
Всем привет! Cегодня я расскажу, как применять InfluxDB для мониторинга систем хранения данных.
Я затрону следующие темы:
В конце я расскажу, какие преимущества всё это нам дало и о некоторых из созданных нами инструментальных панелей.
Начнём наше путешествие в стек InfluxDB. Чтобы вы лучше понимали все те вызовы, с которыми нам пришлось столкнуться, давайте я расскажу о нашем продукте.
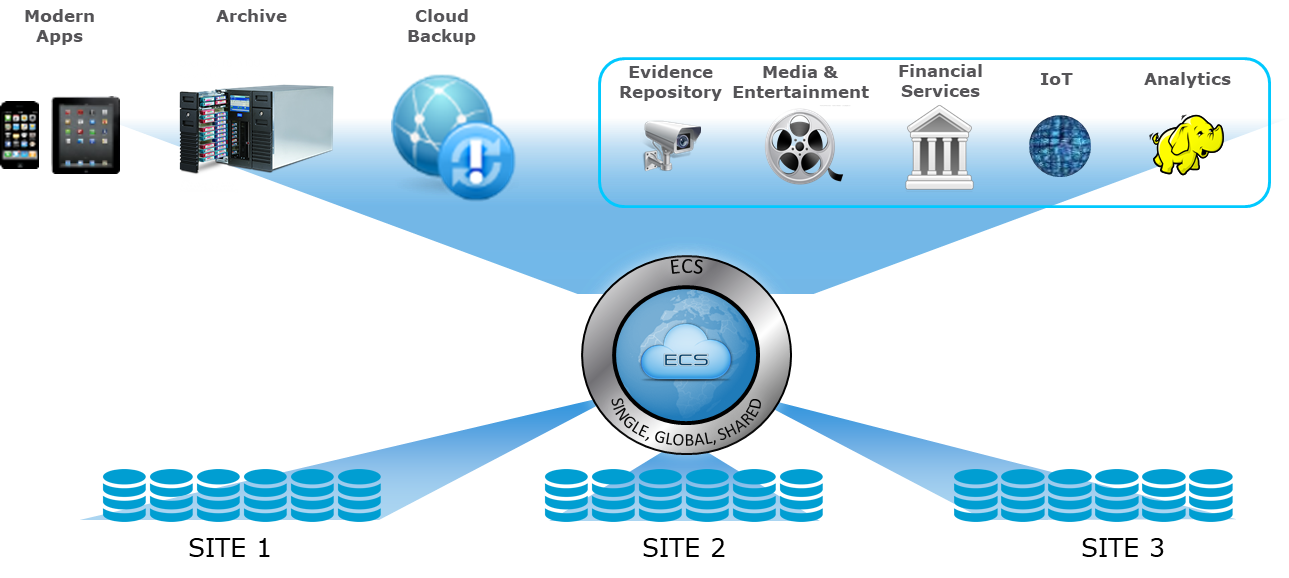
ECS является ведущей объектной платформой хранения Dell EMC, которая может похвастаться непревзойдённой масштабируемостью, производительностью, отказоустойчивостью и экономической эффективностью. Имея возможность развёртывания в качестве реального оборудования или по программно-определяемой модели, ECS обеспечивает высокую совместимость с S3 на глобально распределённой архитектуре, позволяя организациям выдерживать нагрузки в масштабах предприятия — с широким использованием приложений Cloud-Native, Archive, IoT, AI, а также Big Data Analytics.
ECS управляется заказчиками. Таким образом, мы продаём заказчикам стойку с реальным оборудованием и программным обеспечением и не занимаемся их управлением.
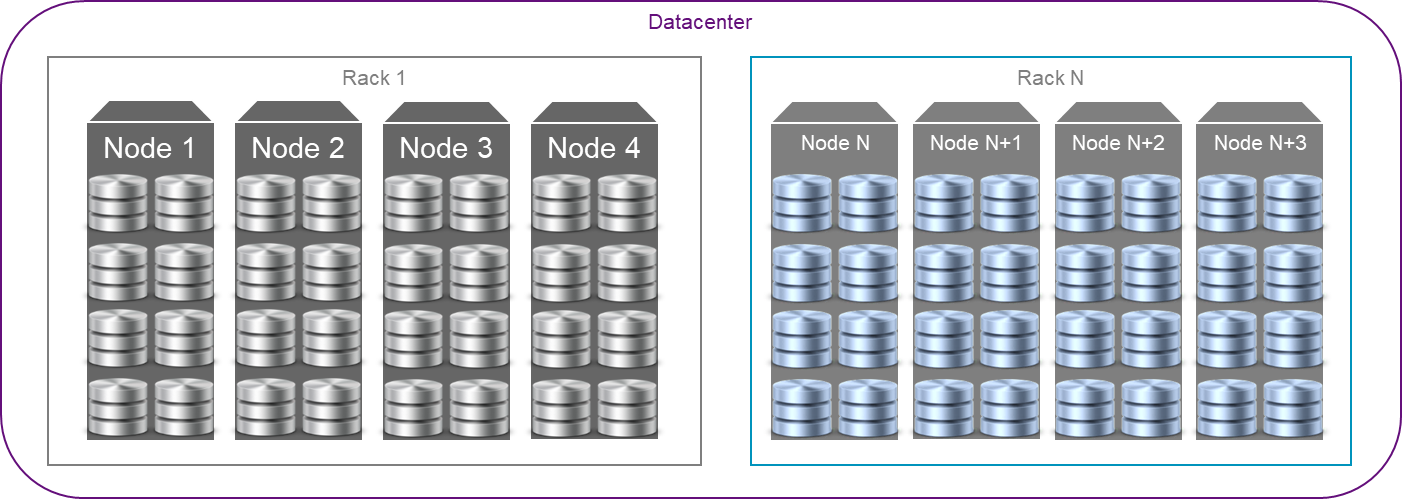
ECS развёртывается на серийном оборудовании с множеством дисков. ECS является горизонтально масштабируемой системой с гомогенными узлами, поэтому на всех узлах запущен одинаковый набор служб.
У нас нет узлов уровня управления, предназначенных для управления и мониторинга.
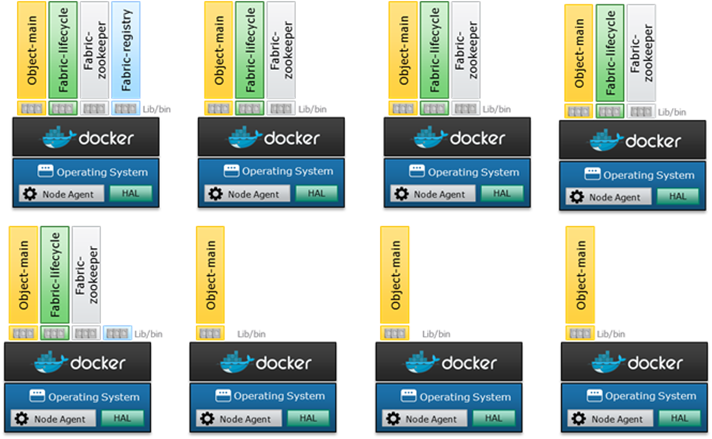
ECS развёртывается на операционной системе Linux внутри контейнеров Docker. Службы главного Datapath выполняются внутри главного контейнера. Службы мониторинга выполняются в отдельных контейнерах Docker. У всех контейнеров есть лимиты выделенной памяти. Разумеется, у главного контейнера Docker для служб Datapath лимиты памяти установлены на максимально достижимые для узлов значения после выделения небольшой части памяти под несколько контейнеров для оркестровки и мониторинга.
Поскольку ECS является продуктом, устанавливаемым у заказчика и управляемым заказчиком, он должен иметь собственный мониторинг, выполняемый внутри самого продукта.
Внутренний мониторинг ECS используется для мониторинга следующих аспектов системы:
Когда моя команда перешла к работе над внутренним мониторингом ECS, внутри уже был фреймворк внутреннего мониторинга. Он послужил отличной отправной точкой, однако имел несколько недостатков:
Целью нашей группы было найти решение для преодоления упомянутых недостатков и предложить фреймворк для мониторинга, который мог бы обеспечить следующее:
Основными сложностями при создании нового решения по мониторингу были:
Поскольку у нас уже был некоторый опыт мониторинга ECS в тестовом окружении, мы выполнили исследование по поиску решения для мониторинга с открытым исходным кодом, которое могло бы удовлетворить наши нужды.
В финальный список кандидатов вошли три альтернативных решения:
ELK
Мы начали изучать вопрос с ElasticSearch. Его использует множество компаний из-за гибкости аналитических возможностей и практически неограниченных возможностей по подготовке высококачественных многомерных представлений точек данных разного рода.
Но когда мы заполнили ELK всеми метриками из одиночного кластера ECS, то вскоре поняли, что гибкость имеет свою цену. В нашем случае ценой было слишком большое потребление ресурсов: мы никак не могли запустить кластер ELK с лимитом всего в 3 Гб на узел.
Prometheus
Следующим рассмотренным нами решением стал Prometheus.
Мы уже использовали его для мониторинга тестового окружения и знали о его высокой производительности при очень малом потреблении дискового пространства и простом в использовании языке запросов.
Мы также знали об ограничениях на данные с высокой кардинальностью, что является проблемой для многих баз данных временных рядов и обычно требует много ресурсов памяти, которые мы не могли предоставить. Однако наш план в отношении данных с высокой кардинальностью заключался в том, чтобы контролировать и избегать их.
Тем не менее, с Prometheus также возникли проблемы на стадии изучения. На тот момент он вообще не поддерживал обратное заполнение. А для нас это была очень важная фича, поскольку нам был нужен способ заполнения инстанса с пропусками после простоя одного из инстансов Prometheus.
Другой большой проблемой стала неспособность Prometheus надёжно работать при получении редких точек данных, а также плохие показатели при подсчёте точных значений.

Когда в Prometheus имеются редкие точки данных, результат будет неточным. Например, если интервал между запросами составляет 2 минуты, а мы хотим рассчитать повышение значения за последние 4 минуты, то Prometheus для расчёта экстраполирует две точки данных. Чем меньше у вас точек в интервале, тем более неточным будет результат функций объединения, которые будут визуализировать значения, способные оказаться в конце интервалов. Этого может быть достаточно для некоторых системных метрик (например, CPU), но такой способ не подходит для точного вычисления метрик, относящихся к ёмкости системы хранения.
Поэтому мы решили, что Prometheus также не подходит для наших нужд.
InfluxDB
Третьим рассмотренным нами решением стал стек InfluxDB. У него были такие же проблемы с высоким потреблением ресурсов при высокой кардинальности, но мы планировали контролировать кардинальность наших метрик.
Первые попытки использования InfluxQL показали, что в первоначальном виде языку InfluxDB недостаёт нескольких очень важных фич: например, возможности выполнять вычисления между измерениями. Это был тупик: мы не могли использовать InfluxDB, поскольку нам нужно было выполнять запросы, которые бы объединяли метрики после различных измерений для получения конечных результатов. Ведь при распределённом хранении бывают случаи, когда для расчёта конечного результата нужно объединить метрики нескольких служб.
Но тут Influx анонсировал новый язык запросов Flux. Мы убедились, что он обладает достаточной гибкостью для выполнения расчётов любой нужной нам сложности.
InfluxDB также показал великолепную производительность при низком потреблении памяти и ресурсов CPU на ряд, а также низком использовании диска, сравнимых с Prometheus.
Мы смогли успешно использовать язык Flux для выполнения точных расчётов даже для редких метрик.
InfluxDB также поддерживал обратное заполнение.
Финальный выбор
Таким образом, Elastic Search и Prometheus не удовлетворили наши запросы, и для внутреннего мониторинга нашей системы распределённого хранения мы выбрали InfluxDB в качестве нового стека мониторинга.
Далее я расскажу про добавление HA в InfluxDB.
PoC системы мониторинга на InfluxDB
Итак, мы решили использовать InfluxDB в качестве главной Time Series Database, которая будет выполняться на кластере ECS для осуществления внутреннего мониторинга. Мы создали контейнер Docker для InfluxDB и изменили нашу оркестровку для развёртывания InfluxDB на одном из узлов кластера.
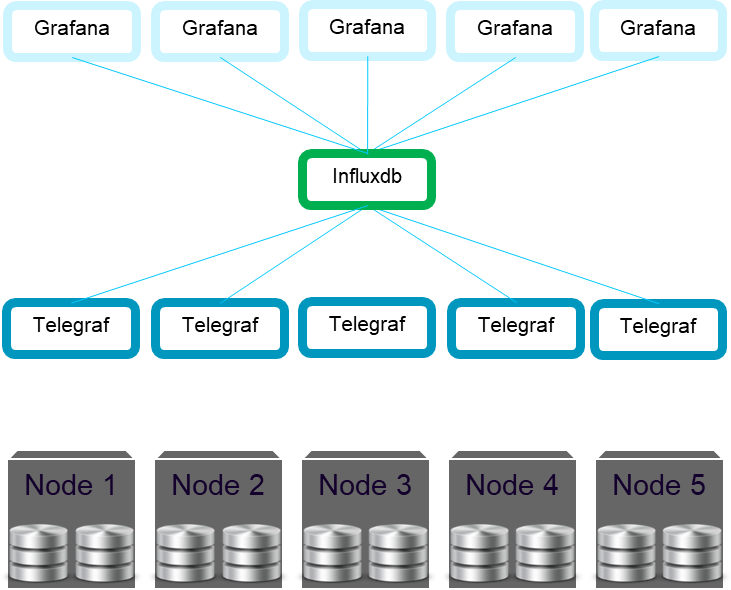
Затем мы создали контейнер Docker для Telegraf и развернули Telegraf на всех узлах кластера для сбора статистических данных на системном уровне, а также для работы в качестве прокси у служб, выполняющихся на всех узлах и помещающих статистику на InfluxDB.
Таким образом, сервисы не обязаны знать место расположения InfluxDB — от них требуется только помещать статистику в Telegraf локального хоста.
В качестве UI для нового фреймворка мониторинга мы выбрали Grafana. И запустили его в контейнере Docker на всех узлах, чтобы заказчик мог получить доступ к ECS UI на любом узле в кластере. Внутрь Grafana мы добавили скрипт, который при запуске предоставлял все необходимые панели инструментов и создавал источник данных InfluxDB, для чего взяли конечную точку InfluxDB из нашего уровня оркестровки.
PoC был готов, и мы смогли создать несколько базовых панелей инструментов для Grafana и увидеть информацию о работоспособности системы.
Что делать с ошибками?
Разумеется, у нас были требования Управления по продукту. Согласно ним, ECS должен был нормально работать при отказе двух узлов.
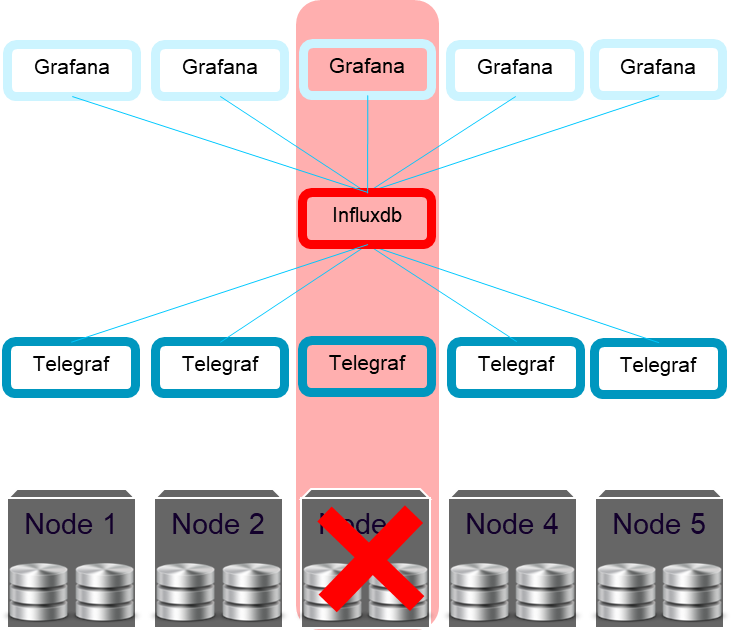
Если бы мы не решили эту задачу, узел, на котором происходил фатальный сбой InfluxDB, становился бы недоступен. Также стали бы недоступны все данные мониторинга, а на панелях инструментов Grafana не отображались бы данные.
Что плохо.
Напоминаем, что у нас не было никакого совместно используемого узлами хранилища, поэтому нельзя было просто перезапустить InfluxDB на другом узле. InfluxDB хранит данные на локальном диске, а значит, при фатальном сбое узла данные с этого инстанса InfluxDB становятся недоступны из других мест.
Как решить такую проблему?
Разумеется, запускать несколько инстансов InfluxDB.
Базовый HA
Чтобы система работала при фатальном сбое двух узлов, нам нужно выполнять три инстанса InfluxDB на разных узлах. Telegraf отправляет метрики на все инстансы InfluxDB.
Таким образом, у нас имеются три идентичные копии InfluxDB. В Grafana есть шаблонная переменная, при помощи которой можно выбрать, какой InfluxDB использовать на текущей панели инструментов.

В случае фатального сбоя двух узлов InfluxDB у нас всё равно остаётся работоспособным третий инстанс InfluxDB, и заказчик может видеть точки данных на панели инструментов Grafana после выбора работоспособного источника данных InfluxDB.

Что замечательно!
Теперь мы, кажется, удовлетворяем требование Управления по продукту о поддержании работоспособности при сценарии с фатальным сбоем двух узлов.
Recovery на старте
Вот только… что если после продолжительного простоя двух узлов и их оживления у нас произойдёт фатальный сбой на третьем узле?
В этом случае работоспособные инстансы InfluxDB не будут иметь доступа к данным за период, пока они были неработоспособны, так что заказчики не смогут видеть некоторые диапазоны данных, пока не восстановится третий инстанс.
Может быть даже хуже: например, если третий инстанс сгорит и придётся заменить отказавший узел, что приведёт к потере данных мониторинга, которые сохранялись только на третьем инстансе.
Это, конечно, плохо.
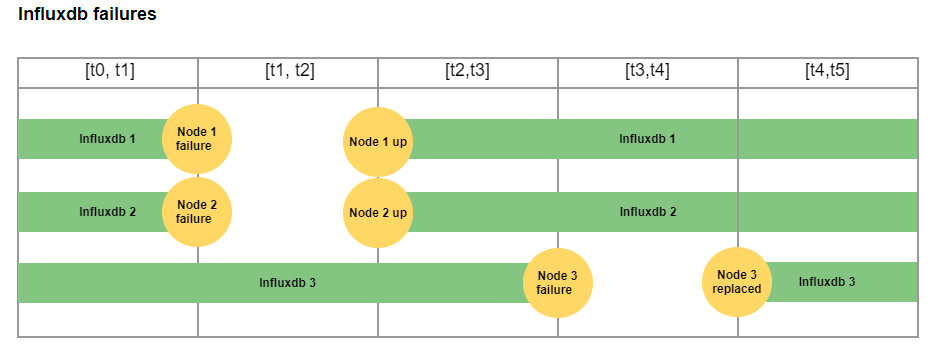
Чтобы избежать такой проблемы, мы решили, что можем восстановить данные на InfluxDB при запуске инстанса.
Во избежание проблем с обратным заполнением мы постарались восстановить при запуске как можно больше данных перед запуском InfluxDB на порте, к которому есть доступ у Telegraf. Для этого мы запустили InfluxDB за два этапа. На первом этапе мы запустили его на другом порте (во избежание новых записей от Telegraf) и восстановили данные из других инстансов InfluxDB за период, во время которого InfluxDB был неработоспособен. На втором этапе мы запустили на обычном порте и восстановили небольшое количество точек данных, которые отсутствовали во время первого этапа. При необходимости мы инициировали восстановление недостающих периодов в фоне.
Такое решение позволило нам не нагружать InfluxDB большим количеством запросов на обратное заполнение и записывать столько же данных при восстановлении в дружественной по отношению к InfluxDB форме путём присоединения новых записей.
Для восстановления мы используем стандартный API копирования-восстановления InfluxDB. Для больших периодов мы разбиваем восстановление на части по одному дню, чтобы не вызвать нехватку памяти в случае, если узел был неработоспособен в течение нескольких недель, и пытаемся восстановить все недостающие данные за одну большую транзакцию.

Теперь всё хорошо, и мы готовы выдержать повторяющиеся отказы или простои. Мы даже сможем справиться с повторяющейся заменой узла, что полезно при обновлении техники, когда заказчик заменяет всё оборудование узлов новым по окончании срока службы старого оборудования.
Итак, в результате использования нескольких инстансов InfluxDB и API копирования-восстановления мы смогли создать высокодоступную структуру инстансов InfluxDB, способную работать при сценарии с фатальным сбоем двух узлов и заменой узлов или при сценарии обновления техники.
Сейчас я перейду к следующему шагу нашего путешествия и расскажу, как мы улучшили уровень вычисления запроса, выделяя его из InfluxDB и делая его горизонтально масштабируемым.
Как вы помните, когда мы добавили три инстанса InfluxDB, то были вынуждены добавить шаблонную переменную в инструментальные панели Grafana, чтобы заказчик мог выбрать хороший инстанс InfluxDB в качестве источника данных.

Но щёлкать по разным инстансам InfluxDB в попытках угадать, который из них в настоящий момент работоспособен и имеет полностью восстановленную базу данных за нужный вам период, — это не лучший опыт использования.
Мы начали думать над тем, как улучшить ситуацию, — и нашли решение.
Мы решили, что нам нужен отдельный вычислительный слой, который будет состоять из служб, выполняющихся на всех узлах и берущих необработанные данные из InfluxDB. И назвали эту службу в честь нового языка InfluxDB — Fluxd.
Данная архитектура позволила нам иметь инстанс службы Fluxd на локальном хосте в качестве единственного источника данных для Grafana. Более того, мы смогли спрятать источник данных InfluxDB от заказчика и всегда использовать Fluxd на локальном хосте в качестве источника данных.

Служба Fluxd должна быть достаточно умной, чтобы понимать, какой из инстансов InfluxDB лучше всего подходит для выполнения каждого конкретного запроса. Когда Fluxd получает запрос от Grafana или любой другой службы, он разбивает запрос и отправляет его необработанным в InfluxDB. Необработанный запрос обычно включает первые три строки: from() filter() range(). Некоторые функции — например, функция last() — также могут быть отправлены в InfluxDB для ускорения запроса, чтобы InfluxDB вернул только последнюю точку вместо полного диапазона.
Fluxd выбирает лучший инстанс InfluxDB, имеющий все восстановленные периоды для используемой в запросе базы данных. Если в запросе указан период, который присутствует во всех инстансах InfluxDB лишь частично (например, после простоя возникли некоторые проблемы при немедленном выполнении восстановления и оно будет выполнено позднее), то Fluxd отвечает за отправку запроса на все инстансы InfluxDB и объединение результатов (дедупликацию результатов во время объединения).
После того как Fluxd получает необработанные данные из InfluxDB, он выполняет оставшиеся вычисления Flux для запроса. Это дополнительно освобождает вычислительные ресурсы от инстансов InfluxDB (они не масштабируются по горизонтали, а потому любое уменьшение потребления ресурсов InfluxDB важно для нас).

Это важно, поскольку у нас был локальный инстанс Fluxd в качестве источника данных для Grafana, а также другие службы, выполняющиеся на узле, которые требовали несколько мониторинговых запросов, что приводило к проблемам с перегрузкой одного из инстансов Fluxd.
Дополнительная балансировка нагрузки между инстансами сервиса Fluxd позволила нам получить минимальное потребление ресурсов на каждом отдельном инстансе Fluxd при сохранении высокой скорости обработки запросов. Это идеально совпало с нашими требованиями к распределённой архитектуре нашего фреймворка мониторинга с горизонтальной масштабируемостью.

Другое серьёзное преимущество при использовании отдельного вычислительного слоя состоит в том, что службы Fluxd не имеют состояния (Stateless). Потеря любого узла с инстансом Fluxd всего-навсего удаляет одного из работников из пула, не оказывая при этом особого влияния на кластер.
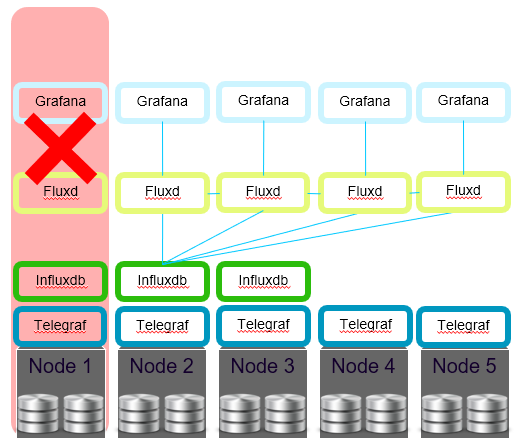
Введя вычислительный слой для запросов, мы:
Теперь я подробно расскажу, как мы добились того, чтобы InfluxDB и другие компоненты его стека подстроились под наши требования к низкому потреблению ресурсов.
Во избежание ошибок нехватки памяти и отказов контейнера Docker наш стек мониторинга должен потреблять предсказуемое количество ресурсов с лимитом в 3 Гб на узле. Главными компонентами нашего стека мониторинга являются Telegraf, InfluxDB, Fluxd и Grafana. Самым ценным ресурсом на наших кластерах является память.
Мы уже видели, как нам удалось освободить InfluxDB от необходимости делать расчёты и снизить его потребность в памяти. Давайте посмотрим, какие ещё шаги нам пришлось сделать, чтобы достичь предсказуемо низкого потребления ресурсов.
Telegraf
Начнём с Telegraf.
Все выполняющиеся на узле службы отправляют свои метрики на локальный инстанс Telegraf. И у нас есть определённые периоды, когда службы могут помещать метрики, так что они не делают это неконтролируемо.

Но произойти может всякое, и в ситуациях сбоя службы могут начать помещать больше метрик, чем ожидалось, создавая большую нагрузку на Telegraf. Это может привести к большему потреблению памяти: когда службы начинают помещать слишком много метрик, Telegraf достигает лимита памяти и его завершает OOM Killer внутри контейнера Docker.
Это не то, чего мы хотим при возникновении ошибки.
Если какая-либо служба выходит из-под контроля и начинает помещать больше метрик, чем ожидалось, нам лучше игнорировать метрики, а не завершать процесс из-за нехватки памяти. Тем самым мы радикально снизим функциональность нашего стека вместо того, чтобы сразу столкнуться с отказом от обслуживания.
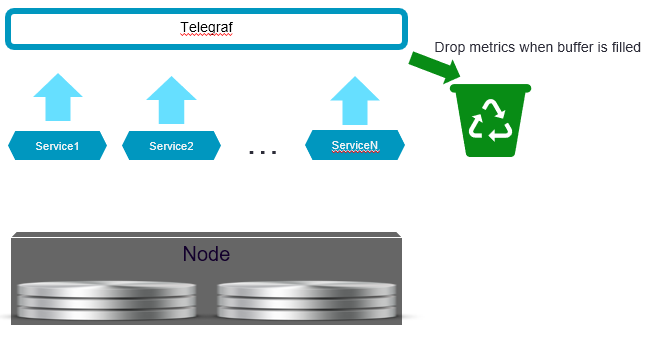
Чтобы справиться с проблемой, нам нужно было задать определённый предел буфера памяти и размер пакета в конфигурации Telegraf.
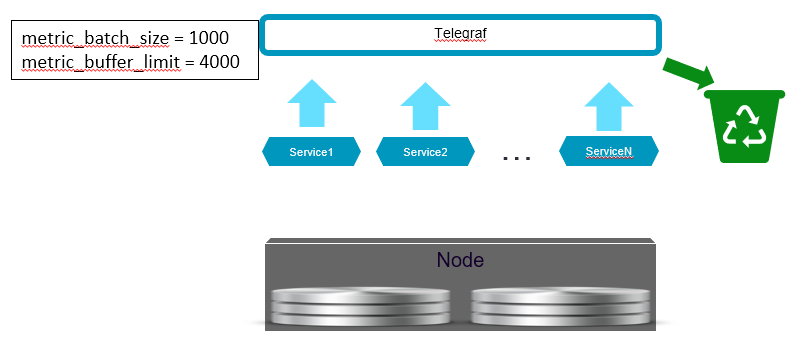
Определив предел буфера, мы также приняли во внимание ситуацию, когда некоторые инстансы InfluxDB оказываются неработоспособны и соответствующие буферы будут всегда полны. Telegraf сохраняет отдельный буфер памяти при каждом выходе, поэтому если вам нужно обработать несколько неработоспособных выходов и быть уверенными, что Telegraf не завершит работу из-за нехватки памяти, вам нужно обеспечить дополнительное место для полного буфера при каждом выходе, который вы определяете в конфигурации Telegraf.

Теперь у Telegraf имелся предсказуемый объём памяти для получаемых метрик, и мы думали, что закончили оптимизацию Telegraf и уже никогда не увидим его перезапуск из-за нехватки памяти.
Но однажды на площадке заказчика возникла новая проблема. Да-да, Telegraf периодически перезапускался из-за нехватки памяти.
Мы были уверены, что это не из-за метрик, получаемых от служб на входе HTTP, поскольку у нас уже были определены подходящие лимиты для буферов памяти. И углубились в вопрос, чтобы понять первопричину.
Разумеется, в Telegraf мы использовали много разных входных плагинов для сбора разных системных метрик. У большинства этих плагинов имелся встроенный код на Go. При изучении проблем с памятью у Telegraf мы обнаружили, что лишняя память потреблялась не самим Telegraf, а другими двоичными программами, которые вызывались из выполняемых входных плагинов.
Мы вспомнили, что для некоторых метрик, которые отсутствовали в наших службах, мы написали несколько скриптов, которые вызывались из исполняемого входного плагина Telegraf для сбора этих метрик. Выяснилось, что в некоторых средах заказчика при некоторых условиях эти скрипты могут потреблять намного больше памяти, чем мы ожидали. Именно это вызывало проблемы нехватки памяти в контейнере Telegraf. Позже мы обнаружили, что такие проблемы вызывают не только клиентские скрипты, но и несколько хорошо известных двоичных программ, используемых для выполняемых входных плагинов: они также могут потреблять неожиданно много памяти.
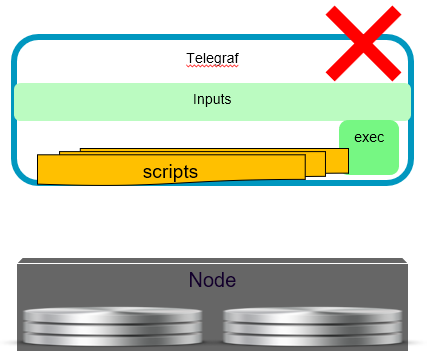
Как решить подобную проблему?
Никогда не использовать выполняемые входные плагины. Особенно при исполнении Telegraf внутри контейнера Docker и заданных для него низких лимитах памяти. Всегда заставляйте группы поддержки добавлять нужную статистику в их отчёты вместо того, чтобы пытаться собрать их, используя клиентские скрипты внутри Telegraf.

В итоге мы убрали все выполняемые входные плагины из нашего Telegraf. И угадайте что?
Telegraf больше не падал из-за нехватки памяти. Нам наконец удалось добиться стабильной работы для нашего варианта использования. При этом полный контейнер Telegraf использовал лимит в 150 Мб памяти. Да, это было на 100 Мб больше, чем мы ожидали от Telegraf изначально, — но всё равно очень хорошо.
Итак, мы закончили оптимизировать Telegraf, и теперь настало время внимательно изучить InfluxDB.
InfluxDB
Существует несколько факторов, определяющих, сколько памяти будет потреблять InfluxDB:
Мы уже показали, как освободили InfluxDB от сложных расчётов. Теперь давайте посмотрим, что можно сделать с другими факторами.
Когда мы впервые настроили InfluxDB для получения всех доступных в кластере метрик, то были разочарованы тем, сколько памяти потребовалось InfluxDB, чтобы справиться со всеми этими метриками. Объём составлял около 30 Гб!
Фильтрование ненужных метрик
Мы знали, что для видимых заказчику панелей инструментов нам нужно около 5 % всех метрик. Ещё примерно 5 % требуется для дополнительных панелей инструментов для Службы поддержки.
Все прочие метрики были добавлены до нас, и ими, кажется, никто не интересовался. Поэтому мы решили, что можно отказаться от них и не помещать эти метрики во внутренний мониторинг. А всем группам перед добавлением новых метрик для внутреннего мониторинга нужно будет пройти нашу проверку, которая обеспечивает, чтобы никто не отправлял данные с высокой кардинальностью во внутренний мониторинг.

Уменьшение интервала посылки метрик
Мы также снизили интервал помещения метрик до минимального: на этом настаивали менеджеры по продукту. ECS UI показывал точки данных каждые 5 минут, так что мы уменьшили интервал помещения для всех метрик до 5 минут — как у Telegraf, так и у служб, генерирующих метрики.
Результат был поразительным! Потребление памяти InfluxDB упало до 2 Гб — и наша цель была достигнута.
Выбор размера шард
Когда мы в течение нескольких месяцев проводили ресурсные испытания на нашем кластере, то обнаружили, что InfluxDB постепенно начал потреблять намного больше памяти, чем мы ожидали. Конечно, мы знали, что сохранение большой истории будет стоить нам ресурсов, но InfluxDB требовал слишком многого.
Проведя исследование, мы обнаружили проблему с индексом InfluxDB.
Вы помните, что все базы данных в InfluxDB имеют политику хранения (Retention)? И что любая политика хранения включает Shard Duration (длительность шарда), которая определяет, сколько шардов будет в вашей базе данных? Например, если ваша политика предполагает срок хранения 2 месяца, а длительность шарда задана равной 1 дню, у вас будет 60 шардов.
Но каждый шард имеет собственный индекс. А индекс является самой требовательной к ресурсам частью InfluxDB. Если в вашей базе данных 60 шардов, у них будет 60 индексов. А 60 индексов потребуют намного больше ресурсов по сравнению со, скажем, 10 шардами при одинаковой политике хранения.
Поэтому запомните одно простое правило: старайтесь не использовать в своей политике хранения больше 10 шардов.
При небольшом времени хранения нормально использовать 1 шард. При длительном хранении учитывайте, что InfluxDB поддерживает работу политики хранения за счёт удаления шардов, если все содержащиеся в них точки данных старше указанного в политике времени хранения. Таким образом, если у вас задана длительность шарда, равная 10 дням, InfluxDB иногда будет хранить в базе данных точки ещё на 10 дней старше, чем задано политикой хранения, пока не сможет удалить самый старый шард.
Никогда не используйте длительность шарда, способную привести к увеличению количества шардов свыше 10. Иначе вы будете расплачиваться за это памятью.
Уменьшение потребления ресурсов при интеграции с внешним мониторингом
Мы закончили, наконец, оптимизировать Telegraf и InfluxDB, оставив Fluxd и Grafana ровно столько памяти, сколько нужно для их нормальной работы, и могли расслабиться, зная, что наш стек мониторинга никогда не пострадает из-за нехватки памяти на площадке заказчика.
Но ECS эксплуатируется заказчиками, и у нас было ещё несколько сценариев использования, потребовавших оптимизации памяти.
Вы всё ещё помните, что ECS эксплуатируется заказчиками в больших центрах обработки данных? И знаете что? Иногда заказчики используют внешний мониторинг и нуждаются во всех метриках от системы, чтобы научиться с ним работать.

Наше первое решение для такого сценария использования было простым: внешний мониторинг только периодически опрашивает Fluxd для получения нужных данных. Звучит хорошо, однако мы быстро нашли недостатки такого подхода.
Внешний мониторинг требует много метрик. Поэтому он выполняет много запросов, нагружает Fluxd и занимает больше памяти, чем мы хотели. Также мониторинг загружал больше инстансов InfluxDB, которым приходилось постоянно извлекать много необработанных данных.
Мы также знали, что внешний мониторинг имеет намного больше свободных ресурсов, чем у нас было на внутреннем мониторинге, и мы сможем создать существенно больше сложных панелей инструментов с гораздо большей детализацией. Во внутренний мониторинг мы не помещали все возможные метрики из служб, а только критически важные метрики, требуемые заказчиком или необходимые при поиске неисправностей.
Таким образом, если внешний мониторинг опрашивает метрики из Fluxd, у него будет доступ только к метрикам, заданным для внутреннего мониторинга. Но нам хотелось большего.

Мы нашли следующее решение: помещать все метрики из инстансов Telegraf не только во внутренний InfluxDB, но и в инстанс внешнего мониторинга. Мы не применяли никакой логики фильтрации для этих внешних исходящих данных, что позволило поместить все доступные метрики. Поскольку метрики помещались в момент создания, это почти не увеличило потребление ресурсов инстансами Telegraf — только размер одиночного буфера памяти, что немного.
Теперь заказчик получает все нужные данные из системы при внешнем мониторинге. Мы даже смогли предоставить больше подробностей насчёт работоспособности и больше деталей с разбивкой ёмкости по внешней системе мониторинга, используя дополнительные непрерывные запросы.
Такой подход позволил нам сохранить контроль над низким потреблением ресурсов компонентов мониторинга для сценария с интегрированием внешнего мониторинга в систему.

Результаты
В этом разделе я показал, какими способами мы смогли контролировать ресурсы памяти в стеке мониторинга InfluxDB, а именно:
Теперь кратко расскажу о шагах, которые потребовались, чтобы мы действительно смогли переключить наш стек мониторинга.
Вначале мы начали работать над изменением стека мониторинга. Для ECS уже имелся рабочий фреймворк мониторинга. Все службы помещали метрики во фреймворк статистики. UI использовал специальную службу панели инструментов, которая готовила данные из фреймворка статистики. Также у нас был предупреждающий фреймворк с уже определёнными различными правилами предупреждений, и некоторые из них использовали фреймворк статистики для предупреждений по метрикам. Но снова-таки все запросы были написаны в виде чистого кода на Java.

Когда мы начали вводить новый фреймворк мониторинга, мы знали, что не сможем полностью переключиться за один релиз. Поэтому мы решили следовать паттерну Strangler Application Pattern и создать новый фреймворк мониторинга, который будет работать параллельно со старым фреймворком. Ведь нам требовалось несколько релизов для переключения стека мониторинга, а мы не могли себе позволить ни на йоту ухудшить функционал, ведь мониторинг и предупреждения у нас уже работали.
Мы добавили в службы нашей низкоуровневой библиотеки простую логику, которая помещала метрики во фреймворк статистики, и теперь могли отправлять метрики в оба стека. Помимо фреймворка статистики такая логика отправляла все метрики в локальный инстанс Telegraf.
Решив вопрос с отправкой метрик в оба стека мониторинга, мы смогли, не нарушая работы, добавлять новые панели инструментов системного уровня в Grafana. Затем мы выпустили следующую версию ECS. Теперь служба поддержки имела намного лучшие панели инструментов и могла быстрее решать проблемы, изучая системные метрики, такие как CPU, память и размер файла подкачки для каждой службы. По требованию службы поддержки был развёрнут Grafana.
Для нашего следующего релиза мы смогли интегрировать ECS UI и предупреждающий фреймворк, чтобы получать несколько метрик из нового фреймворка мониторинга, который позволил добавить несколько панелей внутрь UI, и добавить новые предупреждения во фреймворк предупреждений при помощи запросов Flux. На этом же этапе мы встроили Grafana в виде iframe в ECS UI, чтобы избежать отдельной авторизации для него. Мы также добавили в Grafana несколько видимых заказчику панелей инструментов — и выпустили новую версию ECS.
После этого стало возможным перенести функционал, связанный с мониторингом, для использования запросов Flux и изъятия старого фреймворка статистики.
Следуя этой стратегии, мы смогли продолжить выпускать новые версии ECS, одновременно изменяя стек мониторинга под прикрытием, улучшая способности к мониторингу нашего продукта и делая группы поддержки более автономными, чтобы те могли добавлять новые предупреждения или создавать новые панели инструментов, используя только запросы Flux.
Давайте взглянем, какие панели инструментов у нас получились в результате изменений стека мониторинга.
Как я уже сказал, панелей было добавлено много, так что все я показать не смогу. Но несколько мы посмотрим.
Панели инструментов с метриками производительности

Мы смогли добавить различные эксплуатационные характеристики, включая разделение по типу метода и протоколу. А также создали детальную панель инструментов касательно задержки системы, показывающую не средние значения задержек, а процентили p50 и p99 (как вы понимаете, это оказывает огромное влияние на понимание реальных задержек системы).
Панели инструментов с системными метриками
Они показывают уровень узла, а также системную статистику по процессам, таким как память, CPU, файл подкачки. Эти панели инструментов очень помогли при изучении различных проблем на площадке заказчика. Они первые, на которые смотрит служба поддержки в поисках первопричины.

Панель инструментов Top N Buckets
Она показывает заказчику самые большие области памяти в системе по размеру и по количеству объектов.

Чтобы рассказать обо всех панелях инструментов, которые нам удалось создать, используя новый фреймворк мониторинга, потребовалась бы ещё одна такая статья. Их действительно много!
Мы подошли к финалу истории, и настало время подвести итоги. Итак:
Желаю вам удачи в использовании InfluxDB в вашем продукте!
Я затрону следующие темы:
- Наше путешествие в стек мониторинга InfluxDB для мониторинга систем хранения ECS.
- Как мы добавили High Availability в версию InfluxDB c открытым исходным кодом.
- Как мы улучшили слой вычисления запроса, выделив его из InfluxDB и сделав его горизонтально масштабируемым.
- Как мы смогли развернуть стек InfluxDB на ресурсах со сравнительно небольшим объёмом памяти.
- И наконец, как мы смогли включить стек мониторинга для хранилища ECS в несколько этапов.
В конце я расскажу, какие преимущества всё это нам дало и о некоторых из созданных нами инструментальных панелей.
Внутренний мониторинг для СХД
ECS. Что это?
Начнём наше путешествие в стек InfluxDB. Чтобы вы лучше понимали все те вызовы, с которыми нам пришлось столкнуться, давайте я расскажу о нашем продукте.
ECS является ведущей объектной платформой хранения Dell EMC, которая может похвастаться непревзойдённой масштабируемостью, производительностью, отказоустойчивостью и экономической эффективностью. Имея возможность развёртывания в качестве реального оборудования или по программно-определяемой модели, ECS обеспечивает высокую совместимость с S3 на глобально распределённой архитектуре, позволяя организациям выдерживать нагрузки в масштабах предприятия — с широким использованием приложений Cloud-Native, Archive, IoT, AI, а также Big Data Analytics.
ECS управляется заказчиками. Таким образом, мы продаём заказчикам стойку с реальным оборудованием и программным обеспечением и не занимаемся их управлением.
ECS развёртывается на серийном оборудовании с множеством дисков. ECS является горизонтально масштабируемой системой с гомогенными узлами, поэтому на всех узлах запущен одинаковый набор служб.
У нас нет узлов уровня управления, предназначенных для управления и мониторинга.
ECS развёртывается на операционной системе Linux внутри контейнеров Docker. Службы главного Datapath выполняются внутри главного контейнера. Службы мониторинга выполняются в отдельных контейнерах Docker. У всех контейнеров есть лимиты выделенной памяти. Разумеется, у главного контейнера Docker для служб Datapath лимиты памяти установлены на максимально достижимые для узлов значения после выделения небольшой части памяти под несколько контейнеров для оркестровки и мониторинга.
Поскольку ECS является продуктом, устанавливаемым у заказчика и управляемым заказчиком, он должен иметь собственный мониторинг, выполняемый внутри самого продукта.
Внутренний мониторинг ECS используется для мониторинга следующих аспектов системы:
- Ёмкость (для распределённого хранения существует множество относящихся к ёмкости метрик, требующих сложных расчётов при подготовке статистики в виде, пригодном для заказчика).
- Производительность.
- Метрики внутренней работоспособности, получаемые от различных сервисов.
- А также для системного мониторинга работоспособности и использования ресурсов оборудования.
Предыдущее решение для мониторинга в ECS
Когда моя команда перешла к работе над внутренним мониторингом ECS, внутри уже был фреймворк внутреннего мониторинга. Он послужил отличной отправной точкой, однако имел несколько недостатков:
- Требовал участия нескольких групп для добавления ряда новых панелей инструментов в UI. Команда, отвечающая за мониторинг, не имела соответствующих знаний о том, как вносить изменения в разные сервисы, необходимые для добавления новых графиков в UI.
- Наш фреймворк не имел гибкого языка запросов.
- Из-за этого все запросы были написаны в виде кода внутри службы, выполняющего подготовку данных для UI или API.
- Во фреймворке также отсутствовало понятие Continuous Query, что вызывало проблемы при больших, длительных по времени запросах, когда нужно было выполнять сложные вычисления для большого количества точек с целью создания хронологических представлений.
Задачи новой системы мониторинга
Целью нашей группы было найти решение для преодоления упомянутых недостатков и предложить фреймворк для мониторинга, который мог бы обеспечить следующее:
- Возможность создания автономных групп поддержки, способных добавлять новые панели инструментов.
- Способ лёгкого создания новых графиков.
- Способ лёгкого создания новых алертов.
- Новый стек мониторинга, позволяющий выполнять детальный мониторинг системных ресурсов.
Сложности
Основными сложностями при создании нового решения по мониторингу были:
- Широкомасштабное развёртывание гомогенных серверов (крупные заказчики имеют кластеры из 300 серверов). А также тот факт, что на одном сервере недостаточно места для вертикального масштабирования в зависимости от размера кластера. Для мониторинга компонентов на одном сервере можно зарезервировать совсем немного памяти.
- Почти все ресурсы потребляются службами Datapath, поэтому обычно на узле отсутствуют свободные ресурсы. Таким образом, фреймворк мониторинга должен потреблять как можно меньше ресурсов. В качестве ограничения у нас был лимит в 3 Гб на сервер для использования всеми службами мониторинга (использование 3 Гб на узел допускалось, но превышать это значение было нельзя).
Альтернативы
Поскольку у нас уже был некоторый опыт мониторинга ECS в тестовом окружении, мы выполнили исследование по поиску решения для мониторинга с открытым исходным кодом, которое могло бы удовлетворить наши нужды.
В финальный список кандидатов вошли три альтернативных решения:
- ELK на основе ElasticSearch.
- Prometheus.
- InfluxDB.
ELK
Мы начали изучать вопрос с ElasticSearch. Его использует множество компаний из-за гибкости аналитических возможностей и практически неограниченных возможностей по подготовке высококачественных многомерных представлений точек данных разного рода.
Но когда мы заполнили ELK всеми метриками из одиночного кластера ECS, то вскоре поняли, что гибкость имеет свою цену. В нашем случае ценой было слишком большое потребление ресурсов: мы никак не могли запустить кластер ELK с лимитом всего в 3 Гб на узел.
Prometheus
Следующим рассмотренным нами решением стал Prometheus.
Мы уже использовали его для мониторинга тестового окружения и знали о его высокой производительности при очень малом потреблении дискового пространства и простом в использовании языке запросов.
Мы также знали об ограничениях на данные с высокой кардинальностью, что является проблемой для многих баз данных временных рядов и обычно требует много ресурсов памяти, которые мы не могли предоставить. Однако наш план в отношении данных с высокой кардинальностью заключался в том, чтобы контролировать и избегать их.
Тем не менее, с Prometheus также возникли проблемы на стадии изучения. На тот момент он вообще не поддерживал обратное заполнение. А для нас это была очень важная фича, поскольку нам был нужен способ заполнения инстанса с пропусками после простоя одного из инстансов Prometheus.
Другой большой проблемой стала неспособность Prometheus надёжно работать при получении редких точек данных, а также плохие показатели при подсчёте точных значений.
Когда в Prometheus имеются редкие точки данных, результат будет неточным. Например, если интервал между запросами составляет 2 минуты, а мы хотим рассчитать повышение значения за последние 4 минуты, то Prometheus для расчёта экстраполирует две точки данных. Чем меньше у вас точек в интервале, тем более неточным будет результат функций объединения, которые будут визуализировать значения, способные оказаться в конце интервалов. Этого может быть достаточно для некоторых системных метрик (например, CPU), но такой способ не подходит для точного вычисления метрик, относящихся к ёмкости системы хранения.
Поэтому мы решили, что Prometheus также не подходит для наших нужд.
InfluxDB
Третьим рассмотренным нами решением стал стек InfluxDB. У него были такие же проблемы с высоким потреблением ресурсов при высокой кардинальности, но мы планировали контролировать кардинальность наших метрик.
Первые попытки использования InfluxQL показали, что в первоначальном виде языку InfluxDB недостаёт нескольких очень важных фич: например, возможности выполнять вычисления между измерениями. Это был тупик: мы не могли использовать InfluxDB, поскольку нам нужно было выполнять запросы, которые бы объединяли метрики после различных измерений для получения конечных результатов. Ведь при распределённом хранении бывают случаи, когда для расчёта конечного результата нужно объединить метрики нескольких служб.
Но тут Influx анонсировал новый язык запросов Flux. Мы убедились, что он обладает достаточной гибкостью для выполнения расчётов любой нужной нам сложности.
InfluxDB также показал великолепную производительность при низком потреблении памяти и ресурсов CPU на ряд, а также низком использовании диска, сравнимых с Prometheus.
Мы смогли успешно использовать язык Flux для выполнения точных расчётов даже для редких метрик.
InfluxDB также поддерживал обратное заполнение.
Финальный выбор
Таким образом, Elastic Search и Prometheus не удовлетворили наши запросы, и для внутреннего мониторинга нашей системы распределённого хранения мы выбрали InfluxDB в качестве нового стека мониторинга.
Как мы добавили High Availability к InfluxDB OSS
Далее я расскажу про добавление HA в InfluxDB.
PoC системы мониторинга на InfluxDB
Итак, мы решили использовать InfluxDB в качестве главной Time Series Database, которая будет выполняться на кластере ECS для осуществления внутреннего мониторинга. Мы создали контейнер Docker для InfluxDB и изменили нашу оркестровку для развёртывания InfluxDB на одном из узлов кластера.
Затем мы создали контейнер Docker для Telegraf и развернули Telegraf на всех узлах кластера для сбора статистических данных на системном уровне, а также для работы в качестве прокси у служб, выполняющихся на всех узлах и помещающих статистику на InfluxDB.
Таким образом, сервисы не обязаны знать место расположения InfluxDB — от них требуется только помещать статистику в Telegraf локального хоста.
В качестве UI для нового фреймворка мониторинга мы выбрали Grafana. И запустили его в контейнере Docker на всех узлах, чтобы заказчик мог получить доступ к ECS UI на любом узле в кластере. Внутрь Grafana мы добавили скрипт, который при запуске предоставлял все необходимые панели инструментов и создавал источник данных InfluxDB, для чего взяли конечную точку InfluxDB из нашего уровня оркестровки.
PoC был готов, и мы смогли создать несколько базовых панелей инструментов для Grafana и увидеть информацию о работоспособности системы.
Что делать с ошибками?
Разумеется, у нас были требования Управления по продукту. Согласно ним, ECS должен был нормально работать при отказе двух узлов.
Если бы мы не решили эту задачу, узел, на котором происходил фатальный сбой InfluxDB, становился бы недоступен. Также стали бы недоступны все данные мониторинга, а на панелях инструментов Grafana не отображались бы данные.
Что плохо.
Напоминаем, что у нас не было никакого совместно используемого узлами хранилища, поэтому нельзя было просто перезапустить InfluxDB на другом узле. InfluxDB хранит данные на локальном диске, а значит, при фатальном сбое узла данные с этого инстанса InfluxDB становятся недоступны из других мест.
Как решить такую проблему?
Разумеется, запускать несколько инстансов InfluxDB.
Базовый HA
Чтобы система работала при фатальном сбое двух узлов, нам нужно выполнять три инстанса InfluxDB на разных узлах. Telegraf отправляет метрики на все инстансы InfluxDB.
Таким образом, у нас имеются три идентичные копии InfluxDB. В Grafana есть шаблонная переменная, при помощи которой можно выбрать, какой InfluxDB использовать на текущей панели инструментов.
В случае фатального сбоя двух узлов InfluxDB у нас всё равно остаётся работоспособным третий инстанс InfluxDB, и заказчик может видеть точки данных на панели инструментов Grafana после выбора работоспособного источника данных InfluxDB.
Что замечательно!
Теперь мы, кажется, удовлетворяем требование Управления по продукту о поддержании работоспособности при сценарии с фатальным сбоем двух узлов.
Recovery на старте
Вот только… что если после продолжительного простоя двух узлов и их оживления у нас произойдёт фатальный сбой на третьем узле?
В этом случае работоспособные инстансы InfluxDB не будут иметь доступа к данным за период, пока они были неработоспособны, так что заказчики не смогут видеть некоторые диапазоны данных, пока не восстановится третий инстанс.
Может быть даже хуже: например, если третий инстанс сгорит и придётся заменить отказавший узел, что приведёт к потере данных мониторинга, которые сохранялись только на третьем инстансе.
Это, конечно, плохо.
Чтобы избежать такой проблемы, мы решили, что можем восстановить данные на InfluxDB при запуске инстанса.
Во избежание проблем с обратным заполнением мы постарались восстановить при запуске как можно больше данных перед запуском InfluxDB на порте, к которому есть доступ у Telegraf. Для этого мы запустили InfluxDB за два этапа. На первом этапе мы запустили его на другом порте (во избежание новых записей от Telegraf) и восстановили данные из других инстансов InfluxDB за период, во время которого InfluxDB был неработоспособен. На втором этапе мы запустили на обычном порте и восстановили небольшое количество точек данных, которые отсутствовали во время первого этапа. При необходимости мы инициировали восстановление недостающих периодов в фоне.
Такое решение позволило нам не нагружать InfluxDB большим количеством запросов на обратное заполнение и записывать столько же данных при восстановлении в дружественной по отношению к InfluxDB форме путём присоединения новых записей.
Для восстановления мы используем стандартный API копирования-восстановления InfluxDB. Для больших периодов мы разбиваем восстановление на части по одному дню, чтобы не вызвать нехватку памяти в случае, если узел был неработоспособен в течение нескольких недель, и пытаемся восстановить все недостающие данные за одну большую транзакцию.
Теперь всё хорошо, и мы готовы выдержать повторяющиеся отказы или простои. Мы даже сможем справиться с повторяющейся заменой узла, что полезно при обновлении техники, когда заказчик заменяет всё оборудование узлов новым по окончании срока службы старого оборудования.
Итак, в результате использования нескольких инстансов InfluxDB и API копирования-восстановления мы смогли создать высокодоступную структуру инстансов InfluxDB, способную работать при сценарии с фатальным сбоем двух узлов и заменой узлов или при сценарии обновления техники.
Горизонтально масштабируемый слой выполнения запросов
Сейчас я перейду к следующему шагу нашего путешествия и расскажу, как мы улучшили уровень вычисления запроса, выделяя его из InfluxDB и делая его горизонтально масштабируемым.
Как вы помните, когда мы добавили три инстанса InfluxDB, то были вынуждены добавить шаблонную переменную в инструментальные панели Grafana, чтобы заказчик мог выбрать хороший инстанс InfluxDB в качестве источника данных.
Но щёлкать по разным инстансам InfluxDB в попытках угадать, который из них в настоящий момент работоспособен и имеет полностью восстановленную базу данных за нужный вам период, — это не лучший опыт использования.
Мы начали думать над тем, как улучшить ситуацию, — и нашли решение.
Мы решили, что нам нужен отдельный вычислительный слой, который будет состоять из служб, выполняющихся на всех узлах и берущих необработанные данные из InfluxDB. И назвали эту службу в честь нового языка InfluxDB — Fluxd.
Данная архитектура позволила нам иметь инстанс службы Fluxd на локальном хосте в качестве единственного источника данных для Grafana. Более того, мы смогли спрятать источник данных InfluxDB от заказчика и всегда использовать Fluxd на локальном хосте в качестве источника данных.
Служба Fluxd должна быть достаточно умной, чтобы понимать, какой из инстансов InfluxDB лучше всего подходит для выполнения каждого конкретного запроса. Когда Fluxd получает запрос от Grafana или любой другой службы, он разбивает запрос и отправляет его необработанным в InfluxDB. Необработанный запрос обычно включает первые три строки: from() filter() range(). Некоторые функции — например, функция last() — также могут быть отправлены в InfluxDB для ускорения запроса, чтобы InfluxDB вернул только последнюю точку вместо полного диапазона.
Fluxd выбирает лучший инстанс InfluxDB, имеющий все восстановленные периоды для используемой в запросе базы данных. Если в запросе указан период, который присутствует во всех инстансах InfluxDB лишь частично (например, после простоя возникли некоторые проблемы при немедленном выполнении восстановления и оно будет выполнено позднее), то Fluxd отвечает за отправку запроса на все инстансы InfluxDB и объединение результатов (дедупликацию результатов во время объединения).
После того как Fluxd получает необработанные данные из InfluxDB, он выполняет оставшиеся вычисления Flux для запроса. Это дополнительно освобождает вычислительные ресурсы от инстансов InfluxDB (они не масштабируются по горизонтали, а потому любое уменьшение потребления ресурсов InfluxDB важно для нас).
Это важно, поскольку у нас был локальный инстанс Fluxd в качестве источника данных для Grafana, а также другие службы, выполняющиеся на узле, которые требовали несколько мониторинговых запросов, что приводило к проблемам с перегрузкой одного из инстансов Fluxd.
Дополнительная балансировка нагрузки между инстансами сервиса Fluxd позволила нам получить минимальное потребление ресурсов на каждом отдельном инстансе Fluxd при сохранении высокой скорости обработки запросов. Это идеально совпало с нашими требованиями к распределённой архитектуре нашего фреймворка мониторинга с горизонтальной масштабируемостью.
Другое серьёзное преимущество при использовании отдельного вычислительного слоя состоит в том, что службы Fluxd не имеют состояния (Stateless). Потеря любого узла с инстансом Fluxd всего-навсего удаляет одного из работников из пула, не оказывая при этом особого влияния на кластер.
Введя вычислительный слой для запросов, мы:
- улучшили опыт пользователя за счёт использования в Grafana всего одного источника данных;
- уменьшили количество необходимых для InfluxDB ресурсов, выделив запросы в отдельный вычислительный слой;
- сделали так, чтобы все узлы получали одинаковую нагрузку запросов Flux, обеспечив более низкие ограничения по ресурсам для всех инстансов Fluxd;
- создали устойчивый, горизонтально масштабируемый, не запоминающий состояние вычислительный слой, служащий для удовлетворения запросов Flux.
Развёртывание с низкими лимитами по памяти
Теперь я подробно расскажу, как мы добились того, чтобы InfluxDB и другие компоненты его стека подстроились под наши требования к низкому потреблению ресурсов.
Во избежание ошибок нехватки памяти и отказов контейнера Docker наш стек мониторинга должен потреблять предсказуемое количество ресурсов с лимитом в 3 Гб на узле. Главными компонентами нашего стека мониторинга являются Telegraf, InfluxDB, Fluxd и Grafana. Самым ценным ресурсом на наших кластерах является память.
Мы уже видели, как нам удалось освободить InfluxDB от необходимости делать расчёты и снизить его потребность в памяти. Давайте посмотрим, какие ещё шаги нам пришлось сделать, чтобы достичь предсказуемо низкого потребления ресурсов.
Telegraf
Начнём с Telegraf.
Все выполняющиеся на узле службы отправляют свои метрики на локальный инстанс Telegraf. И у нас есть определённые периоды, когда службы могут помещать метрики, так что они не делают это неконтролируемо.
Но произойти может всякое, и в ситуациях сбоя службы могут начать помещать больше метрик, чем ожидалось, создавая большую нагрузку на Telegraf. Это может привести к большему потреблению памяти: когда службы начинают помещать слишком много метрик, Telegraf достигает лимита памяти и его завершает OOM Killer внутри контейнера Docker.
Это не то, чего мы хотим при возникновении ошибки.
Если какая-либо служба выходит из-под контроля и начинает помещать больше метрик, чем ожидалось, нам лучше игнорировать метрики, а не завершать процесс из-за нехватки памяти. Тем самым мы радикально снизим функциональность нашего стека вместо того, чтобы сразу столкнуться с отказом от обслуживания.
Чтобы справиться с проблемой, нам нужно было задать определённый предел буфера памяти и размер пакета в конфигурации Telegraf.
Определив предел буфера, мы также приняли во внимание ситуацию, когда некоторые инстансы InfluxDB оказываются неработоспособны и соответствующие буферы будут всегда полны. Telegraf сохраняет отдельный буфер памяти при каждом выходе, поэтому если вам нужно обработать несколько неработоспособных выходов и быть уверенными, что Telegraf не завершит работу из-за нехватки памяти, вам нужно обеспечить дополнительное место для полного буфера при каждом выходе, который вы определяете в конфигурации Telegraf.
Теперь у Telegraf имелся предсказуемый объём памяти для получаемых метрик, и мы думали, что закончили оптимизацию Telegraf и уже никогда не увидим его перезапуск из-за нехватки памяти.
Но однажды на площадке заказчика возникла новая проблема. Да-да, Telegraf периодически перезапускался из-за нехватки памяти.
Мы были уверены, что это не из-за метрик, получаемых от служб на входе HTTP, поскольку у нас уже были определены подходящие лимиты для буферов памяти. И углубились в вопрос, чтобы понять первопричину.
Разумеется, в Telegraf мы использовали много разных входных плагинов для сбора разных системных метрик. У большинства этих плагинов имелся встроенный код на Go. При изучении проблем с памятью у Telegraf мы обнаружили, что лишняя память потреблялась не самим Telegraf, а другими двоичными программами, которые вызывались из выполняемых входных плагинов.
Мы вспомнили, что для некоторых метрик, которые отсутствовали в наших службах, мы написали несколько скриптов, которые вызывались из исполняемого входного плагина Telegraf для сбора этих метрик. Выяснилось, что в некоторых средах заказчика при некоторых условиях эти скрипты могут потреблять намного больше памяти, чем мы ожидали. Именно это вызывало проблемы нехватки памяти в контейнере Telegraf. Позже мы обнаружили, что такие проблемы вызывают не только клиентские скрипты, но и несколько хорошо известных двоичных программ, используемых для выполняемых входных плагинов: они также могут потреблять неожиданно много памяти.
Как решить подобную проблему?
Никогда не использовать выполняемые входные плагины. Особенно при исполнении Telegraf внутри контейнера Docker и заданных для него низких лимитах памяти. Всегда заставляйте группы поддержки добавлять нужную статистику в их отчёты вместо того, чтобы пытаться собрать их, используя клиентские скрипты внутри Telegraf.
В итоге мы убрали все выполняемые входные плагины из нашего Telegraf. И угадайте что?
Telegraf больше не падал из-за нехватки памяти. Нам наконец удалось добиться стабильной работы для нашего варианта использования. При этом полный контейнер Telegraf использовал лимит в 150 Мб памяти. Да, это было на 100 Мб больше, чем мы ожидали от Telegraf изначально, — но всё равно очень хорошо.
Итак, мы закончили оптимизировать Telegraf, и теперь настало время внимательно изучить InfluxDB.
InfluxDB
Существует несколько факторов, определяющих, сколько памяти будет потреблять InfluxDB:
- Количество метрик, помещаемых в InfluxDB.
- Cardinality метрик.
- Retention баз данных.
- Вычислительные ресурсы для сложных запросов.
Мы уже показали, как освободили InfluxDB от сложных расчётов. Теперь давайте посмотрим, что можно сделать с другими факторами.
Когда мы впервые настроили InfluxDB для получения всех доступных в кластере метрик, то были разочарованы тем, сколько памяти потребовалось InfluxDB, чтобы справиться со всеми этими метриками. Объём составлял около 30 Гб!
Фильтрование ненужных метрик
Мы знали, что для видимых заказчику панелей инструментов нам нужно около 5 % всех метрик. Ещё примерно 5 % требуется для дополнительных панелей инструментов для Службы поддержки.
Все прочие метрики были добавлены до нас, и ими, кажется, никто не интересовался. Поэтому мы решили, что можно отказаться от них и не помещать эти метрики во внутренний мониторинг. А всем группам перед добавлением новых метрик для внутреннего мониторинга нужно будет пройти нашу проверку, которая обеспечивает, чтобы никто не отправлял данные с высокой кардинальностью во внутренний мониторинг.
Уменьшение интервала посылки метрик
Мы также снизили интервал помещения метрик до минимального: на этом настаивали менеджеры по продукту. ECS UI показывал точки данных каждые 5 минут, так что мы уменьшили интервал помещения для всех метрик до 5 минут — как у Telegraf, так и у служб, генерирующих метрики.
Результат был поразительным! Потребление памяти InfluxDB упало до 2 Гб — и наша цель была достигнута.
Выбор размера шард
Когда мы в течение нескольких месяцев проводили ресурсные испытания на нашем кластере, то обнаружили, что InfluxDB постепенно начал потреблять намного больше памяти, чем мы ожидали. Конечно, мы знали, что сохранение большой истории будет стоить нам ресурсов, но InfluxDB требовал слишком многого.
Проведя исследование, мы обнаружили проблему с индексом InfluxDB.
Вы помните, что все базы данных в InfluxDB имеют политику хранения (Retention)? И что любая политика хранения включает Shard Duration (длительность шарда), которая определяет, сколько шардов будет в вашей базе данных? Например, если ваша политика предполагает срок хранения 2 месяца, а длительность шарда задана равной 1 дню, у вас будет 60 шардов.
Но каждый шард имеет собственный индекс. А индекс является самой требовательной к ресурсам частью InfluxDB. Если в вашей базе данных 60 шардов, у них будет 60 индексов. А 60 индексов потребуют намного больше ресурсов по сравнению со, скажем, 10 шардами при одинаковой политике хранения.
Поэтому запомните одно простое правило: старайтесь не использовать в своей политике хранения больше 10 шардов.
При небольшом времени хранения нормально использовать 1 шард. При длительном хранении учитывайте, что InfluxDB поддерживает работу политики хранения за счёт удаления шардов, если все содержащиеся в них точки данных старше указанного в политике времени хранения. Таким образом, если у вас задана длительность шарда, равная 10 дням, InfluxDB иногда будет хранить в базе данных точки ещё на 10 дней старше, чем задано политикой хранения, пока не сможет удалить самый старый шард.
Никогда не используйте длительность шарда, способную привести к увеличению количества шардов свыше 10. Иначе вы будете расплачиваться за это памятью.
Уменьшение потребления ресурсов при интеграции с внешним мониторингом
Мы закончили, наконец, оптимизировать Telegraf и InfluxDB, оставив Fluxd и Grafana ровно столько памяти, сколько нужно для их нормальной работы, и могли расслабиться, зная, что наш стек мониторинга никогда не пострадает из-за нехватки памяти на площадке заказчика.
Но ECS эксплуатируется заказчиками, и у нас было ещё несколько сценариев использования, потребовавших оптимизации памяти.
Вы всё ещё помните, что ECS эксплуатируется заказчиками в больших центрах обработки данных? И знаете что? Иногда заказчики используют внешний мониторинг и нуждаются во всех метриках от системы, чтобы научиться с ним работать.
Наше первое решение для такого сценария использования было простым: внешний мониторинг только периодически опрашивает Fluxd для получения нужных данных. Звучит хорошо, однако мы быстро нашли недостатки такого подхода.
Внешний мониторинг требует много метрик. Поэтому он выполняет много запросов, нагружает Fluxd и занимает больше памяти, чем мы хотели. Также мониторинг загружал больше инстансов InfluxDB, которым приходилось постоянно извлекать много необработанных данных.
Мы также знали, что внешний мониторинг имеет намного больше свободных ресурсов, чем у нас было на внутреннем мониторинге, и мы сможем создать существенно больше сложных панелей инструментов с гораздо большей детализацией. Во внутренний мониторинг мы не помещали все возможные метрики из служб, а только критически важные метрики, требуемые заказчиком или необходимые при поиске неисправностей.
Таким образом, если внешний мониторинг опрашивает метрики из Fluxd, у него будет доступ только к метрикам, заданным для внутреннего мониторинга. Но нам хотелось большего.
Мы нашли следующее решение: помещать все метрики из инстансов Telegraf не только во внутренний InfluxDB, но и в инстанс внешнего мониторинга. Мы не применяли никакой логики фильтрации для этих внешних исходящих данных, что позволило поместить все доступные метрики. Поскольку метрики помещались в момент создания, это почти не увеличило потребление ресурсов инстансами Telegraf — только размер одиночного буфера памяти, что немного.
Теперь заказчик получает все нужные данные из системы при внешнем мониторинге. Мы даже смогли предоставить больше подробностей насчёт работоспособности и больше деталей с разбивкой ёмкости по внешней системе мониторинга, используя дополнительные непрерывные запросы.
Такой подход позволил нам сохранить контроль над низким потреблением ресурсов компонентов мониторинга для сценария с интегрированием внешнего мониторинга в систему.
Результаты
В этом разделе я показал, какими способами мы смогли контролировать ресурсы памяти в стеке мониторинга InfluxDB, а именно:
- ограничивая буфер Telegraf;
- избегая использования выполняемых входных плагинов в Telegraf;
- освобождая InfluxDB от необходимости выполнять расчёты;
- отфильтровывая все ненужные метрики;
- отправляя метрики с максимально низкой частотой для удовлетворения наших требований;
- и наконец, помещая метрики во внешний мониторинг прямо из Telegraf.
Как полностью изменить стек мониторинга в продукте
Теперь кратко расскажу о шагах, которые потребовались, чтобы мы действительно смогли переключить наш стек мониторинга.
Вначале мы начали работать над изменением стека мониторинга. Для ECS уже имелся рабочий фреймворк мониторинга. Все службы помещали метрики во фреймворк статистики. UI использовал специальную службу панели инструментов, которая готовила данные из фреймворка статистики. Также у нас был предупреждающий фреймворк с уже определёнными различными правилами предупреждений, и некоторые из них использовали фреймворк статистики для предупреждений по метрикам. Но снова-таки все запросы были написаны в виде чистого кода на Java.
Когда мы начали вводить новый фреймворк мониторинга, мы знали, что не сможем полностью переключиться за один релиз. Поэтому мы решили следовать паттерну Strangler Application Pattern и создать новый фреймворк мониторинга, который будет работать параллельно со старым фреймворком. Ведь нам требовалось несколько релизов для переключения стека мониторинга, а мы не могли себе позволить ни на йоту ухудшить функционал, ведь мониторинг и предупреждения у нас уже работали.
Мы добавили в службы нашей низкоуровневой библиотеки простую логику, которая помещала метрики во фреймворк статистики, и теперь могли отправлять метрики в оба стека. Помимо фреймворка статистики такая логика отправляла все метрики в локальный инстанс Telegraf.
Решив вопрос с отправкой метрик в оба стека мониторинга, мы смогли, не нарушая работы, добавлять новые панели инструментов системного уровня в Grafana. Затем мы выпустили следующую версию ECS. Теперь служба поддержки имела намного лучшие панели инструментов и могла быстрее решать проблемы, изучая системные метрики, такие как CPU, память и размер файла подкачки для каждой службы. По требованию службы поддержки был развёрнут Grafana.
Для нашего следующего релиза мы смогли интегрировать ECS UI и предупреждающий фреймворк, чтобы получать несколько метрик из нового фреймворка мониторинга, который позволил добавить несколько панелей внутрь UI, и добавить новые предупреждения во фреймворк предупреждений при помощи запросов Flux. На этом же этапе мы встроили Grafana в виде iframe в ECS UI, чтобы избежать отдельной авторизации для него. Мы также добавили в Grafana несколько видимых заказчику панелей инструментов — и выпустили новую версию ECS.
После этого стало возможным перенести функционал, связанный с мониторингом, для использования запросов Flux и изъятия старого фреймворка статистики.
Следуя этой стратегии, мы смогли продолжить выпускать новые версии ECS, одновременно изменяя стек мониторинга под прикрытием, улучшая способности к мониторингу нашего продукта и делая группы поддержки более автономными, чтобы те могли добавлять новые предупреждения или создавать новые панели инструментов, используя только запросы Flux.
Dashboards
Давайте взглянем, какие панели инструментов у нас получились в результате изменений стека мониторинга.
Как я уже сказал, панелей было добавлено много, так что все я показать не смогу. Но несколько мы посмотрим.
Панели инструментов с метриками производительности
Мы смогли добавить различные эксплуатационные характеристики, включая разделение по типу метода и протоколу. А также создали детальную панель инструментов касательно задержки системы, показывающую не средние значения задержек, а процентили p50 и p99 (как вы понимаете, это оказывает огромное влияние на понимание реальных задержек системы).
Панели инструментов с системными метриками
Они показывают уровень узла, а также системную статистику по процессам, таким как память, CPU, файл подкачки. Эти панели инструментов очень помогли при изучении различных проблем на площадке заказчика. Они первые, на которые смотрит служба поддержки в поисках первопричины.
Панель инструментов Top N Buckets
Она показывает заказчику самые большие области памяти в системе по размеру и по количеству объектов.
Чтобы рассказать обо всех панелях инструментов, которые нам удалось создать, используя новый фреймворк мониторинга, потребовалась бы ещё одна такая статья. Их действительно много!
Выводы
Мы подошли к финалу истории, и настало время подвести итоги. Итак:
- Мы доказали себе, что InfluxDB — отличная база данных временных рядов.
- Он достаточно гибкий, чтобы добавлять возможности, обладающие высокой доступностью, даже в версию с открытым исходным кодом.
- Если работать с ним осмотрительно, его можно вписать в рамки ограничений на потребляемые ресурсы памяти.
- InfluxDB можно использовать в качестве надёжного решения по мониторингу для развёртывания у заказчика.
Желаю вам удачи в использовании InfluxDB в вашем продукте!



