Clickhouse — это столбцовая система управления базами данных для онлайн обработки аналитических запросов (OLAP) с открытым исходным кодом, созданная Яндексом. Ее используют Яндекс, CloudFlare, VK.com, Badoo и другие сервисы по всему миру для хранения действительно больших объемов данных (вставка тысяч строк в секунду или петабайты данных, хранящихся на диске).
В обычной, «строковой» СУБД, примерами которых служат MySQL, Postgres, MS SQL Server, данные хранятся в таком порядке:
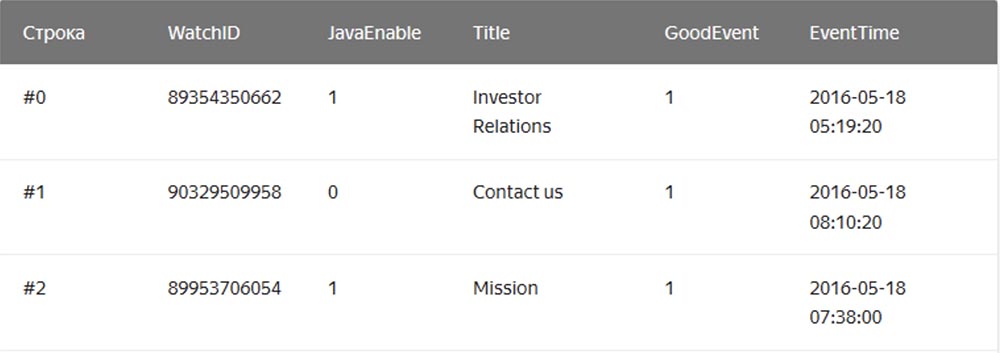
При этом значения, относящиеся к одной строке, физически хранятся рядом. В столбцовых СУБД значения из разных столбцов хранятся отдельно, а данные одного столбца – вместе:
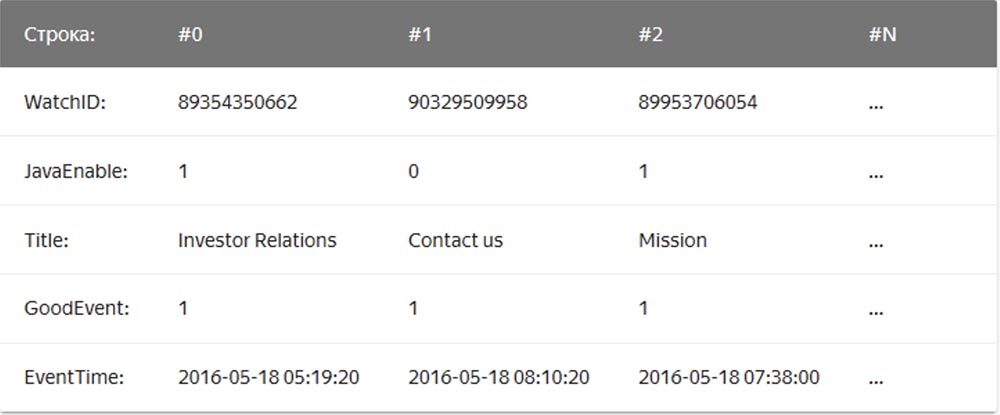
Примерами столбцовых СУБД служат Vertica, Paraccel (Actian Matrix, Amazon Redshift), Sybase IQ, Exasol, Infobright, InfiniDB, MonetDB (VectorWise, Actian Vector), LucidDB, SAP HANA, Google Dremel, Google PowerDrill, Druid, kdb+.
Компания – мейлфорвардер Qwintry стала использовать Clickhouse в 2018 году для составления отчетов и очень впечатлилась ее простотой, масштабируемостью, поддержкой SQL и скоростью. Быстрота работы этой СУБД граничила с волшебством.
Clickhouse устанавливается в Ubuntu одной единственной командой. Если вы знаете SQL, то можете незамедлительно начать использовать Clickhouse для своих нужд. Однако это не означает, что вы можете выполнить «show create table» в MySQL и сделать копипаст SQL в Clickhouse.
По сравнению с MySQL, в этой СУБД существуют важные различия типов данных в определениях схемы таблиц, поэтому для комфортной работы вам все же потребуется некоторое время, чтобы изменить определения схемы таблиц и изучить движки таблиц.
Clickhouse отлично работает без какого-либо дополнительного программного обеспечения, но если вы захотите использовать репликацию, вам понадобится установить ZooKeeper. Анализ производительности запросов показывает отличные результаты — системные таблицы содержат всю информацию, а все данные могут быть получены с помощью старого и скучного SQL.

База данных ClickHouse обладает очень простым дизайном — все узлы в кластере имеют одинаковую функциональность и для координации используют только ZooKeeper. Мы построили небольшой кластер из нескольких узлов и выполнили тестирование, в ходе которого обнаружили, что система обладает довольно впечатляющей производительностью, которая соответствует заявленным преимуществам в бенчмарках аналитических СУБД. Мы решили более детально рассмотреть концепцию, лежащую в основе ClickHouse. Первым препятствием для исследований было отсутствие инструментов и немногочисленность сообщества ClickHouse, поэтому мы углубились в дизайн этой СУБД, чтобы понять, как она работает.
ClickHouse не поддерживает прием данных непосредственно от Kafka, так как это всего лишь база данных, поэтому мы написали собственный сервис адаптеров на языке Go. Он считывал кодированные сообщения Cap’n Proto у Kafka, преобразовывал их в TSV и вставлял в ClickHouse пакетами через HTTP-интерфейс. Позже мы переписали этот сервис, чтобы использовать библиотеку Go совместно с собственным интерфейсом ClickHouse для повышения производительности. При оценке производительности приема пакетов мы обнаружили важную вещь – оказалось, что у ClickHouse эта производительность сильно зависит от размера пакета, то есть количества одновременно вставляемых строк. Чтобы понять, почему это происходит, мы изучили, как ClickHouse хранит данные.
Основным движком, вернее, семейством движков для таблиц, используемым ClickHouse для хранения данных, является MergeTree. Этот движок концептуально похож на алгоритм LSM, применяемый в Google BigTable или Apache Cassandra, однако избегает построения промежуточной таблицы памяти и записывает данные непосредственно на диск. Это дает ему отличную пропускную способность записи, так как каждый вставленный пакет сортируется только по “первичному ключу” primary key, сжимается и записывается на диск, чтобы сформировать сегмент.
Отсутствие таблицы памяти или какого-либо понятия “свежести” данных также означает, что их можно только добавлять, изменение или удаление система не поддерживает. На сегодня единственный способ удалить данные — это удалить их по календарным месяцам, так как сегменты никогда не пересекают границу месяца. Команда ClickHouse активно работает над тем, чтобы сделать эту функцию настраиваемой. С другой стороны, это делает бесконфликтным запись и слияние сегментов, поэтому пропускная способность приема линейно масштабируется с количеством параллельных вставок до тех пор, пока не произойдет насыщение I/O или ядер.
Однако это обстоятельство также означает, что система не подходит для небольших пакетов, поэтому для буферизации используются сервисы Kafka и инсертеры. Далее, ClickHouse в фоновом режиме продолжает постоянно выполнять слияние сегментов, так что многие мелкие части информации будут объединены и записаны большее количество раз, таким образом, наращивая интенсивность записи. При этом слишком много несвязанных частей вызовет агрессивный троттлинг вставок до тех пор, пока продолжается слияние. Мы обнаружили, что наилучшим компромиссом между приемом данных в режиме реального времени и производительностью приема является прием в таблицу ограниченного числа вставок в секунду.
Ключом к производительности чтения таблиц является индексация и расположение данных на диске. Независимо от того, насколько быстра обработка, когда движку нужно просканировать терабайты данных с диска и использовать только часть из них, это займет время. ClickHouse является колоночным хранилищем, поэтому каждый сегмент содержит файл для каждого столбца (колонки) с отсортированными значениями для каждой строки. Таким образом, целые столбцы, отсутствующие в запросе, сначала могут быть пропущены, а затем несколько ячеек могут быть обработаны параллельно с векторизованным выполнением. Чтобы избежать полного сканирования, каждый сегмент имеет маленький индексный файл.
Учитывая, что все столбцы отсортированы по “первичному ключу”, индексный файл содержит только метки (захваченные строки) каждой N-й строки, чтобы иметь возможность хранить их в памяти даже для очень больших таблиц. Например, можно установить настройки по умолчанию «помечать каждую 8192-ю строку», тогда «скудное» индексирование таблицы с 1 трлн. строк, которая легко помещается в память, займет всего 122 070 знаков.
Развитие и совершенствование Clickhouse можно проследить на Github repo и убедиться, что процесс «взросления» происходит впечатляющими темпами.
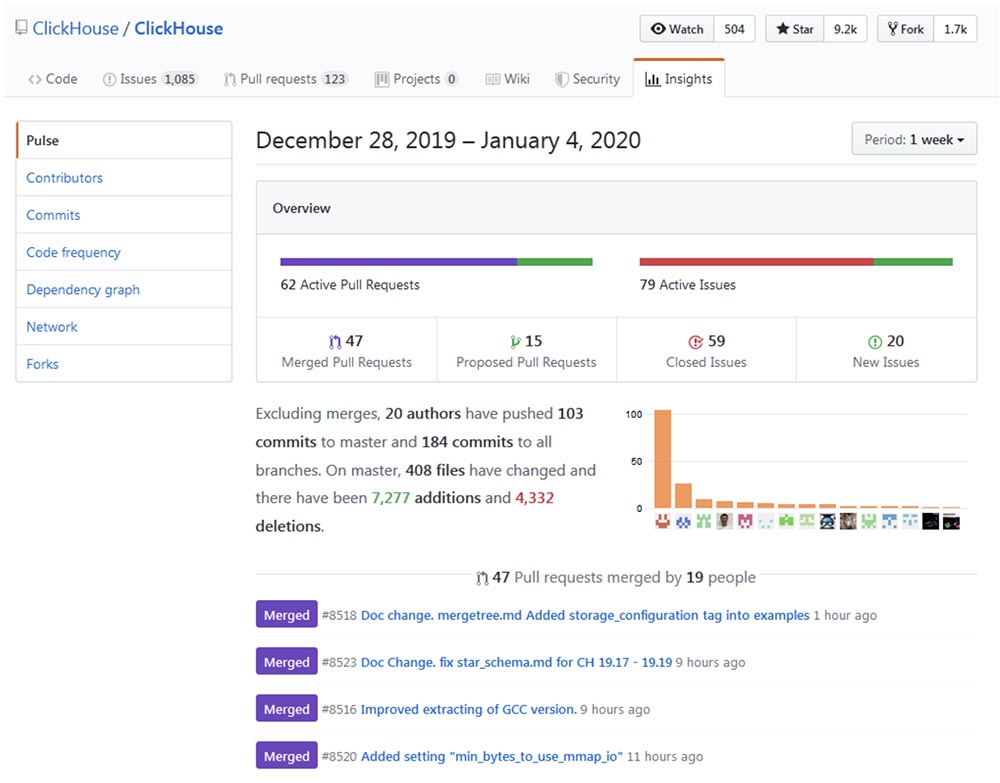
Похоже, популярность Clickhouse растет экспоненциально, особенно в русскоязычном сообществе. Прошлогодняя конференция High load 2018 (Москва, 8-9 ноября 2018 г.) показала, что такие монстры, как vk.com и Badoo, используют Clickhouse, с помощью которой вставляют данные (например, журналы) с десятков тысяч серверов одновременно. В 40-минутном видео Юрий Насретдинов из команды ВКонтакте рассказывает о том, как это делается. Вскоре мы выложим стенограму на Хабр для удобства работы с материалом.
После того, как я потратил некоторое время на исследования, думаю, что существуют области, в которых ClickHouse может быть полезен или способен полностью заменить другие, более традиционные и популярные решения, такие как MySQL, PostgreSQL, ELK, Google Big Query, Amazon RedShift, TimescaleDB, Hadoop, MapReduce, Pinot и Druid. Далее изложены подробности использования ClickHouse для модернизации или полной замены вышеперечисленных СУБД.
Совсем недавно мы частично заменили MySQL на ClickHouse для платформы информационных бюллетеней Mautic newsletter. Проблема заключалась в том, что MySQL из-за непродуманного дизайна регистрировал каждое отправляемое письмо и каждую ссылку в этом письме с хэшем base64, создавая огромную таблицу MySQL (email_stats). После отправки подписчикам сервиса всего лишь 10 миллионов писем эта таблица занимала 150 ГБ файлового пространства, и MySQL начинал «тупить» на простых запросах. Чтобы исправить проблему файлового пространства, мы успешно использовали сжатие таблицы InnoDB, которое уменьшило ее в 4 раза. Однако все равно не имеет смысла хранить более 20-30 миллионов электронных писем в MySQL только ради чтения истории, так как любой простой запрос, который по какой-то причине должен выполнить полное сканирование, приводит к свопу и большой нагрузке на I/O, по поводу чего мы регулярно получали предупреждения Zabbix.

Clickhouse использует два алгоритма сжатия, которые сокращают объем данных примерно в 3-4 раза, но в данном конкретном случае данные были особенно «сжимаемыми».

Исходя из собственного опыта, стек ELK (ElasticSearch, Logstash и Kibana, в данном конкретном случае ElasticSearch) требует гораздо больше ресурсов для запуска, чем это необходимо для хранения логов. ElasticSearch отличный движок, если вам нужен хороший полнотекстовый поиск в логах (а я не думаю, что он вам реально нужен), но мне интересно, почему де-факто он стал стандартным движком для ведения журнала. Его производительность приема в сочетании с Logstash создавала нам проблемы даже при довольно небольших нагрузках и требовала добавления все большего объема оперативной памяти и дискового пространства. Как БД, Clickhouse лучше ElasticSearch по следующим причинам:
В настоящее время самая большая проблема, возникающая при сравнении ClickHouse с ELK, это отсутствие решений для отгрузки логов, а также нехватка документации и учебных пособий по данной теме. При этом каждый пользователь может настроить ELK с помощью руководства Digital Ocean, что очень важно для быстрого внедрения подобных технологий. Здесь есть движок БД, но пока еще нет Filebeat для ClickHouse. Да, там присутствует fluentd и система для работы с логами loghouse, существует инструмент clicktail для ввода в ClickHouse данных лог-файлов, но все это требует больше времени. Однако ClickHouse все равно лидирует в силу своей простаты, поэтому даже новички элементарно ее устанавливают и приступают к полнофункциональному использованию буквально через 10 минут.
Предпочитая минималистские решения, я попытался использовать FluentBit, инструмент для отгрузки журналов с очень небольшим объемом памяти, вместе с ClickHouse, при этом стараясь избежать применения Kafka. Однако необходимо устранить небольшие несовместимости, такие как проблемы формата даты, прежде чем это можно будет сделать без proxy-слоя, который преобразует данные из FluentBit в ClickHouse.
В качестве альтернативы Kibana можно в роли бэкенда ClickHouse использовать Grafana. Насколько я понял, при этом могут возникать проблемы с производительностью при рендеринге огромного количества пунктов данных, особенно с более старыми версиями Grafana. В Qwintry мы пока что это не пробовали, но жалобы на такое время от времени появляются на канале поддержки ClickHouse в Telegram.
Идеальный вариант использования BigQuery – это загрузить 1 ТБ данных JSON и выполните по ним аналитические запросы. Big Query — это отличный продукт, масштабируемость которого трудно переоценить. Это гораздо более сложное ПО, чем ClickHouse, работающее на внутреннем кластере, но с точки зрения клиента оно имеет много общего с ClickHouse. BigQuery может быстро «подорожать», как только вы станете платить за каждый SELECT, так что это настоящее решение SaaS со всеми его плюсами и минусами.
ClickHouse является наилучшим выбором в случае, когда вы выполняете много дорогих с точки зрения вычислений запросов. Чем больше запросов SELECT вы выполняете каждый день — тем больше смысла в замене Big Query на ClickHouse, потому что такая замена поможет вам сэкономить тысячи долларов, если речь идет о многих терабайтах обрабатываемых данных. Это не относится к хранимым данным, обработка которых в Big Query обходится довольно дешево.
В статье сооснователя компании Altinity Александра Зайцева «Переход на ClickHouse» рассказывается о преимуществах такой миграции СУБД.
TimescaleDB является расширением PostgreSQL, которое оптимизирует работу с временными рядами timeseries в обычной базе данных (https://docs.timescale.com/v1.0/introduction, https://habr.com/ru/company/zabbix/blog/458530/).
Хотя ClickHouse не является серьезным конкурентом в нише временных рядов, но столбцовой структуре и векторному выполнению запросов, в большинстве случаев обработки аналитических запросов он намного быстрее TimescaleDB. При этом производительность приема пакетных данных ClickHouse примерно в 3 раза выше, к тому же он использует в 20 раз меньше дискового пространства, что действительно важно для обработки больших объемов исторических данных: https://www.altinity.com/blog/ClickHouse-for-time-series.
В отличие от ClickHouse, единственным способом сэкономить немного дискового пространства в TimescaleDB является использование ZFS или аналогичных файловых систем.
Грядущие обновления ClickHouse, скорее всего, введут дельта-компрессию, которая сделает его еще более подходящим для обработки и хранения данных временных рядов. TimescaleDB может стать лучшим выбором, чем «голый» ClickHouse, в следующих случаях:
Hadoop и другие продукты MapReduce могут выполнять множество сложных вычислений, но они, как правило, работают с огромными задержками ClickHouse исправляет эту проблему, обрабатывая терабайты данных и почти мгновенно выдавая результат. Таким образом, ClickHouse намного эффективнее для выполнения быстрого, интерактивного аналитического исследования, что должно заинтересовать специалистов в области обработки данных.
Ближайшими конкурентами ClickHouse являются столбцовые линейно-масштабируемые open source продукты Pinot и Druid. Отличная работа по сравнению этих систем опубликована в статье Романа Левентова от 1 февраля 2018 г.
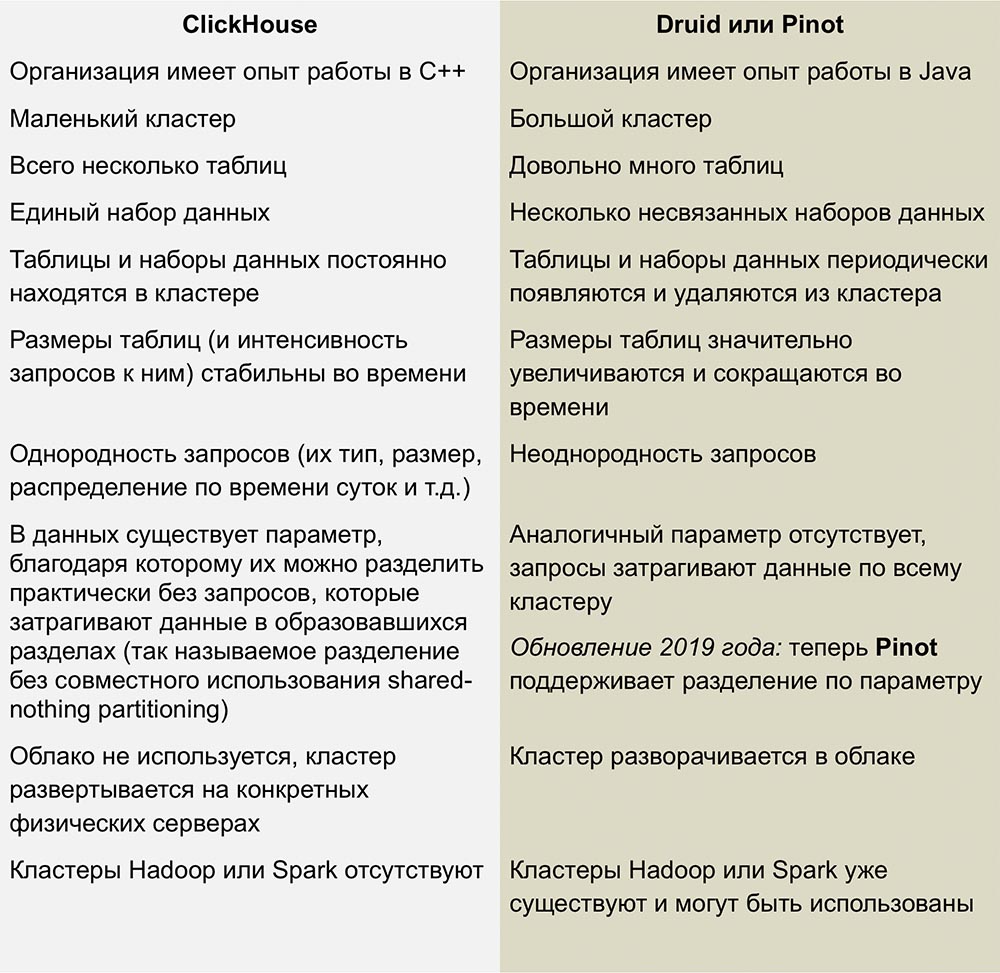
Данная статья требует обновления – в ней говорится, что ClickHouse не поддерживает операции UPDATE и DELETE, что не совсем верно в отношении последних версий.
У нас нет достаточного опыта работы с этими СУБД, но мне совсем не нравится сложность используемой инфраструктуры, которая требуется для запуска Druid и Pinot - это целая куча «подвижных частей», окруженных Java со всех сторон.
Druid и Pinot являются инкубаторскими проектами Apache, ход развития которых подробно освещается Apache на страницах своих проектов GitHub. Pinot появился в инкубаторе в октябре 2018, а Druid родился на 8 месяцев раньше – в феврале.
Отсутствие информации о том, как работает AFS, вызывает у меня некоторые, и возможно, глупые вопросы. Интересно, заметили ли авторы Pinot, что Apache Foundation более расположены к Druid, и не вызвало ли такое отношение к конкуренту чувство зависти? Замедлиться ли развитие Druid и ускорится развитие Pinot, если спонсоры, поддерживающие первый, внезапно заинтересуются вторым?
Незрелость: очевидно, что это все еще не скучная технология, но в любом случае, ничего подобного в других столбчатых СУБД не наблюдается.
Маленькие вставки плохо работают с высокой скоростью: вставки должны быть разделены на большие куски, потому что производительность небольших вставок снижается пропорционально количеству столбцов в каждой строке. Именно так в ClickHouse хранятся данные на диске — каждый столбец означает 1 файл или больше, поэтому для вставки 1 строки, содержащей 100 столбцов, необходимо открыть и записать не менее 100 файлов. Вот почему для буферизации вставок требуется посредник (если только сам клиент не обеспечивает буферизацию) — обычно это Kafka или какая-то система управления очередями. Можно также использовать движок Buffer table, чтобы позже копировать большие фрагменты данных в таблицы MergeTree.
Соединения таблиц ограничены оперативной памятью сервера, зато, по крайней мере, они там есть! Например, у Druid и Pinot вообще нет таких соединений, поскольку их трудно реализовать прямо в распределенных системах, которые не поддерживают перемещение больших кусков данных между узлами.
В ближайшие годы мы планируем широко использовать ClickHouse в Qwintry, поскольку эта СУБД обеспечивает отличный баланс производительности, низких накладных расходов, масштабируемости и простоты. Я почти уверен, что она начнет быстро распространяться, как только сообщество ClickHouse придумает больше способов ее использования на малых и средних инсталляциях.
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
В обычной, «строковой» СУБД, примерами которых служат MySQL, Postgres, MS SQL Server, данные хранятся в таком порядке:
При этом значения, относящиеся к одной строке, физически хранятся рядом. В столбцовых СУБД значения из разных столбцов хранятся отдельно, а данные одного столбца – вместе:
Примерами столбцовых СУБД служат Vertica, Paraccel (Actian Matrix, Amazon Redshift), Sybase IQ, Exasol, Infobright, InfiniDB, MonetDB (VectorWise, Actian Vector), LucidDB, SAP HANA, Google Dremel, Google PowerDrill, Druid, kdb+.
Компания – мейлфорвардер Qwintry стала использовать Clickhouse в 2018 году для составления отчетов и очень впечатлилась ее простотой, масштабируемостью, поддержкой SQL и скоростью. Быстрота работы этой СУБД граничила с волшебством.
Простота
Clickhouse устанавливается в Ubuntu одной единственной командой. Если вы знаете SQL, то можете незамедлительно начать использовать Clickhouse для своих нужд. Однако это не означает, что вы можете выполнить «show create table» в MySQL и сделать копипаст SQL в Clickhouse.
По сравнению с MySQL, в этой СУБД существуют важные различия типов данных в определениях схемы таблиц, поэтому для комфортной работы вам все же потребуется некоторое время, чтобы изменить определения схемы таблиц и изучить движки таблиц.
Clickhouse отлично работает без какого-либо дополнительного программного обеспечения, но если вы захотите использовать репликацию, вам понадобится установить ZooKeeper. Анализ производительности запросов показывает отличные результаты — системные таблицы содержат всю информацию, а все данные могут быть получены с помощью старого и скучного SQL.
Производительность
- Бенчмарк сравнения Clickhouse с Vertica и MySQL на сервере конфигурации: два сокета Intel® Xeon® CPU E5-2650 v2 @ 2.60GHz; 128 GiB RAM; md RAID-5 на 8 6TB SATA HDD, ext4.
- Бенчмарк сравнения Clickhouse с облачным хранилищем данных Amazon RedShift.
- Выдержки из блога Сloudflare о производительности Clickhouse:
База данных ClickHouse обладает очень простым дизайном — все узлы в кластере имеют одинаковую функциональность и для координации используют только ZooKeeper. Мы построили небольшой кластер из нескольких узлов и выполнили тестирование, в ходе которого обнаружили, что система обладает довольно впечатляющей производительностью, которая соответствует заявленным преимуществам в бенчмарках аналитических СУБД. Мы решили более детально рассмотреть концепцию, лежащую в основе ClickHouse. Первым препятствием для исследований было отсутствие инструментов и немногочисленность сообщества ClickHouse, поэтому мы углубились в дизайн этой СУБД, чтобы понять, как она работает.
ClickHouse не поддерживает прием данных непосредственно от Kafka, так как это всего лишь база данных, поэтому мы написали собственный сервис адаптеров на языке Go. Он считывал кодированные сообщения Cap’n Proto у Kafka, преобразовывал их в TSV и вставлял в ClickHouse пакетами через HTTP-интерфейс. Позже мы переписали этот сервис, чтобы использовать библиотеку Go совместно с собственным интерфейсом ClickHouse для повышения производительности. При оценке производительности приема пакетов мы обнаружили важную вещь – оказалось, что у ClickHouse эта производительность сильно зависит от размера пакета, то есть количества одновременно вставляемых строк. Чтобы понять, почему это происходит, мы изучили, как ClickHouse хранит данные.
Основным движком, вернее, семейством движков для таблиц, используемым ClickHouse для хранения данных, является MergeTree. Этот движок концептуально похож на алгоритм LSM, применяемый в Google BigTable или Apache Cassandra, однако избегает построения промежуточной таблицы памяти и записывает данные непосредственно на диск. Это дает ему отличную пропускную способность записи, так как каждый вставленный пакет сортируется только по “первичному ключу” primary key, сжимается и записывается на диск, чтобы сформировать сегмент.
Отсутствие таблицы памяти или какого-либо понятия “свежести” данных также означает, что их можно только добавлять, изменение или удаление система не поддерживает. На сегодня единственный способ удалить данные — это удалить их по календарным месяцам, так как сегменты никогда не пересекают границу месяца. Команда ClickHouse активно работает над тем, чтобы сделать эту функцию настраиваемой. С другой стороны, это делает бесконфликтным запись и слияние сегментов, поэтому пропускная способность приема линейно масштабируется с количеством параллельных вставок до тех пор, пока не произойдет насыщение I/O или ядер.
Однако это обстоятельство также означает, что система не подходит для небольших пакетов, поэтому для буферизации используются сервисы Kafka и инсертеры. Далее, ClickHouse в фоновом режиме продолжает постоянно выполнять слияние сегментов, так что многие мелкие части информации будут объединены и записаны большее количество раз, таким образом, наращивая интенсивность записи. При этом слишком много несвязанных частей вызовет агрессивный троттлинг вставок до тех пор, пока продолжается слияние. Мы обнаружили, что наилучшим компромиссом между приемом данных в режиме реального времени и производительностью приема является прием в таблицу ограниченного числа вставок в секунду.
Ключом к производительности чтения таблиц является индексация и расположение данных на диске. Независимо от того, насколько быстра обработка, когда движку нужно просканировать терабайты данных с диска и использовать только часть из них, это займет время. ClickHouse является колоночным хранилищем, поэтому каждый сегмент содержит файл для каждого столбца (колонки) с отсортированными значениями для каждой строки. Таким образом, целые столбцы, отсутствующие в запросе, сначала могут быть пропущены, а затем несколько ячеек могут быть обработаны параллельно с векторизованным выполнением. Чтобы избежать полного сканирования, каждый сегмент имеет маленький индексный файл.
Учитывая, что все столбцы отсортированы по “первичному ключу”, индексный файл содержит только метки (захваченные строки) каждой N-й строки, чтобы иметь возможность хранить их в памяти даже для очень больших таблиц. Например, можно установить настройки по умолчанию «помечать каждую 8192-ю строку», тогда «скудное» индексирование таблицы с 1 трлн. строк, которая легко помещается в память, займет всего 122 070 знаков.
Развитие системы
Развитие и совершенствование Clickhouse можно проследить на Github repo и убедиться, что процесс «взросления» происходит впечатляющими темпами.
Популярность
Похоже, популярность Clickhouse растет экспоненциально, особенно в русскоязычном сообществе. Прошлогодняя конференция High load 2018 (Москва, 8-9 ноября 2018 г.) показала, что такие монстры, как vk.com и Badoo, используют Clickhouse, с помощью которой вставляют данные (например, журналы) с десятков тысяч серверов одновременно. В 40-минутном видео Юрий Насретдинов из команды ВКонтакте рассказывает о том, как это делается. Вскоре мы выложим стенограму на Хабр для удобства работы с материалом.
Области применения
После того, как я потратил некоторое время на исследования, думаю, что существуют области, в которых ClickHouse может быть полезен или способен полностью заменить другие, более традиционные и популярные решения, такие как MySQL, PostgreSQL, ELK, Google Big Query, Amazon RedShift, TimescaleDB, Hadoop, MapReduce, Pinot и Druid. Далее изложены подробности использования ClickHouse для модернизации или полной замены вышеперечисленных СУБД.
Расширение возможностей MySQL и PostgreSQL
Совсем недавно мы частично заменили MySQL на ClickHouse для платформы информационных бюллетеней Mautic newsletter. Проблема заключалась в том, что MySQL из-за непродуманного дизайна регистрировал каждое отправляемое письмо и каждую ссылку в этом письме с хэшем base64, создавая огромную таблицу MySQL (email_stats). После отправки подписчикам сервиса всего лишь 10 миллионов писем эта таблица занимала 150 ГБ файлового пространства, и MySQL начинал «тупить» на простых запросах. Чтобы исправить проблему файлового пространства, мы успешно использовали сжатие таблицы InnoDB, которое уменьшило ее в 4 раза. Однако все равно не имеет смысла хранить более 20-30 миллионов электронных писем в MySQL только ради чтения истории, так как любой простой запрос, который по какой-то причине должен выполнить полное сканирование, приводит к свопу и большой нагрузке на I/O, по поводу чего мы регулярно получали предупреждения Zabbix.
Clickhouse использует два алгоритма сжатия, которые сокращают объем данных примерно в 3-4 раза, но в данном конкретном случае данные были особенно «сжимаемыми».
Замена ELK
Исходя из собственного опыта, стек ELK (ElasticSearch, Logstash и Kibana, в данном конкретном случае ElasticSearch) требует гораздо больше ресурсов для запуска, чем это необходимо для хранения логов. ElasticSearch отличный движок, если вам нужен хороший полнотекстовый поиск в логах (а я не думаю, что он вам реально нужен), но мне интересно, почему де-факто он стал стандартным движком для ведения журнала. Его производительность приема в сочетании с Logstash создавала нам проблемы даже при довольно небольших нагрузках и требовала добавления все большего объема оперативной памяти и дискового пространства. Как БД, Clickhouse лучше ElasticSearch по следующим причинам:
- Поддержка диалекта SQL;
- Лучшая степень сжатия хранимых данных;
- Поддержка поиска регулярных выражений Regex вместо поиска полного текста;
- Улучшенное планирование запросов и более высокая общая производительность.
В настоящее время самая большая проблема, возникающая при сравнении ClickHouse с ELK, это отсутствие решений для отгрузки логов, а также нехватка документации и учебных пособий по данной теме. При этом каждый пользователь может настроить ELK с помощью руководства Digital Ocean, что очень важно для быстрого внедрения подобных технологий. Здесь есть движок БД, но пока еще нет Filebeat для ClickHouse. Да, там присутствует fluentd и система для работы с логами loghouse, существует инструмент clicktail для ввода в ClickHouse данных лог-файлов, но все это требует больше времени. Однако ClickHouse все равно лидирует в силу своей простаты, поэтому даже новички элементарно ее устанавливают и приступают к полнофункциональному использованию буквально через 10 минут.
Предпочитая минималистские решения, я попытался использовать FluentBit, инструмент для отгрузки журналов с очень небольшим объемом памяти, вместе с ClickHouse, при этом стараясь избежать применения Kafka. Однако необходимо устранить небольшие несовместимости, такие как проблемы формата даты, прежде чем это можно будет сделать без proxy-слоя, который преобразует данные из FluentBit в ClickHouse.
В качестве альтернативы Kibana можно в роли бэкенда ClickHouse использовать Grafana. Насколько я понял, при этом могут возникать проблемы с производительностью при рендеринге огромного количества пунктов данных, особенно с более старыми версиями Grafana. В Qwintry мы пока что это не пробовали, но жалобы на такое время от времени появляются на канале поддержки ClickHouse в Telegram.
Замена Google Big Query и Amazon RedShift (решение для крупных компаний)
Идеальный вариант использования BigQuery – это загрузить 1 ТБ данных JSON и выполните по ним аналитические запросы. Big Query — это отличный продукт, масштабируемость которого трудно переоценить. Это гораздо более сложное ПО, чем ClickHouse, работающее на внутреннем кластере, но с точки зрения клиента оно имеет много общего с ClickHouse. BigQuery может быстро «подорожать», как только вы станете платить за каждый SELECT, так что это настоящее решение SaaS со всеми его плюсами и минусами.
ClickHouse является наилучшим выбором в случае, когда вы выполняете много дорогих с точки зрения вычислений запросов. Чем больше запросов SELECT вы выполняете каждый день — тем больше смысла в замене Big Query на ClickHouse, потому что такая замена поможет вам сэкономить тысячи долларов, если речь идет о многих терабайтах обрабатываемых данных. Это не относится к хранимым данным, обработка которых в Big Query обходится довольно дешево.
В статье сооснователя компании Altinity Александра Зайцева «Переход на ClickHouse» рассказывается о преимуществах такой миграции СУБД.
Замена TimescaleDB
TimescaleDB является расширением PostgreSQL, которое оптимизирует работу с временными рядами timeseries в обычной базе данных (https://docs.timescale.com/v1.0/introduction, https://habr.com/ru/company/zabbix/blog/458530/).
Хотя ClickHouse не является серьезным конкурентом в нише временных рядов, но столбцовой структуре и векторному выполнению запросов, в большинстве случаев обработки аналитических запросов он намного быстрее TimescaleDB. При этом производительность приема пакетных данных ClickHouse примерно в 3 раза выше, к тому же он использует в 20 раз меньше дискового пространства, что действительно важно для обработки больших объемов исторических данных: https://www.altinity.com/blog/ClickHouse-for-time-series.
В отличие от ClickHouse, единственным способом сэкономить немного дискового пространства в TimescaleDB является использование ZFS или аналогичных файловых систем.
Грядущие обновления ClickHouse, скорее всего, введут дельта-компрессию, которая сделает его еще более подходящим для обработки и хранения данных временных рядов. TimescaleDB может стать лучшим выбором, чем «голый» ClickHouse, в следующих случаях:
- небольшие инсталляции с очень малым объемом оперативной памяти (<3 ГБ);
- большое количество мелких INSERT, которые вы не хотите буферизировать в большие фрагменты;
- лучшая согласованность, единообразие и требования AСID;
- поддержка PostGIS;
- объединение с существующими таблицами PostgreSQL, так как по существу Timescale DB является PostgreSQL.
Конкуренция с системами Hadoop и MapReduce
Hadoop и другие продукты MapReduce могут выполнять множество сложных вычислений, но они, как правило, работают с огромными задержками ClickHouse исправляет эту проблему, обрабатывая терабайты данных и почти мгновенно выдавая результат. Таким образом, ClickHouse намного эффективнее для выполнения быстрого, интерактивного аналитического исследования, что должно заинтересовать специалистов в области обработки данных.
Конкуренция с Pinot и Druid
Ближайшими конкурентами ClickHouse являются столбцовые линейно-масштабируемые open source продукты Pinot и Druid. Отличная работа по сравнению этих систем опубликована в статье Романа Левентова от 1 февраля 2018 г.
Данная статья требует обновления – в ней говорится, что ClickHouse не поддерживает операции UPDATE и DELETE, что не совсем верно в отношении последних версий.
У нас нет достаточного опыта работы с этими СУБД, но мне совсем не нравится сложность используемой инфраструктуры, которая требуется для запуска Druid и Pinot - это целая куча «подвижных частей», окруженных Java со всех сторон.
Druid и Pinot являются инкубаторскими проектами Apache, ход развития которых подробно освещается Apache на страницах своих проектов GitHub. Pinot появился в инкубаторе в октябре 2018, а Druid родился на 8 месяцев раньше – в феврале.
Отсутствие информации о том, как работает AFS, вызывает у меня некоторые, и возможно, глупые вопросы. Интересно, заметили ли авторы Pinot, что Apache Foundation более расположены к Druid, и не вызвало ли такое отношение к конкуренту чувство зависти? Замедлиться ли развитие Druid и ускорится развитие Pinot, если спонсоры, поддерживающие первый, внезапно заинтересуются вторым?
Недостатки ClickHouse
Незрелость: очевидно, что это все еще не скучная технология, но в любом случае, ничего подобного в других столбчатых СУБД не наблюдается.
Маленькие вставки плохо работают с высокой скоростью: вставки должны быть разделены на большие куски, потому что производительность небольших вставок снижается пропорционально количеству столбцов в каждой строке. Именно так в ClickHouse хранятся данные на диске — каждый столбец означает 1 файл или больше, поэтому для вставки 1 строки, содержащей 100 столбцов, необходимо открыть и записать не менее 100 файлов. Вот почему для буферизации вставок требуется посредник (если только сам клиент не обеспечивает буферизацию) — обычно это Kafka или какая-то система управления очередями. Можно также использовать движок Buffer table, чтобы позже копировать большие фрагменты данных в таблицы MergeTree.
Соединения таблиц ограничены оперативной памятью сервера, зато, по крайней мере, они там есть! Например, у Druid и Pinot вообще нет таких соединений, поскольку их трудно реализовать прямо в распределенных системах, которые не поддерживают перемещение больших кусков данных между узлами.
Выводы
В ближайшие годы мы планируем широко использовать ClickHouse в Qwintry, поскольку эта СУБД обеспечивает отличный баланс производительности, низких накладных расходов, масштабируемости и простоты. Я почти уверен, что она начнет быстро распространяться, как только сообщество ClickHouse придумает больше способов ее использования на малых и средних инсталляциях.
Немного рекламы :)
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
