
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

С вами на просторах Хабра два капитана команд сотрудников «Роснефти», которые участвовали в финале ИТ-марафона «Цифровой прорыв – 2020» и не могут об этом молчать.
Компания «Роснефть» весьма неравнодушна к айтишным событиям. Да что там, компания сама ежегодно генерирует хакатоны и челленджи (https://rn.digital/it2020), чтобы раскачивать ИТ-сообщество на решение актуальных для неё задач. Только вот в собственных хакатонах-марафонах «Роснефти» своим сотрудникам участвовать не положено – не этично по отношению к сторонним участникам. А ведь и им, разработчикам и программистам корпоративного наукоёмкого ПО, хочется померяться силушкой богатырской!
Поэтому участие сотрудников «Роснефти» в разных хакатонах – это своего рода поддержание коллектива в боевом состоянии, источник вдохновения и идей, поощрение развития нестандартных подходов к ИТ-задачам. Главное – не в ущерб основной работе, но это и так очевидно. Нефтяной лидер нацелен на цифровизацию бизнес-процессов и импортозамещение информационных технологий в области нефтегазодобычи, а потому наличие соревновательного духа у сотрудников компании и готовность составить конкуренцию всему остальному миру считаются хорошим тоном.
В этой статье сотрудники «РН-БашНИПИнефть» Чингиз Ахметов и Майя Бикметова в красках расскажут о пути своих команд к финалу крутого айтишного ивента, поделятся инсайтами и лайфхаками.
Чингиз Ахметов и команда «Inn BTG»
Сначала представимся. «Inn BTG» – это: «Innovatively. Brilliantly. Technologically. Grandly». А ещё это Владимир Рыжиков, Радмир Каримов и Мурад Мусин и Чингиз Ахметов.
Чуть больше года назад, когда в нашей родной Уфе проходил один из этапов хакатона «Цифровой прорыв – 2019», мы сформировали команду для участия в нём и включились в решение задачи. В тот памятный раз мы прошли в финал, который проводился в Казани! К сожалению, тогда не всем из нашей команды удалось поехать на мероприятие. Поэтому в авральном режиме остаткам команды пришлось формировать новую «банду» из таких же отщепенцев из других городов (нашей Уфе составили компанию Череповец и Санкт-Петербург). В финале, нам, к сожалению, не удалось победить или хотя бы получить номинацию. Поэтому, с прошлогоднего хакатона у нас остался только мерч в виде красивых ярких толстовок с символикой конкурса и незакрытый гештальт на победу в финале…
В связи с этим, в 2020 году за две недели до начала работы Уральского IT-хаба марафона «Цифрой прорыв – 2020», было принято волевое решение создать новую команду для блестящей и безоговорочной победы сначала в региональном, а потом и в финальном этапе конкурса.
Как и в прошлом году, костяк (3 бойца) сформировался из коллег одного отдела нашего научно-проектного института, которые сейчас разрабатывают программный комплекс для геологического моделирования нефтяных месторождений «РН-ГЕОСИМ». Также для надёжности команда была пополнена сотрудником банка, но не ради кредитов и ипотек, а так как он наш товарищ по бывшей студенческой скамье и он знает своё дело. Таким образом, удалось собрать «фантастическую четвёрку», где каждый участник имел опыт в определённых областях программирования, был в чём-то экспертом.
Скриншот трансляции во время объявления победителей кейса.
Как бывалые участники, хотим отметить рост уровня организации хакатона, чем в прошлом. В этом году больше задач, и они разнообразнее, например, появились задачи не только на веб-сервисы. В этот раз хакатон проходит в онлайн-формате, что значительно облегчило жизнь участникам и позволило сэкономить на транспортных расходах. Основные новости, интервью с интересными персонами, различные конкурсы и викторины транслируются на YouTube-канале. Информация для участников размещается на каналах в Telegram. В основном Telegram-чате конкурса происходит общение с поддержкой по общим вопросам, ответы приходят незамедлительно. Также присутствует канал для поиска участников и команды. Для общения внутри команды был выбран Discord (в нём же проходило общение с экспертами кейса на чекпоинтах). Словом, всё для людей!
Отдельно хотим поставить «плюс» за то, что теперь нет жёсткой привязки к региону: наша команда из Уфы, но мы в одно время были заняты и не смогли участвовать в Приволжском Хабе, но зато смогли посоревноваться в Уральском. Порадовало, что записи всех трансляций и потоковых защит выкладывают на YouTube-канале. Прозрачно и информативно.
Наша команда выбрала участие в решении кейса «Веломаршрут» от департамента информатизации Тюменской области: «Разработка программного обеспечения, позволяющего анализировать исходное размещение пешеходных переходов, велосипедных дорожек и фактическое пешеходное и велосипедное передвижения жителей города». Не то, чтоб мы прям такие фанаты великов. Эта задача была выбрана потому, что она была весьма подробно описана в интервью кейсодержателя (https://www.youtube.com/watch?v=hLPGCZ-5HRc), и основной целью было получение некоторой методики, алгоритма. Вот это, как раз, наша тема.

Команды перед стартом распределяли кейсы по своим приоритетам. Итоговое соотношение числа команд по кейсам на Уральском Хабе стали видны после старта.
Мы понимали, что очень важно выбрать инструменты, которые помогут сделать MVP (Minimum Viable Product, или по-нашему «продукт, обладающий минимальными, но достаточными для удовлетворения первых потребителей функциями») наиболее быстрым образом. Для нас ими стали Python с его библиотеками NetworkX (для работы с графами) и OSMnx (для представления OpenStreetMap данных в виде графа). Производительность такого решения оставляет желать лучшего, так как Python сам по себе медленный, и в NetworkX не было специализированных алгоритмов для работы с дорожными графами. В нашем прототипе время работы при достаточно мелкой кластеризации доходило до десятков минут. Понятно, что такое время неприемлемо для пользователя, но зато мы показали, что идея рабочая. В дальнейшем, считаем, расчётное ядро лучше переписать на компилируемый язык с использованием специализированных алгоритмов с распараллеливанием.
Краткая суть нашего алгоритма состоит в том, что весь город (схема работы алгоритма, слева, сверху) кластеризуется на участки. В каждом участке определяется степень востребованности в велодорожках (схема работы алгоритма, справа, сверху). Граф дорог фильтруется, оставляются только те дороги, где возможно проложить велодорожки. Затем отфильтрованный граф сопоставляется с кластером, и оставляются только те дороги, которые попадают в востребованные участки кластера (схема работы алгоритма, слева, снизу). Полученные островки соединяются алгоритмом кратчайших путей, чтобы система велодорожек была связной, то есть велосипедист смог проехать из одного района в любой другой (схема работы алгоритма, справа, снизу).

Схема работы алгоритма.
Мы распределились по подзадачам: один делал расчётную часть, второй поднимал сервер, третий делал визуализацию на веб-странице, четвёртый делал десктопную вьюшку. Удалось выполнить почти всё. Мы решили передавать результирующий граф на клиент целиком и рисовать через OpenLayers, хотя, наверное, лучше было бы развернуть свой тайл-сервер.
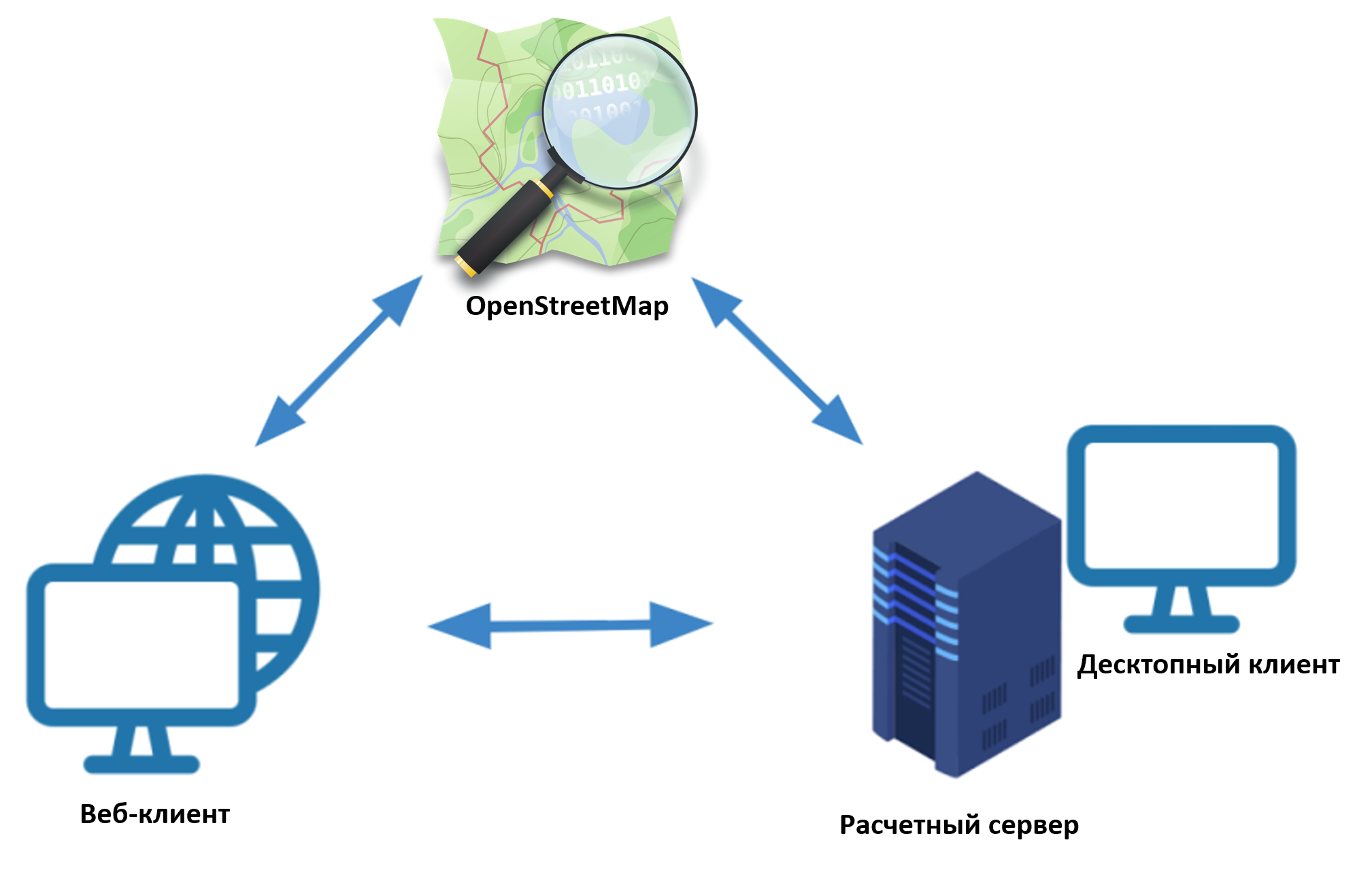
Схема разработанного MVP (неоптимальный).
Итоги финала
В финале конкурса «Цифровой прорыв» нам достался кейс от Министерства энергетики «Разработка системы моделирования зависимости потребления электроэнергии и экономических показателей Российской Федерации по территориям и отраслям». По сравнению с региональным этапом финальный был более масштабным: увеличилось количество кейсов (15 против 9), количество команд в кейсе (26 против 10). Также подрос призовой фонд для победителей, точные цифры можно увидеть на сайте https://leadersofdigital.ru.
В ходе работы над задачей и по результатам консультаций с держателями кейса мы решили реализацию проекта выполнить в Jupyter Notebook на Python, а для моделирования использовать методы эконометрики. Зависимой переменной модели был фактической объём энергопотребления, независимыми – объёмы добычи полезных ископаемых, обрабатывающей промышленности. Прогноз зависимой переменной выполнялся по следующему алгоритму:
1. Прогнозируется промышленное производство (строится линейный тренд):
a. Выделяется участок графика, который используется для расчёта коэффициентов тренда.
b. Методом наименьших квадратов определяются коэффициенты линейного тренда.
2. Строится модель зависимости тренда потребления электроэнергии от объёмов промышленного производства

3. Прогнозируется объём энергопотребления при помощи построенной модели и моделирования методом SARIMA (в этом нам здорово помогла статья https://habr.com/ru/company/ods/blog/327242/).
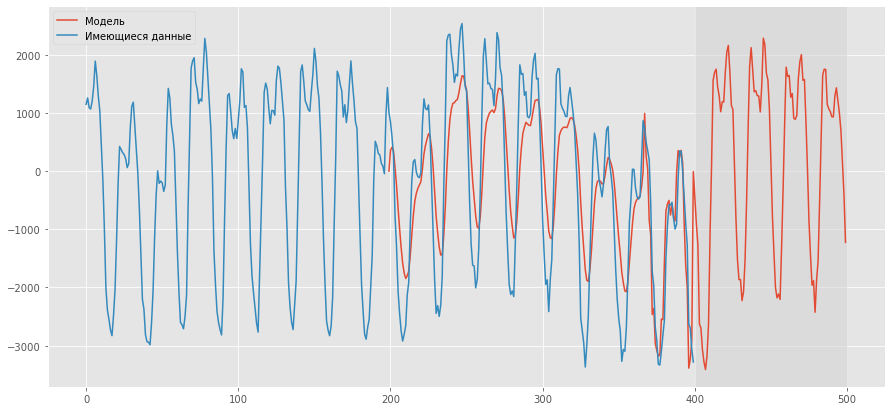
Результаты прогноза остатка.
К сожалению, выбранный подход немного не дотянул до призовой тройки, и мы заняли 22 место. Будем ли мы участвовать в подобных хакатонах в будущем? Конечно! Решение задач, не связанных с работой, позволяет потом и на рабочие задачи посмотреть свежим взглядом.
Майя Бикметова и «НеИИ»
За несколько недель до «Цифрового прорыва – 2020» я участвовала в другом, менее масштабном хакатоне, и моя команда взяла первое место. Наверное, это и повлияло на решение попробовать свои силы во всероссийском соревновании.
В команду я позвала коллег и друзей Марину Семёнову, Гузель и Наиля Акмурзиных, поскольку работать в режиме цейтнота гораздо легче со знакомыми ребятами. Так не тратится время на притирку, и все 30-36 часов хакатона можно посвятить разработке и созданию MVP. На Приволжский IT-хаб «Цифрового прорыва – 2020» мы заявились как команда «НеИИ». Это название с нами уже давно. Считаем, что оно лучше всего отражает нашу суть: работники научно-исследовательского института, занимающиеся развитием систем на основе искусственного интеллекта (ИИ).
Как уже писали коллеги (и они же конкуренты) выше, в связи со сложной эпидобстановкой хакатон проводился онлайн. У нас было три чекпоинта, на которых мы общались с модератором, техническим экспертом и представителем кейсодержателя. Они слушали наши идеи, давали советы, смотрели, что у нас сделано, оценивали нашу презентацию.
Всем командам был предоставлен список из 10 кейсов. При регистрации мы расставляли приоритеты. И один из наиболее приоритетных для команды кейсов должен был достаться ей на хакатоне. К тому же в каждом кейсе было общее описание задачи, а подробное – давали только в начале соревнования. Нам достался кейс, где было необходимо разработать интеллектуальную систему для автоматизации информирования и предоставления социальных льгот населению. Заказчиком данного кейса выступило Министерство социально-демографической и семейной политики Самарской области.

Общая схема разработанного решения.
Для обсуждения задач мы также общались в Discord. Вместе накидывали идеи по решениям, распределяли, кто и что будет делать. За логику сервера – backend и базу данных – отвечала Марина, за презентацию – Гузель, за frontend – Наиль. На себя я взяла разработку модели машинного обучения, управление командой и общение с кейсодержателем.
В результате работы над задачей мы реализовали прототипы двух систем.
1. Веб-приложение в виде чат-бота для информирования населения о положенных льготах.
В клиентской части гражданин описывает свою жизненную ситуацию. Полученный запрос отправляется на сервис NLP, который отвечает за обработку естественного языка. Под «капотом» происходит определение категории обращения пользователя с помощью методов машинного обучения. Другими словами, решается задача классификации текста. Прогноз NLP модели отправляется в базу данных. Из БД по ключу возвращается необходимая информация о полагаемых льготах и предоставляется снова клиенту.
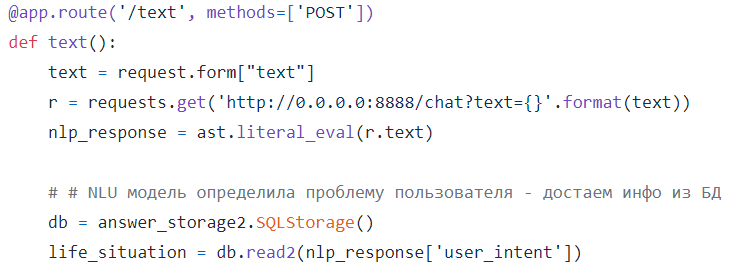
Главный backend скрипт обращается к NLP сервису и к базе данных.
В диалоговом окне пользователь видит, какие льготы ему положены, какие документы нужно собрать.

Скриншот работы прототипа чат-бота для информирования населения о льготах.
2. Сервис проверки обновления нормативных и законодательных актов.
В ходе общения с представителем кейсодержателя выяснилось, что большой болью работников соцзащиты является необходимость регулярно просматривать множество нормативных документов для оперативного выявления изменений в законодательстве. При наличии изменений сотрудник обновляет локальную базу данных. Естественно, на это тратится уйма сил и времени, и у сотрудников остаётся меньше времени на непосредственную работу с людьми. Мы убеждены, что такую рутинную работу можно и нужно автоматизировать.
В качестве первого приближения для решения этой проблемы мы предложили сервис, который на регулярной основе производит сравнение документов в локальной базе данных соцзащиты с теми же документами в БД некого онлайн-сервиса, например, «Консультант Плюс». При обнаружении различий в документах, сервис отправляет работнику соцзащиты оповещение типа «В документе X произошли изменения. Обновите локальную БД». Таким образом, сотрудник соцзащиты освобождается от необходимости перелопачивать кучу документов. Машина обнаружит изменения законов за него/неё, пока он/она работает с гражданами.
Если говорить о технической стороне вопроса, в качестве бейзлайна для решения задачи сравнения текстов мы использовали классический подход, часто применяемый в Information Retrieval, – представление документов в виде числовых векторов с последующей оценкой косинусного расстояния между ними.

Формула для расчета косинусного расстояния между векторами двух документов.
А теперь пара лайфхаков по выживанию на хакатонах. Рекомендуем в самом начале утвердить список и версии библиотек, с которыми предстоит работать. Это позволит избежать ситуаций, когда проект не собирается из-за конфликтов версий, а вам нужно сдавать код на проверку через 10 минут. К слову, лучше выложить ссылки на презентацию и решение за полчаса до окончания соревнования, а не оставлять это на последний момент. На хакатоне людей здорово заставил понервничать сайт, упавший за пять минут до окончательной сдачи всего проекта…

Используемые технологии: да здравствует open source! Главное следить за версиями фреймворков.
С одной стороны, хакатон – это соревнование технических специалистов, и жюри оценивает код: читабельность, работоспособность, архитектуру решения, документирование. С другой стороны, есть кейсодержатель, и его представители далеки от мира ИТ. Они, в первую очередь, оценивают красоту, логичность и понятность презентации, дизайн интерфейса. Другими словами, лучше в команде иметь человека, который будет заниматься только презентацией, того, кто с её помощью «продаст» решение кейсодержателю.
Итоги финала
К финалу «Цифрового прорыва – 2020» времени готовиться, к сожалению, не было. Работы к концу года традиционно становится больше. Так что мы полагались на удачу и друг на друга!
В финале хакатона мы были в том же составе. В этот раз нам попался кейс от Сбербанка: задача – создать решение, которое помогло бы ускорить работу с почтой. Оказалось, что это большая проблема, поскольку руководителям высшего звена приходится разбирать по 2000 писем в день, что занимает минимум 3 часа!
На первом чек-поинте нам сказали, что над данной проблемой разработчики Сбербанка уже давно ломают голову, но конкретного решения ещё не придумали – им нужна была идея, которая помогла бы им, наконец, к чему-то прийти.
И мы принялись думать. За 2 часа мы сгенерировали много разных интересных идей (это была самая творческая часть хакатона, поскольку один предлагал, другой дополнял, и эта идея превращалась в совершенный инструмент, который бы заменил обычную электронную почту =D).
В итоге мы задумали реализацию собственного почтового клиента «Сбер-секретарь», который бы превращал переписку в чат, чаты бы группировались по тематикам в папки, и система бы автоматически определяла важность переписки (чата). В чате можно бы было прослушивать непрочитанные сообщения, тексты сообщений можно бы было надиктовать, новое письмо создавалось бы одной голосовой командой, а на главном окне вместо одной переписки для ускорения могло бы отображаться от 1 до 4, и ещё несколько дополнительных фич.
Дальше мы распределили обязанности: я отвечала за серверную часть проекта, Наиль – за клиентскую часть, Марина разрабатывала дизайн в figma, а Гузель делала красивую и ёмкую презентацию и готовилась к защите.
Мы сразу знали, что не успеем сделать работающее приложение, но надеялись, что созреет хотя бы клиентская часть. Работы оказалось очень много, и по итогу мы показали в figma, каким бы функционалом обладал наш почтовый клиент, описали архитектуру проекта, назвали ряд преимуществ такого решения, привели сравнение с Outlook, стоимость проекта и этапы в реализации.
Думаю, можно сказать, что жюри наше решение понравилось, поскольку во время одного из чек-поинтов трекеры показали, что мы двигаемся в правильном направлении. Сделать рабочее приложение мы так и не успели, но вошли в топ-5 (5 место) из 11 команд. Что значит для нас 5 место? Это значит, у нас есть возможность показать лучший результат в следующий раз!
Если вы тоже участвовали в «Цифровом прорыве – 2020», то пишите в комментах свои впечатления и мысли!


 телефонной платформы. Часть 2")

