
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Рынок маркетплейсов развивается независимо от платформы, на которой работают онлайн-магазины. Необходимость в формировании полного спектра услуг пока еще остается неудовлетворенной, особенно, когда речь заходит о выборе лекарств или косметики. Решить основные проблемы, с которыми сталкиваются многочисленные сайты, должны рекомендательные системы, разработанные на основе искусственного интеллекта. Как это должно происходить, можно рассмотреть на предмете магазинов, предлагающих всевозможные кремы, лосьоны, косметику и средства по уходу за кожей.
Для таких случаев неплохо подходит принцип коллаборативной фильтрации, который выстраивает прогнозы, основываясь на уже известных предпочтениях, и дает рекомендации еще неизвестных предпочтений совсем других пользователей. Принцип прост – однажды данная оценка явления или товара, оставленная ранее, является базисом для схожих оценок других явлений и товаров в будущем. Плюсом коллаборативной фильтрации является ее индивидуальная «заточенность» под каждого клиента, несмотря на то, что информационное обоснование для прогноза собрана из ответов тысяч других людей.
При таком подходе используются три метода создания рекомендательных систем. Первый – коллаборативная фильтрация, второй – контентно-основанные рекомендации, третий – гибридный.
Выглядит вся рекомендательная система при этом таким образом.
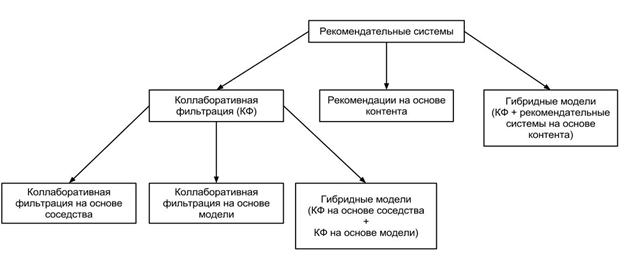
Принцип работы основанный на соседстве позволяет в случае каждого запроса подбирать группу схожих – оценки и весы ложатся в основу для составления прогноза. Процесс подбора рекомендации выглядит таким образом, рассмотрим основные шаги:
каждому пользователю присваивается вес, исходя из его активности и оценок;
производится выборка пользователей (соседей) с максимальным весом схожести активного пользователя;
подсчитывается вероятность тех или иных оценок активного пользователя пока еще не оцененных им товаров и явлений, основываясь на оценках соседей.
Метод, основанный на данной модели, измеряет параметры статмоделей с помощью метода байесовских сетей, латентной семантической модели, сингулярного разложения, скрытого распределения Дирихле, марковского процесса принятия решения на основе моделей, кластеризации. Разработка моделей производится в процессе интеллектуального анализа данных и машинного обучения. Результатом является обнаружение закономерностей на основе обучающих данных. Этот подход более точный, так как лучше обрабатываются разреженные матрицы, что улучшает процесс масштабирования больших наборов данных. Гибридный метод наиболее распространен при создании рекомендательных систем, но дорог в реализации и использовании с точки зрения большого количества вычислений.
Получить численное выражение рекомендации от множества пользователей – одна из задач. Делается при помощи выстраивания оценки каждого пользователя, выбранного числа товаров в вектор. После чего производится сравнение этого вектора с вектором других пользователей в рамках заданной выборки товаров. Сравнение можно проводить при помощи коэффициента корреляции Пирсона, Евклидового расстояния, косинусной меры и других методов. Наиболее подходящим и доступным является косинусная мера. При использовании косинусной меры рассчитывается это косинус угла между двумя векторами. Одним словом, достаточно будет заглянуть в учебник алгебры и начать высчитывать по формуле:

За счет коллаборативной фильтрации можно будет оптимизировать данные. Но лучше сокращать строки названий и использовать числовые идентификаторы товаров, а не названия. Чтобы сократить часть расходов можно делить пользователей на категории, высчитывать только меры схожести в рамках одной категории. Также важно транспонировать матрицу и рассчитать наиболее схожие продукты при помощи косинусной меры. При этом выбор меры следует производить лишь при наличии результатов анализа данных.
Кто первый?
Прорывной должна стать программа, которая по фотографиям будет способна определить не только цветовую гамму и тип кожи клиента, но и возможные реакции организма на то или иное средство. Чтобы решить эту непростую задачу искусственный интеллект должен обладать способностью проводить глубокое ранжирование данных при анализе фотографий, автоматически создавать виртуальную модель состава кожи, структуры волос, особенностей пигментации при воздействии солнечных лучей, мороза, различных видах освещения и в других внешних условиях.
Попытки создать нечто подобное уже предпринимались, но назвать их удачными нельзя. Алгоритмы «путали» предпочтения пользователей, предлагали не вполне подходящие кремы и мази, показывали неплохую эффективность при работе только со светлыми оттенками кожи.
Для быстрого и эффективного поиска товаров искусственный интеллект должен работать по эффективному детализированному алгоритму обучения. Успешно решить эту задачу может сеть нейронная Хопфилда, которая составляет задаваемые образы за счет отклика на зафиксированные эталонные «образы». При этом сеть восстанавливает «образы» при искажениях и «корректирует» их в рамках запрашиваемых оригиналов. Нейроны в сети Хопфилда принимают на входе и выходе одно из двух возможных состояний, и по этой причине ее часто называют «спиной» - нейроны взаимосвязаны, работа основана на весовых коэффициентах и за счет этого формируется итоговая матрица. Эта матрица запоминает «образы»-эталоны в виде бинарных векторов и формирует отклик системы на входящие запросы после серии итераций.
Матрица симметричная с элементами, равными нулю, что в определенной мере не позволяет нейрону самоискажаться, но на достаточном уровне обеспечивается асинхронный режим работы.
Весовая матрица работает таким образом: сигнал с 15 параметрами преобразуется на одном уровне с 15 нейронами, каждый из которых связан с 14 другими нейронами. В итоге образуется 210 (15х14) связей, каждая из которых получает свой «вес» или весовой коэффициент. Собранные веса заполняют матрицу взаимодействий. Самообучение основано на взаимодействии весов в матрице – их расположение задают запоминаемые векторы, образующие память. Этот процесс должен соответствовать уравнению:
Xi = WXi
Состояния сети Х в этом случае устойчиво, что делает ее устойчивой.
При заданной бинарности векторов, расчет веса проводится таким образом:

N – это N размерность векторов, mm – число запоминаемых выходных векторов, dd — номер запоминаемого выходного вектора, XijXij — i-я компонента запоминаемого выходного j-го вектора. Расчет этих весовых коэффициентов и есть процесс обучения сети.
Таким образом в сеть Хопфилда закладываются параметры поиска с учетом личностных особенностей, специфики профессионального опыта, то пользователи могут отказаться от сервиса.
Главное – подробная консультация
Сегодня все понимают, что искусственный интеллект способен решить эту задачу, если будет правильно построен процесс онлайн-консультирования при помощи чат-ботов. Модерирование такой беседы должно сопровождаться автоматическим самообучением нейронных сетей. Но для этого потребуется собрать максимально большую базу неповторяющихся данных, научить И.И. генерировать репрезентации, чтобы устранить вероятность ошибок.
К примеру, программа запускается, и сразу «впитывает» сотни тысяч фотографий, сделанных при разном освещении, ракурсах. При появлении пользователя, процесс обучения продолжается, новые данные поступают в «копилку» и одновременно обрабатываются для выдачи рекомендации. Генерирующая сеть обучается высчитывать погрешности в реконструкции виртуального образа, форматирует изображения таким образом, чтобы можно было одновременно «подстраивать» под клиента весь объем данных. По сути, искусственный интеллект обучается самоконтролю, за счет учета многочисленных признаков, синтезируя изображения. Автоматический синтез изображений дробит их на тысячи категорий, из которых выстраиваются индивидуальные модели, наиболее подходящие исходной фотографии.
Безопасность
Рекомендательные системы такого типа заставляют серьезно задуматься о безопасности личных данных. Очевидно, что лидерами рынка онлайн-консультирования станут именно те компании, которые сумеют гарантировать хранение и защиту информации о своих клиентах. Для этого искусственный интеллект должен автоматически вырабатывать стратегию и тактику активной защиты. Такой подход позволит предотвращать атаки на серверы, а не «латать дыры» после того, как злоумышленники проникли в архивы.
Например, система выстраивает систему признаков, распознающих потенциальную угрозу – подозрительные IP-адреса, хеши вредоносных файлов и прочее. Все это соотносится с моделями поведения конкретных пользователей. И если будет замечена подозрительная активность в нетипичное время захода или из другой географической точки, то включится система отслеживания и безопасности. Такой подход более качественный и быстрый, так как хакеров блокируют в режиме реального времени за счет глубокого анализа потенциальной угрозы. То есть, искусственный интеллект постоянно создает новые варианты возможных атак со стороны злоумышленников и готовится к их отражению.




