
Следующая конференция HighLoad++ пройдет 6 и 7 апреля 2020 года в Санкт-Петербурге. Подробности и билеты по ссылке. HighLoad++ Moscow 2018. Зал «Дели + Калькутта». 8 ноября, 14:00. Тезисы и презентация.

Я работаю в команде «ВКонтакте» и занимаюсь разработкой системы видеотрансляций.
В докладе поделюсь особенностями разработки бэкенда, тем, как эволюционировала наша система, и техническими решениями, к которым мы пришли:
Михаил Райченко (далее – МР): – Немного экскурса. Я расскажу вам про людей, которые стримят нам, про сами лайвы (live), о том, с каких платформ мы принимаем видеопоток и на какие раздаём. В конце расскажу текущую архитектуру лайвов, про её ограничения и возможности, а также о том, как текущая архитектура пережила такой эффект, как «Клевер».

Все сервисы трансляций выглядят примерно так:
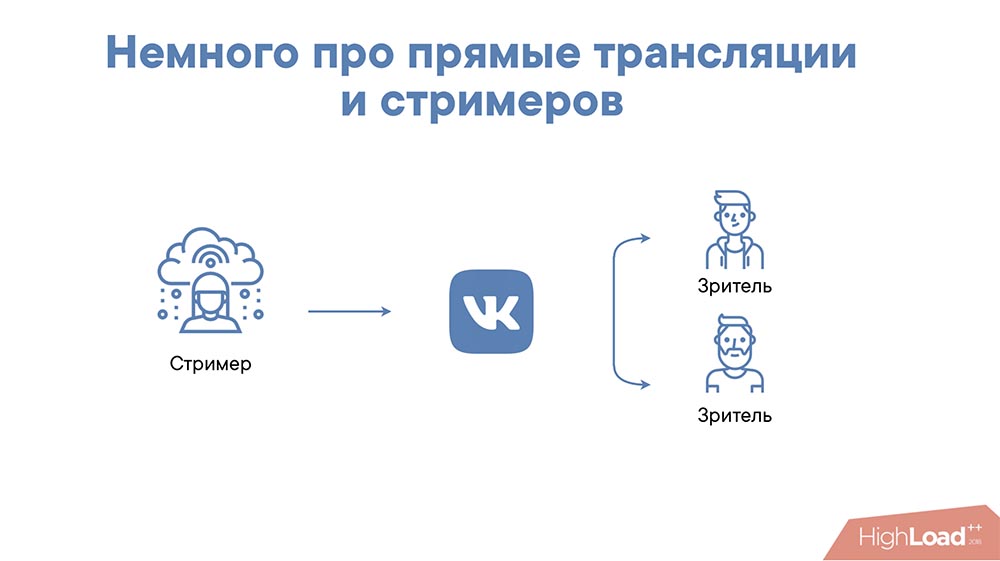
У нас есть некоторый стример, он присылает поток RTMP нам, и мы показываем зрителям – ничего удивительного, ничего сверхъестественного.

Откуда приходит видеопоток? Значительным источником трафика для нас является наше мобильное приложение VKlife. Что в нём хорошо? В нём мы можем полностью контролировать то, как мы кодируем видео. Можем произвести много оптимизаций на стороне клиента, чтобы потом с минимальными задержками показывать его нашим зрителям.
Из минусов: мобильные приложения работают поверх сетей. Это может быть 3G… В любом случае это почти всегда мобильные сети, что вносит некоторые лаги – необходимо дополнительное буферизировать данные на стороне приложения, чтобы поток шёл как можно более ровно.
Вторым источником являются стримеры с OBS, Wirecast или те, кто стримит с других десктопных приложений. Это достаточно большая аудитория. Иногда это семинары, иногда – игровые стримы (их особенно много с таких приложений). Из положительного: таких приложений немного, мы можем давать нашим стримерам хорошие рекомендации по настройке. Но при этом там много настроек и шлют не совсем тот поток, который мы хотим.
Третья категория – это RTMP-поток от медиасерверов. Это могут быть совсем маленькие медиасерверы, то есть домашнего формата: человек стримит вид на улицу или что-то ещё. Либо достаточно серьёзные трансляции от наших партнёров: там может быть всё что угодно, таких стримов не очень много, но в основном они весьма важны для нас.
Опять же, это мобильное приложение – тут всё понятно. Самая большая проблема – сетевые задержки. Из плюсов: мы можем кастомизировать плеер – нам это удобно, хорошо, но не везде это получается на 100%.
Веб-плеер на vk.com. Тут тоже всё просто – это обычный веб-плеер, который можете открыть посмотреть. Достаточно большая аудитория у vk.com, много зрителей на трансляциях. Некоторые трансляции висят у нас в разделе «Видео» – там могут быть десятки тысяч (иногда без всякого пиара), особенно если это интересный контент.
Соответственно, каналы достаточно большие у зрителей, которые сидят на веб-плеере. Поэтому трафика достаточно много, в том числе на одну трансляцию.
Третье – это веб-плеер «ВКонтакте» на каком-нибудь стороннем сайте. Вы можете начать стримить всё, что хотите, и у себя на сайте повесить веб-плеер «ВКонтакте». Вы можете выступить нашим партнёром, если у вас интересный контент: можете повесить у себя, можете повесить у нас – как хотите. Можете организовать свои трансляции таким образом, и всё будет работать.
В видеозвонках нам простят некоторое искажение изображения. В видеозвонках проще: мы можем существенно ухудшить изображение, но при этом мы обязаны выдерживать очень хороший latency. При большой задержке сервис будет абсолютно невозможно использовать.
В трансляциях в этом смысле немного наоборот: мы должны поддерживать высокое качество изображения, но при этом можем увеличить latency в силу множества факторов. Например, плеер так или иначе буферизирует у себя поток (это может быть секунда, две, чтобы пережить деградацию сети, например), поэтому там не нужны секундные, миллисекундные задержки в большинстве случаев. Можно к этому стремиться, но продуктово это не является обязательным условием.
С обычным видео ситуация ровно обратная. Нам нужно очень хорошее качество. При этом желательно минимизировать размер видео, соотношение битрейта и качества, чтобы с минимальным потоком отдавать наилучшее решение. Из плюсов: мы не ограничены по времени: в момент загрузки видео у нас достаточно времени для того, чтобы оптимизировать видео, посмотреть, как его сжать наилучшим образом, что-то сделать, утащить его на кэши, если надо – в общем, всё достаточно хорошо.

В лайвах ситуация, опять же, обратная: у нас очень мало времени на транскодирование. При этом возможностей по времени мало, но нет никаких ожиданий по трансляции. Зрители нам простят, если у нас будет поддержка или качество будет не очень.
Она вполне ожидаемая:
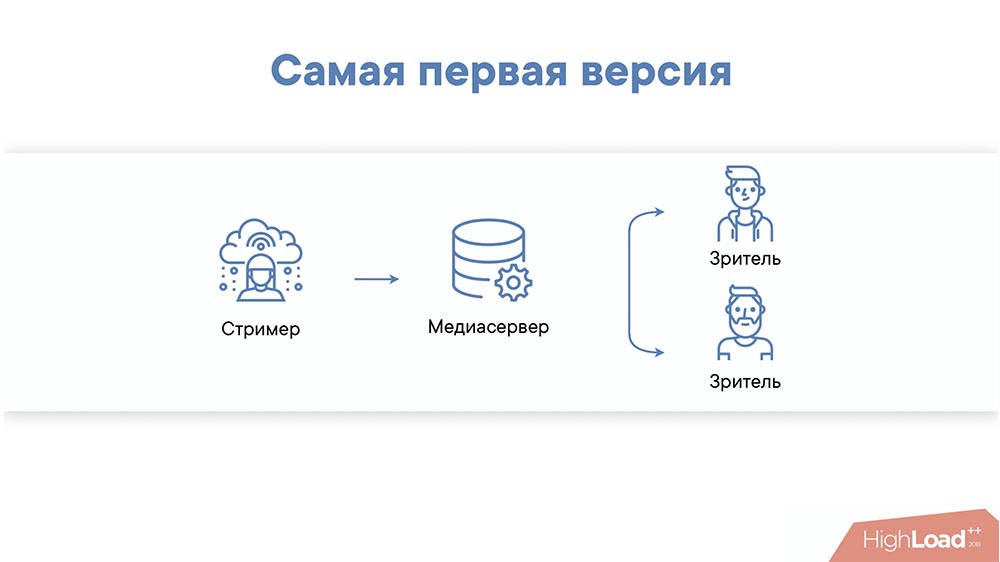
На самом деле она немного другая:

«Стример – медиасервер – уровень кэширования – зрители». В принципе эта версия позволяет масштабироваться достаточно сильно. Я бы сказал, что десятки тысяч зрителей она уже должна выдерживать. У неё есть другие недостатки…
Например, если посмотреть на эту схему (предыдущий слайд), видно, что она не отказоустойчивая. Мы должны угадывать с медиасервером, чтобы хорошо балансировать зрителей. Мы не можем на каждый сервер повесить много кэшей – это просто дорого. Поэтому мы посмотрели, поняли, что это просто и понятно, есть некоторые возможности для масштабирования, но явно чего-то не хватает… И начали формулировать требования.
Что важно?

В итоге мы пришли к достаточно простой, но эффективной инфраструктуре…
Что интересно? Балансировка! В этой схеме мы выбираем балансировку, стараемся на каждый edge-сервер прислать зрителей, которые смотрят один и тот же поток. Здесь очень важна локальность кэша, потому что edge-серверов может быть много; и если мы не будем соблюдать и временную, и локальность кэша с точки зрения стрима, то мы перегрузим внутренний слой. Этого нам тоже не хотелось бы.
Поэтому балансируем мы следующим образом: выбираем некий сервер edge для региона, на который мы отсылаем зрителей, и отсылаем до тех пор, пока не начинаем понимать, что произошло некоторое заполнение и стоит отсылать на другой сервер. Схема простая и работает очень надёжно. Естественно, для разных стримов вы выбираем разную последовательность edge-серверов (последовательность, в которой мы рассылаем зрителей). Соответственно, балансировка работает достаточно просто.
Также мы отдаём клиенту ссылку на доступный edge-сервер. Это сделано для того, чтобы в случае отказа edge-сервера мы могли перенаправить зрителя на другой. То есть, когда зритель смотрит трансляцию, ему раз в несколько секунд приходит ссылка на нужный сервер. Если он понимает, что ссылка должна быть другой, он переключается (переключается плееер) и продолжает смотреть трансляцию уже с другого сервера.
Ещё одна важная роль edge-серверов – это защита контента. Вся защита контента по сути происходит там. У нас свой модуль nginx для этого допилен. Он чем-то похож на Security Link.

Одним из основных протоколов у нас был RTMP (не только на вход, но и на раздачу контента). Основное преимущество – низкая задержка. Это может быть полсекунды, секунда, две секунды. На самом деле преимущества на этом заканчиваются…

Этот потоковый протокол сложно мониторить – он закрытый в некотором смысле, несмотря на то, что есть спецификация. Flash-плеер уже не работает (по сути он «уже всё»). Нужна поддержка на уровне CDN – необходимы специальные модули nginx или свой софт, чтобы нормально передать поток. Есть также некоторые сложности в мобильных клиентах. «Из коробки» в мобильных клиентах поддерживается очень плохо – нужны специальные доработки, и всё это очень сложно.
Второй протокол, который мы использовали – это HLS. Выглядит он достаточно просто: это текстовый файл, так называемый index file. В нём содержатся ссылки на индексные файлы с различными разрешениями, а в самих файлах – ссылки на медиасегменты.

Чем он хорош? Он очень простой, несмотря на то, что староват. Он позволяет использовать CDN, то есть вам нужен всего лишь nginx, чтобы раздать HLS-протокол. Он понятен с точки зрения мониторинга.
Вот его плюсы:
Существенный минус:

Задержка в HLS фактически вложена в сам протокол; так как необходимо продолжительное время буферизации, плеер вынужден ждать как минимум когда загрузится один чанк, а по-хорошему он должен ждать пока загрузятся два чанка (два медиасегмента), иначе в случае лага у клиента появится прогруз плеера, а это не очень хорошо влияет на user experience.
Второй момент, который даёт задержку в HLS – это кэширование. Плейлист кэшируется на внутреннем слое и на edge-серверах. Даже если мы кэшируем, условно говоря, на секунду-полсекунды, то это – примерно плюс 2-3 секунды задержки. Суммарно получается от 12 до 18 секунд – это не очень приятно, явно можно лучше.
С этими мыслями мы начали улучшать HLS. Улучшали мы его достаточно простым путём: давайте отдавать последний, даже ещё не записанный медиасегмент плейлиста немного раньше. Т. е. как только мы начали писать последний медиасегмент, мы сразу анонсируем его в плейлисте. Что в этот момент происходит?..
Уменьшается время буферизации в плеерах. Плеер считает, что он уже всё загрузил, и спокойно начинает качать нужные сегменты. Мы немного «обманываем» таким образом плеер, но если мы хорошо мониторим «сталы» (прогрузы в плеере), нас это не пугает – мы можем перестать отдавать сегмент заранее, и всё вернётся к норме.
Второй момент: выигрываем суммарно примерно 5-8 секунд. Откуда они берутся? Это время сегмента – от 2 до 4 секунд на один сегмент, плюс время на кэширование плейлиста (это еще 2-3 секунды). Задержка у нас уменьшается, притом существенно. Задержка уменьшается с 12-15 секунд до 5-7.
Что ещё хорошего в таком подходе? Это фактически бесплатно! Нам нужно лишь проверить, совместимы ли плееры с таким подходом. Те, которые несовместимы, мы отправляем на старые URL-ы, а на новые URL-ы мы отправляем совместимые плееры. Нам не нужно апгрейдить старые клиенты, которые это поддерживают, что тоже важно. Нам фактически не нужно дорабатывать, релизить плееры в мобильных клиентах. Нам не нужно разрабатывать веб-плеер. Это выглядит достаточно хорошо!

Из минусов – необходимость контролировать входящий видеопоток. В случае мобильного клиента мы это можем делать достаточно легко (когда стрим идёт с мобильного клиента), либо транскодить в обязательном порядке, поскольку плеер должен знать, сколько занимает один медиасегмент времени. А поскольку мы анонсируем его до того, как он реально записан, мы должны знать, какое время он займёт, когда мы его запишем.
Таким образом мы улучшили HLS. Теперь хочу рассказать, как мы мониторим и какие метрики качества снимаем:
Одна из основных метрик качества – это время старта. Идеально – это когда вы листаете в мобильном клиенте до трансляции, нажимаете кнопку, и она сразу начинается. Идеально было бы, чтобы она начиналась до того, как вы нажали кнопку, но, к сожалению – только когда нажали.
Второй момент – задержка сигнала. Мы считаем, что несколько секунд – это очень хорошо, 10 секунд – терпимо, 20-30 секунд – совсем плохо. Почему это важно? Например, для концертов и каких-то массовых мероприятий это – абсолютно неважная метрика, там нет обратной связи; мы просто показываем стрим – лучше пусть не лагает, чем будет небольшая задержка. А для стрима, где идёт какая-то конференция или человек что-то рассказывает и ему задают вопросы, это начинает быть важным, потому что вопросов в комментариях задают достаточно много и хочется, чтобы зрители получали фидбэк как можно раньше.
Ещё одна из важных метрик – это буферизация и лаги. На самом деле эта метрика важна не столько с точки зрения клиента и качества, сколько с позиции того, насколько мы можем «протюнить» доставку HLS, насколько мы можем выжать данные из наших серверов. Поэтому мы мониторим как среднее время буфера в плеерах, так и «сталы».
Выбор качества в плеерах – это понятно: неожиданные изменения всегда напрягают.
Соответственно, это тоже важная метрика.
У нас есть много метрик мониторинга, но здесь я выбрал те метрики, которые срабатывают всегда, если что-то пошло не так:

Теперь расскажу, как мы справились с таким приложением, как «Плеер», когда мы использовали нашу инфраструктуру для того, чтобы траслировать видеопоток с вопросами и ответами.
«Клевер» – это онлайн-викторина. Ведущий что-то говорит, спрашивает: выпадают вопросы – вы отвечаете. 12 вопросов, 10 минут игры, в конце – какой-то приз. Что здесь сложного? Это рост!
Справа – этот график:

Пик [на графике] – это нагрузка на серверы в части API в момент старта «Клевера». Всё остальное время – это обычное течение трансляций. Это нельзя приравнять к количеству зрителей. Пожалуй, это количество запросов и нагрузка.
Это тяжело: за 5 минут к нам на пике пришёл миллион зрителей. Они начинают смотреть трансляцию, регистрируются, выполняют какие-то действия, запрашивают видео… Казалось бы, очень простая игра, но это происходит очень в очень сжатый промежуток времени (все действия, в том числе финал игры) – это даёт достаточно высокую нагрузку.


Архитектура нас полностью устраивает, и могу её смело рекомендовать. HLS останется у нас основным протоколом как минимум для веб-сайта и как минимум запасным протоколом для всего остального. Возможно, мы перейдем на MPEG-DASH.
Отказались от RTMP. Несмотря на то, что он даёт меньшую задержку, мы решили, что будем тюнинговать HLS. Возможно, рассмотрим другие средства доставки, в том числе DASH в качестве альтернативы.

Будем улучшать входящую балансировку. Также хотим сделать бесшовный failover для входящей балансировки, чтобы в случае проблем на одном из медиасерверов для клиента переключение происходило бы совсем незаметно.
Возможно, разработаем средства доставки от edge-серверов до клиента. Скорее всего, это будет какой-то UDP. Какой именно – мы сейчас думаем и находимся в стадии исследования.
Собственно, всё. Всем спасибо!
Вопрос из аудитории (далее – А): – Большое спасибо за доклад! Только выступал спикер от «Одноклассников», и он рассказывал, что им пришлось переписать стример, экнриптор, энкодер… Применяете ли вы такие решения или используете стоковые, которые есть на рынке (вроде «Гармоника» (Harmonic) и т. д.)?

МР: – Сейчас у нас крутятся сторонние решения. Из опенсорс-решений, которые мы использовали, у нас был nginx, модуль RTMP (долгое время). С одной стороны, он нас радовал, потому что работал, достаточно простой. Мы очень долго с ним бились, чтобы он стабильно работал. Сейчас он происходит переезд с Nginx-RTMP на собственное решение. С транскодером сейчас думаем. Приёмник, именно приёмная часть тоже уже переписана с Nginx-RTMP на своё решение.
А: – Я хотел задать вопрос о нарезке RTMP на HLS, но я так понимаю, что вы уже ответили… Подскажите, свои решения у вас опенсорсные?
МР: – Мы рассматриваем возможность выпуска в opensource. Мы его скорее хотим выпустить, но вопрос заключается во времени выпуска в опенсорс. Просто выложить в интернет исходники – этого мало. Нужно подумать, сделать некоторые примеры деплоймента. А вы с какой целью спрашиваете? Хотите использовать?
А: – Потому что я тоже сталкивался с Nginx-RTMP! Он, мягко говоря, не поддерживается очень давно. Автор даже не отвечает особо на вопросы…
МР: – Если хотите, можете написать на почту. Отдать для собственного использования? Можем договориться. Мы действительно планируем его заопенсорсить.
А: – Ещё вы говорили, что можете с HLS на DASH переехать. HLS не устраивает?
МР: – Это вопрос о том, что можем, а может, и нет. Это сильно зависит от того, к чему мы придём в плане research-а альтернативных способов доставки (т. е. UDP). Если мы найдём что-то «совсем» хорошее, то, наверное, не будем трогать HLS. Если покажется, что MPEG-DASH больше устраивает – может, переедем. Кажется, что это не очень сложно, но мы не уверены, нужно или нет. Синхронизация между стримами, между качествами и прочим там явно лучше. Есть плюсы.
А: – По поводу алертов. Вы говорили о том, что если стримы перестают стримиться, то это сразу некий алерт. А вы не ловили что-то независящее от вас: провайдер упал, «Мегафон» упал, и люди перестал стримить?..
МР: – Скажем так, что-то независящее от нас – это в основном всякие праздники и прочее. Да ловили. Ну, поймали, да. Администраторы посмотрели – сегодня праздники, остальные характеристики все в порядке – успокоились.
А: – И про масштабирование. На каком уровне масштабируется? Я, допустим, с телефона запросил стрим – мне сразу придёт некая ссылка с правильным ash-сервером?
МР: – Сразу придёт ссылка и, если надо, вас переключит (если будут проблемы на конкретном сервере).

А: – Переключит кто?
МР: – Мобильный плеер либо веб-плеер.
А: – Он перезапустит стрим или как?
МР: – Ему придёт новая ссылка, куда он должен пойти лайв-стримом. Он туда пойдёт и перезапросит стрим.
А: – На каком уровне у вас кэши? И плейлисты, и чанки или только?..
МР: – И плейлисты, чанки! По-разному немного кэшируется и в плане времени, и в плане отдачи времени, но кэшируем и то, и другое.
А: – По поводу создания ash-серверов? У вас было такое, что вы наблюдаете 2 миллиона зрителей на одну трансляцию, что-то не успеваете и быстренько поднимаете какой-нибудь ash-сервер? Или вы заранее всё поднимаете с запасом?
МР: – Пожалуй, такого не было. Во-первых, запас всегда есть небольшой или большой – тут не важно. Во-вторых, так не бывает, чтобы трансляция внезапно стала сверхпопулярной. Мы умеем неплохо предсказывать количество зрителей. В основном, для того чтобы пришлось очень много людей, мы должны приложить усилия. Соответственно, мы можем регулировать количество зрителей трансляции в зависимости от того, какие усилия прикладываем.
А: – Вы сказали, что мерите инструментально задержки со стороны плеера. Как?
МР: – Очень просто. У нас в чанках (в медиасегментах) есть timestamp, в имени медиасегмента – в плеере мы его просто возвращаем. Если он не в явном виде совсем, он возвращается.
А: – Помнится, пробовали запускать пиринг на WebRTC. Почему отказались?
МР: – Я вам не могу ответить на этот вопрос – это происходило без меня. Не могу сказать, почему пробовали и не могу сказать, почему отказались.
А: – По поводу приёмника и медиасервера. Насколько я понимаю, раньше у вас был Nginx-RTMP, сейчас и там, и там у вас самописные решения. По факту это один медиасервер, который проксирует другие медиасерверы, а они уже в кэше и на edge.
МР: – Так, да не совсем. Это самописное решение, но оно разное и в плане медиасервера, и в плане приёмника. Nginx-RTMP – это был некоторый комбайн, который умел и то, и то. У нас сильно отличаются внутренности приёмника и медиасервера – и по коду, и по всему. Единственное, что их объединяет – это обработка RTMP.
А: – По поводу балансировки между edge-ами. Каким образом это происходит?
МР: – Мы мерим трафик, отсылаем на нужный сервер. Немного не понял вопроса…
А: – Поясню: пользователь запрашивает через плеер плейлист – ему возвращает относительные пути к манифестам и чанкам или абсолютные пути, например, по IP или по домену?..
МР: – Пути относительные.
А: – То есть не происходит балансировки в процессе просмотра стрима одним пользователем?
МР: – Происходит. Достаточно хитро. Мы можем использовать 301-й редирект при перегрузке сервера. Если мы видим, что там всё совсем плохо, за сегментами мы можем отправить его на другой сервер.
А: – Но это должно быть зашито в логику плеера?
МР: – Нет, как раз это часть не должна быть зашита. 301-й редирект! Просто плеер должен уметь выходить по 301-й ссылке. Мы можем со стороны сервера в момент перегрузки отправить его на другой сервер.
А: – То есть он спрашивает у сервера, и сервер ему отдаёт?
МР: – Да. Это не очень хорошо, поэтому в логику плеера зашито переполучение ссылки на случай отказа одного из серверов – это уже в логике плеера.
А: – А не пробовали работать не по относительным, а по абсолютным путям: при запросе к плееру производить какую-то магию, выяснять, где есть ресурсы, а где нет, и уже отдавать плейлисты с указанием конкретного сервера?
МР: – На самом деле это выглядит рабочим решением. Если бы вы пришли тогда, мы бы взвесили и то, и другое! Но текущее решение тоже рабочее, поэтому перескакивать с одного на другое не очень хочется, хотя, пожалуй, это тоже выглядит рабочим решением.
А: – Скажите, с multicast-ом это как-то дружит? HLS, как я понимаю, совсем никак…
МР: – В текущей реализации у нас в системе ничего, наверное, с мультикастом в лайве не дружит. У нас там не включается понятие мультикаста. Возможно, где-то в глубине админской магии, внутри сети что-то есть, но это скрыто вообще от всех и никому неизвестно…

Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Я работаю в команде «ВКонтакте» и занимаюсь разработкой системы видеотрансляций.
В докладе поделюсь особенностями разработки бэкенда, тем, как эволюционировала наша система, и техническими решениями, к которым мы пришли:
- как мы делали бэкенд видеотрансляций, и процесс эволюции как он есть;
- влияние бизнес-требований и требований эксплуатации на архитектуру;
- «подождать» и «попробовать ещё раз» не получится;
- как самые простые задачи усложняются количеством пользователей;
- как уменьшить задержку без UDP;
- проводим стресс-тесты 2 раза в день, или в чем нам помог «Клевер».
Михаил Райченко (далее – МР): – Немного экскурса. Я расскажу вам про людей, которые стримят нам, про сами лайвы (live), о том, с каких платформ мы принимаем видеопоток и на какие раздаём. В конце расскажу текущую архитектуру лайвов, про её ограничения и возможности, а также о том, как текущая архитектура пережила такой эффект, как «Клевер».
О прямых трансляциях. План доклада
- Сперва я расскажу немного о самих прямых трансляциях и стримерах, присылающих нам видеоконтент, который мы показываем другим зрителям.
- После этого немного сравню с видеозвонками и с самим видео. Зачем я это делаю? Если вы задумаетесь над тем, чтобы сделать свой сервис трансляций, то, наверное, вы хотите каким-то образом где-то схитрить, где-то сэкономить, оптимизировать. Тут важно понимать, где мы можем сэкономить по сравнению с видео: где мы проигрываем, где – выигрываем.
- Также проведу экскурс в историю. Расскажу, как была устроена первая архитектура видеотрансляций. Это можно даже назвать прототипом. Тем не менее она работала, и если вы делаете свои трансляции, можете даже на ней остановиться.
- После этого расскажу, как формулировались требования к архитектуре, откуда они взялись. Расскажу о том, как мы их реализовывали и что в итоге получилось. Могу сказать, что версия архитектуры, которая сейчас есть, была сделана, наверное, примерно в 2014-2015 году. Она пережила достаточно существенный тюнинг, но все основы остались теми же.
- После этого мы поговорим о масштабировании и балансировке. Это важно, поскольку хорошая архитектура должна выдерживать горизонтальное масштабирование и вести себя достаточно устойчиво при большом количестве зрителей и большом количестве стримов.
- Расскажу, какие протоколы мы используем. У нас достаточно небольшой набор протоколов как для приёма видео, так и для доставки. Расскажу, почему мы их выбрали.
- Обсудим метрики качества и то, как мы мониторим трансляции. Это важно для эксплуатации любой системы.
- Как уже сказал, ещё расскажу о том, как текущая архитектура пережила рост «Клевера», и насколько она справилась.
Немного о прямых трансляциях и стримерах
Все сервисы трансляций выглядят примерно так:
У нас есть некоторый стример, он присылает поток RTMP нам, и мы показываем зрителям – ничего удивительного, ничего сверхъестественного.
Откуда приходит видеопоток? Значительным источником трафика для нас является наше мобильное приложение VKlife. Что в нём хорошо? В нём мы можем полностью контролировать то, как мы кодируем видео. Можем произвести много оптимизаций на стороне клиента, чтобы потом с минимальными задержками показывать его нашим зрителям.
Из минусов: мобильные приложения работают поверх сетей. Это может быть 3G… В любом случае это почти всегда мобильные сети, что вносит некоторые лаги – необходимо дополнительное буферизировать данные на стороне приложения, чтобы поток шёл как можно более ровно.
Вторым источником являются стримеры с OBS, Wirecast или те, кто стримит с других десктопных приложений. Это достаточно большая аудитория. Иногда это семинары, иногда – игровые стримы (их особенно много с таких приложений). Из положительного: таких приложений немного, мы можем давать нашим стримерам хорошие рекомендации по настройке. Но при этом там много настроек и шлют не совсем тот поток, который мы хотим.
Третья категория – это RTMP-поток от медиасерверов. Это могут быть совсем маленькие медиасерверы, то есть домашнего формата: человек стримит вид на улицу или что-то ещё. Либо достаточно серьёзные трансляции от наших партнёров: там может быть всё что угодно, таких стримов не очень много, но в основном они весьма важны для нас.
Кто смотрит?
Опять же, это мобильное приложение – тут всё понятно. Самая большая проблема – сетевые задержки. Из плюсов: мы можем кастомизировать плеер – нам это удобно, хорошо, но не везде это получается на 100%.
Веб-плеер на vk.com. Тут тоже всё просто – это обычный веб-плеер, который можете открыть посмотреть. Достаточно большая аудитория у vk.com, много зрителей на трансляциях. Некоторые трансляции висят у нас в разделе «Видео» – там могут быть десятки тысяч (иногда без всякого пиара), особенно если это интересный контент.
Соответственно, каналы достаточно большие у зрителей, которые сидят на веб-плеере. Поэтому трафика достаточно много, в том числе на одну трансляцию.
Третье – это веб-плеер «ВКонтакте» на каком-нибудь стороннем сайте. Вы можете начать стримить всё, что хотите, и у себя на сайте повесить веб-плеер «ВКонтакте». Вы можете выступить нашим партнёром, если у вас интересный контент: можете повесить у себя, можете повесить у нас – как хотите. Можете организовать свои трансляции таким образом, и всё будет работать.
Сравнение с видеозвонками
В видеозвонках нам простят некоторое искажение изображения. В видеозвонках проще: мы можем существенно ухудшить изображение, но при этом мы обязаны выдерживать очень хороший latency. При большой задержке сервис будет абсолютно невозможно использовать.
В трансляциях в этом смысле немного наоборот: мы должны поддерживать высокое качество изображения, но при этом можем увеличить latency в силу множества факторов. Например, плеер так или иначе буферизирует у себя поток (это может быть секунда, две, чтобы пережить деградацию сети, например), поэтому там не нужны секундные, миллисекундные задержки в большинстве случаев. Можно к этому стремиться, но продуктово это не является обязательным условием.
С обычным видео ситуация ровно обратная. Нам нужно очень хорошее качество. При этом желательно минимизировать размер видео, соотношение битрейта и качества, чтобы с минимальным потоком отдавать наилучшее решение. Из плюсов: мы не ограничены по времени: в момент загрузки видео у нас достаточно времени для того, чтобы оптимизировать видео, посмотреть, как его сжать наилучшим образом, что-то сделать, утащить его на кэши, если надо – в общем, всё достаточно хорошо.
В лайвах ситуация, опять же, обратная: у нас очень мало времени на транскодирование. При этом возможностей по времени мало, но нет никаких ожиданий по трансляции. Зрители нам простят, если у нас будет поддержка или качество будет не очень.
Самая первая версия
Она вполне ожидаемая:
На самом деле она немного другая:
«Стример – медиасервер – уровень кэширования – зрители». В принципе эта версия позволяет масштабироваться достаточно сильно. Я бы сказал, что десятки тысяч зрителей она уже должна выдерживать. У неё есть другие недостатки…
Например, если посмотреть на эту схему (предыдущий слайд), видно, что она не отказоустойчивая. Мы должны угадывать с медиасервером, чтобы хорошо балансировать зрителей. Мы не можем на каждый сервер повесить много кэшей – это просто дорого. Поэтому мы посмотрели, поняли, что это просто и понятно, есть некоторые возможности для масштабирования, но явно чего-то не хватает… И начали формулировать требования.
Требования к инфраструктуре
Что важно?
- Количество трансляций. Мы должны держать тысяч и, возможно, даже десятки тысяч трансляций. При этом количество зрителей на одну трансляцию может быть достаточно велико (до миллиона вполне должны держать на данный момент). Суммарное количество зрителей тоже достаточно велико (десятки, сотни тысяч).
- Отказоустойчивость. Тут отказоустойчивость с двух сторон: во-первых, отказ принимающей стороны (точка, где мы принимаем видеопоток) не должен сильно влиять на трансляции; во-вторых, отказ со стороны раздающей – отказ одного из серверов со стороны, откуда мы раздаём видеопоток, тоже не должен влиять на наши трансляции.
- Доставка до регионов. Тоже важный момент! Глупо тащить весь видеоконтент от Петербурга или Москвы до какого-нибудь Новосибирска, Екатеринбурга, или даже от Питера до Москвы. Это не очень хорошо, поскольку сетевая задержка будет длинной – будут лаги, всё будет лагать, а это нехорошо. Поэтому наша инфраструктура должна учитывать, что мы доставляем контент до регионов.
- Удобство эксплуатации и мониторинг. Важное свойство. Так как система большая, зрителей много, то важно вовремя отсылать алерты администраторам в случае каких-то проблем, в том числе мониторить продуктовые и технические метрики.
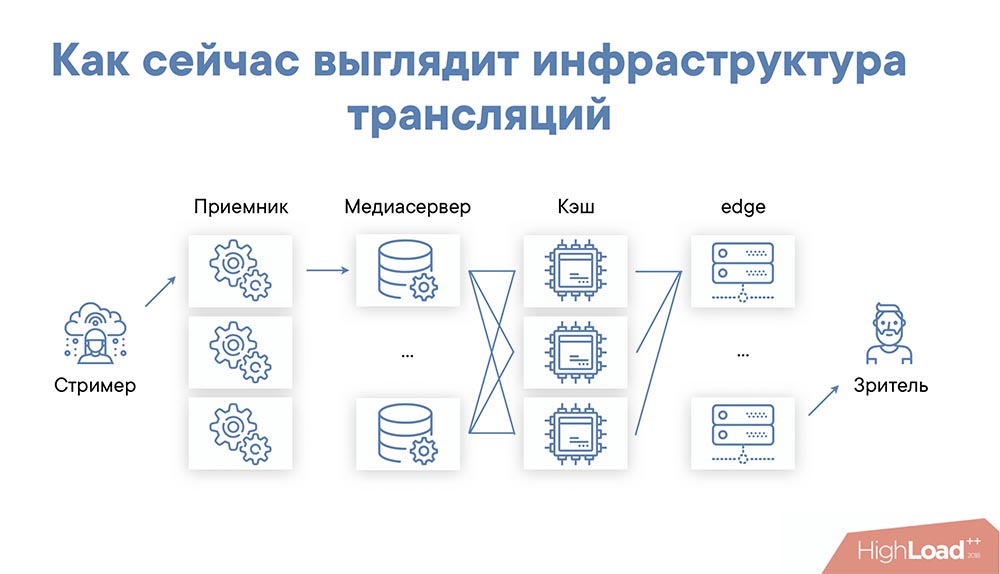
Как сейчас выглядит инфраструктура трансляций?
В итоге мы пришли к достаточно простой, но эффективной инфраструктуре…
- Это – стример, которому выдаётся ссылка на точку входа (это приёмники, их несколько). Стример начинает RTMP-поток, тот попадает на приёмник. На приёмнике происходит некоторая валидация и пересылка далее, на медиасерверы.
- Приёмник выбирает, на какой из медиасерверов направить поток, балансирует зачастую по входящему трафику, по нагрузке, по доступности сервера. Он выбрал сервер и направил туда медиапоток. Задача сервера, с одной стороны, простая и понятная, с другой – сложная: нужно, во-первых, затранскодить (т. е. преобразовать видеопоток в несколько разрешений для доставки); во-вторых, нужно упаковать в нужный формат.
- С медиасерверов мы попадаем на уровень кэширования. Это первый уровень кэширования – он не очень большой, но очень важный. На этом уровне мы кэшируем фактически все видеопотоки, которые у нас есть, и раздаём их дальше. Это не очень большое количество серверов, но большое количество оперативной памяти либо быстрых дисков (на самом деле и того, и другого).
- Этот уровень защищает медиасерверы от перегрузки фактически в любом случае, вне зависимости от количества зрителей или раздающих серверов (edge-серверов). Медиасерверы не будут перегружены отсоединениями, ни раздачей. Они защищены достаточно надёжно!
- Последний уровень кэширования – это edge-серверы, которые уже стоят непосредственно в регионах, в точках доставки. Тут всё просто: они не очень сильно кэшируют трафик, их задача – просто отдать его зрителю.
Что интересно? Балансировка! В этой схеме мы выбираем балансировку, стараемся на каждый edge-сервер прислать зрителей, которые смотрят один и тот же поток. Здесь очень важна локальность кэша, потому что edge-серверов может быть много; и если мы не будем соблюдать и временную, и локальность кэша с точки зрения стрима, то мы перегрузим внутренний слой. Этого нам тоже не хотелось бы.
Поэтому балансируем мы следующим образом: выбираем некий сервер edge для региона, на который мы отсылаем зрителей, и отсылаем до тех пор, пока не начинаем понимать, что произошло некоторое заполнение и стоит отсылать на другой сервер. Схема простая и работает очень надёжно. Естественно, для разных стримов вы выбираем разную последовательность edge-серверов (последовательность, в которой мы рассылаем зрителей). Соответственно, балансировка работает достаточно просто.
Также мы отдаём клиенту ссылку на доступный edge-сервер. Это сделано для того, чтобы в случае отказа edge-сервера мы могли перенаправить зрителя на другой. То есть, когда зритель смотрит трансляцию, ему раз в несколько секунд приходит ссылка на нужный сервер. Если он понимает, что ссылка должна быть другой, он переключается (переключается плееер) и продолжает смотреть трансляцию уже с другого сервера.
Ещё одна важная роль edge-серверов – это защита контента. Вся защита контента по сути происходит там. У нас свой модуль nginx для этого допилен. Он чем-то похож на Security Link.
Масштабирование и балансировка
- Масштабирование по количеству стримов. Понятно, что в этой архитектуре мы очень хорошо отмасштабированы: мы можем легко добавить медиасерверов, приёмников и у нас не будет проблем. С точки зрения раздачи контента мы можем легко масштабировать edge-серверы, пока не упрёмся в пропускную способность внутреннего кэширования. Но это достаточно тяжело сделать. Масштабирование по суммарному количеству зрителей. Тут тоже всё понятно… Нас не пугает, что зрителей стримов много – мы соблюдаем локальность кэширования, поэтому один-два-три зрителя на стрим – легко, сто – легко, тысячи, десятки, сотни тысяч – тоже легко! Если что – добавляем сервер для стрима и начинаем масштабировать дальше.
- Масштабирование по количеству зрителей на одной трансляции. Тут сложнее, потому что, если мы начинаем отдавать один и тот же сервер, а потом пускаем трансляцию, то может произойти не очень хорошая вещь: сервер будет некоторое время перегружен. Для этого мы иногда включаем режим (в случае популярной трансляции) выдачи не одного сервера, а сразу нескольких – либо случайным образом, либо по трафику. Или, в случае перегрузки сервиса, придёт со ссылкой новый сервис, и зритель переключится на другой edge-сервер.
- После того как масштабировали, можно заниматься качеством, чем мы и занимаемся в последнее время, так как масштабирование работает хорошо.
Какие протоколы мы использовали?
Одним из основных протоколов у нас был RTMP (не только на вход, но и на раздачу контента). Основное преимущество – низкая задержка. Это может быть полсекунды, секунда, две секунды. На самом деле преимущества на этом заканчиваются…
Этот потоковый протокол сложно мониторить – он закрытый в некотором смысле, несмотря на то, что есть спецификация. Flash-плеер уже не работает (по сути он «уже всё»). Нужна поддержка на уровне CDN – необходимы специальные модули nginx или свой софт, чтобы нормально передать поток. Есть также некоторые сложности в мобильных клиентах. «Из коробки» в мобильных клиентах поддерживается очень плохо – нужны специальные доработки, и всё это очень сложно.
Второй протокол, который мы использовали – это HLS. Выглядит он достаточно просто: это текстовый файл, так называемый index file. В нём содержатся ссылки на индексные файлы с различными разрешениями, а в самих файлах – ссылки на медиасегменты.
Чем он хорош? Он очень простой, несмотря на то, что староват. Он позволяет использовать CDN, то есть вам нужен всего лишь nginx, чтобы раздать HLS-протокол. Он понятен с точки зрения мониторинга.
Вот его плюсы:
- простота эксплуатации – nginx как прокси-сервер;
- легко мониторить и снимать метрики (вам достаточно мониторить примерно то же, что вы мониторите на своём веб-сайте);
- сейчас этот протокол – основной у нас для доставки контента.
Существенный минус:
- высокая задержка.
Задержка в HLS фактически вложена в сам протокол; так как необходимо продолжительное время буферизации, плеер вынужден ждать как минимум когда загрузится один чанк, а по-хорошему он должен ждать пока загрузятся два чанка (два медиасегмента), иначе в случае лага у клиента появится прогруз плеера, а это не очень хорошо влияет на user experience.
Второй момент, который даёт задержку в HLS – это кэширование. Плейлист кэшируется на внутреннем слое и на edge-серверах. Даже если мы кэшируем, условно говоря, на секунду-полсекунды, то это – примерно плюс 2-3 секунды задержки. Суммарно получается от 12 до 18 секунд – это не очень приятно, явно можно лучше.
Улучшаем HLS
С этими мыслями мы начали улучшать HLS. Улучшали мы его достаточно простым путём: давайте отдавать последний, даже ещё не записанный медиасегмент плейлиста немного раньше. Т. е. как только мы начали писать последний медиасегмент, мы сразу анонсируем его в плейлисте. Что в этот момент происходит?..
Уменьшается время буферизации в плеерах. Плеер считает, что он уже всё загрузил, и спокойно начинает качать нужные сегменты. Мы немного «обманываем» таким образом плеер, но если мы хорошо мониторим «сталы» (прогрузы в плеере), нас это не пугает – мы можем перестать отдавать сегмент заранее, и всё вернётся к норме.
Второй момент: выигрываем суммарно примерно 5-8 секунд. Откуда они берутся? Это время сегмента – от 2 до 4 секунд на один сегмент, плюс время на кэширование плейлиста (это еще 2-3 секунды). Задержка у нас уменьшается, притом существенно. Задержка уменьшается с 12-15 секунд до 5-7.
Что ещё хорошего в таком подходе? Это фактически бесплатно! Нам нужно лишь проверить, совместимы ли плееры с таким подходом. Те, которые несовместимы, мы отправляем на старые URL-ы, а на новые URL-ы мы отправляем совместимые плееры. Нам не нужно апгрейдить старые клиенты, которые это поддерживают, что тоже важно. Нам фактически не нужно дорабатывать, релизить плееры в мобильных клиентах. Нам не нужно разрабатывать веб-плеер. Это выглядит достаточно хорошо!
Из минусов – необходимость контролировать входящий видеопоток. В случае мобильного клиента мы это можем делать достаточно легко (когда стрим идёт с мобильного клиента), либо транскодить в обязательном порядке, поскольку плеер должен знать, сколько занимает один медиасегмент времени. А поскольку мы анонсируем его до того, как он реально записан, мы должны знать, какое время он займёт, когда мы его запишем.
Метрики качества
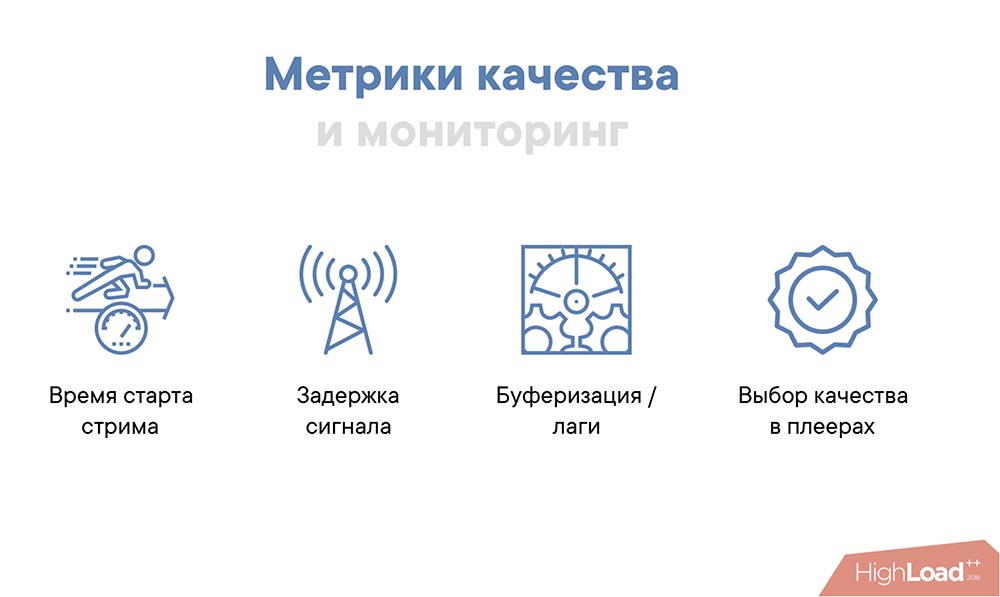
Таким образом мы улучшили HLS. Теперь хочу рассказать, как мы мониторим и какие метрики качества снимаем:
Одна из основных метрик качества – это время старта. Идеально – это когда вы листаете в мобильном клиенте до трансляции, нажимаете кнопку, и она сразу начинается. Идеально было бы, чтобы она начиналась до того, как вы нажали кнопку, но, к сожалению – только когда нажали.
Второй момент – задержка сигнала. Мы считаем, что несколько секунд – это очень хорошо, 10 секунд – терпимо, 20-30 секунд – совсем плохо. Почему это важно? Например, для концертов и каких-то массовых мероприятий это – абсолютно неважная метрика, там нет обратной связи; мы просто показываем стрим – лучше пусть не лагает, чем будет небольшая задержка. А для стрима, где идёт какая-то конференция или человек что-то рассказывает и ему задают вопросы, это начинает быть важным, потому что вопросов в комментариях задают достаточно много и хочется, чтобы зрители получали фидбэк как можно раньше.
Ещё одна из важных метрик – это буферизация и лаги. На самом деле эта метрика важна не столько с точки зрения клиента и качества, сколько с позиции того, насколько мы можем «протюнить» доставку HLS, насколько мы можем выжать данные из наших серверов. Поэтому мы мониторим как среднее время буфера в плеерах, так и «сталы».
Выбор качества в плеерах – это понятно: неожиданные изменения всегда напрягают.
Соответственно, это тоже важная метрика.
Мониторинг
У нас есть много метрик мониторинга, но здесь я выбрал те метрики, которые срабатывают всегда, если что-то пошло не так:
- Во-первых, это количество стримов онлайн. Как только что-то идёт не так, это количество падает сразу. Иногда сильно, иногда – нет, но в случае любой ошибки или проблемы на серверах мы замечаем это моментально (десятки секунд, минуты – достаточно быстро).
- Входящий / исходящий трафик тоже понятная метрика. Причём входящий, пожалуй, более стабильный, поскольку исходящий зависит от популярности трансляции, а тут далеко не всегда можно сказать заранее, какое мероприятие будет популярным. Поэтому в основном входящий трафик.
- Время ответа edge-серверов. Понятная метрика, которая скорее важна для администрирования и эксплуатации, так как проблемы на edge-серверах сразу себя проявляют в случае любых проблем.
Что такое «Клевер», и как мы справились с его ростом?
Теперь расскажу, как мы справились с таким приложением, как «Плеер», когда мы использовали нашу инфраструктуру для того, чтобы траслировать видеопоток с вопросами и ответами.
«Клевер» – это онлайн-викторина. Ведущий что-то говорит, спрашивает: выпадают вопросы – вы отвечаете. 12 вопросов, 10 минут игры, в конце – какой-то приз. Что здесь сложного? Это рост!
Справа – этот график:
Пик [на графике] – это нагрузка на серверы в части API в момент старта «Клевера». Всё остальное время – это обычное течение трансляций. Это нельзя приравнять к количеству зрителей. Пожалуй, это количество запросов и нагрузка.
Это тяжело: за 5 минут к нам на пике пришёл миллион зрителей. Они начинают смотреть трансляцию, регистрируются, выполняют какие-то действия, запрашивают видео… Казалось бы, очень простая игра, но это происходит очень в очень сжатый промежуток времени (все действия, в том числе финал игры) – это даёт достаточно высокую нагрузку.
Какие вопросы и челленджы перед нами были?
- Быстрый рост. Иногда это было +50% в неделю. Если, например, в среду у вас 200 тысяч людей, то в субботу или воскресенье могло быть уже 300. Это много! Начинают всплывать проблемы, которых раньше не было видно.
- При этом он проходит 2 раза в день. Очень мало времени на решение этих проблем. В утренней трансляции обычно поменьше людей, вечером побольше. В принципе у вас есть утренняя трансляция, чтобы отдебажиться, понять, что может пойти не так или начинает идти не так, и к вечерней трансляции вы должны иметь решение проблемы, иначе будет очень неприятно.
Примерно 12 часов у нас уходило на исследование и устранение проблем. Кажется, что этого времени много, но на самом деле нет, потому что нужно протестировать, выкатить, попробовать подходы на какой-то другой трансляции и нужно быть уверенными, что вы решили эту проблему, потому что… - Если вы не справляетесь за это время, в следующий раз скорее всего вы упадёте. Все проблемы начинают себя проявлять, например, на 200-300 тысячах, и это приводит к очень неприятным последствиям на 400-500.
- Из-за того, что эта трансляция одна, а зрителей много, то в случае лагов на сервере трафик моментально взлетает в 3-5 раз. Как это происходит? У плеера происходит «стал», он получает новый плейлист, в котором есть сегменты, которых он ещё не видел и которые не скачал, и он начинает их качать.
Качает он их в три раза быстрее (хочет скачать в 3 раза больше одномоментно, чтобы немного буферизировать), и при этом через некоторое время ещё может переключить качество, что приведёт к росту ещё в 3-5 раз. Как с этим бороться? Первое – деградация качества, второе – обязательно делать на клиенте exponential backoff, иначе вы просто не поднимите в случае проблем.
Как работает exponential on backoff: попробовали – сломалось, в следующий раз должны попробовать через 2 секунды, потом через 4, через 8. Тогда вы достаточно быстро поднимитесь в случае проблемы и не перегрузите свои backend-серверы.
Что нам показал рост «Клевера»?
- Во-первых, масштабирование и балансировка работают очень хорошо в такой схеме. Если будете делать большую систему трансляций, рекомендую такой подход – очень хорошо работает.
- Мы сделали тестирование «в фоне». Каждый раз, когда пользователь открывает любую трансляцию, мы формируем некоторую фейковую, в которую шлём те же запросы, которые слали бы в «Клевер». В этом случае мы можем удостовериться, что наши решения, во-первых, сработали в случае проблем, а во-вторых, что не возникли новые проблемы.
- Сделали метрику, которую мы обычно не отслеживаем и не смотрим – это количество пользователей, у которых не было «сталов» в течение пяти минут. Это интересная метрика именно для «Клевера». Если у вас обычная трансляция, то кажется, что не важно, сколько пользователей испытывает проблемы… То есть в среднем – работает. 10% «сталов» – нормально, 10% «сталов» на 100 стримов – тоже нормально.
- Для «Клевера» это важно потому, что в видеопотоке идут вопросы, и даже один «стал» или один пролаг вызывает большой негатив. Такого не происходит в обычной трансляции – там не такой негатив из-за одного лага. Вот если там 100 лагов у пользователя – это неприятно, а 1 лаг в течение 15 минут – нет такого негатива.
- Сильно улучшилось взаимодействие команд. В «Клевере» поучаствовали сетевой инфраструктуры, администрирования, бэкенда, продуктовые команды. Я бы сказал, что взаимодействие стало существенно более продуктивным, как ни странно это звучит.
- Улучшили инструментарий для диагностики. Фактически в плане видеотрансляций мы научились детектировать проблемы сразу после возникновения и даже предвосхищать в некотором смысле любые проблемы, которые у нас возникали. На финальном этапе мы не деградировали ни по качеству, ни по latency, ни по другим характеристикам.
- Прокачали навыки нагрузочного тестирования. Спасибо нашим тестировщикам – они многое сделали для того, чтобы помочь нам разобраться с любыми вопросами.
- В пик «Клевера» на одну трансляцию у нас приходилось 1 миллион зрителей и на одну трансляцию мы отдавали около терабита видеопотока. Может, не миллион, а чуть меньше. Это достаточно много для одной трансляции. Возникали скорее не проблемы, а интересные ситуации с балансировкой, а также балансировкой других стримов. Тем не менее архитектура справилась хорошо.
Что в итоге?
Архитектура нас полностью устраивает, и могу её смело рекомендовать. HLS останется у нас основным протоколом как минимум для веб-сайта и как минимум запасным протоколом для всего остального. Возможно, мы перейдем на MPEG-DASH.
Отказались от RTMP. Несмотря на то, что он даёт меньшую задержку, мы решили, что будем тюнинговать HLS. Возможно, рассмотрим другие средства доставки, в том числе DASH в качестве альтернативы.
Будем улучшать входящую балансировку. Также хотим сделать бесшовный failover для входящей балансировки, чтобы в случае проблем на одном из медиасерверов для клиента переключение происходило бы совсем незаметно.
Возможно, разработаем средства доставки от edge-серверов до клиента. Скорее всего, это будет какой-то UDP. Какой именно – мы сейчас думаем и находимся в стадии исследования.
Собственно, всё. Всем спасибо!
Вопросы
Вопрос из аудитории (далее – А): – Большое спасибо за доклад! Только выступал спикер от «Одноклассников», и он рассказывал, что им пришлось переписать стример, экнриптор, энкодер… Применяете ли вы такие решения или используете стоковые, которые есть на рынке (вроде «Гармоника» (Harmonic) и т. д.)?
МР: – Сейчас у нас крутятся сторонние решения. Из опенсорс-решений, которые мы использовали, у нас был nginx, модуль RTMP (долгое время). С одной стороны, он нас радовал, потому что работал, достаточно простой. Мы очень долго с ним бились, чтобы он стабильно работал. Сейчас он происходит переезд с Nginx-RTMP на собственное решение. С транскодером сейчас думаем. Приёмник, именно приёмная часть тоже уже переписана с Nginx-RTMP на своё решение.
А: – Я хотел задать вопрос о нарезке RTMP на HLS, но я так понимаю, что вы уже ответили… Подскажите, свои решения у вас опенсорсные?
МР: – Мы рассматриваем возможность выпуска в opensource. Мы его скорее хотим выпустить, но вопрос заключается во времени выпуска в опенсорс. Просто выложить в интернет исходники – этого мало. Нужно подумать, сделать некоторые примеры деплоймента. А вы с какой целью спрашиваете? Хотите использовать?
А: – Потому что я тоже сталкивался с Nginx-RTMP! Он, мягко говоря, не поддерживается очень давно. Автор даже не отвечает особо на вопросы…
МР: – Если хотите, можете написать на почту. Отдать для собственного использования? Можем договориться. Мы действительно планируем его заопенсорсить.
А: – Ещё вы говорили, что можете с HLS на DASH переехать. HLS не устраивает?
МР: – Это вопрос о том, что можем, а может, и нет. Это сильно зависит от того, к чему мы придём в плане research-а альтернативных способов доставки (т. е. UDP). Если мы найдём что-то «совсем» хорошее, то, наверное, не будем трогать HLS. Если покажется, что MPEG-DASH больше устраивает – может, переедем. Кажется, что это не очень сложно, но мы не уверены, нужно или нет. Синхронизация между стримами, между качествами и прочим там явно лучше. Есть плюсы.
А: – По поводу алертов. Вы говорили о том, что если стримы перестают стримиться, то это сразу некий алерт. А вы не ловили что-то независящее от вас: провайдер упал, «Мегафон» упал, и люди перестал стримить?..
МР: – Скажем так, что-то независящее от нас – это в основном всякие праздники и прочее. Да ловили. Ну, поймали, да. Администраторы посмотрели – сегодня праздники, остальные характеристики все в порядке – успокоились.
А: – И про масштабирование. На каком уровне масштабируется? Я, допустим, с телефона запросил стрим – мне сразу придёт некая ссылка с правильным ash-сервером?
МР: – Сразу придёт ссылка и, если надо, вас переключит (если будут проблемы на конкретном сервере).
А: – Переключит кто?
МР: – Мобильный плеер либо веб-плеер.
А: – Он перезапустит стрим или как?
МР: – Ему придёт новая ссылка, куда он должен пойти лайв-стримом. Он туда пойдёт и перезапросит стрим.
А: – На каком уровне у вас кэши? И плейлисты, и чанки или только?..
МР: – И плейлисты, чанки! По-разному немного кэшируется и в плане времени, и в плане отдачи времени, но кэшируем и то, и другое.
А: – По поводу создания ash-серверов? У вас было такое, что вы наблюдаете 2 миллиона зрителей на одну трансляцию, что-то не успеваете и быстренько поднимаете какой-нибудь ash-сервер? Или вы заранее всё поднимаете с запасом?
МР: – Пожалуй, такого не было. Во-первых, запас всегда есть небольшой или большой – тут не важно. Во-вторых, так не бывает, чтобы трансляция внезапно стала сверхпопулярной. Мы умеем неплохо предсказывать количество зрителей. В основном, для того чтобы пришлось очень много людей, мы должны приложить усилия. Соответственно, мы можем регулировать количество зрителей трансляции в зависимости от того, какие усилия прикладываем.
А: – Вы сказали, что мерите инструментально задержки со стороны плеера. Как?
МР: – Очень просто. У нас в чанках (в медиасегментах) есть timestamp, в имени медиасегмента – в плеере мы его просто возвращаем. Если он не в явном виде совсем, он возвращается.
А: – Помнится, пробовали запускать пиринг на WebRTC. Почему отказались?
МР: – Я вам не могу ответить на этот вопрос – это происходило без меня. Не могу сказать, почему пробовали и не могу сказать, почему отказались.
А: – По поводу приёмника и медиасервера. Насколько я понимаю, раньше у вас был Nginx-RTMP, сейчас и там, и там у вас самописные решения. По факту это один медиасервер, который проксирует другие медиасерверы, а они уже в кэше и на edge.
МР: – Так, да не совсем. Это самописное решение, но оно разное и в плане медиасервера, и в плане приёмника. Nginx-RTMP – это был некоторый комбайн, который умел и то, и то. У нас сильно отличаются внутренности приёмника и медиасервера – и по коду, и по всему. Единственное, что их объединяет – это обработка RTMP.
А: – По поводу балансировки между edge-ами. Каким образом это происходит?
МР: – Мы мерим трафик, отсылаем на нужный сервер. Немного не понял вопроса…
А: – Поясню: пользователь запрашивает через плеер плейлист – ему возвращает относительные пути к манифестам и чанкам или абсолютные пути, например, по IP или по домену?..
МР: – Пути относительные.
А: – То есть не происходит балансировки в процессе просмотра стрима одним пользователем?
МР: – Происходит. Достаточно хитро. Мы можем использовать 301-й редирект при перегрузке сервера. Если мы видим, что там всё совсем плохо, за сегментами мы можем отправить его на другой сервер.
А: – Но это должно быть зашито в логику плеера?
МР: – Нет, как раз это часть не должна быть зашита. 301-й редирект! Просто плеер должен уметь выходить по 301-й ссылке. Мы можем со стороны сервера в момент перегрузки отправить его на другой сервер.
А: – То есть он спрашивает у сервера, и сервер ему отдаёт?
МР: – Да. Это не очень хорошо, поэтому в логику плеера зашито переполучение ссылки на случай отказа одного из серверов – это уже в логике плеера.
А: – А не пробовали работать не по относительным, а по абсолютным путям: при запросе к плееру производить какую-то магию, выяснять, где есть ресурсы, а где нет, и уже отдавать плейлисты с указанием конкретного сервера?
МР: – На самом деле это выглядит рабочим решением. Если бы вы пришли тогда, мы бы взвесили и то, и другое! Но текущее решение тоже рабочее, поэтому перескакивать с одного на другое не очень хочется, хотя, пожалуй, это тоже выглядит рабочим решением.
А: – Скажите, с multicast-ом это как-то дружит? HLS, как я понимаю, совсем никак…
МР: – В текущей реализации у нас в системе ничего, наверное, с мультикастом в лайве не дружит. У нас там не включается понятие мультикаста. Возможно, где-то в глубине админской магии, внутри сети что-то есть, но это скрыто вообще от всех и никому неизвестно…
Немного рекламы :)
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
 защита изображений от копирования")


