
По следам своего доклада на конференции AI Journey, прошедшей 4 декабря, хочу рассказать вам, как правильное применение ИИ-систем в управлении сетью позволяет строить на базе решений Huawei современные центры обработки данных без узких мест и без потери пакетов. Выгоды от таких решений особенно наглядны, когда в ЦОДе эксплуатируются хранилища All-Flash, проводится обучение нейросетей или выполняются высокопроизводительные вычисления на GPU.

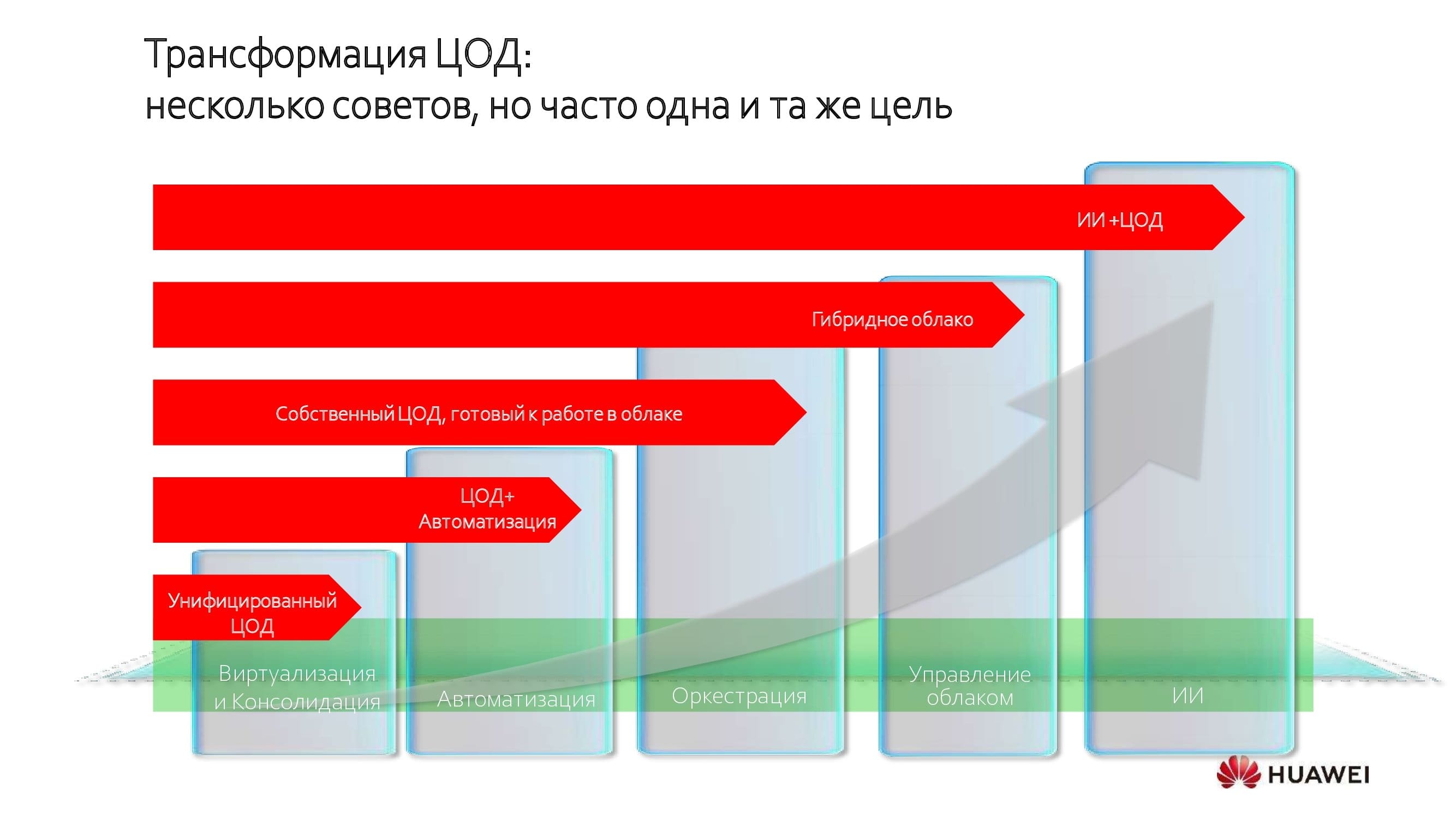
Центры обработки данных концептуально меняются, и меняются разительно. Относительно массовым тренд стал около десяти лет назад, однако, скажем, в банковской сфере начался гораздо раньше. Вне зависимости от выбранного пути цели преобразований более или менее сходные — унификация и консолидация ресурсов.
Это первый шаг, за которым следует дальнейшее повышение эффективности работы дата-центра путём автоматизации, оркестрации и перехода в режим гибридного облака. И самый дальний предел трансформации из досягаемых на сегодняшний день — внедрение систем искусственного интеллекта.
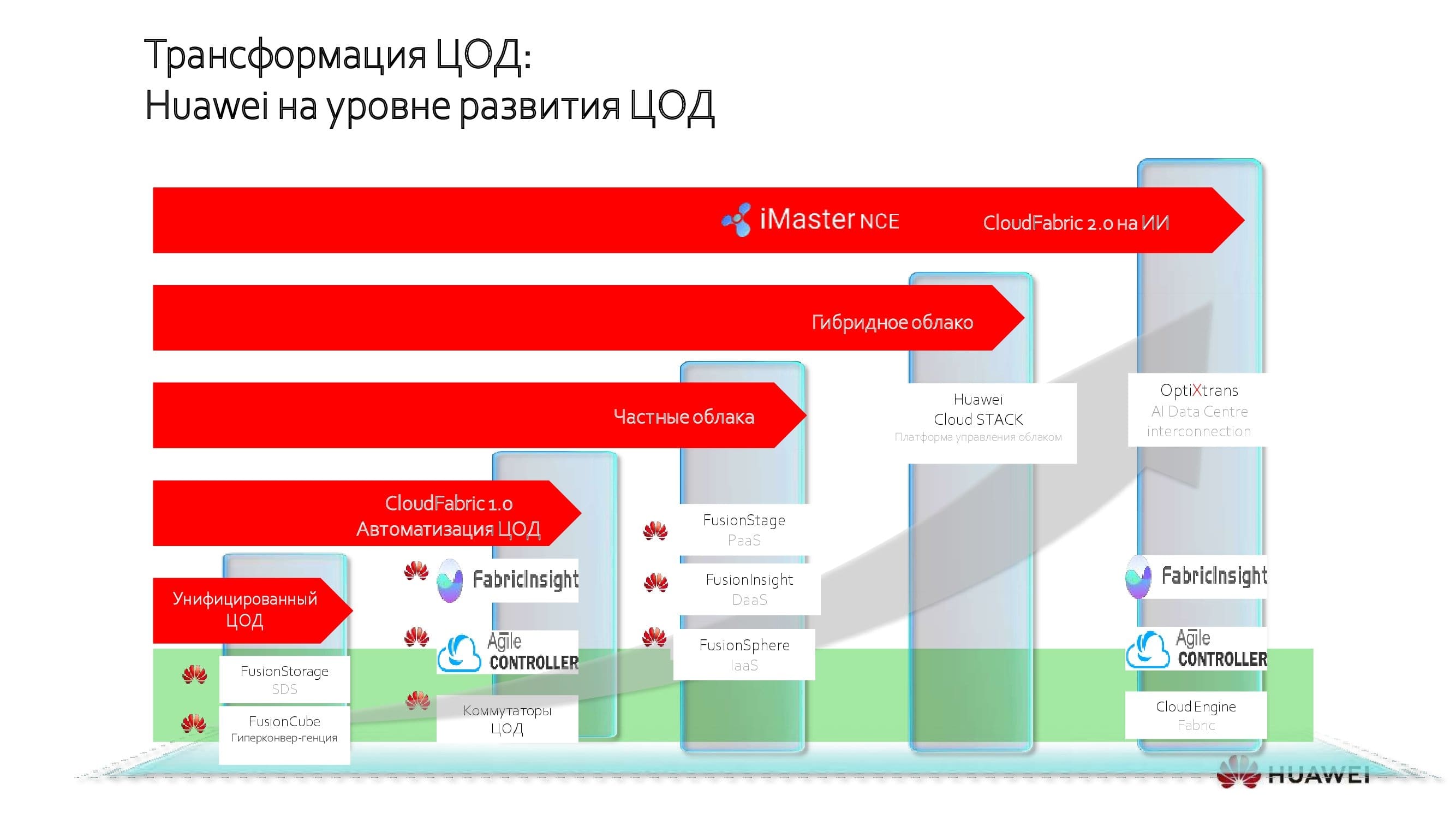
На каждой стадии в зависимости от «IT-зрелости» заказчика компания Huawei предлагает собственные решения, призванные обеспечить наилучший результат модернизации без лишних трат. Сегодня хотелось бы подробнее поговорить как раз о «вишенке на торте» — системах ИИ в современных ЦОДах.

Если провести аналогию с человеческим организмом, коммутаторы сети ЦОД выполняют роль системы кровообращения, обеспечивая связанность между различными компонентами: вычислительными узлами, системами хранения данных и т. д.
Буквально несколько лет назад технологии хранения данных на твердотельных дисках стали широко доступны, а производительность центральных процессоров продолжает расти. Благодаря этому хранилища и вычислительные узлы перестали быть главными причинам задержек. А вот сеть ЦОД долгое время оставалась в структуре дата-центров своего рода «младшим братом».
Производители пытались решить проблему по-разному. Кто-то выбирал для построения сети лицензированные технологии InfiniBand (IB). Сеть получалась специализированной и способной решать только узкопрофильные задачи. Кто-то предпочитал строить сетевые фабрики на протоколах Fibre Channel (FC). Оба подхода имели свои ограничения: либо пропускная способность сети оказывалась относительно скромной, либо общая цена решения кусалась, что вдобавок усугублялось зависимостью от одного вендора.
Наша компания пошла путём использования открытых технологий. В основу решений Huawei легла работа со второй версией RoCE, возможности которой были расширены за счёт использования дополнительных лицензируемых алгоритмов в наших коммутаторах. Это позволило серьёзно оптимизировать возможности сетей.
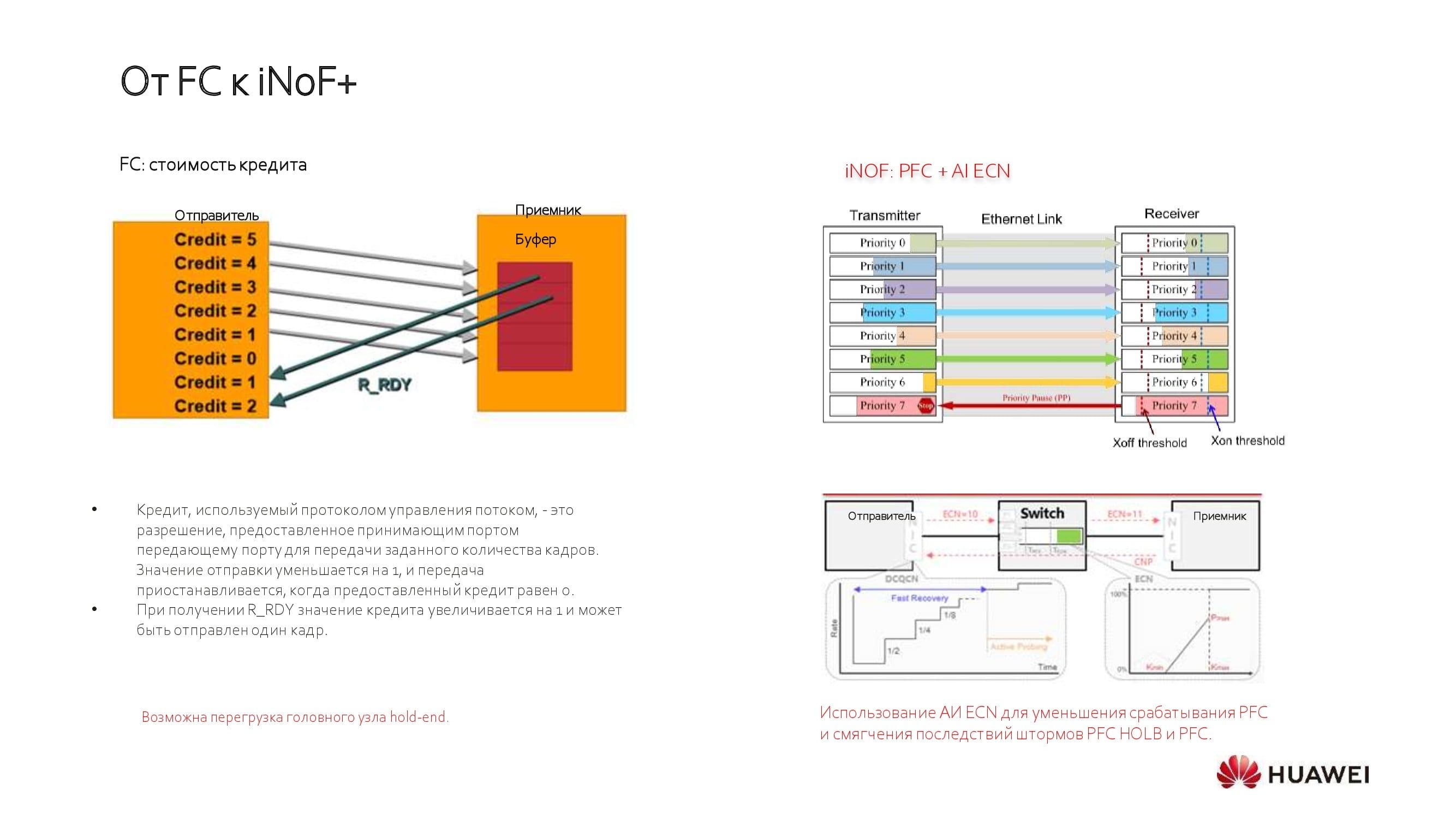
Почему мы не видим будущего за классическими FC-решениями? Дело в том, что они работают по принципу статического выделения кредитов, что требует настройки сетевой фабрики в соответствии с потребностями ваших приложений на ограниченный срез времени.
В последнее время FC шагнул вперёд к автономным сетям хранения данных, но продолжает нести в себе ограничения производительности. Сейчас мейнстрим — шестое поколение технологии, позволяющее добиться пропускной способности 32 Гбит/с, начинают внедряться и решения 64 Гбит/с. При этом с помощью Ethernet мы уже сегодня, используя таблицы приоритета, можем получить 100, 200 и даже 400 Гбит/с до сервера.
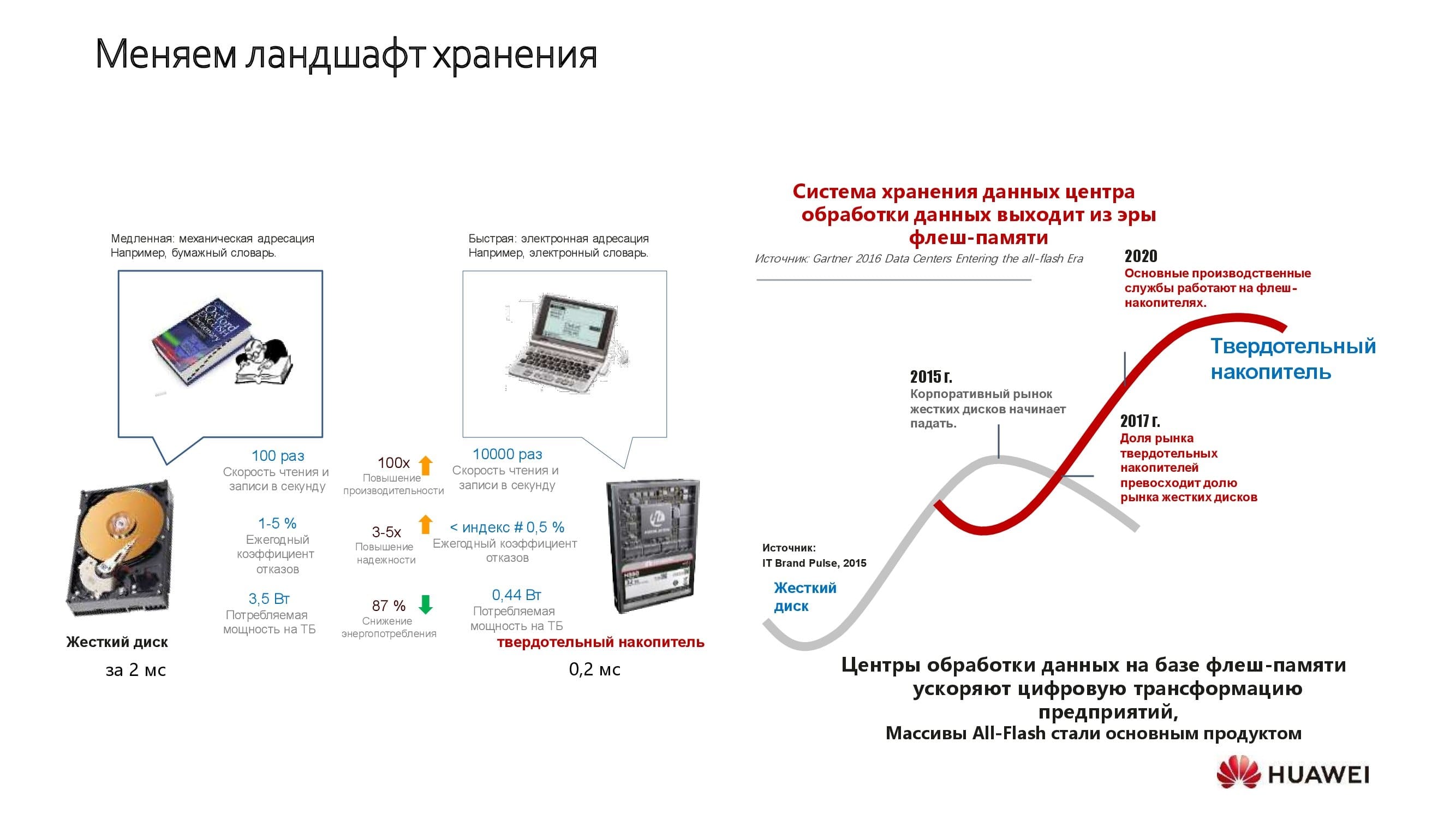
Дополнительные возможности сети ЦОД приобретают особое значение в мире, где твердотельные накопители со скоростными интерфейсами занимают всё большую долю рынка, вытесняя классические шпиндельные. Huawei стремится к тому, чтобы дать СХД на основе SSD полностью раскрыть свой потенциал.
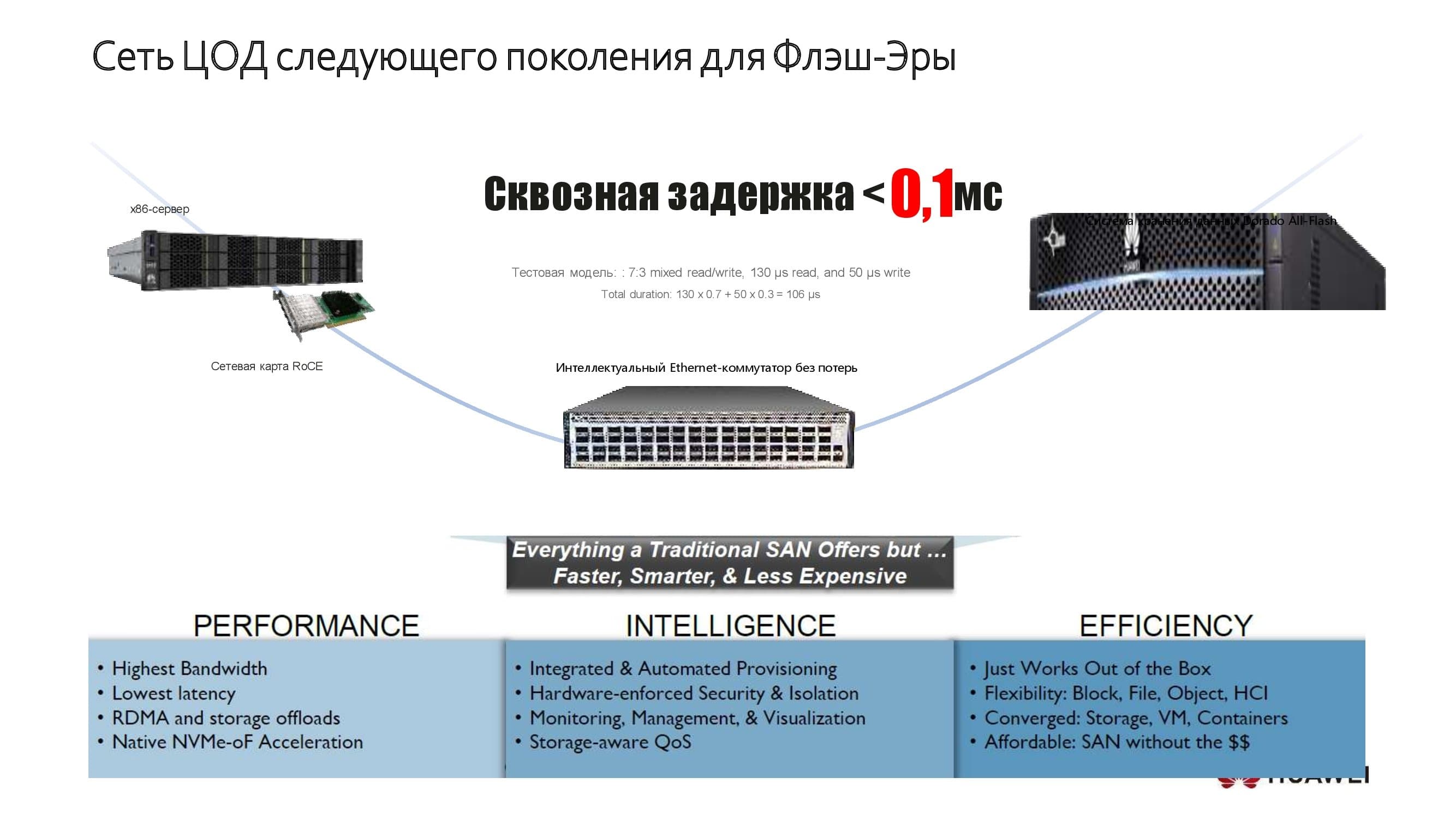
Небольшой пример того, как мы это делаем. На схеме изображена одна из наших систем хранения данных, признанных самыми быстрыми в мире. Здесь же показаны наши серверы, построенные на архитектуре x86 или ARM и демонстрирующие производительность на уровне ожиданий крайне требовательных клиентов. В ЦОДах на основе этих решений нам удаётся добиться сквозной задержки не более 0,1 мс. Получить такой результат нам помогает использование новых application-технологий.
Классические технологии, применяемые в СХД, были ограничены, в частности, достаточно высокими задержками, которые обуславливались шиной SAS. Переход на новые протоколы, такие как NVMe, позволил значительно улучшить этот параметр, и вместе с тем ограничивающим производительность фактором становилась сама сеть.
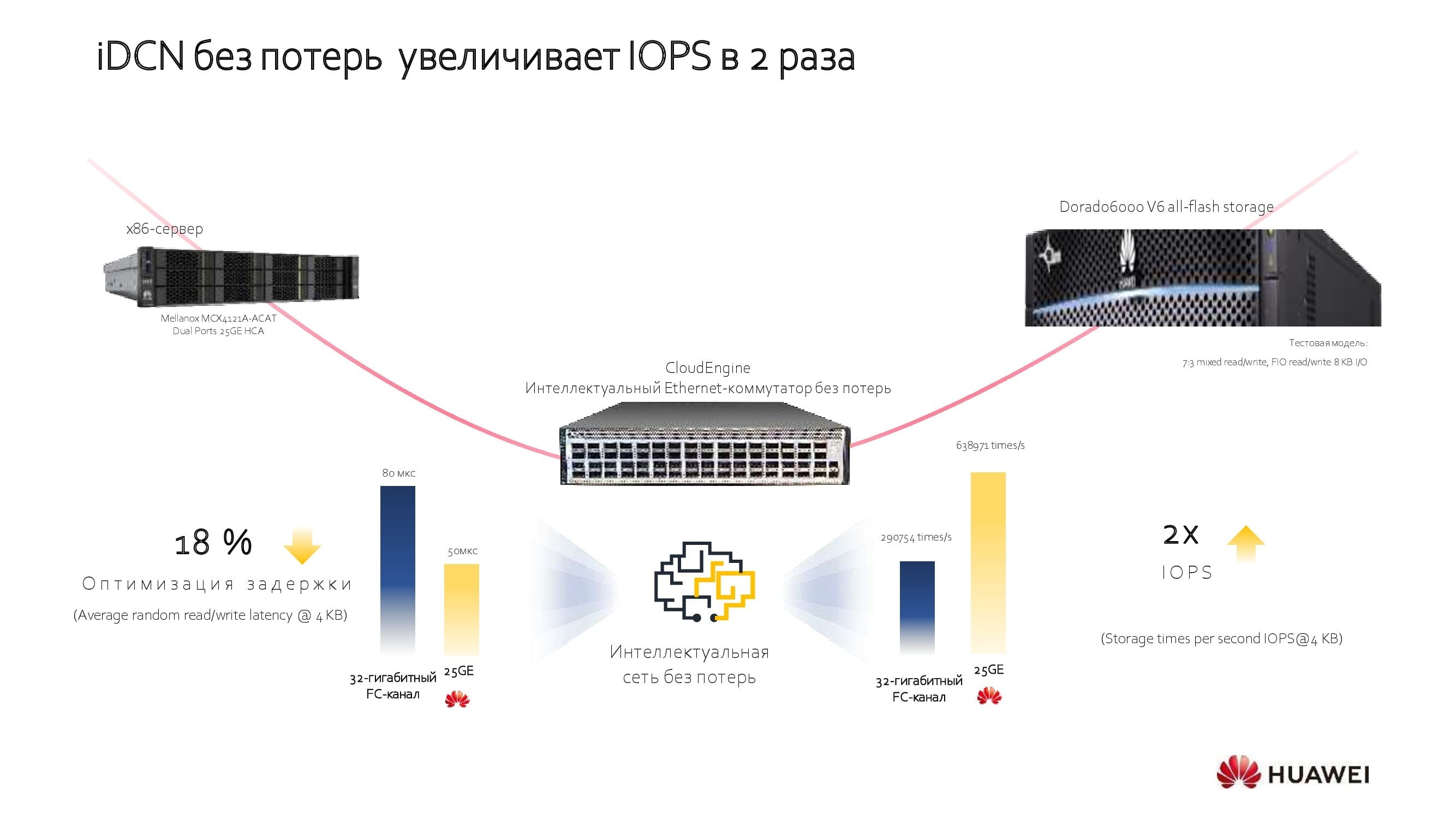
Рассмотрим в рамках этого же примера использование сетей с дополнительными лицензируемыми алгоритмами. Они позволяют оптимизировать сквозную задержку, существенно повысить пропускную способность сети и увеличить количество операций ввода-вывода на единицу времени. Такой подход помогает избежать «двойной закупки», подчас необходимой для достижения необходимых параметров производительности, а совокупная экономия (в измерении TCO) при внедрении новой сети достигает 18–40% в зависимости от моделей применяемого оборудования.
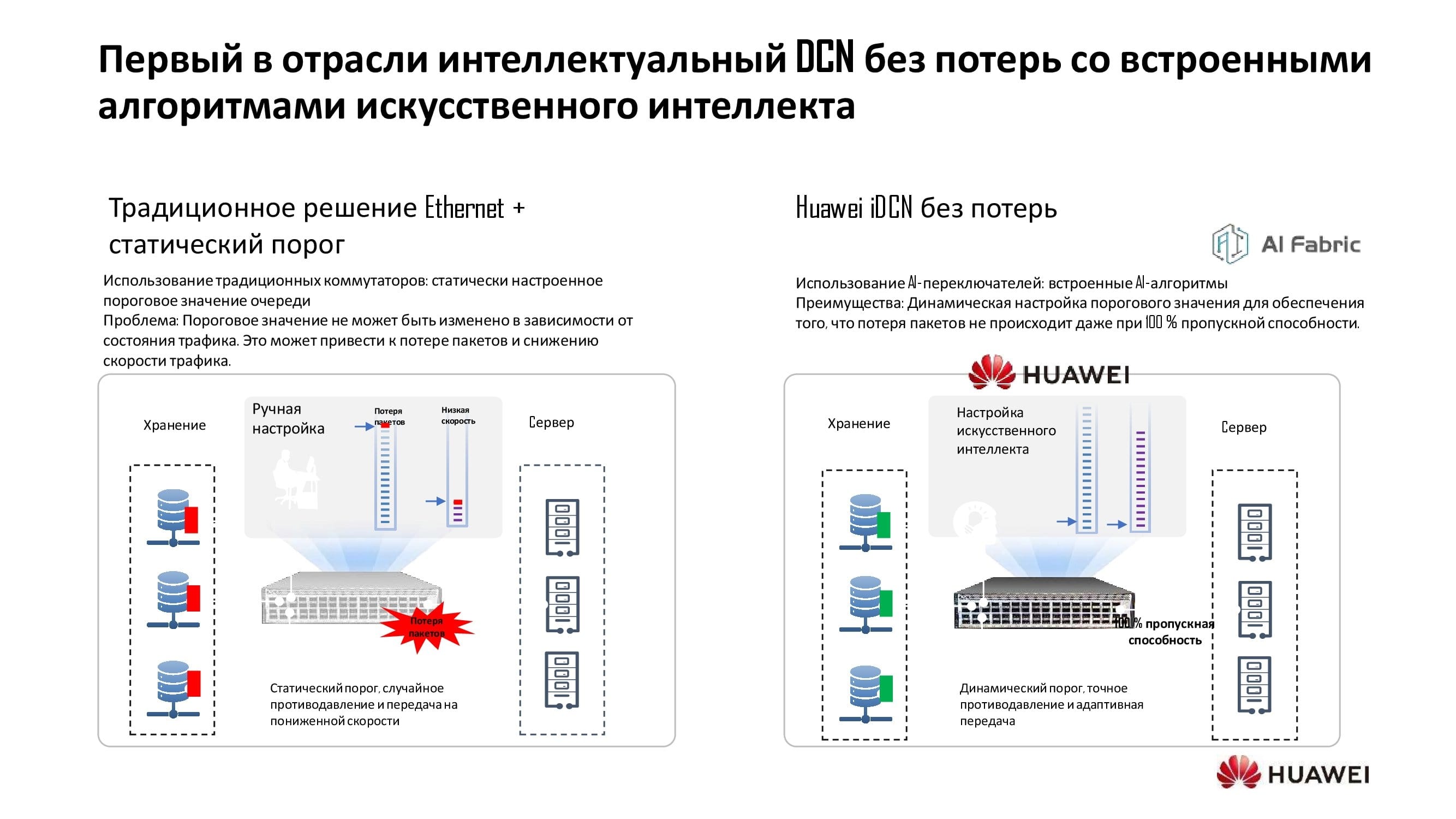
Привычные технологии несли с собой привычные же проблемы, так как работали со статическими пороговыми значениями очереди. Такой порог означал, что для всех приложений формировалась некое базовое соотношение между скоростью и задержкой. Ручной режим управления не давал обеспечить динамическую подстройку параметров сети.
Используя в коммутаторах дополнительные чипсеты машинного обучения, мы научили сеть работать в режиме, позволяющем строить интеллектуальные сети ЦОД без потерь пакетов (мы назвали его iDCN).
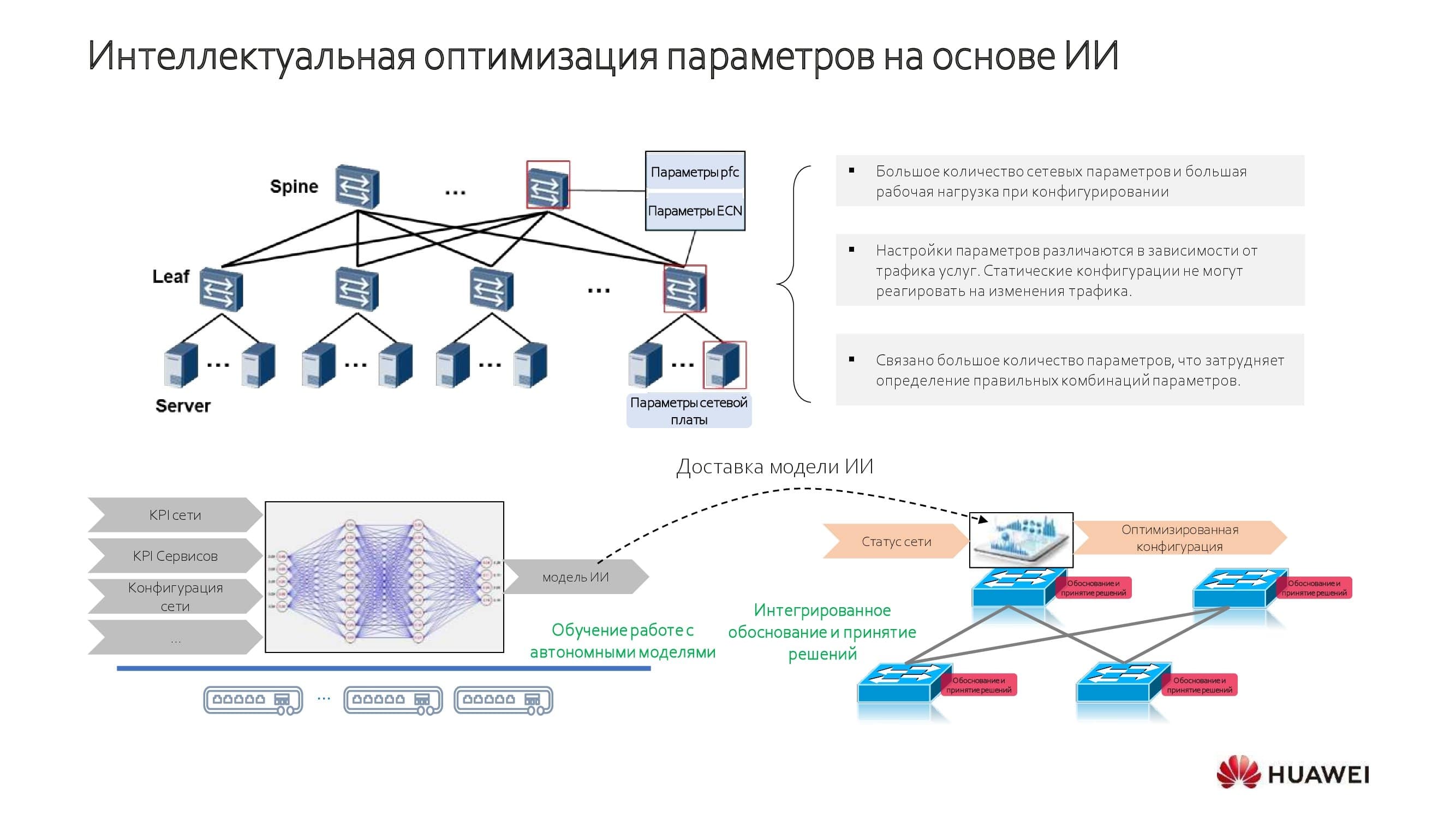
Как достигается интеллектуальная оптимизация? Те, кто занимается нейросетями, легко найдут на схеме знакомые элементы и механизмы training / inference. Наличие в наших решениях встроенных моделей сочетается со способностью обучаться на конкретной сети.
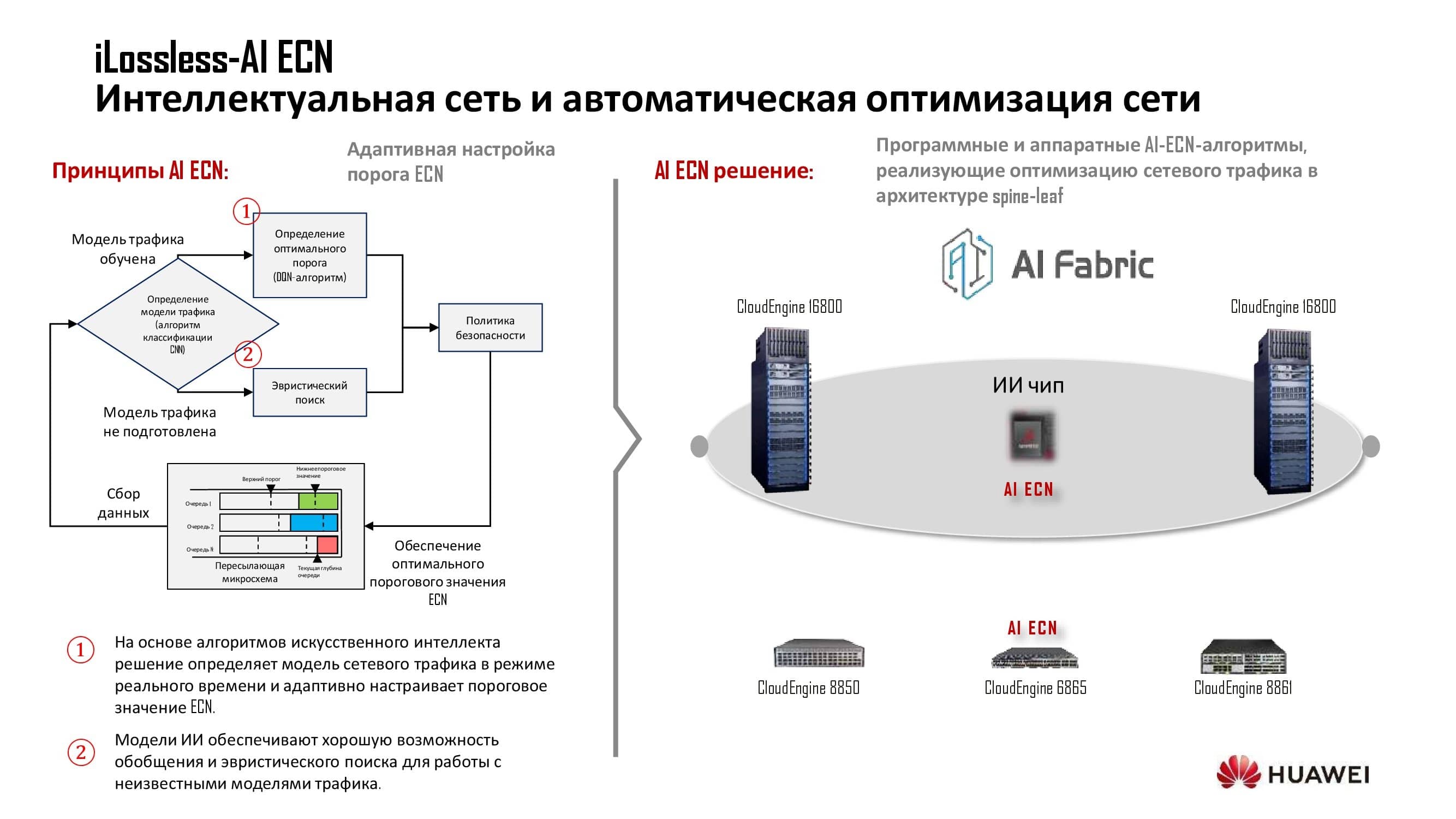
Система ИИ накапливает определённый объём знаний о сети, которые затем аппроксимируются и используются при динамической настройке сети. В устройствах на базе наших собственных аппаратных решений применяется специальный ИИ-чип. В моделях, построенных на лицензируемых чипсетах американских производителей, задействуются дополнительный модуль и программная шина.
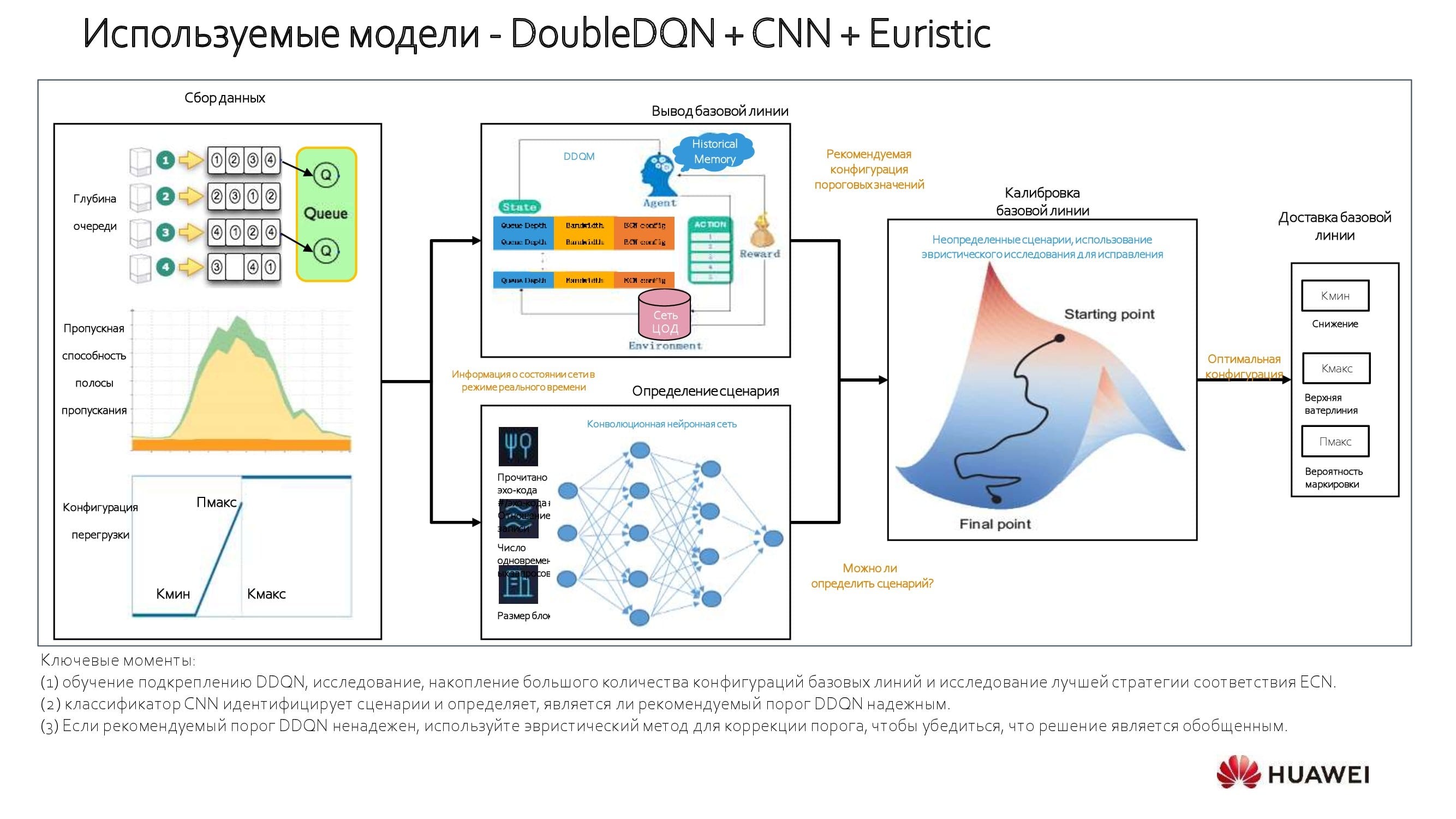
О применяемых моделях. Мы используем подход, который опирается на модель обучения с подкреплением. Система анализирует 100% проходящих через сетевое устройство данных и выбирает базовую линию. Если, к примеру, известны пропускная способность и те задержки, которые критичны для конкретного приложения, определить базовую линию не составляет труда. При большом количестве приложений можно проводить «медианные» вычисления и выполнять настройки в автоматическом режиме, ощутимо повышая производительность.

На схеме процесс представлен более подробно. На старте оптимизации сети мы производим вычисления пороговых значений — как минимальных, так и максимальных. Далее в дело вступает конволюционная нейронная сеть (CNN). Таким образом удаётся выровнять пропускную способность и коэффициенты задержек для каждого приложения, а также определить его общий «вес» в рамках сетевых сервисов. Используя такой стратифицированный подход, мы получаем действительно интересные выводы.
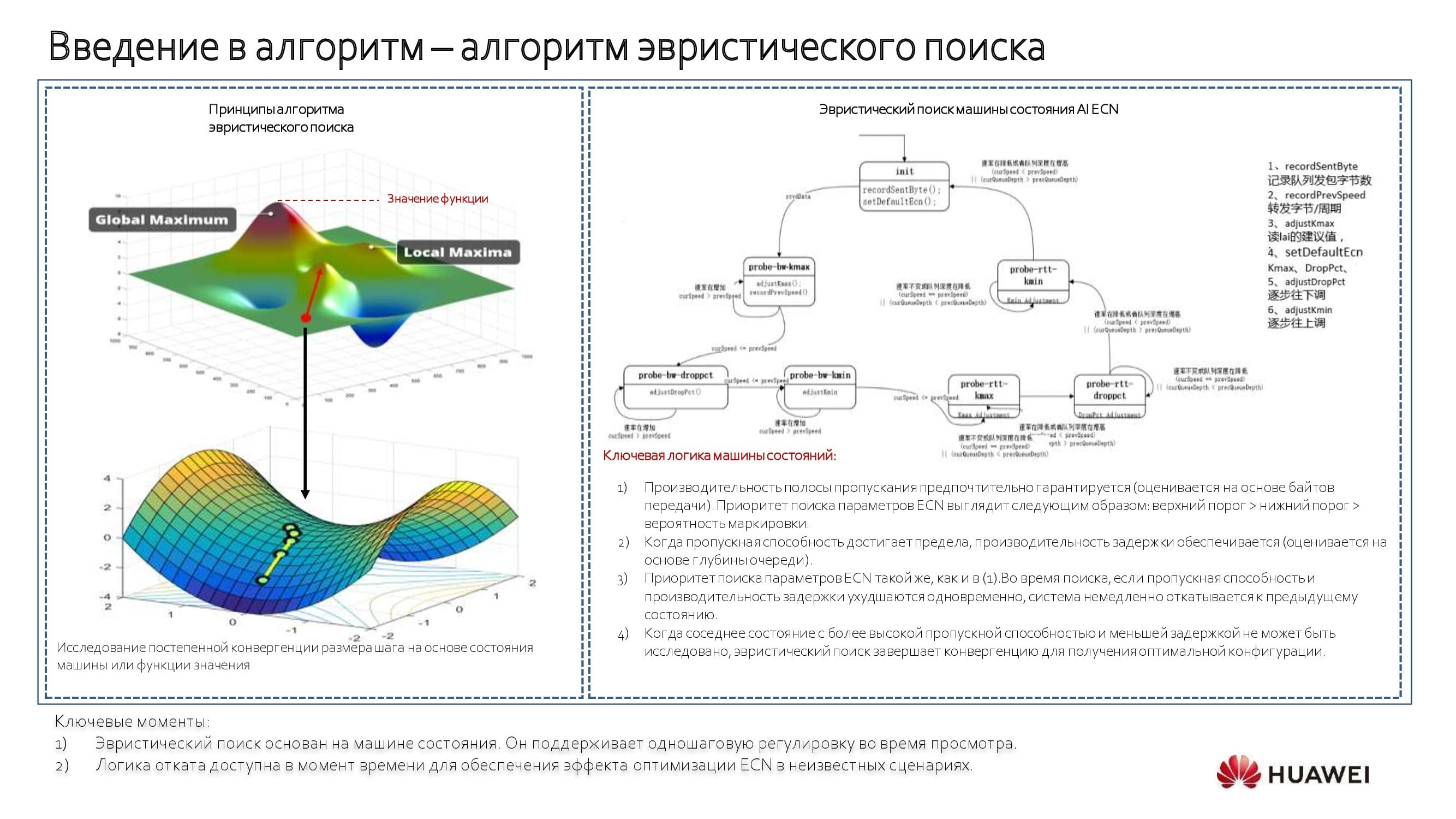
Когда приложение неизвестно, применяется алгоритм эвристического поиска в сочетании с «машиной состояний». С её помощью мы начинаем двигаться по изображённой выше блок-схеме против часовой стрелки, выявляя пороговые значения и строя модель. Это автоматический процесс, на который при необходимости можно оказывать управляющее воздействие. Если такой необходимости нет, проще положиться на коммутатор и его сервисы.
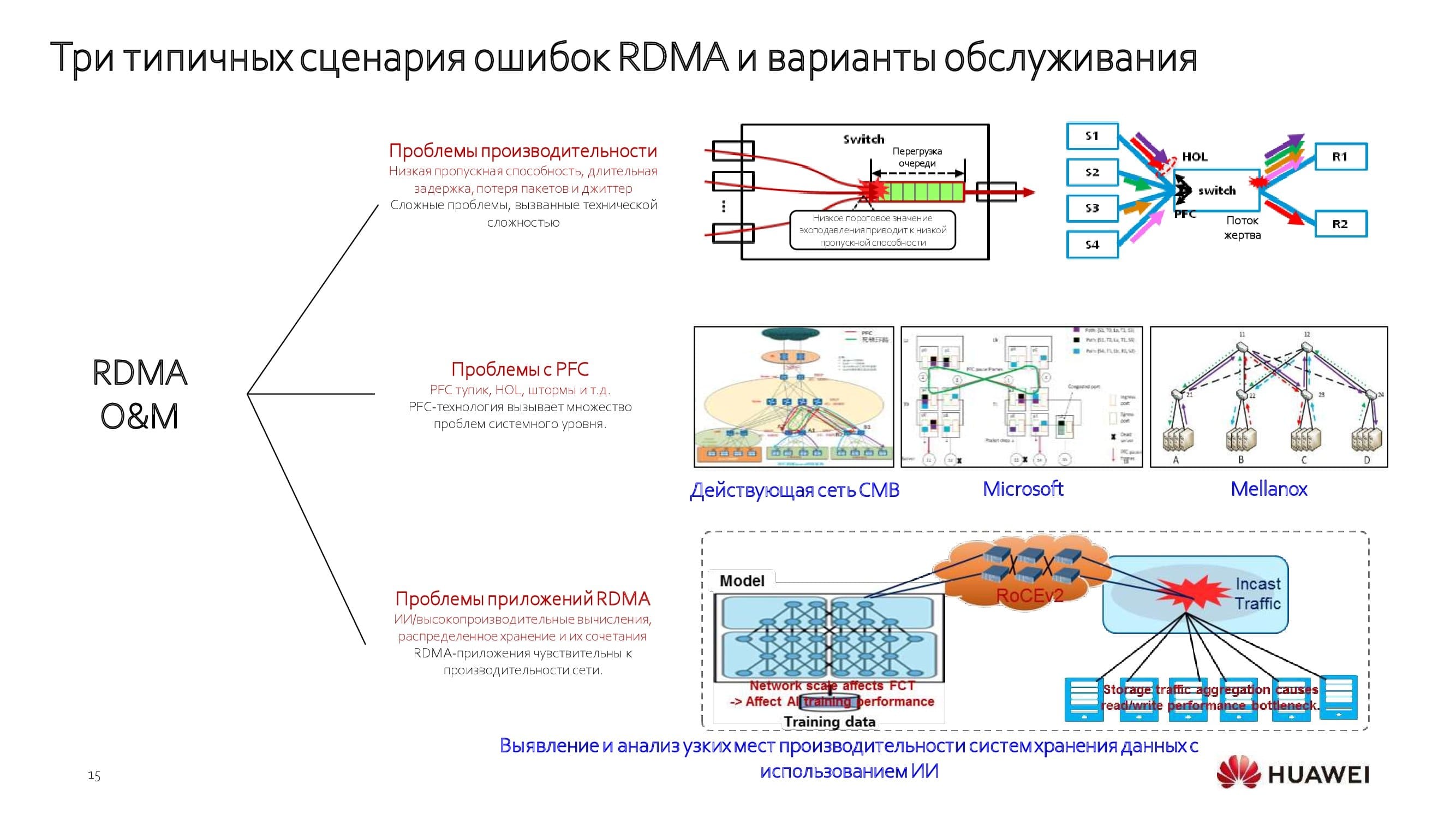
Применяя такие алгоритмы и работая на уровне всей сети, а не отдельных её срезов, мы решаем все основные проблемы производительности. Уже есть интересные кейсы внедрения и использования подобных технологий в банковской сфере. Востребованы эти механизмы и в других отраслях, например среди операторов связи.
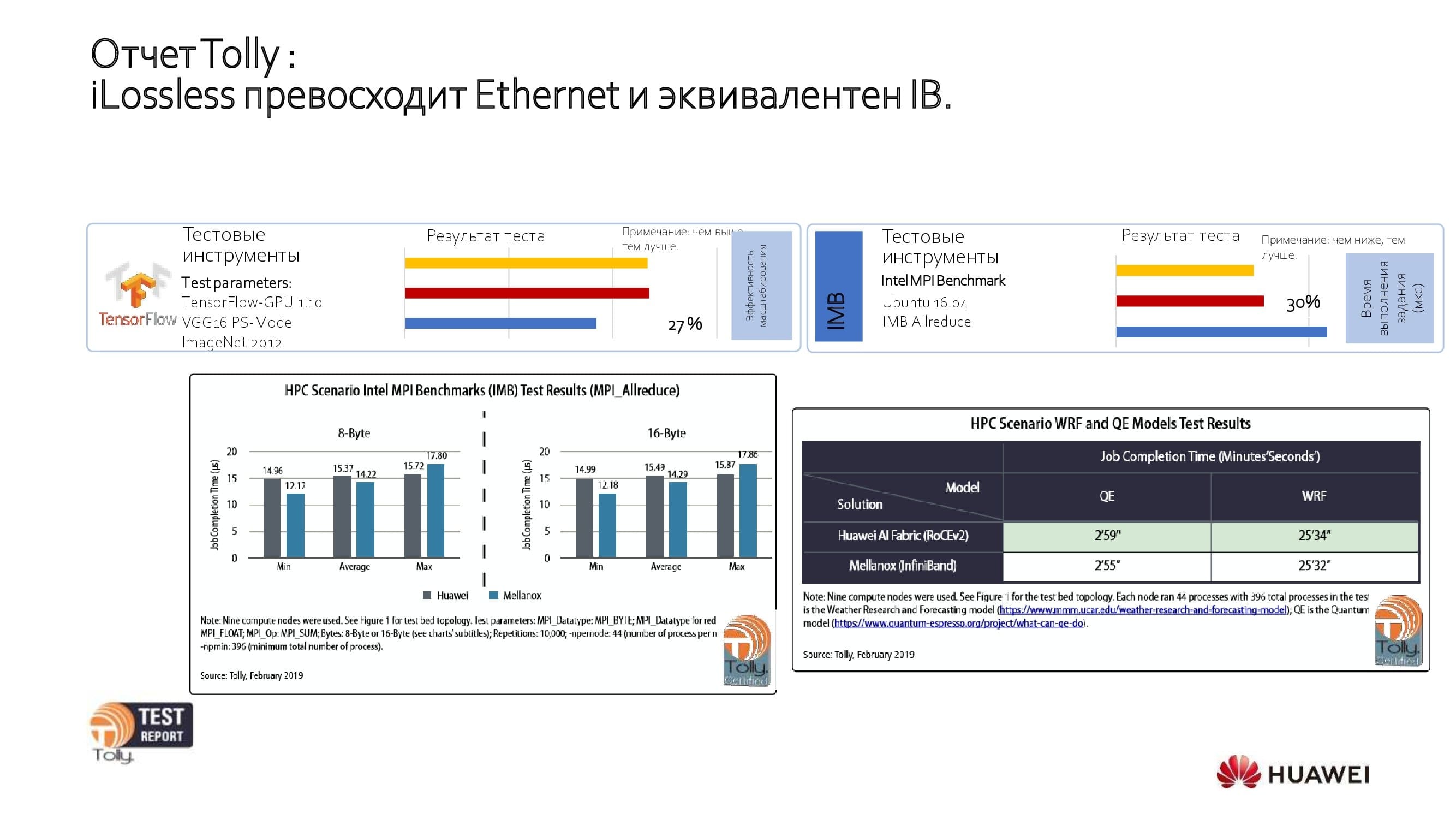
Обратимся к результатам открытых тестов. Независимая лаборатория The Tolly Group протестировала наше решение и сравнила его с решениями Ethernet и IB других производителей. Как показали испытания, производительность продукта Huawei эквивалентна возможностям IB и на 27% превосходит Ethernet-продукты других крупных производителей.
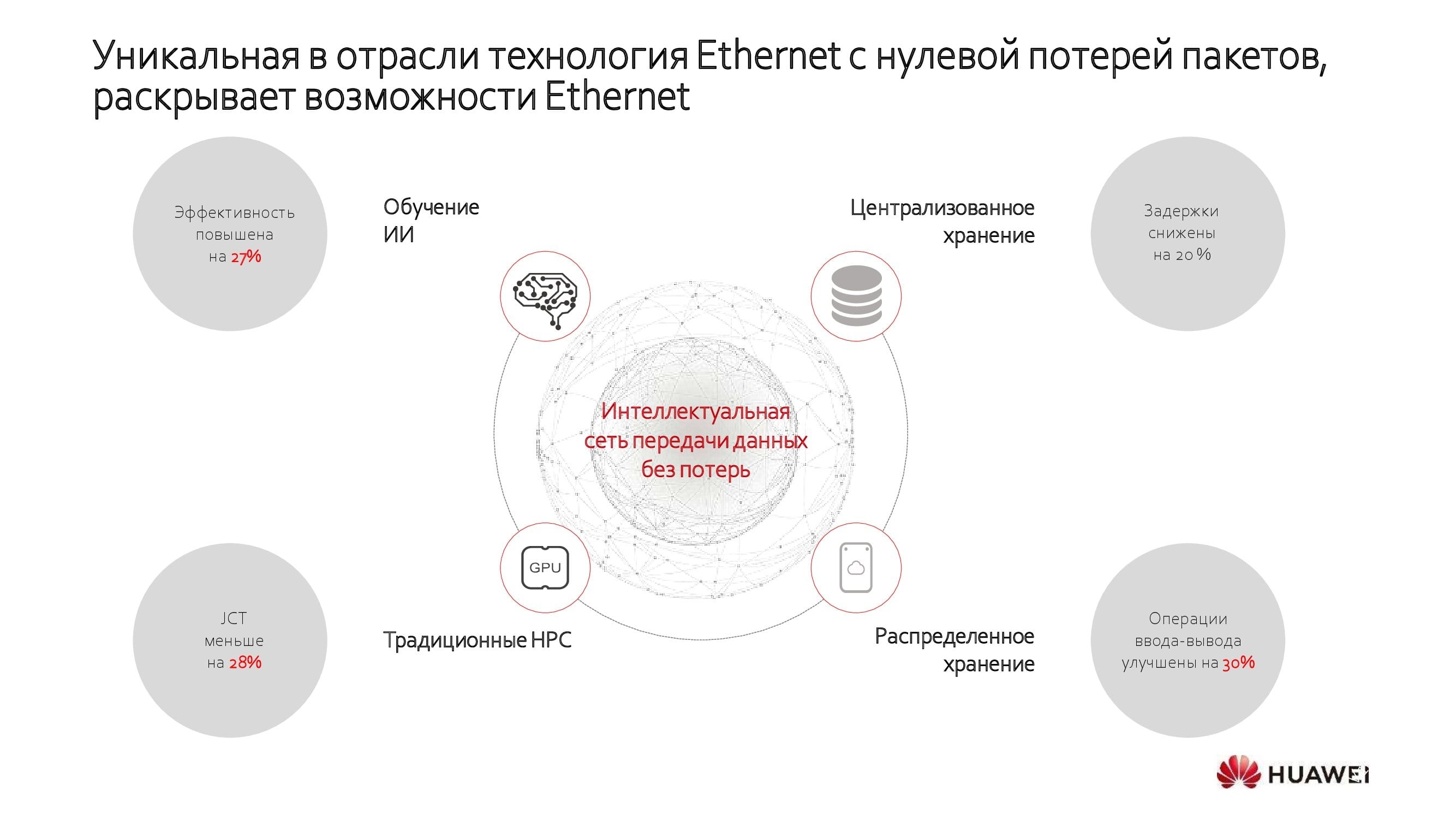
Максимальную эффективность «сеть ЦОД без потерь» демонстрирует в нескольких сценариях, как то:

В заключение рассмотрим один из сценариев применения интеллектуальной сети ЦОД. Многие заказчики используют распределённые системы хранения (SDS). Интегрируя между собой программные СХД разных производителей с помощью нашего решения, можно добиться на 40% более высокой производительности, чем без него. А значит, когда известен требуемый уровень производительности вашей SDS, его можно добиться, используя на 40% меньше серверов.
Кстати, не забывайте про наши многочисленные вебинары, проводящиеся не только в русскоязычном сегменте, но и на глобальном уровне. Список вебинаров на декабрь доступен по ссылке.
Трансформация ЦОД
Центры обработки данных концептуально меняются, и меняются разительно. Относительно массовым тренд стал около десяти лет назад, однако, скажем, в банковской сфере начался гораздо раньше. Вне зависимости от выбранного пути цели преобразований более или менее сходные — унификация и консолидация ресурсов.
Это первый шаг, за которым следует дальнейшее повышение эффективности работы дата-центра путём автоматизации, оркестрации и перехода в режим гибридного облака. И самый дальний предел трансформации из досягаемых на сегодняшний день — внедрение систем искусственного интеллекта.
Решения Huawei для каждого этапа трансформации
На каждой стадии в зависимости от «IT-зрелости» заказчика компания Huawei предлагает собственные решения, призванные обеспечить наилучший результат модернизации без лишних трат. Сегодня хотелось бы подробнее поговорить как раз о «вишенке на торте» — системах ИИ в современных ЦОДах.
Если провести аналогию с человеческим организмом, коммутаторы сети ЦОД выполняют роль системы кровообращения, обеспечивая связанность между различными компонентами: вычислительными узлами, системами хранения данных и т. д.
Буквально несколько лет назад технологии хранения данных на твердотельных дисках стали широко доступны, а производительность центральных процессоров продолжает расти. Благодаря этому хранилища и вычислительные узлы перестали быть главными причинам задержек. А вот сеть ЦОД долгое время оставалась в структуре дата-центров своего рода «младшим братом».
Производители пытались решить проблему по-разному. Кто-то выбирал для построения сети лицензированные технологии InfiniBand (IB). Сеть получалась специализированной и способной решать только узкопрофильные задачи. Кто-то предпочитал строить сетевые фабрики на протоколах Fibre Channel (FC). Оба подхода имели свои ограничения: либо пропускная способность сети оказывалась относительно скромной, либо общая цена решения кусалась, что вдобавок усугублялось зависимостью от одного вендора.
Наша компания пошла путём использования открытых технологий. В основу решений Huawei легла работа со второй версией RoCE, возможности которой были расширены за счёт использования дополнительных лицензируемых алгоритмов в наших коммутаторах. Это позволило серьёзно оптимизировать возможности сетей.
Почему мы не видим будущего за классическими FC-решениями? Дело в том, что они работают по принципу статического выделения кредитов, что требует настройки сетевой фабрики в соответствии с потребностями ваших приложений на ограниченный срез времени.
В последнее время FC шагнул вперёд к автономным сетям хранения данных, но продолжает нести в себе ограничения производительности. Сейчас мейнстрим — шестое поколение технологии, позволяющее добиться пропускной способности 32 Гбит/с, начинают внедряться и решения 64 Гбит/с. При этом с помощью Ethernet мы уже сегодня, используя таблицы приоритета, можем получить 100, 200 и даже 400 Гбит/с до сервера.
Дополнительные возможности сети ЦОД приобретают особое значение в мире, где твердотельные накопители со скоростными интерфейсами занимают всё большую долю рынка, вытесняя классические шпиндельные. Huawei стремится к тому, чтобы дать СХД на основе SSD полностью раскрыть свой потенциал.
Сеть ЦОД следующего поколения
Небольшой пример того, как мы это делаем. На схеме изображена одна из наших систем хранения данных, признанных самыми быстрыми в мире. Здесь же показаны наши серверы, построенные на архитектуре x86 или ARM и демонстрирующие производительность на уровне ожиданий крайне требовательных клиентов. В ЦОДах на основе этих решений нам удаётся добиться сквозной задержки не более 0,1 мс. Получить такой результат нам помогает использование новых application-технологий.
Классические технологии, применяемые в СХД, были ограничены, в частности, достаточно высокими задержками, которые обуславливались шиной SAS. Переход на новые протоколы, такие как NVMe, позволил значительно улучшить этот параметр, и вместе с тем ограничивающим производительность фактором становилась сама сеть.
Рассмотрим в рамках этого же примера использование сетей с дополнительными лицензируемыми алгоритмами. Они позволяют оптимизировать сквозную задержку, существенно повысить пропускную способность сети и увеличить количество операций ввода-вывода на единицу времени. Такой подход помогает избежать «двойной закупки», подчас необходимой для достижения необходимых параметров производительности, а совокупная экономия (в измерении TCO) при внедрении новой сети достигает 18–40% в зависимости от моделей применяемого оборудования.
Что же это за вау-алгоритмы?
Привычные технологии несли с собой привычные же проблемы, так как работали со статическими пороговыми значениями очереди. Такой порог означал, что для всех приложений формировалась некое базовое соотношение между скоростью и задержкой. Ручной режим управления не давал обеспечить динамическую подстройку параметров сети.
Используя в коммутаторах дополнительные чипсеты машинного обучения, мы научили сеть работать в режиме, позволяющем строить интеллектуальные сети ЦОД без потерь пакетов (мы назвали его iDCN).
Как достигается интеллектуальная оптимизация? Те, кто занимается нейросетями, легко найдут на схеме знакомые элементы и механизмы training / inference. Наличие в наших решениях встроенных моделей сочетается со способностью обучаться на конкретной сети.
Система ИИ накапливает определённый объём знаний о сети, которые затем аппроксимируются и используются при динамической настройке сети. В устройствах на базе наших собственных аппаратных решений применяется специальный ИИ-чип. В моделях, построенных на лицензируемых чипсетах американских производителей, задействуются дополнительный модуль и программная шина.
О применяемых моделях. Мы используем подход, который опирается на модель обучения с подкреплением. Система анализирует 100% проходящих через сетевое устройство данных и выбирает базовую линию. Если, к примеру, известны пропускная способность и те задержки, которые критичны для конкретного приложения, определить базовую линию не составляет труда. При большом количестве приложений можно проводить «медианные» вычисления и выполнять настройки в автоматическом режиме, ощутимо повышая производительность.
На схеме процесс представлен более подробно. На старте оптимизации сети мы производим вычисления пороговых значений — как минимальных, так и максимальных. Далее в дело вступает конволюционная нейронная сеть (CNN). Таким образом удаётся выровнять пропускную способность и коэффициенты задержек для каждого приложения, а также определить его общий «вес» в рамках сетевых сервисов. Используя такой стратифицированный подход, мы получаем действительно интересные выводы.
Когда приложение неизвестно, применяется алгоритм эвристического поиска в сочетании с «машиной состояний». С её помощью мы начинаем двигаться по изображённой выше блок-схеме против часовой стрелки, выявляя пороговые значения и строя модель. Это автоматический процесс, на который при необходимости можно оказывать управляющее воздействие. Если такой необходимости нет, проще положиться на коммутатор и его сервисы.
От теории к практике
Применяя такие алгоритмы и работая на уровне всей сети, а не отдельных её срезов, мы решаем все основные проблемы производительности. Уже есть интересные кейсы внедрения и использования подобных технологий в банковской сфере. Востребованы эти механизмы и в других отраслях, например среди операторов связи.
Обратимся к результатам открытых тестов. Независимая лаборатория The Tolly Group протестировала наше решение и сравнила его с решениями Ethernet и IB других производителей. Как показали испытания, производительность продукта Huawei эквивалентна возможностям IB и на 27% превосходит Ethernet-продукты других крупных производителей.
Максимальную эффективность «сеть ЦОД без потерь» демонстрирует в нескольких сценариях, как то:
- обучение ИИ;
- централизованное хранение;
- распределённое хранение;
- высокопроизводительные вычисления на GPU.
В заключение рассмотрим один из сценариев применения интеллектуальной сети ЦОД. Многие заказчики используют распределённые системы хранения (SDS). Интегрируя между собой программные СХД разных производителей с помощью нашего решения, можно добиться на 40% более высокой производительности, чем без него. А значит, когда известен требуемый уровень производительности вашей SDS, его можно добиться, используя на 40% меньше серверов.
***
Кстати, не забывайте про наши многочисленные вебинары, проводящиеся не только в русскоязычном сегменте, но и на глобальном уровне. Список вебинаров на декабрь доступен по ссылке.



