
Дисклеймер
Статья посвящёна проблеме обработки длинных входных последовательностей нейросетевыми моделями на основе архитектуры Transformer. От читателя требуется понимание общих принципов работы Transformer и устройства self-attention. Если хочется сперва разобраться в существующих моделях от самых простых до более современных, можно заглянуть в этот обзор (часть более старых работ позаимствована оттуда). Если непонятно вообще всё, то лучше начать с основ.
Работы по теме в русскоязычном сегменте есть (например, эта, эта или эта) и их имеет смысл почитать. Текст статьи основан на моей лекции для студентов ВМК МГУ.
Введение
Одна из ключевых проблем Transformer — квадратичная сложность обработки последовательности слоем self-attention (механизм внимания),  , где
, где  — длина последовательности, а
— длина последовательности, а  — размерность каждого её элемента. Из-за этого первые модели обычно ограничивались относительно небольшими длинами контекста (256, 512), да и сейчас основные LLM общего назначения обычно имеют контекст 2048 или 4096 (либо используют какие-то оптимизации из описываемых ниже). В ряде задач (суммаризация книг, анализ документации, ведение длинных диалогов и т.д.) длина последовательности имеет критическое значение, поэтому попытки каким-то образом расширить контекст начали предприниматься почти сразу после появления первых предобученных моделей.
— размерность каждого её элемента. Из-за этого первые модели обычно ограничивались относительно небольшими длинами контекста (256, 512), да и сейчас основные LLM общего назначения обычно имеют контекст 2048 или 4096 (либо используют какие-то оптимизации из описываемых ниже). В ряде задач (суммаризация книг, анализ документации, ведение длинных диалогов и т.д.) длина последовательности имеет критическое значение, поэтому попытки каким-то образом расширить контекст начали предприниматься почти сразу после появления первых предобученных моделей.
В этой (первой) статье приведены основные идеи большинства популярных работ по теме оптимизации self-attention, опубликованных за последние годы. Рассматриваются разные подходы: приближённое вычисление внимания, иерархическая обработка последовательности, добавление рекурентности, математические преобразования формул self-attention и вычислительные оптимизации. Все изображения взяты из первоисточников, туда же рекомендуется идти за подробностями реализаций.
Ещё одной важной частью работы с длинным контекстом является выбор эффективного способа кодирования позиционной информации, этой теме будет посвящена вторая статья. В описаниях ниже для простоты эта информация не приводится или присутствует минимально.
Обзор работ
Transformer-XL, 2019
Архитектура декодировщика, входная последовательность разбивается на сегменты, обрабатываемые рекурентно:
выходы self-attention для текущего сегмента кэшируются во всех блоках Transformer
при обработке i-го сегмента используются кэшированные выходы (i-1)-го
выходы двух сегментов конкатенируются, по ним считаются ключи (K) и значения (V)
запросы (Q) считаются только по токенам текущего сегмента, градиент тоже течёт только через эти токены
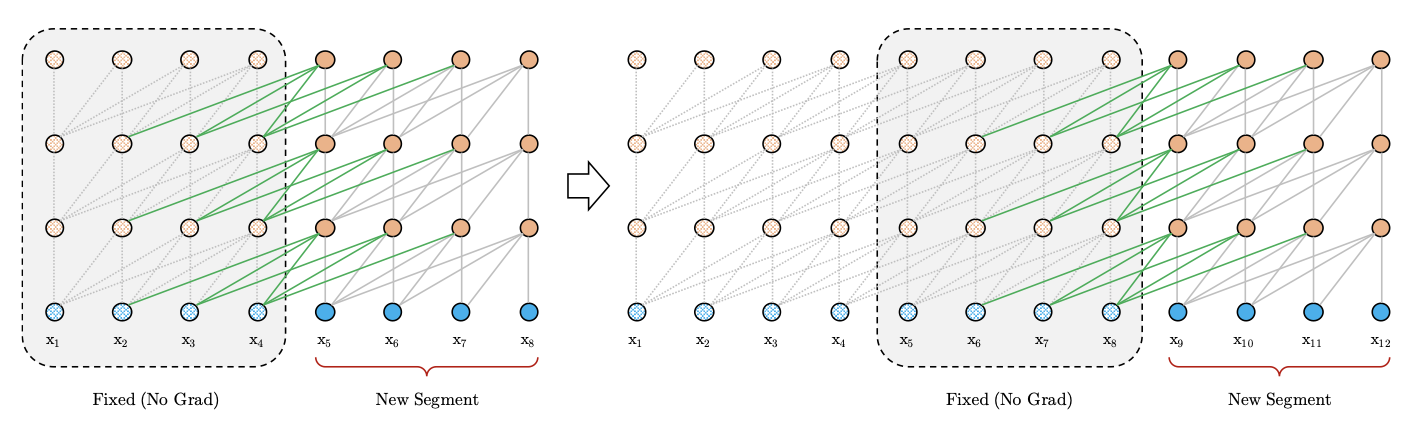
Такая схема обработки не может работать с абсолютным позиционным кодированием, оно заменяется на относительное: позиционные эмбеддинги убираются, вместо них информация о позиции добавляется напрямую в подсчёт self-attention. Для этого используются фиксированная матрица на основе значений синусов от расстояний между всевозможными позициями токенов и два обучаемых вектора, общих для всех позиций.
Sparse Transformer, 2019
Архитектура декодировщика, для ускорения используется локальный self-attention: при обработке токена внимание обращается не на всю последовательность, а на сегмент до текущего токена (если вход двумерный, то по вертикали и горизонтали)
Для того, чтобы информация о других частях последовательности тоже могла дойти до токена, в каждом сегменте используется C выделенных токенов, на которые могут смотреть при подсчёте внимания как токены текущего сегмента, так и токены всех последующих сегментов. Например, в каждом сегменте из 128 токенов можно брать по 8 таких токенов, т.е. токены из более поздних сегментов смогут взаимодействовать с большим числом выделенных токенов. Параметры можно подобрать так, чтобы свести сложность к  .
.

Reformer, 2020
В self-attention наибольший вклад для запроса вносят ключи, которые являются наиболее близкими к нему, поэтому предлагается производить вычисления только для близких пар K и V.
Реализуется это с помощью kNN:
обучается общая для ключей и запросов весовая матрица
ключи собираются в LSH-индекс
для запроса ищется ближайший в индексе центроид
внимание для запроса считается только с соседями центроида слева
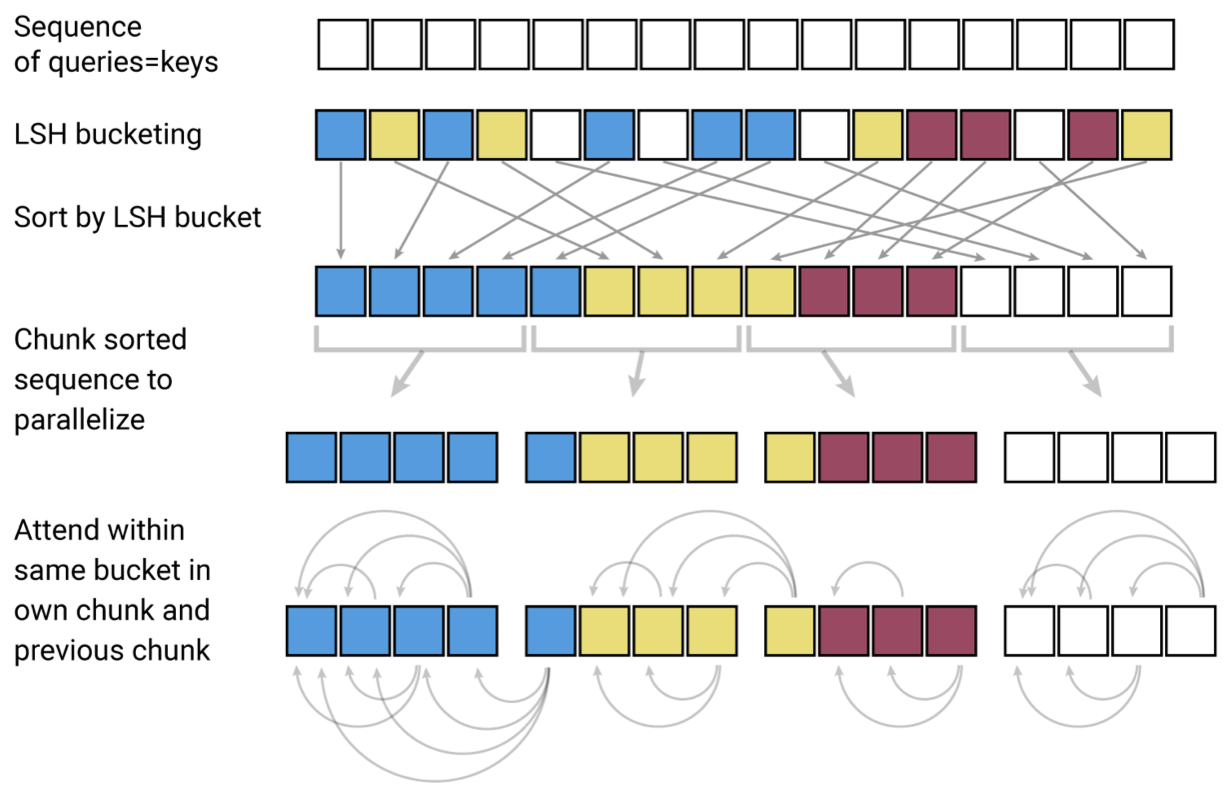
Для экономии памяти за счёт замедления обучения используются RevNet (пересчёт выходов слоя по выходам следующего в backprop) и блочные вычисления на каждом слое. Настройкой модели можно снизить сложность до  , обучаются модели с контекстом до 64К токенов.
, обучаются модели с контекстом до 64К токенов.
Longformer, 2020
Разделение внимания на локальное и глобальное, у каждого свои весовые матрицы. Для глобального self-attention выбирается фиксированный набор токенов (могут быть важные, типа CLS или токенов вопроса для QA), на эти токены могут смотреть все остальные токены, и эти токены могут взаимодействовать со всеми остальными.
В локальном внимании токен может смотреть на N токенов вокруг себя, от слоя к слою захватывая всё более длинные зависимости. При этом N токенов могут быть как ближайшими к текущему обрабатываемому, так и идти с заданным шагом (Dilated Sliding Window, допустимо на верхних слоях). Разные головы self-attention могут иметь шаблоны внимания.
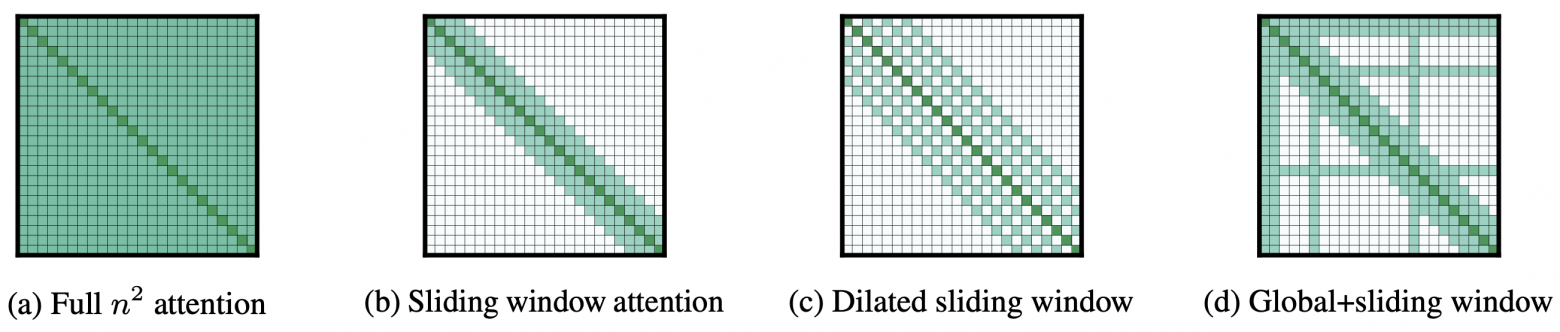
Модели тренируются с относительным позиционным кодированием, n при обучении наращивается от 2К до 23К, тестируется на 32K.
Performer, 2020
Вместо упрощения подсчёта self-attention производится его аппроксимация. За счёт использования специальных ядер получаются новые матрицы K' и Q' с новой небольшой размерностью признаков  . С их помощью которых можно получить схожий результат со сложностью
. С их помощью которых можно получить схожий результат со сложностью  :
:


Модели учатся для разных задач с длиной контекста от 8K до 12K.
Linformer, 2020
Ещё один подход к приближённому вычислению self-attention. Предлагается понижать ранг матриц K и V, что позволяет уменьшить размерность длины последовательности с  до
до  и понизить сложность с
и понизить сложность с  до
до  :
:

Проекция векторов матриц K и V в меньшую размерность k производится с помощью обучаемых линейных слоёв. Модели обучаются для разные задачи с длиной контекста от 8K до 12K.
Big Bird, 2020
Продолжение идей self-attention с разными масками внимания. Предлагается использовать три типа внимания:
локальное в пределах контекста токена
внимание на случайный разреженный набор токенов по всей последовательности
глобальное внимание (как в Longformer)

В применении к модели RoBERTa удалось увеличить размер контекста с 512 до 4096.
LongT5, 2021
Sequence-to-sequence модель на базе Т5 с локальным и глобальным вниманием. Локальное — в пределах контекста токена (127 в каждую сторону).
Глобальное внимание:
вход делится на блоки по 16 токенов
глобальный токен блока равен сумме токенов блока
все токены смотрят на все глобальные токены
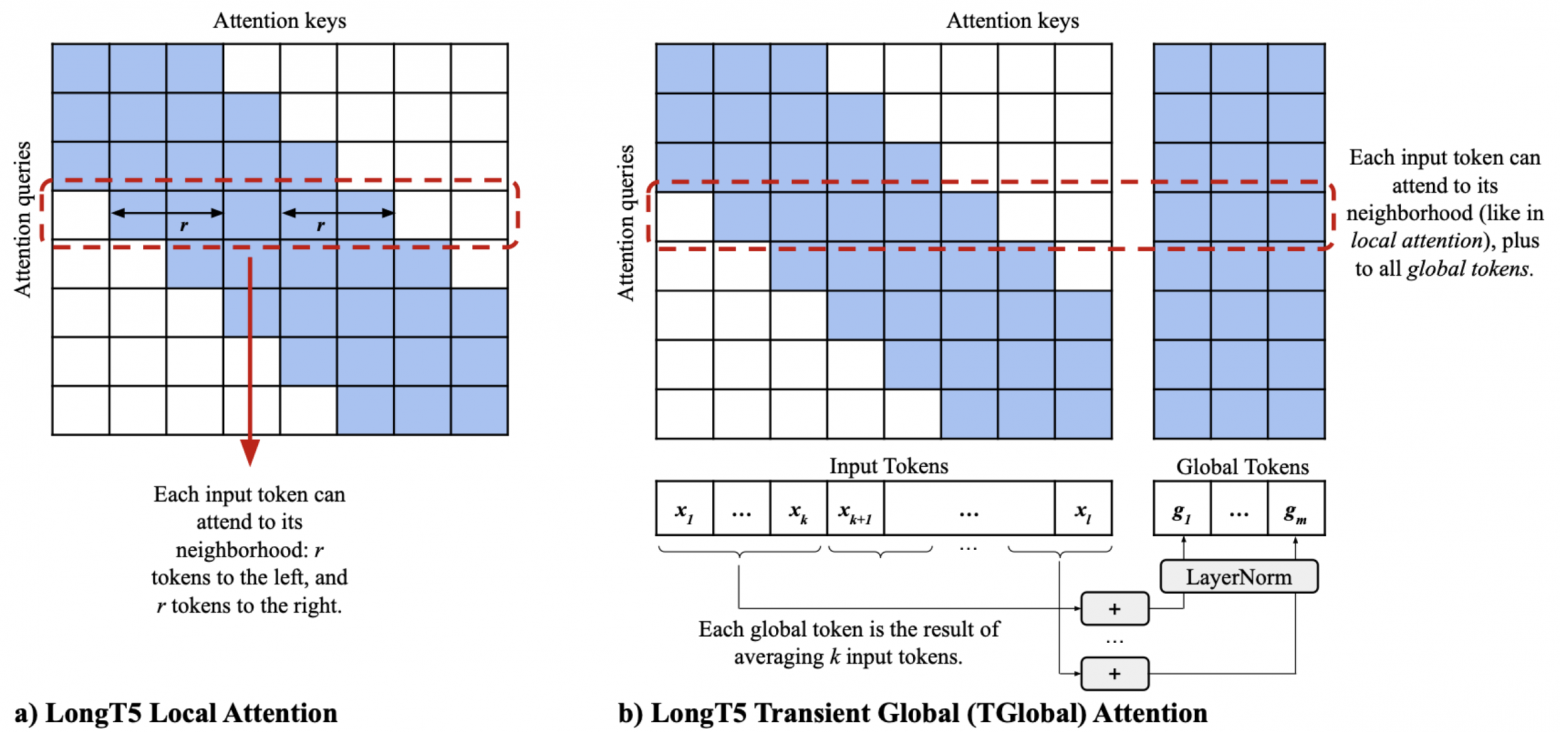
На предобучении n = 4K, на этапе fine-tuning в разных задачах n = 4-47K.
Top Down Transformer, 2022
В основе тоже полный Transformer, предлагается двухуровневая обработка входа для модели суммаризации.
Шаг 1:
локальный self-attention на последовательности (w соседей у каждого токена)
пулинг поверх выходов для получения
 глобальных токенов
глобальных токеновполный self-attention на глобальных токенах
Шаг 2:
на основе выходов локального self-attention получаются Q (их
 штук)
штук)выходы полного self-attention дают K и V (их по
 штук)
штук)self-attention с этими Q, K и V даёт итоговый выход кодировщика

Далее выходы кодировщика идут как обычно в cross-attention в декодировщик. Пулинг может быть усреднением или более сложным и обучаемым. Сложность (опустим  для наглядности) понижается до
для наглядности) понижается до  .
.
Memorizing Transformer, 2022
В основе лежит Transformer-XL с сегментами по 512 токенов. В последнем блоке добавляется слой kNN-augmented attention:
для слоя заводится блок памяти на M пар векторов ключей и значений
текущие K и V self-attention слоя добавляются в конец памяти
на ключах памяти запускается kNN, свой для запроса из текущего Q
self-attention для запроса считается только с ближайшими соседями
Результаты обычного и kNN-augmented внимания складываются с обучаемым весом. Память своя для каждой головы self-attention, если в ней не хватает места, вытесняются наиболее старые пары.
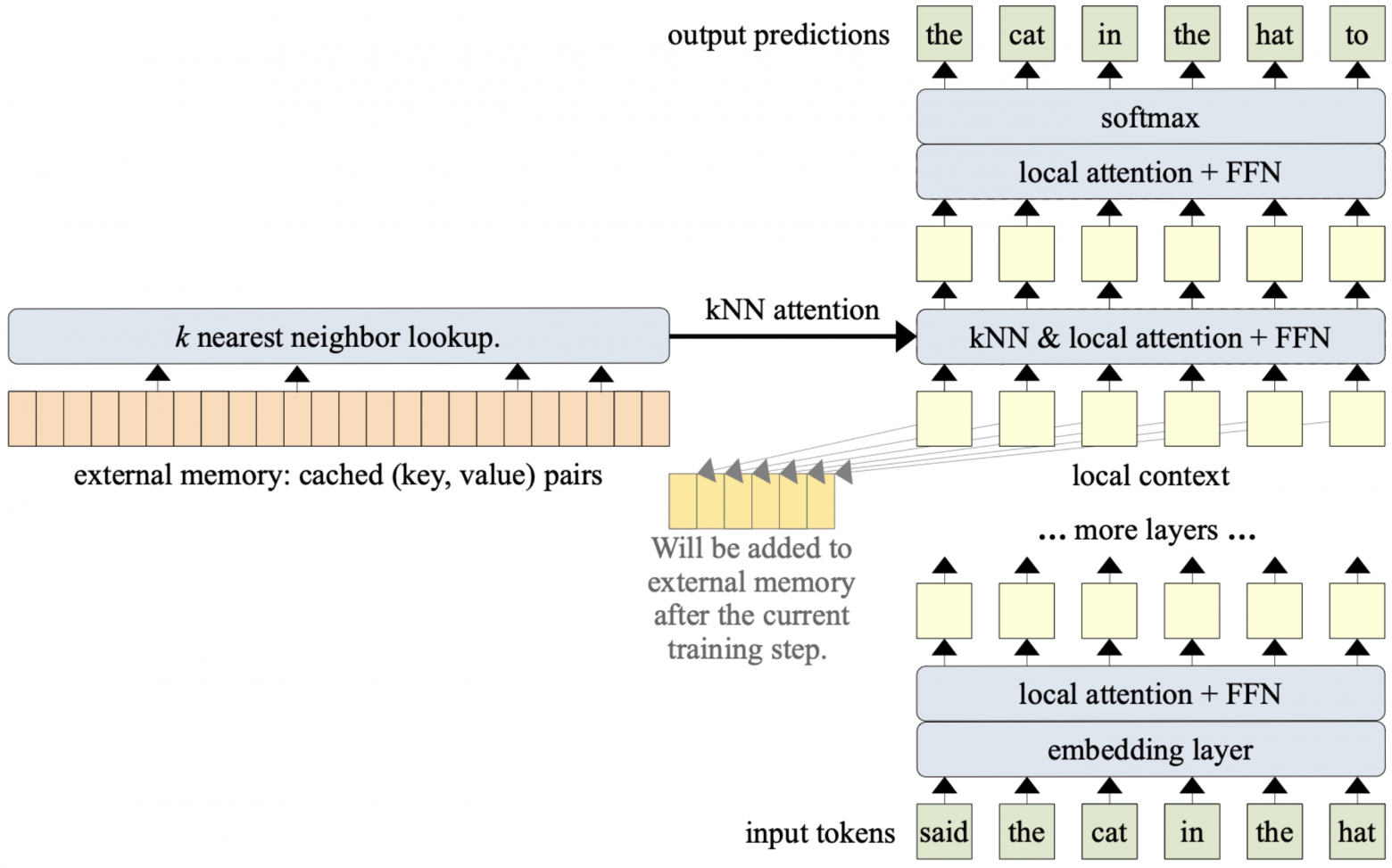
Ценность подхода в том, что его можно применять не только на стадии предобучения, но и при дообучении модели, за счёт чего удаётся быстро достигнуть того же качества, что и при обучении с нуля.
SLED, 2022
В работе предлагается подход по увеличению длины обрабатываемого контекста в sequence-to-sequence моделях на этапе fine-tuning:
вход (16К) нарезается на сегменты с контекстом с обеих сторон (256)
опционально к каждому сегменту добавляется префикс (промпт, вопрос)
каждый сегмент обрабатывается кодировщиком независимо, токены внутри него могут обращать внимание друг на друга, на токены префикса и контекста вокруг
из результатов удаляются лишние токены, закодированная последовательность идёт в cross-attention в декодировщик

FlashAttention, 2022
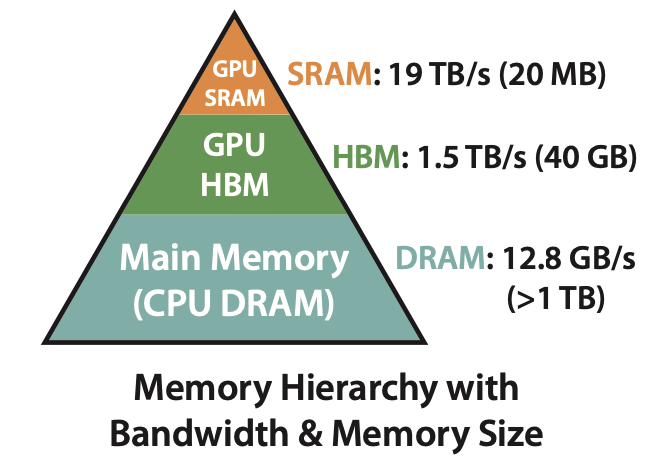
Одна из наиболее успешных работ по оптимизации работы моделей Transformer. Вместо аппроксимации полного подсчёта self-attention можно оптимизировать само его вычисление.
Слева показана иерархия типов памяти при работе с GPU: помимо известных всем DRAM и VRAM (GPU HBM) есть ещё GPU SRAM, представляющая собой аналог кэша в CPU. Это очень маленькая и быстрая память в которой производятся вычисления.
Проблема вычисления self-attention в том, что на каждом его шаге требуется множество пересылок данных между HBM и SRAM, на это тратится значительное время:

Первое нововведение состоит в по-блочном вычислении softmax (Tiling), это возможно при использовании дополнительной памяти O(N) для специальных счётчиков. В этом случае вычисления идут в двух циклах: во внешнем идёт итерация по блокам K и V, во внутреннем — по Q, что позволяет минимизировать количество операций обмена данными между кэшем и основной памятью GPU:

Выполнение многих операций за раз (умножение матриц, вычисление softmax, маскирование, дропаут) позволяет выполнять их одним CUDA ядром (fusing), что тоже значительно ускоряет вычисления.
Второй применяемой техникой в статье является пересчёт промежуточных значений на шаге backward (Recomputation):
для обычного вычисления градиентов требуются промежуточные матрицы размера
 (входы и выходы softmax)
(входы и выходы softmax)их можно не хранить, а вычислять на лету, имея выходы self-attention и дополнительные статистики (считаются при tiling), в статье приводятся полные формулы обратного шага
получается вариация gradient checkpointing, но за счёт уменьшения переноса данных в SRAM она не только экономит память, но ещё и ускоряет подсчёт внимания
Работа стала стандартом в мире обучения и инференса LLM, поскольку внимание вычисляется точно, а не приближённо, и функции из FlashAttention легко подменяют собой оригинальную реализацию. Модификация сразу стала внедряться в разные модели, а её версия 2.0 (2023) с дополнительными вычислительными оптимизациями на GPU вошла в библиотеку transformers. Для крупных моделей FlashAttention даёт и ускорение, и экономию потребления памяти, что позволяет сильно увеличивать число параметров и длину обрабатываемого контекста в рамках тех же вычислительных ресурсов.
Unlimiformer, 2023
Ориентация на полный Transformer, можно использовать как с дообучением, так и без. Вход кодировщика разбивается на сегменты с пересечением, обрабатываемые независимо, в конце контекст удаляется. Результаты всего сохраняются и используются в cross-attention декодировщика с kNN-индесом (как в Memorizing Transformers):
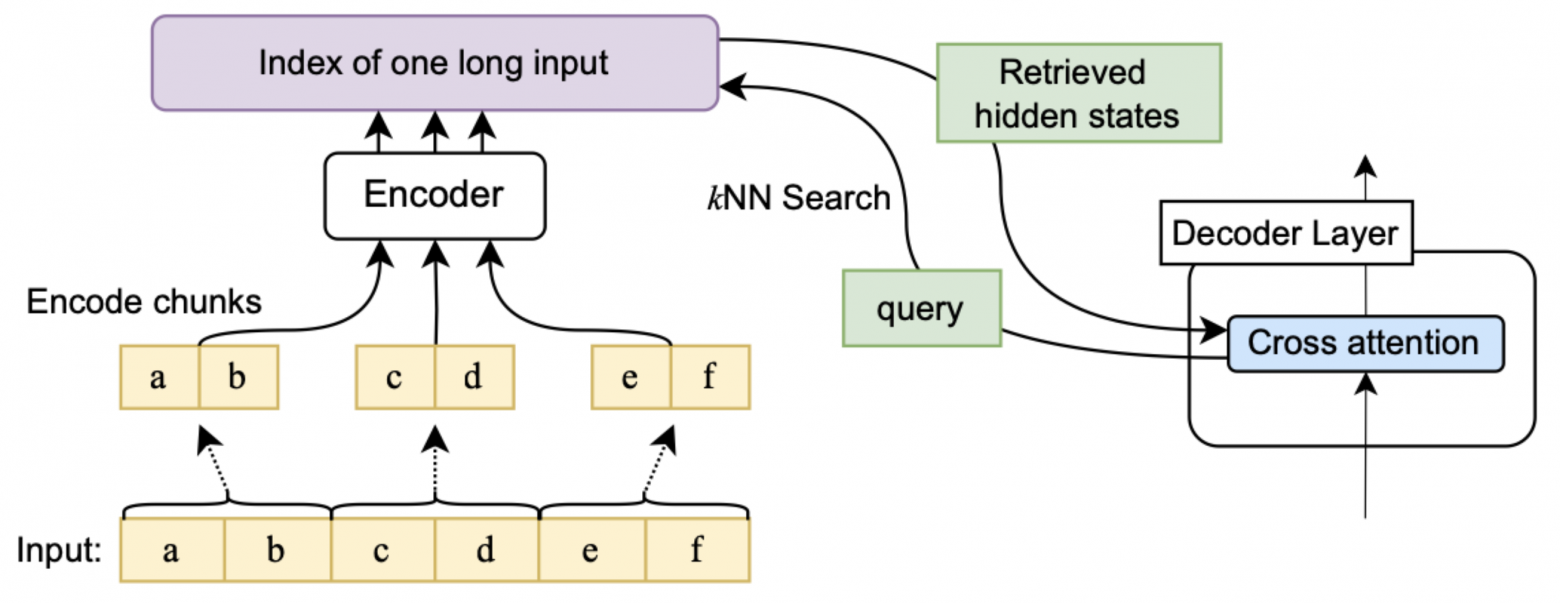
Есть проблема: на каждом слое и в каждой голове нужен свой kNN-индекс, который нужно перестраивать для каждого набора пар ключ-значение. Это очень затратно по памяти и времени, поэтому в Memorizing Transformers модифицированный слой добавляется только в последнем блоке.
Предлагается следующее решение. Переписывается формула подсчёта весов внимания ( и
и  — выходы кодировщика и декодировщика соответственно,
— выходы кодировщика и декодировщика соответственно,  и
и  — матрицы весов внимания):
— матрицы весов внимания):

В поисковый индекс кладутся не ключи, а выходы кодировщика, которые являются общими для всех слоёв. Запросы для kNN-индекса формируются на каждом слое-голове, для извлечённых  несложно считаются значения V.
несложно считаются значения V.
Возможны разные варианты применения Unlimiformer к модели:
fine-tuning модели на задачу с ограниченной длиной сэмплов + Unlimiformer на тесте
то же самое, но с Unlimiformer на валидации для возможности раннего останова и выбора более хорошего чекпойнта
то же самое, но тексты не обрезаются, а нарезаются на сегменты максимальной длины и подаются как отдельные сэмплы
fine-tuning с Unlimiformer с контекстом 8-16K + неограниченный контекст на тесте
то же самое, но при обучении вместо kNN выбираются случайные токены
чередование двух подходов: первый учит, второй выступает регуляризатором и не даёт модели зацикливать своё внимание на топ-k ключах
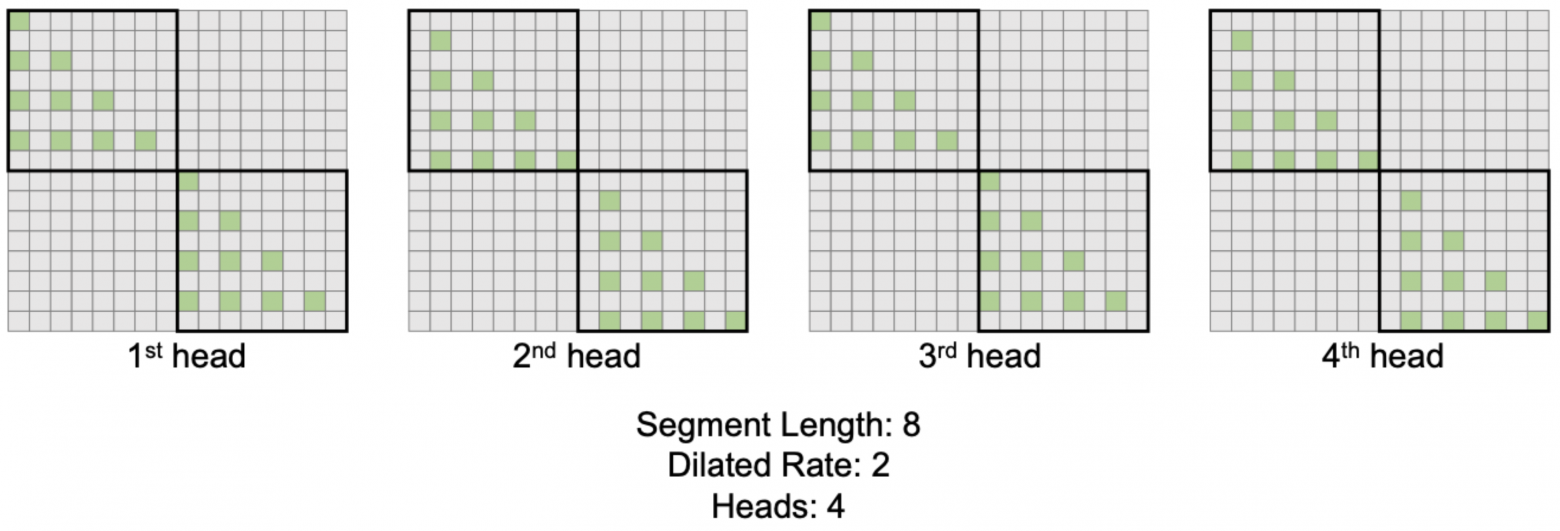
LongNet, 2023
Последовательность разбивается на сегменты длины w, обрабатываемые независимо. Внутри сегмента self-attention считается разреженно (dilated), участвуют только  токенов с индексом
токенов с индексом  :
:
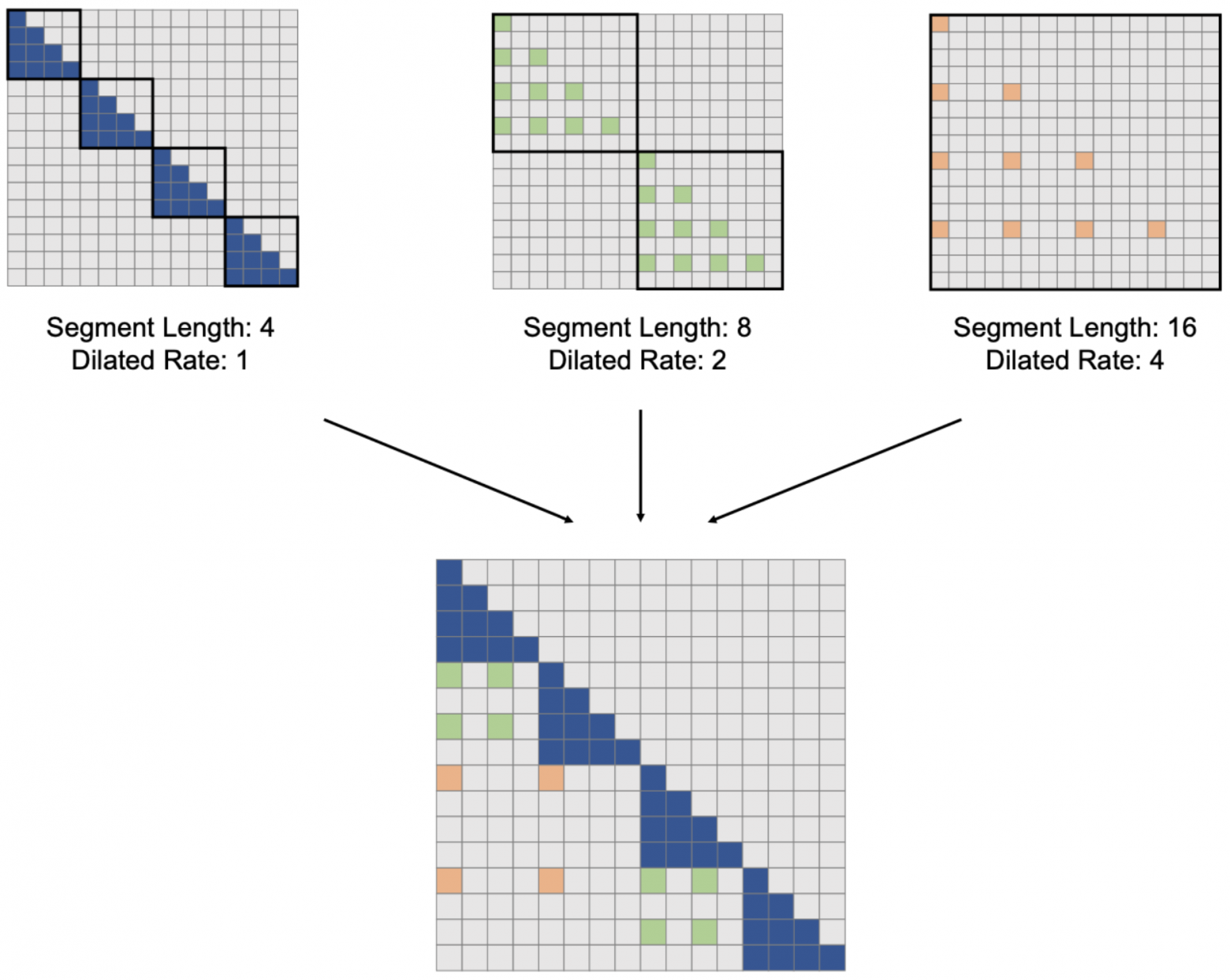
При этом в одной голове несколько подсчётов с разными  , результаты суммируются с весами, пропорциональными их знаменателям softmax. Во всех головах внимания используется один и тот же шаблон маски, и для того, чтобы улавливать различные зависимости, предлагается в каждой голове делать свой сдвиг маски:
, результаты суммируются с весами, пропорциональными их знаменателям softmax. Во всех головах внимания используется один и тот же шаблон маски, и для того, чтобы улавливать различные зависимости, предлагается в каждой голове делать свой сдвиг маски:
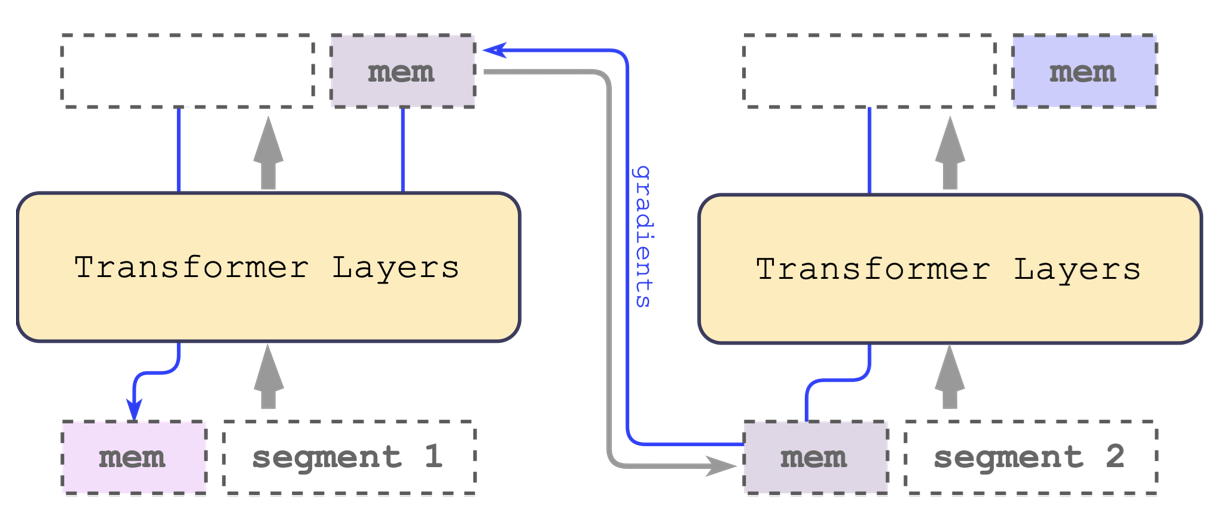
RMT, 2023
Архитектура кодировщика, последовательность разбивается на сегменты, обрабатываемые последовательно. В начало каждой последовательности добавляются  «векторов памяти». Выходные представления векторов памяти сегмента i идут на вход сегменту i+1 (как вектор состояния в RNN). Механизм рекурентности дополняет модель, не требуя архитектурных изменений.
«векторов памяти». Выходные представления векторов памяти сегмента i идут на вход сегменту i+1 (как вектор состояния в RNN). Механизм рекурентности дополняет модель, не требуя архитектурных изменений.
Focused Transformer (LongLLaMA), 2023
Идея схожа с Memorizing Transformers. Вход нарезается на сегменты, обрабатываемые последовательно, на инференсе у модели в части слоёв есть кэши для пар K и V. При подсчёте внимания для запроса q используются и K и V из текущего сегмента, и наиболее близкие пары (по ключу к q) из кэша (можно брать и все пары, это не сильно медленнее и проще в реализации). Кэш с вытеснением, пополняется по мере обработки сегментов.

На обучении описанные кэши не используется, но модель нужно научить смотреть на много пар K и V и уметь выделять нужные. Для этого на обучении заводится свой кэш:
порядок документов в батче фиксированный (сегменты одного документа всегда в той же позиции)
кэш перезаписывается для каждого сегмента и содержит K и V для предыдущего сегмента этого документа
дополнительно в него пишутся дистракторы: ключи и значения предыдущего сегмента
 случайных документов
случайных документовв результате при обработке сегмента документа есть возможность заглядывать в кэш, но нужно учиться вытаскивать из него именно нужные данные
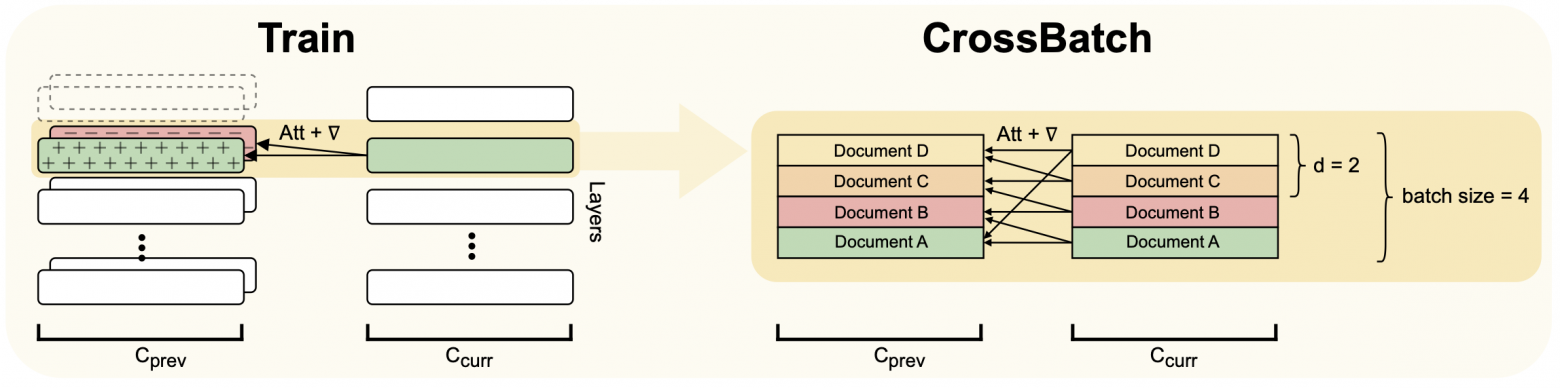
Выбор количества дистракторов имеет значение, предлагается начинать с 2 и постепенно повышать  до 64. Обученная при такой стратегии модель на слое внимания с памятью даёт большие вероятности парам K и V из целевого документа.
до 64. Обученная при такой стратегии модель на слое внимания с памятью даёт большие вероятности парам K и V из целевого документа.
Grouped-Query Attention
Обобщение предложенной ранее идеи MQA (Multi-query attention), в рамках которой self-attention для разных голов рассчитывается со своими векторами Q и с общими векторами K и V. Предлагается Grouped-Query Attention, в котором ключи и значения свои в каждой группе голов внимания:
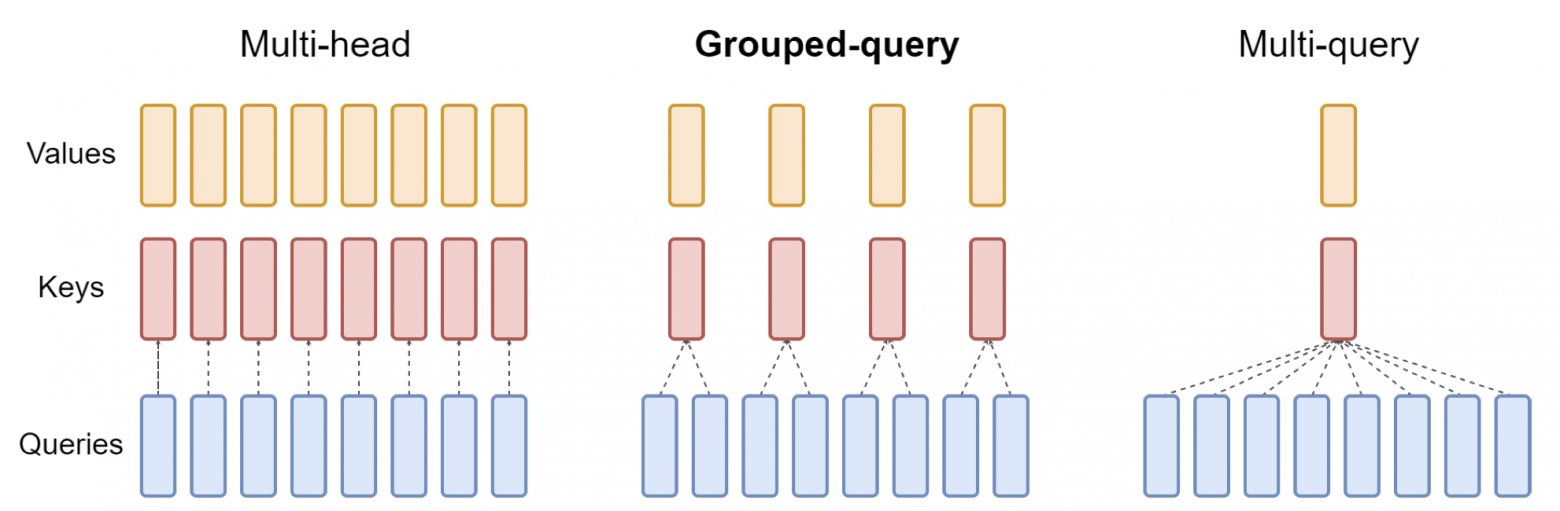
Переход от обученной модели к новому подсчёту делается в два шага: сперва веса конвертируются (в рамках группы голов их матрицы для получения K и V усредняются в одну), затем обновлённая модель дообучается (до  вычислений от предобучения). В результате получается при правильном подборе числа групп и итераций дообучения достичь ускорения при генерации последовательности и сохранить качество почти неизменным (для набора генеративных задач):
вычислений от предобучения). В результате получается при правильном подборе числа групп и итераций дообучения достичь ускорения при генерации последовательности и сохранить качество почти неизменным (для набора генеративных задач):

RetNet (2023)
Инференс моделей с длинным контекстом является отдельной проблемой, которую в работе предлагается решать, заменив блок multi-head self-attention (MHA) на multi-scale retention MSR. С математической и практической точек зрения механизм retention близок к attention, но у него есть важное преимущество: возможность параллельного и рекурентного представления.
Выбор представления определяет способ подсчёта заменителя внимания. В параллельном варианте получается конструкция, схожая с обычным подсчётом self-attention, что даёт возможность эффективно (по сравнению с RNN) учить модели. В рекурентном же представлении модель может эффктивно генерировать тексты без необходимости использовать большой кэш с помощью передаваемого между токенами скрытого состояния (как в RNN). Математические детали retention можно разобрать в оригинальной работе

Оставаясь достаточно эффективным на обучении, RetNet показывает впечатляющие результаты на инференсе:

Qwen (2023)
LLM общего назначения с контекстом 8К, для поддержки которого использует две модификации внимания: LogN-Scaling (масштабирует числовые значения в self-attention для стабилизации внимания при росте длины контекста) и локальное внимание (как в Longfomer). В последнем было отмечено более сильное влияние расширения контекста на нижние слои, поэтому у каждого слоя модели для токенов в self-attention используются окна разного размера: более короткие для первых слоёв, более длинные для последующих. Реализация активно использует FlashAttention.
LongLoRA, 2023
LoRA — популярный метод эффективного дообучения моделей Transformer, использующий низкоранговое разложение обучаемых матриц-добавок к замороженным основным весовым матрицам нейросети. В случае длинного контекста обычная LoRA слабо повышает эффективность дообучения из-за квадратичности внимания. Кроме того, качество такого дообучения с т.з. перплексии оказывается сильно уже нормального fine-tuning. LongLoRA соединяет в себе LoRA и эффективный подсчёт self-attention:
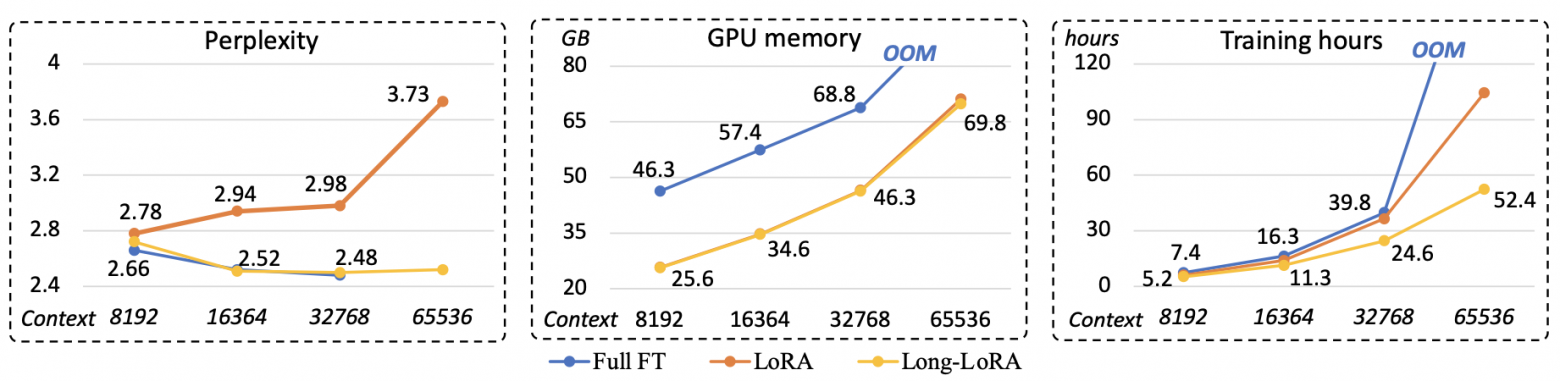
Внимание считается локально внутри заданных окон по двум шаблонам: обычный и сдвинутый на половину окна. Веса внимания дообучаются с помощью LoRA, дополнительно обычным образом дообучаются веса слоёв нормализации и входные эмбеддинги (в большой модели их доля от общего числа параметров невелика).

Новый подсчёт self-attention реализуется так:
Все головы внимания делятся на две части
Выбирается размер окна (группы), во второй половине голов векторы сдвигаются на полгруппы
В каждой группе self-attention считается как обычно (по всем головам)
Результаты для «сдвинутых» голов сдвигаются обратно
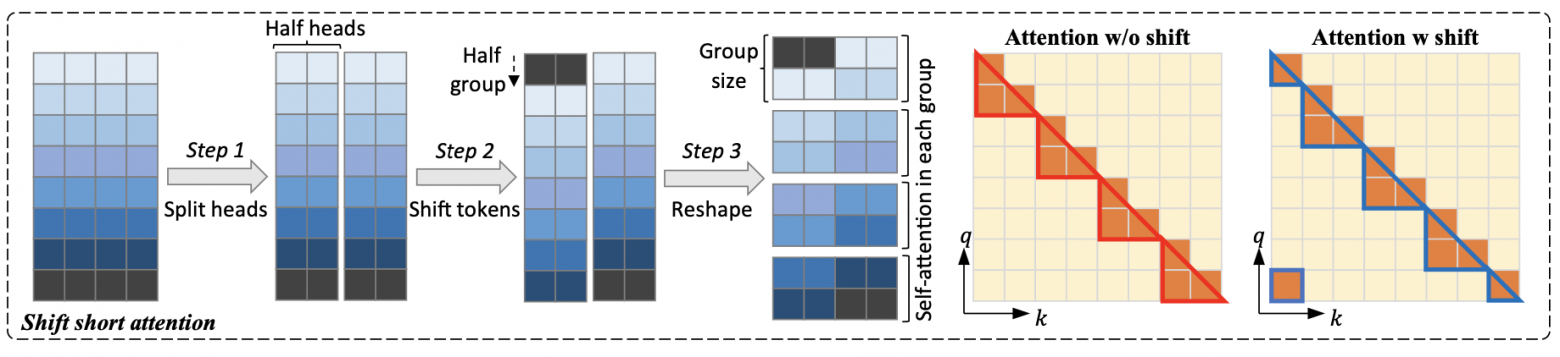
В таком подходе сама схема вычислений не меняется — можно использовать готовые оптимизации (например, Flash Attention).
Mistral (2023)
LLM общего назначения с контекстом до 32К, использующая набор описанных подходов: Grouped-Query Attention, локальное внимание из Longformer (Sliding Window Attention) и FlashAttention (что стандартно для моделей последних месяцев).
Дополнительно используется Rolling Buffer Cache (фиксированный размер окна позволяет при генерации текста вытеснять из кэша декодировщика векторы, оказавшиеся за пределами контекста внимания):

На момент написания статьи Mistral 7B — одна из самых сильный open-source моделей, превосходящая по качеству на многих задачах LLaMA 2 13B.
Заключение
Тема расширения контекста для LLM на подъёме, предлагается много разных идей, наибольшее распространение получают самые простые (локальное внимание) и универсальные, не требующие настройки и не снижающие качество (FlashAttention). С этих подходов и рекомендуется начинать любую работу по серьёзному раширению контекста имеющейся модели с помощью дообучения. Также актуальны исследования, связанные с кэшированием информации из более старой части последовательности, тут ещё большое поле для экспериментов.
Стоит отметить, что в задачах генерации короткого текста по длинному контексту хорошо показывают себя и модели на основе декодировщика Transformer, и полный Transformer. Но если речь идёт о задачах типа суммаризации, то при фиксированных размерах моделей лучше могут справиться именно полные Transformer-ы, что подтверждается интересом именно к этой архитектуре в работах, направленных на увеличение длины последовательности для seq-to-seq.
Спасибо за внимание и успехов!



