
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
На самом деле почти никто не знает, что такое GitOps. Я тоже заблуждался, пока не начал готовить доклад, а потом статью по этой теме. Самое распространенное определение GitOps — это «хранение состояния в Git», но оно не единственное и не самое главное. Это звучное словечко придумали в Weaveworks, но его название несколько разнится с его реальным пониманием. Созвучие с DevOps — скорее, маркетинговый ход, чем реальное отражение сущности. Основная идея GitOps в том, что помимо хранения состояния в Git, у нас есть непрерывный процесс его синхронизации с реальным миром, то есть, что у вас Kubernetes-кластере или где либо ещё в вашем окружении.
Меня зовут Андрей Квапил. Я работал в чешском хостинге WEDOS. Он не сильно популярен в России, но это крупнейший хостинг на территории Чехии (просто Чехия маленькая). Сейчас я работаю во Фланте, но именно на примере европейского хостинга WEDOS, хочу рассказать историю имплементации GitOps.

У нас было 2 собственных дата-центра. Мы хостили сотни тысяч сайтов и виртуалок. Активно использовали Kubernetes для декларативного описания инфраструктуры и наших сервисов для управления физическими серверами и всех рабочих нагрузок, которые на них запускаются.
Наша инфраструктура:
Bare metal-сервера;
Ванильный Kubernetes;
15 кластеров;
1000 нод;
Stateful-приложения;
Несколько команд разработчиков.
Стоит упомянуть, что у этой инфраструктуры была одна особенность. Kubernetes в основном используется для запуска stateless-, мы же использовали его в первую очередь для запуска stateful-приложений. У нас их было почти 80%. Kubernetes помогал нам декларативно управлять сотнями приложений и чтобы нескольким командам разработчиков было удобно работать, нужно было настроить кооперацию.
Но давайте по порядку. Чтобы не случалось разночтений, и мы с вами разговаривали на одном языке, определимся с терминологией.
Continuous Integration vs. Continuous Delivery
Начнем с терминов Continuous Integration и Continuous Delivery. Далеко не все могут сказать, чем одно отличается от второго. Давайте разбираться.

Когда мы говорим про CI/CD, обычно подразумеваем некий pipeline.
Он запускается и автоматизирует сборку, тестирование, создает релиз и частенько доставляет наше приложение на конечное окружение (стейджинг, прод).
К сожалению это не всегда происходит так, как мы хотим. Потому что мы зависим от внешних факторов. Pipeline может сломаться, а стейт приложения разъехаться и его придется чинить вручную. Один из немаловажных моментов, который помогает решить GitOps — это существенно упростить пайплайны, отказавшись от стадии доставки приложения в конечные окружения.


На схеме приведен полный цикл приложения от его планирования, написания кода до того момента, когда приложение уже задеплоено и работает в продакшене. Здесь есть два окружения: Staging и Production. На последнем шаге мы не считаем что цикл окончен, потому что нам по прежнему нужно следить за приложением, постоянно удостоверяться в том, что оно работает и с ним всё в порядке.
Continuous Integration — это набор практик позволяющих настроить процесс совместной разработки, а также автоматизировать большинство шагов по сборке, тестированию и публикации релизов. Когда мы запушили новую ветку, смерджили в мастер или сделали тег, у нас запускается автоматизация — сборка образов, автоматическое тестирование и все шаги не зависящие от конкретного окружения. На этом этапе приложение еще ничего не знает о том, где оно будет работать. В теории на данном этапе может создаваться динамическое тестовое окружение, но оно используется только для проведения тестов. Тогда как сама доставка приложения в реальное окружение практиками CI не описывается, и может происходить даже вручную.
Теперь поговорим про Continuous Delivery, набор практик который отвечает на вопросы непосредственно доставки вашего приложения в конкретные окружения. Например, в стейджинг или сразу на прод. Сам процесс, при этом, автоматизирован, но может включать и ручные действия. Например, деплой на стейдж может происходить автоматически, но деплой на прод включает некоторую абстрактную кнопку, которую следует нажимать только, удостоверившись, что текущая версия приложения на стейдже развернулось и исправно работает.

Есть еще третий термин — Continuous Deployment, который подразумевает автоматизацию доставки приложения, также, и на продакшен окружение:

Шаги в рамке — это и есть те задачи, которые решает GitOps при доставке приложения на окружение.
Что такое GitOps
Вот мы и подобрались к самому интересному. Так что же такое GitOps? На самом деле GitOps — это одновременно Git, как единственный источник правды и непрекращаемый процесс синхронизации из него. И если первый содержит декларативное описание нашей инфраструктуры или приложения, ожидаемой в текущий момент времени в нужном окружении. То второй нужен, для того чтобы сохранять наше окружение в соответствии с описанным в репозитории состоянием. Объясню подробнее графически.

Предположим, у нас есть Git-репозиторий с приложением и манифестами для его деплоя в конкретные окружения. И есть pipeline, который запускается на любое изменение по триггеру и деплоит приложение в Kubernetes. Например, запускает kubectl apply или helm Install, тем самым приводя состояние задеплоенного в Kubernetes приложения к состоянию описанному в Git-репозитории.
Кому-то может показаться: «Вот оно»! Мы описываем и доставляем состояние из Git-репозитория прямо в Kubernetes. Это настоящий GitOps? Нет. Для того чтобы это считалось GitOps нужно ещё кое-что.
Подход GitOps, придуманный в Weaveworks основывается на идее того, что есть непрекращаемый reconciliation loop — который продолжает следить за источником правды (в нашем случае Git-репозиторием) и непрерывно синхронизировать его состояние в реальный мир (в нашем случае Kubernetes-кластер).
Если посмотреть на то, как работают контроллеры в Kubernetes, мы увидим точно такую же логику, за исключением того, что они смотрят в Kubernetes API, а не в Git-репозиторий.
Есть объект Deployment, который генерит ресурс ReplicaSet. Каждый объект ReplicaSet обслуживается ReplicaSet контроллером, который генерит уже непосредственно поды. Если мы удаляем какой-то под вручную, ReplicaSet-контроллер заметит это изменение в кластере и попытается привести его к состояние, которое описано у него в объекте. То же произойдёт и с объектом ReplicaSet — если его удалить, то Deployment-контроллер создаст новый ReplicaSet, чтобы соответствовать состоянию описанному в Deployment. Это работает и в другую сторону — если мы обновляем спеку объекта Deployment, создаются новый ReplicaSet и новый Pod.
Контроллеры и непрерывное приведение к желаемому состоянию — это основная логика Kubernetes. Именно ей и вдохновились создатели подхода GitOps.
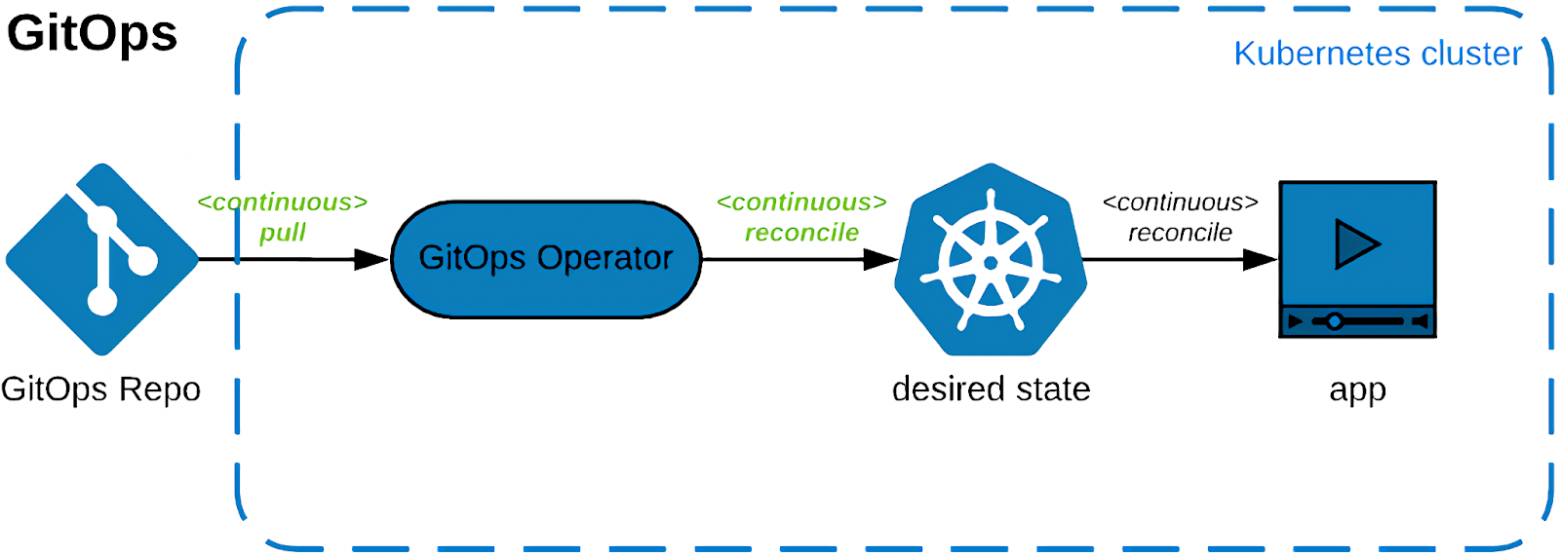
GitOps подразумевает, что есть некий GitOps-оператор или контроллер, который делает то же самое, что и контроллеры в Kubernetes, но смотрит не в Kubernetes API, а в конкретный Git-репозиторий. То есть, берет состояние Git-репозитория и перекладывает его в Kubernetes. А также следит за тем, чтобы оно всегда ему соответствовало.
5 лучших GitOps-практик
Рассмотрим решения по автоматизации доставки для Kubernetes на примере ArgoCD и Flux:
На это меня вдохновила статья про 5 лучших GitOps-практик в блоге ArgoCD.
#1. Два репозитория: один для исходников, второй для манифестов
Эталонный вариант имплементации GitOps от ArgoCD предлагает использование двух Git-репозиториев:

В первом лежат только исходники приложения, а также Helm-chart’ы и Dockerfiles. По сути в этом репозитории лежит всё, что не зависит от конкретного окружения.
Второй репозиторий — для манифестов — он описывает конкретное приложение и как оно должно быть задеплоено в кластере. Для продакшен среды там есть Helm-chart с одними values, а для стейджинга — с другими. Helm здесь приведён в качестве примера, на самом деле это могут быть и простые YAML-манифесты разложенные по папкам, или любой другой инструмент, позволяющий получить отрендеренный YAML, готовый для деплоя приложения в наше окружение. При этом ничто не мешает нам завести pipeline, который будет обновлять состояние второго репозитория из первого. Тут уже как кому удобней.
Второй репозиторий используется GitOps-оператором, как единая точка правды, всё что в нём описано, должно быть синхронизировано с Kubernetes.
#2: Выберите подходящий метод организации репозитория
ArgoCD и Flux полностью мультитенатные системы. Это значит, что вы можете использовать несколько Git-репозиториев, а GitOps-оператор может синхронизировать их состояние с несколькими Kubernetes-кластерами. В итоге один и тот же GitOps-оператор может использоваться для нескольких команд разработчиков и заниматься доставкой сразу нескольких, независящих друг от друга, приложений. В результате у нас центральная дашборда, где можно наблюдать за состоянием всех наших деплойментов.
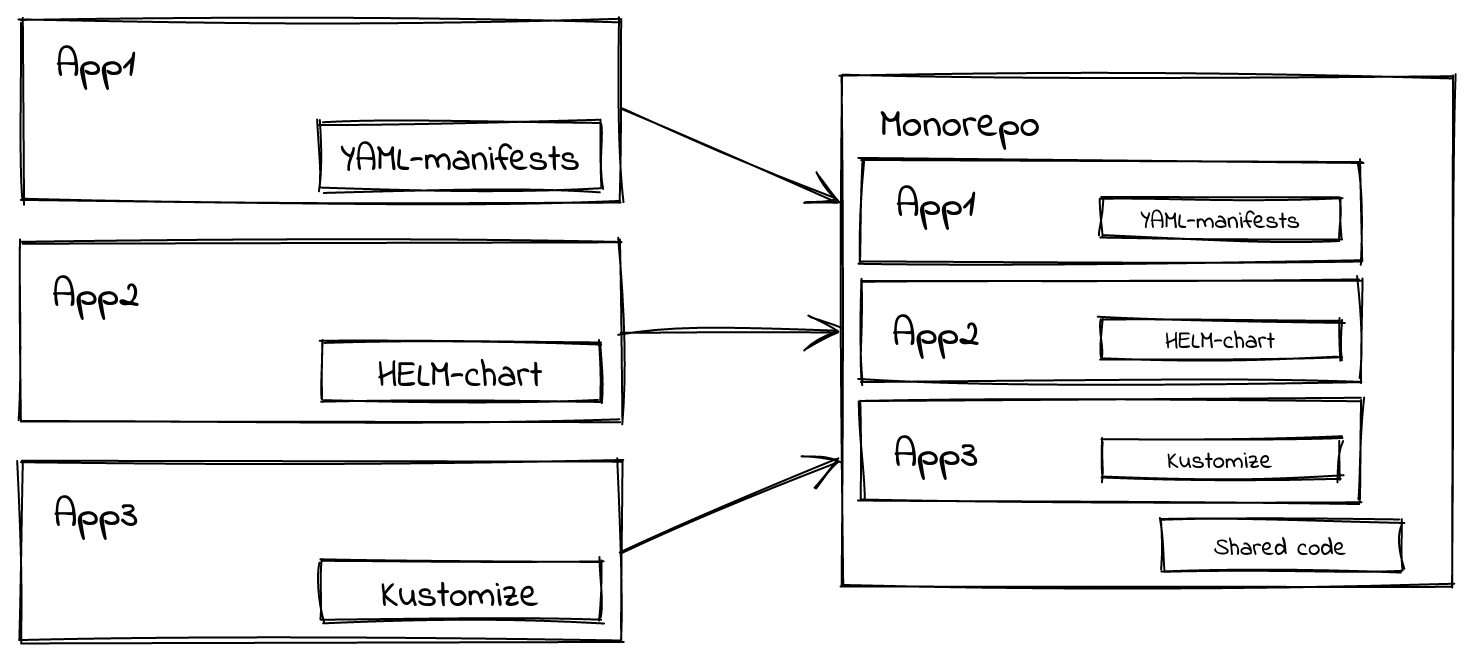
Тем не менее нужно выбрать подходящий метод организации репозитория. Можно использовать монорепозиторий, и описать все наши приложения и уже его отдать на управление GitOps-оператору. Либо использовать отдельные Git-репозитории на каждое приложение, которые будут обновляться независимо.
Лично мы использовали гибридный вариант, когда для каждой команды разработки выделяется монорепо, содержащий все необходимые манифесты в рамках одного проекта. Такой подход зарекомендовал себя, как наиболее простой, и не погружающий нас в Dependency hell.
#3: Проверяйте манифесты перед коммитом
Когда вы отправляете манифесты на деплой, необходима валидация. Прежде чем смерджить в main, нужно выполнить helm template, либо kubectl apply с ключём –dry-run, чтобы удостовериться, что с манифестами все в порядке и синтаксис не нарушен.
Это можно делать как вручную, так из CI-pipeline. Мы используем GitLab. На каждый merge-реквест у нас есть проверка, которая рендерит все манифесты и применяет в фейковый кластер. Если все в порядке, тогда можно мерджить.

Еще в ArgoCD девелоперу можно выдать права в какой-нибудь devel-кластер, и использовать CLI для проверки манифестов в режиме реального времени. Девелопер может обновить приложение или посмотреть diff через ArgoCD, не выполняя непосредственно операцию коммита.

Для этого достаточно запустить команду argocd app diff с названием приложения, и он покажет, какие части в Kubernetes будут обновлены. Таким же образом, его можно обновить прямо с локального компьютера девелопера. Определённо, это очень удобный инструмент для локальной разработки.
Однако, эта возможность идёт вразрез с принципами, которые проповедует GitOps. По этому Flux такую возможность не предоставляет, он более нативный к Git и подразумевает, что все изменения должны быть обязательно коммитнуты, прежде чем они поедут в кластер.
#4: Манифесты не должны изменяться от внешних факторов
Этот момент, скорее, Argo-специфичный. В первую очередь это касается паролей и сертификатов. Прежде, чем применить какие-то изменения в кластер, ArgoCD генерирует yaml-файл для применения в кластер. В терминах ArgoCD есть desired и live состояние вашего приложения. desired — это манифест полученный из нашего источника правды (Git-репозитория). live — то, что уже есть и работает в кластере. ArgoCD их сравнивает и сообщает, какие именно поля должны поменяется. Поэтому, если helm template каждый раз будет возвращать разные значения, например, строку со случайным паролем, то ArgoCD будет бесконечно пытаться привести их к состоянию OutOfSync. Поэтому манифесты должны быть идемпотентны, надо помнить, что каждое поле описанное в Git-репозитории, будет сверено с тем, что в Kubernetes.
У Flux такой проблемы нет, потому что он использует нативный Helm для применения Helm-чартов. Таким образом, все нативные функции helm будут работать во Flux так же, как если бы вы деплоили обычным helm’ом. Даже абстрактный хук для генерации случайного пароля не доставит вам проблем.
У этих двух инструментов разная логика. Каждая из них имеет право на существование. Все дело в том, что для вас важнее — жесткий контроль применяемых манифестов или удобство деплоя тем инструментом к которому вы привыкли.
#5: Подумайте о том, как и где вы будете хранить секреты
ArgoCD не решает проблему хранения секретов, а оставляет ее на ваших плечах. Тем не менее ArgoCD можно расширять кастомными плагинами, либо использовать отдельные контроллеры, работающие на стороне Kubernetes. Давайте рассмотрим несколько их них:

SOPS и git-crypt работают локально, их можно запустить в качестве бинарников на своем компьютере:
1. SOPS
Это самое популярное и простое решение. Оно позволяет шифровать конкретные файлы. Обычно работает с yaml и JSON, но может и полностью шифровать отдельные файлы.
Фишка SOPS в том, что он работает не только с PGP, но и со сторонними secret-менеджерами: Google, AWS, HashiCorp Vault. При этом вся зашифрованная информация хранится прямо в Git-репозитории.
2. Git-crypt
Можно задать какие файлы должны быть зашифрованы по маске через .gitattribute. Используя две команды: git-crypt lock и git-crypt unlock зашифровывать и расшифровывать весь репозиторий.
Другие два решения представляют Kubernetes-контроллеры, которые расшифровывают информацию уже после применения манифестов:
3. Bitnami Sealed Secrets
Это решение позволяет применить объект SealedSecret в Kubernetes. Он автоматически делает из него объект секрета. Если вам нужно простейшее решение — это оно.
4. Banzai Cloud Bank-Vaults
Это сложное решение завязано на HashiCorp Vault. Оно имплементирует его таким образом, что все вытащенные из Vaults секреты, не фигурируют в Kubernetes API. А именно не создаётся никаких секретов, которые можно украсть при доступе к манифестам вашего кластера или даже дампам etcd. Все секреты передаются прямо в runtime приложения при помощи хитрого бинарника, в итоге приложение видит его как переменную.
Как работает ArgoCD
Рассмотрим схему самого ArgoCD:

Здесь есть несколько деплойментов. Самый интересный argocd-repo-server. Это контейнер, внутри которого Git и различные инструменты для рендеринга манифестов: Helm, Kustomize и любые другие. Туда можно поместить свои утилиты, например jsonnet, tanka или qbec. Задача этих инструментов — сгенерировать готовый для деплоя YAML из того, что есть в репозитории.
Важное замечание, у argocd-repo-server нет доступа к Kubernetes API. По логике ArgoCD — мы сначала получаем готовый для деплоя YAML с помощью запуска бинарника в контейнере repo-сервера, а дальше argocd-application-controller синкает его с тем состоянием, что есть в Kubernetes-кластере.
argocd--server предоставляет красивый интерфейс для взаимодействия с пользователем. Он использует argocd-dex-server и argocd-redis. Думаю, их назначение можно не рассматривать.
Custom plugin
Посмотрим, как добавить кастомный плагин к ArgoCD:

У нас есть ConfigMap, в котором можно описывать configManagementPlugins. У каждого плагина есть две стадии: init и generate.
Стадия init запускает скрипт для подготовки репозитория к генерации манифеста. Например, можно выполнить helm dependency update, чтобы скачать все зависимости для нашего helm-чарта. Если использовать шифрование на уровне репозитория, здесь можно добавить операцию расшифровки.
Вторая стадия generate — это команда для получения yaml-файла. В случае с Helm, здесь была бы команда helm template. Полученные таким образом манифесты применяются в кластер уже отдельным GitOps-engine.
Как работает Flux2
Flux работает немного иначе. Он реализует паттерн Kubernetes с кастомными ресурсами и контроллерами.

У Flux есть source контроллер, который скачивает изменения из source repo. Помимо Git, это может быть S3, или Helm Chart Repository. А также отдельные Kustomize-контроллер и Helm-контроллер, которые занимаются применением манифестов в кластер. Если бы мы хотели расширить Flux, пришлось бы написать отдельный контроллер и CustomResource для него.
ArgoCD VS Flux
Итоговая сравнительная табличка:
")
Благодаря логике контроллеров Flux поддерживает все нативные возможности Helm и Kustomize. У ArgoCD Helm немного обрезанный. Он работает с ним только через helm template. Поэтому если использовать готовые Helm Charts, могут возникнуть проблемы с некоторыми функциями. Например, с lookup, которые в ArgoCD просто не работают. Возможно придётся пересмотреть некоторые helm hooks. Большинство из них работает, но так как они выполняются не самим Helm’ом, а GitOps Engine ArgoCD, они работают немного иначе.
В ArgoCD достаточно специфичный Image Updater. Он генерирует файл, который можно использовать только с Helm или Kustomize. Flux использует условные комментарии. Image name можно подставить куда угодно в yaml-файл.
По модели безопасности оба инструмента используют RBAC. У Flux он более понятный, так как переиспользует стандартные политики Kubernetes, а у ArgoCD свой формат. Еще у ArgoCD есть sync windows. Например, вы можете указать, что какие-то кластера разрешено деплоить только ночью.
С секретами в ArgoCD все сложно. А Flux поддерживает SOPS из коробки.
С точки зрения observability жирный плюс идет ArgoCD, у которого из коробки классная и удобная дашборда. Думаю, большинство людей, выбирающие ArgoCD, выбирают его за дашборды. Flux не имеет такой красивой дашборды, но и логика там немного другая.
Тем не менее, как и ArgoCD он предоставляет CLI-утилиты, notifications-контроллер, а также дашборду для Grafana.
Continuous Integration
Мы поговорили про Continuous Deployment, отвечающую за доставку нашего приложения в Kubernetes, но что насчет Continuous Integration?

Напомню, что Pipeline’ы никуда не делись, но стали проще, потому что мы избавили их от логики доставки нашего приложения. Так на чём же реализовать CI? Есть несколько решений, которые можно использовать:
Github Actions — на момент моего выступления они ещё не были так популярны как сейчас. Если вы ведёте разработку в GitHub, это одно из самых удобных решений. К сожалению, оно полностью завязано на Github.
GitLab CI — на сегодняшний день также популярна одна из киллер-фич, возможность развернуть Gitlab локально. Тогда из коробки будет все, что нужно для разработки, включая Git-репозиторий, docker registry, CI-систему и многое другое.
Но также есть решения позволяющие запускать CI-пайплайны на стороне Kubernetes:
Tekton уже стал своего рода стандартом. Он принят Cloud Native Foundation и является частью OpenShift. Это OpenShift нативные и Kubernetes нативные pipeline’ы.
Argo Workflows также неплохо себя зарекомендовал. Его вроде бы можно использовать, чтобы не покидать экосистему ArgoCD, но это это не совсем так. Потому что интерфейс Argo Workflows не интегрируется с ArgoCD почти никак. Это отдельный инструмент решающий конкретно свои задачи.
В целом, для простых проектов можно обойтись и без CI-системы. Есть множество инструментов для локальной разработки. Помню, одно время я написал плагин kubectl-build, который позволяет запускать сборку и публикацию Docker-образов прямо в Kubernetes-кластере, но, при этом, не покидая удобного локального окружения.

Взгляд werf
Open Source-проект werf не был затронут в оригинальном докладе, однако этот подход тоже интересен при рассмотрении концепции GitOps.
Werf — это утилита, заточенная на построение рабочего процесса по принципам CI/CD. Она встраивается в любую CI/CD-систему и «из коробки» решает типичные проблемы при построении такого процесса. Авторы werf пошли немного другим (чем в Weaveworks) и представили гитерминизм. Он схож с GitOps в плане организации декларативной и версионируемой инфраструктуры. Однако для применения изменений вместо pull-модели (т.е. оператора-«синхронизатора», как это сделано у упомянутых Flux и ArgoCD) используется push-модель.
С одной стороны Werf отдельно покрывает CI/CD, но в полной мере не реализует GitOps. С другой стороны, отдельно GitOps не покрывает весь цикл CI/CD (локальная разработка, сборка образов, запуск тестов). Поэтому в werf предусмотрена интеграция для совместного использования с ArgoCD для построения полного CI/CD с использованием GitOps на основе pull-модели. Интеграция предполагает использование ArgoCD для деплоя в production-контур и опционально для деплоя в production-like. Это происходит по такой схеме:

Еще больше самых актуальных материалов для разработчиков высоконагруженных систем будет на конференции HighLoad++ 2022 - 24 и 25 ноября в Москве. Посмотреть программу докладов и приобрести билеты можно на официальном сайте конференции.




