
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Совсем недавно мне пришлось разбираться с проблемами перформанса одного веб приложения. В процессе определения источника проблем возникали вопросы "сколько в среднем занимает вызов метода класса X", "как много данных приходит на эндпоинт Y", "как часто происходит flush в Z", и несколько стандартных вопросов при перформанс оптимизациях: "как мы потом узнаем что стало лучше", "насколько стало лучше", "было бы неплохо показать графики для демонстрации" и т.д. Так как некоторая часть работы была спрятана вне API endpoint-ов (background workers) и требовалась более детальная статистика для некоторых компонентов, стандартные средства перформанс мониторинга Application Insights не полностью покрывали все нужды. Для поиска ответов был необходим дополнительный набор инструментов мониторинга и после небольшого исследования были выбраны NET event counters в связке с уже применяемым на проекте Application Insights.
В этой статье я хочу финализировать все полученные знания об этом инструменте, о его конфигурации для Azure + Application Insights, а также порассуждать о том где и в каких сценариях этот инструмент применим. Статья может быть интересна всем NET разработчикам как общий обзор данной технологии, короткий гайд по ее конфигурации и обзор списка возможных сценариев ее применения.
Вступление. Что такое event counters?
"Event counters" это набор инструментов, которые позволяют публиковать данные мониторинга работающего приложения через стандартизированное API, чтобы различные обработчики могли потреблять эти данные в режиме реального времени. Обработчики могут потреблять эти данные как и изнутри приложения (с помощью класса EventListener) так и извне рабочего процесса (через EventPipe). Это API появилось в NET Core 3.0 и является кросплатформенным, что означает что использование этого инструмента не ограничено операционной системой (а только наличием соответствующего инструментария для считывания данных). Также "event counters" позиционируются как инструмент с минимальными накладными расходами на производительность.
Суть работы "event counters" (далее просто "каунтеры") предельно проста:
Приложение создает и обновляет обьект каунтера. Обьект в это время накапливает и вычисляет статистические данные за определенный интервал (минимальное значение, среднее значение, максимальное значение)
Через обозначенные интервалы обьект публикует min-avg-max значения через стандартизированное API
Данные потребляются внутри (in-proc) и/или вне (out-of-proc) приложения обработчиками

Как каунтеры выглядят в коде ?
Вот основные действующие классы:
EventSource- это класс аггрегатор каунтеров. Имеет уникальный идентификатор, указываемый через атрибут.EventCounter/PollingCounter- классы каунтеров. Именно они собирают данные. Также имеют свои уникальные (в рамкахEventSource) идентификаторы.
Реализация EventSource:
using System.Diagnostics.Tracing;
namespace TestApplication.Monitoring
{
[EventSource(Name = "TestApplication.Tracing.Monitoring")] // <- unique
internal class WorkerEventSource : EventSource
{
public static readonly WorkerEventSource Log = new WorkerEventSource(); // <- entrypoint for using counters in application
private long _workInProgressItems = 0;
private EventCounter? _processingTimeCounter;
private PollingCounter? _workInProgressCounter;
private WorkerEventSource() { }
public void WorkItemAdded()
{
Interlocked.Increment(ref _workInProgressItems);
}
public void WorkItemCompleted(long elapsedMilliseconds)
{
_processingTimeCounter?.WriteMetric(elapsedMilliseconds);
Interlocked.Decrement(ref _workInProgressItems);
}
protected override void OnEventCommand(EventCommandEventArgs command)
{
if (command.Command == EventCommand.Enable)
{
_processingTimeCounter ??= new EventCounter("unit-processing-time", this)
{
DisplayName = "Unit of work processing time",
DisplayUnits = "milliseconds"
};
_workInProgressCounter ??= new PollingCounter("worker-queue-length", this, () => Volatile.Read(ref _workInProgressItems))
{
DisplayName = "Worker queue length",
DisplayUnits = "items"
};
}
}
protected override void Dispose(bool disposing)
{
_processingTimeCounter?.Dispose();
_processingTimeCounter = null;
_workInProgressCounter?.Dispose();
_workInProgressCounter = null;
base.Dispose(disposing);
}
}
}Давайте рассмотрим пример более подробно. Класс наследует System.Diagnostics.Tracing.EventSource и имеет атрибут [EventSource(Name="...")], который содержит уникальный идентификатор этого источника данных.
[EventSource(Name = "TestApplication.Tracing.WorkerEventSource")] // <- unique
internal class WorkerEventSource : EventSourceКласс источник содержит набор приватных полей-каунтеров и методы, предназначеные для обновления данных каунтеров.
private EventCounter _processingTimeCounter;
...
public void WorkItemCompleted(long elapsedMilliseconds)
{
_processingTimeCounter?.WriteMetric(elapsedMilliseconds);
}Существует четыре класса каунтеров, которые можно разделить на две категории. Первая категория (EventCounter, IncrementingEventCounter) это каунтеры, которые вычисляют статистику основываясь на переданных им значениях. Это категория каунтеров подходит для общей "оценки" значений. В нашем примере это EventCounter _processingTimeCounter, который собирает статистику по времени выполнения метода, вычисляет min-avg-max значения за интервал и публикует. Вторая категория (PollingCounter, IncrementingPollingCounter) это каунтеры, которые возвращают значения с помощью метода обратного вызова, который обычно читает значения из переменной-счетчика. Например: количество потоков в очереди, количество элементов в кэшэ, количество запросов в обработке и т.д. В нашем примере это PollingCounter _workInProgressCounter, который считает количество записей в обработке из обновляемой вручную переменной. Метод обратного вызова указывается при регистрации:
_workInProgressCounter ??= new PollingCounter("worker-queue-length", this, () => Volatile.Read(ref _workInProgressItems))Важно отметить что класс источник должен существовать в единственном экземпляре (singletone). Из этого следуют две вещи. Первая - статическое поле с экземпляром и приватный конструктор.
public static readonly WorkerEventSource Log = new WorkerEventSource(); // <- entrypoint for using counters in application
...
private WorkerEventSource() { }Вторая - хоть код класса источника обычно предельно прост, в некоторых случаях вам придется подумать о потокобезопасности. Самый распространенный сценарий это использование переменной-счетчика. В этом случае все операции записи и чтения должны быть потокобезопасны.
public void WorkItemAdded()
{
Interlocked.Increment(ref _workInProgressItems);
}
...
public void WorkItemCompleted(long elapsedMilliseconds)
{
Interlocked.Decrement(ref _workInProgressItems);
}Для передачи данных в каунтеры достаточно вызвать публичный метод экземпляра класса источника.
Схематичный пример реализации класса, генерирующего статистику:
public class WorkerManager
{
private static WorkerEventSource Log = WorkerEventSource.Log;
...
private void DoWork()
{
Log.WorkItemAdded();
var stopWatch = new Stopwatch();
stopWatch.Start();
...
stopWatch.Stop();
Log.WorkItemCompleted(stopWatch.ElapsedMilliseconds);
}
}Чтение значений каунтеров
Когда с определением каунтеров, схемой их работы и используемыми классами мы разобрались, можем переходить к нашему тестовому приложению (ссылка кликабельна и ведет на GitHub) для проверки на практике. В качестве иллюстрации будет выступать небольшое веб приложение.
Для начала проверим что приложение запускается и попробуем прочитать данные из каунтеров используя dotnet-counters, консольный инструмент для out-of-proc мониторинга. Сначала предлагаю ознакомиться с каунтерами, которые публикуются средой NET по умолчанию. Для этого запустим приложение из Visual Studio, затем с помощью команды dotnet-counters ps находим наш процесс и подключаемя к нему используя следующую команду, не указывая дополнительных параметров кроме идентификатора процесса:
dotnet-counters monitor --process-id <our process id>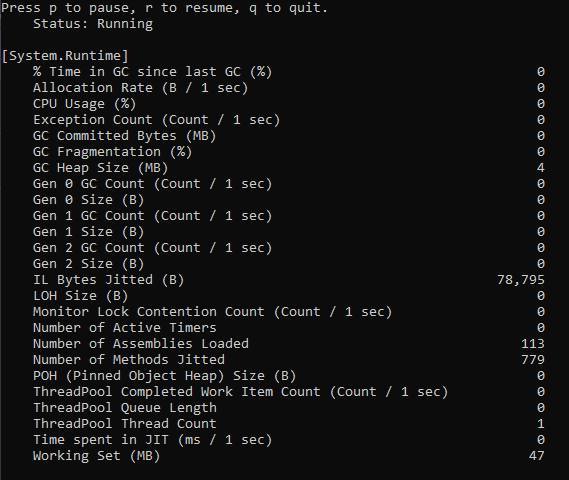
Как мы можем видеть, приложение выводит очень много значений разных каунтеров. NET и ASP NET Core по умолчанию включают в себя множество полезных каунтеров, позволяющих мониторить общее состояние системы, работу GC, нагрузку памяти, процессора, состояние пула потоков, показатели выполнения ASP NET запросов. С полным списком доступных по умолчанию каунтеров можно ознакомится по этой ссылке. Также можно подсмотреть как именно реализованы каунтеры самими Microsoft. Для этого можно изучить следующие классы в исходных кодах NET, например тут и тут.
Чтобы убедиться что добавленные нами каунтеры работают, необходимо отфильтровать каунтеры используя --counters параметр и выполнить несколько запросов через Swagger, чтобы убедится что данные собираются:
dotnet-counters monitor --process-id <our process id> --counters TestApplication.Tracing.Monitoring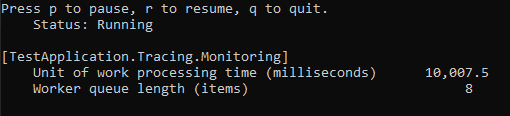
Все отлично работает, поэтому можно приступать к следующей части нашей статьи.
Конфигурация каунтеров с Azure Application Insights
Чтобы добавить Application Insights в ваше веб приложение достаточно одной строчки в конфигурации и наличие настроенного Application Insights ресурса в Azure. Но для того чтобы настроить каунтеры, Application Insights требуется дополнительная конфигурация. Нужно сконфигурировать EventCounterCollectionModule и вручную указать каунтеры, значения которых вы бы хотели отправлять в Azure. Для нашего демонстрационного примера нам понадобятся не только каунтеры реализованные в нашем приложении, но и некоторые каунтеры доступные по умолчанию. Поверьте, их важность сложно переоценить, что мы продемонстрируем далее в этой статье. Вот код метода ConfigureServices в Startup.cs (или Program.cs, если вы уже работаете с NET 6):
void ConfigureServices(IServiceCollection services)
{
...
// add application insights into DI
services.AddApplicationInsightsTelemetry();
// configure module for collecting event counters data
services.ConfigureTelemetryModule<EventCounterCollectionModule>(
(module, o) =>
{
// This removes all default counters, if any.
module.Counters.Clear();
// common NET and ASP NET application counters
...
module.Counters.Add(
// record format "EventSource Name", "event counter identifier"
new EventCounterCollectionRequest("System.Runtime", "threadpool-thread-count"));
module.Counters.Add(
new EventCounterCollectionRequest("System.Runtime", "threadpool-queue-length"));
...
module.Counters.Add(
new EventCounterCollectionRequest("Microsoft.AspNetCore.Hosting", "requests-per-second"));
module.Counters.Add(
new EventCounterCollectionRequest("Microsoft.AspNetCore.Hosting", "current-requests"));
module.Counters.Add(
new EventCounterCollectionRequest("Microsoft.AspNetCore.Hosting", "failed-requests"));
// custom application counters
module.Counters.Add(
new EventCounterCollectionRequest("TestApplication.Tracing.Monitoring", "unit-processing-time"));
module.Counters.Add(
new EventCounterCollectionRequest("TestApplication.Tracing.Monitoring", "worker-queue-length"));
}
);
}Осталось только добавить Application Insights ключ в appsettings.json.
{
"ApplicationInsights": {
"InstrumentationKey": "**********" // <- put your key here
}
}Запускаем приложение и генерируем несколько запросов с помощью Swagger, чтобы отправить начальные данные в Application Insights.
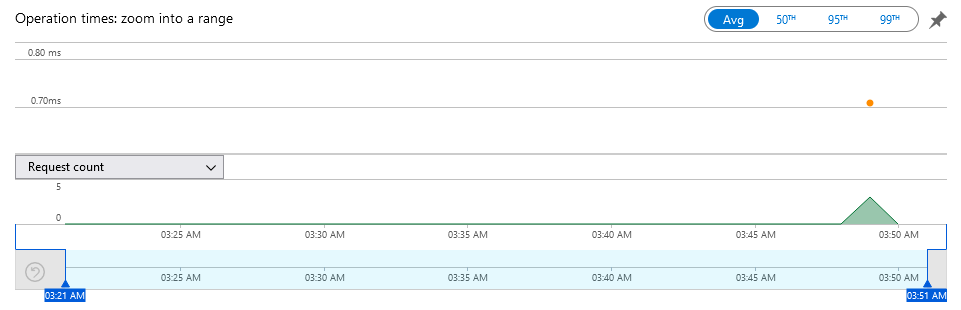
Работает! Переходим к самому интересному.
Демонстрация применения каунтеров
Идея веб приложения следующая: API имеет единственный POST метод, который запускает некую обработку в другом потоке (worker) и не дожидаясь окончания обработки (Task.Run(() => ...)) возвращает клиенту результат 200. В первоначальном варианте обработка будет использовать блокирующий вызов Thread.Sleep(10 000) и при определенном количестве запросов обработка будет опосредовано влиять на наш API метод, ухудшая пропускную способность. Таким образом мы сможем рассмотреть случай, когда источник проблем в обработке запросов будет сложно обнаружить стандартными средствами мониторинга Azure Application Insights, так как проблемы в работе worker-а нельзя будет напрямую увидеть в статистике HTTP запросов и в трэйсах вызова API метода. После мы изменим имплементацию на асинхронную и наглядно рассмотрим как это отобразилось на метриках и насколько улучшило пропускную способность API метода. Для создания нагрузки и оценки пропускной способности мы будем использовать jMeter с подготовленной заранее конфигурацией (файл POST Work Item.jmx в корне репозитория).
Запустим приложение, проведем стресс-тестирование с помощью jMeter и проанализируем полученные результаты.


Сценарий jMeter для не оптимальной имплементации выполнялся 7:06 минут со средней пропускной способностью 5.9 запросов в секунду. На графике среднего времени выполнения запроса в Application Insights (доступен через вкладку Overview Application Insights ресурса) вначале мы видим пик (несмотря на то что потоки в jMeter добавлялись постепенно на протяжении 30 секунд), после следует пик в середине и за ним следует еще один пик, который просто не успел сформироватся до окончания стресс-теста. Разработчик, столкнувшийся с такими показателями для настолько простого запроса может очень удивиться. "Как так, запрос же совсем ничего не делает, а график показывает какие то пики и спады. Очень странно". Конечно, среднестатистический API метод скорее всего будет выглядеть сложнее и будет иметь как минимум несколько зависимостей, но от возникновения подобной странной и сложно обьяснимой картины никто не застрахован, с чем мне и пришлось столкнутся. Первой моей мыслью тогда было:
Ничего не понятно, нужно больше данных
Теперь добавляем каунтеры! Давайте посмотрим на значения каунтеров, доступных в виде графиков во вкладке Monitoring -> Metrics Application Insights ресурса. Стоит отметить что на одно окно можно добавлять графики нескольких каунтеров, что позволит вам легко выявить корреляцию. Мы сразу выберем нужные нам метрики, а именно метрики отображающие состояние пула потоков (количество потоков в очереди, размер пула потоков) и размер очереди выполнения (метрику, добавленную в нашем приложении), но не стоит считать это жульничеством. Ведь при наличии такого удобного инструмента на проверку нескольких гипотез и выделение нужных метрик у разработчика уйдет значительно меньше времени чем без него.
Обозначения:
светло синий - очередь пула потоков (System.Runtime|ThreadPool Queue Length)
желтый - количество потоков в пуле (System.Runtime|ThreadPool Thread Count)
темно синий - размер очереди выполнения (TestApplication.Tracing.Monitoring|Worker queue length)

Сопоставив графики мы можем с большой точностью определить что же произошло. Получая все больше запросов на обработку, текущего размера пула потоков становится недостаточно, что ведет к скоплению потоков в очереди. Обработка запроса при этом замедляется, что видно на графике среднего времени выполнения в виде пика. После пулл потоков расширяется, потоков становится больше, очередь пула потоков одновременно с этим уменьшается и обработка запроса становится снова быстрой, пока в системе хватает потоков. Далее, так как мы заполняем очередь обработки быстрее чем успеваем ее освобождать, ситуация вновь повторяется в виде пика. При этом на графике хорошо видно что рост количества потоков в пуле коррелирует с ростом очереди обработки.
Bingo! Виновник найден и его необходимо починить. Меняем имплементацию на не блокирующий вызов Task.Delay(10 000), меняя вызов метода на DoWorkAsync и повторяем наш стресс тест.


В результате правильных изменений в коде, который напрямую не относится к API методу, нам удалось добится средней пропускной способности в 84.5 запроса в секунду, а сценарий jMeter на 2500 запросов завершился всего за 29 секунд. Иногда хорошо продуманные и предсказуемые изменения могут давать позитивный эффект, но не за счет механизмов на которые вы изначально расчитывали, или еще хуже - создавать неожиданные побочные эффекты. Чтобы окончательно убедиться что мы сделали именно то что собирались, нам нужно подтвердить или опровергнуть нашу изначальную гипотезу. Обратимся к метрикам.
Обозначения:
светло синий - очередь пула потоков (System.Runtime|ThreadPool Queue Length)
желтый - количество потоков в пуле (System.Runtime|ThreadPool Thread Count)
темно синий - размер очереди выполнения (TestApplication.Tracing.Monitoring|Worker queue length)

Как видим количество потоков в очереди за время выполнения минимально а количество рабочих потоков в пуле не превышает 25. К сожалению в выборку не попали значения размера очереди выполнения, так как тест окончился слишком быстро и значения не попали в интервал. Чтобы результаты были более наглядными, мы можем увеличить время тестирования одновременно увеличив нагрузку на приложение. Для этого в jMeter увеличим число потоков до 100, а число итераций до 500.
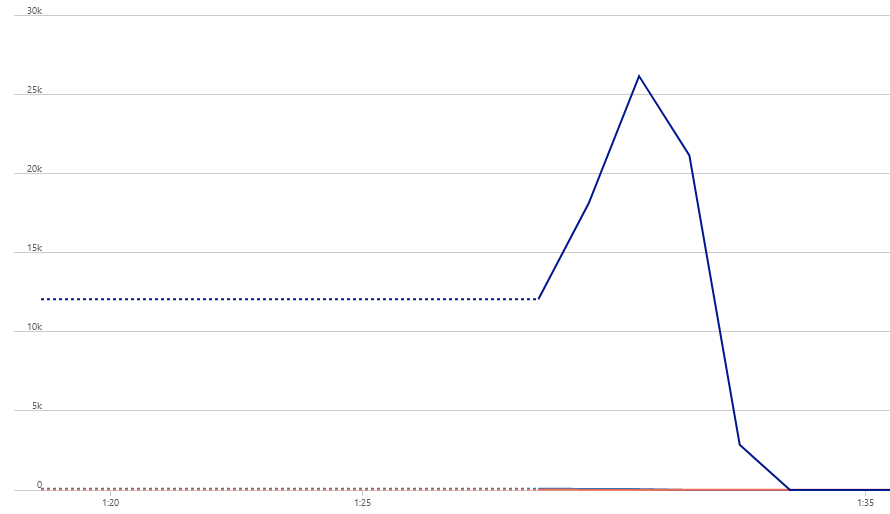
Результаты, на мой взгляд, выглядят более чем убедительно. Размер очереди пула потоков и общее количество потоков больше не корелирует с количеством элементов в очереди выполнения и на протяжении всего теста остается стабильно низким. Гипотеза подтверждена и мы можем быть спокойны что решили проблему именно так, как планировали.
Варианты и способы применения каунтеров
Каунтеры, как мы с вами могли убедиться, это легко добавляемый и лекго конфигурируемый кросс-платформенный инструмент для сбора статистики в рельном времени, который минимально влияет на производительность вашей системы. В связке с Azure Application Insights вы можете интегрировать данные в вашу Azure экосистему, извлекать их, строить графики с помощью вкладки Monitoring -> Metrics или составлять более сложные запросы с помощью Azure Monitor, находить корреляции, оценивать эволюцию вашей системы или отдельно взятого компонента за определенный период времени. Каунтеры доступные по умолчанию в NET и ASP NET это полезный источник дополнительной информации при поиске проблем в производительности вашего веб приложения. Каунтерам можно найти множество применений, среди которых, на мой взгляд, можно выделить следующие:
Сбор статистики для критически важных компонентов вашей системы, оценка производительности отдельных программных компонентов, сервисов, классов или middleware
Публикация статистики для библиотек написанных на C#, SDK и API клиентов
Сбор бизнес статистики о наиболее часто используемых функциях
Вместо выводов
Во время решения проектной задачи, у меня возникла необходимость получить больше данных о конкретных компонентах и частях системы, а также больше данных о работе системы в целом, в частности о пуле потоков, работе процессора и памяти. В результате небольшого поиска необходимых инструментов я остановился на каунтерах. Данные полученные из каунтеров а также удобная визуализация в Azure в итоге помогли мне решить поставленную задачу с просадками производительности а также отлично дополнили данные о системе, которые мы теперь получаем. Мы добавили множество каунтеров для важных компонентов нашего приложения с целью сбора данных о производительности, зная что скоро они нам понадобятся и мы сможем наглядно оценить будут ли дальнейшие оптимизации успешными. Я рад что смог пополнить свой инструментарий таким инструментом как event counters и буду пользоватmся им и дальше не только в рабочих проектах, но и обязательно буду добавлять их в свои пет проекты.
Существуют и другие инструменты и подходы для решения похожих проблем. Я не могу утверждать что выбранные мной являлись наилучшими, но они помогли мне в решении конкретной задачи. Мне было бы очень интересно почитать о том какие инструменты и подходы вы обычно применяете для решения проблем мониторинга системы, сбора статистики и отслеживания перформанс показателей. Надеюсь моя статья была вам полезна.
Спасибо за внимание!


