

На железячных форумах периодически поднимается тема про «40 000 часов». Речь о том, что из-за бага в прошивке некоторые накопители выходят из строя через 40 000 часов работы (четыре года, 206 дней, 16 ч).
Это не городская легенда, а реально известный баг у некоторых SSD производства SanDisk, которые повсеместно используются в индустрии, в том числе в серверах, NAS и других сетевых продуктах разных фирм.
С точки зрения сисадмина, выход из строя одного накопителя через четыре года — не такое критическое событие, если у нас резервные копии на нескольких SSD. Хотя постойте…
Вообще, об этой проблеме известно как минимум с 2019 года. Однако в то время мало кто обратил внимание на эту информацию…
Баги в прошивках
В 2020 году компания Hewlett-Packard рекомендовала обновить прошивки четырёх фирменных SSD:
- HPE 800GB 12G SAS WI-1 SFF SC SSD (номер детали 846622-001)
- HPE 800GB 12G SAS MU-1 SFF SC SSD (846624-001)
- HPE 1.6TB 12G SAS WI-1 SFF SC SSD (846623-001)
- HPE 1.6TB 12G SAS MU-1 SFF SC SSD (846625-001)
Эти накопители поставляются с множеством сетевых продуктов HPE, включая HPE ProLiant, Synergy, Apollo 4200, Synergy Storage Modules, D3000 Storage Enclosure, StoreEasy 1000 Storage.
К сожалению, прошивка проприетарная, код не публикуется в открытом доступе, как и патчи для него. В описании патча от Dell написано, что он исправляет «ошибку проверки максимального значения индекса циркулярного буфера» (судя по всему, максимально допустимое значение уменьшалось на единицу при каждой проверке). То же самое написано в исправлении прошивки Lightning Gen II SAS:

Годом ранее Hewlett-Packard сообщала о похожем баге, когда SSD тоже выходил из строя через определённое количество часов, а именно 32 768.
32 768 часов
В ноябре 2019 года речь шла о двадцати моделях SSD, которые поставляются с серверами и хранилищами HPE ProLiant, Synergy, Apollo, JBOD D3xxx, D6xxx, D8xxx, MSA, StoreVirtual 4335 и StoreVirtual 3200:
Список SSD, подверженных «внезапной смерти»:
- HP 480GB 12Gb SAS 2.5 RI PLP SC SSD (номер детали 817047-001)
- HP 960GB 12Gb SAS 2.5 RI PLP SC SSD (817049-001)
- HP 1.92TB 12Gb SAS 2.5 RI PLP SC SSD (817051-001)
- HP 3.84TB 12Gb SAS 2.5 RI PLP SC SSD (817053-001)
- HP 400GB 12Gb SAS 2.5 MU PLP SC SSD S2 (822784-001)
- HP 800GB 12Gb SAS 2.5 MU PLP SC SSD S2 (822786-001)
- HP 1.6TB 12Gb SAS 2.5 MU PLP SC SSD S2 (822788-001)
- HP 3.2TB 12Gb SAS 2.5 MU PLP SC SSD S2 (822790-001)
- HPE 480GB SAS SFF RI SC DS SSD (875681-001)
- HPE 960GB SAS SFF RI SC DS SSD (875682-001)
- HPE1.92TB SAS RI SFF SC DS SSD (875684-001)
- HPE 3.84TB SAS RI SFF SC DS SSD (875686-001)
- HPE 7.68TB SAS 12G RI SFF SC DS SSD (870460-001)
- HPE 15.3TB SAS 12G RI SFF SC DS SSD (870462-001)
- HPE 960GB SAS RI SFF SC DS SSD (P08608-001)
- HPE 1.92TB SAS RI SFF SC DS SSD (P08609-001)
- HPE 3.84TB SAS RI SFF SC DS SSD (P08610-001)
- HPE 3.84TB SAS RI LFF SCC DS SPL SSD (P11360-001)
- HPE 7.68TB SAS RI SFF SC DS SSD (P08611-001)
- HPE 15.3TB SAS RI SFF SC DS SSD (P08612-001)
В официальном руководстве компания Hewlett-Packard рекомендует владельцам потенциально уязвимых SSD проверить параметр
Power-on Hours в программе мониторинга Smart Storage Administrator.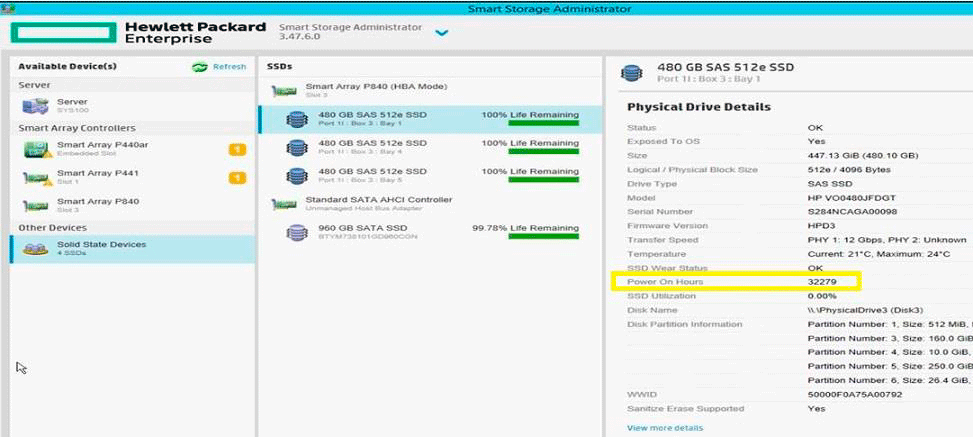
В случае необходимости патч устанавливается специальным инструментом для прошивки HDD/SSD под VMware ESXi, Windows и Linux.
«После выхода из строя SSD ни сам накопитель, ни данные восстановить невозможно. Кроме того, SSD, которые введены в эксплуатацию в одно и то же время, скорее всего, выйдут из строя почти одновременно», — сказано в сообщении HP.
Основным виновником сбоя HP назвала «стороннего подрядчика, который занимался разработкой и производством SSD для компании». Конкретное имя подрядчика не прозвучало, но шила в мешке не утаишь. Вскоре выяснилось, что это были накопители SanDisk (подразделение Western Digital).
SanDisk — один из крупнейших в мире производителей SSD, а львиную долю накопителей он производит по заказу крупных вендоров, так что они продаются не под маркой SanDisk, а под маркой HPE, Cisco и др.
В феврале 2020 года об аналогичном баге предупредила компания Dell:

Как можно понять, затронуты различные модели SSD SanDisk ёмкостью от 200 ГБ до 1,6 ТБ. Теоретически, «внезапная смерть» может затронуть устройства разных вендоров под другими брендами. Некоторые из них не признались публично, что использовали эти SSD. Они надеются на авось, что немногие пострадавшие спишут сбой на «естественные причины».
Падение Hacker News
Таким образом, в мире продолжают работают десятки тысяч непропатченных SSD, которые с каждой минутой приближаются к роковому времени. Новости о багах прошивок в 2019 и 2020 годах прошли, по сути, незамеченными. Мол, это какие-то корпоративные продукты… Никто не думал, что проблема затронет лично его. Но вот наступил «час Х».
8 июля 2022 года упал популярный сайт Hacker News. Разработчики по всему миру целый день маялись без привычного чтива, ведь в западном IT-сообществе это чуть ли не главный сайт для новостей и общения, примерно как Хабр в русскоязычном сегменте.
Когда упал основной сервер HN, нагрузку перевели на резервный — но он тоже упал.
Естественно, возникает вопрос, как у главного IT-сайта в мире могут возникнуть такие проблемы с бэкапами? А вот так. Как потом выяснилось, основные и резервные серверы работали на накопителях SanDisk Optimus Lightning II и отработали примерно одинаковый срок. Cкладывается впечатление, сисадмины HN вообще не могли представить, что все накопители могут выйти из строя в одну минуту:

На обоих серверах работала установка RAID, то есть как минимум четыре SSD вышли из строя почти одновременно.
Это нормальная ситуация, когда несколько серверов запускается в один день. На каждом стоит массив RAID из двух или более накопителей. Казалось бы, это гарантирует почти абсолютную защиту от фатальных сбоев и аптайм 99,999%. По теории вероятности, ну как могут четыре накопителя в двух RAID выйти из строя одновременно? А вот бывает.
К счастью, у Hacker News нашлись резервные копии на других серверах (с другими накопителями), так что через шесть часов после второго падения работа сайта была восстановлена через 14 часов после падения первого сервера (и через 8 часов после второго).
И это не единственный случай, когда несколько HDD/SSD выходят из строя в один момент.
Чёрные лебеди
«Чёрный лебедь» — явление очень редкое, но с катастрофическими последствиями. Однако на бесконечно длинном промежутке времени вероятность даже самого редкого события стремится к 1. То есть прилёт «чёрного лебедя» можно гарантировать на 100%. Вопрос только в том, когда это случится.
И вопрос в том, насколько адекватно мы оцениваем риски, то есть насколько реалистично оцениваем вероятность того или иного события. История с четырьмя SSD показывает — то, что мы считали как четыре разных события (перемножая их вероятности), на самом деле может оказаться одним событием.
А ведь такое очень часто происходит и на работе, и в жизни. Мы строим десяток «запасных планов» на все случаи. А потом оказывается, что все «запасные стратегии» накрылись из-за одного-единственного события. И на самом деле это вовсе не «запасные стратегии», а скорее иллюзия безопасности, самообман.
Из этой истории напрашивается вывод. Если опасности не видно, то последствия сбоя могут оказаться хуже, чем если мы заранее предусмотрели множество рисков и продумали сценарии ответных действий.
Получается, что чем больше рисков мы видим перед собой — тем лучше. И наоборот, самая опасная ситуация — когда всё вокруг хорошо и спокойно. Это реальный повод включать все сигнализации.
В ментальной модели будущего человек видит те варианты развития событий, которые способен понять в силу имеющихся знаний и информации. Воображение помогает представить, какие знания у нас отсутствуют, чтобы дополнить ментальную модель (второй шаг в технике Фейнмана). Но воображение тоже не безгранично…
Мне кажется, отсюда возникает побочное следствие — самый худший сценарий невозможно представить (потому что всегда возможен ещё более худший). И это в каком-то смысле успокаивает, потому что перфекционизм оказывается ни к чему. Достаточно сделать только то, что в наших силах, и успокоиться на этом.
Ну а практический вывод из этой истории такой, что в один RAID нежелательно ставить накопители одной модели, а тем более из одной партии (с серийными номерами подряд).




