

Всем привет! Меня зовут Иван Максимов, и я работаю Lead Data Scientist-ом в Delivery Club. Это вторая часть статьи об изменении подхода к рекомендациям ресторанов в нашей компании. В первой части я подробно описал текущие проблемы нашей рекомендательной системы: локально оптимальный баланс exploitation и cold start, а также недостаточно развитый механизм exploration. А также рассказал, как мы решали проблему exploitation через карусель «Вы заказывали», а проблему cold start — через карусель популярных фастфуд-ресторанов.
В этой статье речь пойдет о том, как мы в первой итерации улучшали exploration в приложении Delivery Club. Если прошлые заказы пользователя и популярные рестораны вынесены в отдельные блоки и исключены из ленты (примечание: всё, что находится под блоком с популярным фастфудом), то в ней остаются только новые для пользователя и не слишком популярные рестораны. А это как раз и есть множество кандидатов для exploration! Вопрос в том, как их отранжировать персонально для каждого пользователя.
Переранжирование в реальном времени с текущей ML-моделью
Напомню, что в ленте ресторанов на тот момент уже работала ML-модель от Поиска Mail.ru. Она была достаточно хороша с точки зрения машинного обучения, но имела ряд недостатков, большинство из которых связаны с отсутствием доступа к некоторым источникам данных:
зоны доставки ресторанов (необходимы для корректного negative sampling и формирования выборки для обучения);
оценки и отзывы клиентов после заказа (дополнительная информация для формирования таргета);
real-time прогноз времени доставки;
подробная информация о блюдах в меню;
данные о ресторанах из внешних источников (особенно актуально для рекомендаций новых ресторанов).
Ключевым недостатком модели, по нашему мнению, являлось неучитывание прогноза времени доставки. Он обновляется каждые пять минут, используя множество признаков, в том числе логистическую ситуацию в режиме реального времени. Заранее рассчитать такие прогнозы для всех возможных локаций и временных интервалов невозможно.
Классический способ учесть real-time признак — это построить новую модель, включив в нее этот признак. Такой способ нам не подходил по нескольким причинам:
Во-первых, на начало 2021 года мы работали с важным ограничением: выкатывать в прод можно только офлайн-модели или очень простые real-time рекомендации. Дело в том, что до 2021 года Data Science-команды занимались в основном проектами в логистике (прогноз спроса, распределение курьеров и т.д.), поэтому еще одной новой команде ML Ops только предстояло построить инфраструктуру для рекомендаций в клиентском приложении. При этом в первых итерациях мы не ожидали возможность раскатывать тяжелые модели, потому что к ним сразу ставилось требование на real-time ответы через микросервис c 99-ым перцентилем времени ответа не более 100 мс при нагрузке до 1 тысячи RPS.
Во-вторых, в модель Поиска Mail.ru встроить этот признак нельзя из-за технических ограничений, а просто взять и заменить текущую production-модель на новую крайне проблематично. Полная замена модели предполагает довольно долгую разработку, а это связано с большим риском: никто не знает точно, получится ли у нас сделать модель лучше. По офлайновым ML-метрикам (NDCG, precision@k, ...) это понять крайне затруднительно: они далеко не всегда коррелируют с продуктовыми метриками. И если первый A/B-тест не покажет статистически значимых улучшений, то мы не будем знать, в чём же дело, так как тестируем не инкрементальное улучшение, а две совершенно разных модели.
В-третьих, не до конца понятно, что должна оптимизировать модель. Обычно ML-модели прогнозируют какую-либо краткосрочную метрику (клики, заказы, лайки). Но при этом не до конца понятно, как изменения повлияют на долгосрочные метрики, например, retention. Внутри одной или нескольких ML-моделей достаточно сложно балансировать краткосрочные и долгосрочные метрики.
Гипотеза гиперлокальной доставки
Еще один аргумент в пользу этого подхода: он позволяет контролировать «честность» маркетплейса. Рекомендательные системы в целом страдают от различных bias’ов. В частности, из-за popularity bias не очень популярные или новые рестораны будут крайне редко рекомендованы пользователям. Это приводит к некоторой нечестности: уже и так популярные рестораны получают бóльшую часть заказов, а новые или не очень популярные, но качественные рестораны получают меньше заказов, чем могли бы.
В случае с рекомендациями в доставке еды проблему popularity bias можно частично решить благодаря принципу гиперлокальной доставки. Идея в следующем: если явно учитывать время доставки в рекомендациях, то рестораны будут конкурировать друг с другом только внутри небольших локаций. Тогда пиццерия за углом дома будет конкурировать с пиццерией на соседней улице, а не с известными сетевыми заведениями (у них много заказов в целом, но время доставки сильно больше, чем у пиццерии за углом дома). Это дает возможность хорошим локальным ресторанам быть более конкурентными и попадать в рекомендации по крайней мере в некоторых локациях.

Такой подход позволяет хорошим локальным ресторанам получать больше заказов. Также эта концепция, теоретически, позволяет снизить среднее время доставки.
Поэтому для начала мы решили сделать простую модель второго уровня. Если предположить, что конверсия монотонно зависит от прогноза (score) ML-модели, а retention — монотонно от времени доставки, то мы можем написать, например, линейную (в реальности это более сложная функция) модель второго уровня:

где:
 — ранг ресторана от ML-модели;
— ранг ресторана от ML-модели;
 — рассчитываемое каждые 5 минут время доставки, которое зависит от расстояния, логистической ситуации, погоды и многих других факторов;
— рассчитываемое каждые 5 минут время доставки, которое зависит от расстояния, логистической ситуации, погоды и многих других факторов;
 — прогноз ML-модели;
— прогноз ML-модели;
 — функция монотонного ранжирования: наибольший score получает ранг 1, следующий за ним — 2, и так далее;
— функция монотонного ранжирования: наибольший score получает ранг 1, следующий за ним — 2, и так далее;
 — монотонная функция.
— монотонная функция.
Мы используем rank, а не исходный score, чтобы формула была стабильной при обновлении модели: при наличии ранжирующей функции потерь может сильно меняться распределение score’ов. Также в этой формуле rank позволяет сравнивать ML-модели между собой, потому что имеет одинаковую размерность для любых моделей: возможно ведь, что мы сравним модель с ранжирующей функцией потерь, которая возвращает некий неограниченный score, и модель, которая прогнозирует вероятность заказа?
Из приятных дополнений: мы можем обойти множество bias’ов рекомендательных систем, подбирая в этой формуле в A/B-тестах коэффициент  или более продвинутыми способами (бандиты или байесовская оптимизация). Таким образом мы можем явно находить баланс между конверсией и удержанием пользователя.
или более продвинутыми способами (бандиты или байесовская оптимизация). Таким образом мы можем явно находить баланс между конверсией и удержанием пользователя.
Своя офлайновая ML-модель
Ограничения по доступу к данным в текущей продовой модели от Поиска Mail.ru однажды заставили нас сделать собственную ML-модель. Благодаря рекомендательным блокам «Вы заказывали» и «Фастфуд» мы смогли очистить ленту ресторанов от двух наиболее очевидных сценариев: прошлые заказы и очень популярный фастфуд. То есть мы хотели рекомендовать новый для пользователя ресторан не из самых популярных.
У нас накопилось довольно много данных, чтобы сразу обучить тяжелую модель, поэтому мы пошли классическим путем с двухуровневой системой рекомендаций. Модель первого уровня отбирает топ-50 кандидатов, а модель второго уровня переранжирует их. Поверх модели второго уровня дополнительно применяем переранжирование в реальном времени.
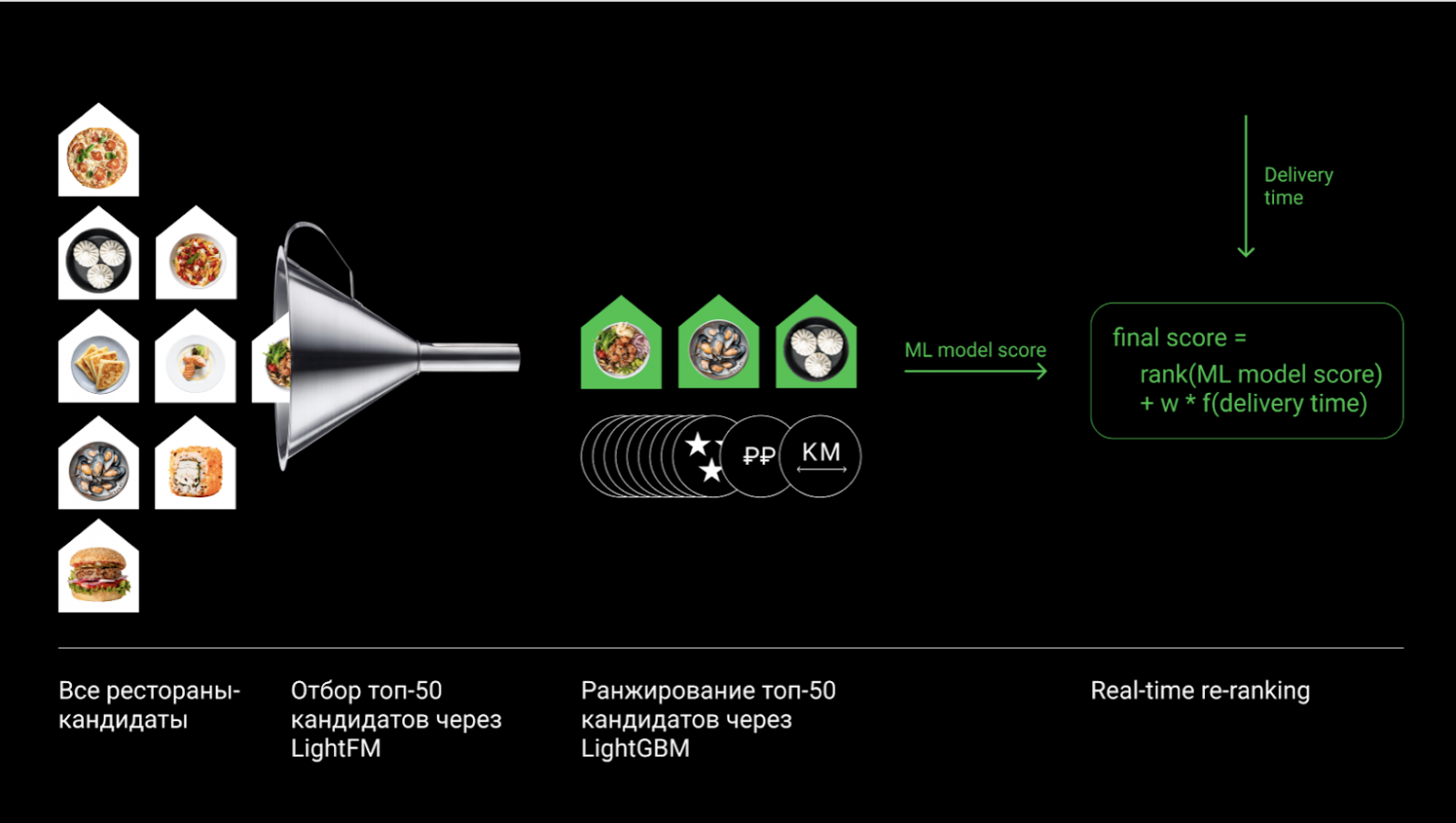
Прежде чем подробно описывать ML-модели стоит упомянуть про метрики, по которым мы их сравниваем. Так как задача — рекомендовать новые для пользователя рестораны, которые не входят в самые популярные, то необходимо модифицировать классические метрики recall@k и precision@k: мы их считаем, исключая прошлые покупки пользователей и топ популярных ресторанов. Назовем такие видоизмененные метрики recall_new@k и precision_new@k. Для модели первого уровня используем recall_new@50, а для второго — precision_new@10.
В качестве модели первого уровня мы тестировали ALS, Item2Vec и LightFM, сравнивая их на тестовой выборке из заказов за последний месяц. В экспериментах победила модель LightFM с WARP-функцией потерь. Подход классический, поэтому подробно на нем останавливаться не будем, но упомянем несколько интересных моментов:
Обучение проводили на матрице из взвешенного таргета — клики и заказы.
Мы обучали по отдельной модели на каждый город, чтобы семплировать негативные примеры только из города, в котором находится пользователь.
Ранжирующая WARP-функция потерь (pairwise-подход) давала существенное улучшение по сравнению с pointwise-подходами.
Очень помогло увеличение количества негативных семплов в LightFM.
Теперь мы имеем топ-50 кандидатов для каждого пользователя и можем их переранжировать более тяжелой моделью. Рекомендации в доставке имеют ряд особенностей, которые нам нужно было учесть:
По разным адресам (дом и работа, например) у пользователя совершенно разные предпочтения.
Крайне важно время доставки. Одно и то же блюдо через 20 минут и через 1,5 часа после приготовления имеет совершенно разный вкус.
Очень силен popularity bias. В том числе из-за того, что сетевые рестораны доступны в большом количестве точек на карте, а локальные рестораны — в малом.
Пользователи часто заказывают там, где уже заказывали. Соответственно, в обучающих данных этот паттерн очень силен. Но в рекомендациях ленты такие рестораны будут исключены, потому что они попадают в подборку «Вы заказывали».
В первой итерации, исходя из простоты использования и возможностей накладывать различные ограничения, мы решили обучать модель LightGBM.
Сначала провели много экспериментов с таргетом модели. Тестировали:
клики;
заказы;
заказы с весом в loss’е, равном выручке;
клики и заказы;
положительные отзывы после заказа;
заказы в новом для пользователя ресторане в совокупности с различными loss’ами: кросс-энтропия и lambdarank.
В итоге оказалось, что все эти параметры не сильно влияют на нашу целевую ML-метрику в модели второго уровня — precision_new@10. Мы выбрали таргет в модели второго уровня — заказы. С одной стороны, это довольно близко к цели ленты: рекомендовать рестораны из не очень популярных и тех, в которых пользователь не заказывал ранее. С другой стороны, заказов достаточно много. Чтобы иметь больше данных в расчете на один ресторан, мы обучали модель прогнозировать не конкретное заведение (Ресторан N по адресу Москва, ул. Ленина, д. 4), а бренд (Ресторан N). В модели тестировалось довольно много признаков. Их можно условно поделить на несколько групп:
Коллаборативные — признаки из модели первого уровня (score и ранг прогноза).
Предпочтения пользователя по кухням и категориям еды.
Признаки пары пользователь-ресторан — фичи, которые зависят одновременно и от пользователя, и от ресторана (расстояние доставки, средний чек пользователя — средний чек в ресторане и т.д.).
Условно статичные признаки пользователя и ресторана (адрес ресторана, стоимость доставки и т.д.).
Чтобы проверить, выучила ли модель зависимости из реального мира и не подвержена ли она различным bias’ам, мы использовали SHAP-векторы. Оказалось, что обученная «в лоб» модель находит крайне странные зависимости. Например, такие:
Вероятность заказа не всегда падает при повышении стоимости доставки.
График разницы средних чеков ресторана-пользователя и вероятности заказа не имеет параболической формы.
Вероятность заказа не падает при росте расстояния от пользователя до ресторана и времени доставки.
Также мы заметили на некоторых графиках SHAP-векторов явные выбросы, которые никак не могут быть объяснены природой данных и предпочтениями пользователей

Например, на графике зависимости SHAP-значения от средней стоимости доставки в ресторане видно, что при увеличении стоимости доставки до определенного уровня вероятность заказа (сонаправлена с SHAP-value) падает. Далее есть два выброса. И при дальнейшем росте стоимости доставки вероятность заказа растет! Возможно, выбросы связаны с тем, что достаточно ограниченное количество ресторанов имели фиксированную стоимость доставки, на которые и переобучается модель. Обычно у ресторанов не фиксированная стоимость доставки, а «лесенка» (условно, при сумме заказа до 500 рублей — доставка 149 руб, 500-1000 руб — доставка 99 руб, …). Из-за этого при вычислении средней стоимости доставки получается дробное число, а не целое.
Рост вероятности заказа при повышении стоимости доставки после выбросов в целом очень контринтуитивен и вряд ли может быть объяснен логически. Если модель с такой зависимостью верна, то мы могли бы поднять стоимость доставки во всех ресторанах до максимально возможной и заработать очень много денег. Но эта стратегия по объективным причинам не сработала бы в реальности.
Чтобы бороться с такого рода bias’ами, в ходе экспериментов мы выработали следующие решения:
Округлять признаки, чтобы избегать переобучения. Например, стоимость доставки округлялась с шагом в 10 рублей, а средний чек — в 20 рублей.
Накладывать ограничения на монотонность по ключевым признакам. Интересный момент: если мы хотим наложить ограничение на форму параболы, то можно разбить признак на два отдельных и наложить ограничение на монотонность для каждого из них. Например, можно разбить признак
«средний чек пользователя — средний чек ресторана» на min(«средний чек пользователя - средний чек ресторана», 0) и min(«средний чек ресторана - средний чек пользователя», 0).На первый признак наложить монотонно возрастающее ограничение, а на второй — убывающее.Использовать относительные, а не абсолютные признаки. Например, вместо среднего чека ресторана и пользователя использовать их разницу. Часть абсолютных признаков с высоким feature importance мы оставили, но до 80% таких признаков удалили.
После применения этих ограничений метрики на тестовой выборке не ухудшились, но модель выучила более логичные взаимосвязи. Из признака «Средняя стоимость доставки в ресторане», который имел странные выбросы и нелогичную зависимость с таргетом, получился признак «Средняя стоимость доставки, которую платил пользователь где-либо, — Средняя стоимость доставки в ресторане».

Этот признак уже имеет достаточно логичную связь с таргетом. При сдвиге от нуля в область отрицательных значений признака (когда стоимость доставки в ресторане выше, чем привык платить пользователь) мы видим резкое падение вероятности заказа. А при сдвиге в область положительных значений — тоже падение, но более плавное. Сам факт падения может быть связан с тем, что более качественные или премиальные рестораны могут иметь более высокую стоимость доставки. Пользователь, привыкший к таким ресторанам и к такой стоимости доставки, не готов переключаться на другой, пусть даже и более дешевый тип ресторанов.
Похожую зависимость можно увидеть и на примере других признаков. Практически аналогично выглядит график зависимости SHAP-value для признака «Средний чек пользователя — Средний чек в ресторане». Более интересная ситуация с признаком «Средний чек пользователя — минимальная сумма доставки в ресторане».
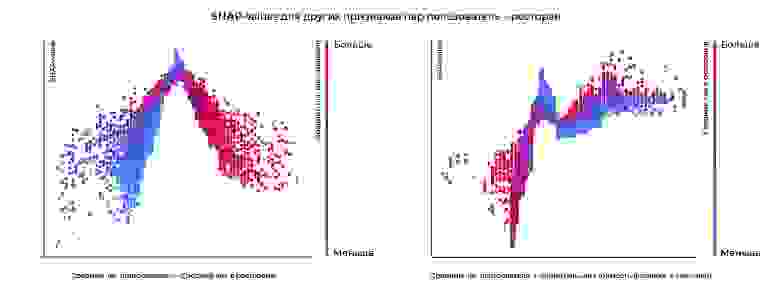
При движении от нуля в область отрицательных значений признака (когда минимальная сумма заказа больше среднего чека пользователя) видно резкое падение вероятности заказа. А при движении в область положительных значений — рост и стабилизация на определенном уровне, что тоже логично: если средний чек уже сильно выше минимальной стоимости доставки, то она перестает влиять на решение о заказе.
Также хотелось бы отметить, что модель учит логичные взаимосвязи по другим важным признакам: расстояние от пользователя до ресторана и популярность заведения.
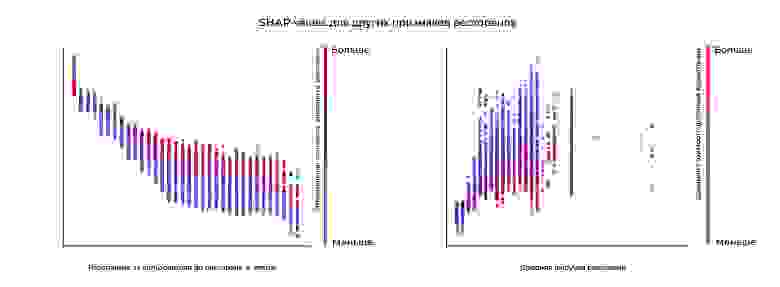
В результате мы получили модель LightGBM, которая выучила логические взаимосвязи из реального мира и не просела по метрикам по сравнению с моделью без ограничений.
Выводы
Наша команда смогла существенно поменять подход к рекомендациям в Delivery Club: комбинация своей офлайн ML-модели и переранжирование дало достаточно сильный рост как в частотности заказов, так и в конверсии. И хотелось бы отметить несколько моментов.
Во-первых, в нашем случае огромную роль сыграло добавление в модель новых источников данных. Улучшение архитектуры модели — это, конечно, хорошо, но в первую очередь стоит следить за тем, что вы подаете модели на вход. От качества входных данных очень сильно зависит качество итоговой модели.
Во-вторых, зачастую обучение моделей «в лоб» не работает. Они могут вырождаться в очевидные baseline’ы (топ популярных, прошлые заказы) или учить нелогичные взаимосвязи. Проверяйте модели всеми доступными способами: ML-метриками, SHAP-значениями, значимостью признаков и т.д.
Мы только в начале пути улучшения рекомендаций в Delivery Club. Еще предстоит множество экспериментов с моделями и форматами рекомендаций. Мы обязательно поделимся новостями в следующих статьях!
Другие материалы
Первая часть из серии статей про рекомендации ресторанов в Delivery Club
Блог ML4Value от автора статьи: о том, как приносить пользу бизнесу с помощью ML.
Как мы создавали платформу A/B-тестирования в Delivery Club.
Эволюция прогноза времени доставки в Delivery Club.
Как мы автоматизировали отрисовку зон доставки ресторанов.



