
Салют, хабровчане! Перевод следующей статьи подготовлен специально для студентов курса «Инфраструктурная платформа на основе Kubernetes», занятия по которому стартуют уже завтра. Начнем.

Автомасштабирование позволяет автоматически увеличивать и уменьшать рабочие нагрузки в зависимости от использования ресурсов.
У автомасштабирования в Kubernetes два измерения:
Автомасштабирование кластера можно использовать в сочетании с горизонтальным автомасштабированием подов для динамического регулирования вычислительных ресурсов и степени параллелизма системы, необходимых для соблюдения соглашений об уровне обслуживания (SLA).
Автомасштабирование кластера сильно зависит от возможностей поставщика облачной инфраструктуры, в которой размещен кластер, а HPA может работать независимо от IaaS/PaaS-провайдера.
Горизонтальное автомасштабирование подов претерпело серьезные изменения с момента появления в Kubernetes v1.1. Первая версия HPA выполняла масштабирование подов на основе измеренного потребления ресурсов ЦП, а позже — на основе использования памяти. В Kubernetes 1.6 был представлен новый API под названием Custom Metrics, обеспечивавший HPA доступ к произвольным показателям. А в Kubernetes 1.7 добавили уровень агрегации, который позволяет сторонним приложениям расширять API Kubernetes, регистрируясь в качестве надстроек API.
Благодаря Custom Metrics API и уровню агрегации, системы мониторинга, такие как Prometheus, могут предоставлять контроллеру HPA специфические показатели приложений.
Горизонтальное автомасштабирование подов реализовано в виде контура управления, который периодически запрашивает в Resource Metrics API (API метрик ресурсов) основные показатели, такие как использование ЦП и памяти, а в Custom Metrics API (API пользовательских метрик) — специфические показатели приложений.
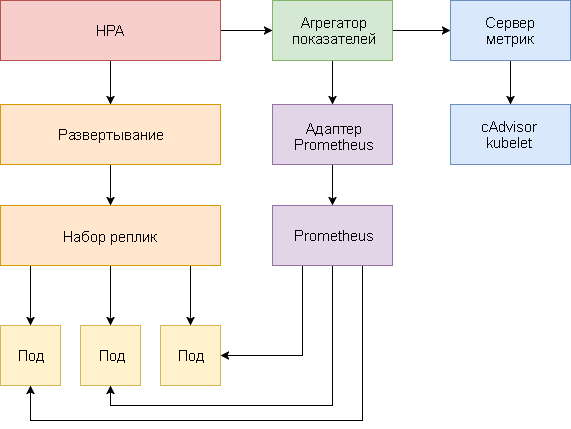
Ниже представлено пошаговое руководство по конфигурированию HPA v2 для Kubernetes 1.9 и более поздних версий.
Перед началом работы необходимо установить Go версии 1.8 (или более поздней) и клонировать репозиторий k8s-prom-hpa в
Сервер метрик Kubernetes — это внутрикластерный агрегатор данных об использовании ресурсов, пришедший на смену Heapster. Сервер метрик собирает сведения об использовании ЦП и памяти для узлов и подов из
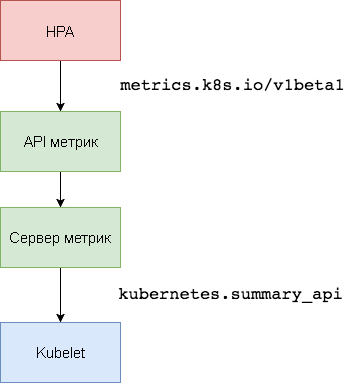
В первой версии HPA для получения показателей ЦП и памяти был нужен агрегатор Heapster. В HPA v2 и Kubernetes 1.8 требуется только сервер метрик с включенным
Разверните сервер метрик в пространстве имен
Через 1 минуту
Просмотр показателей узлов:
Просмотр показателей подов:
Для тестирования горизонтального автомасштабирования подов (HPA) можно использовать небольшое веб-приложение на основе Golang.
Разверните podinfo в пространстве имен
Обратитесь к
Задайте HPA, которое будет обслуживать не менее двух реплик и выполнять масштабирование до десяти реплик, если средний показатель использования ЦП превысит 80 % или если расход памяти будет выше 200 МиБ:
Создайте HPA:
Через пару секунд контроллер HPA свяжется с сервером метрик и получит сведения об использовании ЦП и памяти:
Чтобы увеличить использование ЦП, выполните нагрузочный тест с помощью rakyll/hey:
Можно выполнять мониторинг событий HPA следующим образом:
Временно удалите podinfo (вам придется выполнить его повторное развертывание на одном из следующих этапов данного руководства).
Для масштабирования на основе специальных показателей необходимо два компонента. Первый — база данных временных рядов Prometheus — собирает показатели приложений и сохраняет их. Второй компонент — k8s-prometheus-adapter — дополняет Custom Metrics API Kubernetes показателями, предоставленными сборщиком.
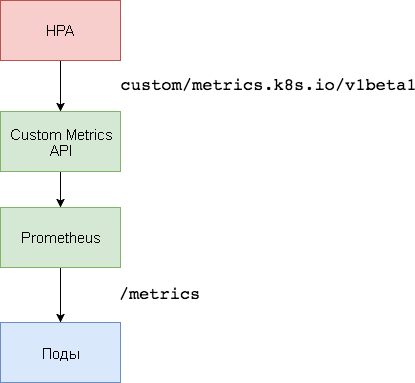
Для развертывания Prometheus и адаптера используется выделенное пространство имен.
Создайте пространство имен
Разверните Prometheus v2 в пространстве имен
Сгенерируйте сертификаты TLS, необходимые для адаптера Prometheus:
Разверните адаптер Prometheus для Custom Metrics API:
Получите список специальных показателей, предоставляемых Prometheus:
Затем извлеките данные по использованию файловой системы для всех подов в пространстве имен
Создайте сервис NodePort
Приложение
Получите общее количество запросов в секунду из Custom Metrics API:
Буква
Создайте HPA, которое будет расширять развертывание podinfo, если количество запросов превысит 10 запросов в секунду:
Разверните HPA
Через несколько секунд HPA получит значение
Примените нагрузку для сервиса podinfo с 25 запросами в секунду:
Через несколько минут HPA начнет масштабировать развертывание:
При текущем количестве запросов в секунду развертывание никогда не достигнет максимальной величины в 10 подов. Трех реплик достаточно для того, чтобы количество запросов в секунду для каждого пода было меньше 10.
После завершения нагрузочных тестов HPA уменьшит масштаб развертывания до первоначального количества реплик:
Возможно, вы заметили, что средство автомасштабирования реагирует на изменение показателей не сразу. По умолчанию их синхронизация выполняется каждые 30 секунд. Кроме того, масштабирование происходит только в том случае, если в течение последних 3–5 минут не было увеличения и снижения рабочих нагрузок. Это позволяет предотвратить выполнение конфликтующих решений и оставляет время для подключения средства автомасштабирования кластера.
Не все системы могут обеспечить соблюдение требований SLA только на основе показателей использования ЦП или памяти (или обоих сразу). Большинство веб-серверов и мобильных серверов для обработки всплесков трафика нуждаются в автомасштабировании на основе количества запросов в секунду.
Для приложений ETL (от англ. Extract Transform Load — «извлечение, преобразование, загрузка») автомасштабирование может запускаться, например, при превышении заданной пороговой длины очереди заданий.
Во всех случаях инструментирование приложений с помощью Prometheus и выделение необходимых показателей для автомасштабирования позволяют выполнить точную настройку приложений, чтобы улучшить обработку всплесков трафика и обеспечить высокую доступность инфраструктуры.
Идеи, вопросы, замечания? Присоединяйтесь к обсуждению в Slack!
Вот такой получился материал. Ждём ваши комментарии и до встречи на курсе!
Автомасштабирование в Kubernetes
Автомасштабирование позволяет автоматически увеличивать и уменьшать рабочие нагрузки в зависимости от использования ресурсов.
У автомасштабирования в Kubernetes два измерения:
- автомасштабирование кластера (Cluster Autoscaler), которое отвечает за масштабирование узлов;
- горизонтальное автомасштабирование подов (Horizontal Pod Autoscaler, HPA), которое автоматически масштабирует количество подов в развертывании или наборе реплик.
Автомасштабирование кластера можно использовать в сочетании с горизонтальным автомасштабированием подов для динамического регулирования вычислительных ресурсов и степени параллелизма системы, необходимых для соблюдения соглашений об уровне обслуживания (SLA).
Автомасштабирование кластера сильно зависит от возможностей поставщика облачной инфраструктуры, в которой размещен кластер, а HPA может работать независимо от IaaS/PaaS-провайдера.
Развитие HPA
Горизонтальное автомасштабирование подов претерпело серьезные изменения с момента появления в Kubernetes v1.1. Первая версия HPA выполняла масштабирование подов на основе измеренного потребления ресурсов ЦП, а позже — на основе использования памяти. В Kubernetes 1.6 был представлен новый API под названием Custom Metrics, обеспечивавший HPA доступ к произвольным показателям. А в Kubernetes 1.7 добавили уровень агрегации, который позволяет сторонним приложениям расширять API Kubernetes, регистрируясь в качестве надстроек API.
Благодаря Custom Metrics API и уровню агрегации, системы мониторинга, такие как Prometheus, могут предоставлять контроллеру HPA специфические показатели приложений.
Горизонтальное автомасштабирование подов реализовано в виде контура управления, который периодически запрашивает в Resource Metrics API (API метрик ресурсов) основные показатели, такие как использование ЦП и памяти, а в Custom Metrics API (API пользовательских метрик) — специфические показатели приложений.
Ниже представлено пошаговое руководство по конфигурированию HPA v2 для Kubernetes 1.9 и более поздних версий.
- Установите надстройку сервера метрик (Metrics Server), который предоставляет основные показатели.
- Запустите демонстрационное приложение, чтобы увидеть, как работает автомасштабирование подов на основе использования ЦП и памяти.
- Выполните развертывание Prometheus и специального сервера API. Зарегистрируйте специальный сервер API на уровне агрегации.
- Сконфигурируйте HPA с использованием специальных показателей, предоставленных демонстрационным приложением.
Перед началом работы необходимо установить Go версии 1.8 (или более поздней) и клонировать репозиторий k8s-prom-hpa в
GOPATH:cd $GOPATH
git clone https://github.com/stefanprodan/k8s-prom-hpa1. Настройка сервера метрик
Сервер метрик Kubernetes — это внутрикластерный агрегатор данных об использовании ресурсов, пришедший на смену Heapster. Сервер метрик собирает сведения об использовании ЦП и памяти для узлов и подов из
kubernetes.summary_api. Сводный API (Summary API) — это эффективно расходующий память API для передачи серверу метрик данных Kubelet/cAdvisor.В первой версии HPA для получения показателей ЦП и памяти был нужен агрегатор Heapster. В HPA v2 и Kubernetes 1.8 требуется только сервер метрик с включенным
horizontal-pod-autoscaler-use-rest-clients. Этот параметр включен по умолчанию в Kubernetes 1.9. GKE 1.9 поставляется с предварительно установленным сервером метрик.Разверните сервер метрик в пространстве имен
kube-system:kubectl create -f ./metrics-serverЧерез 1 минуту
metric-server начнет передавать данные об использовании ЦП и памяти узлами и подами.Просмотр показателей узлов:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" | jq .Просмотр показателей подов:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/pods" | jq .2. Автомасштабирование на основе использования ЦП и памяти
Для тестирования горизонтального автомасштабирования подов (HPA) можно использовать небольшое веб-приложение на основе Golang.
Разверните podinfo в пространстве имен
default:kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yamlОбратитесь к
podinfo с помощью сервиса NodePort по адресу http://<K8S_PUBLIC_IP>:31198.Задайте HPA, которое будет обслуживать не менее двух реплик и выполнять масштабирование до десяти реплик, если средний показатель использования ЦП превысит 80 % или если расход памяти будет выше 200 МиБ:
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: podinfo
spec:
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: podinfo
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 80
- type: Resource
resource:
name: memory
targetAverageValue: 200MiСоздайте HPA:
kubectl create -f ./podinfo/podinfo-hpa.yamlЧерез пару секунд контроллер HPA свяжется с сервером метрик и получит сведения об использовании ЦП и памяти:
kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
podinfo Deployment/podinfo 2826240 / 200Mi, 15% / 80% 2 10 2 5mЧтобы увеличить использование ЦП, выполните нагрузочный тест с помощью rakyll/hey:
#install hey
go get -u github.com/rakyll/hey
#do 10K requests
hey -n 10000 -q 10 -c 5 http://<K8S_PUBLIC_IP>:31198/Можно выполнять мониторинг событий HPA следующим образом:
$ kubectl describe hpa
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 7m horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 3m horizontal-pod-autoscaler New size: 8; reason: cpu resource utilization (percentage of request) above targetВременно удалите podinfo (вам придется выполнить его повторное развертывание на одном из следующих этапов данного руководства).
kubectl delete -f ./podinfo/podinfo-hpa.yaml,./podinfo/podinfo-dep.yaml,./podinfo/podinfo-svc.yaml3. Настройка сервера Custom Metrics
Для масштабирования на основе специальных показателей необходимо два компонента. Первый — база данных временных рядов Prometheus — собирает показатели приложений и сохраняет их. Второй компонент — k8s-prometheus-adapter — дополняет Custom Metrics API Kubernetes показателями, предоставленными сборщиком.
Для развертывания Prometheus и адаптера используется выделенное пространство имен.
Создайте пространство имен
monitoring:kubectl create -f ./namespaces.yamlРазверните Prometheus v2 в пространстве имен
monitoring:kubectl create -f ./prometheusСгенерируйте сертификаты TLS, необходимые для адаптера Prometheus:
make certsРазверните адаптер Prometheus для Custom Metrics API:
kubectl create -f ./custom-metrics-apiПолучите список специальных показателей, предоставляемых Prometheus:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .Затем извлеките данные по использованию файловой системы для всех подов в пространстве имен
monitoring:kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/monitoring/pods/*/fs_usage_bytes" | jq .4. Автомасштабирование на основе специальных показателей
Создайте сервис NodePort
podinfo и выполните развертывание в пространстве имен default:kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yamlПриложение
podinfo передаст специальный показатель http_requests_total. Адаптер Prometheus удалит суффикс _total и пометит этот показатель как контрпоказатель.Получите общее количество запросов в секунду из Custom Metrics API:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests" | jq .
{
"kind": "MetricValueList",
"apiVersion": "custom.metrics.k8s.io/v1beta1",
"metadata": {
"selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/http_requests"
},
"items": [
{
"describedObject": {
"kind": "Pod",
"namespace": "default",
"name": "podinfo-6b86c8ccc9-kv5g9",
"apiVersion": "/__internal"
},
"metricName": "http_requests",
"timestamp": "2018-01-10T16:49:07Z",
"value": "901m" },
{
"describedObject": {
"kind": "Pod",
"namespace": "default",
"name": "podinfo-6b86c8ccc9-nm7bl",
"apiVersion": "/__internal"
},
"metricName": "http_requests",
"timestamp": "2018-01-10T16:49:07Z",
"value": "898m"
}
]
}Буква
m означает milli-units, поэтому, к примеру, 901m — это 901 миллизапрос.Создайте HPA, которое будет расширять развертывание podinfo, если количество запросов превысит 10 запросов в секунду:
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: podinfo
spec:
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: podinfo
minReplicas: 2
maxReplicas: 10
metrics:
- type: Pods
pods:
metricName: http_requests
targetAverageValue: 10Разверните HPA
podinfo в пространстве имен default:kubectl create -f ./podinfo/podinfo-hpa-custom.yamlЧерез несколько секунд HPA получит значение
http_requests от API метрик:kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
podinfo Deployment/podinfo 899m / 10 2 10 2 1mПримените нагрузку для сервиса podinfo с 25 запросами в секунду:
#install hey
go get -u github.com/rakyll/hey
#do 10K requests rate limited at 25 QPS
hey -n 10000 -q 5 -c 5 http://<K8S-IP>:31198/healthzЧерез несколько минут HPA начнет масштабировать развертывание:
kubectl describe hpa
Name: podinfo
Namespace: default
Reference: Deployment/podinfo
Metrics: ( current / target )
"http_requests" on pods: 9059m / 10<
Min replicas: 2
Max replicas: 10
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 2m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above targetПри текущем количестве запросов в секунду развертывание никогда не достигнет максимальной величины в 10 подов. Трех реплик достаточно для того, чтобы количество запросов в секунду для каждого пода было меньше 10.
После завершения нагрузочных тестов HPA уменьшит масштаб развертывания до первоначального количества реплик:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 5m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target
Normal SuccessfulRescale 21s horizontal-pod-autoscaler New size: 2; reason: All metrics below targetВозможно, вы заметили, что средство автомасштабирования реагирует на изменение показателей не сразу. По умолчанию их синхронизация выполняется каждые 30 секунд. Кроме того, масштабирование происходит только в том случае, если в течение последних 3–5 минут не было увеличения и снижения рабочих нагрузок. Это позволяет предотвратить выполнение конфликтующих решений и оставляет время для подключения средства автомасштабирования кластера.
Заключение
Не все системы могут обеспечить соблюдение требований SLA только на основе показателей использования ЦП или памяти (или обоих сразу). Большинство веб-серверов и мобильных серверов для обработки всплесков трафика нуждаются в автомасштабировании на основе количества запросов в секунду.
Для приложений ETL (от англ. Extract Transform Load — «извлечение, преобразование, загрузка») автомасштабирование может запускаться, например, при превышении заданной пороговой длины очереди заданий.
Во всех случаях инструментирование приложений с помощью Prometheus и выделение необходимых показателей для автомасштабирования позволяют выполнить точную настройку приложений, чтобы улучшить обработку всплесков трафика и обеспечить высокую доступность инфраструктуры.
Идеи, вопросы, замечания? Присоединяйтесь к обсуждению в Slack!
Вот такой получился материал. Ждём ваши комментарии и до встречи на курсе!




