
Расстояние редактирования Левенштейна (для сравнения РНК)
Как мы уже говорили в первой части, для демонстрации анализа алгоритма в более широком контексте примером послужит расстояние редактирования Левенштейна. Расстояние редактирования также иногда называют поиском похожих строк (или нечетким поиском). Это метрика редактирований (изменений символов), необходимых для преобразования одной строки в другую (целевую) строку. Из самых известных применений алгоритма можно выделить предоставление предложений по правильному написанию, нечеткий поиск по строке поискового запроса и сравнение последовательностей ДНК/РНК.
По сравнению с бинарным поиском, который построен вокруг одной операции поиска, классический алгоритм Левенштейна поддерживает три операции: вставить/insert, удалить/delete и заменить/substitute (символ в строке). Расстояние редактирования, которое он выдает, является минимальным количеством необходимых операций. Существует также разновидность под названием Дамерау — Левенштейна, добавляющая транспозицию/transposition (перестановку), но чтобы лишний раз не усложнять пример, я здесь буду использовать классический вариант Левенштейна.
Некоторые примеры:
test -> tent: одна замена s->n = оценка расстояния Левенштейна 11
Levenstein -> Levenshtein: одна вставка h = оценка расстояния Левенштейна 1
Levenshtein -> Levenstein: одно удаление h = оценка расстояния Левенштейна 1
bad -> base: одна замена d -> s + одна вставка e = оценка расстояния Левенштейна 2
bad -> based: две вставки s + e = оценка расстояния Левенштейна 2
Определение примера для применения
Как я уже отмечал ранее, я буду рассматривать алгоритм Левенштейна исходя из примера его применения, чтобы дать ему некоторый контекст, которого не хватало в моем примере с бинарным поиском. Поскольку алгоритм Левенштейна применяется в анализе РНК, я считаю, что сравнение РНК (RNA search) послужит отличным примером. В частности, РНК-содержащий вирус COVID-19. По нему доступно очень много информации, что дает мне возможность поиграть с длинными цепочками РНК на актуальную тему. Как и в случае с бинарным поиском, я начинаю с исследования, целью которого является понять область применения и применяемый алгоритм.
Последовательность РНК COVID-19, состоящая из четырехбуквенного алфавита, представляющего ее химическую основу, имеет длину 29881 “символов”. Одна часть структуры COVID-19 представляет особый интерес — это шиповидный белок. Этот интерес связан с ролью шиповидного белка в заражении клеток человека.
Шиповидный белок задается подпоследовательностью общей вирусной РНК длиной 3831 символов. Википедия указывает, что штамм Omicron имеет 60 мутаций в сравнении с исходным штаммом Wuhan, 32 из которых находятся в шиповом белке.
Итак, в этом примере я попробую применить алгоритм Левенштейна к последовательностям длиной 3831 символов (возможно, и до всех 29881). Учитывая известное количество мутаций Omicron, я установлю 60 редактирований в качестве максимума в своем тестировании. Как и в случае с бинарным поиском, я определяю параметры алгоритма (для тестирования) на основе знания предметной области и предполагаемого использования.
ДИСКЛЕЙМЕР: я не участвовал в каких-либо серьезных исследованиях, задействующих алгоритмы сравнения РНК, но я уверен, что они куда более продвинуты, чем базовый пример, который я взял для этой статьи.
Постановка эксперимента
Я использовал библиотеку Python weighted-levenshtein. Мои тесты базовой гарантии (base assurance tests) включают обработку ситуаций с пустой строкой, строками различной длины, недопустимыми символами и мутациями конкретной строки. И так далее.
Чтобы масштабировать тестирование, я снова создал несложный генератор ввода для генерации входных строк и применения операций, поддерживаемых алгоритмом (вставка, удаление, замена). Он генерировал случайные строки заданной длины, применял полученные операции к строке и вычисляло оценку расстояния для модифицированной и исходной (немодифицированной) строки. В то же время я замерял время выполнения и проверял набор выходных инвариантов:
Оценка, выдаваемая алгоритмом, всегда должна соответствовать количеству примененных операций.
Когда мы меняем местами сравниваемые строки, например, car->cars на cars->car, мы всегда должны получать один и тот же результат. Так как операции обратимы.
Моя тестовая среда проверяла эти инварианты для каждого сгенерированного (тестового) прогона алгоритма.
Для своих тестов базовой гарантии, я сначала использовал генератор входных данных для создания большого количества строк относительно небольшой длины (5–10 символов) с различным числом примененных операций (0–9). Это дало мне больше уверенности, более широкий охват позиций и упростило отладку результатов (с ограниченной длиной). Для подсчета оценок, границ строк, групповых операций и т. д. Это также показало мне, насколько мои предположения о двух вышеупомянутых инвариантах были неверны (для первого).
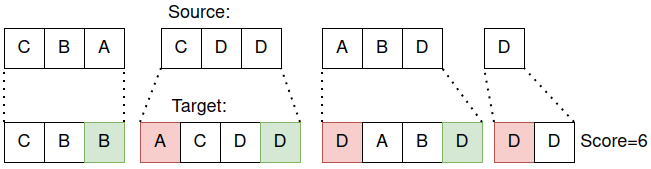
Я обнаружил, что при запуске алгоритма с достаточным количеством итераций есть вероятность, что он случайным образом найдет случаи, когда целевая строка, построенная с помощью нескольких замен, может быть достигнута за меньшее количество комбинаций операций вставки, удаления и замены. Вот пример:
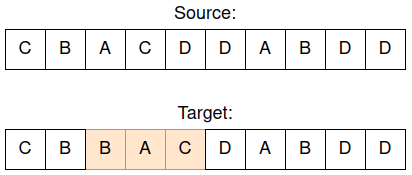
Применение 3 замен к исходной строке для создания целевой, ожидаемая оценка расстояния Левенштейна 3.
Приведенные выше исходная и целевая строки после выполнения 3 замен по случайно выбранным индексам на случайно выбранные символы. Помните, моей целью было сравнение РНК COVID-19 с алфавитом из 4-х символов (ABCD). Произведены следующие замены; индекс 3: A->B, индекс 4: C->A, индекс 5: D->C. Ожидая, что оценка Левенштейна будет соответствовать количеству операций редактирования (здесь 3 замены), мы думаем, что получим оценку 3.
Однако вместо оценки 3 приведенный выше пример даст оценку 2. После небольшого анализа я понял, что та же целевая строка может быть получена с помощью одной вставки и одного удаления, что дает минимальный балл 2:
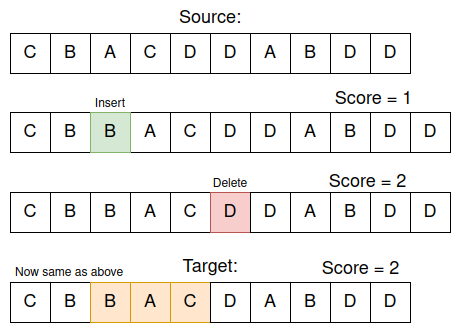
Получение той же целевой строки, что и выше, всего за 2 операции (вставка + удаление).
С этим знанием мне пришлось убрать неверный инвариант из проверок. Вместо этого я решил собрать статистику по результатам, полученным при различном количестве примененных операций. Затем я мог проверить, что общее распределение баллов не слишком сильно отличается от количества примененных операций, если не является точно таким же. Второй инвариант (замена строк местами) подходил для всех сгенерированных тестов.
Я считаю, что это хороший пример того, что можно назвать исследовательским тестированием алгоритмов. Сформулируйте любые предположения о том, как работает алгоритм, представьте их как инварианты (или что-то еще, с чем вы работаете), создайте дополнительные тесты, чтобы убедиться, верны ли они. Во время этой работы вы лучше разбирайтесь в алгоритме и области его применения.
После успешного выполнения этих небольших тестов и приобретения уверенности в том, что я достаточно охватил свои предположения, я увеличил размеры строк генерируемых для проверки вычислительной сложности.
Вычислительная сложность: подготовка
В рамках этой оценки я использовал генератор входных данных для создания строк длиной от 100 до 5000 символов с интервалом в 250 символов (100, 350, 600, 850, … до 4850). Целевая длина строки, которую я установил ранее, составляла 3981 символ, что здесь учтено с большим запасом. Для достижения статистической достоверности я повторил тестирования для каждого варианта длины (от 100 до 4850) 100 раз.
Для каждой сгенерированной строки я применил следующие операции 1, 3, 9 и 60 раз (60 — предел для омикрона, определенный выше):
Замена символов в строке в случайных (неперекрывающихся) местах.
Вставка случайных символов в случайном месте в тестовой строке.
Удаление случайных символов в тестовой строке.
Комбинации вышеперечисленного.
Моя цель состояла в том, чтобы увидеть, повлияют ли операции, их количество или длина строки на время выполнения. Или, выражаясь более в более формальных терминах, протестировать операции и параметры алгоритма, чтобы увидеть, как они влияют на время его выполнения.
Вычислительная сложность: измерения
Результаты вышеописанных экспериментов получились очень похожими с точки зрения производительности. На следующем изображении показаны замены и их общее время выполнения:
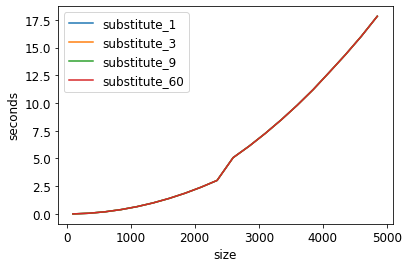
Время выполнения алгоритма Левенштейна в зависимости от размера строки.
Substitute_x относится к замене X символов в исходной строке и вычислению оценки расстояния Левенштейна. По оси X указан размер строки от 100 до 4850. По оси Y указано время, затраченное на выполнение 100 экспериментов.
Четыре линии на приведенном выше графике практически перекрываются, потому что время выполнения в каждом случае было очень близким. Поскольку мне это показалось немного подозрительным, я провел несколько отдельных экспериментов с различными параметрами, чтобы проверить, верно ли это, и убедился, что верно. Немного странно, но ладно. Было бы очень интересно услышать мнение эксперта в этой предметной области и команду.
Я не стал приводить здесь графики для остальных операций. Все они были очень похожи (и даже для комбинации операций), что указывает на то, что время выполнения практически не зависело от типа или количества операций.
Вышеприведенный график в целом напоминает экспоненциально растущую кривую. Чтобы проверить это, я поэкспериментировал с несколькими параметрами, чтобы попытаться визуализировать соответствующую форму экспоненциальной кривой. Вот окончательный график измеренного времени выполнения по сравнению с теоретическим графиком для экспоненциального времени:
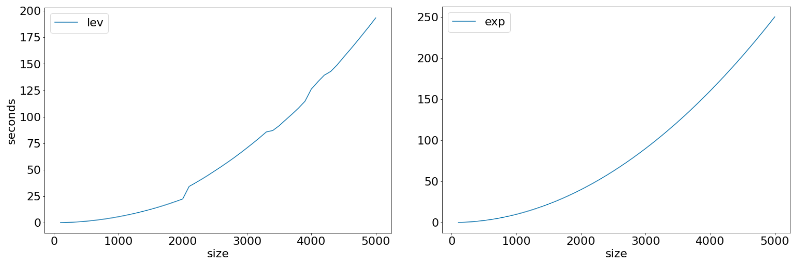
Время выполнения (слева) по сравнению с экспоненциальным графиком (справа).
Исходя из этого, я бы сказал, что алгоритм имеет экспоненциальную сложность. В Википедии даже есть несколько слов о высокой вычислительной сложности алгоритма Левенштейна. Исходя из этого, мой вердикт состоит в том, что эти результаты соответствуют теоретическим ожиданиям, этот алгоритм кажется менее оптимальным для более длинных входных данных.
Тестирование адаптации алгоритма
Иногда в результате тестирования и анализа алгоритма мы понимаем, что он не очень подходит для наших нужд. Но мы еще можем попробовать альтернативу или адаптацию этого алгоритма для решения нашей задачи. Давайте рассмотрим здесь один пример.
Экспоненциальный рост времени выполнения обычно считается плохой новостью с точки зрения масштабируемости. Для коротких строк (например, проверка орфографии слова или shell-команды) это, вероятно, не проблема, так как эффект экспоненциального прироста временных затрат очень мал для короткого ввода. Однако в своем примере с РНК я хотел найти и проанализировать последовательности длиной в 3831+ символов. В этой ситуации мне может помочь исследование всевозможных ускорений.
Допустим, мы решили попытаться сделать его быстрее, пытаясь запускать алгоритм на меньших фрагментах входных данных. Это должно сделать время выполнения более линейным, а не экспоненциальным. В конце концов, нам достаточно поранжировать относительные результаты поиска, а не обязательно получить точные. И как только лучшие результаты станут известны, можно будет рассчитать точные оценки для этого подмножества. Поскольку это гипотетический пример, я называю это гипотетической идеей развития :).
Вот график времени выполнения при разделении сгенерированных входных строк на фрагменты длиной 100 символов и суммировании их оценок:
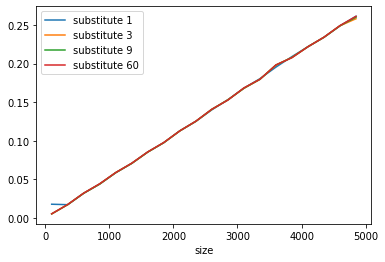
Время выполнения после разделения на фрагменты по 100 символов.
С точки зрения времени выполнения приведенный выше график выглядит намного лучше. Экспоненциальный рост стал линейным. Но как насчет результатов, насколько велика разница в оценке расстояний между их вычислением для полной строки и суммированием оценок для фрагментов из 100 символов? Следующие таблицы это иллюстрируют:
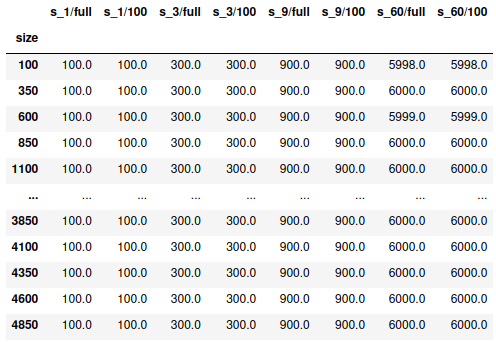
Оператор вставки, фрагменты из 100 символов и полная строка.
В приведенной выше таблице s_x относится к замене X символов в строке. Size — это общая длина строки. Постфикс /full относится к запуску алгоритма Левенштейна на полной строке. Версия /100 использует фрагменты по 100 символов. Каждая конфигурация повторялась 100 раз для достижения статистического охвата. Вот почему, например, s_1/full получил оценку 100 (100 запусков, каждый оценивается 1).
В этом примере с заменами оценки расстояний редактирования для нарезанных версий очень близки к полным версиям. Возможно, потому что замена является локальным изменением и не так сильно влияет на несколько срезов. В таблице есть несколько строк, где суммарный балл отличается на 1–2 редактирования (6000 на 5998 и 5999). Это связано с проблемой, которую я отметил выше, когда вставка и удаление могут сработать в комбинации, давая меньший минимум. Если бы замены было достаточно, это выглядело бы правдоподобной адаптацией. Но целью была поддержка всех операций.
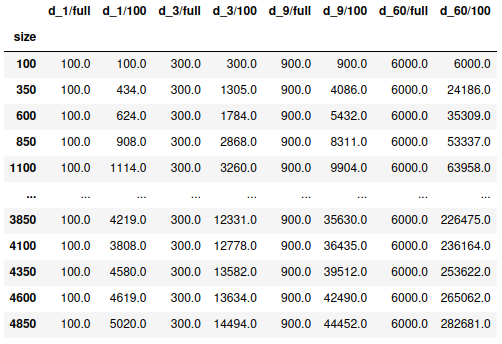
В приведенных ниже таблицах префикс i означает вставку, а d - удаление. Таким образом , i_x означает вставку X символов, а d_x - удаление X символов:
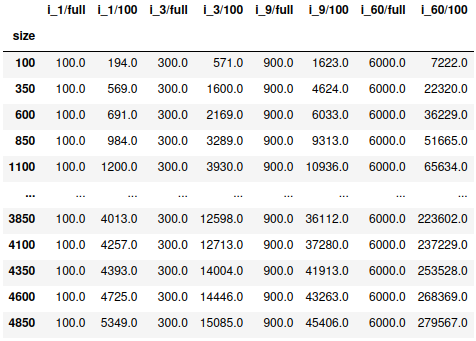
Оператор вставки, срезы по 100 и полные строки.
В приведенной выше таблице для вставки оценка расстояния i_x/full всегда соответствует ожидаемому количеству операций (*100). Для i_x/100 оценка начинает увеличиваться по мере увеличения длины строки и увеличения количества применяемых операций (от 1 до 3, 9 и 60). После некоторого анализа я пришел к выводу, что это связано с тем, что вставка символа в начале строки сдвигает все остальные символы в фрагментах вперед вправо, и, таким образом, каждый фрагмент требует многократного редактирования и значительно увеличивает суммарный балл.
На следующих изображениях проиллюстрирована эта проблема:
Выше строка длиной 10 символов, вставляем B, оценка расстояния Левенштейна рассчитывается для полной строки.
То же, что и строка выше, оценка Левенштейна рассчитывается по срезам длиной в 3 символа.
Выше приведен пример фрагмента с размером в 3 вместо 100 символов, но задумка та же. В зависимости от местоположения вставки счетчик редактирований распространяется ближе к концу и увеличивает сумму на большую величину. Чтобы каждый срез из 3 совпадал, он должен удалить первый и добавить последний символ. То же самое для операции удаления:
Оператор удаления, фрагменты по 100 символов и полная строка.
Приведенная выше таблица для удаления показывает поведение, очень похожее на то, что мы видели в таблице для вставки. И по тому же принципу удаление сдвигает все фрагменты влево (вставка сдвигает их вправо).
Таким образом, несмотря на то, что подход с нарезкой успешно сокращает время обработки алгоритма, он определенно не сработает для правильного ранжирования результатов поиска для вставки и удаления. С точки зрения применения я бы назвал эту адаптацию неудачным экспериментом, за исключением приобретения бесценного опыта.
Однако для целей этой статьи я считаю, что это хороший эксперимент. Он показывает, как можно запускать тесты алгоритма, анализировать его результаты, соответствие целям и другим свойствам, строить гипотезы, проводить эксперименты, оценивать их и повторять. Именно на таких примерах я вижу, как тестирование и анализ алгоритмов вносят вклад в общее развитие в более широком смысле, помогая планировать и оценивать эксперименты для улучшения алгоритмов и их адаптаций.
Завершение эксперимента с расстоянием редактирования Левенштейна
В более реалистичном сценарии, я надеюсь, мне пришлось бы работать с группой экспертов. И я располагал бы всеми ресурсами для проведения исследований всех возможных подходов, актуального положения вещей и всего остального по этому вопросу. На самом деле, когда алгоритм и область его применения сложны, но есть возможность упростить их, я бы считал это важной частью процесса тестирования и анализа. Работая с экспертами в предметной области, командой исследования и разработки и передовыми знаниями в предметной области, я бы продолжил. Но здесь я вынужден закончить свой анализ, поскольку мои ресурсы ограничены.
Подытожим
Моей целью в этой статье было исследовать идею того, каким может быть тестирование (и анализ) алгоритмов. Обобщающий список упрощает поможет систематизировать вышеизложенное:
Традиционные методы тестирования могут определять тесты базовой гарантии с определенными экспертами входными данными и ожидаемыми выходными данными.
Хорошее и глубокое понимание алгоритма помогает понять, как его тестировать и как адаптировать его к предметной области.
Это также включает в себя формирование хорошего понимания данных которым он применяется, и того, как они связаны с алгоритмом.
В идеале вышеизложенное происходит итеративно, во взаимодействии с исследованиями, разработками и тестированием.
Помимо проверки, тестирование алгоритма может способствовать пониманию его ограничений, потенциальных оптимизаций, и оценке альтернатив.
Формирование предположений о данных и вводе алгоритма дает нам понять, с чем алгоритм, как ожидается, будет работать.
Исследовательский анализ данных может использовать эти предположения в качестве входных данных, проверить, верны ли они, и уточнить их.
Идентификация предположений о данных и результатах работы алгоритма дает нам основу для написания инвариантов для проверки в каждом тесте.
Автоматический генератор тестов помогает масштабировать тестирование с этими инвариантами и проверкой того, верны ли наши допущения.
Объем тестирования определяется областью применения алгоритма по сравнению с общей системой, использующей его, ответственностью за обработку ввода и вывода.
Теоретическая вычислительная сложность очень полезна, но всегда следует провести практическую оценку (справедлива ли она для реализации), если имеются хорошие данные.
Тестирование алгоритма может служить инструментом для изучения алгоритма путем формулирования гипотез о нем (которые можно проверить в рамках самого тестирования).
Инструменты и методы, такие как метаморфическое тестирование могут помочь оценить устойчивость алгоритма к различным типам допустимых и недопустимых входных данных.
Тестирование и анализ в идеале являются итеративным процессом, где конечным результатом являются окончательные сгенерированные тесты и проверки, и лучшее понимание алгоритма, которое мы приобрели в процессе.
Заключение
Я начал эту статью с идеи исследовать, что значит тестировать алгоритм или что может означать “инженерный подход к тестированию алгоритмов”. Мне кажется, что я добился некоторого прогресса, хотя я уверен, что это мнение может быть очень субъективным, как и “правильность” результата алгоритма (в машинном обучении).
Оба моих примера в этой статье, бинарный поиск и расстояние редактирования Левенштейна, в конце концов являются достаточно простыми и базовыми алгоритмами. Как отмечено в этой статье, базовое тестирование таких алгоритмов не слишком сложно. Однако, рассматривая тестирование и анализ алгоритмов как часть более широкого процесса исследования и разработки, я считаю, что взаимодействие, сотрудничество и личный вклад в сообщество могут сделать его более разнообразным и интересным.
В этой статье я рассмотрел два “классических” алгоритма, в которых ввод, вывод и их отношения определить довольно просто. В следующей статье я хочу рассмотреть алгоритм(ы) на основе машинного обучения и пример алгоритма, в котором отношения ввода-вывода и правильность вывода труднее определить - они субъективны или “не поддаются определению” в традиционном смысле.
А на этом все. Всего доброго!
Перевод статьи подготовлен в преддверии старта курса "Архитектура и шаблоны проектирования".


")

