
Данная публикация не относится к материалам серии «вот он event horizon», а наоборот, как советчик по применению признанных методов анализа БигДата (BigDate) в практической деятельности простых людей, далеких от зоопарка с Пайтонами (Python), Эскьюэлями (SQL), Сиплюсплюсами (C++) и др. – оценщиков, при определении рыночной стоимости недвижимости. Необходимость определять влияние местоположения на стоимость недвижимости не вызывает сомнения. Этот факт закреплен практически, в требованиях ФСО-7 (Федеральный стандарт оценки «Оценка недвижимости (ФСО N 7)» п.11б и 22е.
В настоящий момент в сети существуют такие «тепловые карты недвижимости», но они узкие по назначению, так как отражают стоимость квартир, а необходимо оценивать и другие виды недвижимости. А с другой стороны эти информационные источники не наделены необходимой полнотой, что ограничивает их применение в судебной экспертизе.
Конечно, каждый оценщик знает свою территорию и у него существует собственная «тепловая карта». Могу представить, как сам проводил районирование без использования матметодов (рис.1).
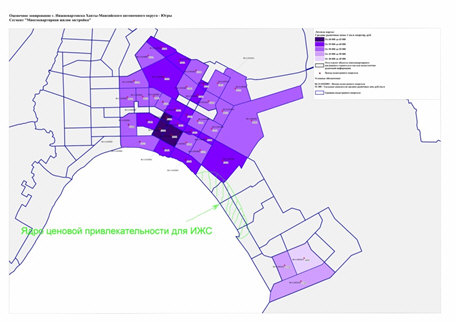
Рис. 1. Проведенное районирования ценовых зон на земельные участки в декабре 2019 г. (основная карта взята из «ОТЧЕТ № 01/ОКС-2019 об итогах государственной кадастровой оценки всех видов объектов недвижимости (за исключением земельных участков) на территории Ханты-Мансийского автономного округа — Югры» Приложение Б. Результаты определения КС_\2. Результаты оценочного зонирования\2.1 Сегмент многоквартирная жилая застройка». Утвержденный Приказом Депимущества Югры от 19.11.2019 № 19-нп «Об утверждении результатов определения кадастровой стоимости всех видов объектов недвижимости (за исключением земельных участков) на территории Ханты-Мансийского автономного округа – Югры»
И определения ценового районирования с помощью инструмента g-means в 2021, рис. 2.
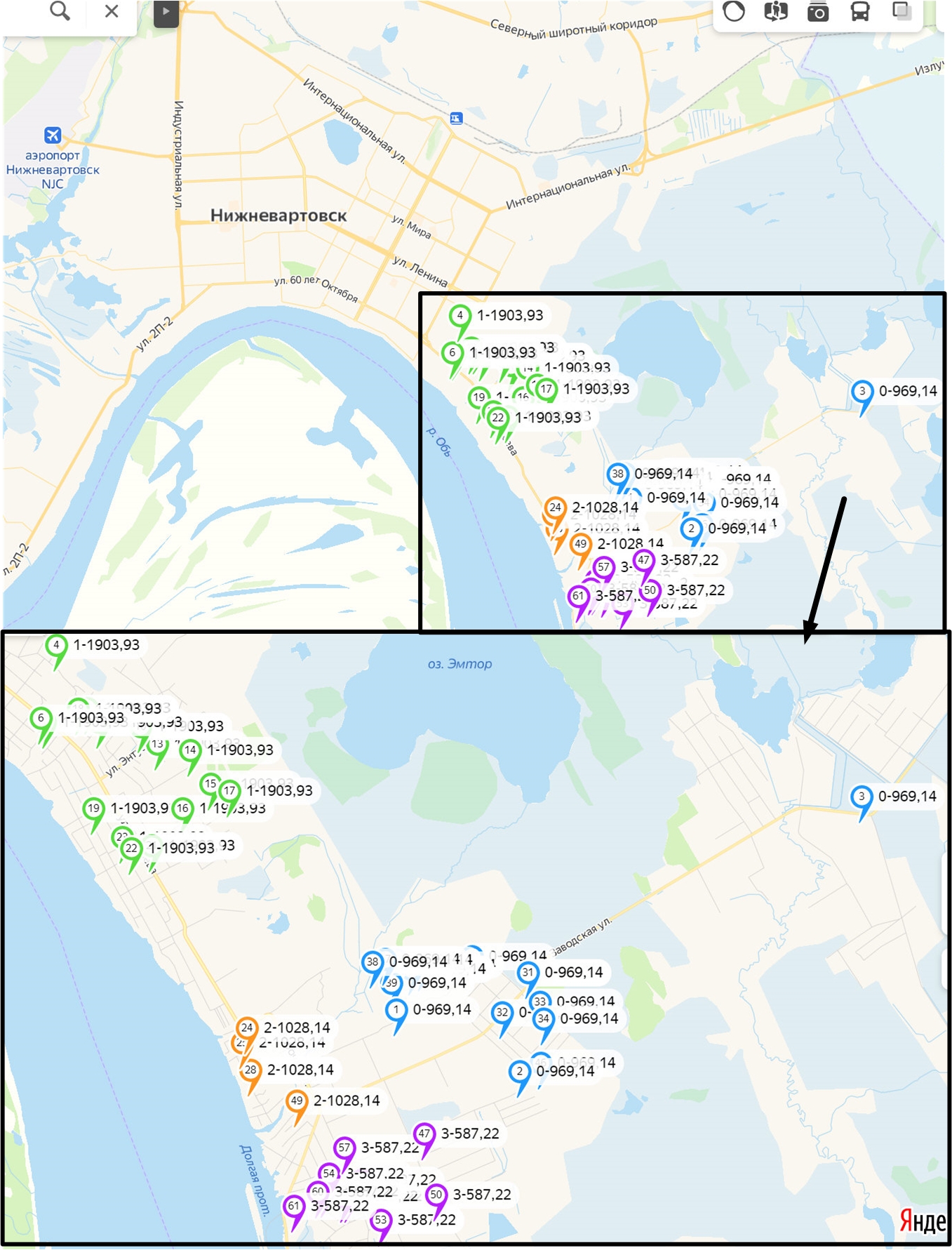
Рис. 2. Проведенное районирования ценовых зон на земельные участки в феврале 2021 г. с помощью инструмента g-means (ссылка на карту)
Более-менее удовлетворяющая «тепловая карта» обнаружена на сайте etagi.com (рис.3) можно провести сравнение качества информации.

Рис. 3. Проведенное районирования ценовых зон на квартиры сайта etagi.com (март 2021 г.) (ссылка на карту)
Не могу сказать, что попыток создать «тепловые карты цен недвижимости» отсутствуют, но для больше 80% случаев задач, возникающих перед оценщиками они бесполезны. А в тех случаях, когда они могут быть использованы, то только как средства подтверждающие вывод оценщика о том или ином аспекте формирующем цену недвижимости на рынке.
Из найденного мною в интернете «тепловых карт» более-менее состоятельным можно признать яндексовскую карту (рис. 4) так как присутствует ее описание.

Рис. 4. Проведенное районирования ценовых зон на квартиры в г.Москва по данным сайта Яндекс.недвижимость (март 2021 г.). (ссылка на карту).
И «Информ-Оценка» - это признанная в оценочном сообществе компания. На рис. 5 представлены ее данные.

Рис. 5. Тепловая карта недвижимости в г.Тюмень по данным фирмы «Информ-Оценка»
У Яндекс.Недвижимость проблема, что это сделано только для г.Москва и Сант-Петербург и, предположительно из-за проблем в сопряжения масштабов не удалось охватить всю страну. И вторая проблема это то, что только жилые квартиры.
У «Информ-оценки» только коммерческая недвижимость с жестким ограничением по периодам и городам.
У «Etagi.com» только жилая недвижимость в многоквартирных домах.
Всего представленного для деятельности оценщика недостаточно. Про остальные ресурсы, попадавшиеся мне и представляющие аналогичные продукты упоминать не буду так как в рамках требований глав 6 и 7 ГОСТ Р 56214-2014 «Качество данных. Часть 1. Обзор» используя нормы ст.67. «Оценка доказательств» ГПК, ст.88. «Правила оценки доказательств» УПК, ст.71. «Оценка доказательств» АПК добиться признания их ничтожными, для среднего специалиста, задача не высокой сложности.
Другие способы независимого районирования это: а) привязка к административному районированию (районы города); б) привязка к станции метрополитена; в) привязка к физическому пространству (ДомКлик от Сбера).
Все они имеют свои недостатки и, как следствие, очень суженую область применения.
Можно констатировать, что в настоящий момент 99% оценщиков, при территориальном районировании опираются на собственный опыт. И это приводит что в случаях состязания двух мнений к ситуации когда «Мнение_1 v.s. Мнение_2». Далее покажу эту проблему на примере, но в случаях судебного спора возникает достаточно сложная задача.
Без сомнения многие хабровцы знают, что инструменты k-means (g-means) известны давно, но в условиях российской оценки они не развивались по причине, что в Excel’е его нет, а другой доступный обычному гражданину РФ статистический софт, в своем большинстве, был англоязычным. И как следствие эти инструменты неизвестны оценщикам. Поэтому когда мне попался продукт «Loginom Company» Deductor Academic изучил его и представляю свои выводы.
1. Достаточно научный (то есть результаты анализа при обработке данных этим инструментом не имеют субъективной составляющей). Конечно «натянуть сову на глобус» можно всегда и даже на Excel, но это уже отдельная правовая ситуация.
2. Русскоязычный.
3. Бесплатная версия вполне достаточна для выполнения описанных задач по кластеризации территориальной информации о ценах.
Представлю пример, который поможет понять эффективность инструмента Deductor Academic.
Цель оценки: определение рыночной стоимости застроенного земельного участка.
Назначение оценки: Для обеспечения исковых требований в судебном процессе.
Из назначения оценки понятно, что стороны будут отстаивать свои права достаточно решительно, так как любое изменение стоимости это реальные деньги для каждой из сторон.
На рис. 2 была представлена локализация найденных предложений. Кластеризация в Deductor Academic дала разбиение на четыре кластера, у каждой оценки стоит уровень кластера. Как видно из рис.2 справа вверху был учтен объект (это результат недостаточно качественного отбора объектов для исследования), который можно следует отнести к дачной недвижимости. После исключения его из датасета проведена повторная операция с теми же параметрами исследования, сопоставление результатов исследований представлено на рисунке 6.

Рис. 6. Сопоставление результатов исследования по территориальной кластеризации предложений земельных участков (верхний / нижний).
Мы видим, что изменения существенны. Следствие этого изменения показаны на рисунке 7.

Рис. 7. Влияние очищенной информации на результаты оценки в сопоставлении с местоположением объекта оценки.
Представленные рядом с точками метки показывают параметры кластеров. Как видно, что в районе нахождения объекта оценки после проведения очистки ценовой уровень снизился практически на 10%. Вот в этом случае возникает ситуация «Мнение_1 v.s. Мнение_2». То есть мнение первого эксперта заключается в том что необходимо брать за основу кластер отраженный на верхней части рисунка 7 и ценовым уровнем 969,14, а мнение второго эксперта заключается в том что брать за основу кластер отраженный на нижней части рисунка 7 и ценовым уровнем 873,28. Несложно догадаться что без аналитического инструмента доказать обоснованность своей позиции ни один из экспертов не сможет. А представленный инструмент Deductor Academic это позволяет.
Другие варианты использования рассматриваемых инструментов? Возможно. По общему пониманию методологии кадастровой оценки могу предположить, что данный инструмент будет эффективен при оспаривании кадастровой стоимости. Так как методология 237-ФЗ не может дать такой степени детализации рыночной ситуации как инструмент k-means (g-means). Проводится поиск локальных минимумов цен и далее процедура признание кадастровой стоимости равной рыночной в областях локального минимума. Но это уже другая история.
Приступим к практической части.
Если вы не дружите с «зоопарком», о котором упоминалось в начале публикации, то много придется делать в рукопашную.
При сборе предложений следует дополнительно к обычной практике собирать координаты местоположения объектов аналогов, в Яндекс.картах это дополнительная минута к обычному режиму. Так как интервалы стоимости необходимо находить (п.11 в,г ФСО-7), то общее время для 40-100 предложений, которые присутствуют на рынках средних и малых городов, увеличивается на час.
Следующая проблема возникает из-за того, что Яндекс.карты выдают обе координаты (широту и долготу) одной строкой - 60.957875, 76.878470. Это решается с помощью функций Excel рис.8.

Рис. 8.
Для загрузки на Яндекс.карты полученных результатов необходимо понимать как туда заливать. На странице Яндекс.Справки и скачиваете файл «Шаблон файла XLSX». Его заполняете как необходимо и потом заливаете на свои карты.
Маркировка по цвету опять же делается в рукопашную. Оценивая логику, по которой проектировал Яндекс, то предполагаю, что она разумна. Синий, голубой цвета – для служебных точек, это могут быть различные вспомогательные точки, зеленый, желтый, красный для цен, фиолетовый – также вспомогательные точки.
Следующий этап это подготовка данных. Deductor Academic достаточно чувствителен к качеству данных и основная проблема, что
1) координаты должны быть в формате с запятой;
2) не должно быть пропусков данных, которые он обрабатывает;
3) формат чисел без разделения на разряды (так как в бесплатной версии можно загрузить только текстовой файл и когда из Excel'я его сохраняешь, то он для разделения разрядов вставляет дополнительный пробел).
Результат представлен на рисунке 9.

Рис. 9. А) Залитые желтым данные – столбцы с форматом, который критически важен. Б) Панель снятия разрядности. В) Удалены записи с номерами 8, 9 из-за отсутствия необходимого качества.
Загружать данные лучше приведя к форме показанной на рис. 10, где проведено следующее:
А) Таблица начинается с ячейки «А1»;
Б) В названиях заголовков столбцов использован «_» вместо пробела и служебных символов;
В) Формат сохраненного файла «Текстовые файлы (с разделителем табуляции) (*.txt);
Г) убраны все не существенные столбцы (Просто Deductor Academic будет вас спрашивать что с этими столбцами делать, а так как и по существенным столбцам вопросов немало, то замучаетесь отвечать. А там он еще может решить, что их нужно анализировать (вы забудете поставить/убрать нужный флажок) и он вам навыдает такой список результатов, что заблудитесь).

Рис. 10.
Приступаем к загрузке данных в Deductor Academic.

Рис. 11.
На рисунке 12 представлено, что вам предстоит пройти, объясняя Deductor Academic что в него загружается.

Рис. 12. Этап классификации загружаемых данных в Deductor Academic (обязательно)
На рисунке 13 представлены вопросы Deductor Academic по поводу того, что вы хотите видеть.

Рис. 13. Этап установления условий вывода данных в Deductor Academic.
На рисунке 14 представлен отчет о принятие данных.

Рис. 14. Результаты приема данных в Deductor Academic.
Приступаем к анализу.
На рис.15 показан алгоритм выбора метода анализа.

Рис.15. Алгоритм выбора метода анализа в интерфейсе Deductor Academic.
Нажимаем далее и запускаем процесс поиска скрытых данных (Data minig) но тут … засада, рис.16. Так как все это делалось в процессе подготовки публикации, то обнаружилась ошибка. Знать о том как ругается Deductor Academic тоже необходимо, поэтому это оставил.

Рис. 16.
Проводим поиск ошибок.

Рис. 17. Результат проверки качества данных.
Из рисунка 17 видно, что наименьшая оценка качества для показателя долгота (0,5512), а затем следует широта (0,6898). Проведем анализ на дубликаты (рис.18).

Рис. 18. Результат проверки на дубликаты. (Красное - дубликаты, зеленое – противоречия)
Эта операция тоже не помогла. Ошибка находилась в том, что существовала последняя строка без значений.

Рис. 19. Очищенный от критических ошибок датасет.

Рис. 20. Задаем распределение на обучающее и тестовое множество датасета.

Рис. 21. Задаем количество кластеров при g-means количество кластеров определяется автоматически.

Рис. 22. Меню запуска процесса.

Рис. 23. Список выводимых параметров.

Рис. 24. Результаты анализа.
Результаты на Яндекс.Карте представлены здесь и на рисунке 25.
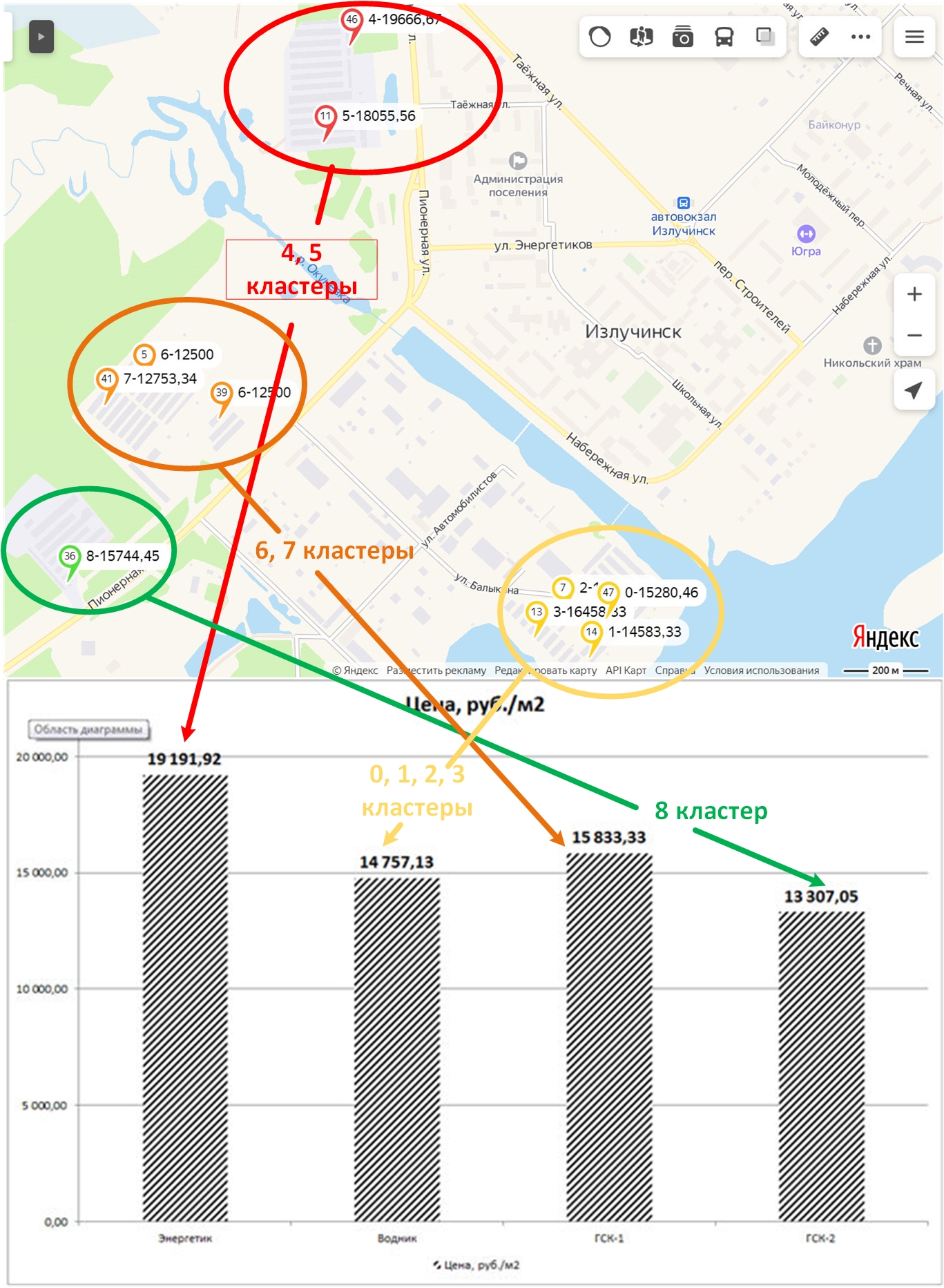
Рис. 25. Сопоставление результатов анализа в Deductor Academic с анализом, который проводился при выполнении этой задачи другими математическими средствами.
И в конце - Добро пожаловать в объятия дата майнинга.
