
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Однажды команда по разработке микросервисов попросила меня помочь с решением таинственной проблемы. Жаловались, что файловая система ZFS потребляет 30% мощности ЦП. В 2017 году я резюмировал этот кейс в Kernel Recipes; так что, это старая история, но, думаю, стоит её здесь пересказать.
Микросервис предназначался для поглощения метрик, и базовый образ операционной системы для него (BaseAMI) был недавно обновлён. После этого и появились жалобы, что файловая система ZFS стала потреблять более 30% мощностей ЦП. Сразу я подумал, что они просто в чём-то ошиблись. Я имел дело с внутренним устройством ZFS ещё в период работы в Sun Microsystems, и, только если не допущены грубые ошибки при конфигурации системы, она просто не может потреблять ресурсы ЦП в таком количестве.
Меня не раз удивляли неожиданные проблемы с производительностью, так что я подумал, что их инстансы в любом случае нужно проверить. Как минимум, мне удалось бы показать, что я подошёл к делу достаточно серьёзно и сам всё просмотрел. Также в таком случае я, должно быть, смог бы найти истинного потребителя ЦП.
Для начала я воспользовался инструментом Atlas, который обеспечивает мониторинг в пределах всего облака. Так я собирался проверить высокоуровневые метрики ЦП. В частности, хотел разбить время ЦП на процентные доли для «usr» (пользователь: приложения) и «sys» (система: ядро).
Насколько же я удивился, увидев, что немыслимые 38% от мощности ЦП расходуется в sys, что крайне необычно для облачных рабочих нагрузок в Netflix. Это действительно подтверждает, что ZFS кушает ЦП, но как? Определённо, это какая-то другая активность в ядре, а не сама ZFS.
Для углублённого анализа я обычно подключаюсь к инстансам по SSH. В таком случае можно применить to mpstat(1), чтобы убедиться в правильности разбиения на usr/sys, а далее взять perf(1) и приступать к профилированию тех путей кода ядра, которые лежат в ЦП. Но, поскольку в Netflix есть инструменты (ранее Vector, теперь FlameCommander), позволяющие легко выводить ступенчатые графики (flame graph) через UI развёрнутой в облаке системы, я полагал, что смогу угнаться за проблемой. Просто в качестве иллюстрации покажу Vector UI и типичный ступенчатый график облачной системы:
Обратите внимание, что в этом ступенчатом графике, приведённом в качестве примера, преобладает код Java – ему соответствуют зелёные кадры.
Вот ступенчатый график ЦП с одного из проблемных инстансов:
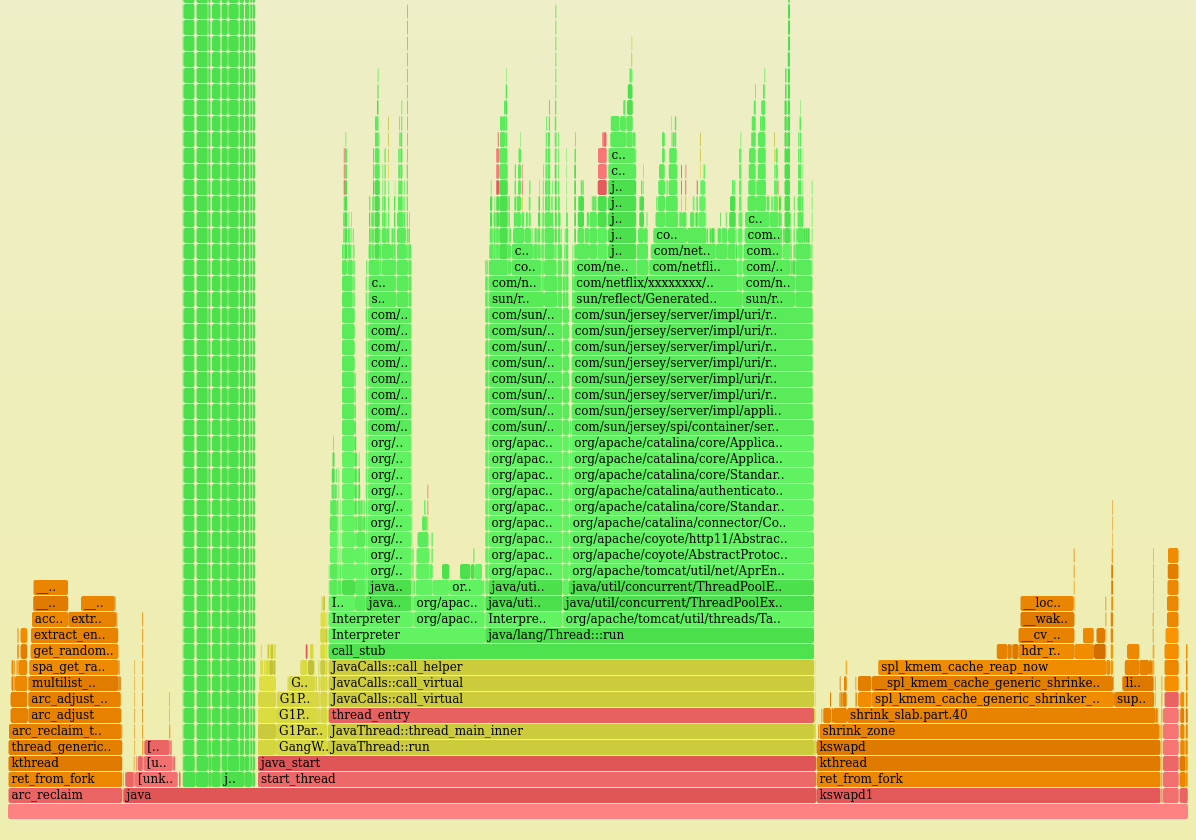
Процессорное время, расходуемое ядром, видно сразу – это две оранжевые башни слева и справа. (Также на этом графике жёлтый цвет соответствует C++, а красный – прочему коду, выполняемому на пользовательском уровне.)
Подробнее рассмотрим левую башню ядра:

Это arc_reclaim_thread! Я работал над этим кодом ещё в Sun.То есть, они в самом деле правы, всему виной ZFS!
Кэш адаптивной замены (ARC) в ZFS – это главный кэш памяти, предназначенный для файловой системы. Поток arc_reclaim_thread выполняет arc_adjust(), чтобы вытеснять память из кэша и не давать кэшу чрезмерно разрастаться, а также поддерживать минимальный объём свободной памяти, которой могут быстро воспользоваться приложения. Это делается периодически, либо если поток разбужен при условии исчерпания памяти. Ранее мне доводилось видеть, чтобы arc_reclaim_thread потреблял слишком много ЦП, когда в файловой системе использовался крошечный размер записей (например, 512 байт), в результате чего создавались миллионы крошечных буферов. Но это, в целом, была ошибка конфигурации. По умолчанию размер буфера равен 128 килобайт, и ни при какой настройке его не следует опускать ниже 8 килобайт.
Правая башня ядра входит в spl_kmem_cache_reap_now(), ещё одну функцию ZFS, отвечающую за освобождение памяти. Я полагаю, это относится и к левой башне (то есть, идёт конкуренция за одни и те же блокировки).
Но первый же вопрос: почему ZFS в деле?
На тот момент мне было известно только об одном случае применения ZFS в Netflix: в новом инфраструктурном проекте ZFS использовалась с контейнерами. Так у меня появилась теория: если они быстро перелопачивают контейнеры, то же должно касаться и файловых систем ZFS. Это может означать, что из кэша требуется быстро удалять множество старых страниц. Вот теперь начинает складываться.
Я поделился с ними этой теорией, будучи уверен, что я на верном пути. Но мне ответили: «Мы не пользуемся контейнерами». Окей, значит, вы точно используете ZFS? И этого ответа я не ожидал:
Но они были совершенно уверены, что вообще не пользуются ZFS. Ступенчатый график противоречил всякой логике. Я должен был им продемонстрировать, что они всяко используют ZFS, а также выяснить, зачем.
Нужно было найти способ отладить эту проблему, не пользуясь ничем кроме команд cd и ls(1). cd – для попадания в файловую систему, а ls(1) – чтобы посмотреть, что в ней. Серьезно прояснить, как она используется, должны были имена файлов.
Сначала требовалось отыскать, где монтируются файловые системы ZFS:
Ничего не показало! В настоящий момент не монтировано ни одной файловой системы ZFS. Я попробовал проверить другой инстанс – картина та же. Что?
Ах, но ведь контейнеры могли быть созданы ранее, а с тех пор уничтожены, следовательно, на настоящий момент никаких файловых систем от них не осталось. Как узнать, использовалась ли ZFS в системе когда-либо?
Знаю, arcstats! Счётчики ядра, отслеживающие статистику ZFS, в том числе, попадания и промахи ARC. Просмотрим их:
Невероятно! Все счётчики по нулям! ZFS действительно ни разу не использовалась. Но, в то же время, она потребляет более 30% ресурсов ЦП. Чтооо??
Клиент с самого начала был прав. ZFS просто поедает ЦП без всякой на то причины.
Как файловая система, которая вообще не используется, может потреблять 38% ЦП? Никогда такого раньше не видел. Просто тайна.
Я внимательнее рассмотрел ступенчатый график и вовлечённые в него пути – и заметил, что пути кода ЦП ведут к get_random_bytes() и extract_entropy(). Они мне раньше не попадались. Просмотрев исходный код и историю изменений, я нашёл, в чём дело.
В ARC содержится список кэшированных буферов для различных типов памяти. Была добавлена оптимизация производительности («multilist»), разбивающая списки ARC по одному на ЦП, чтобы сократить число споров за блокировку в многопроцессорных системах. Звучит хорошо, так как, по идее, должно повышать производительность. Но что происходит при попытке вытеснить память? Нужно выбрать один из этих списков ЦП. Который? Можно перебрать их по принципу карусели, но разработчик решил, что лучше выбирать один из них случайно.
Я сообщил об этой проблеме с ZFS под номером #6531. Думаю, первым делом нужно было добиться, чтобы arc_reclaim_thread выходил из игры ещё раньше, как только выяснится, что ZFS не используется, и даже не участвовал в выборе списков. С тех пор в ARC было внесено множество изменений, и я не слышал, чтобы эта проблема возникала вновь.
P.S.
На сайте издательства продолжается весенняя распродажа.
1. Постановка задачи
Микросервис предназначался для поглощения метрик, и базовый образ операционной системы для него (BaseAMI) был недавно обновлён. После этого и появились жалобы, что файловая система ZFS стала потреблять более 30% мощностей ЦП. Сразу я подумал, что они просто в чём-то ошиблись. Я имел дело с внутренним устройством ZFS ещё в период работы в Sun Microsystems, и, только если не допущены грубые ошибки при конфигурации системы, она просто не может потреблять ресурсы ЦП в таком количестве.
Меня не раз удивляли неожиданные проблемы с производительностью, так что я подумал, что их инстансы в любом случае нужно проверить. Как минимум, мне удалось бы показать, что я подошёл к делу достаточно серьёзно и сам всё просмотрел. Также в таком случае я, должно быть, смог бы найти истинного потребителя ЦП.
2. Мониторинг
Для начала я воспользовался инструментом Atlas, который обеспечивает мониторинг в пределах всего облака. Так я собирался проверить высокоуровневые метрики ЦП. В частности, хотел разбить время ЦП на процентные доли для «usr» (пользователь: приложения) и «sys» (система: ядро).
Насколько же я удивился, увидев, что немыслимые 38% от мощности ЦП расходуется в sys, что крайне необычно для облачных рабочих нагрузок в Netflix. Это действительно подтверждает, что ZFS кушает ЦП, но как? Определённо, это какая-то другая активность в ядре, а не сама ZFS.
3. Что дальше
Для углублённого анализа я обычно подключаюсь к инстансам по SSH. В таком случае можно применить to mpstat(1), чтобы убедиться в правильности разбиения на usr/sys, а далее взять perf(1) и приступать к профилированию тех путей кода ядра, которые лежат в ЦП. Но, поскольку в Netflix есть инструменты (ранее Vector, теперь FlameCommander), позволяющие легко выводить ступенчатые графики (flame graph) через UI развёрнутой в облаке системы, я полагал, что смогу угнаться за проблемой. Просто в качестве иллюстрации покажу Vector UI и типичный ступенчатый график облачной системы:
Обратите внимание, что в этом ступенчатом графике, приведённом в качестве примера, преобладает код Java – ему соответствуют зелёные кадры.
4. Ступенчатый график
Вот ступенчатый график ЦП с одного из проблемных инстансов:
Процессорное время, расходуемое ядром, видно сразу – это две оранжевые башни слева и справа. (Также на этом графике жёлтый цвет соответствует C++, а красный – прочему коду, выполняемому на пользовательском уровне.)
Подробнее рассмотрим левую башню ядра:
Это arc_reclaim_thread! Я работал над этим кодом ещё в Sun.То есть, они в самом деле правы, всему виной ZFS!
Кэш адаптивной замены (ARC) в ZFS – это главный кэш памяти, предназначенный для файловой системы. Поток arc_reclaim_thread выполняет arc_adjust(), чтобы вытеснять память из кэша и не давать кэшу чрезмерно разрастаться, а также поддерживать минимальный объём свободной памяти, которой могут быстро воспользоваться приложения. Это делается периодически, либо если поток разбужен при условии исчерпания памяти. Ранее мне доводилось видеть, чтобы arc_reclaim_thread потреблял слишком много ЦП, когда в файловой системе использовался крошечный размер записей (например, 512 байт), в результате чего создавались миллионы крошечных буферов. Но это, в целом, была ошибка конфигурации. По умолчанию размер буфера равен 128 килобайт, и ни при какой настройке его не следует опускать ниже 8 килобайт.
Правая башня ядра входит в spl_kmem_cache_reap_now(), ещё одну функцию ZFS, отвечающую за освобождение памяти. Я полагаю, это относится и к левой башне (то есть, идёт конкуренция за одни и те же блокировки).
Но первый же вопрос: почему ZFS в деле?
5. Конфигурация
На тот момент мне было известно только об одном случае применения ZFS в Netflix: в новом инфраструктурном проекте ZFS использовалась с контейнерами. Так у меня появилась теория: если они быстро перелопачивают контейнеры, то же должно касаться и файловых систем ZFS. Это может означать, что из кэша требуется быстро удалять множество старых страниц. Вот теперь начинает складываться.
Я поделился с ними этой теорией, будучи уверен, что я на верном пути. Но мне ответили: «Мы не пользуемся контейнерами». Окей, значит, вы точно используете ZFS? И этого ответа я не ожидал:
«Мы не используем ZFS.»Что?! Да используете же, я сам видел arc_reclaim_thread в ступенчатом графике. Он же не для красоты там работает! В ЦП он может заниматься только вытеснением страниц из ZFS ARC. Если вы не пользуетесь ZFS, то никаких страниц в ARC нет, поэтому и работать этот поток не должен.
Но они были совершенно уверены, что вообще не пользуются ZFS. Ступенчатый график противоречил всякой логике. Я должен был им продемонстрировать, что они всяко используют ZFS, а также выяснить, зачем.
6. cd & ls
Нужно было найти способ отладить эту проблему, не пользуясь ничем кроме команд cd и ls(1). cd – для попадания в файловую систему, а ls(1) – чтобы посмотреть, что в ней. Серьезно прояснить, как она используется, должны были имена файлов.
Сначала требовалось отыскать, где монтируются файловые системы ZFS:
df -h
mount
zfs listНичего не показало! В настоящий момент не монтировано ни одной файловой системы ZFS. Я попробовал проверить другой инстанс – картина та же. Что?
Ах, но ведь контейнеры могли быть созданы ранее, а с тех пор уничтожены, следовательно, на настоящий момент никаких файловых систем от них не осталось. Как узнать, использовалась ли ZFS в системе когда-либо?
7. arcstats
Знаю, arcstats! Счётчики ядра, отслеживающие статистику ZFS, в том числе, попадания и промахи ARC. Просмотрим их:
# cat /proc/spl/kstat/zfs/arcstats
name type data
hits 4 0
misses 4 0
demand_data_hits 4 0
demand_data_misses 4 0
demand_metadata_hits 4 0
demand_metadata_misses 4 0
prefetch_data_hits 4 0
prefetch_data_misses 4 0
prefetch_metadata_hits 4 0
prefetch_metadata_misses 4 0
mru_hits 4 0
mru_ghost_hits 4 0
mfu_hits 4 0
mfu_ghost_hits 4 0
deleted 4 0
mutex_miss 4 0
evict_skip 4 0
evict_not_enough 4 0
evict_l2_cached 4 0
evict_l2_eligible 4 0
[...]Невероятно! Все счётчики по нулям! ZFS действительно ни разу не использовалась. Но, в то же время, она потребляет более 30% ресурсов ЦП. Чтооо??
Клиент с самого начала был прав. ZFS просто поедает ЦП без всякой на то причины.
Как файловая система, которая вообще не используется, может потреблять 38% ЦП? Никогда такого раньше не видел. Просто тайна.
8. Анализ кода
Я внимательнее рассмотрел ступенчатый график и вовлечённые в него пути – и заметил, что пути кода ЦП ведут к get_random_bytes() и extract_entropy(). Они мне раньше не попадались. Просмотрев исходный код и историю изменений, я нашёл, в чём дело.
В ARC содержится список кэшированных буферов для различных типов памяти. Была добавлена оптимизация производительности («multilist»), разбивающая списки ARC по одному на ЦП, чтобы сократить число споров за блокировку в многопроцессорных системах. Звучит хорошо, так как, по идее, должно повышать производительность. Но что происходит при попытке вытеснить память? Нужно выбрать один из этих списков ЦП. Который? Можно перебрать их по принципу карусели, но разработчик решил, что лучше выбирать один из них случайно.
Случайно, в криптографически защищённом режиме.Гвоздь программы – ZFS была совершенно ни при чём. Кэш ARC обнаруживал дефицит памяти, после чего пытался соответствующим образом скорректировать свой размер – и в этот момент обнаруживал, что уже равен нулю, следовательно, делать ничего не требуется. Но в таком случае мы случайным образом выбирали список нулевого размера, применяя для этого ресурсозатратный генератор случайных чисел.
Я сообщил об этой проблеме с ZFS под номером #6531. Думаю, первым делом нужно было добиться, чтобы arc_reclaim_thread выходил из игры ещё раньше, как только выяснится, что ZFS не используется, и даже не участвовал в выборе списков. С тех пор в ARC было внесено множество изменений, и я не слышал, чтобы эта проблема возникала вновь.
P.S.
На сайте издательства продолжается весенняя распродажа.



