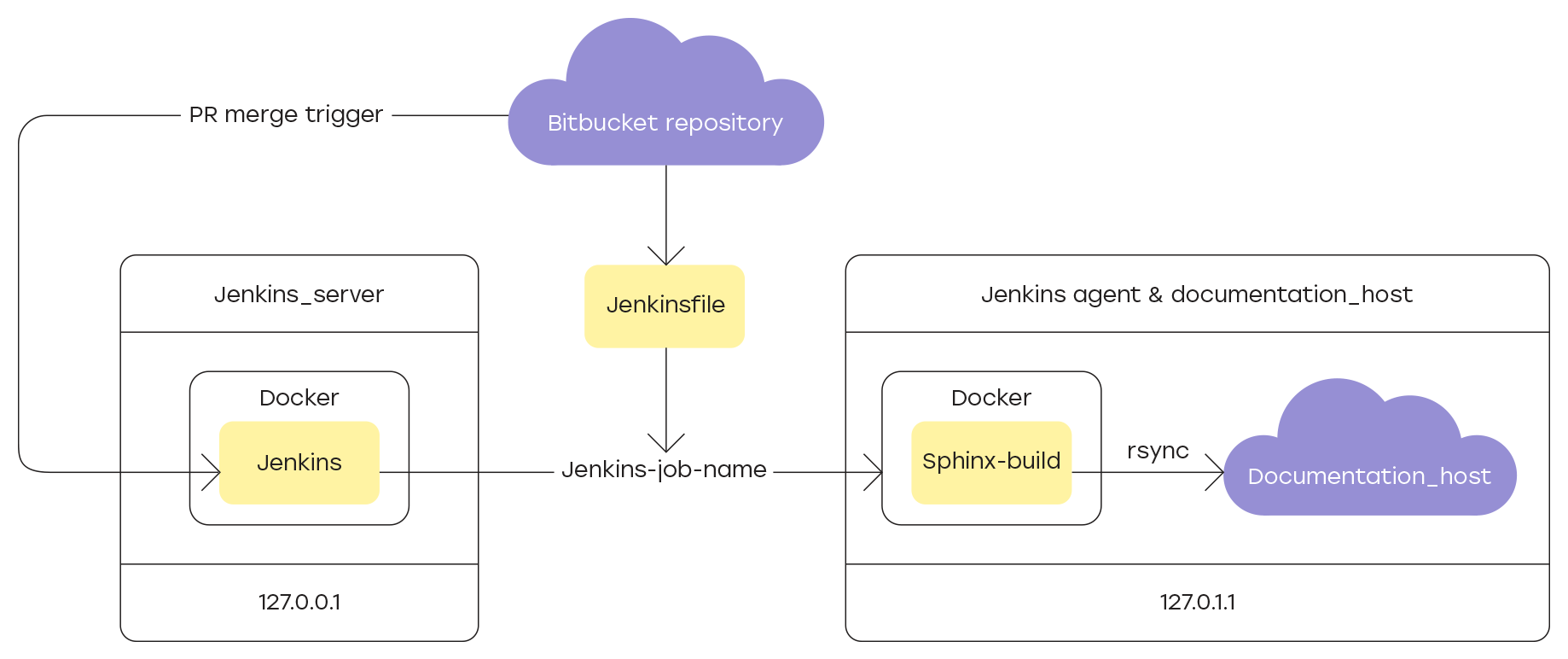
Реализовать подобную логику позволяет Jenkins — система непрерывной интеграции разработки, в нашем случае — документации. Подробнее о настройке я расскажу в разделах:
- Добавление нового узла в Jenkins
- Описание Jenkinsfile
- Интеграция Jenkins и Bitbucket
Добавление нового узла в Jenkins
Для сборки и обновления документации на сайте необходимо зарегистрировать в качестве агента Jenkins заранее подготовленную для этого машину.
Подготовка машины
Согласно требованиям Jenkins, на всех компонентах, входящих в систему, включая мастер-машину и все зарегистрированные агентские узлы, должна быть установлена JDK или JRE. В нашем случае будет использоваться JDK 8, для установки которой достаточно выполнить команду:
sudo apt-get -y install java-1.8.0-openjdk gitМастер-машина будет подключаться к агенту для выполнения на нём назначенных задач. Для этого на агенте необходимо создать пользователя, под которым будут выполняться все операции, и в домашней папке которого будут храниться все генерируемые Jenkins-файлы. В Linux-системах достаточно выполнить команду:
sudo adduser jenkins \--shell /bin/bash
su jenkinsДля установки соединения между мастер-машиной и агентом необходимо настроить SSH и добавить необходимые ключи авторизации. Сгенерируем ключи на агенте, после чего для пользователя jenkins добавим публичный ключ в файл authorized_keys.
Собирать сайт с документацией будем в Docker-контейнере, использующем готовый образ python:3.7. Для установки Docker на агенте следуйте инструкциям официальной документации. Чтобы завершить процесс установки, необходимо переподключиться к агенту. Проверим корректность установки, выполнив команду, которая загружает тестовый образ:
docker run hello-worldЧтобы не приходилось запускать команды Docker от имени суперпользователя (sudo), достаточно добавить в созданную на этапе установки группу docker пользователя, от имени которого будут выполняться команды.
sudo usermod -aG docker $USERКонфигурация нового узла в Jenkins
Поскольку подключение к агенту требует авторизации, в настройках Jenkins необходимо добавить соответствующие учётные данные. Подробная инструкция о том, как это делать на Windows-машинах, представлена в официальной документации Jenkins.
ВАЖНО: Идентификатор, который задаётся в разделе Настроить Jenkins -> Управление средами сборки -> Имя узла -> Настроить в параметре Метки, в дальнейшем используется в Jenkinsfile для указания агента, на котором будут выполнены все операции.
Описание Jenkinsfile
В корне репозитория проекта хранится Jenkinsfile, который содержит инструкции по:
- подготовке среды сборки и установке зависимостей;
- сборке сайта с помощью Sphinx;
- обновлению информации на хосте.
Инструкции задаются с помощью специальных директив, применение которых мы рассмотрим далее на примере используемого в проекте файла.
Указание агента
В начале Jenkinsfile укажем метку агента в Jenkins, на котором будут выполняться все операции. Для этого необходимо использовать директиву agent:
agent {
label 'название-метки'
}Подготовка среды
Для выполнения команды сборки сайта sphinx-build необходимо задать переменные среды, в которых будут храниться актуальные пути к данным. Также для обновления информации на хосте необходимо заранее указать пути, где хранятся данные сайта с документацией. Присвоить эти значения переменным позволяет директива environment:
environment {
SPHINX_DIR = '.' //папка, в которой установлен Sphinx
BUILD_DIR = 'project_home_built' //папка с собранным сайтом
SOURCE_DIR = 'project_home_source' //папка с исходными .rst и .md файлами
DEPLOY_HOST = 'username@127.1.1.0:/var/www/html/' //пользоатель@IP_адрес_хоста:папка_с_сайтом
}Основные действия
Основные инструкции, которые будут выполняться в Jenkinsfile, содержатся внутри директивы stages, которая состоит из разных шагов, описываемых директивами stage. Простой пример трёхэтапного CI-pipeline:
pipeline {
agent any
stages {
stage('Build') {
steps {
echo 'Building..'
}
}
stage('Test') {
steps {
echo 'Testing..'
}
}
stage('Deploy') {
steps {
echo 'Deploying....'
}
}
}
}Запуск контейнера Docker и установка зависимостей
Сначала запустим Docker-контейнер с готовым образом python:3.7. Для этого воспользуемся командой docker run с флагами --rm и -i. Затем последовательно сделаем следующее:
- установим python virtualenv;
- создадим и активируем новую виртуальную среду;
- установим в ней все необходимые зависимости, перечисленные в файле
requirements.txt, который хранится в корне репозитория проекта.
stage('Install Dependencies') {
steps {
sh '''
docker run --rm -i python:3.7
python3 -m pip install --user --upgrade pip
python3 -m pip install --user virtualenv
python3 -m virtualenv pyenv
. pyenv/bin/activate
pip install -r \${SPHINX\_DIR}/requirements.txt
'''
}
}Сборка сайта с документацией
Теперь соберём сайт. Для этого необходимо выполнить команду sphinx-build со следующими флагами:
-q: записывать в лог только предупреждения и ошибки;
-w: записывать лог в указанный после флага файл;
-b: имя сборщика сайта;
-d: указать директорию для хранения кешированных файлов — doctree pickles.
Перед запуском сборки, с помощью команды rm -rf удалим предыдущую сборку сайта и логи. В случае ошибки на одном из этапов в консоли Jenkins появится лог выполнения sphinx-build.
stage('Build') {
steps {
// clear out old files
sh 'rm -rf ${BUILD_DIR}'
sh 'rm -f ${SPHINX_DIR}/sphinx-build.log'
sh '''
${WORKSPACE}/pyenv/bin/sphinx-build -q -w ${SPHINX_DIR}/sphinx-build.log \
-b html \
-d ${BUILD_DIR}/doctrees ${SOURCE\_DIR} ${BUILD\_DIR}
'''
}
post {
failure {
sh 'cat ${SPHINX_DIR}sphinx-build.log'
}
}
}Обновление сайта на хосте
И в завершение обновим информацию на хосте, обслуживающем доступный в локальной среде сайт с документацией продукта. В текущей реализации хостом служит та же виртуальная машина, которая зарегистрирована в качестве Jenkins-агента для выполнения задач по сборке и обновлению документации.
В качестве инструмента синхронизации используем утилиту rsync. Для её корректной работы необходимо настроить подключение по SSH между Docker-контейнером, в котором собирался сайт с документацией, и хостом.
Чтобы можно было с помощью Jenkinsfile настраивать подключение по SSH, в Jenkins нужно установить следующие плагины:
- SSH Agent Plugin — позволяет использовать в скриптах шаг
sshagentдля предоставления учётных данных вида имя_пользователя/ключ. - SSH Credentials Plugin — позволяет сохранять в настройках Jenkins учётные данные вида имя_пользователя/ключ.
После установки плагинов необходимо указать актуальные учётные данные для подключения к хосту, заполнив форму в разделе Credentials:
- ID: идентификатор, который будет использоваться в Jenkinsfile на шаге
sshagentдля указания конкретных учётных данных (docs-deployer); - Username: имя пользователя, под которым будут выполняться операции обновления данных сайта (пользователь должен иметь доступ на запись в папку
/var/htmlхоста); - Private Key: приватный ключ для доступа к хосту;
- Passphrase: пароль для ключа, если он задавался на этапе генерирования.
Ниже представлен код скрипта, который подключается по SSH и обновляет информацию на хосте, используя заданные на этапе подготовки среды системные переменные с путями к необходимым данным. Результат выполнения команды rsync записывается в лог, который будет выводиться в консоли Jenkins в случае ошибок синхронизации.
stage('Deploy') {
steps {
sshagent(credentials: ['docs-deployer']) {
sh '''
#!/bin/bash
rm -f ${SPHINX_DIR}/rsync.log
RSYNCOPT=(-aze 'ssh -o StrictHostKeyChecking=no')
rsync "${RSYNCOPT[@]}" \
--delete \
${BUILD_DIR_CI} ${DEPLOY_HOST}/
'''
}
}
post {
failure {
sh 'cat ${SPHINX_DIR}/rsync.log'
}
}
}Интеграция Jenkins и Bitbucket
Существует много способов организовать взаимодействие Jenkins и Bitbucket, но в нашем проекте мы решили использовать плагин Parameterized Builds for Jenkins. В официальной документации есть подробная инструкция по установке плагина, а также приведены настройки, которые должны быть заданы для обеих систем. Для работы с этим плагином необходимо создать пользователя Jenkins и сгенерировать для него специальный токен, который позволит этому пользователю авторизоваться в системе.
Создание пользователя и API-токена
Для создания нового пользователя в Jenkins необходимо перейти в раздел Настройки Jenkins -> Управление пользователями -> Создать пользователя, и в форме заполнить все необходимые учётные данные.
Механизм аутентификации, позволяющий сторонним скриптам или приложениям использовать API Jenkins без фактической передачи пароля пользователя, представляет собой специальный API-токен, который можно сгенерировать для каждого пользователя Jenkins. Для этого:
- авторизуйтесь в консоли управления, используя реквизиты пользователя, созданного ранее;
- перейдите в раздел Настроить Jenkins -> Управление пользователями;
- нажмите на значок шестерёнки справа от имени пользователя, под которым авторизовались в системе;
- в списке параметров найдите API Token и нажмите на кнопку Add new Token;
- в появившемся поле укажите идентификатор API-токена и нажмите кнопку Generate;
- следуя подсказке на экране, скопируйте и сохраните сгенерированный API-токен.
Теперь в настройках сервера Bitbucket можно указывать пользователя по умолчанию для подключения к Jenkins.
Заключение
Если раньше процесс состоял из нескольких шагов:
- загрузить обновление в репозиторий;
- дождаться подтверждения корректности;
- собрать сайт с документацией;
- обновить информацию на хосте;
то теперь достаточно нажать одну кнопку Merge в Bitbucket. Если после проверки не требуется вносить изменения в исходные файлы, то актуальная версия документации обновляется сразу же после подтверждения корректности данных.
Это значительно облегчает задачу технического писателя, избавляя его от большого количества ручных действий, а руководители проектов получают удобный инструмент для отслеживания дополнений документации и обратной связи.
Автоматизация этого процесса — первый шаг в построении инфраструктуры по управлению документацией. В дальнейшем мы планируем добавить автоматические тесты, которые будут проверять корректность внешних ссылок, используемых в документации, а также хотим создать интерактивные объекты интерфейса, встраиваемые в готовые темы для Sphinx.
Спасибо дочитавшим за внимание, скоро мы продолжим делиться подробностями создания документации в нашем проекте!


")

. Часть 1: Быстрый и базовый поиск")