

Долго колебался мыслями о необходимости написания этой статьи, но все таки решился. Интерес к красивым дашбордам победил лень и отсутствие мотивации к слишком мудреным реализациям мониторинга такого типа (для микросервисных систем). Плюс накопилось желание поскорее все выложить, после полученных впечатлений в процессе изучения, но тут конечно необходимо чтобы это было понятно всем, поэтому постараюсь сдержать свои эмоции) и описать это более детально.
Былой опыт
Ранее несколько лет назад был 5 летний опыт работы с СУБД Oracle в среде RISC-овой архитектуры на базе IBM, c их очень хорошей юникс подобной ОС AIX c своим прекрасным инструментом smitty, и все это еще разворачивалось на аппаратной виртуализации PowerVM, где можно настраивать балансировку на базе двух VIOS и т.д.

За всем этим набором как-то надо было следить, особенно за БД, и у всех этих программ были свои средства мониторинга, но вдохновлял меня на тот момент самый красивый и имеющий дашборды для всех этих компонентов, инструмент под названием spotlight от компании Quest.

Дашборд Spotlight
Прошло время пришлось работать с другими технологиями, как и многие попал в течение тенденций в сторону открытого ПО, где проприетарный spotlight конечно не очень котируется. Избалованный всякими простыми, платными удобностями, сквозь негативные эмоции, пользовался средствами от разработчиков свободного ПО и иногда ностальгировал по spotlight. Например Zabbix как-то не особо привлекал к себе внимание, но как только услышал про Grafana с Prometheus, само название меня уже заинтересовало, а когда увидел дашборды то, вспомнил про Spotlight. Хотя наверно и в Zabbix можно добиться такого же эффекта или даже использовать его через тот же Grafana, но изначально как я понял без особой персонализации красивых дашбордов там нет, с таким же наборов возможностей, впрочем как и в простом Prometheus.
Соблазнительно-таинственный grafana+prometheus
Конечно главнее всего полезность мониторинга, а не его красота, но для админа и инженеров всяких кластерных систем это все рано или поздно становится рутиной, и хочется тоже как-то чувствовать современный приятный дизайн, превращая эту рутину в интересную красивую игру. Чем больше я узнавал про Grafana плюс Prometheus, тем больше меня это привлекало, особенно своими названиями, красивыми дашбордами с графиками, бесплатностью, и даже не смотря на весь на мой взгляд геморой, в реализации этой связки со ложными системами на микросервисной архитектуре, с которым мне пришлось столкнутся.

Но кто работает с открытым ПО для них эти трудности привычное дело, и они даже получают удовольствие от этого садомазохизма, где даже самые простые вещи необходимо делать самому, своими ручками. Что противоречит например таким понятиям как: клиент недолжен парится, что там скрывается под капотом, главное простота, удобство, предоставляющие надежность, быстрый оперативный результат при выполнении задач клиента и т.д. Поэтому дальнейшее описание интеграции у меня язык не поворачивается назвать удобной и простой, а красота как говорится требует жертв, но для неизбалованных любителей linux это все просто как два пальца об асфальт)

На самом деле для Grafana и Prometheus уже есть много разработанных готовых дашбордов и экспортеров метрик от различных систем, что делает его простым и удобным для использования, но когда идет речь о чем-то своеобразном то, необходимо немного заморачиваться и хорошо если разработчики постарались, написали метрики к своим сервисам, а бывает что приходится самому варганить эти метрики. Тогда уже может невольно прийти желание использовать другие средства мониторинга, например как в Росплатформе если недостаточно встроенных предлагается Zabbix, это лучше чем возится с разработкой метрик каждого сервиса под Prometheus.
Мониторинг Росплатформы
В Росплатформе конечно есть еще и свои встроенные средства мониторинга, например в веб UI для SDS vstorage или для гипервизора с виртуальными средами или для таких сервисов на экспорт как s3, iscsi.
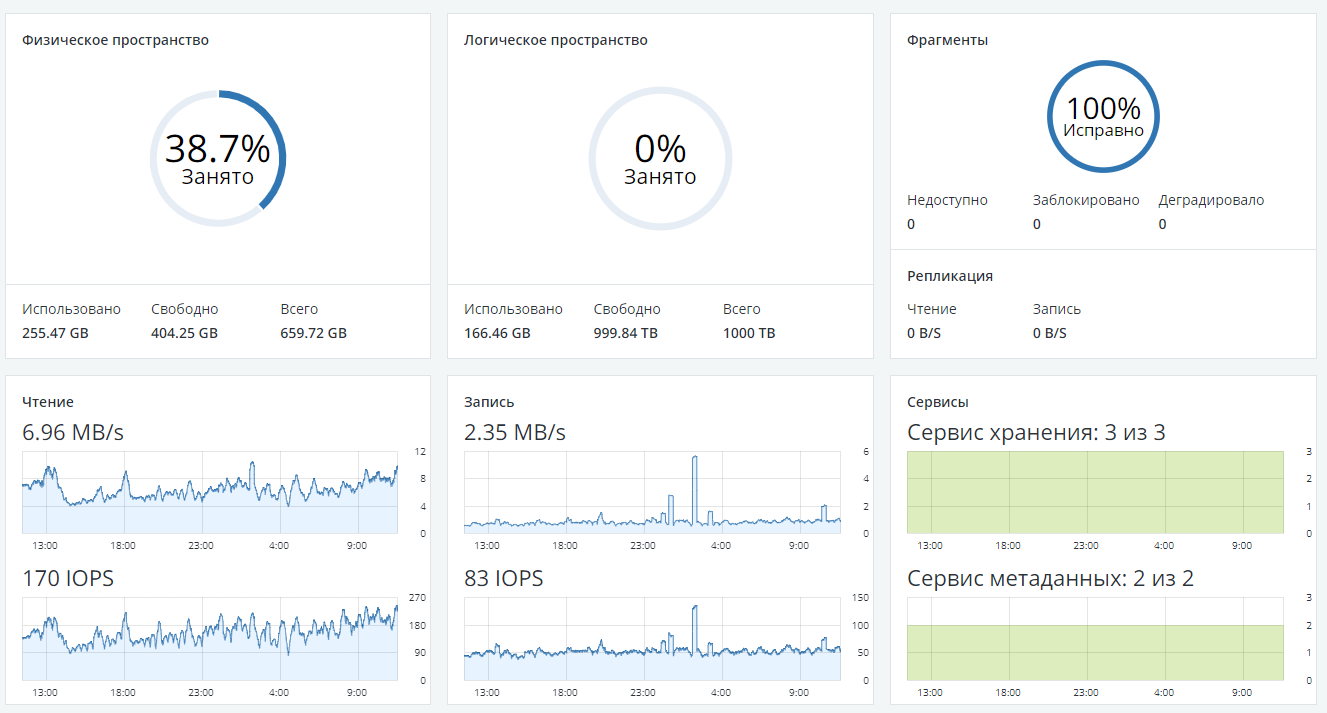
Главный дашборд SDS-а(Р-хранилище) Росплатформы

Дашборд одной из нод кластера Росплатформы(в Р-хранилище)
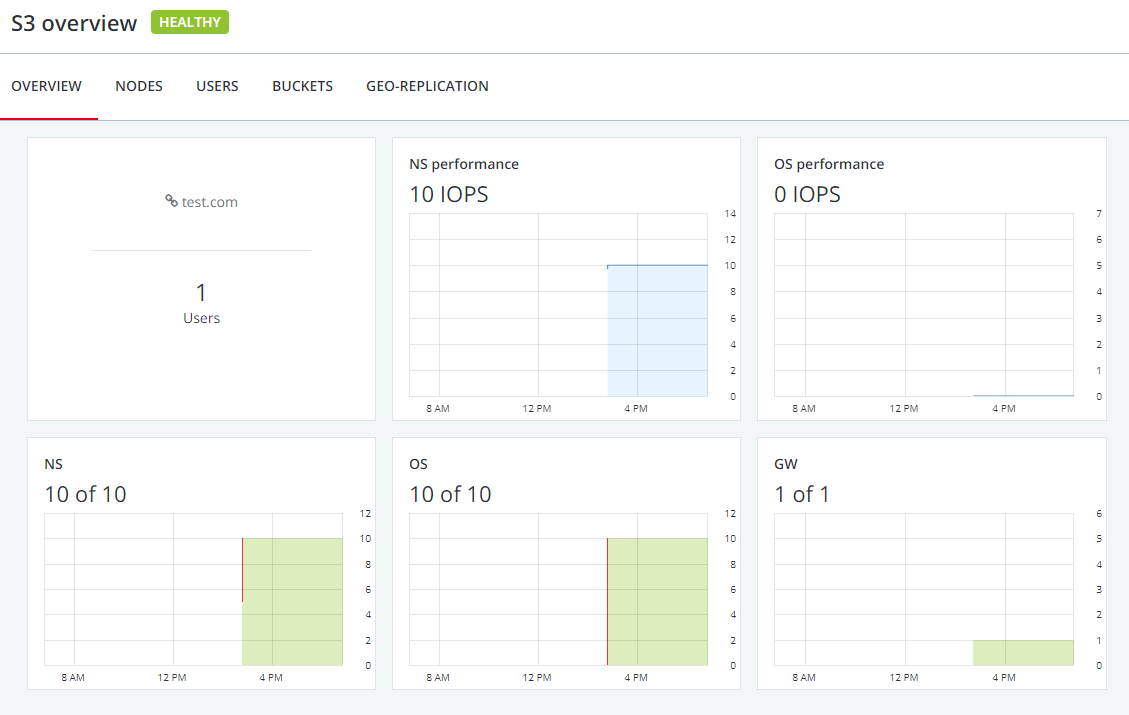
Дашборд Росплатфомы для s3 в Р-хранилище

Мониторинг виртуальной машины Росплатформы(В Р-управлении виртуализации)
Есть даже CLI мониторинг SDS(Р-хранилища) – сердце Росплатформы #vstorage –c имякластера top

Мониторинг SDS(Р-хранилища) Росплатформы через CLI
Но когда необходим более детальный мониторинг по каждому сервису/службе то, тут уже необходимо что-то другое, а в Росплатформе как в инфраструктурной экосистеме, сервисов немало. И разработчики как оказалось работают в этом направлении и можно даже увидеть результат их деятельности, если в развернутом кластере Росплатформы посмотреть на сервисы SDS через команду #netstat –tunap | grep имясервиса, где имя сервиса например cs – служба чанк сервера.
И мы можем увидеть вывод:
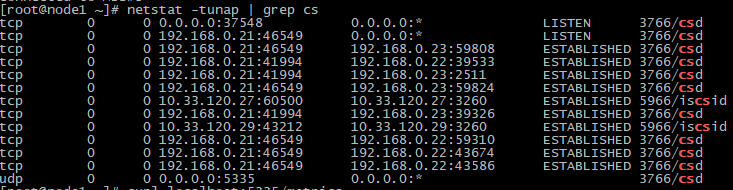
Где есть адрес 0.0.0.0 и порт 37548 который можно прослушать через команду
#curl localhost: 37548/metrics
И мы увидим целую кучу метрик, которые как раз подходят для Prometheus и для рисования графиков с привлекательным интерфейсом в Grafana.

По мимо этих просто чудо метрик есть конечно возможность использовать обычные доступные всем экспортеры для Prometheus, потому что под капотом Росплатформы модифицированный гипервизор kvm-qemu плюс libvirt и операционная система на базе linux ядра. Разработчики Росплатформы также планируют добавить в свой репозиторий эти экспортеры с модификацией под новую версию, но можно не дожидаясь воспользоваться уже сейчас выше описанными. В этой статье попробую описать все таки как можно работать с чудо метриками отдельных сервисов так как это оказалось более сложнее чем просто готовые экспортеры.

В общем сама Grafana умеет только рисовать, а для сбора метрик она использует различные сборщики, одним из которых является выше описанный Prometheus. Он конечно сам умеет рисовать графики и имеет свой веб ui, но это далеко от Grafana.

Веб ui от Prometheus
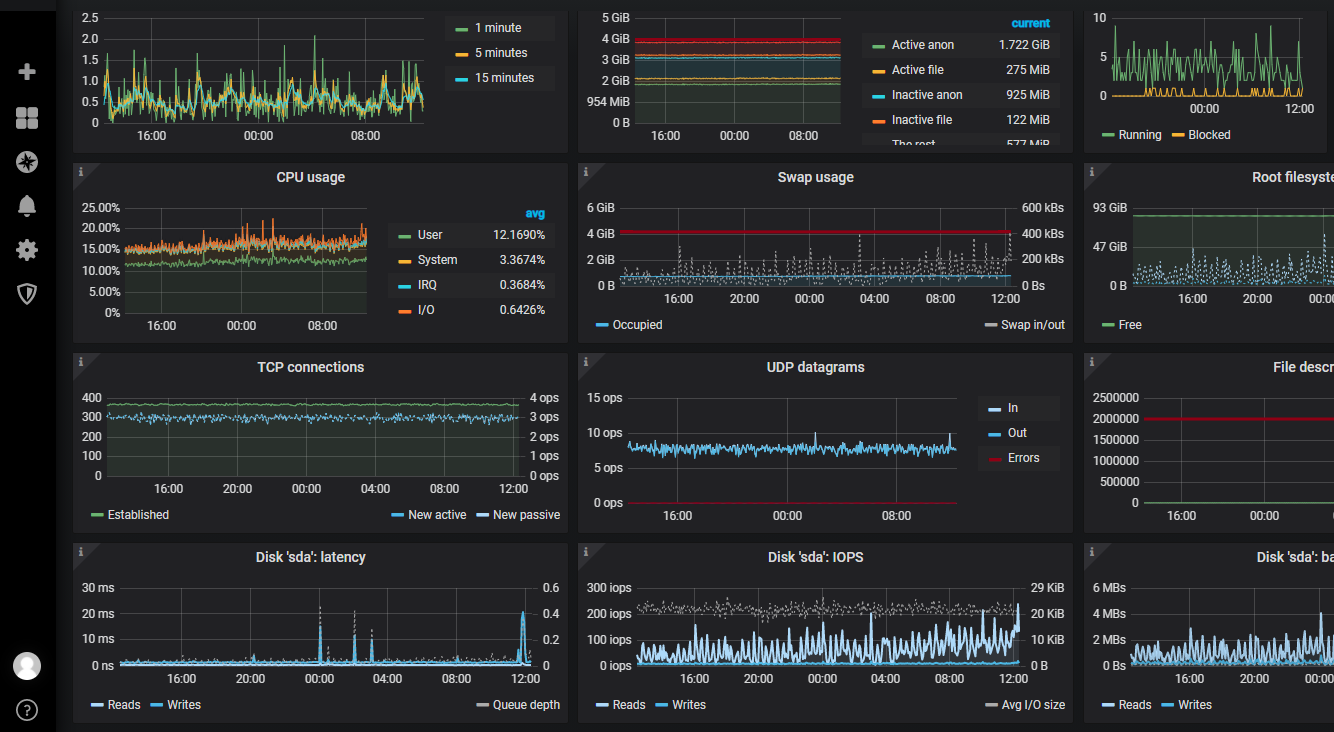
Дашборд Grafana
Модный Prometheus как и Grafana, тоже может только видеть метрики там где они лежат, или забирать их через экспортеры, в которых описывают места вывода метрик. Все это конечно можно настроить в конфиге Prometheus, и в экспортере добавить адреса(цели), по которым будут транслироваться метрики.
Service Discovery
Изначально мне показалось, что всего этого будет достаточно чтобы замутить свой мониторинг на базе этих прекрасных инструментов, но не тут-то было. Дело в том, что например для микросервисов SDS-а нет готовых экспортеров, для каждой его службы, да и вряд ли появятся, так как сервис работающий для одного диска может появляться и исчезать, если этот диск например заменить или добавить новые диски, или сервисы s3/iscsi при масштабировании могут плодится и т.д. И что получается каждый новый сервис прописывать в экспортере или в конфиге Prometheus, где для каждого свой уникальный порт?
Можно конечно написать целую программу под это дело, но это уже другая история, и хочется как-то менее рутинным и более легким путем. Покапавшись в гугле узнал, что есть еще программы service discover и одна из самых популярных для Prometheus это Сonsul.

Насмотревшись про него видео и изучив его возможности оказалось, что в нем можно просто зарегистрировать/ отрегистрировать сервисы с их портами для последующей передачи Prometheus, но сам он конечно ничего не ищет, как это описывают на первый взгляд в многих статьях и документации этого инструмента. То есть искать он может разными способами (DNS, HTTP API, RPC) уже у себя внутри среди зарегистрированных в нем сервисах.
В результате можно вернутся к нашей команде #netstat, и выполнять эту команду через Ansible или написать скрипт под планировщик задач с помощью которого будут сканироваться наши сервисы netstat-ом. Далее каждый найденный сервис наш скрипт будет регистрировать в Сonsul командой
#curl --request PUT --data @services.json localhost:8500/v1/agent/service/registerГде файл services.json это описание сервиса в этом формате:
{
"services":[{
"name":"cs",
"tags":["csid=1026"],
"address":"127.0.0.1",
"port":33074
},{
"name":"mds",
"address":"127.0.0.1",
"tags":["mdsid=2"],
"port": 9100
}]
}В данном примере описываются два сервиса это чанк сервер “cs” и служба метаданных SDS Росплатформы “mds”.
Отрегистрировать также можно устроить с помощью одного и того же скрипта, который будет проверять доступность метрик от этого сервиса по его порту и в случае пустого ответа выкидывать этот сервис из Consul по команде:
#curl --request PUT http://127.0.0.1:8500/v1/agent/service/deregister/my-service-idЕсть конечно еще путь эмулировать API Consul, чтобы Prometheus думал, что он обращается к Consul, а на самом деле к ngnix, где ему подкладывал бы в формате json список сервисов этот же скрипт. Но это уже опять другая история, близкая к разработке. Можно оставить сам консул, который идет в виде отдельно выполняемого файла, в связи с чем его можно расположить на SDS для отказоустойчивости вместо его кластерной настройки, которую также можно осуществить, но это усложняет инструкцию и выходит за рамки этого описания.
Далее после того как у нас запущен Consul с необходимыми зарегистрированными сервисами, надо установить и настроить Prometheus. Можно это сделать в виртуальной среде, а на каждой ноде только его экспортер. Например в Росплатформе он уже предустановлен в контейнере vstorage-ui управления SDS-ом(Р-хранилище), остается только установить экспортеры на ноды и прописать их в конфиге Prometheus.
В его конфиге также можно прописать правила выборки метрик далее адрес и порт Consul, и регулярные выражения с метками для фильтрации нужных значений.
После этого мы можем устанавливать Grafana можно на этом же узле или даже на клиенте на своем ноутбуке, а можно как в моем варианте в гостевой машине, где в настройках Grafana указать сборщик данных Prometheus с адресом на наш установленный и его портом.
Если пройти в раздел explore то, можно проверить нашу работу, нажав на кнопку метрики, где у вас появится меню/список с разделами метрик.
Установка настройка Consul

В выше описанной краткой инструкции я опустил настройку конфигурационного файла Prometheus,
но для начала установим и запустим сам Consul на одной из нод кластера Росплатформы(Р-виртуализации):
Можно скачать его следующей командой
#wget https://releases.hashicorp.com/consul/1.9.1/сonsul_1.9.1_linux_amd64.zipРаспаковываем его
# unzip сonsul_1.9.1_linux_amd64.zipB сразу можно запустить проверить
#./consul –vДля начала чтобы не заморачиваться со автоскриптом по поиску и регистрации сервисов служб SDS-а Росплатформы в Consul, описанным выше, попробуем просто создать папку с прописанными службами в файле json.
#mkdir consul.dИ внутри этой папки создадим файл
#vi services.jsonСо следующим содержимом
{
"services":[{
"name":"cs",
"tags":["csid=1026"],
"address":"127.0.0.1",
"port":33074
},{
"name":"mds",
"address":"127.0.0.1",
"tags":["mdsid=2"],
"port": 9100
}]
}Где 1026 это id службы чанк сервера, которую можно увидеть по команде
#vstorage –c имя_вашего_кластера list-services
По ней также можно увидеть mdsid
Порты можно посмотреть через #netstat –tunap | grep cs или mds в строке с адресом 0.0.0.0 с протоколом tcp.
После этого можно проверить запустить наш Consul
#consul agent -dev -enable-script-checks -config-dir=./consul.dНа экран будут выводится сообщения, можно это окно закрыть consul продолжит работать в фоновом режиме, для его перезагрузки можно воспользоваться командой
#consul reloadМожно проверить работу Consul через команду
#curl localhost:8500/v1/catalog/servicesОн должен вывести наши зарегистрированные сервисы
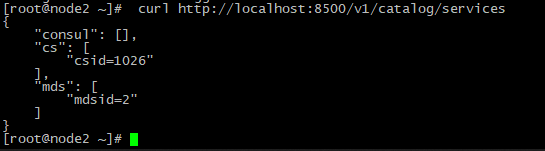
И можно еще проверить каждый сервис:
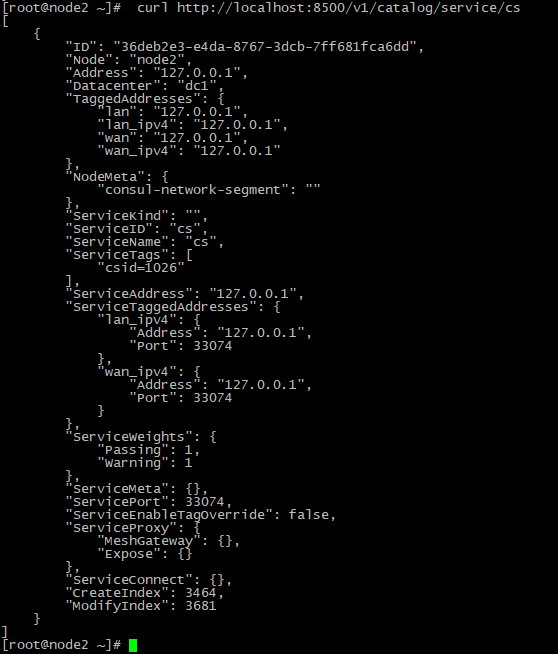
Установка настройка Prometheus

Теперь можно установить Prometheus прям на ноду чтобы пока не возится с Prometheus в vstorage-ui
#wget https://github.com/prometheus/prometheus/releases/download/v2.23.0/prometheus-2.23.0.linux-amd64.tar.gz
#mkdir /etc/Prometheus
#mkdir /var/lib/Prometheus
#tar zxvf prometheus-2.23.0.linux-amd64.tar.gz
#cd prometheus-*.linux-amd64
#cp prometheus promtool /usr/local/bin/
#cp -r console_libraries consoles prometheus.yml /etc/Prometheus
#useradd --no-create-home --shell /bin/false Prometheus
#chown -R prometheus:prometheus /etc/prometheus /var/lib/Prometheus
#chown prometheus:prometheus /usr/local/bin/{prometheus,promtool}Как запустить и прописать в автозапуск в виде сервиса смотрим здесь
Редактируем наш конфиг файл Prometheus:
#vi /etc/systemd/system/prometheus.serviceglobal:
scrape_interval: 1m
evaluation_interval: 1m
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
rule_files:
- /var/lib/prometheus/rules/*.rules
- /var/lib/prometheus/alerts/*.rules
- job_name: consul
honor_labels: true
consul_sd_configs:
- server: '127.0.0.1:8500' #адрес и порт Consul
datacenter: 'dc1' # к какому датацентру Consul относится - опционально
scheme: http # по какому протоколу/схеме взаимодействие
relabel_configs:
- source_labels: [__address__]
regex: (.*)[:].+
target_label: instance
replacement: '${1}'
- source_labels: [__meta_consul_service]
target_label: 'job'
- source_labels: [__meta_consul_node]
target_label: 'node'
- source_labels: [__meta_consul_tags]
regex: ',(?:[^,]+,){0}([^=]+)=([^,]+),.*'
target_label: '${1}'
replacement: '${2}' Здесь
Нам в помощь дока про конфиг, а в самом примере здесь некоторые строки с комментарием.
Теперь можно запустить Prometheus проверить его работоспособность
#systemctl start prometheus.service
#systemctl status prometheus.serviceПройти через браузер по адресу адрес_ноды_где_установлен_Prometheus:9090

И потом пройти в меню status -> targets
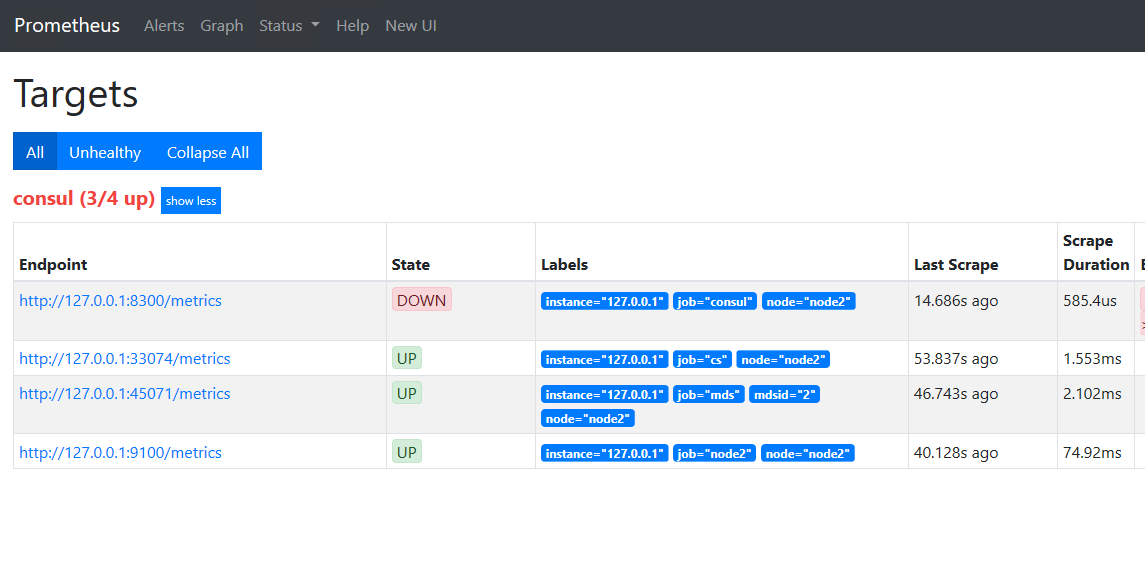
И провалится например по ссылке 127.0.0.1:33074 /metrics где мы увидим наши метрики от службы чанк сервера
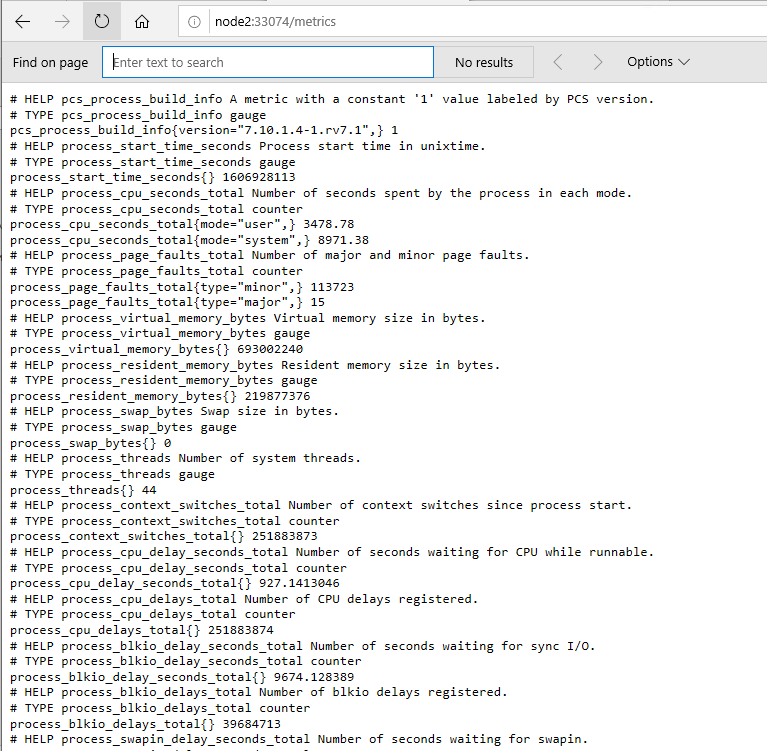
К каждой строке есть комментарий
Установка настройка Grafana

Далее устанавливаем grafana
Я установил у себя на ноутбуке на windows 10 и зашел через браузер по адресу localhost:3000
Далее подключился к серверу к ноде с установленным Prometheus
Теперь проходим в меню manage и создаем наш новый дашборд.
Выбираем добавить новую панель
Можно ее назвать например “memory use”, для того чтобы попробовать отобразить использование памяти сервера нашей выше описанной службы чанк сервер.
На вкладе query выбрать из выпадающего списка datasource Prometheus, который мы ранее настроили на наш сервер(Р-виртуализации) Росплатформы с прослушивающим портом 9090.
Далее в поле metrics мы должны вставить метрику, ее можно подобрать из списка всех метрик по описанию после слова HELP.
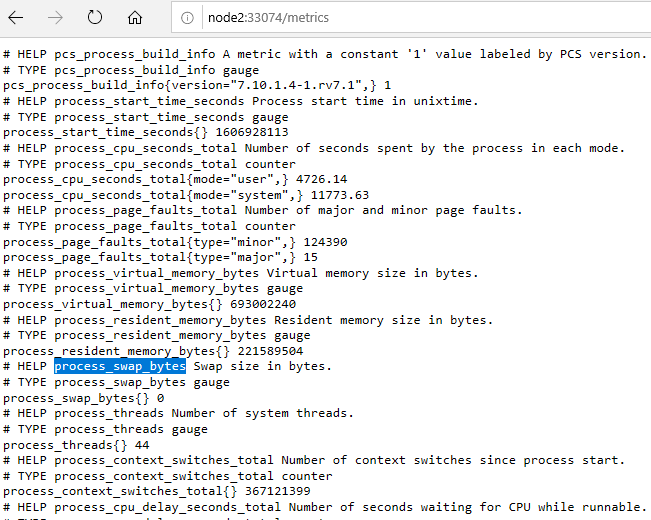
Находим process_swap_bytes – использование swap в байтах. Еще можно взять process_resident_memory_bytes – из комментария видно, что это использование памяти сервера.
И дополнительно взять process_swapin_delay_seconds – задержка при передачи памяти swap в резидентную память.
В Grafana в дашборде можно создать переменную:

После этого редактируем панель

- 1. Название панели memory use.
- 2. Выбираем data sources в нашем случае это Prometheus.
- 3. Добавляем описание например “общий объем памяти и памяти подкачки, занятой CS, а также процент времени, затраченного на ожидание передачи памяти swap в резидентную память.”
- 4. Пишем первый запрос с именем метрики process_swap_bytes{job=”cs”,csid=”$cs”}, где указываем службу cs и переменную его id.
- 5. Имя определения.
- 6. Разрешение.

Добавляем еще query и прописываем туда аналогично как мы прописывали для swap,
Только в поле напротив metrics где B будет process_resident_memory_bytes{job=«cs»,csid="$cs"}, а в С будет instance:process_swapin_delay_seconds:rate5m{job=«cs»,csid="$cs"}

Здесь настраиваем цвет и шкалу графика

В результате должен получится вот такой график
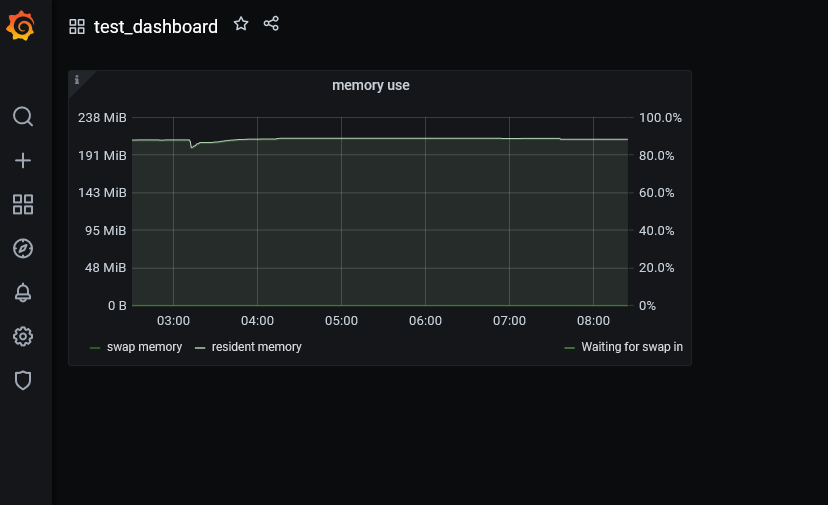
На этом пока все, надеюсь это как-то поможет тем, кто интересуется настройкой своего мониторинга на базе Grafana и Prometheus плюс Consul для Росплатформы или других похожих систем.

Полезные ссылки:
- Наборы дашбордов Grafana https://grafana.com/grafana/dashboards
- Различные экспортеры Prometheus https://prometheus.io/docs/instrumenting/exporters/
- Экспортер для libvirt https://github.com/kumina/libvirt_exporter
- Экспортер для Linux https://github.com/prometheus/node_exporter
- Документация консула https://www.consul.io/docs/intro
- Статья про Consul https://habr.com/ru/post/278085/ и https://habr.com/ru/post/266139/
- Вторая статья про работу с Consul https://dotsandbrackets.com/using-consul-service-discovery-ru/
- третья статья Consul про регистрацию https://www.airpair.com/scalable-architecture-with-docker-consul-and-nginx
- установка, настройка Prometheus https://www.dmosk.ru/instruktions.php?object=prometheus-linux или https://eax.me/prometheus-and-grafana/
- Подробнее о Prometheus https://habr.com/ru/company/selectel/blog/275803/
- Как писать свои метрики для Prometheus https://eax.me/golang-prometheus-metrics/
- статья про настройку связки Grafana с Prometheus https://devconnected.com/monitoring-linux-processes-using-prometheus-and-grafana/#a_Installing_Pushgateway или https://rtfm.co.ua/grafana-sozdanie-dashboard/




