
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Когда мы добавляем зависимость в проект, мы подписываем контракт. Зачастую, многие условия в нем «написаны мелким шрифтом». В этой статье мы рассмотрим кое-что, что легко пропустить при подписании трехстороннего контракта между вами, Hibernate и Spring Boot. Речь пойдет о стратегиях именования.
Значения по умолчанию в JPA
Главное правило для значений по умолчанию: они должны быть интуитивно понятными. Давайте проверим, следует ли этому правилу обычное приложение на Spring Boot с конфигурацией по умолчанию, Hibernate в качестве реализации JPA и PostgreSQL в качестве БД. Допустим, у нас есть сущность «PetType». Давайте угадаем, как будет называться ее таблица в базе данных.
Первый пример:
@Entity
public class PetType {
// fields omitted
}Я бы предположил, что именем таблицы станет имя класса, то есть PetType. Однако, после запуска приложения оказалось, что имя таблицы на самом деле pet_type.
Явно зададим имя с помощью @Table:
@Entity
@Table(name = "PetType")
public class PetType {
// fields omitted
}В этот раз имя точно должно быть PetType. Запустим приложение… Таблица снова называется pet_type!
Тогда попробуем заключить название таблицы в кавычки. Таким образом, должно сохраниться не только имя, но и регистр:
@Entity
@Table(name = "\"PetType\"")
public class PetType {
// fields omitted
}И опять наши ожидания не оправдались, имя снова "pet_type", но теперь в кавычках!
Стратегии именования Hibernate
На запрос «имя таблицы по умолчанию для JPA-сущностей» Google выдает следующий результат (англ.):
По умолчанию, имя таблицы в JPA — это имя класса (без пакета) с заглавной буквы. Каждый атрибут класса хранится в столбце таблицы.
Именно это мы ожидали увидеть в первом примере, не так ли? Очевидно, что-то нарушает стандарт.
Углубимся в Hibernate. Согласно документации (англ.), в Hibernate есть два интерфейса, отвечающих за именование таблиц, столбцов и пр.: ImplicitNamingStrategy и PhysicalNamingStrategy.
ImplicitNamingStrategy отвечает за генерацию имен для всех объектов, которые не были явно названы разработчиком: имя сущности, имя таблицы, имя столбца, индекса, внешнего ключа и т.д.. Получившееся имя называется логическим, оно используется внутри Hibernate для идентификации объекта. Это не то имя, которое будет использовано в базе данных.
PhysicalNamingStrategy создает подлинное физическое имя на основе логического имени объекта JPA. Именно физическое имя используется в базе данных. Фактически, это означает, что с помощью Hibernate нельзя напрямую указать физическое имя объекта в БД, можно указать только логическое. Чтобы лучше понять, как это все работает, посмотрите на схему ниже.
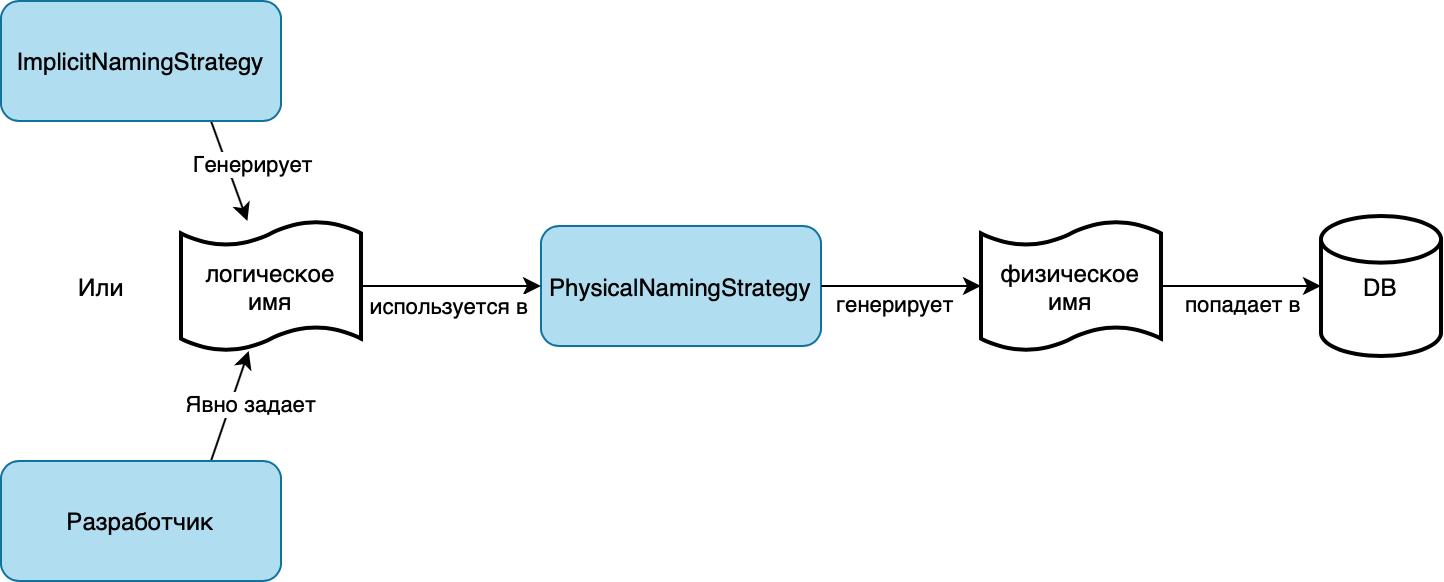
По умолчанию, в Hibernate используются следующие реализации этих интерфейсов: ImplicitNamingStrategyJpaCompliantImpl и PhysicalNamingStrategyStandardImpl. Первый генерирует логические имена в соответствии со спецификацией JPA, а второй использует их как физические имена без каких-либо изменений. Лучше всего это описано в документации:
JPA определяет четкие правила автоматического именования. Если вам важна независимость от конкретной реализации JPA, или если вы хотите придерживаться определенных в JPA правил именования, используйте ImplicitNamingStrategyJpaCompliantImpl (стратегия по умолчанию). Кроме того, в JPA нет разделения между логическим и физическим именем. Согласно спецификации JPA, логическое имя — это и есть физическое имя. Если вам важна независимость от реализации JPA, не переопределяйте PhysicalNamingStrategy.
Однако наше приложение ведет себя по-другому. И вот почему. Spring Boot переопределяет реализации Hibernate по умолчанию для обоих интерфейсов и вместо них использует SpringImplicitNamingStrategy и SpringPhysicalNamingStrategy.
SpringImplicitNamingStrategy фактически копирует поведение ImplicitNamingStrategyJpaCompliantImpl, есть только незначительное различие в именовании join таблиц. Значит, дело в SpringPhysicalNamingStrategy. В документации (англ.) указано следующее:
По умолчанию, в Spring Boot используется SpringPhysicalNamingStrategy в качестве физической стратегии именования. Эта реализация использует те же правила именования, что и Hibernate 4:
1. Все точки заменяются символами подчеркивания.
2. Заглавные буквы CamelCase приводятся к нижнему регистру, и между ними добавляются символы подчеркивания. Кроме того, все имена таблиц генерируются в нижнем регистре. Например, сущности TelephoneNumber соответствует таблица с именем telephone_number.
По сути, Spring Boot всегда преобразовывает camelCase и PascalCase в snake_case. Более того, использование чего-либо помимо snake_case вообще невозможно. Я бы не стал использовать camelCase или PascalCase для именования объектов базы данных, но иногда у нас нет выбора. Если ваше приложение на Spring Boot работает со сторонней базой данных, где используется PascalCase или camelCase, конфигурация Spring Boot по умолчанию для вас не подойдет. Обязательно убедитесь, что используемая PhysicalNamingStrategy совместима с именами в базе данных.
Получается, Hibernate соответствует спецификации JPA, а Spring Boot — нет. Можно подумать, что это ошибка. Однако Spring Boot — фреймворк, в котором множество решений уже принято за разработчика, в этом и есть его ценность. Другими словами, он имеет полное право по-своему реализовывать стандарты и спецификации тех технологий, которые он использует. Для разработчика это означает следующее:
Конечное поведение всегда определяется конкретной реализацией и может отличаться от спецификации.
Если что-то и работает «из коробки», всегда нужно разбираться, что именно оно делает под капотом.
Поведение по умолчанию может измениться с обновлением версии библиотеки, что может привести к непредсказуемым побочным эффектам;
Заключение
Магия конфигураций «из коробки» — это отлично, но может привести к неожиданному поведению. Один из способов избежать подобных проблем — явно задавать все значения и не полагаться на автогенерацию. Для именования объектов JPA рекомендации следующие:
Всегда называйте свои объекты JPA явно, чтобы никакая автоматическая стратегия именования не повлияла на ваш код.
Используйте snake_case для имен столбцов, таблиц, индексов и других объектов JPA, чтобы все реализации PhysicalNamingStrategy никак их не преобразовывали.
Если нельзя использовать snake_case (например, при использовании сторонней базы данных), используйте PhysicalNamingStrategyStandardImpl в качестве PhysicalNamingStrategy.
Еще один плюс явного именования объектов JPA — вы никогда случайно не переименуете таблицу или атрибут в самой базе при рефакторинге Java-модели. Для этого придется менять имя в @Table или @Column.
Однако, введя эти правила мы просто переложили ответственность на разработчиков. Теперь нам надо следить, чтобы вся команда им следовала. К счастью, этот процесс можно автоматизировать с помощью инструментов разработки.
Если вы пользуетесь IntelliJ IDEA, попробуйте JPA Buddy — плагин, который упрощает работу с JPA, Hibernate, Spring Data JPA, Liquibase и подобными технологиями. В настройках JPA Buddy есть специальная секция, в которой можно установить шаблоны для имен сущностей, атрибутов и пр.. Эти шаблоны применяются каждый раз, когда разработчики создают сущность или атрибут:
По задумке, настройки JPA Buddy хранятся в Git, таким образом все разработчики используют одни и те же шаблоны и следуют одним и тем же правилам.




