
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Рекрутеры используют всё более сложное ПО и инструменты для анализа и сопоставления присылаемых резюме с размещёнными вакансиями и описанием должностных обязанностей в них. Если в вашем резюме будет представлена только общая информация или если ваши ответы на описание должностных обязанностей будут указаны расплывчато и/или без всякой конкретики, такие инструменты сработают против вас. Ваш отклик на вакансию может быть отвергнут искусственным интеллектом. Да, это действительно так, и бьюсь об заклад, что вы об этом не знали, а если знали, то не верили!
В этой статье я хочу представить ряд техник, которые помогут повысить шансы вашего резюме на рассмотрение. В этом практическом примере мы будем использовать алгоритмы обработки текстов на естественных языках (Natural Language Processing, NLP), Python и ряд визуальных инструментов библиотеки Altair. Итак, готовы нанести ответный удар по кадровикам?
Предположим, что вы хотите получить хорошую должность, и, вот, вам встретилась в Интернете заманчивая вакансия. Сколько других людей, таких же, как вы, увидели эту вакансию? Имеют ли эти люди примерно такой же опыт и квалификацию, как и вы? Как вы полагаете, сколько претендентов откликнулись на эту вакансию? Десять, или, быть может, тысяча?
Далее давайте предположим, что отборочная комиссия отберёт только пять сильнейших претендентов и далее будет работать только с ними. Так как же вам не попасть в число несчастливых 995 претендентов, а остаться в рядах 5 сильнейших? Вот почему я говорю, что вам нужно повысить шансы, иначе судьба вашего резюме будет печальна!
Обработка 1 000 резюме (CV)
Я думаю, что такие "резюме" вначале делятся на стопки – по 3 или по 5 резюме в стопке. Резюме распечатывают и раздают другим людям, чтобы те их прочитали. Каждый из таких читателей отдаст обратно одно резюме из стопки. Если раздать резюме 5 читателям, то в итоге получится набор из 200 резюме – из них предстоит выбрать лучшего одного или двух претендентов. Чтение всех этих резюме занимает много времени, и единственным результатом такого чтения будет лишь ответ на искомый вопрос – "да" или "нет". А что если использовать Python, чтобы прочитать все такие резюме за считанные минуты?
В статье Как я использовал NLP (SpaCy) для отфильтровки резюме на получение работы в области интеллектуальной обработки данных, опубликованной здесь, в Medium, говорится, что имена файлов таких 1 000 резюме можно собрать, используя всего две строки кода.
#Function to read resumes from the folder one by one
mypath='D:/NLP_Resume/Candidate Resume'
onlyfiles = [os.path.join(mypath, f) for f in os.listdir(mypath)
if os.path.isfile(os.path.join(mypath, f))]Переменная onlyfiles представляет собой список Python, содержащий имена файлов всех резюме, которые были получены с использованием библиотеки Python os. Если внимательно прочитать эту статью, можно понять, что резюме можно ранжировать и исключать из рассмотрения, используя техники анализа ключевых слов. Так как мы пытаемся повысить шансы, нам необходимо сосредоточиться на описании должностных обязанностей и на информации, содержащейся в вашем текущем резюме. Совпадают ли они?
Сопоставление резюме и описания должностных обязанностей
Чтобы повысить шансы, необходимо проанализировать описание должностных обязанностей, содержание резюме и оценить степень их совпадения. В идеальном случае мы получим что-то вроде рекомендации, которую вы сможете использовать, чтобы "оставаться в игре".
Чтение документов
Поскольку речь идёт о резюме, то, по всей видимости, оно будет оформлено в виде файла в формате PDF или DOCX. Модули Python существуют для большинства форматов данных. На рисунке 1 показано, как можно считывать документы, сохраняя их содержимое в текстовом файле.

Первым шагом всегда должны быть открытие файла и считывание строк. На следующем этапе список строк преобразуется в единый текст, при этом выполняются определённые операции очистки. На рисунке 1 показано создание переменных jobContent и cvContent, представляющих собой строковый объект, включающий весь текст. Следующий фрагмент кода демонстрирует механизм непосредственного считывания документа Word.
import docx2txt
resume = docx2txt.process("DAVID MOORE.docx")
text_resume = str(resume)Переменная text_resume представляет собой строковый объект, в котором, как и раньше, хранится весь текст резюме. Также с этой целью можно использовать библиотеку PyPDF2.
import PyPDF2Не вдаваясь в подробности, отметим, что существует целый ряд возможностей, позволяющих специалисту-практику считывать документы, преобразовывая их в "чистый" текст. Такие документы могут быть очень пространными, трудно читаемыми и, откровенно говоря, скучными. Начать чтение можно с краткого изложения.
Обработка текста
Мне нравится скрипт Gensum, и я часто им пользуюсь.
from gensim.summarization.summarizer import summarize
from gensim.summarization import keywordsПрочитав файл Word, мы создали переменную resume_text. Теперь давайте составим краткое изложение резюме и объявления о приёме на работу.
print(summarize(text_resume, ratio=0.2))Краткое изложение резюме создадим с помощью скрипта Gensim.summarization.summarizer.summarize
summarize(jobContent, ratio=0.2)Теперь вы можете прочитать краткое изложение должностных обязанностей и ваше текущее резюме! Возможно, вы пропустили какую-то часть должностных обязанностей, на которой был сделан акцент в кратком изложении? Успешно подать себя вам помогут мелкие детали. Всем ли понятен ваш документ с кратким изложением, правильно ли в нём указаны ваши основные качества?
Возможно, одного лишь краткого изложения будет недостаточно. Теперь давайте поймём, насколько хорошо ваше резюме соответствует описанию должностных обязанностей. Код представлен на рисунке 2.

В общем случае мы составляем список наших текстовых объектов, а затем создаём экземпляр класса sklearn CountVectorizer() Мы также импортируем метрику cosine_similarity с помощью которой измеряется степень сходства двух документов. "Ваше резюме приблизительно на 69,44 % соответствует описанию должностных обязанностей". Звучит заманчиво, но пока не будем поддаваться эмоциям. Теперь можно прочитать краткое изложение документов и получить измеренное значение сходства. Шансы повышаются.
Далее можно проанализировать ключевые слова, встречающиеся в описании должностных обязанностей, и проверить, какие из них также встречаются в резюме. Но, возможно, мы пропустили несколько ключевых слов, которые могли бы довести степень совпадения до 100 %? Теперь переходим к spacy. Между прочим, заметили, какие красивые названия мы используем? Gensim, sklearn, а теперь и spacy! Надеюсь, у вас ещё не закружилась голова?
from spacy.matcher import PhraseMatcher
matcher = PhraseMatcher(Spnlp.vocab)
from collections import Counter
from gensim.summarization import keywordsДля определения степени соответствия важных фраз из описания должностных обязанностей содержанию резюме мы используем интегрированную в Spacy функцию PhraseMatcher В определении такого соответствия нам помогут ключевые слова Gensim. На рисунке 3 показано, как запустить скрипт соответствия.

Используя фрагмент кода, представленного на рисунке 3, можно получить список ключевых слов, для которых обнаружены совпадения. На рисунке 4 показано, как формируется список ключевых слов, для которых обнаружены совпадения. Воспользуемся словарём Counter из модуля Collections

Термин "составление отчётов" (reporting – в оригинале) содержится в описании должностных обязанностей, а в резюме обнаружены три случая употребления этого термина. Какие фразы или ключевые слова присутствуют в объявлении о приёме на работу, но отсутствуют в резюме? Можем ли мы что-нибудь добавить в резюме? Для ответа на этот вопрос я использовал библиотеку Pandas – результат представлен на рисунке 5.

Если это действительно так, то это тоже странно. Степень совпадений составила 69,44 % на уровне документов, но только посмотрите на этот длинный список ключевых слов, которые не встречаются в резюме. На рисунке 6 показаны встречающиеся в резюме ключевые слова.

В действительности ключевых слов, совпадающих с описанием должностных обязанностей, очень мало, и именно это стало причиной моего скептицизма по отношению к значению косинусного коэффициента 69,44 %. Тем не менее наши шансы увеличиваются, так как в описании должностных обязанностей встречаются ключевые слова, которых нет в резюме. Чем меньше будет совпадений с ключевыми словами, тем вероятнее, что ваше резюме будет отправлено в корзину. Поняв, каких ключевых слов нет в резюме, можно подправить резюме и запустить анализ заново. Однако не стоит действовать "в лоб" и переписывать резюме, просто подставляя в него ключевые слова, тут необходимо быть крайне осторожным. Вполне возможно, что вы сумеете пройти этап первоначального отсева, но возможное отсутствие письменных навыков (умения писать грамотно) на следующих этапах выдаст вас с головой. Поэтому то, что нам нужно сейчас, – это ранжировать фразы и сосредоточиться на основных темах или словах, которые встречаются в описании должностных обязанностей.
Давайте взглянем на ранжированный список фраз. Для этого упражнения я использую собственный класс NLP и некоторые ранее используемые мною методы.
from nlp import nlp as nlp
LangProcessor = nlp()
keywordsJob = LangProcessor.keywords(jobContent)
keywordsCV = LangProcessor.keywords(cvContent)Используя собственный класс, я восстановил ранжированные фразы из ранее созданных объектов описания должностных обязанностей и резюме. Приведённый ниже фрагмент кода определяет метод. Для извлечения строк ranked_phrases и scores теперь будем использовать модуль rake.
def keywords(self, text):
keyword = {}
self.rake.extract_keywords_from_text(text)
keyword['ranked phrases'] = self.rake.get_ranked_phrases_with_scores()
return keywordНа рисунке 7 показан результат вызова метода.

Фраза "Методология проектного управления – проектное управление" (в оригинале – project management methodology — project management) соответствует рангу 31.2, поэтому будем считать, что в объявлении о приёме на работу – это самое важное квалификационное требование. Надо учитывать, что важные фразы в резюме также могут представлены с незначительными вариациями.
for item in keywordsCV['ranked phrases'][:10]:
print (str(round(item[0],2)) + ' - ' + item[1] )Читая самые часто встречающиеся фразы как в резюме, так и в объявлении о приёме на работу, спросим себя, есть ли в них совпадения или сходство? Естественно! И мы можем выяснить его с помощью кода. Следующий код устанавливает соответствие между ранжированными фразами в объявлении о приёме на работу и в резюме.
sims = []
phrases = []
for key in keywordsJob['ranked phrases']:
rec={}
rec['importance'] = key[0]
texts = key[1]
sims=[]
avg_sim=0
for cvkey in keywordsCV['ranked phrases']:
cvtext = cvkey[1]
sims.append(fuzz.ratio(texts, cvtext))
#sims.append(lev.ratio(texts.lower(),cvtext.lower()))
#sims.append(jaccard_similarity(texts,cvtext))
count=0
for s in sims:
count=count+s
avg_sim = count/len(sims)
rec['similarity'] = avg_sim
rec['text'] = texts
phrases.append(rec)Обратите внимание, что при использовании механизма сопоставления мы использовали опцию поиска по сходству (приближённого поиска). В коде также использованы коэффициент Левенштейна и функция jaccard_similarity (коэффициент Жаккара). На рисунке 8 показано, как выглядит результат.

Переменная importance представляет собой рейтинговую оценку фразы из резюме. Переменная similarity – рейтинговую оценку результатов поиска по сходству. Термину методология проектного управления присвоен ранг 31.2, соответствующие ему ранжированные фразы резюме набрали в среднем 22.5 балла. Несмотря на то что главным квалификационным требованием в объявлении о приёме на работу является "проектное управление", наибольшее количество рейтинговых баллов в резюме получили различные технические аспекты. Из этого примера можно понять, как искусственный интеллект работает против вашего резюме.
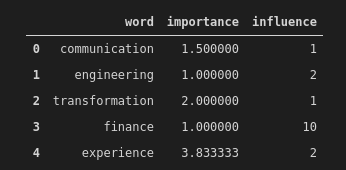
На рисунке 9 эта же ситуация представлена с другой точки зрения. Работа с лексемами (словами) показывает важность каждого слова в описании должностных обязанностей по сравнению с количеством совпадений в резюме: чем чаще встречается в документе конкретное слово, тем большую значимость оно имеет. Фраза "финансы" (finance) не имеет большой важности в описании должностных обязанностей, однако имеет большую значимость в резюме. Кто это там ищет работу в сфере IT? Финансист? Хе-хе. Не шутите с искусственным интеллектом, он может буквально интерпретировать ваши слова!
Теперь, я полагаю, картина для вас стала ясна. Использование инструментов и библиотек NLP может помочь по-настоящему понять описание должностных обязанностей и измерить степень относительных совпадений. Эти инструменты, естественно, не вполне надёжны и не являются истиной в последней инстанции, но, тем не менее, их можно использовать, чтобы повысить шансы вашего резюме. То, что сказано вами в резюме, естественно, сыграет свою роль, но вы не должны тупо переносить ключевые слова в резюме. Поступите проще – составьте действительно сильное резюме и отправьте отклик на вакансию, которая вам подходит. Обработка и интеллектуальный анализ текста – это неисчерпаемая тема. Мы только слегка приоткрыли завесу того, что можно сделать с помощью алгоритмов искусственного интеллекта. Лично я считаю алгоритмы интеллектуального анализа текста и модели машинного обучения на базе текста весьма точными инструментами. Давайте напоследок посмотрим на некоторые визуальные инструменты, предлагаемые библиотекой Altair, а затем подведём итог.
Визуальные инструменты Altair
В последнее время я часто пользуюсь библиотекой Altair – гораздо чаще, чем библиотеками Seaborn или Matplotlib. Грамматика в Altair как будто создана для меня. В качестве вспомогательных материалов, которые можно использовать при обсуждении, я создал три визуальных инструмента – на рисунке 10 изображены такие параметры, как важность и значимость ключевых слов в резюме. Применив цветовую шкалу, мы видим, что такое слово, как "внедрение", встречается в резюме дважды, однако оно имеет более низкий приоритет в объявлении о приёме на работу.

На рисунке 11 показаны соответствия ранжированных тем, обнаруженных в объявлениях о приёме на работу, и тем, обнаруженных в резюме. Самая важная фраза в объявлении о приёме на работу – "проектное управление…", однако в рейтинге фраз резюме эта фраза стоит не на первом месте.

На рисунке 12 показаны сходные слова. Слово "финансы" в резюме встречается 10 раз, однако ни разу не встречается в объявлении о приёме на работу. Слово "проект" встречается и в резюме, и в объявлении о приёме на работу.

Если посмотреть на эти диаграммы, можно прийти к выводу, что содержания резюме и описания должностных обязанностей сочетаются друг с другом не очень хорошо. Общих для двух документов ключевых слов крайне мало, ранжированные фразы выглядят очень по-разному. И именно это сыграет роковую роль – ваше резюме будет отправлено в корзину!
Заключение
Чтение этой статьи может показаться больше похожим на сценарий высокобюджетного голливудского фильма со спецэффектами "Пристрели их всех". В голливудских блокбастерах, как правило, в главных ролях снимаются известные актёры. Так и здесь – в этой статье главную роль сыграли крупные NLP-библиотеки, а некоторые библиотеки даже выступили в роли камео – как более старые, более опытные и более зрелые инструменты, например библиотека NLTK. Мы использовали такие библиотеки, как Gensim, Spacy, sklearn, и получили представление о том, как их применять. Используя специально созданный собственный класс, в котором я объединил библиотеки NLTK, rake, textblob и множество других модулей, я получил инструмент, с помощью которого неопределённые догадки можно облечь в форму поддающегося анализу текста и с помощью которого вы получите шанс получить работу своей мечты.
Получение работы мечты требует ясного понимания и неослабного внимания к деталям и крайне аккуратной подготовки отклика на вакансию, резюме и сопроводительного письма. Использование алгоритмов обработки текстов на естественных языках, естественно, не превратит вас в претендента номер один на получение заветного места. Тут всё зависит от вас! Но это может повысить ваши шансы на прохождение хотя бы первого этапа, на котором с помощью систем искусственного интеллекта отсеиваются "непроходные" резюме.
Любой рыбак знает – без жирной наживки никакой рыбы не поймать!

Узнайте подробности, как получить Level Up по навыкам и зарплате или востребованную профессию с нуля, пройдя онлайн-курсы SkillFactory со скидкой 40% и промокодом HABR, который даст еще +10% скидки на обучение.
Профессия Data Scientist
Профессия Data Analyst
Курс по Data Engineering
Другие профессии и курсы
ПРОФЕССИИ
Профессия Java-разработчик
Профессия QA-инженер на JAVA
Профессия Frontend-разработчик
Профессия Этичный хакер
Профессия C++ разработчик
Профессия Разработчик игр на Unity
Профессия Веб-разработчик
Профессия iOS-разработчик с нуля
Профессия Android-разработчик с нуля
КУРСЫ
Курс по Machine Learning
Курс "Математика и Machine Learning для Data Science"
Курс "Machine Learning и Deep Learning"
Курс "Python для веб-разработки"
Курс "Алгоритмы и структуры данных"
Курс по аналитике данных
Курс по DevOps

