
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Читая различные каналы и рассылки, я часто встречаю статьи о конкретных «болях» и проблемах, возникающих при росте компании, когда надежность и масштабируемость выходят на первый план. Эта статья — иная. Здесь нет подробного разбора конкретных архитектурных решений или пошагового руководства по изменению инженерной культуры. Скорее, это взгляд сверху на те вызовы, которые возникают при эксплуатации распределенных систем, и отправная точка, которая поможет сориентироваться в потоке терминов, аббревиатур и технологий.
Предлагаю вашему вниманию перевод статьи, написанной инженером из Uber.
* * *
В последние несколько лет я создавал и обслуживал большую распределённую систему платежей в Uber. За это время я многое узнал о концепциях распределённых архитектур и на своём опыте выяснил, насколько трудно создавать и обслуживать высоконагруженные системы с высокой доступностью. Построение такой системы — работа интересная. Мне нравится планировать, как система будет обрабатывать рост трафика в 10-100 раз, обеспечивать надёжность данных вне зависимости от аппаратных сбоев. Однако эксплуатация большой распределённой системы дала мне неожиданный опыт.
Чем больше система, тем вероятнее, что вы столкнётесь с проявлением закона Мёрфи: «Всё, что может пойти не так, пойдёт не так». Вероятность особенно высока при частых релизах, когда много разработчиков выкатывают код, при использовании нескольких дата-центров и при огромной аудитории пользователей по всему миру. В последние несколько лет я столкнулся с разнообразными сбоями системы, многие из которых меня удивили: начиная от предсказуемых проблем, вроде аппаратных сбоев или невинных багов, заканчивая обрывом кабелей, которыми подключены дата-центры, и многочисленными каскадными сбоями, происходящими одновременно. Я прошёл через десятки сбоев, при которых части системы работали некорректно, что сильно влияло на бизнес.
В этой статье собраны методики, которые принесли пользу при эксплуатации большой системы в Uber. Мой опыт не уникален: другие работают с системами такого же размера и проходят через такие же приключения. Я разговаривал с инженерами из Google, Facebook и Netflix, которые столкнулись с аналогичными ситуациями и пришли к похожим решениям. Многие описанные здесь идеи и процессы могут применяться к системам того же масштаба, вне зависимости от того, работают ли они в дата-центрах принадлежащих компании (как это чаще всего бывает в Uber) или в облаке (куда Uber иногда масштабируется). Однако эти советы могут оказаться избыточными для не столь крупных или важных для компании систем.
Мы поговорим на такие темы:
- Мониторинг.
- Дежурства (on-call), обнаружение аномалий и оповещение.
- Сбои и управление инцидентами.
- Post Mortems, анализ инцидентов и культура постоянных улучшений.
- Отработка аварийных переключений, планирование ресурсов и blackbox-тестирование.
- SLO, SLA и отчётность по ним.
- SRE в качестве независимой команды.
- Надёжность как постоянная инвестиция.
- Полезные материалы.
Мониторинг
Чтобы понимать, здорова ли система, нам нужно ответить на вопрос: «Она работает корректно?». Для этого жизненно важно собирать информацию о критических частях системы. А когда у вас распределённые системы, состоящие из различных сервисов на многочисленных серверах и в разных дата-центрах, бывает трудно решить, какие ключевые моменты действительно нужно отслеживать.
Мониторинг состояния инфраструктуры. Если одна или несколько машин/виртуальных машин будут перегружены, то какие-то части распределённой системы могут деградировать по производительности. Метрики состояния машин, на которых работает сервис — потребление ресурсов процессоров и памяти — это базовые параметры, которые нужно мониторить. Есть платформы, которые изначально отслеживают эти метрики и автоматически масштабируют инстансы. В Uber замечательная команда базовой инфраструктуры, она по умолчанию обеспечивает мониторинг и оповещение. Вне зависимости от способа реализации, у вас обязательно должна быть информация о том, что у инстансов, инфраструктуры или отдельных сервисов возникли проблемы.
Мониторинг состояния сервиса: трафик, ошибки, задержка. Часто нужно иметь ответ на вопрос «Нормально ли работает бэкенд?». Наблюдение за такими метриками, как количество приходящего трафика, доля ошибок и задержка ответа, даёт ценную информацию о состоянии сервиса. Я предпочитаю делать информационные панели по всем этим метрикам. Когда вы создаёте новый сервис, использование правильных HTTP-ответов и мониторинг соответствующих кодов могут многое рассказать о состоянии системы. Если вы уверены, что коды 4xx возвращаются при ошибках клиентов, а 5xx — при ошибках серверов, то вам будет легко создать и интерпретировать такой мониторинг.
Нужно ещё кое-что сказать о мониторинге задержки ответа. Цель production-сервисов в том, чтобы большинству конечных пользователей нравилось ими пользоваться. И измерение средней задержки — не лучшее решение, потому что среднее значение может скрывать в себе небольшое количество запросов с большой задержкой. Гораздо лучше измерять p95, p99 или p999 — задержку для 95-го, 99-го или 99,9-го перцентиля запросов. Эти числа помогают ответить на вопросы вроде «Насколько быстрым будет запрос для 99 % посетителей?» (р99) или «Насколько медленным будет запрос для одного посетителя из 1000?» (р999). Если вас интересуют подробности, то можете почитать эту статью.
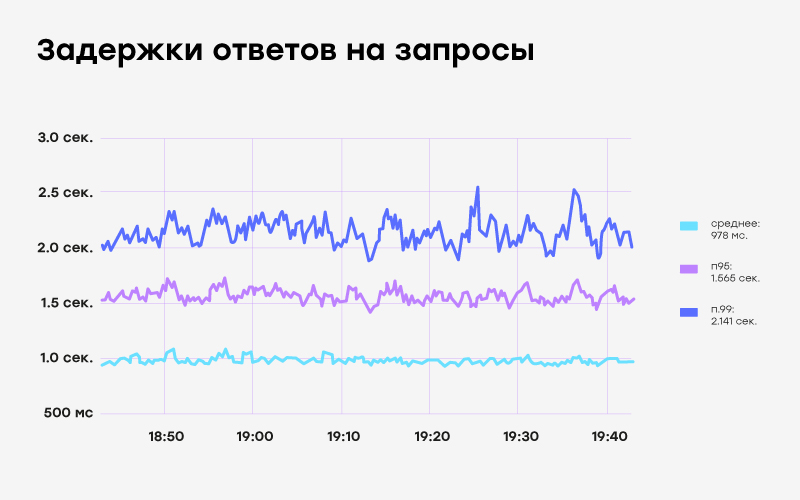
График для p95 и p99. Обратите внимание, что средняя задержка для этой конечной точки меньше 1 сек., а выполнение 1 % запросов занимает 2 сек. и более — этого не увидеть при измерении среднего значения.
Тема мониторинга и наблюдаемости (observability) гораздо глубже. Рекомендую почитать Google SRE book и раздел Four golden signals про мониторинг распределённых систем. Если для системы, с которой взаимодействуют пользователи, вы можете получить только четыре метрики, то сосредоточьтесь на трафике, ошибках, задержке и насыщении (saturation). Есть материал поменьше — электронная книга Distributed Systems Observability, в которой описываются такие полезные инструменты, как логи, а также лучшие методики использования метрик и трассировки.
Мониторинг бизнес-метрик. Мониторинг сервисов говорит нам об их состоянии в целом. Но по одним лишь данным мониторинга мы не можем сказать, работают ли сервисы штатно, всё ли корректно обрабатывается с точки зрения бизнеса. В случае с системой платежей основной вопрос такой: «Могут ли люди совершать поездки, используя конкретный метод оплаты?». Один из важнейших шагов в мониторинге заключается в определении и отслеживании бизнес-событий, которые создаются и обрабатываются этим сервисом.
Моя команда создала мониторинг бизнес-метрик после сбоя, который мы не могли выявить другими способами. Всё выглядело так, словно сервисы функционируют нормально, но на самом деле не работала ключевая функциональность. Такой вид мониторинга был весьма необычным для нашей компании и сферы деятельности. Поэтому нам пришлось приложить много усилий для настройки этого мониторинга под себя, создав собственную систему.
Дежурство, обнаружение аномалий и оповещение
Мониторинг — прекрасный инструмент для проверки текущего состояния системы. Но это лишь ступень на пути к автоматическому определению сбоев и оповещению тех, кто должен в этом случае что-то предпринять.
Дежурство — это обширная тема. Журнал Increment проделал прекрасную работу, осветив многие вопросы в номере On-Call. На мой взгляд, дежурство является логичным продолжением подхода «ты создал — ты и владеешь». Сервисами владеют команды, которые их сделали, и они же владеют системой оповещения и реагирования на инциденты. Моя команда владела такой системой для платёжного сервиса, который мы создали. И когда приходит оповещение, дежурный инженер должен среагировать и выяснить, что происходит. Но как нам перейти от мониторинга к оповещениям?
Определение аномалий на основе данных мониторинга — это трудная задача, и здесь в полной мере должно проявить себя машинное обучение. Есть много сторонних сервисов для определения аномалий. К счастью для моей команды, у нас в компании есть своя группа машинного обучения для решения задач, стоящих перед Uber. Нью-Йоркская команда написала полезную статью о том, как в Uber работает определение аномалий. С точки зрения моей команды, мы только передаём данные мониторинга в этот конвейер и получаем оповещения с различной степенью уверенности. А затем решаем, нужно ли сообщать об этом инженеру.
Когда нужно отправлять оповещение? Вопрос интересный. Если оповещений слишком мало, то мы можем пропустить важный сбой. Если слишком много, то люди не будут спать по ночам. Отслеживание и категоризация оповещений, а также измерение отношения сигнал/шум играет большую роль в настройке системы оповещения. Хорошим шагом на пути к устойчивой ротации дежурных инженеров будет анализ оповещений, категоризация событий на «требующие действий» и «не требующие», а затем уменьшение количества оповещений, не требующих действий.

Пример панели дежурства по вызову, созданной командой Uber Developer Experience в Вильнюсе.
Команда Uber по созданию инструментария разработчиков из Вильнюса создала небольшой инструмент, который мы используем для комментирования оповещений и визуализации дежурных смен. Наша команда еженедельно создаёт отчёт о работе последней дежурной смены, анализирует слабые места и улучшает методику дежурств.
Сбои и управление инцидентами
Представьте: вы дежурный инженер на протяжении недели. Посреди ночи вас будит сообщение на пейджер. Вы проверяете, случился ли сбой в production. Чёрт, похоже, часть системы упала. Что теперь? Мониторинг и оповещение только что сработали.
Сбои могут не представлять особых проблем для маленьких систем, когда дежурный инженер может понять, что и почему произошло. Обычно в таких системах можно быстро выявить причины и избавиться от них. Но в случае со сложными системами, содержащими много (микро)сервисов, когда много инженеров отправляют код в эксплуатацию, довольно трудно причину сбоя. И огромную помощь может оказать соблюдение нескольких стандартных процедур.
Первой линией обороны являются разработанные на случай оповещений перечни стандартных процедур реагирования (runbooks), в которых описываются простые шаги по устранению проблем. Если в компании такие перечни есть и активно поддерживаются, то поверхностное представление дежурного инженера о системе вряд ли окажется проблемой. Перечни необходимо поддерживать в актуальном состоянии, обновлять и перерабатывать под новые способы решения проблем.
Информирование о сбоях других сотрудников обретает большое значение, если выкаткой сервиса занимается несколько команд. В среде, в которой я работаю, сервисы по мере надобности выкатывают тысячи инженеров, с частотой в сотни релизов в час. И безобидная на первый взгляд выкатка одного сервиса может повлиять на другой. В такой ситуации важную роль играет стандартизация информирования о сбоях и каналов коммуникаций. У меня было много случаев, когда оповещение не было похоже ни на что другое, и я понимал, что для других команд это тоже выглядит странно. Общаясь в общем чате, посвящённом сбоям, мы выявляем сервис, ответственный за сбой, и быстро ликвидируем последствия. Вместе нам удаётся сделать это гораздо быстрее, чем любому из нас по отдельности.
Ликвидируйте последствия сейчас, а разбирайтесь завтра. В разгар аварии меня часто накрывала волна адреналина из-за желания исправить ошибки. Часто причиной проблемы было выкатывание плохого кода с очевидным багом. Раньше я бы всё бросил и начал править ошибки, отправлять фикс и откатывать сбойный код. Но исправлять причину посреди аварии ужасная идея. С быстрым исправлением можно мало добиться и много потерять. Поскольку фикс нужно делать быстро, тестировать его приходится в бою. А это путь к новому багу — или новому сбою — поверх уже имеющегося. Я видел, как это становилось причиной целого ряда сбоев. Просто сосредоточьтесь на устранении последствий, не поддавайтесь соблазну заняться исправлением кода или поиском причины. Расследование подождёт до завтра.
Post Mortems, анализ инцидентов и культура постоянных улучшений
Отчёт от инциденте — это важная характеристика того, как команда справляется с последствиями сбоя. Волнует ли людей возникшая ситуация? Проводят ли они небольшое исследование, или тратят удивительно много сил на наблюдения, останавливают работу продукта и вносят исправления?
Правильно написанный постмортем — это один из основных элементов построения устойчивых систем. В нём никого не осуждают и не ищут виновников, это вдумчивое исследование и анализ произошедшего инцидента. Со временем наши шаблоны для таких отчётов развивались, появились разделы с итоговыми выводами, оценкой влияния, хронологией событий, анализом главной причины, вынесенными уроками и подробным списком элементов для последующего наблюдения.
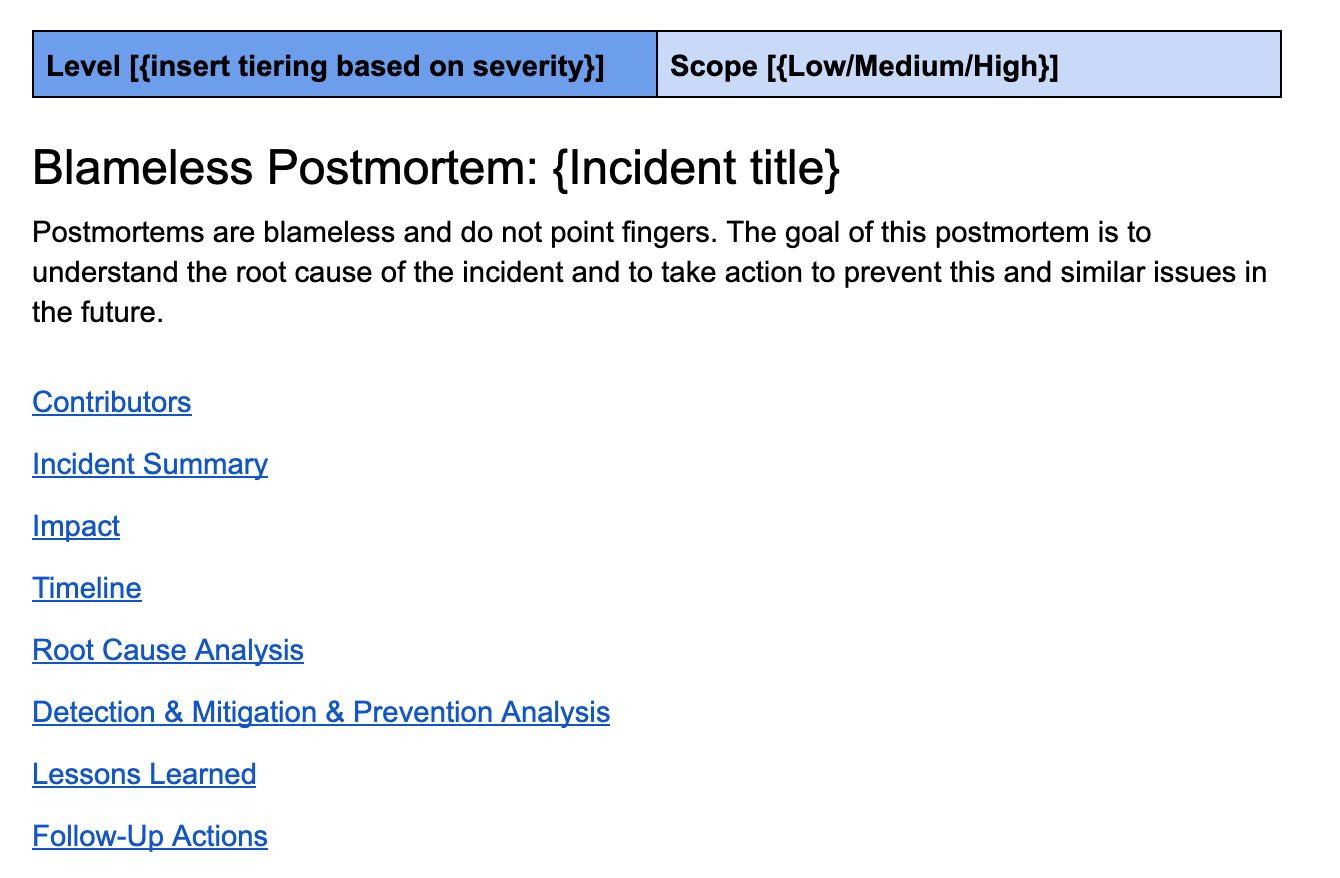
Такой шаблон работы над ошибками я использовал в Uber.
В хорошем постмортеме глубоко исследуется причина сбоя и предлагаются меры по предотвращению, обнаружению или скорейшей ликвидации последствий аналогичных сбоев. И когда я говорю «глубоко», я имею в виду, что авторы не останавливаются на том, что причиной стала накатка кода с багом, который не заметил рецензент. Авторы должны применять методику «пяти почему», чтобы придти к более полезному заключению. Например:
- Почему возникла проблема? --> Баг был залит как часть кода.
- Почему никто не поймал баг? --> Тот, кто делал ревью не заметил, что изменение кода может привести к такой проблеме.
- Почему мы зависим только от рецензента, который вылавливает этот баг? --> Потому что у нас нет автотеста для такой ситуации.
- Почему у нас нет автотеста для такой ситуации? --> Потому что её сложно тестировать без тестовых учётных записей.
- Почему у нас нет тестовых учётных записей? --> Потому что система их ещё не поддерживает.
- Заключение: это событие указывает на системную проблему отсутствия тестовых учётных записей. Предлагаем добавить их поддержку, а затем написать автоматизированные тесты для всех последующих аналогичных изменений кода.
Анализ инцидентов — важный сопутствующий инструмент для работы над ошибками. В то время, как одни команды проводят тщательную работу над ошибками, другие могут извлечь пользу из дополнительных данных и внести профилактические улучшения. Важно также, чтобы команды считали себя ответственными и способными сделать предлагаемые ими улучшения на системном уровне.
В организациях, серьёзно относящихся к надёжности, самые тяжёлые инциденты анализируются и устраняются опытными инженерами. Также необходимо управлять инжинирингом на уровне компании, чтобы обеспечить возможность внесения исправлений — особенно, если они требуют много времени или мешают другой работе. Надёжную систему не создать за одну ночь: потребуются постоянные итерации. Итерации, проистекающие из принятой в компании культуры постоянных улучшений на основе вынесенных из инцидентов уроков.
Отработка аварийных переключений, планирование ресурсов и blackbox-тестирование
Есть несколько регулярных процедур, которые требуют значительных инвестиций, но которые критически важны для поддержания работы большой распределённой системы. К этим идеям я впервые пришёл в Uber, применять их в других компаниях не требовалось из-за меньших масштабов и неготовности инфраструктуры.
Отработку аварийных переключений в дата-центре (failover) я считал глупостью, пока не столкнулся с этим сам. Изначально я считал, что проектирование устойчивой распределённой системы заключается в устойчивости дата-центров к падению. Зачем это регулярно тестировать, если всё должно теоретически работать? Ответ зависит от масштабирования и тестирования возможности сервисов эффективно обрабатывать неожиданное увеличение трафика в новом дата-центре.
Самый распространённый сценарий сбоя, с которым я сталкивался, заключается в том, что у сервиса нет достаточных ресурсов в новом дата-центре, чтобы обрабатывать глобальный трафик в случае аварийного переключения. Допустим, в одном дата-центре работает сервис А, а в другом — сервис Б. Пусть потребление ресурсов составляет 60 % — в каждом дата-центре крутятся десятки или сотни виртуалок, а оповещения срабатывают при достижении порога в 70 %. Произошло аварийное переключение всего трафика из дата-центра А в дата-центр Б. Второй дата-центр не может справиться с таким ростом нагрузки без развёртывания новых машин. Однако это может занять много времени, поэтому запросы начинают копиться и отбрасываться. Блокировка начинает влиять на другие сервисы, провоцируя каскадный отказ других систем, которые не имеют отношения к первичному аварийному переключению.

Возможная ситуация, когда аварийное переключение приводит к проблемам.
Ещё один популярный сценарий сбоя подразумевает наличие проблем на уровне маршрутизации, проблем с пропускной способностью сети или с back pressure. Аварийные переключения дата-центров — это отработка, которую любая надёжная распределённая система должна выполнять без какого-либо влияния на пользователей. Подчёркиваю — должна, эта отработка является одним из самых полезных упражнений на проверку надёжности распределённых веб-систем.
Упражнения по плановому простою сервиса — прекрасный способ тестирования устойчивости всей системы. Также это замечательный инструмент обнаружения скрытых зависимостей или неприемлемых/неожиданных использований конкретной системы. Упражнения по плановому простою можно относительно легко проводить с сервисами, с которыми взаимодействуют клиенты и у которых мало известных зависимостей. Однако если речь идёт о критически важных системах, для которых допустим очень короткий период простоя или от которых зависят многие другие системы, то проводить такие упражнения будет сложно. Но что произойдёт, если такая система однажды окажется недоступна? Лучше ответить на этот вопрос в рамках контролируемого эксперимента, чтобы все команды были предупреждены и готовы.
Blackbox-тестирование (метод «чёрного ящика») — это способ оценки корректности работы системы в ситуации, максимально приближенной к тому, как проходит взаимодействие с конечным пользователем. Это аналогично end-to-end тестированию, не считая того, что для большинства продуктов правильное blackbox-тестирование требует вложения собственных инвестиций. Хорошими кандидатами для такого тестирования являются ключевые пользовательские процессы и сценарии, в которых подразумевается взаимодействие с пользователем: для проверки работы системы делайте так, чтобы они могли быть запущены в любое время.
На примере Uber очевидным blackbox-тестом является проверка взаимодействия водитель-пассажир на уровне города: сможет ли пассажир по конкретному запросу найти водителя и совершить поездку? После автоматизации этого сценария тест можно прогонять регулярно, эмулируя разные города. Надёжная система blackbox-тестирования облегчает проверку корректности работы системы или её частей. Она также очень помогает с отработками аварийных переключений: самый быстрый способ получения обратной связи по переключению — прогнать blackbox-тестирование.
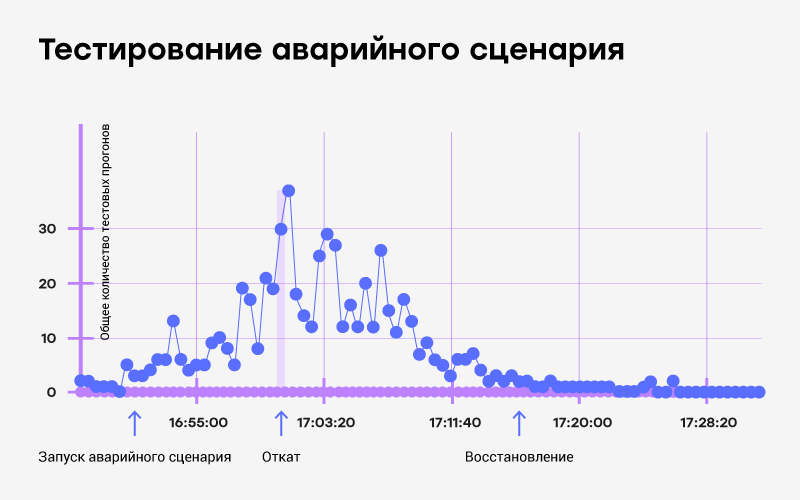
Пример blackbox-тестирования в ходе сбойной отработки аварийного переключения и ручного отката.
Планирование ресурсов играет особенно важную роль для больших распределённых систем. Под большими я подразумеваю те, у которых стоимость вычисления и хранения исчисляется в десятках или сотнях тысяч долларов в месяц. При таком масштабе может быть дешевле иметь фиксированное количество развёртываний, чем использовать самомасштабируемые облачные решения. В крайнем случае фиксированные развёртывания должны обрабатывать трафик, характерный для «обычного ведения бизнеса», с автоматическим масштабированием только при пиковых нагрузках. Но какое минимальное количество инстансов нужно применять в следующем месяце? В следующие три месяца? На следующий год?
Не трудно прогнозировать паттерны будущего трафика для зрелых систем с большими объёмами статистики. Это важно для бюджета, выбора вендоров или для фиксации скидок у облачных провайдеров. Если ваш сервис генерирует большие счета и вы не задумывались о планировании ресурсов, значит, вы упускаете простой способ снижения расходов и управления ими.
SLO, SLA и отчётность по ним
SLO означает Service Level Objective — это метрика доступности системы. Хорошей практикой является задавать SLO на уровне сервисов по производительности, времени ответа, корректности и доступности. Затем эти SLO можно использовать в качестве порогов для оповещений. Пример:
| SLO-метрика | Подкатегория | Значение для сервиса |
|---|---|---|
| Производительность | Минимальная пропускная способность | 500 запросов в секунду |
| Максимальная ожидаемая пропускная способность | 2 500 запросов в секунду | |
| Время ответа | Ожидаемая медианная длительность ответа | 50-90 мс |
| Ожидаемая длительность ответа p99 | 500-800 мс | |
| Точность | Максимальная доля | 0,5 % |
| Доступность | Гарантированная работоспособностьы | 99,9 % |
SLO на бизнес-уровне. или функциональные SLO, это абстракция над сервисами. Они охватывают пользовательские или бизнес-метрики. Например, SLO на бизнес-уровне может быть таким: ожидается отправка на почту 99,99 % чеков в течение 1 минуты после завершения поездки. Этот SLO может быть сопоставлен со SLO на уровне сервисов (например, с задержкой платежной системы или системы почтовой отправки чеков), а может измеряться отдельно.
SLA — Service Level Agreement. Это более общее соглашение между поставщиком сервиса и его потребителем. Обычно несколько SLO составляют SLA. Например, доступность платёжной системы на уровне 99,99 % может быть SLA, которое разбивается на конкретные SLO для каждой соответствующей системы.
После определения SLO нужно измерить их и составить отчёт. Автоматический мониторинг и отчётность по SLA и SLO часто представляет собой сложный проект, который не хотят ставить в приоритет ни инженеры, ни бизнес. Инженеры не будут заинтересованы, потому что у них уже есть разные уровни мониторинга для определения сбоев в реальном времени. А бизнес лучше приоритезирует доставку функциональности, а не вложение в сложный проект, который не даст немедленной выгоды.
И это приводит нас к другой теме: организациям, эксплуатирующим большие распределённые системы, рано или поздно понадобится выделять людей для обеспечения надёжности этих систем. Давайте поговорим о команде SRE — Site Reliability Engineering.
SRE в качестве независимой команды
Термин Site Reliability Engineering придумали в Google примерно в 2003-м, и сегодня там больше 1500 SRE-инженеров. Поскольку эксплуатация production-среды становится всё более сложной задачей, требующей всё большей автоматизации, в скором времени это превращается в полноценную работу. Это происходит тогда, когда компании понимают, что инженеры почти весь рабочий день занимаются автоматизацией production-среды: чем важнее системы и чем больше возникает сбоев, тем раньше SRE превращается в отдельную должность.
Быстрорастущие технологические компании зачастую рано выделяют SRE-команду, которая сама составляет для себя план. В Uber такая команда была создана в 2015-м, её целью было управление сложностью системы. В других компаниях выделение SRE-команды могут связать с созданием отдельной инфраструктурной команды. Когда компания дорастает до такого уровня, что обеспечение надёжности работы сервиса требует внимания существенного количества инженеров, то пора создавать отдельную команду.
Команда SRE значительно упрощает всем инженерам обслуживание крупных распределённых систем. Вероятно, SRE-команда владеет стандартными инструментами мониторинга и оповещения. Вероятно, они покупают или создают инструменты для организации дежурств (on-call) и готовы поделиться своим опытом. Они могут облегчить анализ инцидентов и создать системы, облегчающие обнаружение сбоев, снижение их последствий и предотвращение в будущем. SRE-команда, безусловно, облегчает отработку аварийных переключений. Она часто применяется для тестирования «чёрных ящиков» и планирования производительности. SRE-инженеры управляют выбором, настройкой или созданием стандартных инструментов для определения и измерения SLO и составления отчётности по ним.
Учитывая, что у всех компаний свои собственные проблемы, для решения которых и набирают SRE, такие команды в разных компаниях устроены по-разному. Даже названия могут различаться: это может быть служба эксплуатации, платформенный инжиниринг или служба инфраструктуры. Google опубликовала две обязательные для прочтения книги об обеспечении надежности работы сервисов. Они выложены в свободный доступ и являются отличным источником информации для более глубокого изучения темы SRE.
Надёжность как постоянная инвестиция
При создании любого продукта сборка первой версии — лишь начало. После этого будут новые итерации, с новыми возможностями. Если продукт успешен и приносит прибыль, то работа продолжается.
У распределённых систем такой же жизненный цикл, за исключением того, что им нужно больше инвестиций не только в новые фичи, но и в то, чтобы идти в ногу с масштабированием. Когда возрастает нагрузка на систему, приходится хранить больше данных, над системой работает больше инженеров, приходится постоянно заботиться о её нормальном функционировании. Многие из тех, кто впервые создают распределённые системы, считают их чем-то вроде машины: один раз сделаешь и достаточно проводить определённое техобслуживание раз в несколько месяцев. Трудно придумать сравнение, более далёкое от реальности.
Мне нравится сравнивать эксплуатацию распределённой системы с управлением большой организацией, например, больницей. Чтобы больница работала хорошо, нужны постоянные проверки (мониторинг, оповещения, тестирование методом «чёрного ящика»). Всё время нужно принимать новый персонал и оборудование: для больниц это медсёстры, врачи и медицинские устройства, а для распределённых систем — новые инженеры и сервисы. По мере увеличения количества сотрудников и сервисов старые методы работы становятся неэффективными: маленькая клиника в сельской местности работает иначе, чем крупная больница в мегаполисе. Достижение более эффективных способов функционирования превращается в полноценную работу, и всё большее значение обретают измерения и оповещения. Как в большой больнице требуется больше обслуживающего персонала вроде бухгалтерии, отдела кадров и службы безопасности, так и эксплуатация больших распределённых систем опирается на обслуживающие команды вроде инфраструктурной и SRE.
Чтобы команда могла поддерживать надёжную распределённую систему, организация должна постоянно инвестировать в её функционирование, а также в работу платформ, на которых построена система.
Полезные материалы
Хотя статья получилась длинной, в ней представлены лишь самые поверхностные моменты. Чтобы подробнее изучить особенности эксплуатации распределённых систем, рекомендую эти источники:
Книги
- Google SRE Book — замечательная бесплатная книга Google. Для этой статьи особенно важна глава Monitoring Distributed Systems.
- Distributed Systems Observability, ещё одна прекрасная бесплатная книга с отличными советами по мониторингу распределённых систем.
- Designing Data-Intensive Applications — самая практическая книга по концепции распределённых систем, что мне попадалось. Однако в ней не так глубоко освещены эксплуатационные аспекты, которые мы рассмотрели.
Сайты
- Издание On-Call журнала Increment: серия статей о процессах реагирования на инциденты в компаниях Amazon, Dropbox, Facebook, Google и Netflix.
- Learning to Build Distributed Systems — статья AWS-инженера, отвечающая на вопрос «как научиться создавать большие распределённые системы?»
См. комментарии к этой статье на Hacker News.




