

Автор материала изменил инструмент перечисления файлов в NeoVim с fd1 на git ls-files2 и заметил, что файлы отображаются быстрее. При этом цель fd — скорость, а Git — это прежде всего система управления исходным кодом, её основная задача3 — не в перечислении файлов. Интрига заставила провести тесты.
Делимся подробностями и набором разнообразных инструментов в арсенале автора, пока начинается курс по Fullstack-разработке на Python.
TL;DR
В Git-репозитории ядра Linux выполните:
hyperfine --export-markdown /tmp/tldr.md --warmup 10 'git ls-files' 'find' 'fd --no-ignore'
Детали
Посмотрим на инструменты бенчмарка и их версии:
fd 8.2.1
git 2.33.0
find 4.8.0
hyperfine 1.11.0
Тесты выполняются с заполненным дисковым кешем, непрогретый кеш мы опустим: команды из списка выше вы можете использовать много раз. Результаты репозитория в памяти аналогичны, и это подтверждает заполнение кеша.
Мы работаем с файлами, так что они уже должны быть частично кешированы. Бенчмарк выполняется на скромном ПК с отключённым энергосбережением процессора. Этот процессор восьмиядерный и поддерживает Hyperthreading, а значит, fd использует 8 потоков. Если не указано иное, файлы в репозитории — это попавшие в коммит файлы, артефактов сборки среди них нет.
Репозиторий Git для тестов
Для тестов я клонировал4 репозиторий ядра Linux: он большой, а производительность Git при разработке измеряется именно на этом репозитории. За счёт нетривиального времени поиска сравнение будет проще и точнее.
git clone --depth 1 --recursive ssh://git@github.com/torvalds/linux.git ~/ghq/github.com/torvalds/linux
cd ~/ghq/github.com/torvalds/linuxКоманды бенчмарка
Итак, мы хотим сравнить git ls-files с fd и find. Но получить одинаковые списки файлов для объективного сравнения — это нетривиальная задача.

Опытным путём выяснилось, что к одинаковым5 с git ls-files результатам вывода приводит эта команда:
fd --no-ignore --hidden --exclude .git --type file --type symlinkЕё сложность может привести к несправедливому преимуществу git ls-files. Поэтому воспользуемся простыми примерами из таблицы выше.
Hyperfine
Hyperfine — отличный инструмент сравнения команд: у него цветной интерфейс и вывод в markdown, он пытается обнаружить ошибки, настраивает количество запусков... [Автор воспользовался генератором ASCII-анимации asciinema6]. Вот вывод7:

Первые результаты
Для первого бенчмарка на SSD с btrfs войдём в коммит ad347abe4a... и запустим команду сравнения производительности:
hyperfine --export-markdown /tmp/1.md --warmup 10 'git ls-files' \
'find' 'fd --no-ignore' 'fd --no-ignore --hidden' 'fd' \
'fd --no-ignore --hidden --exclude .git --type file --type symlink'Вот её вывод:

В чём причины столь резкого различия? Давайте разбираться.
Как Git хранит файлы в репозитории
Чтобы понять, откуда берётся преимущество git ls-files, посмотрим, как файлы хранятся в репозитории. Подробную информацию о внутреннем устройстве репозитория Git вы найдёте в этом разделе книги Pro Git.
Объекты Git
Git строит собственное представление дерева файловой системы в репозитории:

Из книги Pro Git, написанной Scott Chakan и Ben Straub и опубликованной издательством Apress, по лицензии Creative Commons Attribution Non Commercial Share Alike 3.0, © 2021.
Каждый объект дерева содержит список папок или имён, а также ссылки на них. Объекты хранятся в папке .git:
.git/objects
├── 65
│ └── 107a3367b67e7a50788f575f73f70a1e61c1df
├── e6
│ └── 9de29bb2d1d6434b8b29ae775ad8c2e48c5391
├── f0
│ └── f1a67ce36d6d87e09ea711c62e88b135b60411
├── info
└── packЧтобы перечислить содержимое папки, Git, похоже, обращается к соответствующему объекту дерева в файле. Этот файл хранится в папке, имя которой — это первые символы соответствующего хеша.
Обращаться таким образом к текущим файлам коммита потоянно — это медленно, особенно в случае часто используемых команд, например git status. К счастью, git поддерживает индексацию файлов в текущем рабочем каталоге.
Индекс Git
Среди прочего, этот индекс перечисляет каждый файл репозитория с метаданными файловой системы, такими как время последней модификации. Более подробную информацию и примеры вы найдёте здесь. Похоже, индекс Git содержит всё, что необходимо ls-files. Давайте посмотрим, как эта команда работает под капотом.
Strace
Вначале убедимся, что ls-files работает только с индексом и не сканирует файлы в репозитории или в папке .git. Чтение файла дешевле обхода множества папок, это и объясняет преимущество ls-files. Чтобы проверить, как работает ls-files, воспользуемся strace8:
strace -e !write git ls-files>/dev/null 2>/tmp/aОказывается, ls-files читает .git/index:
openat(AT_FDCWD, ".git/index", O_RDONLY) = 3Что на самом не удивительно. Из документации:
Команда объединяет список файлов в индексе с фактическим списком рабочего каталога и показывает различные комбинации одного и другого.
Быстрая проверка исходного кода Git подтверждает, что объекты в папке .git и файлы репозитория не читаются. Теперь у нас есть объяснение скорости git ls-files!
Другие ситуации
Как git ls-files работает в других ситуациях? Перечисление файлов в репозитории, где коммит выполнен — не самый распространённый случай. Во время работы всё больше файлов изменяется или добавляется.
Ситуация с изменениями файлов
Мы не должны заметить существенной разницы в производительности, когда изменяется несколько файлов: индекс по-прежнему используется непосредственно для получения имён файлов в репозитории. Изменение содержимого в этой ситуации нас не очень волнует. Чтобы убедиться, что особой разницы нет, изменим все файлы на С в коде ядра Linux. Для этого воспользуемся сценариями оболочки fish:
for f in (fd -e c)
echo 1 >> $f
endgit status | wc -l
28350hyperfine --export-markdown /tmp/2.md --warmup 10 'git ls-files' 'find' 'fd --no-ignore' \
'fd --no-ignore --hidden --exclude .git --type file --type symlink'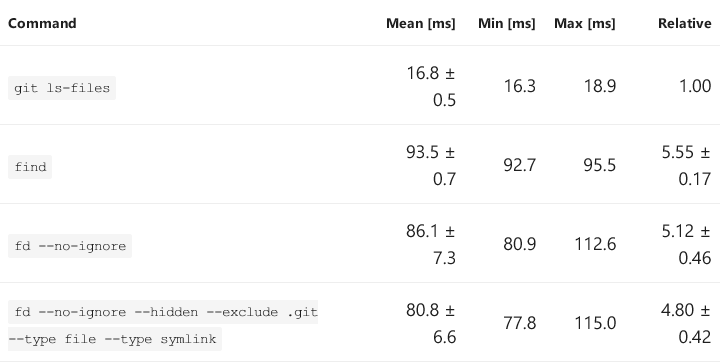
Мы видим те же цифры, что и раньше, и они согласуются с исходным кодом ls-files. Теперь запустим git checkout -f @, чтобы удалить изменения.
Ситуация с новыми файлами и флагом -o
С файлами вне коммита есть два случая:
Файлы созданы и добавлены через git add: в этом случае они находятся в индексе, и ls-files достаточно прочитать его.
Файлы созданы, но не добавлены: в индексе их нет, но без флага -o ls-files также не выведет их. Значит, ls-files, как и раньше, может использовать индекс.
Таким образом, единственный случай, который ещё нужно исследовать, — это использование аргумента -o. Базовых результатов для -o у нас ещё нет, поэтому сначала посмотрим, как аргумент работает без добавления новых файлов.
-o без новых файлов
Если мы не добавили в репозиторий никаких новых файлов:
hyperfine --export-markdown /tmp/3.md --warmup 10 'git ls-files' 'git ls-files -o' 'find' \
'fd --no-ignore' 'fd --no-ignore --hidden --exclude .git --type file --type symlink'
Эти результаты свидетельствуют о том, что git ls-files -o выполняет ещё какую-то работу, а не «просто» читает индекс, при этом strace показывает такие строки:
strace -e !write git ls-files -o>/dev/null 2>/tmp/a
…
openat(AT_FDCWD, "Documentation/", O_RDONLY|O_NONBLOCK|O_CLOEXEC|O_DIRECTORY) = 4
newfstatat(4, "", {st_mode=S_IFDIR|0755, st_size=1446, ...}, AT_EMPTY_PATH) = 0
getdents64(4, 0x55df0a6e6890 /* 99 entries */, 32768) = 3032С недобавленными новыми файлами
Давайте добавим несколько файлов:
for f in (seq 1 1000)
touch $f
endИ сравним с нашим базовым уровнем:
hyperfine --export-markdown /tmp/4.md --warmup 10 'git ls-files' 'git ls-files -o' 'find' \
'fd --no-ignore' 'fd --no-ignore --hidden --exclude .git --type file --type symlink'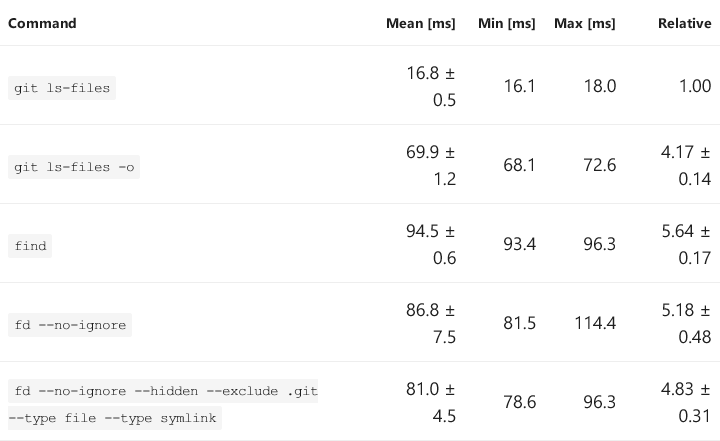
Статистически значимых отличий от базового уровня практически нет, а значит, большая часть времени тратится на операции, относительно независимые от количества обрабатываемых файлов. Также стоит отметить, что разница в скорости между git ls-files -o и fd --no-ignore --hidden --exclude .git --type file --type symlink невелика.
При помощи strace можно установить, что все команды, за исключением git ls-files, читали все файлы в репозитории. Сравнивая результаты strace git ls-files -o и fd --no-ignore --hidden --exclude .git --type file --type symlink, мы увидим, что команды для каждого файла выполняют одинаковые системные вызовы.
Как объяснить небольшую разницу во времени между ними? Я не нашёл убедительных причин в исходном коде git для этого случая. Возможно, использование индекса даёт ls-files преимущество.
Выводы
Теперь вместо fd и find в своём текстовом редакторе я использую git ls-files. Это быстрее, хотя ощутимая разница, вероятно, связана со скачками задержки на холодном кеше. Выборка файлов с помощью ls-files сужает список до файлов, которые меня интересуют. Листинг файлов с fd я сохранил как запасной вариант, поскольку иногда я работаю вне репозитория Git.
Сноски
С помощью Telescope.nvim
:Telescope find_files↩︎С помощью Telescope.nvim
:Telescope git_files show_untracked=false︎Это не значит, что git медленный, наоборот, когда читаешь примечания к релизу, становится очевидно, что проделана большая работа по оптимизации производительности. ↩︎
Использование неглубокого клона позволяет быстрее воспроизвести результаты локально. Но повторный запуск бенчмарков на полном клоне существенно не изменил результаты. ↩︎
diffпо выводам командgit ls-filesandfd --no-ignore --hidden --exclude .git --type file --type symlink↩︎Вставляется на страницу с помощью asciinema hugo module ↩︎
Этот вывод отредактирован, чтобы удалить предупреждение о выбросах, которое появилось только в случае
asciinema, вероятно, потому, что она нарушает эталон. Это объясняет, почему значения "asciicast" отличаются от таблиц в остальной части статьи: для этих таблиц я использовал значения из прогонов вне asciinemaТакже смотрите https://jvns.ca/blog/2014/04/20/debug-your-programs-like-theyre-closed-source/ ↩︎
Продолжить изучение инструментов разработки вы сможете на наших курсах:

Узнать подробности акции
Профессия Fullstack-разработчик на Python (15 месяцев)
Профессия Data Scientist (24 месяца)
Другие профессии и курсы
Data Science и Machine Learning
Профессия Data Scientist
Профессия Data Analyst
Курс «Математика для Data Science»
Курс «Математика и Machine Learning для Data Science»
Курс по Data Engineering
Курс «Machine Learning и Deep Learning»
Курс по Machine Learning
Python, веб-разработка
Профессия Fullstack-разработчик на Python
Курс «Python для веб-разработки»
Профессия Frontend-разработчик
Профессия Веб-разработчик
Мобильная разработка
Профессия iOS-разработчик
Профессия Android-разработчик
Java и C#
Профессия Java-разработчик
Профессия QA-инженер на JAVA
Профессия C#-разработчик
Профессия Разработчик игр на Unity
От основ — в глубину
Курс «Алгоритмы и структуры данных»
Профессия C++ разработчик
Профессия Этичный хакер
А также
Курс по DevOps
Все курсы


