
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
В автоматизации отчетности очень часто используют открытую Java-библиотеку JasperReports, например статья Опенсорс-решение для автоматизации отчетности рассказывает об ее использовании для получения PDF форматов отчетности между делом упомянув о возможности экспорта в другие форматы.
Однако нередко возникает потребность получать данные не в твердой копии, а в форматах электронных таблиц и в этом направлении в библиотеке JasperReports есть мощный инструмент Crosstab. Вместе с механизмом экспорта в форматы электронных таблиц данный инструмент может быть востребован для получения форматированных документов, которые годны как отчеты для анализа, так и для дальнейшей обработки данных.
Основная цель использования печатной формы - выгрузка данных в электронную таблицу для дальнейшего использования данных. Разработку печатной формы будем делать в среде TIBCO Jaspersoft® Studio
Основой для построения любых форм библиотека JasperReports использует наборы данных DataSet. Существует множество способов заполнения данных. Для простоты и скорости данные будут формироваться в open-source решении MyCompany работающего на open-source разработки lsFusion.
Все нижесказанное справедливо к jasper report вообще, если не принимать во внимание специфику получения данных из LsFusion. Более того, подключаемая в данном решении дополнительная java обработка как внешняя - в других решениях просто будет интегрирована.
1. Подготовка данных в LsFusion/MyCompany
Пример формы будем делать для отчета по продажам определенного в модуле SalesLedgerReport. Допишем в файл SalesLedgerReport.lsf следующее
// ++ добавим команды печати
printXlsx 'Печать хslx' (){
PRINT salesLedgerReport
XLSX;
}
print 'Печать превью' (){
PRINT salesLedgerReport
PREVIEW;
}
EXTEND FORM salesLedgerReport
// кнопки печати
PROPERTIES printXlsx(), print();
2. Создание шаблонов jrxml
После запуска программы в отчете по продажам появятся 2 кнопки

Согласно документации формируем шаблоны jrxml из интерфейса превью.

В итоге в каталоге ../src/main/lsfusion получим файл
Sales_salesLedgerReport.jrxml
3. Редактирование шаблонов jrxml
Далее будем работать с файлом Sales_salesLedgerReport.jrxml в TIBCO Jaspersoft® Studio

В шаблоне уже сформирован заголовок и вставлена автоматически сформированная Detail область. Для наших целей Detail 1 можно удалить.
4. Вставка Crosstab
Вставляем
Crosstabиз палитры в раздел Summary
Оставляем основной источник данных отчета

Колонки сделаем год, месяц (на номер месяца исправим позже)

В качестве групп возьмем 4 верхних группы и наименование товара. Сразу сделаем верхнюю группу с итогом внизу, а остальные вверху. Строчки итогов будут играть роль строк групп.

Мерами возьмем для примера количество и сумму продаж.

Оформление принимаем по умолчанию. Оно настолько яркое, что дальше от него можно избавится.

Разделы
Detail1и шапку таблицы в заголовке удаляем, сохраняем шаблон. После перезапуcка программы командаПечать хslxпокажет заполненный шаблон в электронной таблице.
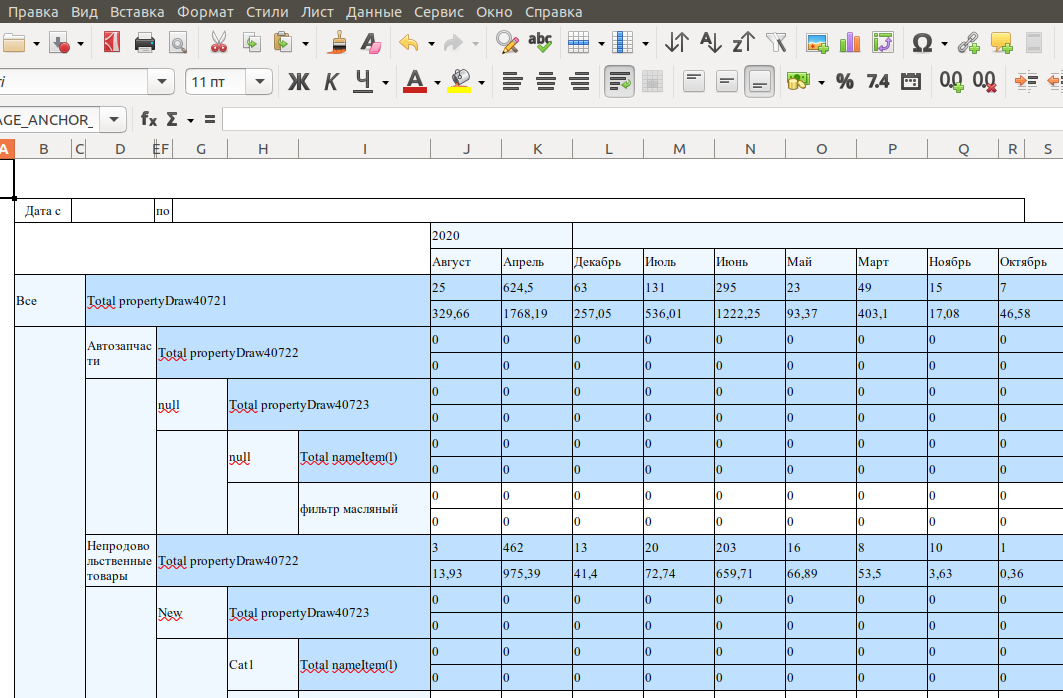
В принципе команда Печать превью нам тоже больше не нужна. Таблица будет заточена под вывод в xlsx формат и в печатном представлении не будет выглядеть хорошо.
4. Оформление
Теперь, как говорится, доработаем напильником до привычного вида.
Поправим группировку с наименование месяца на его номер (исправим выше сделанную ошибку)


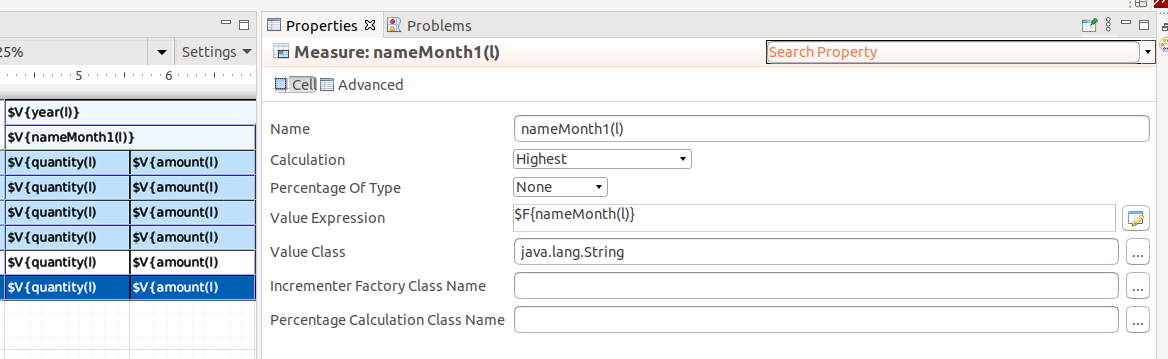
Вернем наименование месяца через объявление новой меры с максимальным значением внутри группы и поправим имя в заголовке.
Развернем поля данных в горизонтальном направлении и сделаем пошире. При форматировании учитывайте, что для каждого окончания ячейки при экспорте в электронную таблицу генерируется новая колонка. Поэтому даже заголовок отчета желательно выровнять по ширине полей основного поля.

Оформим ячейки с цифрами

Чтобы было в электронной таблице удобней работать - перебросим формулы в ячейках как показано на картинке (конвертируйте ячейки static в text), а сами ячейки сделаем с 0 шириной

Удаляем стили, копируем в отчет свои. Назначаем стили по строкам.

Кстати Crosstab удобен не только тем, что считает итоги по группам самостоятельно, но и тем, что создает переменные итогов по группам доступные на всех нижележащих уровнях.

это дает широкую возможность добавлять расчетные показатели начиная от долей до формул различного факторного анализа.
На этом этапе должны получить следующее:

5. Прочие мелочи
В готовом отчете хотелось бы получить следующие вкусности
Смещение текста нижестоящих групп
Работающее дерево иерархии отчета в электронной таблице
Пропуск пустых групп.
Заморозка строк/столбцов
Все эти перечисленные вещи (кроме последней) в jasper report для экспорта в электронную таблицу довольно неудобны для быстрого использования, поэтому пришел к тому, что слева от отчета добавляю колонку (которая скрывается при выводе) в которой помещаю номер уровня. И после формирования xlsx файла делаю его дообработку.
Итак
Добавим в проект в папку
.../src/main/javaфайл с именемXlsCreateRowOutline.javaсо следующим содержимым
XlsCreateRowOutline.java
import lsfusion.base.file.RawFileData;
import lsfusion.server.data.sql.exception.SQLHandledException;
import lsfusion.server.language.ScriptingErrorLog;
import lsfusion.server.language.ScriptingLogicsModule;
import lsfusion.server.logics.action.controller.context.ExecutionContext;
import lsfusion.server.logics.classes.ValueClass;
import lsfusion.server.logics.property.classes.ClassPropertyInterface;
import lsfusion.server.physics.dev.integration.internal.to.InternalAction;
import org.apache.commons.lang.StringUtils;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.CellType;
import org.apache.poi.xssf.usermodel.XSSFCell;
import org.apache.poi.xssf.usermodel.XSSFRow;
import org.apache.poi.xssf.usermodel.XSSFSheet;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import static java.lang.Math.abs;
//https://poi.apache.org/components/spreadsheet/quick-guide.html
public class XlsCreateRowOutline extends InternalAction {
public XlsCreateRowOutline(ScriptingLogicsModule LM, ValueClass... classes) {
super(LM, classes);
}
XSSFSheet sheet;
@Override
protected void executeInternal(ExecutionContext context) throws SQLException, SQLHandledException {
// выполняет доформатирование документа эксель
// 1. формирует иерархию отчета - создавая сворачиваемые группы/подгруппы
// 2. выполняет фиксацию заголовка
// 3. добавляет ко всем цифровым форматам - отрицательное красным
// 4. удаляет специально помеченные строки из отчета - актуально для crosstab
RawFileData f = (RawFileData)getParam(0, context); // файл экселя
Integer negativeRed = (Integer)getParam(1, context); //1 - отрицательное красным
Integer fixRow = (Integer)getParam(3, context); // если >0 фиксирует строки
Integer fixColumn = (Integer)getParam(2, context); // если больше 0 фиксирует столбцы
Integer columnTreeIndex = (Integer)getParam(4, context); // колонка в которой находится число - уровень иерархии строки
// если уровень сделать отрицательным - строка будет удалена
// сам уровень берется как abs от числа в ячейке
Integer allLevelsRequired = (Integer)getParam(5, context); // инициация всех уровне согласно порядковому номеру уровня, или можно пропускать
Map> ol = new HashMap<>();
for (int i =0;i<20;i++) ol.put(i,new HashMap<>());
int currentLevel=0;
int rowLevel=0;
int rowIndex=0;
Cell cell;
try {
XSSFWorkbook workbook = new XSSFWorkbook(f.getInputStream() );
sheet = workbook.getSheetAt(0);
for (rowIndex = 0; sheet.getLastRowNum() > rowIndex; rowIndex++) {
XSSFRow removingRow = sheet.getRow(rowIndex);
if (removingRow != null) {
if (
removingRow.getCell(columnTreeIndex).getCellType() == CellType.NUMERIC
&& abs(removingRow.getCell(columnTreeIndex).getNumericCellValue()) >= 0
// && abs(removingRow.getCell(columnTreeIndex).getNumericCellValue())<
) {
rowLevel = abs((int) removingRow.getCell(columnTreeIndex).getNumericCellValue());
if (currentLevel < rowLevel) {
// уровень повышен
while (currentLevel < rowLevel) {
ol.get(currentLevel).put(0, 1);
ol.get(currentLevel).put(1, rowIndex);
if (allLevelsRequired == 1) {
currentLevel++; //=rowLevel;
} else {
currentLevel = rowLevel;
}
}
}
// уровень понижен - сброс уровня
while (currentLevel > rowLevel) {
currentLevel--;
if (ol.get(currentLevel).containsKey(0) && (ol.get(currentLevel).get(0) == 1)) {
ol.get(currentLevel).put(0, 0);
sheet.groupRow(ol.get(currentLevel).get(1), rowIndex - 1);
}
}
// при отрицательном значении индекса - удаляем всю строчку
if (removingRow.getCell(columnTreeIndex).getNumericCellValue() < 0) {
sheet.removeRow(removingRow);
sheet.shiftRows(rowIndex + 1, sheet.getLastRowNum(), -1);
rowIndex--;
}
}
}
}
rowLevel = 0;
// уровень понижен - сброс уровня
while (currentLevel > rowLevel) {
currentLevel--;
if (ol.get(currentLevel).containsKey(0) && (ol.get(currentLevel).get(0) == 1)) {
ol.get(currentLevel).put(0, 0);
sheet.groupRow(ol.get(currentLevel).get(1), rowIndex - 1);
}
}
XSSFCell cellXSSF;
// все табуляторы в тексте отчета заменить на смещения
// внимание: СТИЛИ для каждого уровня ДОЛЖНЫ БЫТЬ СВОИ - тогда работает
for (rowIndex = 0; sheet.getLastRowNum() > rowIndex; rowIndex++) {
Iterator cellIterator = sheet.getRow(rowIndex).cellIterator();
while (cellIterator.hasNext()) {
cell = cellIterator.next();
cellXSSF = (XSSFCell)cell;
if (cellXSSF.getCellType() == CellType.STRING
&& StringUtils.countMatches(cellXSSF.getStringCellValue(), "\t") > 0) {
String str = cellXSSF.getStringCellValue();
if (cellXSSF.getCellStyle().getIndention() == (short) 0) {
cellXSSF.getCellStyle().setIndention((short) (StringUtils.countMatches(str, "\t")));
}
// cellXSSF.setCellFormula();
// cellXSSF.setCellType(CellType.STRING);
// cellXSSF.setCellValue( StringUtils.replace(str, "\t", ""));
// ms office и так удаляет табуляторы в начале. open office не удаляет
// но setCellType ломает документ для ms office а без setCellType в open office - пустые поля
} else if (cellXSSF.getCellType() == CellType.FORMULA) {
// cellXSSF.setCellFormula(cellXSSF.getStringCellValue());
} else if (negativeRed == 1 && cellXSSF.getCellType() == CellType.NUMERIC) {
int s = 1;
String format = cellXSSF.getCellStyle().getDataFormatString();
if (format.contains("#,##0") && !format.contains("RED")) {
format = format.concat(";[RED]-").concat(format);
cellXSSF.getCellStyle().setDataFormat(workbook.createDataFormat().getFormat(format));
}
}
}
}
if(fixRow>0 || fixColumn>0){
sheet.createFreezePane(fixColumn,fixRow);
}
if(columnTreeIndex>0) {
sheet.setColumnHidden(columnTreeIndex,true);
}
OutputStream os = new ByteArrayOutputStream();
workbook.write(os);
RawFileData rf = new RawFileData((ByteArrayOutputStream)os);
findProperty("fileXLS").change(rf, context);
} catch (IOException e) {
e.printStackTrace();
} catch (ScriptingErrorLog.SemanticErrorException e) {
e.printStackTrace();
}
}
}
Итоговый текст с учетом вышесказанного, добавленный в модуле lsFusion, будет таким:
fileXLS = DATA EXCELFILE();
// подключим java модуль
xlsCreateRowOutline 'Добавление сворачивающихся групп' INTERNAL 'XlsCreateRowOutline' (EXCELFILE, INTEGER, INTEGER, INTEGER, INTEGER, INTEGER);
// ++ добавим команды печати
printXlsx 'Печать хslx' (){
PRINT salesLedgerReport
XLSX SHEET 'Sheet1' TO fileXLS; // сохраним в файл
xlsCreateRowOutline(fileXLS(), 0, 3, 5, 1, 0); // дополнительно обработаем
open(fileXLS()); // откроем
}
EXTEND FORM salesLedgerReport
PROPERTIES printXlsx();
DESIGN salesLedgerReport {
OBJECTS {
TOOLBAR {
MOVE PROPERTY (printXlsx()) { }
}
}
}
Обработка согласно количеству вставленных табуляторов в ячейках добавила в них поля, согласно номеру уровня - сформировала иерархию. Если наименование в уровне null то уровень при формировании помечается отрицательным и при выводе строка удаляется. Уровень иерархии в таком случае можно либо сохранить (удаленные пустые группы увеличивают уровень группировки), либо нет.
В итоге получаем вполне годную форму для дальнейшей работы в электронной таблице.
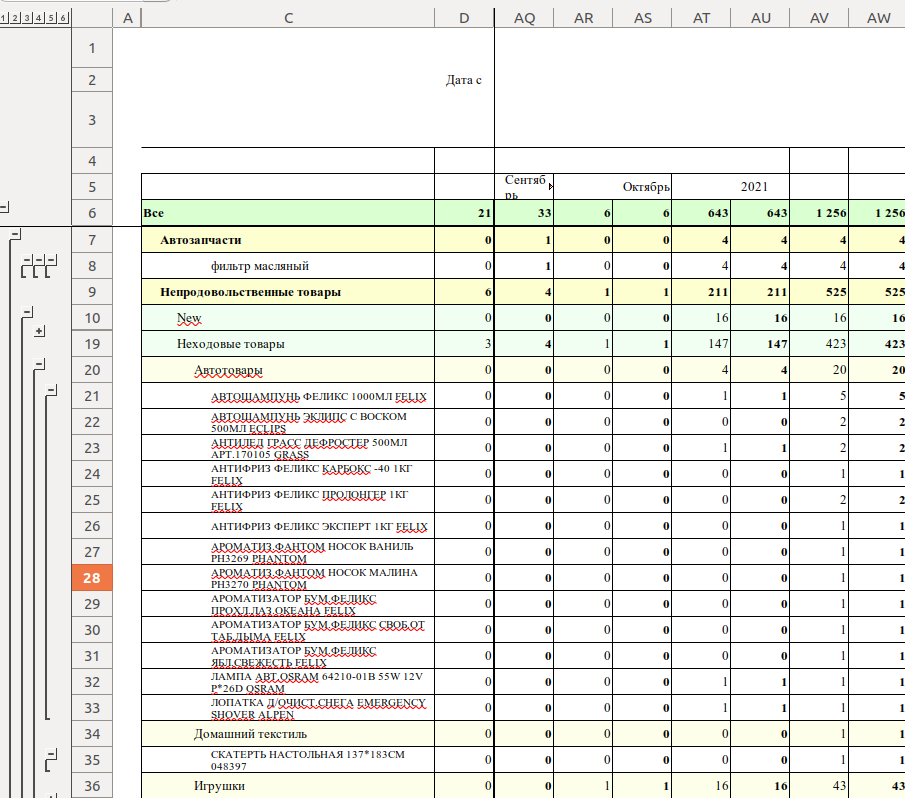
6. Еще одна мелочь - а приятно.
Если в отчете присвоить имя Anchor

то поле при экспорте в xlsx становится именованным

что позволяет в шаблон отчета вставлять поля с формулами эксель в виде сводок и произвольных формул

Устанавливаем свойство экспорта в электронную таблицу

Не забыть добавить свойство ко всему отчету

Итого получим в ячейке результат работающий как формула. (В Calc возможно надо будет после открытия нажать Ctrl-F9)

Данная возможность позволяет не только добавлять сводки и расчеты с параметрами (например позже ввести ставку планируемого налога в готовый отчет), но и формировать группу связанных ссылками отчетов, что часто практикуется при значительном использовании электронных таблиц на предприятии.



