
Классический CDN — anycast, GeoDNS, веб-сервер с кешем — отлично работает с простыми файлами и небольшим количеством пользователей. Но если возникает необходимость раздавать потоковое видео, всё становится намного интереснее. Вместо одного короткого запроса появляется сессия, которая длится десятки минут. Без правильной балансировки пользователей и контента уже не прожить: кеша на всё не хватает, а когда Россия играет против Испании, это хотят смотреть сразу все. Руководитель разработки платформы видеостриминга Андрей Василенков рассказал, благодаря чему наш CDN позволяет обслуживать сотни тысяч пользовательских сессий одновременно и переживать отключения серверов и дата-центров. А в качестве бонуса показал на примере, как современная поп-культура мешает обучению.
— Всем привет! Расскажу, какие вопросы приходится решать, когда вам нужно подготовить ваш сервис к нагрузкам в несколько сотен гигабит, а то и терабит в секунду. Впервые мы с такой проблемой столкнулись в 2018 году, когда готовились к трансляциям чемпионата мира по футболу.
Начнем с того, что вообще такое стриминговые протоколы и как они устроены — самый поверхностный обзорный вариант.

В основе любого стримингового протокола лежит манифест [manifest] или плейлист [playlist]. Это небольшой текстовый файл, который содержит метаинформацию о контенте. Там описан тип контента — live-трансляция или VoD-трансляция (video on demand). Например, в случае live это футбольный матч или онлайн-конференция, как у нас сейчас с вами, а в случае VoD ваш контент заранее подготовлен и лежит на ваших серверах, готовый к раздаче в сторону пользователей. В этом же файле описана длительность контента, информация о DRM.

Там же описаны вариации контента — видеодорожки, аудиодорожки, субтитры. Видеодорожки могут быть представлены в разных кодеках. Например, универсальный H.264 поддерживается на любом устройстве. С его помощью вы сможете проиграть видео на любом утюге у вас дома. Или есть более современные и более эффективные кодеки HEVC и VP9, которые позволяют вам передавать картинку 4K с поддержкой HDR.
Аудиодорожки тоже могут быть представлены в разных кодеках с разными битрейтами. А еще их может быть несколько — оригинальная аудиодорожка фильма на английском языке, перевод на русский язык, интершум или, например, запись спортивного события напрямую со стадиона без комментаторов.

Что со всем этим делает плеер? Задача плеера — в первую очередь выбрать те вариации контента, которые он может проиграть, просто потому что не все кодеки универсальны, не все могут быть проиграны на определенном устройстве.
После этого ему нужно подобрать качество видео и аудио, с которого он будет начинать проигрывание. Сделать это он может на основе условий сети, если они ему известны, или на основе какой-нибудь очень простой эвристики. Например, начинать проигрывать с низкого качества и, если сеть позволяет, потихоньку увеличивать разрешение.
Также на этом этапе он выбирает аудиодорожку, с которой он будет начинать проигрывание. Предположим, у вас в операционной системе стоит английский язык. Тогда он может выбрать по умолчанию английскую аудиодорожку. Наверное, вам так будет удобнее.
После этого он начинает формировать ссылки на видео- и аудиосегменты. На самом деле это обычные HTTP-ссылки, такие же, как во всех остальных сценариях в интернете. И он начинает скачивать видео- и аудиосегменты, складывать их в буфер друг за другом и бесшовно проигрывать. Такие видеосегменты, как правило, имеют длительность 2, 4, 6 секунд, может быть, 10 секунд в зависимости от вашего сервиса.

Какие тут есть важные моменты, про которые нам нужно думать, когда мы проектируем наш CDN? В первую очередь, у нас появляется сессия пользователя.
Мы не можем просто отдать пользователю файл и забыть про этого пользователя. Он постоянно возвращается и докачивает новые и новые сегменты себе в буфер.
Тут важно понимать, что время ответа сервера тоже имеет значение. Если мы показываем какую-нибудь live-трансляцию в реальном времени, то не можем делать большой буфер просто потому, что пользователь хочет смотреть видео настолько близко к реальному времени, насколько возможно. Ваш буфер в принципе не может быть большим. Соответственно, если сервер не успевает отвечать за то время, пока пользователь успевает просматривать контент, видео в какой-то момент просто зависнет. К тому же контент довольно тяжеловесный. Стандартный битрейт для Full HD 1080p — 3-5 Мбит/с. Соответственно, на одном гигабитовом сервере вы не сможете обслужить больше 200 пользователей одновременно. И это идеальная картинка, потому что пользователи, как правило, равномерно по времени со своими запросами не ходят.

В какой момент пользователь вообще взаимодействует с вашим CDN? Взаимодействие происходит в основном в двух местах: когда плеер скачивает манифест (плейлист), и когда он скачивает сегменты.
Про манифесты мы уже поговорили, это небольшие текстовые файлы. С раздачей таких файлов нет особых проблем. Хотите — хоть с одного сервера их раздавайте. А если это сегменты, то они и составляют бо́льшую часть вашего трафика. Про них мы и будем говорить.
Задача всей нашей системы сводится к тому, что мы хотим сформировать правильную ссылку на эти сегменты и подставить туда правильный домен какого-нибудь нашего CDN-хоста. В этом месте мы пользуемся следующей стратегией: сразу в плейлисте отдаем нужный CDN-хост, куда пользователь пойдет. Этот подход лишен многих недостатков, но обладает одним важным нюансом. Вам нужно гарантировать, что у вас есть механизм, который позволит увести пользователя с одного хоста на другой бесшовно в процессе проигрывания, не прерывая просмотр. На самом деле такая возможность есть у всех современных стриминговых протоколов, и HLS, и DASH такое поддерживают. Нюанс: довольно часто даже в очень популярных опенсорс-библиотеках такая возможность не реализована, хоть и существует по стандарту. Нам самим приходилось посылать пачки в опенсорс-библиотеку Shaka, она джаваскриптовая, используется для веб-плеера, для проигрывания DASH.
Есть еще одна схема — anycast-схема, когда вы используете один единый домен и отдаете во всех ссылках именно его. В этом случае вам не нужно думать ни про какие нюансы, — отдаете один домен, и все счастливы. (...)
Теперь давайте поговорим про то, как мы будем формировать наши ссылки.
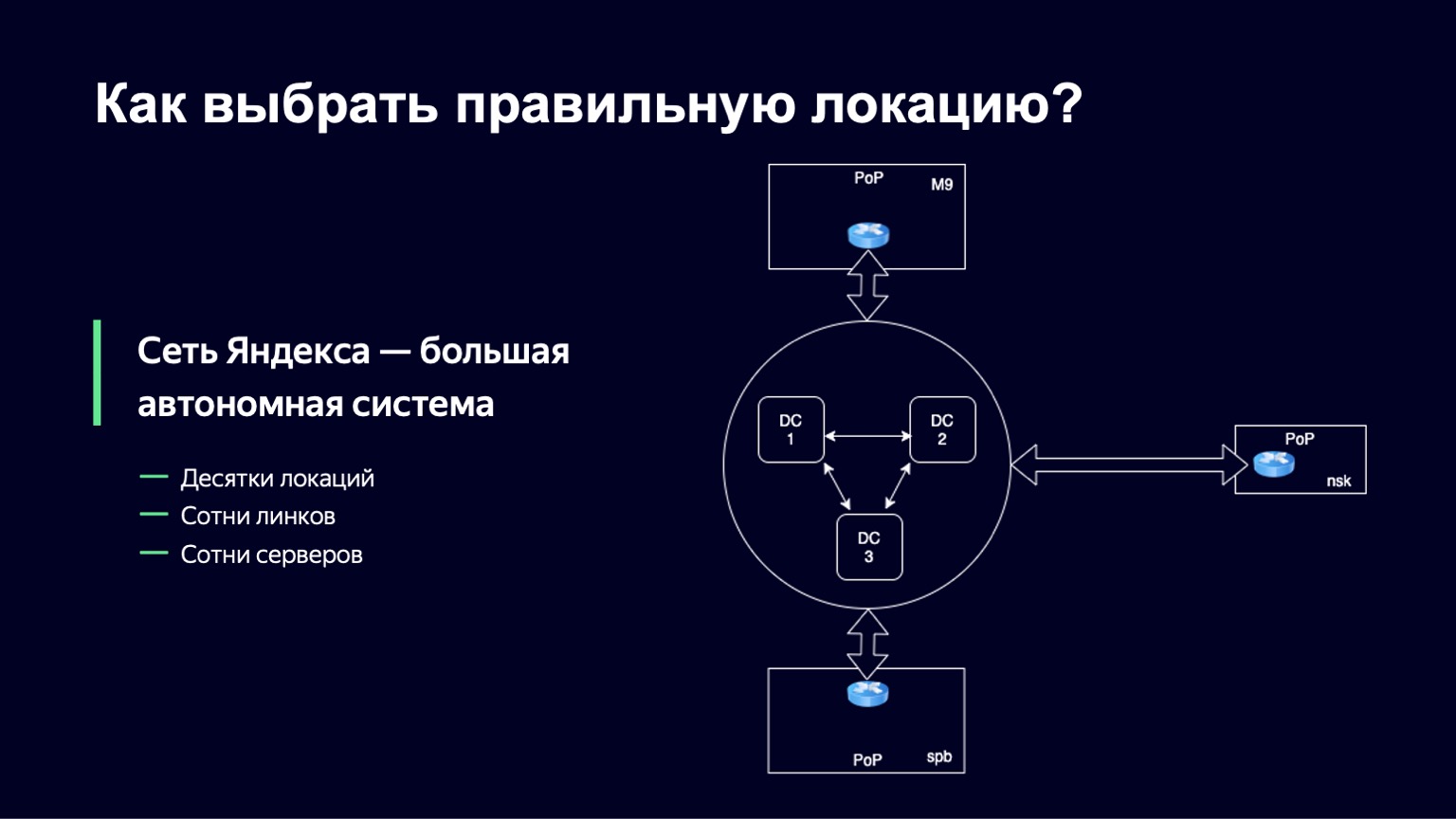
С точки зрения сети любая крупная компания устроена как автономная система, и часто даже не одна. На самом деле автономная система — это система IP-сетей и маршрутизаторов, которые управляются единым оператором и обеспечивают единую политику маршрутизации с внешней сетью, с интернетом. Яндекс тут не исключение. Сеть Яндекса — тоже автономная система, и связь с другими автономными системами происходит за пределами дата-центров Яндекса в точках присутствия. В эти точки присутствия приходят физические кабели Яндекса, физические кабели других операторов, и они коммутируются на месте, на железном оборудовании. Именно в таких точках у нас есть возможность поставить несколько своих серверов, жесткие диски, SSD. Именно туда мы и будем направлять трафик пользователей.
Этот набор серверов мы будем называть локацией. И в каждой такой локации у нас есть уникальный идентификатор. Мы его будем использовать в составе доменного имени хостов на этой площадке и просто чтобы однозначно ее идентифицировать.
Таких площадок в Яндексе несколько десятков, серверов на них несколько сотен, и в каждую локацию приходят линки от нескольких операторов, поэтому линков у нас тоже порядка нескольких сотен.
Как мы будем выбирать, на какую локацию отправить конкретного пользователя?

На этом этапе вариантов не очень много. Мы можем использовать только IP-адрес, чтобы принимать решения. С этим нам помогает отдельная команда Яндекса Traffic Team, которая знает все про то, как устроен трафик и сеть в компании, и именно она собирает маршруты других операторов, чтобы мы использовали эти знания в процессе балансировки пользователей.
Набор маршрутов она собирает с помощью BGP. Про BGP подробно говорить не будем, это протокол, который позволяет участникам сети на границах своих автономных систем анонсировать, какие же маршруты их автономная система может обслужить. Traffic Team собирает всю эту информацию, агрегирует, анализирует и строит полную карту всей сети, которой мы и пользуемся для балансировки.
Мы получаем от команды Traffic Team набор IP-сетей и линков, через которые мы можем обслуживать клиентов. Дальше нам нужно понять, какая же IP-подсеть подходит конкретному пользователю.
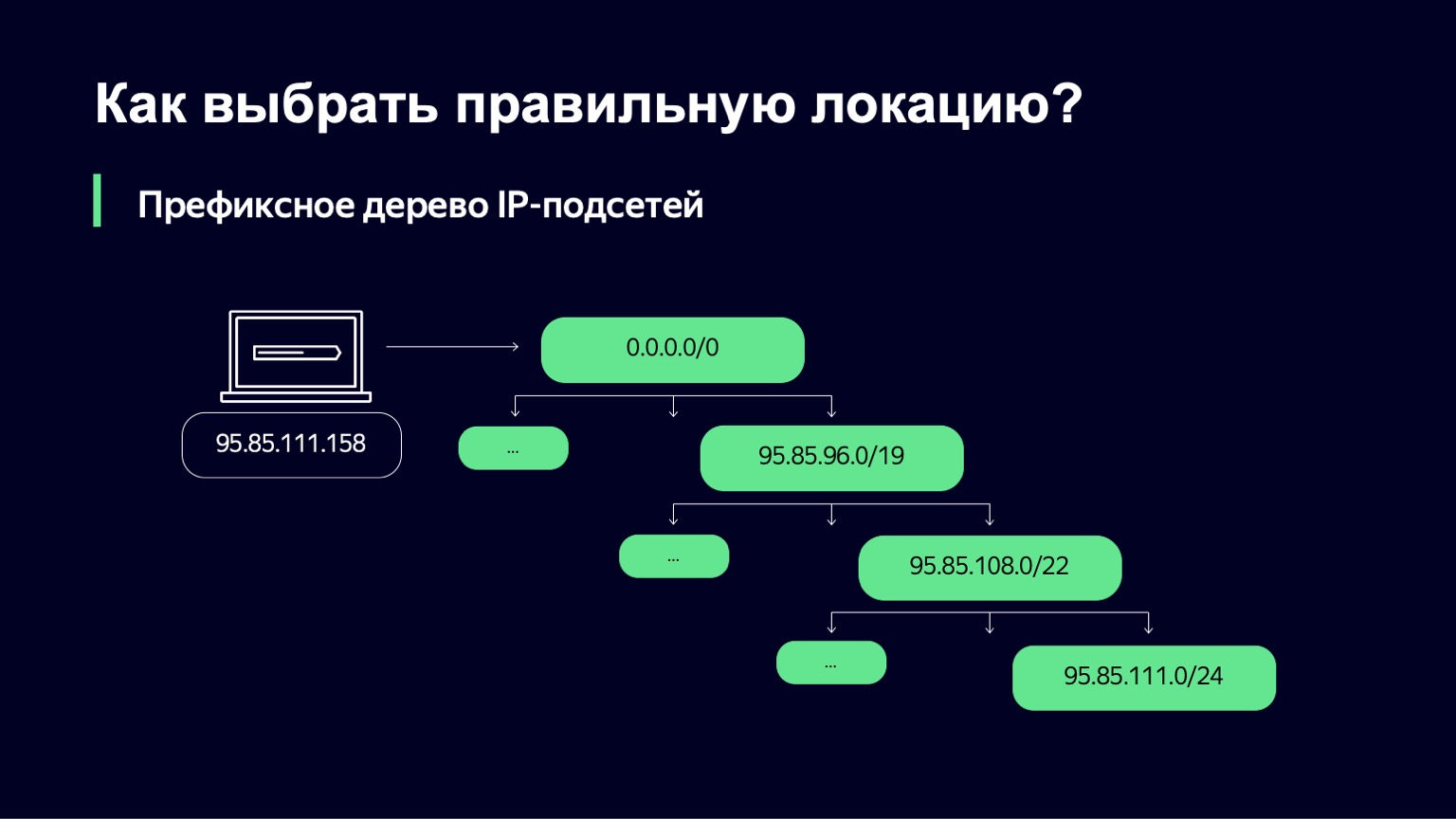
Делаем это довольно простым способом — строим префиксное дерево. А дальше наша задача — используя в качестве ключа IP-адрес пользователя, найти, какая подсеть наиболее точно соответствует этому IP-адресу.
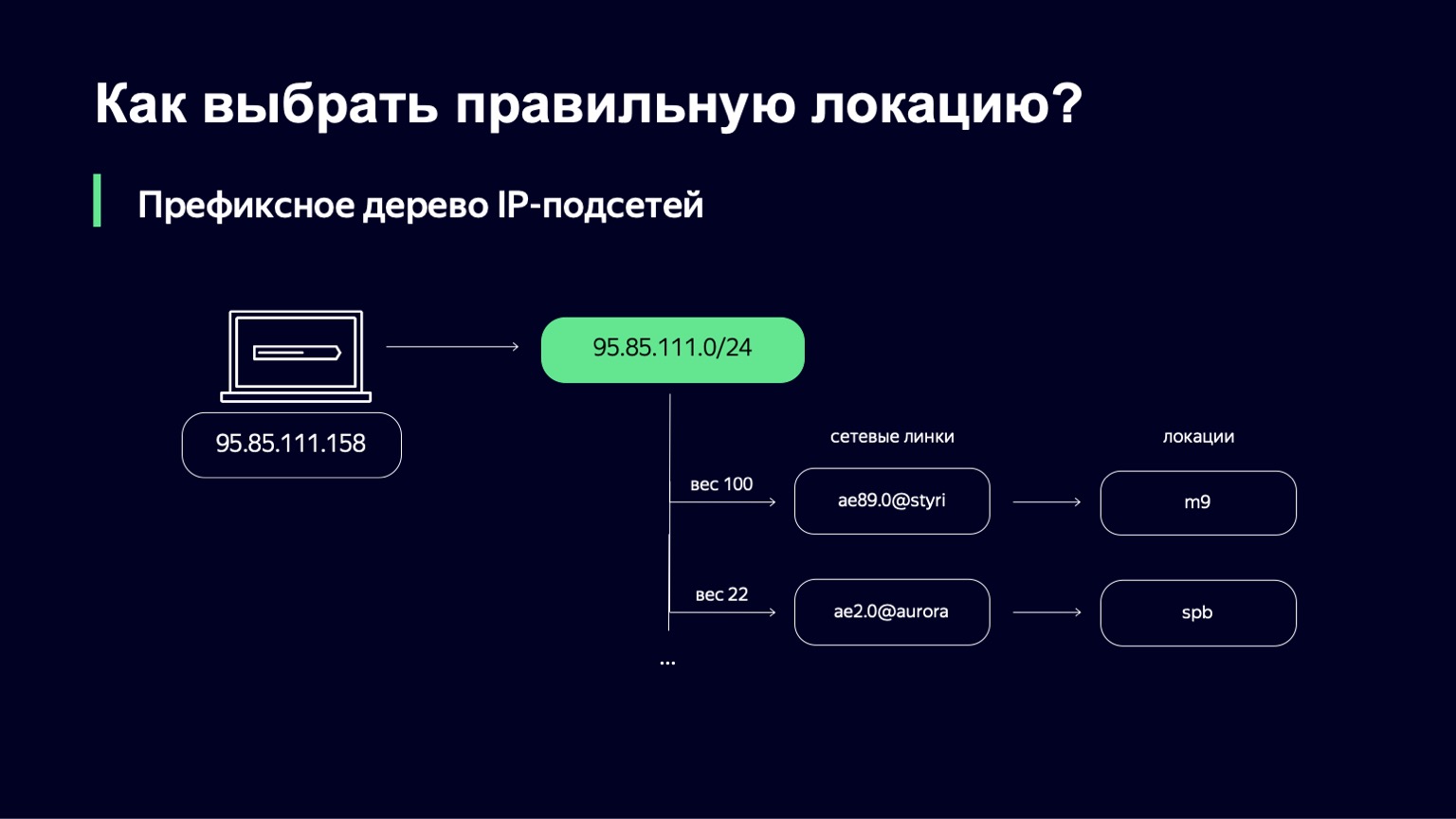
Когда мы ее нашли, у нас есть список линков, их веса, и по линкам мы можем однозначно определить ту локацию, куда отправим пользователя.

Что такое вес в этом месте? Это метрика, которая позволяет управлять распределением пользователей по разным локациям. У нас могут быть линки, например, разной емкости. У нас может быть 100-гигабитный линк и 10-гигабитный линк на одной площадке. Очевидно, что в первый линк мы хотим отправлять больше пользователей, потому что он более емкий. Этот вес учитывает топологию сети, потому что интернет — сложный граф связанного между собой сетевого оборудования, трафик у вас может пойти по разным путям, и эту топологию тоже нужно учитывать.
Обязательно нужно смотреть, как происходит реальное скачивание данных пользователями. Это можно делать и на серверной, и на клиентской стороне. На сервере мы активно собираем в логах TCP info пользовательских соединений, смотрим на round-trip time. С пользовательской стороны мы активно собираем perf-логи браузера и плеера. В этих perf-логах есть подробная информация о том, как происходило скачивание файлов с нашего CDN.
Если все это проанализировать, проагрегировать, то с помощью этих данных мы можем улучшить веса, которые на первом этапе были выбраны командой Traffic Team.

Допустим, мы выбрали линк. Можем ли мы прямо на этом этапе отправлять туда пользователей? Не можем, потому что вес довольно статичен на протяжении долгого периода времени, и он не учитывает никакую реальную динамику нагрузки. Мы хотим в реальном времени определять, можем ли мы сейчас использовать линк, загруженный, скажем, на 80%, когда рядом есть чуть менее приоритетный линк, загруженный всего на 10%. Скорее всего, в этом случае мы как раз захотим использовать второй.

Что еще нужно принимать во внимание в этом месте? Мы должны учитывать пропускную способность линка, понимать его текущий статус. Он может работать или быть технически неисправным. Или, может быть, мы его хотим увести в сервис, чтобы не пускать туда пользователей и обслуживать его, расширить, например. Мы всегда должны учитывать текущую нагрузку этого линка.
Тут есть несколько интересных нюансов. Собирать информацию о загрузке линка можно в нескольких точках — скажем, на сетевом оборудовании. Это самый точный способ, но его проблема в том, что на сетевом оборудовании вы не можете получить быстрый период апдейта этой загрузки. Например, в Яндексе сетевое оборудование довольно разнообразное, и у нас не получается собирать эти данные чаще, чем раз в минуту. Если система по нагрузке довольно стабильна, это вообще не проблема. Все будет работать замечательно. Но как только у вас появляются резкие притоки нагрузки, вы просто не успеваете реагировать, и это приводит, например, к дропам пакетов.
С другой стороны, вы знаете, сколько байт отдали в сторону пользователя. Вы можете собирать эту информацию на самих раздающих машинках, сделать прямо счетчик байтов. Но это будет не настолько точно. Почему?
В нашем CDN есть и другие пользователи. Мы не единственный сервис, который пользуется этими раздающими машинками. И на фоне нашей нагрузки нагрузка других сервисов не такая значительная. Но даже на нашем фоне она бывает довольно-таки заметной. Их раздачи проходят не через наш контур, поэтому мы не можем управлять этим трафиком.
Другой момент: даже если вы считаете на раздающей машине, что вы отправили трафик в какой-то один конкретный линк, — это далеко не факт, потому что BGP как протокол не дает вам такой гарантии. И тут есть способы, как можно увеличить вероятность того, что вы угадаете, но это предмет отдельного разговора.

Допустим, мы посчитали метрики, всё собрали. Теперь нужен алгоритм принятия решения при балансировке. Он должен обладать четырьмя важными свойствами:
— Обеспечивать пропускную способность линка.
— Предупреждать перегрузку линка, просто потому что если вы загрузили линк на 95% или 98%, то у вас начинают переполняться буферы на сетевом оборудовании, начинаются дропы пакетов, ретрансмиты, и пользователи ничего хорошего от этого не получают.
— Предупреждать «пил» нагрузки, про это поговорим чуть позже.
— В идеальном мире было бы здорово, чтобы мы научились утилизировать линк до определенного уровня, который мы считаем правильным. Например, 85% загрузки.

Мы взяли за основу следующую мысль. У нас есть два разных класса сессий пользователей. Первый класс — это новые сессии, когда пользователь только открыл фильм, еще ничего не смотрел и мы пытаемся понять, куда же его отправить. Или же второй класс, когда у нас есть текущая сессия, пользователь уже обслуживается на линке, занимает определенную часть полосы, обслуживается на конкретном сервере.
Что мы с ними будем делать? Введем по одной вероятностной величине на каждый такой класс сессии. У нас будет величина под названием Slowdown, определяющая процент новых сессий, которые мы не будем пускать на этот линк. Если Slowdown равен нулю, то мы все новые сессии принимаем, а если он равен 50%, то каждую, грубо говоря, вторую сессию мы отказываемся обслуживать на этом линке. При этом наш алгоритм балансировки на более высоком уровне будет проверять альтернативные варианты для этого пользователя. Drop — то же самое, только для текущих сессий. Мы можем часть пользовательских сессий увести с площадки куда-нибудь в другое место.
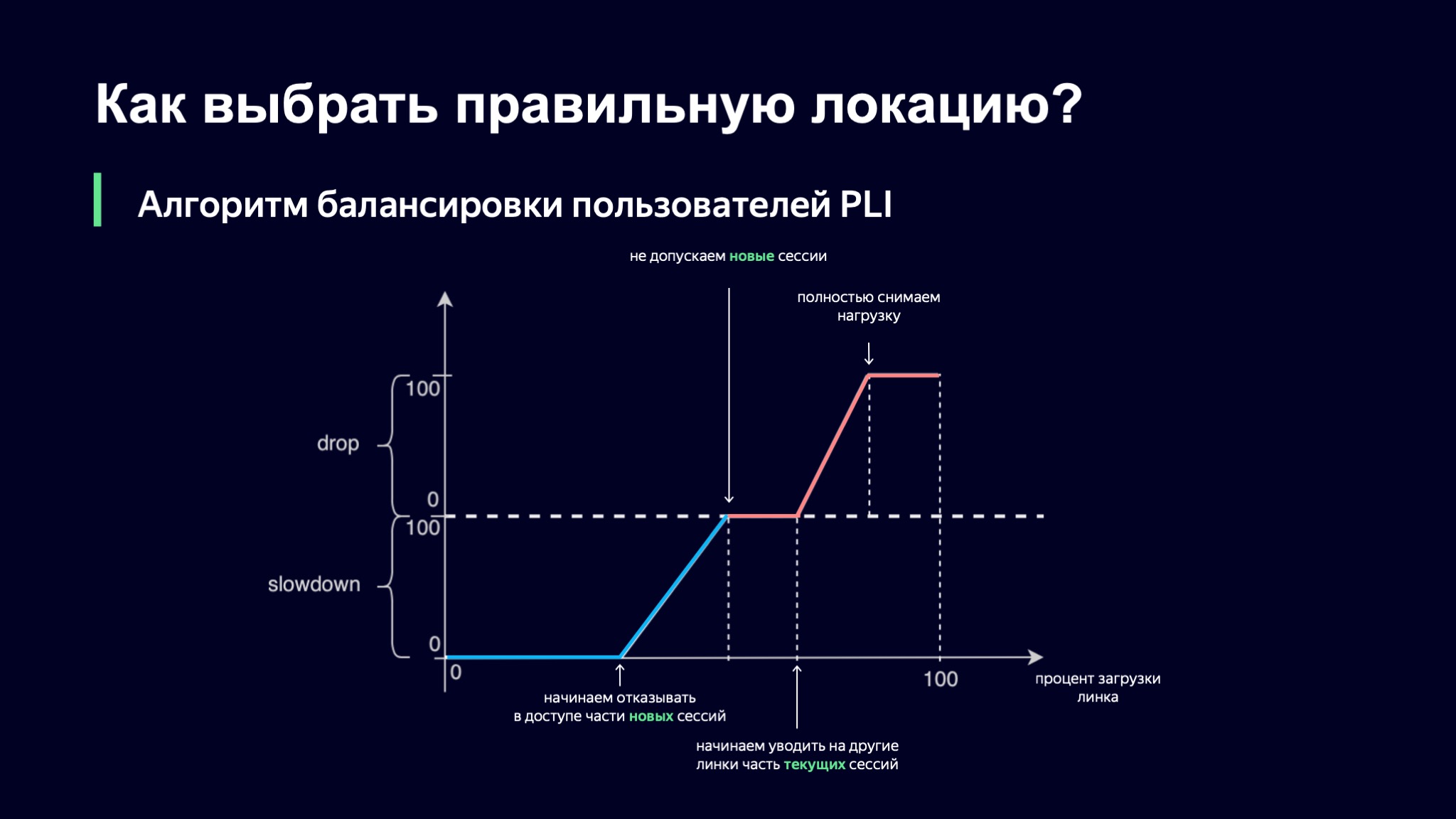
Как мы будем выбирать, каким будет значение наших вероятностных метрик? В качестве основы возьмем процент загрузки линка, а дальше первая наша идея была такой: давайте воспользуемся кусочно-линейной интерполяцией.
Мы взяли такую функцию, которая имеет несколько точек преломления, и по ней смотрим значение наших коэффициентов. Если уровень загрузки линка минимальный, то все хорошо, Slowdown и Drop равны нулю, мы пускаем всех новых пользователей. Как только уровень загрузки переходит через некоторый порог, мы начинаем части пользователей отказывать в обслуживании на этом линке. В какой-то момент, если нагрузка продолжает расти, мы просто перестаем пускать новые сессии.
Тут есть интересный нюанс: текущие сессии в этой схеме имеют приоритет. Думаю, понятно, почему так происходит: если ваш пользователь уже обеспечивает вам стабильный паттерн нагрузки, вы не хотите его никуда уводить, потому что таким образом увеличиваете динамику системы, а чем стабильнее система, тем нам проще ее контролировать.
Тем не менее, загрузка может продолжать расти. В какой-то момент мы можем начать уводить часть сессий или даже полностью снять нагрузку с этого линка.
Именно в таком виде мы и запустили этот алгоритм на первых матчах чемпионата мира по футболу. Наверное, интересно посмотреть, какую картинку мы увидели. Она была примерно следующей.
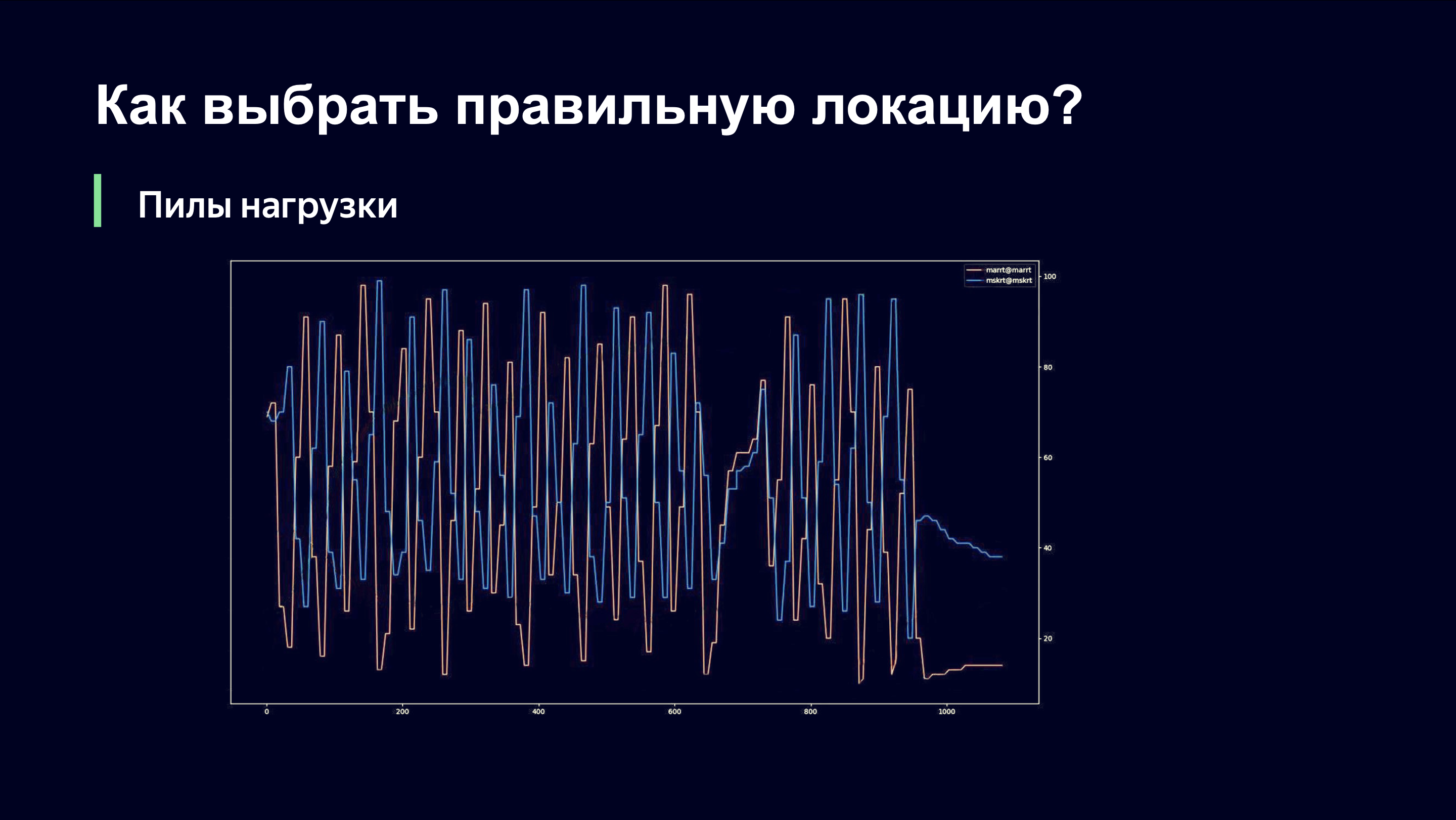
Даже невооруженным глазом сторонний наблюдатель может понять, что тут что-то, наверное, не так, и спросить меня: «Андрей, все ли у вас хорошо?». А если бы вы были моим начальником, вы бы бегали по комнате и кричали: «Андрей, боже мой! Откатывайте все назад! Верните все как было!» Давайте расскажу, что тут происходит.
По оси X время, по оси Y мы наблюдаем за уровнем нагрузки линков. Тут изображены два линка, которые обслуживают одну и ту же площадку. Важно понимать, что в этот момент мы пользовались только той схемой наблюдения за загрузкой линка, которая снимается с сетевого оборудования, и поэтому не могли быстро реагировать на динамику нагрузки.
Когда мы отправляем пользователей в какой-то из линков, происходит резкий рост трафика на этом линке. Линк перегружается. Мы снимаем нагрузку и оказываемся в правой части функции, которую видели на предыдущем графике. И мы начинаем сбрасывать старых пользователей и перестаем пускать новых. Им нужно куда-то идти, а идут они, конечно же, на соседний линк. В прошлый раз он, возможно, был менее приоритетным, а теперь он у них в приоритете.
На втором линке повторяется та же картинка. Мы резко повышаем нагрузку, замечаем, что линк перегружен, снимаем нагрузку, и эти два линка оказываются в противофазе по уровню нагрузки.
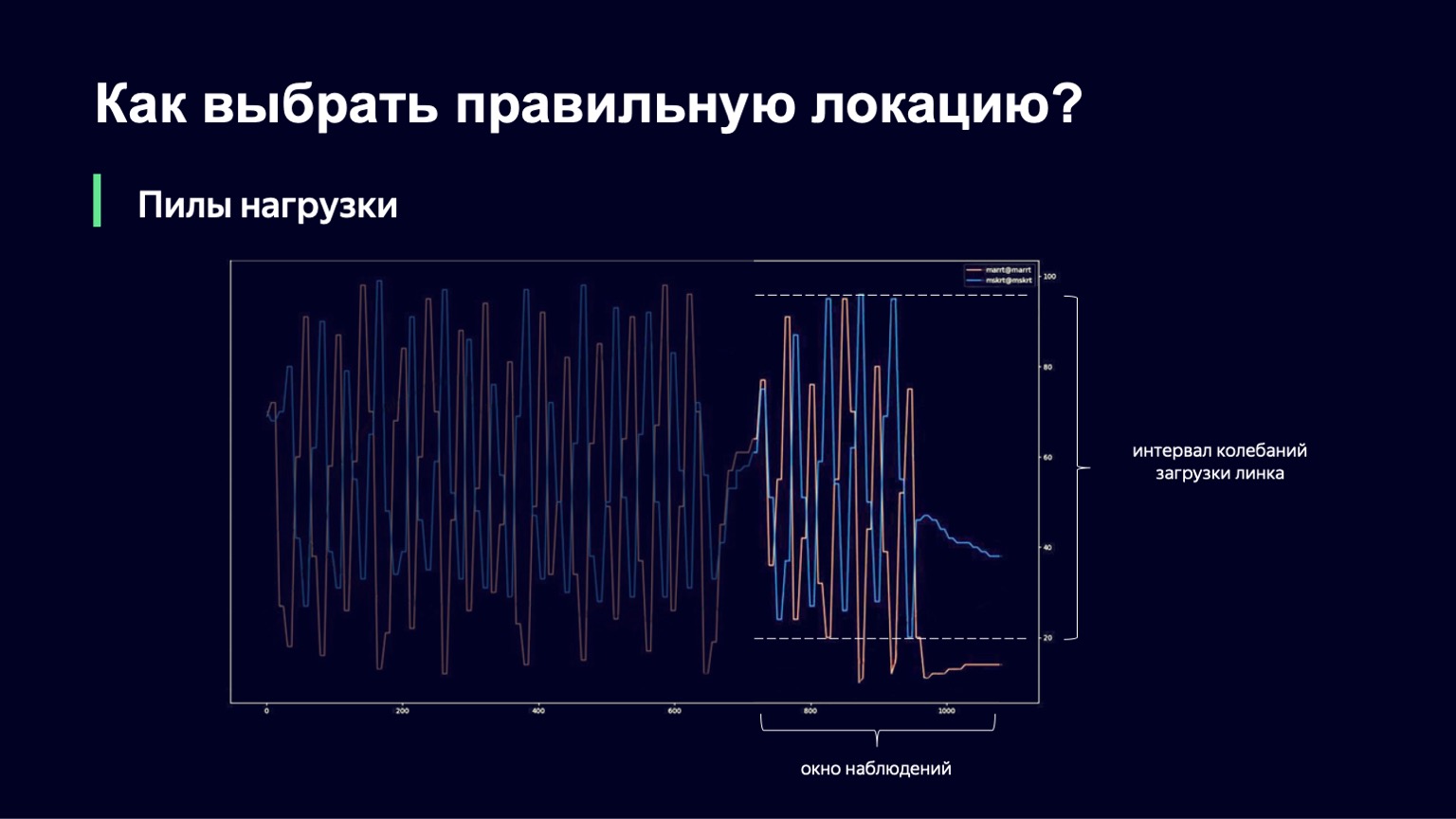
Что можно сделать? Мы можем проанализировать динамику системы, при большом росте нагрузки замечать это и немного ее демпфировать. Именно это мы и сделали. Мы взяли текущий момент, взяли окно наблюдений в прошлое за несколько минут, например 2-3 минуты, и посмотрели, насколько сильно меняется загрузка линка на этом интервале. Разницу между минимальным и максимальным значением мы будем называть интервалом колебаний этого линка. И если этот интервал колебаний большой, мы добавим демпфирование, таким образом увеличим наш Slowdown и станем пускать меньше сессий.
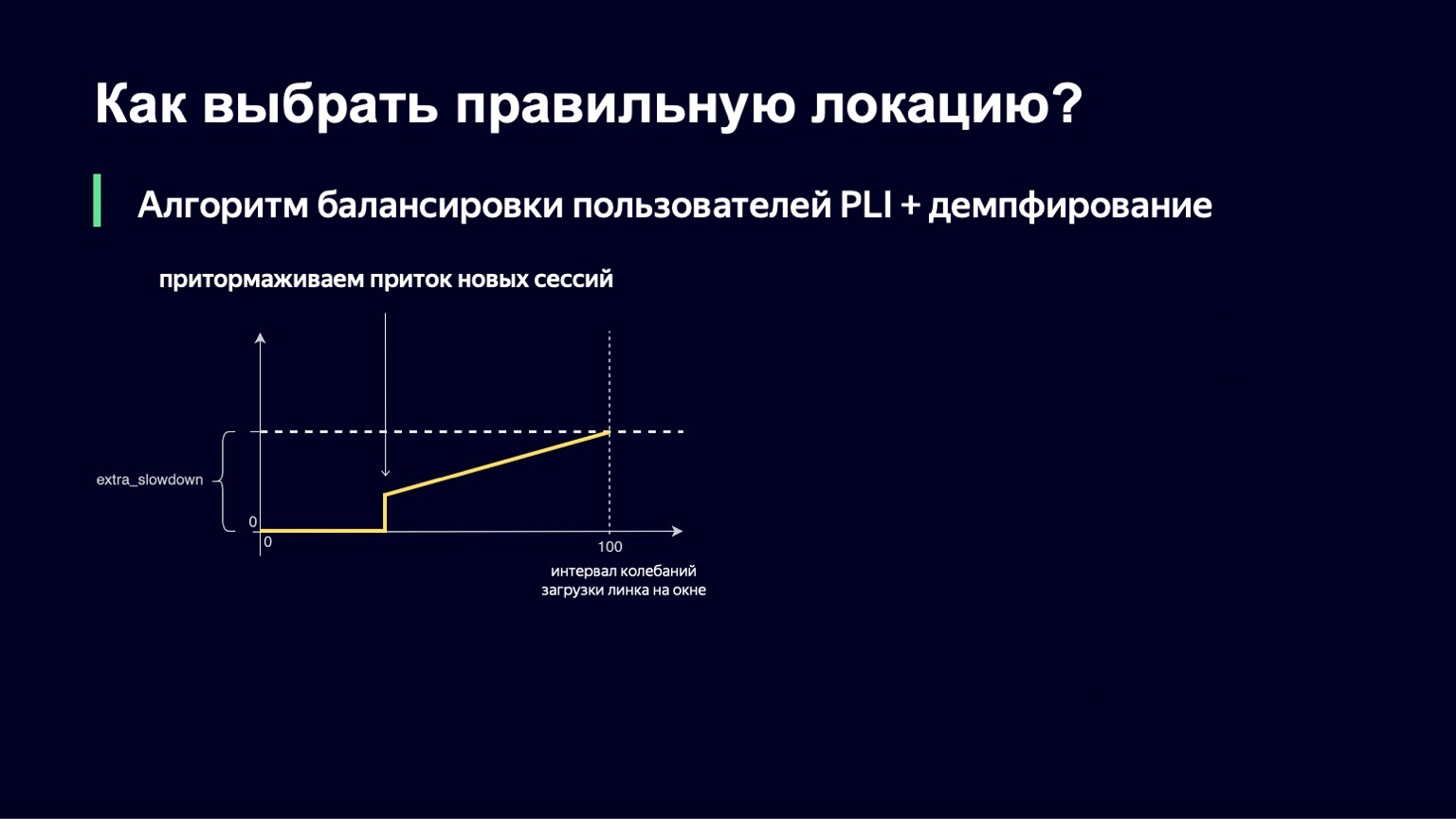
Выглядит эта функция примерно так же, как и прошлая, с чуть меньшим числом переломов. Если у нас интервал загрузки колебаний небольшой, то никакого extra_slowdown мы добавлять не будем. А если интервал колебаний начинает расти, то extra_slowdown принимает ненулевые значения, позже мы будем прибавлять его к основному Slowdown.
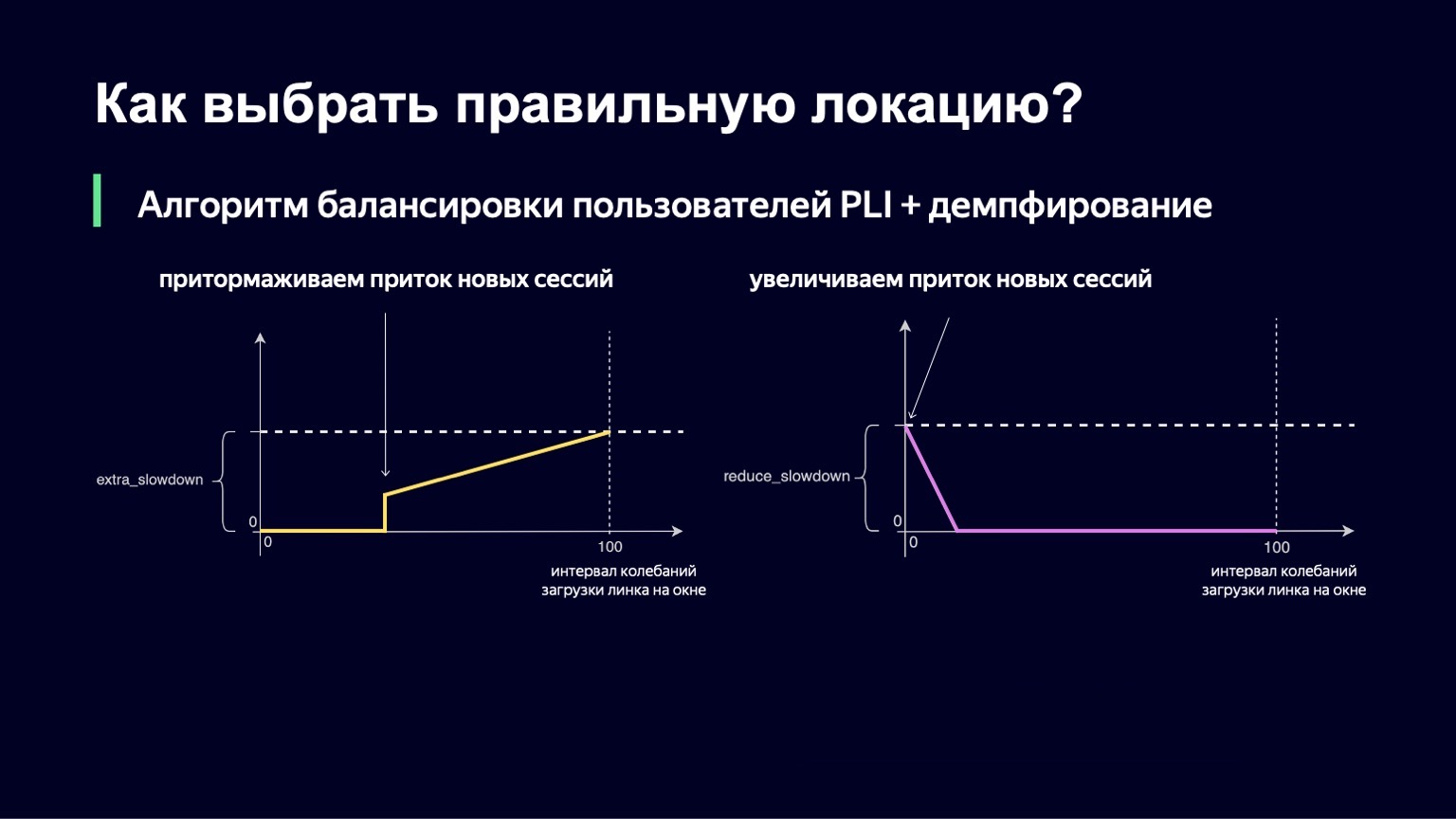
Такая же логика работает и при низких значениях интервала колебаний. Если у вас колебания на линке минимальные, то вы, возможно, наоборот, хотите пустить туда немножко больше пользователей, снизить Slowdown и тем самым лучше утилизировать ваш линк.
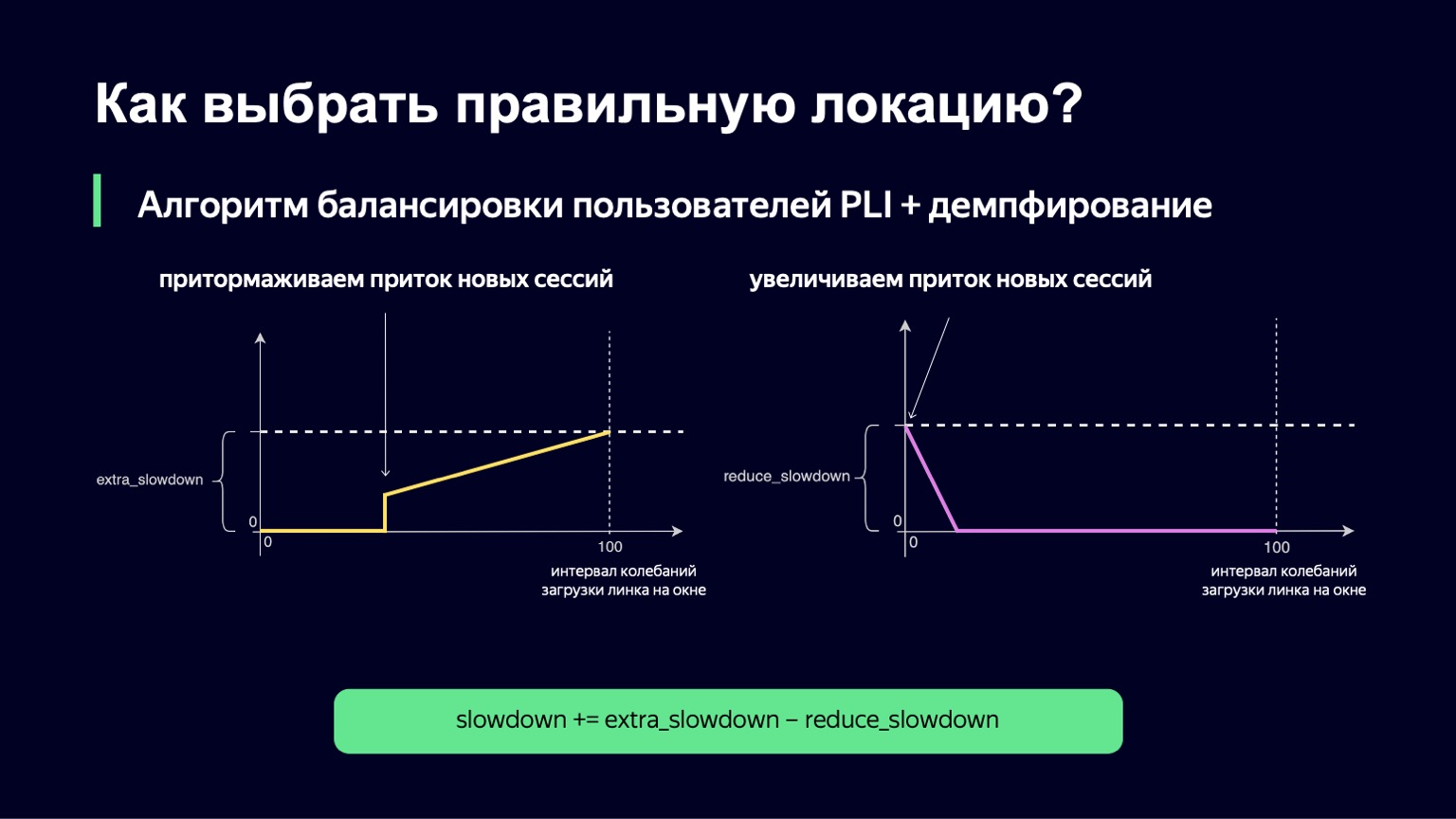
Эту часть мы тоже внедрили. Итоговая формула имеет примерно следующий вид. При этом мы гарантируем, что обе эти величины — extra_slowdown и reduce_slowdown — никогда не имеют ненулевого значения одновременно, поэтому эффективно работает только одна из них. Именно в таком виде эта формула балансировки пережила все топовые матчи чемпионата мира по футболу. Даже на самых популярных матчах она работала довольно хорошо: это «Россия — Хорватия», «Россия — Испания». Во время этих матчей мы раздавали рекордные для Яндекса объемы трафика — 1,5 терабита в секунду. Мы спокойно это пережили. С тех пор формула никак не менялась, потому что такого трафика на нашем сервисе с тех пор не было — до определенного момента.
Потом к нам пришла пандемия. Людей отправили сидеть домой, а дома есть хороший интернет, телевизор, планшет и много свободного времени. Трафик на наши сервисы стал органично расти, довольно быстро и значимо. Сейчас такого рода нагрузки, как были во время чемпионата мира по футболу, — наша ежедневная рутина. Мы с тех пор немного расширили наши каналы с операторами, но, тем не менее, начали задумываться о следующей итерации нашего алгоритма, о том, какой она должна быть и как нам лучше утилизировать нашу сеть.

Какие есть недостатки у нашего предыдущего алгоритма? Мы не решили две проблемы. Мы не избавились полностью от «пил» нагрузок. Мы очень сильно улучшили картинку и амплитуда этих колебаний минимальна, период сильно увеличился, что тоже позволяет лучше утилизировать сеть. Но все равно они временами появляются, остаются. Мы не научились утилизировать сеть до того уровня, до какого хотели бы. Например, у нас нет возможности с помощью конфигурации задать желаемый максимальный уровень нагрузки линка в 80-85%.

Какие у нас есть мысли о следующей итерации алгоритма? Как мы представляем себе идеальную утилизацию сети? Одним из перспективных направлений, казалось бы, является вариант, когда у вас есть единое место принятия решений о трафике. Вы в одном месте собираете все метрики, туда же приходит пользовательский запрос о скачивании сегментов, и в каждый момент времени у вас есть полное состояние системы, вам очень легко принимать решения.
Но тут есть два нюанса. Первый — в Яндексе не принято писать «единые места принятия решений», просто потому что при наших уровнях нагрузки, при нашем трафике, такое место быстро становится узким местом.
Есть еще один нюанс — в Яндексе важно писать еще и отказоустойчивые системы. Мы часто полностью отключаем дата-центры, при этом ваш компонент должен продолжать работать без ошибок, без прерываний. И в таком виде это единое место становится, на самом деле, распределенной системой, которую вам нужно контролировать, а это чуть более сложная задача, чем та, которую мы бы хотели решать в этом месте.

Нам обязательно нужны быстрые метрики. Без них единственное, что вы можете сделать, избежав страданий пользователя, — недоутилизировать сеть. Но это нас тоже не устраивает.
Если посмотреть на нашу систему высокоуровнево, станет понятно, что наша система — динамическая система с обратной связью. У нас есть пользовательская нагрузка, которая является входящим сигналом. Люди приходят и уходят. У нас есть контрольный сигнал — те самые две величины, которые мы можем менять в реальном времени. Для таких динамических систем с обратной связью уже давно, несколько десятилетий, разрабатывается теория автоматического управления. И именно ее компоненты мы бы хотели применить для того, чтобы стабилизировать нашу систему.
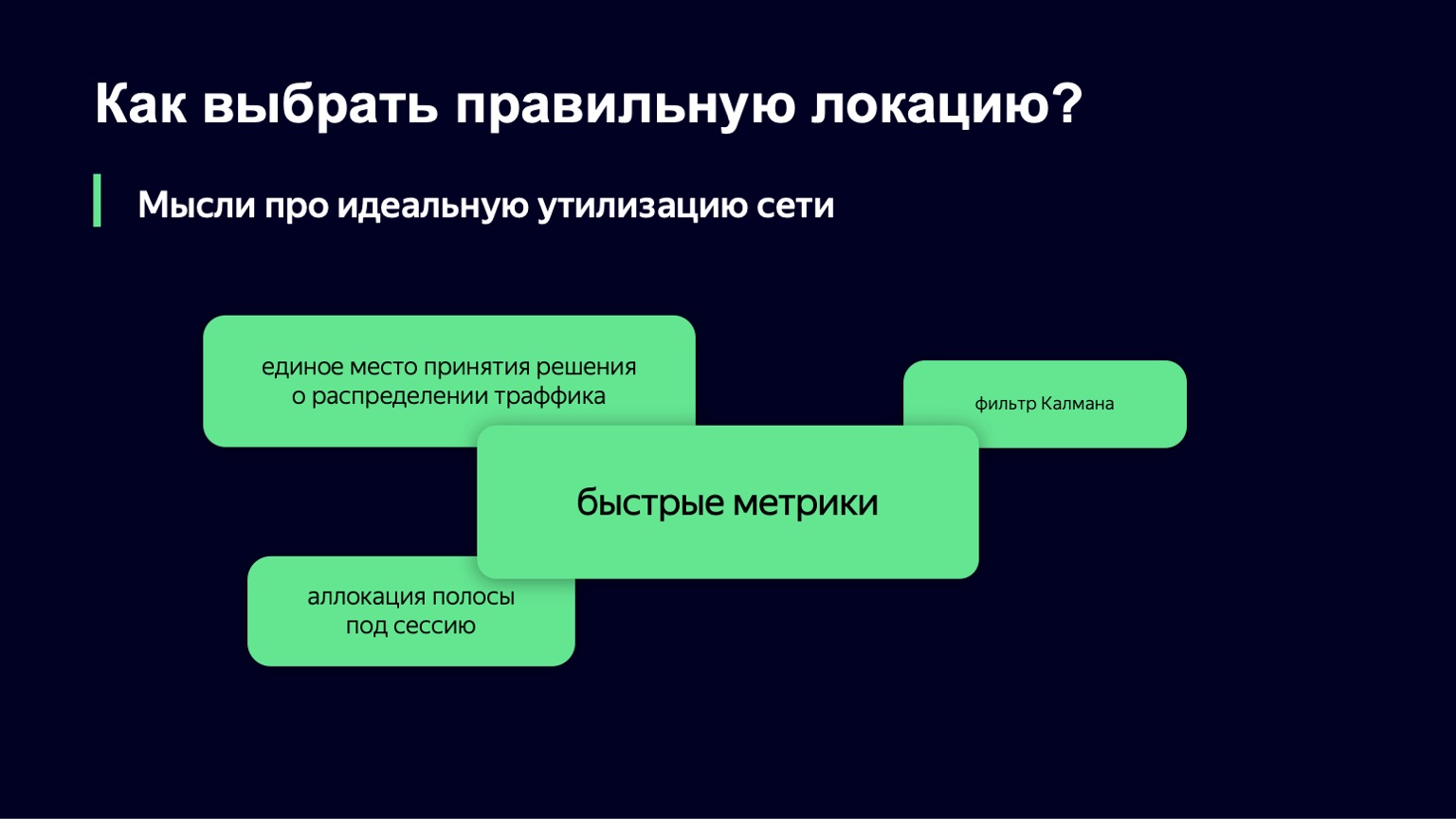
Мы посмотрели на фильтр Калмана. Это такая крутая штука, которая позволяет построить математическую модель системы и при зашумленных метриках или при отсутствии некоторых классов метрик улучшить модель с помощью вашей реальной системы. И потом принимать решение о реальной системе, основываясь на математической модели. К сожалению, оказалось, что у нас не так много классов метрик, которые мы можем использовать, и не получается этот алгоритм применить.
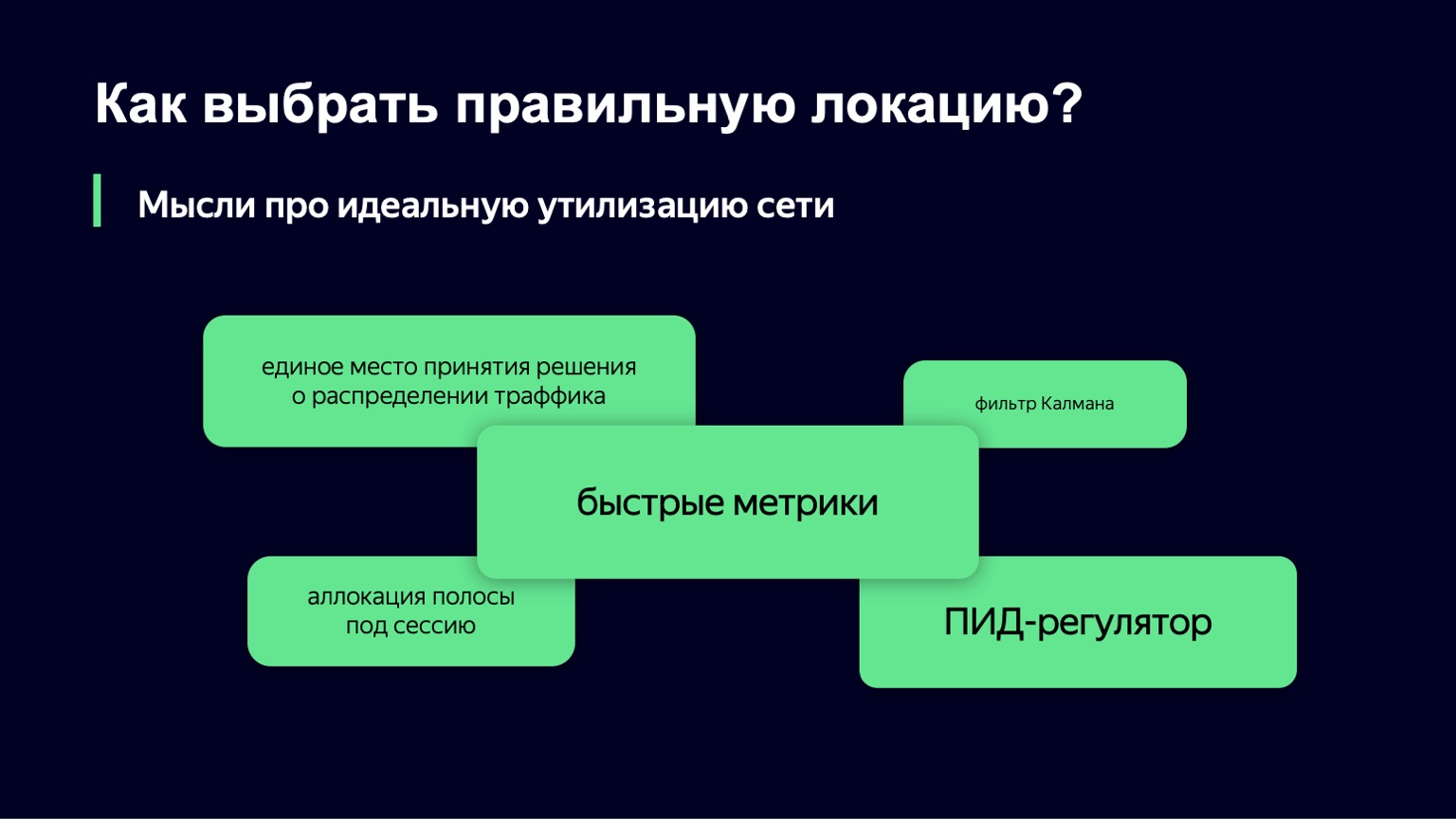
Мы подошли с другой стороны, взяли за основу другой компонент этой теории — PID-регулятор. Он ничего не знает про вашу систему. Его задача — знать идеальное состояние системы, то есть наш желаемый уровень загрузки, и текущее состояние системы, например уровень нагрузки. Разницу между двумя этими состояниями он считает ошибкой и с помощью своих внутренних алгоритмов управляет контрольным сигналом, то есть нашими значениями Slowdown и Drop. Его цель — минимизировать ошибку, которая есть в системе.
Со дня на день мы попробуем этот PID-регулятор в продакшене. Возможно, через несколько месяцев сможем рассказать вам о результатах.
На этом мы, наверное, закончим про сеть. Очень хотелось бы рассказать вам и про то, как мы распределяем трафик внутри самой локации, когда уже выбрали ее между хостами. Но на это времени не остается. Это, наверное, тема для отдельного большого доклада.

Поэтому в следующих сериях вы узнаете, как оптимально утилизировать кеш на хостах, что делать с горячим и холодным трафиком, а также откуда берется тепленький, как тип контента влияет на алгоритм его распределения и какой ролик дает самый высокий кеш-хит на сервисе, и кто же, кто же, кто же песенку поет.
У меня есть еще одна интересная история. Весной, как вы знаете, начался карантин. У Яндекса давно есть образовательная платформа Яндекс.Учебник, которая позволяет учителям загружать ролики, уроки. Школьники туда приходят и смотрят контент. Во время пандемии Яндекс начал поддерживать школы, активно звать их на свою платформу, чтобы школьники могли обучаться удаленно. И мы в какой-то момент увидели довольно хороший рост трафика, довольно стабильную картинку. Но в один из апрельских вечеров мы увидели на графиках примерно следующее.
Снизу — картинка трафика на образовательном контенте. Мы увидели, что он в какой-то момент резко упал. Начали паниковать, выяснять, что вообще происходит, что у нас сломалось. Потом мы заметили, что общий трафик на сервис при этом начал расти. Очевидно, случилось что-то интересное.
На самом деле в этот момент произошло следующее.
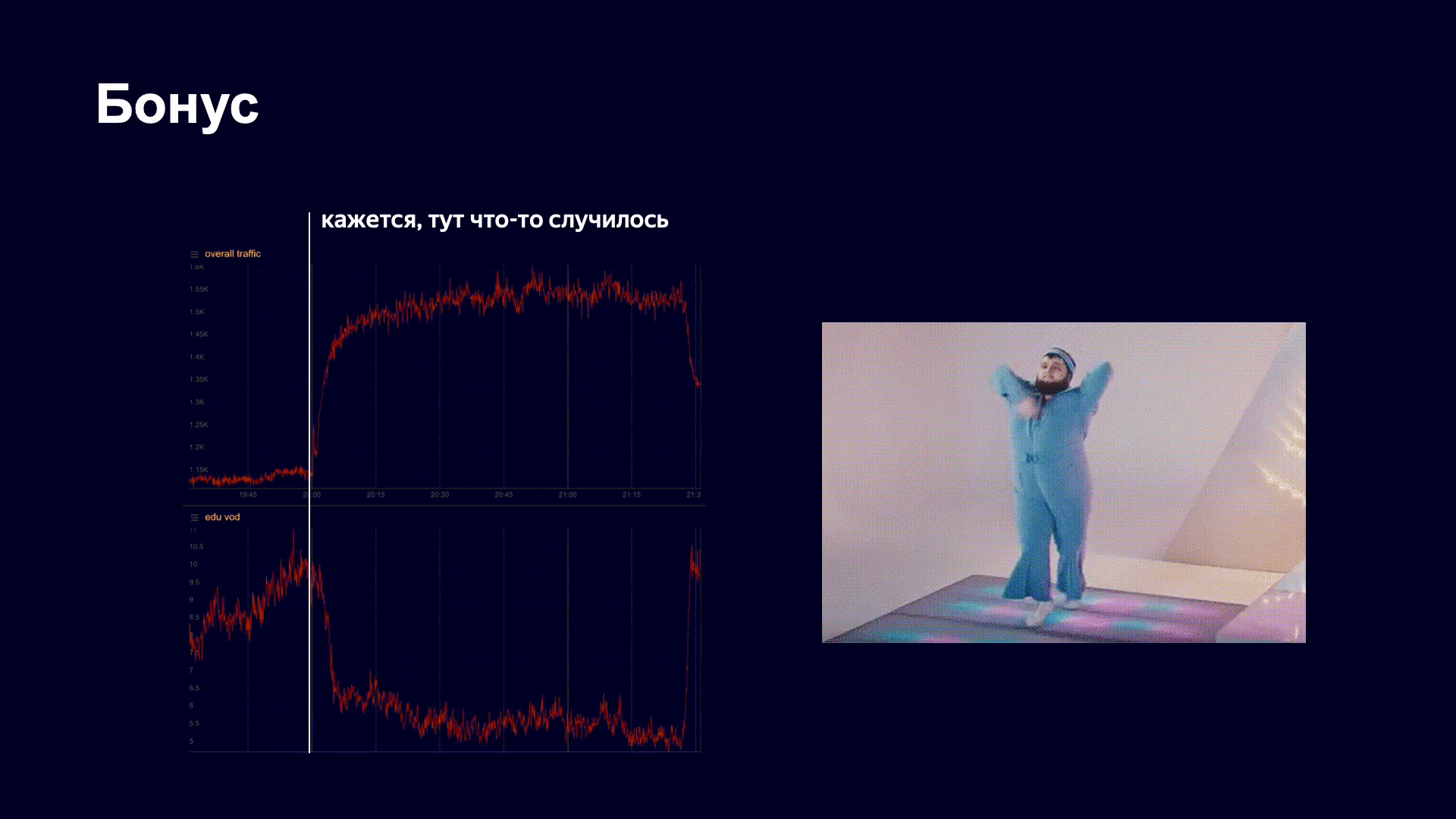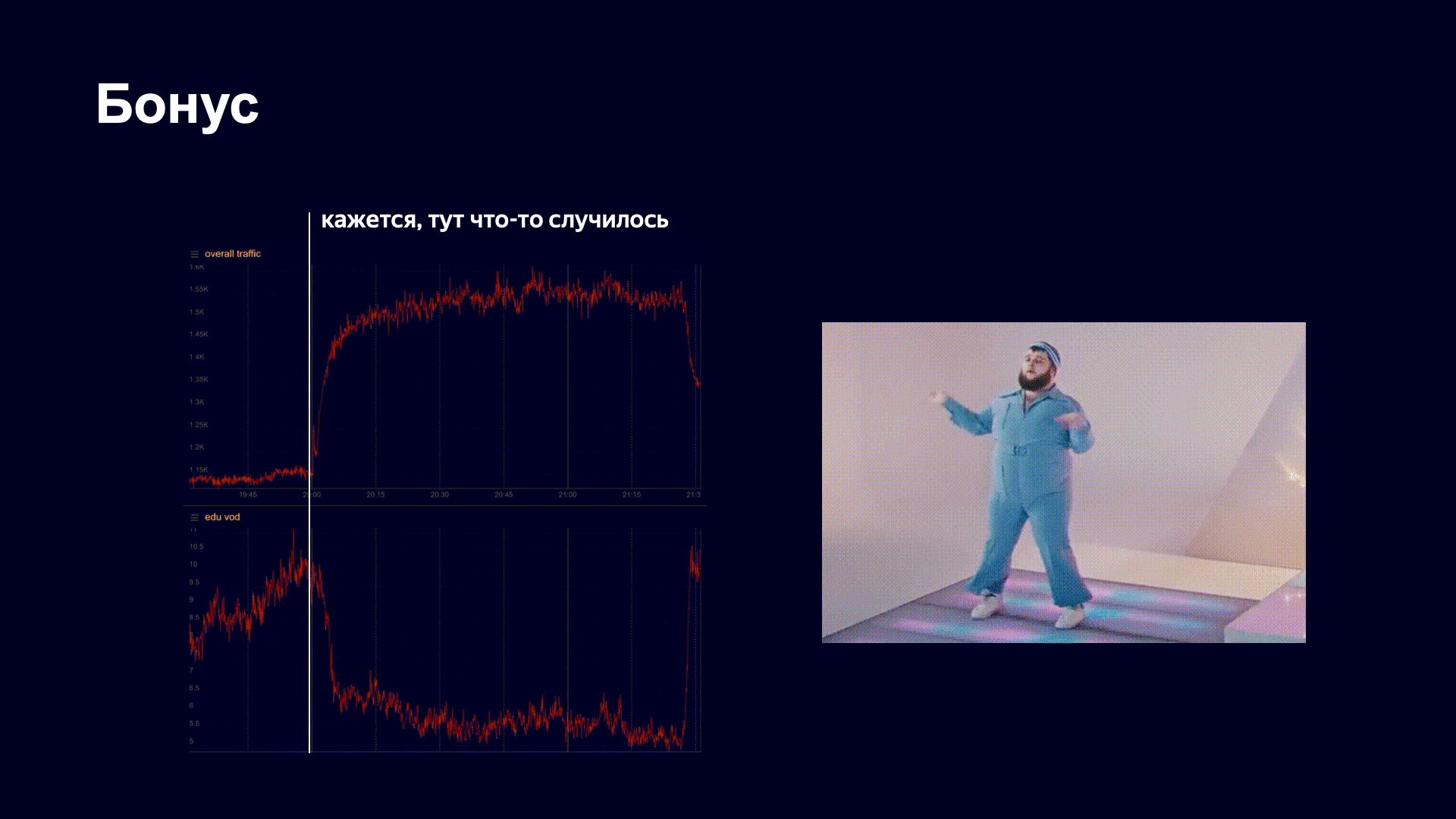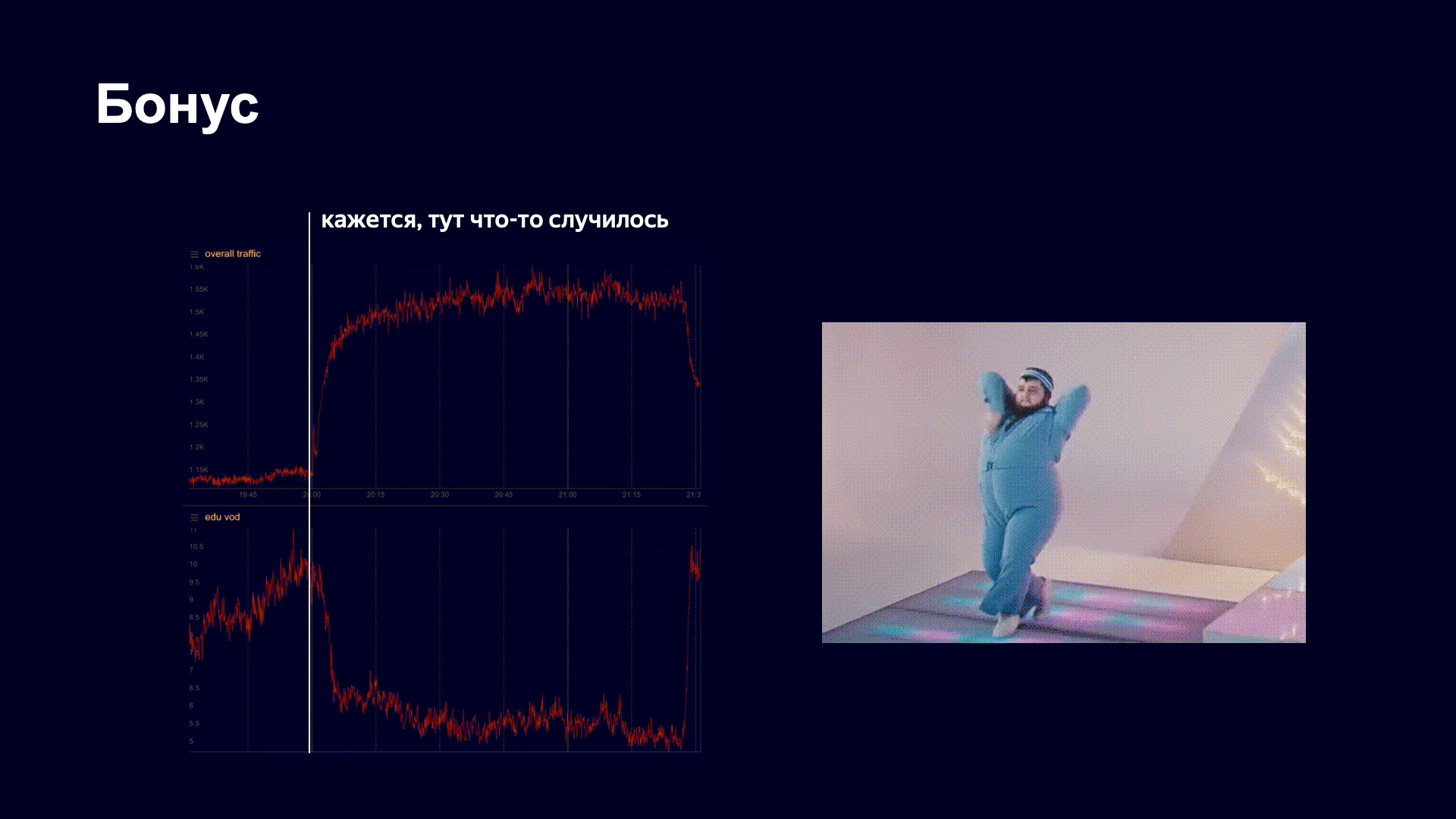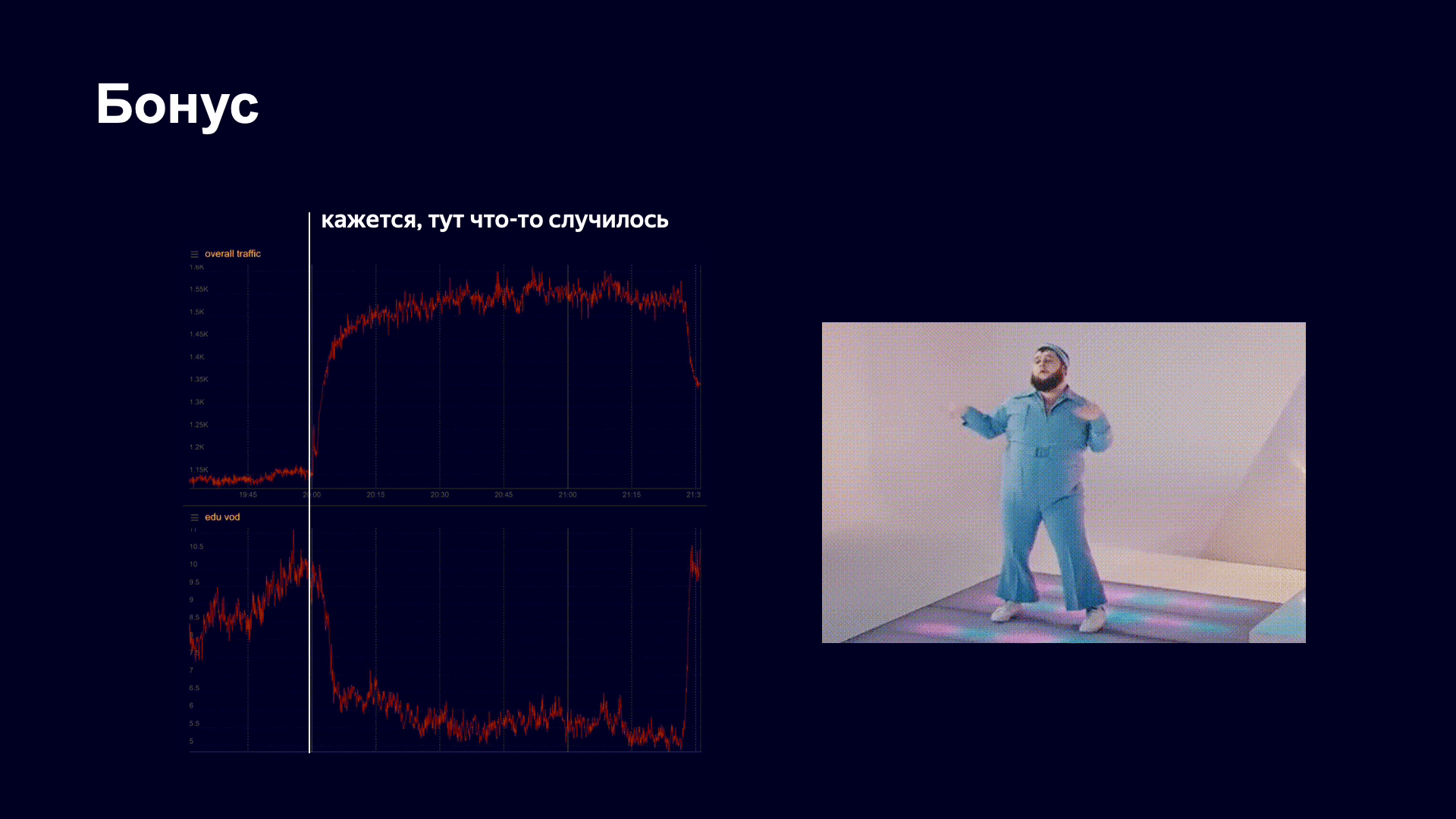
Вот как быстро танцует человечек.
Начался концерт Little Big, и все школьники ушли смотреть его. Но после окончания концерта они вернулись и с успехом продолжили обучаться дальше. Такие картинки мы довольно часто наблюдаем на нашем сервисе. Поэтому, думаю, работа у нас довольно интересная. Всем спасибо! На этом про CDN я, наверное, закончу.
— Всем привет! Расскажу, какие вопросы приходится решать, когда вам нужно подготовить ваш сервис к нагрузкам в несколько сотен гигабит, а то и терабит в секунду. Впервые мы с такой проблемой столкнулись в 2018 году, когда готовились к трансляциям чемпионата мира по футболу.
Начнем с того, что вообще такое стриминговые протоколы и как они устроены — самый поверхностный обзорный вариант.
В основе любого стримингового протокола лежит манифест [manifest] или плейлист [playlist]. Это небольшой текстовый файл, который содержит метаинформацию о контенте. Там описан тип контента — live-трансляция или VoD-трансляция (video on demand). Например, в случае live это футбольный матч или онлайн-конференция, как у нас сейчас с вами, а в случае VoD ваш контент заранее подготовлен и лежит на ваших серверах, готовый к раздаче в сторону пользователей. В этом же файле описана длительность контента, информация о DRM.
Там же описаны вариации контента — видеодорожки, аудиодорожки, субтитры. Видеодорожки могут быть представлены в разных кодеках. Например, универсальный H.264 поддерживается на любом устройстве. С его помощью вы сможете проиграть видео на любом утюге у вас дома. Или есть более современные и более эффективные кодеки HEVC и VP9, которые позволяют вам передавать картинку 4K с поддержкой HDR.
Аудиодорожки тоже могут быть представлены в разных кодеках с разными битрейтами. А еще их может быть несколько — оригинальная аудиодорожка фильма на английском языке, перевод на русский язык, интершум или, например, запись спортивного события напрямую со стадиона без комментаторов.
Что со всем этим делает плеер? Задача плеера — в первую очередь выбрать те вариации контента, которые он может проиграть, просто потому что не все кодеки универсальны, не все могут быть проиграны на определенном устройстве.
После этого ему нужно подобрать качество видео и аудио, с которого он будет начинать проигрывание. Сделать это он может на основе условий сети, если они ему известны, или на основе какой-нибудь очень простой эвристики. Например, начинать проигрывать с низкого качества и, если сеть позволяет, потихоньку увеличивать разрешение.
Также на этом этапе он выбирает аудиодорожку, с которой он будет начинать проигрывание. Предположим, у вас в операционной системе стоит английский язык. Тогда он может выбрать по умолчанию английскую аудиодорожку. Наверное, вам так будет удобнее.
После этого он начинает формировать ссылки на видео- и аудиосегменты. На самом деле это обычные HTTP-ссылки, такие же, как во всех остальных сценариях в интернете. И он начинает скачивать видео- и аудиосегменты, складывать их в буфер друг за другом и бесшовно проигрывать. Такие видеосегменты, как правило, имеют длительность 2, 4, 6 секунд, может быть, 10 секунд в зависимости от вашего сервиса.
Какие тут есть важные моменты, про которые нам нужно думать, когда мы проектируем наш CDN? В первую очередь, у нас появляется сессия пользователя.
Мы не можем просто отдать пользователю файл и забыть про этого пользователя. Он постоянно возвращается и докачивает новые и новые сегменты себе в буфер.
Тут важно понимать, что время ответа сервера тоже имеет значение. Если мы показываем какую-нибудь live-трансляцию в реальном времени, то не можем делать большой буфер просто потому, что пользователь хочет смотреть видео настолько близко к реальному времени, насколько возможно. Ваш буфер в принципе не может быть большим. Соответственно, если сервер не успевает отвечать за то время, пока пользователь успевает просматривать контент, видео в какой-то момент просто зависнет. К тому же контент довольно тяжеловесный. Стандартный битрейт для Full HD 1080p — 3-5 Мбит/с. Соответственно, на одном гигабитовом сервере вы не сможете обслужить больше 200 пользователей одновременно. И это идеальная картинка, потому что пользователи, как правило, равномерно по времени со своими запросами не ходят.
В какой момент пользователь вообще взаимодействует с вашим CDN? Взаимодействие происходит в основном в двух местах: когда плеер скачивает манифест (плейлист), и когда он скачивает сегменты.
Про манифесты мы уже поговорили, это небольшие текстовые файлы. С раздачей таких файлов нет особых проблем. Хотите — хоть с одного сервера их раздавайте. А если это сегменты, то они и составляют бо́льшую часть вашего трафика. Про них мы и будем говорить.
Задача всей нашей системы сводится к тому, что мы хотим сформировать правильную ссылку на эти сегменты и подставить туда правильный домен какого-нибудь нашего CDN-хоста. В этом месте мы пользуемся следующей стратегией: сразу в плейлисте отдаем нужный CDN-хост, куда пользователь пойдет. Этот подход лишен многих недостатков, но обладает одним важным нюансом. Вам нужно гарантировать, что у вас есть механизм, который позволит увести пользователя с одного хоста на другой бесшовно в процессе проигрывания, не прерывая просмотр. На самом деле такая возможность есть у всех современных стриминговых протоколов, и HLS, и DASH такое поддерживают. Нюанс: довольно часто даже в очень популярных опенсорс-библиотеках такая возможность не реализована, хоть и существует по стандарту. Нам самим приходилось посылать пачки в опенсорс-библиотеку Shaka, она джаваскриптовая, используется для веб-плеера, для проигрывания DASH.
Есть еще одна схема — anycast-схема, когда вы используете один единый домен и отдаете во всех ссылках именно его. В этом случае вам не нужно думать ни про какие нюансы, — отдаете один домен, и все счастливы. (...)
Теперь давайте поговорим про то, как мы будем формировать наши ссылки.
С точки зрения сети любая крупная компания устроена как автономная система, и часто даже не одна. На самом деле автономная система — это система IP-сетей и маршрутизаторов, которые управляются единым оператором и обеспечивают единую политику маршрутизации с внешней сетью, с интернетом. Яндекс тут не исключение. Сеть Яндекса — тоже автономная система, и связь с другими автономными системами происходит за пределами дата-центров Яндекса в точках присутствия. В эти точки присутствия приходят физические кабели Яндекса, физические кабели других операторов, и они коммутируются на месте, на железном оборудовании. Именно в таких точках у нас есть возможность поставить несколько своих серверов, жесткие диски, SSD. Именно туда мы и будем направлять трафик пользователей.
Этот набор серверов мы будем называть локацией. И в каждой такой локации у нас есть уникальный идентификатор. Мы его будем использовать в составе доменного имени хостов на этой площадке и просто чтобы однозначно ее идентифицировать.
Таких площадок в Яндексе несколько десятков, серверов на них несколько сотен, и в каждую локацию приходят линки от нескольких операторов, поэтому линков у нас тоже порядка нескольких сотен.
Как мы будем выбирать, на какую локацию отправить конкретного пользователя?
На этом этапе вариантов не очень много. Мы можем использовать только IP-адрес, чтобы принимать решения. С этим нам помогает отдельная команда Яндекса Traffic Team, которая знает все про то, как устроен трафик и сеть в компании, и именно она собирает маршруты других операторов, чтобы мы использовали эти знания в процессе балансировки пользователей.
Набор маршрутов она собирает с помощью BGP. Про BGP подробно говорить не будем, это протокол, который позволяет участникам сети на границах своих автономных систем анонсировать, какие же маршруты их автономная система может обслужить. Traffic Team собирает всю эту информацию, агрегирует, анализирует и строит полную карту всей сети, которой мы и пользуемся для балансировки.
Мы получаем от команды Traffic Team набор IP-сетей и линков, через которые мы можем обслуживать клиентов. Дальше нам нужно понять, какая же IP-подсеть подходит конкретному пользователю.
Делаем это довольно простым способом — строим префиксное дерево. А дальше наша задача — используя в качестве ключа IP-адрес пользователя, найти, какая подсеть наиболее точно соответствует этому IP-адресу.
Когда мы ее нашли, у нас есть список линков, их веса, и по линкам мы можем однозначно определить ту локацию, куда отправим пользователя.
Что такое вес в этом месте? Это метрика, которая позволяет управлять распределением пользователей по разным локациям. У нас могут быть линки, например, разной емкости. У нас может быть 100-гигабитный линк и 10-гигабитный линк на одной площадке. Очевидно, что в первый линк мы хотим отправлять больше пользователей, потому что он более емкий. Этот вес учитывает топологию сети, потому что интернет — сложный граф связанного между собой сетевого оборудования, трафик у вас может пойти по разным путям, и эту топологию тоже нужно учитывать.
Обязательно нужно смотреть, как происходит реальное скачивание данных пользователями. Это можно делать и на серверной, и на клиентской стороне. На сервере мы активно собираем в логах TCP info пользовательских соединений, смотрим на round-trip time. С пользовательской стороны мы активно собираем perf-логи браузера и плеера. В этих perf-логах есть подробная информация о том, как происходило скачивание файлов с нашего CDN.
Если все это проанализировать, проагрегировать, то с помощью этих данных мы можем улучшить веса, которые на первом этапе были выбраны командой Traffic Team.
Допустим, мы выбрали линк. Можем ли мы прямо на этом этапе отправлять туда пользователей? Не можем, потому что вес довольно статичен на протяжении долгого периода времени, и он не учитывает никакую реальную динамику нагрузки. Мы хотим в реальном времени определять, можем ли мы сейчас использовать линк, загруженный, скажем, на 80%, когда рядом есть чуть менее приоритетный линк, загруженный всего на 10%. Скорее всего, в этом случае мы как раз захотим использовать второй.
Что еще нужно принимать во внимание в этом месте? Мы должны учитывать пропускную способность линка, понимать его текущий статус. Он может работать или быть технически неисправным. Или, может быть, мы его хотим увести в сервис, чтобы не пускать туда пользователей и обслуживать его, расширить, например. Мы всегда должны учитывать текущую нагрузку этого линка.
Тут есть несколько интересных нюансов. Собирать информацию о загрузке линка можно в нескольких точках — скажем, на сетевом оборудовании. Это самый точный способ, но его проблема в том, что на сетевом оборудовании вы не можете получить быстрый период апдейта этой загрузки. Например, в Яндексе сетевое оборудование довольно разнообразное, и у нас не получается собирать эти данные чаще, чем раз в минуту. Если система по нагрузке довольно стабильна, это вообще не проблема. Все будет работать замечательно. Но как только у вас появляются резкие притоки нагрузки, вы просто не успеваете реагировать, и это приводит, например, к дропам пакетов.
С другой стороны, вы знаете, сколько байт отдали в сторону пользователя. Вы можете собирать эту информацию на самих раздающих машинках, сделать прямо счетчик байтов. Но это будет не настолько точно. Почему?
В нашем CDN есть и другие пользователи. Мы не единственный сервис, который пользуется этими раздающими машинками. И на фоне нашей нагрузки нагрузка других сервисов не такая значительная. Но даже на нашем фоне она бывает довольно-таки заметной. Их раздачи проходят не через наш контур, поэтому мы не можем управлять этим трафиком.
Другой момент: даже если вы считаете на раздающей машине, что вы отправили трафик в какой-то один конкретный линк, — это далеко не факт, потому что BGP как протокол не дает вам такой гарантии. И тут есть способы, как можно увеличить вероятность того, что вы угадаете, но это предмет отдельного разговора.
Допустим, мы посчитали метрики, всё собрали. Теперь нужен алгоритм принятия решения при балансировке. Он должен обладать четырьмя важными свойствами:
— Обеспечивать пропускную способность линка.
— Предупреждать перегрузку линка, просто потому что если вы загрузили линк на 95% или 98%, то у вас начинают переполняться буферы на сетевом оборудовании, начинаются дропы пакетов, ретрансмиты, и пользователи ничего хорошего от этого не получают.
— Предупреждать «пил» нагрузки, про это поговорим чуть позже.
— В идеальном мире было бы здорово, чтобы мы научились утилизировать линк до определенного уровня, который мы считаем правильным. Например, 85% загрузки.
Мы взяли за основу следующую мысль. У нас есть два разных класса сессий пользователей. Первый класс — это новые сессии, когда пользователь только открыл фильм, еще ничего не смотрел и мы пытаемся понять, куда же его отправить. Или же второй класс, когда у нас есть текущая сессия, пользователь уже обслуживается на линке, занимает определенную часть полосы, обслуживается на конкретном сервере.
Что мы с ними будем делать? Введем по одной вероятностной величине на каждый такой класс сессии. У нас будет величина под названием Slowdown, определяющая процент новых сессий, которые мы не будем пускать на этот линк. Если Slowdown равен нулю, то мы все новые сессии принимаем, а если он равен 50%, то каждую, грубо говоря, вторую сессию мы отказываемся обслуживать на этом линке. При этом наш алгоритм балансировки на более высоком уровне будет проверять альтернативные варианты для этого пользователя. Drop — то же самое, только для текущих сессий. Мы можем часть пользовательских сессий увести с площадки куда-нибудь в другое место.
Как мы будем выбирать, каким будет значение наших вероятностных метрик? В качестве основы возьмем процент загрузки линка, а дальше первая наша идея была такой: давайте воспользуемся кусочно-линейной интерполяцией.
Мы взяли такую функцию, которая имеет несколько точек преломления, и по ней смотрим значение наших коэффициентов. Если уровень загрузки линка минимальный, то все хорошо, Slowdown и Drop равны нулю, мы пускаем всех новых пользователей. Как только уровень загрузки переходит через некоторый порог, мы начинаем части пользователей отказывать в обслуживании на этом линке. В какой-то момент, если нагрузка продолжает расти, мы просто перестаем пускать новые сессии.
Тут есть интересный нюанс: текущие сессии в этой схеме имеют приоритет. Думаю, понятно, почему так происходит: если ваш пользователь уже обеспечивает вам стабильный паттерн нагрузки, вы не хотите его никуда уводить, потому что таким образом увеличиваете динамику системы, а чем стабильнее система, тем нам проще ее контролировать.
Тем не менее, загрузка может продолжать расти. В какой-то момент мы можем начать уводить часть сессий или даже полностью снять нагрузку с этого линка.
Именно в таком виде мы и запустили этот алгоритм на первых матчах чемпионата мира по футболу. Наверное, интересно посмотреть, какую картинку мы увидели. Она была примерно следующей.
Даже невооруженным глазом сторонний наблюдатель может понять, что тут что-то, наверное, не так, и спросить меня: «Андрей, все ли у вас хорошо?». А если бы вы были моим начальником, вы бы бегали по комнате и кричали: «Андрей, боже мой! Откатывайте все назад! Верните все как было!» Давайте расскажу, что тут происходит.
По оси X время, по оси Y мы наблюдаем за уровнем нагрузки линков. Тут изображены два линка, которые обслуживают одну и ту же площадку. Важно понимать, что в этот момент мы пользовались только той схемой наблюдения за загрузкой линка, которая снимается с сетевого оборудования, и поэтому не могли быстро реагировать на динамику нагрузки.
Когда мы отправляем пользователей в какой-то из линков, происходит резкий рост трафика на этом линке. Линк перегружается. Мы снимаем нагрузку и оказываемся в правой части функции, которую видели на предыдущем графике. И мы начинаем сбрасывать старых пользователей и перестаем пускать новых. Им нужно куда-то идти, а идут они, конечно же, на соседний линк. В прошлый раз он, возможно, был менее приоритетным, а теперь он у них в приоритете.
На втором линке повторяется та же картинка. Мы резко повышаем нагрузку, замечаем, что линк перегружен, снимаем нагрузку, и эти два линка оказываются в противофазе по уровню нагрузки.
Что можно сделать? Мы можем проанализировать динамику системы, при большом росте нагрузки замечать это и немного ее демпфировать. Именно это мы и сделали. Мы взяли текущий момент, взяли окно наблюдений в прошлое за несколько минут, например 2-3 минуты, и посмотрели, насколько сильно меняется загрузка линка на этом интервале. Разницу между минимальным и максимальным значением мы будем называть интервалом колебаний этого линка. И если этот интервал колебаний большой, мы добавим демпфирование, таким образом увеличим наш Slowdown и станем пускать меньше сессий.
Выглядит эта функция примерно так же, как и прошлая, с чуть меньшим числом переломов. Если у нас интервал загрузки колебаний небольшой, то никакого extra_slowdown мы добавлять не будем. А если интервал колебаний начинает расти, то extra_slowdown принимает ненулевые значения, позже мы будем прибавлять его к основному Slowdown.
Такая же логика работает и при низких значениях интервала колебаний. Если у вас колебания на линке минимальные, то вы, возможно, наоборот, хотите пустить туда немножко больше пользователей, снизить Slowdown и тем самым лучше утилизировать ваш линк.
Эту часть мы тоже внедрили. Итоговая формула имеет примерно следующий вид. При этом мы гарантируем, что обе эти величины — extra_slowdown и reduce_slowdown — никогда не имеют ненулевого значения одновременно, поэтому эффективно работает только одна из них. Именно в таком виде эта формула балансировки пережила все топовые матчи чемпионата мира по футболу. Даже на самых популярных матчах она работала довольно хорошо: это «Россия — Хорватия», «Россия — Испания». Во время этих матчей мы раздавали рекордные для Яндекса объемы трафика — 1,5 терабита в секунду. Мы спокойно это пережили. С тех пор формула никак не менялась, потому что такого трафика на нашем сервисе с тех пор не было — до определенного момента.
Потом к нам пришла пандемия. Людей отправили сидеть домой, а дома есть хороший интернет, телевизор, планшет и много свободного времени. Трафик на наши сервисы стал органично расти, довольно быстро и значимо. Сейчас такого рода нагрузки, как были во время чемпионата мира по футболу, — наша ежедневная рутина. Мы с тех пор немного расширили наши каналы с операторами, но, тем не менее, начали задумываться о следующей итерации нашего алгоритма, о том, какой она должна быть и как нам лучше утилизировать нашу сеть.
Какие есть недостатки у нашего предыдущего алгоритма? Мы не решили две проблемы. Мы не избавились полностью от «пил» нагрузок. Мы очень сильно улучшили картинку и амплитуда этих колебаний минимальна, период сильно увеличился, что тоже позволяет лучше утилизировать сеть. Но все равно они временами появляются, остаются. Мы не научились утилизировать сеть до того уровня, до какого хотели бы. Например, у нас нет возможности с помощью конфигурации задать желаемый максимальный уровень нагрузки линка в 80-85%.
Какие у нас есть мысли о следующей итерации алгоритма? Как мы представляем себе идеальную утилизацию сети? Одним из перспективных направлений, казалось бы, является вариант, когда у вас есть единое место принятия решений о трафике. Вы в одном месте собираете все метрики, туда же приходит пользовательский запрос о скачивании сегментов, и в каждый момент времени у вас есть полное состояние системы, вам очень легко принимать решения.
Но тут есть два нюанса. Первый — в Яндексе не принято писать «единые места принятия решений», просто потому что при наших уровнях нагрузки, при нашем трафике, такое место быстро становится узким местом.
Есть еще один нюанс — в Яндексе важно писать еще и отказоустойчивые системы. Мы часто полностью отключаем дата-центры, при этом ваш компонент должен продолжать работать без ошибок, без прерываний. И в таком виде это единое место становится, на самом деле, распределенной системой, которую вам нужно контролировать, а это чуть более сложная задача, чем та, которую мы бы хотели решать в этом месте.
Нам обязательно нужны быстрые метрики. Без них единственное, что вы можете сделать, избежав страданий пользователя, — недоутилизировать сеть. Но это нас тоже не устраивает.
Если посмотреть на нашу систему высокоуровнево, станет понятно, что наша система — динамическая система с обратной связью. У нас есть пользовательская нагрузка, которая является входящим сигналом. Люди приходят и уходят. У нас есть контрольный сигнал — те самые две величины, которые мы можем менять в реальном времени. Для таких динамических систем с обратной связью уже давно, несколько десятилетий, разрабатывается теория автоматического управления. И именно ее компоненты мы бы хотели применить для того, чтобы стабилизировать нашу систему.
Мы посмотрели на фильтр Калмана. Это такая крутая штука, которая позволяет построить математическую модель системы и при зашумленных метриках или при отсутствии некоторых классов метрик улучшить модель с помощью вашей реальной системы. И потом принимать решение о реальной системе, основываясь на математической модели. К сожалению, оказалось, что у нас не так много классов метрик, которые мы можем использовать, и не получается этот алгоритм применить.
Мы подошли с другой стороны, взяли за основу другой компонент этой теории — PID-регулятор. Он ничего не знает про вашу систему. Его задача — знать идеальное состояние системы, то есть наш желаемый уровень загрузки, и текущее состояние системы, например уровень нагрузки. Разницу между двумя этими состояниями он считает ошибкой и с помощью своих внутренних алгоритмов управляет контрольным сигналом, то есть нашими значениями Slowdown и Drop. Его цель — минимизировать ошибку, которая есть в системе.
Со дня на день мы попробуем этот PID-регулятор в продакшене. Возможно, через несколько месяцев сможем рассказать вам о результатах.
На этом мы, наверное, закончим про сеть. Очень хотелось бы рассказать вам и про то, как мы распределяем трафик внутри самой локации, когда уже выбрали ее между хостами. Но на это времени не остается. Это, наверное, тема для отдельного большого доклада.
Поэтому в следующих сериях вы узнаете, как оптимально утилизировать кеш на хостах, что делать с горячим и холодным трафиком, а также откуда берется тепленький, как тип контента влияет на алгоритм его распределения и какой ролик дает самый высокий кеш-хит на сервисе, и кто же, кто же, кто же песенку поет.
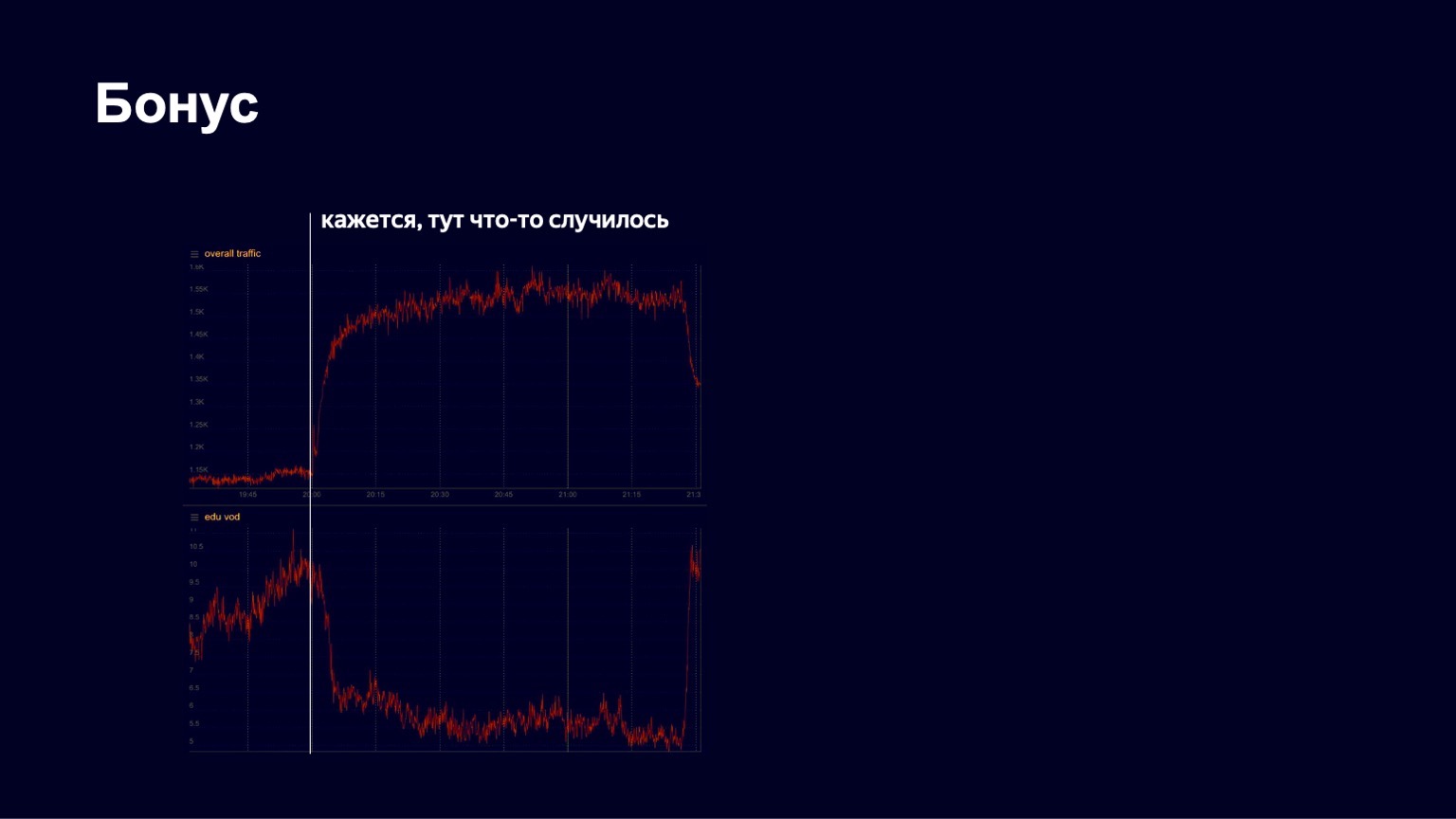
У меня есть еще одна интересная история. Весной, как вы знаете, начался карантин. У Яндекса давно есть образовательная платформа Яндекс.Учебник, которая позволяет учителям загружать ролики, уроки. Школьники туда приходят и смотрят контент. Во время пандемии Яндекс начал поддерживать школы, активно звать их на свою платформу, чтобы школьники могли обучаться удаленно. И мы в какой-то момент увидели довольно хороший рост трафика, довольно стабильную картинку. Но в один из апрельских вечеров мы увидели на графиках примерно следующее.
Снизу — картинка трафика на образовательном контенте. Мы увидели, что он в какой-то момент резко упал. Начали паниковать, выяснять, что вообще происходит, что у нас сломалось. Потом мы заметили, что общий трафик на сервис при этом начал расти. Очевидно, случилось что-то интересное.
На самом деле в этот момент произошло следующее.
Вот как быстро танцует человечек.
Начался концерт Little Big, и все школьники ушли смотреть его. Но после окончания концерта они вернулись и с успехом продолжили обучаться дальше. Такие картинки мы довольно часто наблюдаем на нашем сервисе. Поэтому, думаю, работа у нас довольно интересная. Всем спасибо! На этом про CDN я, наверное, закончу.


