
Развернутые ответы на вопросы открытой предметной области (Open-domain Long-form Question Answering, LFQA) — это одна из фундаментальных задач в обработке естественного языка (Natural Language Processing, NLP), которая включает в себя извлечение документов, относящихся к заданному вопросу, и их использование для генерации подробного ответа, доходящего до абзаца в длину. Несмотря на то что в последнее время был достигнут значительный прогресс в области ответов на фактоидные вопросы (QA) открытой предметной области, для которых достаточно короткой фразы или сущности, гораздо меньше было сделано в области ответов на вопросы в развернутой форме. Тем не менее, LFQA является важной задачей, особенно потому, что она предоставляет тестовую площадку для измерения фактологичности генеративных текстовых моделей. Но действительно ли существующие тесты и метрики подходят для дальнейшего развития технологий LFQA?
В статье «Hurdles to Progress in Long-form Question Answering» (появится на конференции NAACL 2021) авторы представляют новую систему для развернутых ответов на вопросы в открытой предметной области, которая использует два последних достижения в области NLP: 1) современные модели разреженного внимания, такие как Routing Transformer (RT), которые позволяют масштабировать модели на основе внимания для больших последовательностей, и 2) модели извлечения релевантных текстов, такие как REALM, которые облегчают извлечение статей в Википедии, связанных с заданным вопросом. Прежде чем генерировать текст, данная система объединяет информацию из нескольких релевантных статей, тем самым способствуя порождению более фактологически обоснованных ответов. Система устанавливает новую планку на ELI5, единственном крупном общедоступном наборе данных для развернутых ответов на вопросы.
Однако, несмотря на то, что данная система возглавляет рейтинг лучших моделей, авторы обнаружили несколько тревожных тенденций в наборе данных ELI5 и связанных с ним оценочных метриках. В частности, было замечено, что:
- существует мало свидетельств того, что модели действительно используют извлеченные тексты как основу для генерации;
- банальные базовые модели (например, копирование входа) превосходят современные системы, такие как RAG / BART+DPR;
- в наборе данных имеется значительное перекрытие между обучающей и валидационной подвыборками.
В своей статье авторы предлагают стратегии смягчения последствий для каждой из этих проблем.
Генерация текста
Основной рабочей лошадкой моделей NLP является архитектура Трансформера, в которой каждый токен в последовательности соответствует каждому другому токену, в результате чего модель масштабируется квадратично длине последовательности. Модель RT представляет динамический, основанный на содержимом механизм разреженного внимания, который снижает сложность внимания в модели Трансформера с n2 до n1.5, где n — длина последовательности, что позволяет масштабировать ее до более длинных последовательностей. Благодаря этому каждое слово соотносится с другими релевантными словами в любом месте всего фрагмента текста, в отличие от таких методов, как Transformer-XL, где слово может соотноситься только со словами в непосредственной близости от него.
Ключевой вывод из работы по RT заключается в том, что такая связь всех токенов часто является избыточной и может быть приближена к комбинации локального и глобального внимания. Локальное внимание позволяет создать локальное представление каждого токена на нескольких уровнях модели, где он соотносится с локальным соседством, обеспечивая локальную согласованность и беглость. В дополнение к локальному вниманию, модель RT также использует мини-пакетную кластеризацию k-средних (k-means clustering), чтобы каждый токен мог соответствовать только набору наиболее подходящих токенов.
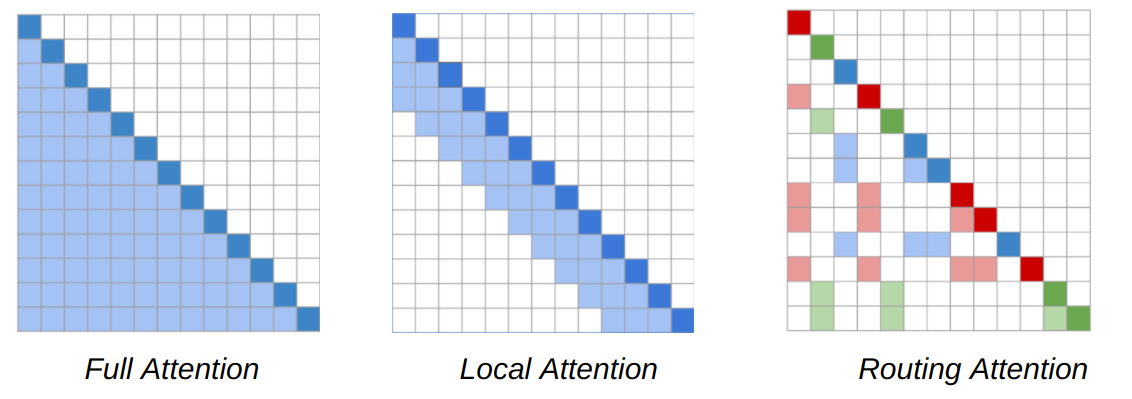
Карты внимания (attention maps) для основанного на содержимом механизма рассеянного внимания, используемого в Routing Transformer. Последовательность слов представлена диагональными квадратами темного цвета. В модели Трансформера (слева) каждый токен последовательности соотносится с каждым другим токеном. Более светлые квадраты представляют токены в последовательности, которой соответствует данный токен (темный квадрат). Модель RT использует как локальное внимание (в центре), где токены связаны только с другими токенами в своем локальном окружении, так и маршрутизирующее внимание (Routing Attention)(справа), в котором токен соотносится только с кластерами токенов, наиболее релевантных ему в контексте. Темно-красный, зеленый и синий токены относятся только к соответствующему цвету более светлых квадратов.
Авторы предварительно обучают RT-модель на наборе данных Project Gutenberg (PG-19) на задаче языкового моделирования, т.е. модель учится предсказывать следующее слово с учетом всех предыдущих слов, чтобы иметь возможность генерировать согласованный длинный текст.
Извлечение информации
Чтобы продемонстрировать эффективность модели RT для задачи LFQA, авторы объединяют ее с извлеченными текстами из REALM. Модель REALM (Guu et al. 2020) — это модель, которая использует поиск на основе максимума скалярного произведения (maximum inner product search) для извлечения статей Википедии, относящихся к определенному запросу или вопросу. Модель была адаптирована для ответов на фактоидные вопросы на наборе данных Natural Questions. REALM использует модель BERT для получения хороших векторных представлений вопроса и использует SCANN для извлечения статей Википедии, которые имеют большое сходство по тематике с векторным представлением вопроса. Затем в ходе end-to-end обучения максимизируется log-likelihood на задаче QA.
Далее авторы улучшают качество извлечений REALM с помощью контрастивной функции потерь (contrastive loss). Идея состоит в том, чтобы стимулировать сближение векторного представления вопроса к представлению правильного ответа на него и удаление от других ответов в его мини-батче. Это позволяет достичь того, что при извлечении релевантных позиций с помощью векторного представления вопроса будут отбираться статьи, «схожие» с правильными ответами. Авторы называют такой модуль контрастивным-REALM или c-REALM.

Объединенная система RT + c-REALM для LFQA.
Оценка
Авторы тестируют модель на развернутых ответах на вопросы с использованием
набора данных ELI5, который является частью теста KILT и единственным крупным общедоступным набором данных LFQA. Тест KILT измеряет извлечение текстов с помощью метрики Precision (R-Prec) и генерацию текста с помощью ROUGE-L. Объединив эти две метрики, авторы получают KILT R-L, которая определяет место модели в таблице лидеров. Авторы тонко настраивают предварительно обученную модель RT вместе с извлечениями из c-REALM на наборе данных ELI5 из KILT.
Результат авторов в таблице лидеров KILT для развернутых ответов на вопросы на ELI5 по объединенной метрике KILT R-L достигает 2.36. Этот результат превышает предыдущий результат на модели BART + DPR (KILT R-L равен 1.9), сохраняя схожее с другими моделями число параметров. В задаче генерации текста улучшение составляет +4.11, +5.78 и +9.14 по метрике Rouge-L для T5, BART + DPR и RAG соответственно.

Результаты авторов в таблице лидеров KILT для развернутых ответов на вопросы на ELI5.
Примеры генерации текста моделью RT
- Q: Why are almost all boats white?
Boats are generally painted white for obvious reasons, as they are inexpensive and easy to clean. Ships are also often painted to provide a visible visual contrast to the sea. Boats also often have high visibility ports to allow for easy international trade. In addition, many boats have an air-breathing function that makes them easier to spot and stay afloat, which is a good thing if you're a pirate or trying to get into some country's waters. Lastly, many ships are built in the last few decades, so they are not as exotic looking as they were thirty years ago. And lastly, many ships are made out of materials that are easy to work with, and so many of them are painted white as a practical matter. There are many, many more reasons for why ships are white, but those are the ones I know of. I'm sure there are many other reasons, but those are the ones I know of. Edit: I forgot to mention that the other answers about visibility and easy to see ports are also true. Ships are painted to appear to be larger, and more expensive. That makes them appear more impressive, and so they are more likely to be bought by people who want to show off their wealth and status.
- Q: What causes the trail behind jets at high altitude?
The same thing that causes the clouds you see at the start of a storm to form in the first place. The air pressure changes as the jet moves through the air, causing it to cool down and condense into water droplets. These droplets are in fact a lot bigger than the water droplets in the clouds, so when the plane passes through them, they can cause the air pressure to change, causing the water droplets to condense into clouds. This is what you see when you look at a cloud formation from the ground. In addition to this, when the plane passes through the clouds, it also moves through the air, causing it to change its temperature, causing the water droplets to condense and form clouds. These clouds are often quite large, and can block out the sun. This is what you see when you look at a contrail. Finally, the water vapor that forms at high altitudes is cooled by the air above, and as it cools, it condenses into clouds. This is what you see when you look at a cumulonimbus cloud. These clouds are even larger than the water droplets in the clouds, and they block out the sun.
- Q: How do shampoo and conditioner work?
The key ingredients in shampoo and conditioner are usually surfactants, they tend to attract oil from your skin. Shampoo will usually contain an anti-dandruff agent (dandruff is caused by fungi in your skin which cause dandruff). They also contain some moisturizing agents (moisturizers are things that stay in your skin longer and protect your scalp from cleaning), and a lot of anti-dandruff (dandruff is a side effect of high doses of both surfactants and moisturizers) Conditioner will contain moisturizing agents, like a skin moisturizer. They tend to cause oils to be separated from your hair (e.g. wash your hair with conditioner instead of shampoo). They both have a foaming agent that makes them foam up (usually Hydrogen Peroxide). They also have a foaming agent that stops dirt from attaching to your hair. Some conditioner will also suppress the action of the shampoo (to help prevent dirt from attaching to your hair).
- Q: When glancing at a clock, why does the first second after glancing at it sometimes feel longer than the rest?
This is known as chronostasis. Your brain gets used to seeing the second hand move after the first, so it ignores the first one. If you were to look at the clock a lot, you'd see the second hand move a lot more than the first, and you'd be able to tell the difference between the second and the first. The second hand will appear to move much slower than the first hand because your brain is used to seeing the second hand move a lot more than the first. If you were to go on a long trip, you'd get used to the second hand moving a lot more than the first, and you'd have no problem telling the difference between the second and the first hand. It's kind of like how you don't notice your nose when you're driving, but if you look at it for a while, you start to notice it. Your brain is just getting used to seeing the nose move a lot more than the other, and it can't tell the difference between the two. It's kind of like that with your eyes.
- Q: Why do Britain and other English empire countries still bow to monarchs? What real purpose does the queen serve?
Depends what you define as "purpose". There is no specific purpose for the British monarch — rather, they are figureheads that serve a role. The role is to have a high degree of influence over a country, though the rules of the monarchy can somewhat vary from country to country, and the ceremony of "kissing the royal corpse" does not always involve kissing the monarch. Whether that's the only reason for the custom, or if it was the only reason, I can't say, but that's the reasoning. When the U.K. was in full power, the monarch was a puppet of Parliament, and the powers of the monarch were transferred to the Prime Minister and thus to the Prime Minister's deputy, who then became the Prime Minister. Since then, Parliament has been able to vote on legislation that goes through the monarch, although they may still act as the monarch's representative in negotiating treaties, which can have very very deep consequences. The Queen's role, as a representative of Britain, doesn't necessarily involve her formal approval of any of the laws or legislation that goes through Parliament, though.
- Q: What exactly is fire, in detail? How can light and heat come from something we can't really touch?
Fire is the chemical reaction of fuel (oxygen) with (what we call) impurities (ash, soot, oil etc). These impurities are created due to a number of things. If you were to study the chemical composition of a log (or a candle) and analyse it you would discover the chemical formula (A, C, and G) which is a simplified version of what actually happens. There is always fuel, and there is always the ash/soot. Wood is made up of mostly carbon and hydrogen and these are the fuels that create the fire. Hydrogen and oxygen are reactive, and they form water (H2O) and CO2 (CO2). If we split a log into smaller pieces, we start to see the process of combustion as it occurs. The carbon is burned, and with the explosion of CO, H2O and H2CO2, we get water and carbon dioxide (mostly). If we smash a log together, we start to see what happens when we also hit another log with another log...imagine smashing two sand castles together. We see how the sand castles and brick castles form and collapse at different rates...then it starts to burn. The smoke, ash and flames are the actual combustion of fuel.
- Q: What goes on in those tall tower buildings owned by major banks?
The actual buildings are not there for profit but for show. There are many real world historical buildings that have little to no effect other than being a symbol of an economic entity or symbol of an era or location, and nothing more. For example look at Sears, Sears didn't care what went on inside, it was all about the _appearance_ of its location, the prestige of the location, the facilities and so on. It didn't care about how long it took it to operate, it was about how much people would pay to go see it. Sears was a landmark as a cultural movement and other big companies followed suit, so if you want to see a building you've never seen before, you have to go see Sears, just like you have to see a Toyota Camry for Toyota Camry. They used to be all about building new factories, some of them if I recall, but now that they're bigger, that means that more factory jobs are coming to them. You've probably seen them in stores as stores where people buy and sell stuff, so there aren't that many places for them to come from. Instead, it's just for show, a symbol of rich people.
Препятствия на пути к прогрессу в LFQA
Несмотря на то что система RT, описанная в данной статье, возглавляет публичную таблицу лидеров, подробный анализ модели и набора данных ELI5 позволяет выявить некоторые тревожные тенденции.
- Train/Valid Overlap
Многие отложенные вопросы перефразированы в обучающей выборке. Лучший ответ на подобные вопросы достигает ROUGE-L около 27.4.

- Gaming ROUGE-L
Простое извлечение ответов на случайные несвязанные вопросы из обучающей выборки дает относительно высокий ROUGE-L, в то время как фактические ответы хуже.

- Lack of Grounding
Условная генерации ответа на случайных документах вместо релевантных не оказывает заметного влияния на ее фактическую правильность. Чем больше длина сгенерированного текста, тем выше ROUGE-L.

Авторы отмечают, что практически отсутствуют доказательства того, что модель фактически основывает свою генерацию текста на извлеченных документах — тонкая настройка модели RT со случайным извлечением из Википедии (т.е. случайное извлечение + RT) работает почти так же хорошо, как c-REALM + RT модель (24.2 против 24.4 ROUGE-L). Они также обнаружили значительное совпадение в наборах для обучения, валидации и тестирования ELI5 (при этом несколько вопросов являются перефразированием друг друга), что может устранить необходимость в поиске. Тест KILT измеряет качество извлечения и генерации отдельно, не проверяя, действительно ли генерация текста использует извлечения.

Тривиальные базовые модели получают более высокие баллы Rouge-L, чем RAG и BART + DPR.
Более того, авторы обнаружили проблемы с метрикой Rouge-L, используемой для оценки качества генерации текста, с тривиальными бессмысленными базовыми моделями, такими как Случайный ответ обучающего набора (Random Training Set answer) и Копирование входных данных (Input Copying), которые достигают относительно высоких оценок Rouge-L (даже превосходящих BART + DPR и RAG).
Заключение
Авторы предложили систему развернутых ответов на вопросы на основе Routing Transformers и REALM, которая возглавляет таблицу лидеров KILT на ELI5. Однако подробный анализ выявляет несколько проблем с тестированием моделей, которые не позволяют использовать его для получения сведений о значимых достижениях в моделировании. Авторы выражают надежду, что сообщество будет работать вместе над решением этих проблем, и исследователи смогут покорить эту гору и добиться значимого прогресса в такой сложной, но важной задаче.
Авторы
- Автор оригинала – Aurko Roy
- Перевод – Смирнова Екатерина
- Редактирование и вёрстка – Шкарин Сергей
Интересные статьи
Интересные статьи
![[Интервью] В чем проблемы современных приложений для знакомств и как их решает голосовое общение](/upload/resize_cache/iblock/efc/105_70_0/efcc45caa1469502aa9c8e8e8184337c.jpeg "[Интервью] В чем проблемы современных приложений для знакомств и как их решает голосовое общение")


