
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Лесли Лэмпорт — автор основополагающих работ в распределённых вычислениях, а ещё вы его можете знать по буквам La в слове LaTeX — «Lamport TeX». Это он впервые, ещё в 1979 году, ввёл понятие последовательной согласованности, а его статья «How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs» получила премию Дейкстры (точней, в 2000 году премия называлась по-старому: «PODC Influential Paper Award»). Про него есть статья в Википедии, где можно добыть ещё несколько интересных ссылок. Если вы в восторге от решения задач на happens-before или проблемы византийских генералов (BFT), то должны понимать, что за всем этим стоит Лэмпорт.
Эта хабрастатья — перевод доклада Лесли на Heidelberg Laureate Forum в 2018 году. В докладе пойдёт речь о формальных методах, применяемых в разработке сложных и критичных систем вроде космического зонда Rosetta или движков Amazon Web Services. Просмотр этого доклада является обязательным для посещения сессии вопросов и ответов, которую проведет Лесли на конференции Hydra — эта хабрастатья может сэкономить вам час времени на просмотр видео. На этом вступление закончено, мы передаём слово автору.
Когда-то давно Тони Хоар написал: «В каждой большой программе живет маленькая программа, которая пытается выбраться наружу». Я бы это перефразировал так: «В каждой большой программе живет алгоритм, который пытается выбраться наружу». Не знаю, правда, согласится ли с такой интерпретацией Тони.
Рассмотрим в качестве примера алгоритм Евклида для нахождения наибольшего общего делителя двух положительных целых чисел . В этом алгоритме мы присваиваем значение , — значение , и затем отнимаем наименьшее из этих значений от наибольшего, пока они не оказываются равны. Значение этих и и будет наибольшим общим делителем. В чем существенное отличие этого алгоритма и программы, которая его реализует? В такой программе будет много низкоуровневых вещей: у и будет определенный тип, BigInteger или что-то в таком роде; нужно будет определить поведение программы в случае, если и неположительные; и так далее и тому подобное. Четкой разницы между алгоритмами и программами нет, но на интуитивном уровне мы чувствуем отличие — алгоритмы более абстрактные, более высокоуровневые. И, как я уже сказал, внутри каждой программы живет алгоритм, который пытается выбраться наружу. Обычно это не те алгоритмы, про которые нам рассказывали в курсе алгоритмов. Как правило, это алгоритм, который полезен только для данной конкретной программы. Чаще всего он будет значительно сложнее тех, которые описаны в книгах. Такие алгоритмы зачастую называют спецификациями. И в большинстве случаев выбраться наружу этому алгоритму не удается, потому что программист не подозревает о его существовании. Дело в том, что этот алгоритм нельзя увидеть, если ваше мышление сосредоточено на коде, на типах, исключениях, циклах while и прочем, а не на математических свойствах чисел. Программу, написанную таким образом, сложно отлаживать, поэтому что это значит отлаживать алгоритм на уровне кода. Средства отладки предназначены для того, чтобы находить ошибки в коде, а не в алгоритме. Кроме того, такая программа будет неэффективной, потому что, опять-таки, вы будете оптимизировать алгоритм на уровне кода.
Как и почти в любой другой области науки и техники, решить эти проблемы можно, описав их математически. Для этого существует много способов, мы рассмотрим наиболее полезный из них. Он работает как с последовательными, так и с параллельными (распределенными) алгоритмами. Заключается этот метод в том, чтобы описать выполнение алгоритма как последовательность состояний, а каждое состояние — как присвоение свойств переменным. Например, алгоритм Евклида описывается как последовательность следующих состояний: вначале x присваивается значение M (число 12), а y — значение N (число 18). Затем мы отнимаем меньшее значение от большего ( от ), что приводит нас к следующему состоянию, в котором мы отнимаем уже от , и на этом выполнение алгоритма останавливается: .
Назовем последовательность состояний поведением, а пару последовательных состояний — шагом. Тогда любой алгоритм можно описать множеством поведений, которые представляют все возможные варианты выполнения алгоритма. Для каждого конкретного M и N есть только один вариант выполнения, поэтому для его описания достаточно множества из одного поведения. У более сложных алгоритмов, в особенности параллельных, множества поведений большие.
Множество поведений описывается, во-первых, начальным предикатом для состояний (предикат — это просто функция с булевым значением); и, во-вторых, предикатом следующего состояния для пар состояний. Некоторое поведение входит в множество поведений только если начальный предикат верен для , и предикаты следующего состояния верны для каждого шага . Попробуем описать таким образом алгоритм Евклида. Начальный предикат здесь такой: . А предикат следующего состояния для пар состояний здесь описывается следующей формулой:

Пожалуйста, не пугайтесь — в ней всего шесть строк, разобраться в них очень просто, если делать это по порядку. В этой формуле переменные без штрихов относятся к первому состоянию, а переменные со штрихами — это те же переменные во втором состоянии.
Как видим, первая строка гласит, что в первом случае x больше y в первом состоянии. После логического И утверждается, что значение x во втором состоянии равно значению x в первом состоянии минус значение y в первом состоянии. После еще одного логического И утверждается, что значение y во втором состоянии равно значению y в первом состоянии. Все это значит, что в случае, когда x больше y, программа отнимет y от x, а y оставит неизменным. Последние три строки описывают случай, когда y больше x. Обратите внимание, что эта формула ложна, если x равен y. В этом случае следующего состояния нет, и поведение останавливается.
Итак, мы только что описали алгоритм Евклида двумя математическими формулами — и нам не пришлось связываться ни с каким языком программирования. Что может быть прекраснее этих двух формул? Заменить их одной формулой. Поведение является выполнением алгоритма Евклида только в том случае, если:
- верно для ,
- верно для каждого шага .
Записать это как предикат для поведений (будем называеть его свойством) можно следующим образом. Первое условие можно выразить просто как . Это значит, что мы интерпретируем предикат состояния как верный для поведения только в том случае, если он верен для первого состояния. Второе условие записывается так: . Квадрат означает соответствие между предикатами пар состояний и предикатами поведений, то есть верно для каждого шага в поведении. В итоге формула выглядит так: .
Итак, мы записали алгоритм Евклида математически. В сущности, это просто определения, или сокращения для и . Полностью эта формула выглядела бы так:

Не правда ли, она прекрасна? К сожалению, для науки и техники красота не является определяющим критерием, но она говорит о том, что мы на правильном пути.
Свойство, которое мы записали, верно для некоторого поведения только в том случае, если выполняются два условия, которые мы только что описали. При и они верны для следующего поведения: . Но эти условия также выполняются для более коротких версий того же поведения: . А их мы не должны учитывать, поскольку это просто отдельные шаги уже учтенного нами поведения. Есть очевидный способ от них избавиться: просто не учитывать поведения, которые заканчиваются состоянием, для которого возможен хотя бы один следующий шаг. Но это не совсем правильный подход, нам нужно более общее решение. Кроме того, такое условие не всегда работает.
Обсуждение этой проблемы приводит нас к понятиям безопасности и активности. Свойство безопасности указывает, какие события допустимы. Например, алгоритму разрешается вернуть правильное значение. Свойство активности указывает, какие события должны рано или поздно произойти. Например, алгоритм рано или поздно должен вернуть некоторое значение. Для алгоритма Евклида свойство безопасности выглядит следующим образом: . К этому необходимо добавить свойство активности, чтобы исключить преждевременные остановки: . В языках программирования в лучшем случае есть некоторое примитивное определение активности. Чаще всего активность даже не упоминается, просто подразумевается, что следующий шаг в программе обязательно должен произойти. И чтобы добавить это свойство, нужен довольно замысловатый код. Математически же активность выразить очень легко (как раз для этого нужен тот квадратик), но, к сожалению, у меня на это нет времени — нам придется ограничить наше обсуждение безопасностью.
Небольшое отступление только для математиков: каждое свойство является множеством поведений, для которых это свойство верно. Для каждого множества последовательностей существует естественная топология, которую создает следующая функция расстояния:
Расстояние между этими двумя функциями — ¼, поскольку первое различие между ними — на четвертом элементе. Соответственно, чем более продолжителен участок, на котором эти последовательности идентичны, тем ближе они друг к другу. Сама по себе эта функция не так уж и интересна, но она создает очень интересную топологию. В этой топологии свойства безопасности являются замкнутыми множествами, а свойства активности являются плотными множествами. В топологии одна из фундаментальных теорем гласит, что каждое множество является пересечением замкнутого множества и плотного множества. Если вспомнить, что свойства — это множества поведений, то из этой теоремы следует, что каждое свойство является конъюнкцией свойства безопасности и свойства активности. Это вывод, который будет интересен в том числе и программистам.
Частичная корректность означает, что программа может остановиться только в том случае, если выдаст правильный ответ. Частичная корректность алгоритма Евклида гласит, что если он завершил выполнение, то . А завершает выполнение наш алгоритм в случае, если . Иначе говоря, . Частичная правильность этого алгоритма означает, что эта формула верна для всех состояний поведения. Добавим в ее начало символ , который означает «для всех шагов». Как видим, в формуле нет переменных со штрихом, так что ее истинность зависит от первого состояния в каждом шаге. А если нечто верно для первого состояния каждого шага, то это утверждение верно для всех состояний. Частичная корректность алгоритма Евклида удовлетворяется любым поведением, допустимым для алгоритма. Как мы видели, поведение допустимо в том случае, если истинна только что приведенная формула. Когда мы говорим, что свойство удовлетворено, это просто значит, что это свойство следует из некоторой формулы. Не правда ли, это прекрасно? Вот она:
Перейдем к инвариантности. Квадрат со скобками после него называется свойство инвариантности:
Значение, заключенное в скобки после квадрата, называется инвариант:
Как доказать инвариантность? Чтобы доказать , нужно доказать, что для любого поведения следствием является истинность для любого состояния . Мы можем доказать это методом индукции, для этого нам необходимо доказать следующее:
- из следует, что верно для состояния ;
- из следует, что если верно для состояния , то оно также
верно для состояния .
Вначале нужно доказать, что подразумевает . Поскольку формула утверждает, что верно для первого состояния, это значит, что верно для первого состояния. Далее, при , верном для любого шага, и , верном для , верно для , потому что значит, что верно для любой пары состояний. Это записывается так: , где — это для всех переменных со штрихом.
Инвариант, отвечающим двум условиям, которые мы только что доказали, называется индуктивным инвариантом. Частичная корректность не индуктивна. Чтобы доказать ее инвариантность, нужно найти индуктивный инвариант, который ее подразумевает. В нашем случае индуктивный инвариант будет такой: .
Каждое следующее действие алгоритма зависит от его текущего состояния, а не от прошлых действий. Алгоритм удовлетворяет свойству безопасности, поскольку в нем сохраняется индуктивный инвариант. Алгоритм Евклида может вычислить наибольший общий знаменатель (т. е. он не останавливается, пока его не достигнет) благодаря тому, что в нем есть инвариант . Чтобы понять алгоритм, необходимо знать его индуктивный инвариант. Если вы изучали верификацию программ, то вы знаете, что только что приведенное доказательство инварианта — это ни что иное, как метод доказательства частичной корректности последовательных программ Флойда-Хоара. Возможно, вы также слышали о методе Овики-Грис, который является распространением метода Флойда-Хоара на параллельные программы. В обоих случаях индуктивный инвариант пишется при помощи аннотации программы. И если это делать при помощи математики, а не языка программирования, это делается предельно просто. Именно это лежит в основе метода Овики-Грис. Математика делает сложные явления значительно доступнее для понимания, хотя сами явления, конечно же, от этого не станут проще.
Взглянем подробнее на формулы. Если в математике мы написали формулу с переменными и , это не значит, что других переменных не существует. Можно добавить еще одно уравнение, в котором поставлено в отношение к , это ничего не поменяет. Просто формула ничего не говорит ни о каких других переменных. Я уже говорил, что состояние — это присвоение значений переменным, сейчас к этому можно добавить: всем возможным переменным, начиная и и заканчивая населением Ирана. Должен признаться: когда я сказал, что формула описывает алгоритм Евклида, я соврал. На самом деле она описывает вселенную, в которой значения и представляют выполнение алгоритма Евклида. Вторая часть формулы () утверждает, что каждый шаг изменяет или . Иначе говоря, она описывает вселенную, в которой население Ирана может измениться только в том случае, если изменилось значение или . Из этого следует, что в Иране никто не может родиться после того, как завершено выполнение алгоритма Евклида. Очевидно, это не так. Исправить эту ошибку можно в том случае, если у нас допустимы шаги, для которых и остаются неизменными. Поэтому к нашей формуле нужно добавить еще одну часть: . Для краткости запишем это так: . Эта формула описывает вселенную, содержащую алгоритм Евклида. Те же изменения нужно внести в доказательство инварианта:
- Доказываем:
- С помощью:
Это изменение отвечает за безопасность алгоритма Евклида, поскольку теперь возможны поведения, в которых значения и не изменяются. Исключить такие поведения нужно с помощью свойства активности. Это сделать довольно просто, но сейчас я про это говорить не буду.
Поговорим о реализации. Предположим, у нас есть некоторая машина, которая реализует алгоритм Евклида подобно компьютеру. Она представляет числа как массивы 32-битных слов. Для простых операций сложения и вычитания ей нужно множество шагов, как компьютеру. Если пока не трогать активность, то такую машину мы также можем представить формулой . Что мы подразумеваем, когда говорим, что машина Евклида реализует алгоритм Евклида? Это значит, что следующая формула верна:

Не пугайтесь, мы сейчас рассмотрим ее по порядку. Она гласит, что наша машина удовлетворяет некоторому свойству (). Этим свойством является формула Евклида , многоточия — это выражения, которые содержат переменные машины Евклида, а — это подстановка. Иначе говоря, вторая строка — это формула Евклида, в которой и заменены на выражения в многоточиях. В математике нет общепринятого обозначения подстановки, поэтому мне пришлось придумать его самому. По сути, формула Евклида () — это сокращение для формулы:
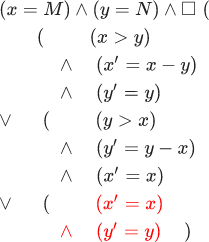
Красным выделена часть формулы, позволяющая и в оставаться неизменными.
Описанное выражение утверждает не только, что машина реализует алгоритм Евклида, но и что она делает это с учетом указанных подстановок. Если просто взять пару программ и сказать, что переменные этих программ связаны с и — бессмысленно говорить, что всё это «реализует алгоритм Евклида». Обязательно указать, как именно алгоритм будет реализован, почему после всех подстановок формула станет истинной. Сейчас у меня нет времени, чтобы показать, что описанное выше определение является правильным, вам придется поверить мне на слово. Но вы, я думаю, уже оценили, насколько оно простое и элегантное. Математика действительно прекрасна — при помощи нее мы смогли определить, что значит, что один алгоритм реализует другой.
Чтобы доказать это, необходимо найти подходящий инвариант машины Евклида. Для этого необходимо выполнить следующие условия:
Не будем сейчас в них вникать, просто обратите внимание на то, что это обычные математические формулы, хоть и не самые простые. Инвариант объясняет, почему машина Евклида реализует алгоритм Евклида. Реализация означает подстановку выражений на место переменных. Это вполне обычная математическая операция. Но в программе такую подстановку выполнить невозможно. Нельзя подставить a + b на место x в выражении присвоения x = …, такая запись не будет иметь смысла. Тогда как определить, что одна программа реализует другую? Если вы думаете только в рамках программирования — это невозможно. В лучшем случае вы сможете найти какое-нибудь мудреное определение, но гораздо более хороший способ — перевести программы в математические формулы и использовать определение, которое я привел выше. Перевести программу в математическую формулу значит дать программе семантику. Если машина Евклида является программой, а — ее математическая запись, то показывает нам, что это значит, что «программа реализует алгоритм Евклида». Языки программирования очень сложные, поэтому этот перевод программы на язык математики тоже сложный, так что на практике мы так не делаем. Просто языки программирования не предназначены для того, чтобы писать на них алгоритмы. Важность приведенного примера в том, что математика здесь показывает, что нужно сделать, чтобы реализовать алгоритм Евклида в программе: нужно определить, как x и y представлены в терминах состоянии программы и рассказывает, и что нужно дальше делать. Но, конечно, в первую очередь, для написания алгоритмов не стоит использовать язык программирования.
Кто-то обязательно скажет: математика работает на мелких выдуманных примерах, все знают, что в реальном мире программистам приходится иметь дело с огромными системами, и там от нее нету толку. На самом деле, это так только кажется. Единственное отличие алгоритма Евклида и большого алгоритма — это размер формулы. Вместо шести строк предикат следующего состояния может занимать несколько сотен или тысяч строк. Для таких больших формул мы используем иерархическую декомпозицию, так мы боремся со сложностью. В программировании есть множество мудреных методов для этого, но самый простой и мощный метод — математический, и этот способ называется определение. Чтобы выполнить иерархическую декомпозицию вот этой формулы:

мы даем имена частям этой формулы. Назовём вот эту часть :
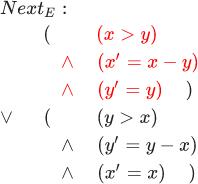
а вот эту часть — :
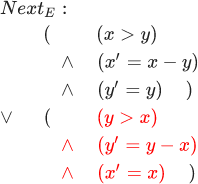
Поэтому можно сказать, что:

Проще определений ничего не придумать.
Поговорим о реальных примерах математического описания алгоритмов. Rosetta — космический зонд, сделанный Европейским космическим агентством для исследования одной кометы. Некоторые ее инструменты управлялись операционной системой реального времени Virtuoso. Ее создатели затем сделали следующую версию этой системы и написали о ней книгу. Высокоуровневая структура там описана на TLA+, это язык для математической записи алгоритмов. Он работает по тем же принципам, что и примеры, которые я приводил в этом докладе. Процитирую отрывок из письма, которое мне прислал Эрик Верхольст (Eric Verhulst), он руководил разработкой системы. Я спросил его, принес ли им пользу TLA+, на что он ответил: «Во многом благодаря TLA+ нам удалось создать значительно более чистую архитектуру. Нам стали видны последствия многолетней промывки мозгов из-за программирования на C. Одним из результатов использования TLA+ стало уменьшение размера кода в десять раз по сравнению с Virtuoso». Вдумайтесь в эту цифру. Просто качественным программированием сокращения кода в десять раз не достичь. Для этого нужна более чистая архитектура, или, другими словами, более совершенный алгоритм. А для этого нужно математическое мышление. А к математическому мышлению приучает TLA+. Если вы мыслите в рамках языка программирования, такого результата вам не достичь.
Из космоса спустимся на облака. В Communications of the ACM несколько лет тому назад была ]опубликована статья о том, как веб-сервисы Amazon используют формальные методы. Amazon Web Services — это те, кто создают облачную инфраструктуру Amazon. Формальный метод, о котором идет речь — это всё тот же TLA+. Основные выводы статьи следующие. Во-первых, при помощи формальных методов удается найти баги в структуре системы, которые невозможно обнаружить никаким другим известным авторам способом. Подчеркну, это пишут программисты, которые в течение долгого времени занимаются распределенными системами. Во-вторых, по их мнению, формальные методы на удивление легко приживаются с общепринятыми методами разработки ПО и отлично окупаются. Нужно сказать, что авторы — люди, которые не витают в облаках, они привыкли оценивать технологии в долларовом эквиваленте. В-третьих, статья сообщает нам, что в Amazon формальные методы систематически применяются для проектирования сложных программ, включая публичные облачные сервисы. Мне недавно говорили, что около 10% программистов в этих группах используют TLA+.
Другой пример — Microsoft. Эпизодически там TLA+ применяется начиная с 2004 года. В конце 2015 года я написал короткую статью про TLA+, в которой было описано в т. ч. его применение в Amazon Web Services. Эту статью прочитал генеральный директор Microsoft Сатья Наделла, и на следующий день после рождества того года он отправил письмо высшему руководству компании, в котором рекомендовал им также познакомиться с этой статьёй. Приведу цитату: «С учетом сложности параллельных распределенных систем мы должны обеспечить корректность алгоритмов на уровне проектирования, в противном случае у нас возникнут проблемы в будущем». К счастью, в Microsoft по-прежнему пост генерального директора занимает бывший программист. Дальше он пишет: «Нам следует постараться вдохновить как можно больше программистов на использование этих методов». В 2016-17 гг. я провел три трёхдневных курса по TLA+, их прошли около 150 программистов, в основном работавших на Azure (облачная платформа Microsoft). Два менеджера из Azure сделали презентацию на семинаре в апреле 2018 года, в которой говорилось, что сложные системы требуют строгого математического мышления на каждом этапе их разработки. Они цитировали меня: «Продумывание задачи не гарантирует, что вы не совершите ошибок. Но если вы ее не продумываете, вы гарантированно сделаете ошибки». В презентации также говорилось о необходимости моделировать систему целиком, то есть всю вселенную, которая включает систему и ее среду. И здесь опять-таки на помощь приходит математика: код хорош для написания системы, но для ее среды необходимо нечто более простое и выразительное. В заключение было сказано, что нужно мыслить математически, и что многие программисты этого не делают.
Процитирую другого менеджера, который говорил о необходимости интегрировать TLA+ в культуру программирования. Этого он предлагал достичь, нанимая программистов с опытом работы в TLA+, интегрируя тренинги по TLA+ в курс адаптации новых программистов и в курс учебного лагеря Azure, и требуя, чтобы каждый анализ причин багов корректности в продакшне сопровождался спецификацией на TLA+. Последняя мера гарантирует, что человек понял первопричину бага. Наконец, автор также говорил о необходимости требовать спецификацию на TLA+ для гарантий, которые заявляет сервис. Сегодня Microsoft выпускает новую версию Cosmos DB, это глобальная база данных, от которой в значительной степени будет зависеть будущее всей компании. Насколько мне известно, этот проект пока что очень успешен. В его разработке использовался TLA+, и гарантии условий правильности, предоставляемые пользователям, сопровождаются в нем спецификациями на TLA+.
TLA+ — это язык для математического описания алгоритмов. В нем есть мощные инструменты для проверки свойств инвариантности и активности и их реализации. Но TLA+ не является лучшим языком для описания всех возможных алгоритмов. Для начала, не все алгоритмы стоят того, чтобы их описывать на полностью формальном языке. Инструменты TLA+ не подходят для многих областей, они лучше всего работают с распределенными системами. Но главное другое: опыт TLA+ доказывает, что математическое описание алгоритмов работает на практике.
В каждой большой программе живет алгоритм, который пытается выбраться наружу. И прежде, чем начинать писать программу, нужно найти и понять этот алгоритм. А лучше всего это можно сделать, описав его математически. Если алгоритмы сложных распределенных систем в Amazon и Microsoft можно описать математически, то и с вашими алгоритмами это получится. Не позволяйте языкам программирования промыть вам мозги, пусть математика освободит ваш разум.
Напоминаю, что это перевод. Когда вы будете писать комментарии — помните, что автор их не прочитает. Если вам действительно хочется пообщаться с автором, то он будет на конференции Hydra 2019, которая пройдёт 11-12 июля 2019 года в Санкт-Петербурге. Билеты можно приобрести на официальном сайте.

