
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
В наше время словами «искусственный интеллект» называют очень много различных систем — от нейросети для распознавания картинок до бота для игры в Quake. В википедии дано замечательное определение ИИ — это «свойство интеллектуальных систем выполнять творческие функции, которые традиционно считаются прерогативой человека». То есть из определения явно видно — если некую функцию успешно удалось автоматизировать, то она перестаёт считаться искусственным интеллектом.
Тем не менее, когда задача «создать искусственный интеллект» была поставлена впервые, под ИИ подразумевалось нечто иное. Сейчас эта цель называется «Сильный ИИ» или «ИИ общего назначения».
Сейчас существуют две широко известные постановки задачи. Первая — Сильный ИИ. Вторая — ИИ общего назначения (он же Artifical General Intelligence, сокращённого AGI).
Сильный ИИ — это гипотетический ИИ, который мог бы делать всё то, что мог бы делать человек. Обычно упоминается, что он должен проходить тест Тьюринга в первоначальной постановке (хм, а люди-то его проходят?), осознавать себя как отдельную личность и уметь достигать поставленных целей.
То есть это что-то вроде искусственного человека. На мой взгляд, польза от такого ИИ в основном исследовательская, потому что в определениях Сильного ИИ нигде не сказано, какие перед ним будут цели.
AGI или ИИ общего назначения — это «машина результатов». Она получает на вход некую постановку цели — и выдаёт некие управляющие воздействия на моторы/лазеры/сетевую карту/мониторы. И цель достигнута. При этом у AGI изначально нет знаний об окружающей среде — только сенсоры, исполнительные механизмы и канал, через который ему ставят цели. Система управления будет считаться AGI, если может достигать любых целей в любом окружении. Ставим её водить машину и избегать аварий — справится. Ставим её управлять ядерным реактором, чтобы энергии было побольше, но не рвануло — справится. Дадим почтовый ящик и поручим продавать пылесосы — тоже справится. AGI — это решатель «обратных задач». Проверить, сколько пылесосов продано — дело нехитрое. А вот придумать, как убедить человека купить этот пылесос — это уже задачка для интеллекта.
В этой статье я буду рассказывать об AGI. Никаких тестов Тьюринга, никакого самосознания, никаких искусственных личностей — исключительно прагматичный ИИ и не менее прагматичные его операторы.
Сейчас существует такой класс систем, как Reinforcement Learning, или обучение с подкреплением. Это что-то типа AGI, только без универсальности. Они способны обучаться, и за счёт этого достигать целей в самых разных средах. Но всё же они очень далеки от того, чтобы достигать целей в любых средах.
Вообще, как устроены системы Reinforcement Learning и в чём их проблемы?
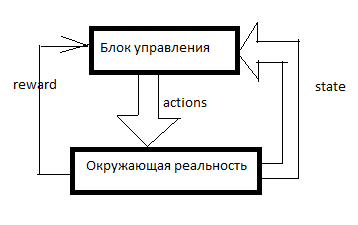
Любой RL устроен примерно так. Есть система управления, в неё через сенсоры (state) входят некоторые сигналы об окружающей реальности и через управляющие органы (actions) она воздействует на окружающую реальность. Reward — это сигнал подкрепления. В RL-системах подкрепление формируется извне управляющего блока и оно обозначает то, насколько хорошо ИИ справляется с достижением цели. Сколько продал пылесосов за последнюю минуту, например.
Затем формируется таблица вот примерно такого вида (буду её называть таблицей SAR):

Ось времени направлена вниз. В таблице отражено всё, что ИИ делал, всё, что он видел и все сигналы подкрепления. Обычно для того, чтобы RL сделал что-то осмысленное, ему надо для начала какое-то время делать случайные ходы, либо смотреть на ходы кого-то другого. В общем, RL начинается тогда, когда в таблице SAR уже есть хотя бы несколько строчек.
Что происходит дальше?
Простейшая форма reinforcement learning.
Мы берём какую-нибудь модель машинного обучения и по сочетанию S и A (state и action) предсказываем суммарный R на следующие несколько тактов. Например, мы увидим, что (исходя из той таблицы выше) если сказать женщине «будь мужиком, купи пылесос!», то reward будет низким, а если сказать то же самое мужчине, то высоким.
Какие именно модели можно применять — я опишу позже, пока лишь скажу, что это не только нейросети. Можно использовать решающие деревья или вообще задавать функцию в табличном виде.
А дальше происходит следующее. ИИ получает очередное сообщение или ссылку на очередного клиента. Все данные по клиенту вносятся в ИИ извне — будем считать базу клиентов и счётчик сообщений частью сенсорной системы. То есть осталось назначить некоторое A (action) и ждать подкрепления. ИИ берёт все возможные действия и по очереди предсказывает (с помощью той самой Machine Learning модельки) — а что будет, если я сделаю то? А если это? А сколько подкрепления будет за вот это? А потом RL выполняет то действие, за которое ожидается максимальная награда.
Вот такую простую и топорную систему я ввёл в одну из своих игр. SARSA нанимает в игре юнитов, и адаптируется в случае изменения правил игры.
Кроме того, во всех видах обучения с подкреплением есть дисконтирование наград и дилемма explore/exploit.
Дисконтирование наград — это такой подход, когда RL старается максимизировать не сумму награду за следующие N ходов, а взвешенную сумму по принципу «100 рублей сейчас лучше, чем 110 через год». Например, если дисконтирующий множитель равен 0.9, а горизонт планирования равен 3, то модель мы будем обучать не на суммарном R за 3 следующих такта, а на R1*0.9+R2*0.81+R3*0.729. Зачем это надо? Затем, что ИИ, создающий профит где-то там на бесконечности, нам не нужен. Нам нужен ИИ, создающий профит примерно здесь и сейчас.
Дилемма explore/exploit. Если RL будет делать то, что его модель полагает оптимальным, он так и не узнает, были ли какие-то стратегии получше. Exploit — это стратегия, при которой RL делает то, что обещает максимум награды. Explore — это стратегия, при которой RL делает что-то, что позволяет исследовать окружающую среду в поисках лучших стратегий. Как реализовать эффективную разведку? Например, можно каждые несколько тактов делать случайное действие. Или можно сделать не одну предсказательную модель, а несколько со слегка разными настройками. Они будут выдавать разные результаты. Чем больше различие, тем больше степень неопределённости данного варианта. Можно сделать, чтобы действие выбиралось таким, чтобы у него максимальной была величина: M+k*std, где M — это средний прогноз всех моделей, std — это стандартное отклонение прогнозов, а k — это коэффициент любопытства.
В чём недостатки?
Допустим, у нас есть варианты. Поехать к цели (которая в 10 км от нас, и дорога до неё хорошая) на автомобиле или пойти пешком. А потом, после этого выбора, у нас есть варианты — двигаться осторожно или пытаться врезаться в каждый столб.
Человек тут же скажет, что обычно лучше ехать на машине и вести себя осмотрительно.
А вот SARSA… Он будет смотреть, к чему раньше приводило решение ехать на машине. А приводило оно вот к чему. На этапе первичного набора статистики ИИ где-то в половине случаев водил безрассудно и разбивался. Да, он умеет водить хорошо. Но когда он выбирает, ехать ли на машине, он не знает, что он выберет следующим ходом. У него есть статистика — дальше в половине случаев он выбирал адекватный вариант, а в половине — самоубийственный. Поэтому в среднем лучше идти пешком.
SARSA полагает, что агент будет придерживаться то же стратегии, которая была использована для заполнения таблицы. И действует, исходя из этого. Но что, если предположить иное — что агент будет придерживаться наилучшей стратегии в следующие ходы?
Эта модель рассчитывает для каждого состояния максимально достижимую из него суммарную награду. И записывает её в специальный столбец Q. То есть если из состояния S можно получить 2 очка или 1, в зависимости от хода, то Q(S) будет равно 2 (при глубине прогнозирования 1). Какую награду можно получить из состояния S, мы узнаём из прогнозной модели Y(S,A). (S — состояние, A — действие).
Затем мы создаём прогнозную модель Q(S,A) — то есть в состояние с каким Q мы перейдём, если из S выполним действие A. И создаём в таблице следующий столбец — Q2. То есть максимальное Q, которое можно получить из состояния S (перебираем все возможные A).
Затем мы создаём регрессионную модель Q3(S,A) — то есть в состояние с каким Q2 мы перейдём, если из S выполним действие A.
И так далее. Таким образом мы можем добиваться неограниченной глубины прогнозирования.
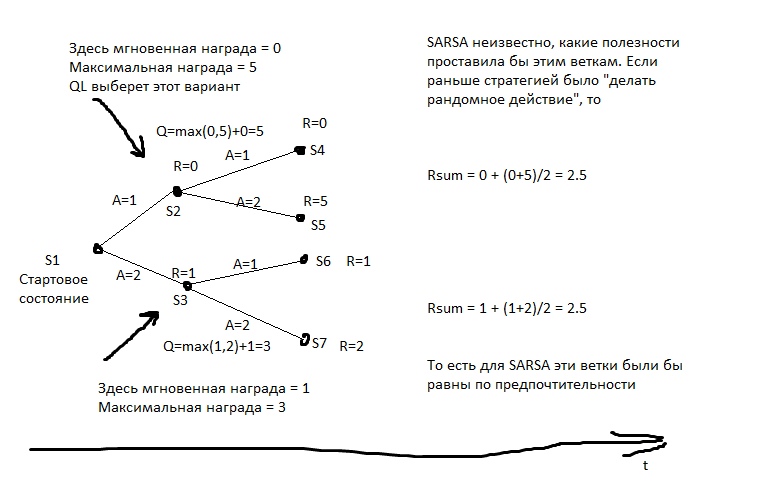
На картинке R — это подкрепление.
А затем каждый ход мы выбираем то действие, которое обещает наибольшее Qn. Если бы мы применяли этот алгоритм к шахматам, получалось бы что-то вроде идеального минимакса. Что-то, почти эквивалентное просчёту ходов на большую глубину.
Бытовой пример q-learning-поведения. У охотника есть копьё, и он с ним идёт на медведя, по собственной инициативе. Он знает, что подавляющее большинство его будущих ходов имеет очень большой отрицательный реворд (способов проиграть намного больше, чем способов победить), на знает, что есть и ходы с положительным ревордом. Охотник полагает, что в будущем он станет делать именно наилучшие ходы (а не неизвестно, какие, как в SARSA), а если делать наилучшие ходы, то медведя он победит. То есть для того, чтобы пойти на медведя, ему достаточно уметь делать каждый элемент, нужный на охоте, но необязательно иметь опыт непосредственного успеха.
Если бы охотник действовал в стиле SARSA, он бы предполагал, что его действия в будущем будут примерно такими же, как раньше (несмотря но то, что сейчас у него уже другой багаж знаний), и на медведя пойдёт, только если он уже ходил на медведя и побеждал, например, в >50% случаев (ну или если другие охотники в более чем половине случаев побеждали, если он учится на их опыте).
В чём недостатки?
А что, если мы будем прогнозировать не только R или Q, но вообще все сенсорные данные? У нас постоянно будет карманная копия реальности и мы сможем проверять на ней свои планы. В этом случае нас гораздо меньше волнует вопрос сложности вычисления Q-функции. Да, она требует на вычисление много тактов — ну так мы всё равно для каждого плана многократно запустим прогнозную модель. Планируем на 10 ходов вперёд? 10 раз запускаем модель, и каждый раз подаём её выходы ей же на вход.
В чём недостатки?
Если у нас есть доступ к тестовой среде для ИИ, если мы его запускаем не в реальности, а в симуляции, то можно в какой-то форме записать стратегию поведения нашего агента. А затем подобрать — эволюцией или чем-то ещё — такую стратегию, что ведёт к максимальному профиту.
«Подобрать стратегию» значит, что нам вначале надо научиться записывать стратегию в такой форме, чтобы её можно было запихивать в алгоритм эволюции. То есть мы можем записать стратегию программным кодом, но в некоторых местах оставить коэффициенты, и пусть эволюция их подбирает. Либо мы можем записать стратегию нейросетью — и пусть эволюция подбирает веса её связей.
То есть никакого прогноза тут нет. Никакой SAR-таблицы. Мы просто подбираем стратегию, а она сразу выдаёт Actions.
Это мощный и эффективный метод, если вы хотите попробовать RL и не знаете, с чего начать — рекомендую. Это очень дешёвый способ «увидеть чудо».
В чём недостатки?
Тот же перебор стратегий, но на живой реальности. Пробуем 10 тактов одну стратегию. Потом 10 тактов другую. Потом 10 тактов третью. Потом отбираем ту, где подкрепление было больше.
Наилучшие результаты по ходячим гуманоидам получены именно этим методом.

Для меня это звучит несколько неожиданно — казалось бы, QL + Model-Based подход математически идеальны. А вот ничего подобного. Плюсы у подхода примерно те же, что и у предыдущего — но они слабее выражены, так как стратегии тестируются не очень долго (ну нет у нас тысячелетий на эволюцию), а значит, результаты неустойчивые. Кроме того, число тестов тоже нельзя задрать в бесконечность — а значит, стратегию придётся искать в не очень сложном пространстве вариантов. Мало у неё будет «ручек», которые можно «подкрутить». Ну и непереносимость опыта никто не отменял. И, по сравнению с QL или Model-Based, эти модели используют опыт неэффективно. Им надо намного больше взаимодействий с реальностью, чем подходам, использующим машинное обучение.
Как можно увидеть, любые попытки создать AGI по идее, должны содержать в себе либо машинное обучение для прогноза наград, либо некую форму параметрической записи стратегии — так, чтобы можно было эту стратегию подобрать чем-то типа эволюции.
Это сильный выпад в сторону людей, предлагающих создавать ИИ на основе баз данных, логики и понятийных графов. Если вы, сторонники символьного подхода, это читаете — добро пожаловать в комментарии, я рад буду узнать, что можно сделать AGI без вышеописанных механик.
Для обучения с подкреплением можно использовать чуть ли не любые модели ML. Нейросети — это, конечно, хорошо. Но есть, например, KNN. Для каждой пары S и A ищем наиболее похожие, но в прошлом. И ищем, какие после этого будут R. Тупо? Да, но это работает. Есть решающие деревья — тут лучше погулить по ключевым словам «градиентный бустинг» и «решающий лес». Деревья плохо умеют улавливать сложные зависимости? Используйте feature engeneering. Хотите, чтобы ваш AI был поближе к General? Используйте автоматический FE! Переберите кучу различных формул, подайте их в качестве фичей для вашего бустинга, отбросьте формулы, увеличивающие погрешность и оставьте формулы, улучшающие точность. Потом подайте наилучшие формулы в качестве аргументов для новых формул, ну и так далее, эволюционируйте.
Можно для прогноза использовать символьные регрессии — то есть просто перебирать формулы в попытках получить что-то, что будет хорошо апроксимировать Q или R. Можно попробовать перебирать алгоритмы — тогда получится штука, которая называется индукцией Соломонова, это теоретически оптимальный, но практически очень труднообучаемый способ апроксимации функций.
Но нейросети обычно являются компромиссом между выразительностью и сложностью обучения. Алгоритмическая регрессия идеально подберёт любую зависимость — за сотни лет. Решающее дерево отработает очень быстро — но уже y=a+b экстраполировать не сможет. А нейросеть — это что-то среднее.
Какие сейчас вообще есть способы сделать именно AGI? Хотя бы теоретически.
Мы можем создать много различных тестовых сред и запустить эволюцию некоей нейросетки. Размножаться будут те конфигурации, которые набирают больше очков в сумме по всем испытаниям.
Нейросетка должна иметь память и желательно бы иметь хотя бы часть памяти в виде ленты, как у машины Тьюринга или как на жёстком диске.
Проблема в том, что с помощью эволюции вырастить что-то типа RL, конечно, можно. Но как должен выглядеть язык, на котором RL выглядит компактно — чтобы эволюция его нашла — и в то же время чтобы эволюция не находила решений типа «а создам-ка я нейронку на стопятьсот слоёв, чтоб вы все чокнулись, пока я её обучаю!». Эволюция же как толпа неграмотных пользователей — найдёт в коде любые недоработки и угробит всю систему.
Можно сделать Model-Based систему, основанную на пачке из множества алгоритмических регрессий. Алгоритм гарантированно полон по Тьюрингу — а значит, не будет закономерностей, которые нельзя подобрать. Алгоритм записан кодом — а значит, можно легко рассчитать его сложность. А значит, можно математически корректно штрафовать свои гипотезы устройства мира за сложность. С нейросетями, например, этот фокус не пройдёт — там штраф за сложность проводится очень косвенно и эвристически.
Осталось только научиться быстро обучать алгоритмические регрессии. Пока что лучшее, что для этого есть — эволюция, а она непростительно долгая.
Было бы круто создать ИИ, который будет улучшать сам себя. Улучшать свою способность решать задачи. Это может показаться странной идеей, но это задача уже решена для систем статической оптимизации, типа эволюции. Если получится это реализовать… Про экспоненту все в курсе? Мы получим очень мощный ИИ за очень короткое время.
Как это сделать?
Можно попробовать устроить, чтобы у RL часть actions влияли на настройки самого RL.
Либо дать системе RL некоторый инструмент для создания себе новых пред- и пост-обработчиков данных. Пусть RL будет тупеньким, но будет уметь создавать себе калькуляторы, записные книжки и компьютеры.
Ещё вариант — создать с помощью эволюции некий ИИ, у которого часть actions будут влиять на его устройство на уровне кода.
Но на данный момент я не видел работоспособных вариантов Seed AI — пусть даже сильно ограниченных. Разработчики скрывают? Или эти варианты настолько слабые, что не заслужили всеобщего внимания и прошли мимо меня?
Впрочем, сейчас и Google, и DeepMind работают в основном с нейросетевыми архитектурами. Видимо, они не хотят связываться с комбинаторным перебором и стараются любые свои идеи сделать пригодными к методу обратного распространения ошибки.
Надеюсь, эта обзорная статья оказалась полезна =) Комментарии приветствуются, особенно комментарии вида «я знаю, как лучше сделать AGI»!
Тем не менее, когда задача «создать искусственный интеллект» была поставлена впервые, под ИИ подразумевалось нечто иное. Сейчас эта цель называется «Сильный ИИ» или «ИИ общего назначения».
Постановка задачи
Сейчас существуют две широко известные постановки задачи. Первая — Сильный ИИ. Вторая — ИИ общего назначения (он же Artifical General Intelligence, сокращённого AGI).
Сильный ИИ — это гипотетический ИИ, который мог бы делать всё то, что мог бы делать человек. Обычно упоминается, что он должен проходить тест Тьюринга в первоначальной постановке (хм, а люди-то его проходят?), осознавать себя как отдельную личность и уметь достигать поставленных целей.
То есть это что-то вроде искусственного человека. На мой взгляд, польза от такого ИИ в основном исследовательская, потому что в определениях Сильного ИИ нигде не сказано, какие перед ним будут цели.
AGI или ИИ общего назначения — это «машина результатов». Она получает на вход некую постановку цели — и выдаёт некие управляющие воздействия на моторы/лазеры/сетевую карту/мониторы. И цель достигнута. При этом у AGI изначально нет знаний об окружающей среде — только сенсоры, исполнительные механизмы и канал, через который ему ставят цели. Система управления будет считаться AGI, если может достигать любых целей в любом окружении. Ставим её водить машину и избегать аварий — справится. Ставим её управлять ядерным реактором, чтобы энергии было побольше, но не рвануло — справится. Дадим почтовый ящик и поручим продавать пылесосы — тоже справится. AGI — это решатель «обратных задач». Проверить, сколько пылесосов продано — дело нехитрое. А вот придумать, как убедить человека купить этот пылесос — это уже задачка для интеллекта.
В этой статье я буду рассказывать об AGI. Никаких тестов Тьюринга, никакого самосознания, никаких искусственных личностей — исключительно прагматичный ИИ и не менее прагматичные его операторы.
Текущее состояние дел
Сейчас существует такой класс систем, как Reinforcement Learning, или обучение с подкреплением. Это что-то типа AGI, только без универсальности. Они способны обучаться, и за счёт этого достигать целей в самых разных средах. Но всё же они очень далеки от того, чтобы достигать целей в любых средах.
Вообще, как устроены системы Reinforcement Learning и в чём их проблемы?
Любой RL устроен примерно так. Есть система управления, в неё через сенсоры (state) входят некоторые сигналы об окружающей реальности и через управляющие органы (actions) она воздействует на окружающую реальность. Reward — это сигнал подкрепления. В RL-системах подкрепление формируется извне управляющего блока и оно обозначает то, насколько хорошо ИИ справляется с достижением цели. Сколько продал пылесосов за последнюю минуту, например.
Затем формируется таблица вот примерно такого вида (буду её называть таблицей SAR):
Ось времени направлена вниз. В таблице отражено всё, что ИИ делал, всё, что он видел и все сигналы подкрепления. Обычно для того, чтобы RL сделал что-то осмысленное, ему надо для начала какое-то время делать случайные ходы, либо смотреть на ходы кого-то другого. В общем, RL начинается тогда, когда в таблице SAR уже есть хотя бы несколько строчек.
Что происходит дальше?
SARSA
Простейшая форма reinforcement learning.
Мы берём какую-нибудь модель машинного обучения и по сочетанию S и A (state и action) предсказываем суммарный R на следующие несколько тактов. Например, мы увидим, что (исходя из той таблицы выше) если сказать женщине «будь мужиком, купи пылесос!», то reward будет низким, а если сказать то же самое мужчине, то высоким.
Какие именно модели можно применять — я опишу позже, пока лишь скажу, что это не только нейросети. Можно использовать решающие деревья или вообще задавать функцию в табличном виде.
А дальше происходит следующее. ИИ получает очередное сообщение или ссылку на очередного клиента. Все данные по клиенту вносятся в ИИ извне — будем считать базу клиентов и счётчик сообщений частью сенсорной системы. То есть осталось назначить некоторое A (action) и ждать подкрепления. ИИ берёт все возможные действия и по очереди предсказывает (с помощью той самой Machine Learning модельки) — а что будет, если я сделаю то? А если это? А сколько подкрепления будет за вот это? А потом RL выполняет то действие, за которое ожидается максимальная награда.
Вот такую простую и топорную систему я ввёл в одну из своих игр. SARSA нанимает в игре юнитов, и адаптируется в случае изменения правил игры.
Кроме того, во всех видах обучения с подкреплением есть дисконтирование наград и дилемма explore/exploit.
Дисконтирование наград — это такой подход, когда RL старается максимизировать не сумму награду за следующие N ходов, а взвешенную сумму по принципу «100 рублей сейчас лучше, чем 110 через год». Например, если дисконтирующий множитель равен 0.9, а горизонт планирования равен 3, то модель мы будем обучать не на суммарном R за 3 следующих такта, а на R1*0.9+R2*0.81+R3*0.729. Зачем это надо? Затем, что ИИ, создающий профит где-то там на бесконечности, нам не нужен. Нам нужен ИИ, создающий профит примерно здесь и сейчас.
Дилемма explore/exploit. Если RL будет делать то, что его модель полагает оптимальным, он так и не узнает, были ли какие-то стратегии получше. Exploit — это стратегия, при которой RL делает то, что обещает максимум награды. Explore — это стратегия, при которой RL делает что-то, что позволяет исследовать окружающую среду в поисках лучших стратегий. Как реализовать эффективную разведку? Например, можно каждые несколько тактов делать случайное действие. Или можно сделать не одну предсказательную модель, а несколько со слегка разными настройками. Они будут выдавать разные результаты. Чем больше различие, тем больше степень неопределённости данного варианта. Можно сделать, чтобы действие выбиралось таким, чтобы у него максимальной была величина: M+k*std, где M — это средний прогноз всех моделей, std — это стандартное отклонение прогнозов, а k — это коэффициент любопытства.
В чём недостатки?
Допустим, у нас есть варианты. Поехать к цели (которая в 10 км от нас, и дорога до неё хорошая) на автомобиле или пойти пешком. А потом, после этого выбора, у нас есть варианты — двигаться осторожно или пытаться врезаться в каждый столб.
Человек тут же скажет, что обычно лучше ехать на машине и вести себя осмотрительно.
А вот SARSA… Он будет смотреть, к чему раньше приводило решение ехать на машине. А приводило оно вот к чему. На этапе первичного набора статистики ИИ где-то в половине случаев водил безрассудно и разбивался. Да, он умеет водить хорошо. Но когда он выбирает, ехать ли на машине, он не знает, что он выберет следующим ходом. У него есть статистика — дальше в половине случаев он выбирал адекватный вариант, а в половине — самоубийственный. Поэтому в среднем лучше идти пешком.
SARSA полагает, что агент будет придерживаться то же стратегии, которая была использована для заполнения таблицы. И действует, исходя из этого. Но что, если предположить иное — что агент будет придерживаться наилучшей стратегии в следующие ходы?
Q-Learning
Эта модель рассчитывает для каждого состояния максимально достижимую из него суммарную награду. И записывает её в специальный столбец Q. То есть если из состояния S можно получить 2 очка или 1, в зависимости от хода, то Q(S) будет равно 2 (при глубине прогнозирования 1). Какую награду можно получить из состояния S, мы узнаём из прогнозной модели Y(S,A). (S — состояние, A — действие).
Затем мы создаём прогнозную модель Q(S,A) — то есть в состояние с каким Q мы перейдём, если из S выполним действие A. И создаём в таблице следующий столбец — Q2. То есть максимальное Q, которое можно получить из состояния S (перебираем все возможные A).
Затем мы создаём регрессионную модель Q3(S,A) — то есть в состояние с каким Q2 мы перейдём, если из S выполним действие A.
И так далее. Таким образом мы можем добиваться неограниченной глубины прогнозирования.
На картинке R — это подкрепление.
А затем каждый ход мы выбираем то действие, которое обещает наибольшее Qn. Если бы мы применяли этот алгоритм к шахматам, получалось бы что-то вроде идеального минимакса. Что-то, почти эквивалентное просчёту ходов на большую глубину.
Бытовой пример q-learning-поведения. У охотника есть копьё, и он с ним идёт на медведя, по собственной инициативе. Он знает, что подавляющее большинство его будущих ходов имеет очень большой отрицательный реворд (способов проиграть намного больше, чем способов победить), на знает, что есть и ходы с положительным ревордом. Охотник полагает, что в будущем он станет делать именно наилучшие ходы (а не неизвестно, какие, как в SARSA), а если делать наилучшие ходы, то медведя он победит. То есть для того, чтобы пойти на медведя, ему достаточно уметь делать каждый элемент, нужный на охоте, но необязательно иметь опыт непосредственного успеха.
Если бы охотник действовал в стиле SARSA, он бы предполагал, что его действия в будущем будут примерно такими же, как раньше (несмотря но то, что сейчас у него уже другой багаж знаний), и на медведя пойдёт, только если он уже ходил на медведя и побеждал, например, в >50% случаев (ну или если другие охотники в более чем половине случаев побеждали, если он учится на их опыте).
В чём недостатки?
- Модель плохо справляется с изменчивой реальностью. Если всю жизнь нас награждали за нажатие красной кнопки, а теперь наказывают, причём никаких видимых изменений не произошло… QL будет очень долго осваивать эту закономерность.
- Qn может быть очень непростой функцией. Например, для её расчёта надо прокрутить цикл из N итераций — и быстрее не выйдет. А прогнозная модель обычно имеет ограниченную сложность — даже у крупной нейросети есть предел сложности, а циклы крутить почти ни одна модель машинного обучения не умеет.
- У реальности обычно бывают скрытые переменные. Например, который сейчас час? Это легко узнать, если мы смотрим на часы, но как только мы отвели взгляд — это уже скрытая переменная. Чтобы учитывать эти ненаблюдаемые величины, нужно, чтобы модель учитывала не только текущее состояние, но и какую-то историю. В QL можно это сделать — например, подавать в нейронку-или-что-у-нас-там не только текущее S, но и несколько предыдущих. Так сделано в RL, который играет в игры Атари. Кроме того, можно использовать для прогноза рекуррентную нейросеть — пусть она пробежится последовательно по нескольким кадрам истории и рассчитает Qn.
Model-based системы
А что, если мы будем прогнозировать не только R или Q, но вообще все сенсорные данные? У нас постоянно будет карманная копия реальности и мы сможем проверять на ней свои планы. В этом случае нас гораздо меньше волнует вопрос сложности вычисления Q-функции. Да, она требует на вычисление много тактов — ну так мы всё равно для каждого плана многократно запустим прогнозную модель. Планируем на 10 ходов вперёд? 10 раз запускаем модель, и каждый раз подаём её выходы ей же на вход.
В чём недостатки?
- Ресурсоёмкость. Допустим, на каждом такте нам нужно сделать выбор из двух альтернатив. Тогда за 10 тактов у нас соберётся 2^10=1024 возможных плана. Каждый план — это 10 запусков модели. У если мы управляем самолётом, у которого десятки управляющих органов? А реальность мы моделируем с периодом в 0.1 секунды? А горизонт планирования хотим иметь хотя бы пару минут? Нам придётся очень много раз запускать модель, выходит очень много процессорных тактов на одно решение. Даже если как-то оптимизировать перебор планов — всё равно вычислений на порядки больше, чем в QL.
- Проблема хаоса. Некоторые системы устроены так, что даже малая неточность симуляции на входе приводит к огромной погрешности на выходе. Чтобы этому противостоять, можно запускать несколько симуляций реальности — чуть-чуть разных. Они выдадут сильно различающиеся результаты, и по этому можно будет понять, что мы находимся в зоне такой вот неустойчивости.
Метод перебора стратегий
Если у нас есть доступ к тестовой среде для ИИ, если мы его запускаем не в реальности, а в симуляции, то можно в какой-то форме записать стратегию поведения нашего агента. А затем подобрать — эволюцией или чем-то ещё — такую стратегию, что ведёт к максимальному профиту.
«Подобрать стратегию» значит, что нам вначале надо научиться записывать стратегию в такой форме, чтобы её можно было запихивать в алгоритм эволюции. То есть мы можем записать стратегию программным кодом, но в некоторых местах оставить коэффициенты, и пусть эволюция их подбирает. Либо мы можем записать стратегию нейросетью — и пусть эволюция подбирает веса её связей.
То есть никакого прогноза тут нет. Никакой SAR-таблицы. Мы просто подбираем стратегию, а она сразу выдаёт Actions.
Это мощный и эффективный метод, если вы хотите попробовать RL и не знаете, с чего начать — рекомендую. Это очень дешёвый способ «увидеть чудо».
В чём недостатки?
- Требуется возможность прогонять одни и те же эксперименты по много раз. То есть у нас должна быть возможность перемотать реальность в начальную точку — десятки тысяч раз. Чтобы попробовать новую стратегию.
Жизнь редко предоставляет такие возможности. Обычно если у нас есть модель интересующего нас процесса, мы можем не создавать хитрую стратегию — мы можем просто составить план, как в model-based подходе, пусть даже тупым перебором. - Непереносимость опыта. У нас есть SAR-таблица по годам опыта? Мы можем о ней забыть, она никак не вписывается в концепцию.
Метод перебора стратегий, но «на живую»
Тот же перебор стратегий, но на живой реальности. Пробуем 10 тактов одну стратегию. Потом 10 тактов другую. Потом 10 тактов третью. Потом отбираем ту, где подкрепление было больше.
Наилучшие результаты по ходячим гуманоидам получены именно этим методом.
Для меня это звучит несколько неожиданно — казалось бы, QL + Model-Based подход математически идеальны. А вот ничего подобного. Плюсы у подхода примерно те же, что и у предыдущего — но они слабее выражены, так как стратегии тестируются не очень долго (ну нет у нас тысячелетий на эволюцию), а значит, результаты неустойчивые. Кроме того, число тестов тоже нельзя задрать в бесконечность — а значит, стратегию придётся искать в не очень сложном пространстве вариантов. Мало у неё будет «ручек», которые можно «подкрутить». Ну и непереносимость опыта никто не отменял. И, по сравнению с QL или Model-Based, эти модели используют опыт неэффективно. Им надо намного больше взаимодействий с реальностью, чем подходам, использующим машинное обучение.
Как можно увидеть, любые попытки создать AGI по идее, должны содержать в себе либо машинное обучение для прогноза наград, либо некую форму параметрической записи стратегии — так, чтобы можно было эту стратегию подобрать чем-то типа эволюции.
Это сильный выпад в сторону людей, предлагающих создавать ИИ на основе баз данных, логики и понятийных графов. Если вы, сторонники символьного подхода, это читаете — добро пожаловать в комментарии, я рад буду узнать, что можно сделать AGI без вышеописанных механик.
Модели машинного обучения для RL
Для обучения с подкреплением можно использовать чуть ли не любые модели ML. Нейросети — это, конечно, хорошо. Но есть, например, KNN. Для каждой пары S и A ищем наиболее похожие, но в прошлом. И ищем, какие после этого будут R. Тупо? Да, но это работает. Есть решающие деревья — тут лучше погулить по ключевым словам «градиентный бустинг» и «решающий лес». Деревья плохо умеют улавливать сложные зависимости? Используйте feature engeneering. Хотите, чтобы ваш AI был поближе к General? Используйте автоматический FE! Переберите кучу различных формул, подайте их в качестве фичей для вашего бустинга, отбросьте формулы, увеличивающие погрешность и оставьте формулы, улучшающие точность. Потом подайте наилучшие формулы в качестве аргументов для новых формул, ну и так далее, эволюционируйте.
Можно для прогноза использовать символьные регрессии — то есть просто перебирать формулы в попытках получить что-то, что будет хорошо апроксимировать Q или R. Можно попробовать перебирать алгоритмы — тогда получится штука, которая называется индукцией Соломонова, это теоретически оптимальный, но практически очень труднообучаемый способ апроксимации функций.
Но нейросети обычно являются компромиссом между выразительностью и сложностью обучения. Алгоритмическая регрессия идеально подберёт любую зависимость — за сотни лет. Решающее дерево отработает очень быстро — но уже y=a+b экстраполировать не сможет. А нейросеть — это что-то среднее.
Перспективы развития
Какие сейчас вообще есть способы сделать именно AGI? Хотя бы теоретически.
Эволюция
Мы можем создать много различных тестовых сред и запустить эволюцию некоей нейросетки. Размножаться будут те конфигурации, которые набирают больше очков в сумме по всем испытаниям.
Нейросетка должна иметь память и желательно бы иметь хотя бы часть памяти в виде ленты, как у машины Тьюринга или как на жёстком диске.
Проблема в том, что с помощью эволюции вырастить что-то типа RL, конечно, можно. Но как должен выглядеть язык, на котором RL выглядит компактно — чтобы эволюция его нашла — и в то же время чтобы эволюция не находила решений типа «а создам-ка я нейронку на стопятьсот слоёв, чтоб вы все чокнулись, пока я её обучаю!». Эволюция же как толпа неграмотных пользователей — найдёт в коде любые недоработки и угробит всю систему.
AIXI
Можно сделать Model-Based систему, основанную на пачке из множества алгоритмических регрессий. Алгоритм гарантированно полон по Тьюрингу — а значит, не будет закономерностей, которые нельзя подобрать. Алгоритм записан кодом — а значит, можно легко рассчитать его сложность. А значит, можно математически корректно штрафовать свои гипотезы устройства мира за сложность. С нейросетями, например, этот фокус не пройдёт — там штраф за сложность проводится очень косвенно и эвристически.
Осталось только научиться быстро обучать алгоритмические регрессии. Пока что лучшее, что для этого есть — эволюция, а она непростительно долгая.
Seed AI
Было бы круто создать ИИ, который будет улучшать сам себя. Улучшать свою способность решать задачи. Это может показаться странной идеей, но это задача уже решена для систем статической оптимизации, типа эволюции. Если получится это реализовать… Про экспоненту все в курсе? Мы получим очень мощный ИИ за очень короткое время.
Как это сделать?
Можно попробовать устроить, чтобы у RL часть actions влияли на настройки самого RL.
Либо дать системе RL некоторый инструмент для создания себе новых пред- и пост-обработчиков данных. Пусть RL будет тупеньким, но будет уметь создавать себе калькуляторы, записные книжки и компьютеры.
Ещё вариант — создать с помощью эволюции некий ИИ, у которого часть actions будут влиять на его устройство на уровне кода.
Но на данный момент я не видел работоспособных вариантов Seed AI — пусть даже сильно ограниченных. Разработчики скрывают? Или эти варианты настолько слабые, что не заслужили всеобщего внимания и прошли мимо меня?
Впрочем, сейчас и Google, и DeepMind работают в основном с нейросетевыми архитектурами. Видимо, они не хотят связываться с комбинаторным перебором и стараются любые свои идеи сделать пригодными к методу обратного распространения ошибки.
Надеюсь, эта обзорная статья оказалась полезна =) Комментарии приветствуются, особенно комментарии вида «я знаю, как лучше сделать AGI»!




