
Команда VK Cloud перевела статью о том, как с течением времени менялась и развивалась архитектура данных и какие инструменты появлялись в ответ на потребности бизнеса.
Введение
Задачи по работе с данными отделяют от бизнес- и других аналитических задач (BI, дата-сайенс, когнитивные решения и т. п.) с тех пор, как появились первые ИТ-системы и бизнес-приложения. Из-за высокой ресурсоемкости рабочие нагрузки по аналитической обработке данных приходится отделять от ИТ-систем, отвечающих за бизнес-операции, иначе они столкнутся со сбоями и нехваткой ресурсов, что приведет к неудобствам для пользователей, работающих с системой.
В последние годы резко возросла наша зависимость от больших данных и бизнес-аналитики — по прогнозам, к 2030 году этот рынок вырастет на 684,12 млрд долларов. Во всем мире компании из разных отраслей вкладывают средства в анализ огромных объемов информации и создают эффективные стратегии по работе с данными. Архитектура данных — это каркас ИТ-инфраструктуры, на котором держится стратегия по работе с данными, фундамент, без которого невозможна ее эффективная реализация. Эволюция именно архитектуры данных на протяжении многих лет влияла наэффективность стратегии.
Модели данных, архитектура и системы хранения постепенно развивались, подстраиваясь под решение разнообразных аналитических задач. В этой статье мы расскажем о разных архитектурах данных, которые формировались как ответ на непрерывно растущие аналитические потребности бизнеса. Подробному описанию каждой такой архитектуры можно было бы посвятить целую книгу, но в статье нам придется ограничиться несколькими абзацами. Наша задача — привести общую характеристику каждой архитектуры.

Эволюция архитектуры данных
1. ODS, EDW и витрины данных
В давние времена в помощь системам поддержки решений был разработан оперативный склад данных (ODS), предназначенный в основном для сотрудников, которым для работы нужны были стандартные отчеты. В ODS хранятся только текущие данные, используемые для рабочей отчетности и принятия тактических решений, например на уровне работника банковского отделения. Обычно данные в ODS живут не дольше полугода. Он помогает решить, предложить ли клиенту овердрафт, увеличить ли для него кредитный лимит и другие подобные задачи.
Появление инструментов бизнес-аналитики расширило круг пользователей аналитических отчетов: теперь в него вошло и высшее руководство, предпочитающее изучать обобщенную информацию в графическом виде. Для удобства этой категории пользователей были разработаны витрины данных и методы пространственного моделирования, например, схемы типа «звезда» и «снежинка». Витрины данных обычно используют для дескриптивной и диагностической аналитики в той или иной предметной области. Они помогают пользователям понять, что и почему произошло или происходит, а также анализировать возможные ситуации.
Хотя ODS и витрины данных для аналитики используют разные группы пользователей, они так или иначе ограничены конкретными функциональными областями. Корпоративные хранилища данных (EDW) были разработаны под потребности кросс-функционального анализа. Хранилища содержат данные за продолжительный период и предназначены для обнаружения долгоиграющих паттернов. В зависимости от предпочтений организации в их проектировании используются методы ER (Entity-Relationship, «сущность — связь») и пространственного моделирования.
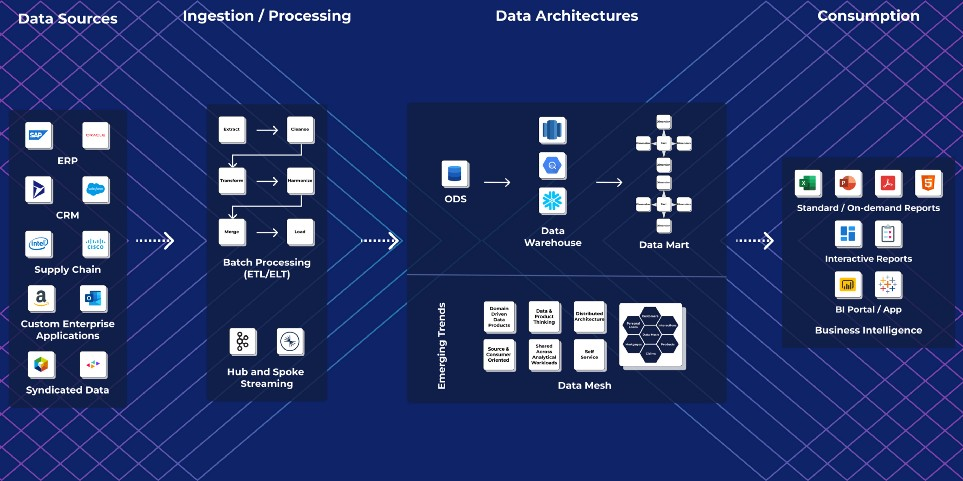
Архитектура решения корпоративной аналитики данных на этом этапе развития
2. MDDB
ODS, витрины данных и EDW обычно реализованы в связке с традиционными реляционными СУБД: DB2, Oracle и SQL Server. Они предназначены для подготовки типовых отчетов и дашбордов для руководства в пакетном режиме по установленному расписанию, чаще всего каждый день. Но при подготовке нетиповых отчетов и выполнении интерактивного анализа у таких инструментов возникают серьезнейшие ограничения производительности.
Для выполнения этих задач были разработаны многомерные базы данных (MDDB): Oracle Express, Cognos Power Play, Hyperion Essbase и другие. Из-за ограничений размера (каждый блок базы мог, как правило, вместить 2 Гб данных) MDDB использовались, чтобы формировать витрины для аналитики в определенных предметных областях: финансовом планировании и составлении смет, бухгалтерском учете, закупках, продажах, маркетинге и т. п. Благодаря MDDB у пользователей появилась возможность выполнять интерактивный анализ с детализацией и переходами на уровень ниже или выше, анализ возможных ситуаций и сценарное планирование, пускай и с ограничениями по конкретной функциональной области.
3. Специальные устройства для хранилищ данных
Чтобы обнаруживать новые паттерны, аналитические приложения должны обрабатывать данные на обобщенном уровне. Традиционные реляционные СУБД, например DB2, Oracle и SQL Server, которые работают на универсальном или стандартном оборудовании, не справляются с такими рабочими нагрузками.
Для решения этой проблемы на рынке появились СУБД Teradata, устройства Netezza, Neoview, Parallel Data Warehouse и SAP HANA. Они работают на специализированном аппаратном обеспечении, в котором используется архитектура с массовым распараллеливанием и обработкой в памяти, за счет чего достигается необходимый рост производительности. Для этих устройств характерен некий флер корпоративного хранилища данных. Но из всех этих технологий большой популярностью пользуется только Teradata.
4. Озера данных
ODS, EDW и витрины данных работают только со структурированными корпоративными данными. Они не могут обрабатывать и анализировать полуструктурированные (JSON, XML и т. п.) и неструктурированные данные (тексты, документы, изображения, видео, аудио и т. п.). Кроме того, они появились еще до облачных технологий. В те времена существовала тесная связка между ресурсами для хранения и вычислительными ресурсами. В результате приходилось закладываться на пиковые нагрузки приложения, понимая, что большую часть времени ресурсы будут использоваться не на полную катушку.
Со временем появился еще один вариант архитектуры — озеро данных. Хотя по своему назначению озеро напоминает EDW или витрину, оно способно работать с полуструктурированными и неструктурированными данными. Озера также лучше подходят для работы в облачной инфраструктуре.
Хранилища и витрины данных создаются с определенной, заранее известной целью. Озера данных предназначены для всевозможных необработанных данных, которые при минимальной стоимости хранения можно обрабатывать в разных целях. Это позволяет обгонять на поворотах хранилища, витрины или дата-пайплайны для когнитивных или аналитических приложений.
Поскольку в озере хранится необработанная данные, на этапе его создания не надо продумывать схему данных. Это отличает его от хранилищ и витрин, которым для загрузки нужна предварительно определенная схема.
Популярности озера данных способствуют невысокая стоимость этого объектного хранилища и поддержка открытого формата, в отличие от дорогих проприетарных хранилищ. Но и у озера есть свои недостатки:
- отсутствие поддержки транзакционных приложений;
- низкая надежность;
- низкое качество данных;
- принудительное применение мер безопасности;
- снижение производительности при увеличении объема данных.
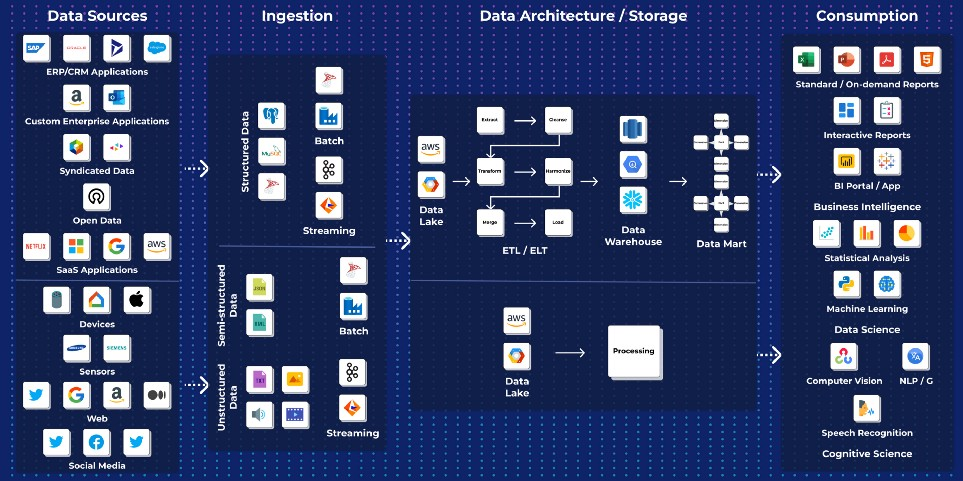
Архитектура озера данных
5. Data Mesh
И хранилище, и озеро — это централизованные решения, для которых характерны ограничения масштабируемости и доступности при потреблении данных. На работу этих решений уходит много времени, они ограничивают понимание данных в ключе доменов и ориентированы скорее на технологии, чем на пользователей. Их проектируют и используют data-инженеры. — Это немногочисленная группа специалистов, что ограничивает масштабируемость и затрудняет демократизацию данных для анализа. Data-инженеры не связаны с бизнес-приложениями, генерирующими данные, так что таким решениям не хватает контекста и понимания данных с точки зрения бизнеса.
Для преодоления этих проблем была разработана архитектура и концепция Data Mesh. В рамках этого подхода данные организуют как data-продукты наряду с разными функциональными и предметными областями. С ними работают сотрудники, отвечающие за бизнес-приложения, так что им понятны контекст, значение и использование данных с точки зрения бизнеса. При проектировании и распространении аналитических data-продуктов их владельцам помогают data-инженеры. Составляется каталог data-продуктов, который виден каждому пользователю в организации. Такие пользователи понимают контекст любого конкретного data-продукта и могут правильно его интерпретировать.
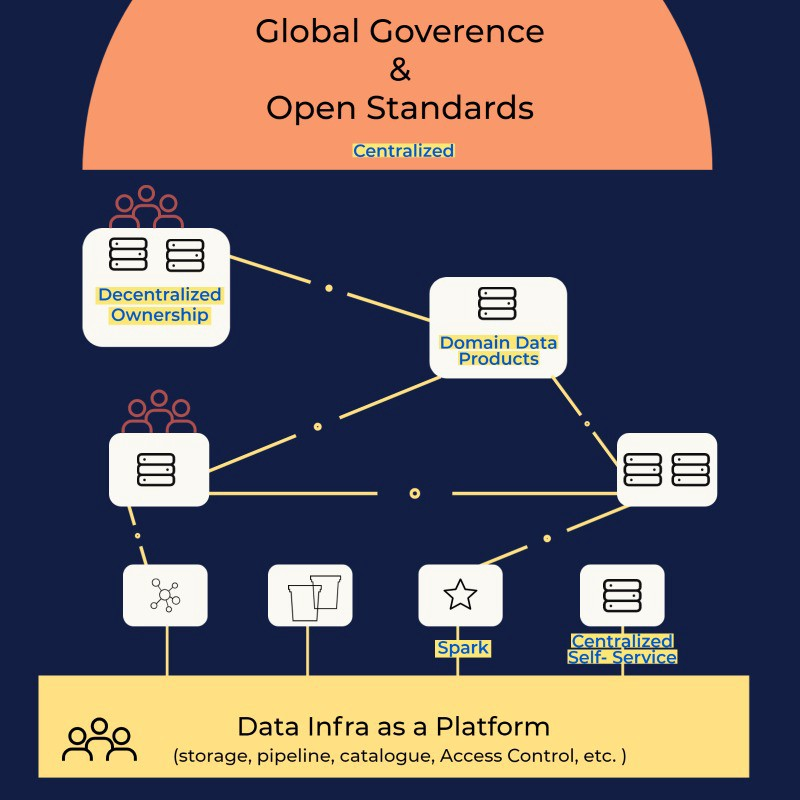
Архитектура Data Mesh
Основные принципы Data Mesh:
- данные как продукт;
- предметно-ориентированное децентрализованное владение данными;
- платформа самообслуживания;
- федеративное управление проектированием и архитектурой.
Data Mesh — это все еще развивающаяся концепция архитектуры данных. На рынке пока нет продуктов, построенных на такой архитектуре.
6. Data Fabric
Data Fabric предназначена для решения тех же задач, что и Data Mesh, хотя подходы в этих решениях довольно разные. Data Mesh основывается на предметно- и бизнес-ориентированном распределенном подходе, а Data Fabric — на централизованном подходе, ориентированном на работу с метаданными и технологиями.
Вместе с Data Fabric разрабатываются метаданные, каталог, логическая модель данных и API доставки. Для части данных используются виртуальные инструменты, а хранение остальных организуется централизованно, как и в хранилище. Этот подход дополняется централизованно контролируемыми политиками управления жизненным циклом данных, а именно:
- управление данными — активное управление, инструменты контроля доступа, Lineage, качество;
- конфиденциальность — маскировка и обезличивание конфиденциальной информации;
- соблюдение законодательных требований — GDPR, HIPPA, FCRA.
В частности, в этой области имеются такие решения, как SAP Data Intelligence, IBM Cloud Pak for Data, Oracle Coherence и Talend Data Fabric. Еще одно решение, Denodo, построено на использовании технологии виртуализации, которая лежит в основе подхода Data Fabric.

Архитектура Data Fabric
7. Архитектура Lakehouse
В озере данных каждому типу аналитической рабочей нагрузки нужен свой отдельный дата-пайплайн из-за разных требований к доступу к данным. Это приводит к отсутствию однозначногопонимания и использованию одних и тех же данных. В итоге появляется еще один слой хранения между аналитическими приложениями (потребителями) и бизнес-приложениями (источниками), которые генерируют данные. Сначала информация попадает в озеро, а потом перемещается в приложения потребителей. К тому моменту, как пользователи начнут действовать, основываясь на этих данных, ценность аналитических сведений может снизиться.
Озеро не поддерживает транзакционные приложения и имеет множество других ограничений, описанных в разделе выше.
Архитектура Lakehouse пытается решить эти проблемы за счет создания общего интерфейса для всех типов рабочих нагрузок по аналитике данных. Она поддерживает ACID-свойства транзакционных приложений. По сути, в ней объединяются преимущества архитектуры хранилища и озера и нивелируются их недостатки.

Архитектура Lakehouse
Заключение
Развитие архитектуры данных идет нога в ногу с потребностью в выполнении аналитических и когнитивных задач, опираясь на инновации облачных решений и технологий по работе с большими данными. Компания выбирает для себя тот или иной вид архитектуры данных в зависимости от степени зрелости аналитики данных, разнообразия этих данных и типа аналитических задач, с которыми ей приходится сталкиваться. Архитектура Lakehouse имеет все шансы стать идеальным решением без недостатков, но пока еще воспринимается как новинка, не получившая широкого распространения.
Архитектура данных — основа основ всех бизнес-стратегий по работе с данными, это критически важный вопрос для каждой компании. Если правильно выбрать архитектуру для своего бизнеса, можно добиться успешной реализации стратегии по работе с данными.
Команда VK Cloud развивает собственные Big Data-решения. Будем признательны, если вы их протестируете и дадите обратную связь. Для тестирования пользователям при регистрации начисляем 3000 бонусных рублей.

![Открытые библиотеки для обучения байесовских сетей [BAMT] и идентификации структуры данных [EPDE]](/upload/resize_cache/iblock/49b/105_70_0/49b93580d511fed5817ca87d7495e23f.jpeg "Открытые библиотеки для обучения байесовских сетей [BAMT] и идентификации структуры данных [EPDE]")

