
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Как известно, файл Excel — это просто набор XML-файлов, определяемых форматом Office Open XML и упакованных в zip-архив, и потому для генерации нового файла помимо специализированных библиотек можно воспользоваться библиотеками для XML и zlib. Как обойтись без внешних зависимостей — под катом.
Для начала рассмотрим структуру zip-архива
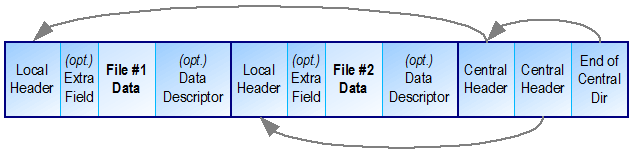
Пример архива из двух файлов. Источник CodeProject
Как видно каждый файл кодируется четырьмя блоками, два из которых опциональны. Каждый блок имеет специальную сигнатуру (последовательность из 4-х байт), которая в текстовом редакторе выглядит как PK.., что позволяет легко определять начало этих блоков. Local Header помимо сигнатуры содержит поля: размер сжатых данных файла, размер несжатых данных, контрольную сумму CRC32 для данных и другие. Central Header содержит те же данные, что и File Header, на который ссылается, а так же указание места, где File Header находится (число байт от начала файла, так называемый offset) и некоторые другие. End of Central Dir (EOCD) содержит число файлов в архиве и место первого Central Header. Формат zip предполагает обработку с конца файла, т.е. сначала читается EOCD секция, потом Central Header нужного файла, по нему находится File Header и потом выполняется переход к сжатым данным. Более подробное описание структур и полей можно увидеть здесь.
Стоит отметить, что каждый файл, входящий в архив, может иметь свой алгоритм и степень сжатия, задаваемые в Local Header. Архив одновременно может содержать как сжатые файлы, так и нет, чем собственно и можно воспользоваться, задав файлу, содержащему данные листа, нулевое сжатие, что позволит добавлять в секцию FileData XML-текст как он есть. После вставки новых данных первого файла необходимо пересчитать не только размер и контрольную сумму в Local Header #1 и обновить Central Header #1, но и увеличить смещение в Central Header #2 (и других тоже, если они есть) на длину добавленных данных. Это не сложно, но можно избежать, если менять не первый, а последний (в данном случае второй) файл. xlsx-файл с одним листом содержит 9 файлов. Данные листа хранятся в
Примерный вид

Hex-данные исправленного архива в Hex-редакторе HxD.
Обратите внимание, что используется обратный порядок байт, так сигнатура
Чтобы внести изменения после вставки данных листа на позицию 3, отмеченную стрелочкой, необходимо из hex-редактора выписать в скольких байтах от начала файла находятся следующие поля (ниже приводятся получившиеся значения в моей файле
После этого можно приступать к генерации файла:
С самой генерацией XML данных листа проблем возникнуть не должно, однако стоит отметить, что числа хранятся как XML-узлы
Сам Excel заполняет больше XML-атрибутов, например номера строк и используемые диапазоны, но они опциональны.
Основная идея: взять заранее подготовленный шаблон xlsx файла с пустым листом, запихнуть в нужное место несжатые (zip-формат это позволяет) XML-данные листа и пересчитать некоторые байты в заранее известных местах. Такой способ нетребователен к CPU, но получаемые файлы значительно больше по размеру, чем обычные.
Для начала рассмотрим структуру zip-архива
Пример архива из двух файлов. Источник CodeProject
Как видно каждый файл кодируется четырьмя блоками, два из которых опциональны. Каждый блок имеет специальную сигнатуру (последовательность из 4-х байт), которая в текстовом редакторе выглядит как PK.., что позволяет легко определять начало этих блоков. Local Header помимо сигнатуры содержит поля: размер сжатых данных файла, размер несжатых данных, контрольную сумму CRC32 для данных и другие. Central Header содержит те же данные, что и File Header, на который ссылается, а так же указание места, где File Header находится (число байт от начала файла, так называемый offset) и некоторые другие. End of Central Dir (EOCD) содержит число файлов в архиве и место первого Central Header. Формат zip предполагает обработку с конца файла, т.е. сначала читается EOCD секция, потом Central Header нужного файла, по нему находится File Header и потом выполняется переход к сжатым данным. Более подробное описание структур и полей можно увидеть здесь.
Стоит отметить, что каждый файл, входящий в архив, может иметь свой алгоритм и степень сжатия, задаваемые в Local Header. Архив одновременно может содержать как сжатые файлы, так и нет, чем собственно и можно воспользоваться, задав файлу, содержащему данные листа, нулевое сжатие, что позволит добавлять в секцию FileData XML-текст как он есть. После вставки новых данных первого файла необходимо пересчитать не только размер и контрольную сумму в Local Header #1 и обновить Central Header #1, но и увеличить смещение в Central Header #2 (и других тоже, если они есть) на длину добавленных данных. Это не сложно, но можно избежать, если менять не первый, а последний (в данном случае второй) файл. xlsx-файл с одним листом содержит 9 файлов. Данные листа хранятся в
xl\worksheets\sheet1.xml. Чтобы сделать этот файл последним в архиве, надо всего лишь удалить его из архива, а потом заново добавить с нулевым сжатием.Примерный вид
sheet1.xml (добавлены переносы строк и отступы для читаемости)<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<worksheet xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships">
<sheetViews>
<sheetView tabSelected="1" workbookViewId="0"/>
</sheetViews>
<sheetFormatPr defaultRowHeight="12.75"/>
<sheetData></sheetData>
<phoneticPr fontId="0" type="noConversion"/>
<pageMargins left="0.75" right="0.75" top="1" bottom="1" header="0.5" footer="0.5"/>
<headerFooter alignWithMargins="0"/>
</worksheet>
Hex-данные исправленного архива в Hex-редакторе HxD.
Обратите внимание, что используется обратный порядок байт, так сигнатура
0x04034b50 записана как 50 4b 03 04, а длина файла sheet1.xml — 0x0000020C = 0x20C = 524 (байт) как 0С 02 00 00.
Как отсчитывать байты
В соответствии с документацией File Header имеет следующую структуру
Открыв архив, в hex-редакторе визуально легко найти данные
Учитывая, что тип uint32_t — это 4 байта, а uint16_t — два, получаем следующую картинку, где
голубой прямоугольник — сигнатура, оранжевый — метод сжатия, два серых — дата и время изменения файла и синий — это контрольная сумма, за которой идут два зеленых, содержащих сжатый и несжатый размеры.

struct LocalFileHeader
{
uint32_t signature; // Обязательная сигнатура, равна 0x04034b50
uint16_t versionToExtract; // Минимальная версия для распаковки
uint16_t generalPurposeBitFlag; // Битовый флаг
uint16_t compressionMethod; // Метод сжатия (0 - нет, 8 - deflate)
uint16_t modificationTime; // Время модификации файла
uint16_t modificationDate; // Дата модификации файла
uint32_t crc32; // Контрольная сумма
uint32_t compressedSize; // Сжатый размер
uint32_t uncompressedSize; // Несжатый размер
...
Открыв архив, в hex-редакторе визуально легко найти данные
sheet1.xml. Чуть выше находится сигнатура PK — это и будет началом File Header. Встав на нее справа (красная полоска), получим выделение слева (толстый красный квадрат) и позицию 0x17E3 в строке состояния — это положение от начала файла заголовка File Header для файла sheet1.xml.Учитывая, что тип uint32_t — это 4 байта, а uint16_t — два, получаем следующую картинку, где
голубой прямоугольник — сигнатура, оранжевый — метод сжатия, два серых — дата и время изменения файла и синий — это контрольная сумма, за которой идут два зеленых, содержащих сжатый и несжатый размеры.
Чтобы внести изменения после вставки данных листа на позицию 3, отмеченную стрелочкой, необходимо из hex-редактора выписать в скольких байтах от начала файла находятся следующие поля (ниже приводятся получившиеся значения в моей файле
template.xlsx)- CRC =
0x17F1. Добавив +4 получится смещение для сжатого размера, и еще +4 несжатого - Начало данных файла (стрелка 2) =
0x1819 - Место куда будут дописаны данные (стрелка 3) =
0x1969 - Конец данных файла =
0x1A24 - CRC в Central Header для
sheet1.xml=0x1C69 - Отступ в EOCD =
0x1CAFи старое значение в нем0x1A25, которое нужно будет увеличить на длину добавленных данных
После этого можно приступать к генерации файла:
- В массив байт читаются данные шаблона
- Вычисляется «накапливаемый» CRC32, сначала по данным шаблона от начала данных (2) до тега
sheetData(3), потом по вставляемым данным, а потом отsheetDataдо конца файла - Обновляются биты CRC и длины в структурах FileHeader и Central Header в массиве байт
- Формируется результирующий массив, как данные файла из шаблона до тега
sheetData+ вставляемые данные + данные шаблона послеsheetData, который и будет итоговым результатом.
С самой генерацией XML данных листа проблем возникнуть не должно, однако стоит отметить, что числа хранятся как XML-узлы
<c><v>100</v></c><c t="s"><v>2</v></c>2 указывает на второй узел в файле xl\sharedStrings.xml. Таким образом Excel экономит место, храня одинаковые строки как одно значение. Чтобы не менять в архиве еще и sharedString, строки можно писать сразу в sheet1.xml, применив атрибут inlineStr <c t="inlineStr"><is><t>I'll be back</t></is></c>< > & ' " символов. В итоге должно получаться что то вида<row>
<c><v>100</v></c>
<c t="inlineStr"><is><t>AAA</t></is></c>
</row>
<row>
<c><v>200</v></c>
<c t="inlineStr"><is><t>BBB</t></is></c>
</row>Сам Excel заполняет больше XML-атрибутов, например номера строк и используемые диапазоны, но они опциональны.
Демо-программа доступна здесь, а файл шаблона здесь.

