
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
1. Введение
SEDA, или Staged Event-Driven Architecture, представляет собой архитектурный стиль, предложенный Мэттом Уэлшем в его докторской диссертации. диссертация. Его основными преимуществами являются масштабируемость, поддержка высококонкурентного трафика и удобство эксплуатации.
В этом туториале мы будем использовать SEDA для подсчета уникальных слов в предложении с помощью двух разных реализаций: Spring Integration и Apache Camel.
2. Обзор SEDA
SEDA удовлетворяет несколько нефункциональных требований, характерных для онлайн-сервисов:
Высокий параллелизм. Архитектура должна поддерживать максимально возможное количество одновременных запросов.
Динамический контент. Программные системы часто должны поддерживать сложные сценарии использования в бизнесе, требующие множества шагов для обработки запросов пользователей и генерации ответов.
Устойчивость к нагрузкам. Пользовательский трафик для онлайн-сервисов может быть непредсказуемым, и архитектура должна легко справляться с изменениями объема трафика.
Для удовлетворения этих требований SEDA декомпозирует сложные сервисы на управляемые событиями этапы. Эти этапы косвенно связаны с очередями и поэтому могут быть полностью отделены друг от друга. Кроме того, каждый этап имеет механизм масштабирования, чтобы справиться с входящей нагрузкой:

На приведенной выше диаграмме из статьи Мэтта Уэлша показана общая структура веб-сервера, реализованного с помощью SEDA. Каждый прямоугольник представляет собой один этап обработки входящего HTTP-запроса. Этапы могут независимо потреблять задания из своих входящих очередей, выполнять некоторую обработку или ввод/вывод, а затем передавать сообщение в следующую очередь.
2.1. Компоненты
Чтобы лучше понять компоненты SEDA, давайте посмотрим, как эта диаграмма из диссертации Мэтта Уэлша показывает внутреннюю работу одного этапа:
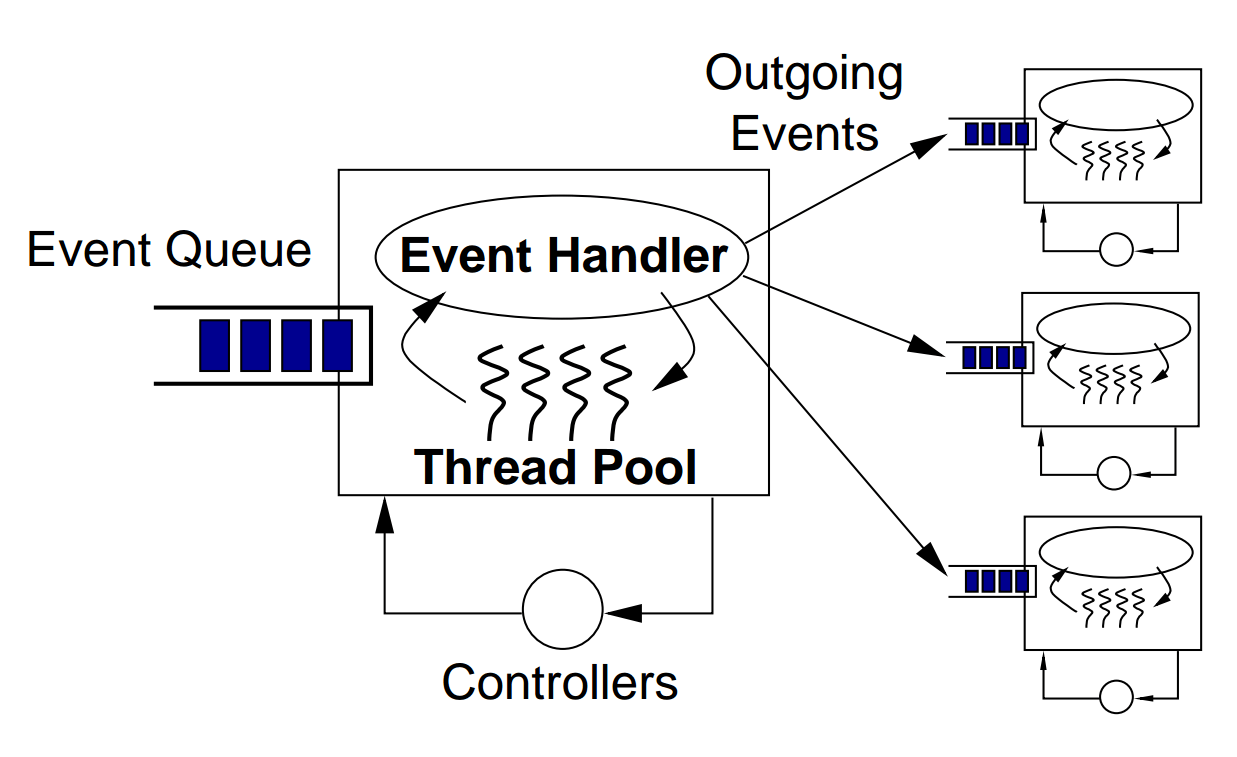
Как мы видим, каждый этап SEDA состоит из следующих компонентов:
Событие: события — это структуры данных, содержащие любые данные, необходимые этапу для выполнения его обработки. Например, для веб-сервера HTTP события могут содержать данные пользователя, такие как тело, заголовок и параметры запроса, а также данные инфраструктуры, такие как IP-адрес пользователя, временная метка запроса и т. д.
Очередь событий: здесь хранятся входящие события этапа.
Обработчик событий: обработчик событий содержит процедурную логику этапа. Это может быть простой этап маршрутизации, пересылающий данные из своей очереди событий в другие соответствующие очереди событий, или более сложный этап, на котором данные обрабатываются каким-либо образом. Обработчик событий может считывать события по отдельности или пакетно — последний вариант полезен, когда пакетная обработка дает преимущество в производительности, например обновление нескольких записей базы данных одним запросом.
Исходящие события: в зависимости от сценария использования и общей структуры потока каждый этап может отправлять новые события в ноль или более очередей событий. Создание и отправка исходящих сообщений осуществляется в методе обработчика событий.
Пул потоков: многопоточность — это хорошо известный механизм параллелизма. В SEDA потоки локализованы и настроены для каждого этапа. Другими словами, каждый этап поддерживает свой пул потоков. Таким образом, в отличие от модели «один поток на запрос», в SEDA каждый запрос пользователя обрабатывается несколькими потоками. Эта модель позволяет нам настраивать каждый этап независимо в зависимости от его сложности.
Контроллеры: контроллер SEDA — это любой механизм, который управляет потреблением ресурсов, таких как размер пула потоков, размер очереди событий, планирование и т. д. Контроллеры отвечают за эластичное поведение SEDA. Простой контроллер может управлять количеством активных потоков в каждом пуле потоков. Более сложный контроллер может реализовать сложные алгоритмы настройки производительности, которые отслеживают все приложение во время выполнения и настраивают различные параметры. Более того, контроллеры отделяют логику настройки производительности от бизнес-логики. Такое разделение задач облегчает сопровождение нашего кода.
Собрав все эти компоненты вместе, SEDA обеспечивает надежное решение для работы с высокими и неустойчивыми нагрузками трафика.
3. Пример задачи
В следующих разделах мы создадим две реализации, решающие одну и ту же проблему с помощью SEDA.
Задача нашего примера будет простой: подсчитать, сколько раз каждое слово встречается в заданной строке без учета регистра.
Давайте определим слово как последовательность символов без пробелов и проигнорируем другие сложности, такие как пунктуация. На выходе мы получим карту, содержащую слова в качестве ключей и счетчики в качестве значений. Например, при вводе «My name is Hesam» вывод будет таким:
{
"my": 1,
"name": 1,
"is": 1,
"hesam": 1
}3.1. Адаптация задачи к SEDA
Давайте посмотрим на нашу задачу с точки зрения этапов SEDA. Поскольку масштабируемость является основной целью SEDA, обычно лучше проектировать небольшие этапы, ориентированные на конкретные операции, особенно если у нас есть задачи с интенсивным вводом-выводом. Кроме того, наличие небольших этапов помогает нам лучше настроить масштаб каждого этапа.
Чтобы решить нашу задачу подсчета слов, мы можем реализовать решение со следующими этапами:

Теперь, когда у нас есть схема этапов, давайте реализуем ее в следующих разделах, используя две разные технологии корпоративной интеграции. В приведенной таблице показано, как SEDA будет отображаться в наших реализациях:
Компонент SEDA | Spring Integration | Apache Camel |
|---|---|---|
Event | org.springframework.messaging.Message | org.apache.camel.Exchange |
Event Queue | org.springframework.integration.channel | Конечные точки, определяемые строками URI |
Event Handler | Экземпляры функциональных интерфейсов | Процессоры, классы утилит и функции Camel |
Thread Pool | Spring абстракция TaskExecutor | Встроенная поддержка в конечных точках SEDA |
4. Решение с использованием Spring Integration
Для нашей первой реализации мы будем использовать Spring Integration. Spring Integration основывается на модели Spring для поддержки популярных шаблонов корпоративной интеграции.
Spring Integration состоит из трех основных компонентов:
Сообщение представляет собой структуру данных, состоящую из заголовка и тела.
Канал передает сообщения от одной конечной точки к другой конечной точке. В Spring Integration существует два вида каналов:
точка-точка: только одна конечная точка может потреблять сообщения в этом канале.
публикация-подписка: несколько конечных точек могут потреблять сообщения в этом канале.
Конечная точка направляет сообщение компоненту приложения, выполняющему определенную бизнес-логику. В Spring Integration существует множество конечных точек, таких как трансформеры, маршрутизаторы, активаторы сервисов и фильтры.
Давайте рассмотрим общий вид нашего решения Spring Integration:

4.1. Зависимости
Давайте начнем с добавления зависимостей для Spring Integration, Spring Boot Test и Spring Integration Test:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-integration</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.integration</groupId>
<artifactId>spring-integration-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>4.2. Шлюз обмена сообщениями
Шлюз обмена сообщениями — это прокси, который скрывает сложность отправки сообщения в потоки интеграции. Давайте настроим его для нашего потока Spring Integration:
@MessagingGateway
public interface IncomingGateway {
@Gateway(requestChannel = "receiveTextChannel", replyChannel = "returnResponseChannel")
public Map<String, Long> countWords(String input);
}Позже мы сможем использовать этот метод шлюза для тестирования всего нашего потока:
incomingGateway.countWords("My name is Hesam");Spring оборачивает входные данные «My name is Hesam» в экземпляр org.springframework.messaging.Message и передает их в receiveTextChannel, а затем выдает нам конечный результат в returnResponseChannel.
4.3. Каналы сообщений
В этом разделе мы рассмотрим, как настроить канал исходящих сообщений нашего шлюза receiveTextChannel.
В SEDA каналы должны быть масштабируемыми с помощью связанного пула потоков, поэтому начнем с создания пула потоков:
@Bean("receiveTextChannelThreadPool")
TaskExecutor receiveTextChannelThreadPool() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(1);
executor.setMaxPoolSize(5);
executor.setThreadNamePrefix("receive-text-channel-thread-pool");
executor.initialize();
return executor;
}Далее мы используем наш пул потоков для создания канала:
@Bean(name = "receiveTextChannel")
MessageChannel getReceiveTextChannel() {
return MessageChannels.executor("receive-text", receiveTextChannelThreadPool)
.get();
}MessageChannels — это класс Spring Integration, который помогает нам создавать каналы различных типов. Здесь мы используем метод executor() для создания ExecutorChannel, который представляет собой канал, управляемым пулом потоков.
Другие наши каналы и пулы потоков настраиваются так же, как описано выше.
4.4. Этап получения текста
Когда наши каналы настроены, мы можем приступить к реализации наших этапов. Давайте создадим наш начальный этап:
@Bean
IntegrationFlow receiveText() {
return IntegrationFlows.from(receiveTextChannel)
.channel(splitWordsChannel)
.get();
}IntegrationFlows — это свободный API интеграции Spring для создания объектов IntegrationFlow, представляющих этапы нашего потока. Метод from() настраивает входящий канал нашего этапа, а channel() настраивает исходящий канал.
В этом примере наш этап передает входное сообщение нашего шлюза в splitWordsChannel.
В производственном приложении этот этап может быть более сложным и требовать интенсивного ввода-вывода для считывания сообщений из постоянной очереди или по сети.
4.5. Этап разделения слов
Наш следующий этап имеет единственную задачу: разделить нашу входную строку на массив строк отдельных слов в предложении:
@Bean
IntegrationFlow splitWords() {
return IntegrationFlows.from(splitWordsChannel)
.transform(splitWordsFunction)
.channel(toLowerCaseChannel)
.get();
}В дополнение к вызовам from() и channel(), которые мы использовали ранее, здесь мы также используем transform(), который применяет предоставленную функцию к нашему входному сообщению. Наша реализация splitWordsFunction очень проста:
final Function<String, String[]> splitWordsFunction = sentence -> sentence.split(" ");4.6. Этап преобразования в нижний регистр
На этом этапе каждое слово в нашем String массиве преобразуется в нижний регистр:
@Bean
IntegrationFlow toLowerCase() {
return IntegrationFlows.from(toLowerCaseChannel)
.split()
.transform(toLowerCase)
.aggregate(aggregatorSpec -> aggregatorSpec.releaseStrategy(listSizeReached)
.outputProcessor(buildMessageWithListPayload))
.channel(countWordsChannel)
.get();
}Первый новый метод IntegrationFlows, который мы здесь используем, это split(). Метод split() использует паттерн splitter для отправки каждого элемента нашего входного сообщения в toLowerCase в виде отдельных сообщений.
Следующий новый метод, который мы используем, это aggregate(), который реализует шаблон агрегатора. Шаблон агрегатора имеет два аргумента:
стратегия публикации, которая определяет, когда объединять сообщения в одно
процессор, который определяет, как объединить сообщения в одно
Наша функция стратегии публикации использует функцию listSizeReached, которая указывает агрегатору начать агрегацию, когда все элементы входного массива будут собраны:
final ReleaseStrategy listSizeReached = r -> r.size() == r.getSequenceSize();Затем процессор buildMessageWithListPayload упаковывает наши результаты в нижнем регистре в список:
final MessageGroupProcessor buildMessageWithListPayload = messageGroup ->
MessageBuilder.withPayload(messageGroup.streamMessages()
.map(Message::getPayload)
.toList())
.build();4.7. Этап подсчета слов
На последнем этапе количество слов упаковывается в Map, где ключами являются слова из исходного текста, а значениями — количество вхождений каждого слова:
@Bean
IntegrationFlow countWords() {
return IntegrationFlows.from(countWordsChannel)
.transform(convertArrayListToCountMap)
.channel(returnResponseChannel)
.get();
}Здесь мы используем нашу функцию convertArrayListToCountMap для упаковки наших счетчиков в виде карты:
final Function<List<String>, Map<String, Long>> convertArrayListToCountMap = list -> list.stream()
.collect(Collectors.groupingBy(Function.identity(), Collectors.counting()));4.8. Тестирование нашего потока
Мы можем передать начальное сообщение в метод шлюза, чтобы протестировать наш поток:
public class SpringIntegrationSedaIntegrationTest {
@Autowired
TestGateway testGateway;
@Test
void givenTextWithCapitalAndSmallCaseAndWithoutDuplicateWords_whenCallingCountWordOnGateway_thenWordCountReturnedAsMap() {
Map<String, Long> actual = testGateway.countWords("My name is Hesam");
Map<String, Long> expected = new HashMap<>();
expected.put("my", 1L);
expected.put("name", 1L);
expected.put("is", 1L);
expected.put("hesam", 1L);
assertEquals(expected, actual);
}
}5. Решение с помощью Apache Camel
Apache Camel — это популярный и мощный фреймворк интеграции с открытым исходным кодом. Он основан на четырех основных концепциях:
Контекст Camel: среда выполнения Camel объединяет разные части.
Маршруты: маршрут определяет, как должно быть обработано сообщение и куда оно должно быть направлено дальше.
Процессоры: это готовые к использованию реализации различных шаблонов корпоративной интеграции.
Компоненты: Компоненты — это точки расширения для интеграции внешних систем через JMS, HTTP, файловый ввод-вывод и т. д.
В Apache Camel есть компонент, предназначенный для функциональности SEDA, что упрощает создание приложений SEDA.
5.1. Зависимости
Давайте добавим необходимые зависимости Maven для Apache Camel и Apache Camel Test:
<dependencies>
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-core</artifactId>
<version>3.18.0</version>
</dependency>
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-test-junit5</artifactId>
<version>3.18.0</version>
<scope>test</scope>
</dependency>
</dependencies>5.2. Определение конечных точек SEDA
Сначала нам нужно определить конечные точки. Конечная точка — это компонент, определенный с помощью строки URI. Конечные точки SEDA должны начинаться с «seda:[endpointName]»:
static final String receiveTextUri = "seda:receiveText?concurrentConsumers=5";
static final String splitWordsUri = "seda:splitWords?concurrentConsumers=5";
static final String toLowerCaseUri = "seda:toLowerCase?concurrentConsumers=5";
static final String countWordsUri = "seda:countWords?concurrentConsumers=5";
static final String returnResponse = "mock:result";Как мы видим, каждая конечная точка настроена на пять одновременных потребителей. Это эквивалентно наличию максимум 5 потоков для каждой конечной точки.
В целях тестирования returnResponse является имитацией конечной точки.
5.3. Расширение RouteBuilder
Далее давайте определим класс, который расширяет класс RouteBuilder Apache Camel и переопределяет его метод configure(). Этот класс подключает все конечные точки SEDA:
public class WordCountRoute extends RouteBuilder {
@Override
public void configure() throws Exception {
}
}В следующих разделах мы определим наши этапы, добавляя строки в метод configure(), используя подходящие методы, унаследованные от RouteBuilder.
5.4. Этап получения текста
Этот этап получает сообщения от конечной точки SEDA и направляет их на следующий этап без какой-либо обработки:
from(receiveTextUri).to(splitWordsUri);Здесь мы использовали унаследованный метод from() для задания входящей конечной точки и to() для задания исходящей конечной точки.
5.5. Этап разделения слов
Давайте реализуем этап разбиения входного текста на отдельные слова:
from(splitWordsUri)
.transform(ExpressionBuilder.bodyExpression(s -> s.toString().split(" ")))
.to(toLowerCaseUri);Метод transform() применяет нашу функцию к входному сообщению, разбивая его на массив.
5.6. Преобразование в нижний регистр
Наша следующая задача — преобразовать каждое слово во входном сообщении в нижний регистр. Поскольку нам нужно применить нашу функцию преобразования к каждой строке в сообщении, а не к самому массиву, мы будем использовать метод split() как для разделения входного сообщения для обработки, так и для последующего объединения результатов обратно в ArrayList:
from(toLowerCaseUri)
.split(body(), new ArrayListAggregationStrategy())
.transform(ExpressionBuilder.bodyExpression(body -> body.toString().toLowerCase()))
.end()
.to(countWordsUri);Метод end() отмечает окончание процесса разделения. После преобразования каждого элемента в списке Apache Camel применяет заданную нами стратегию агрегирования ArrayListAggregationStrategy.
ArrayListAggregationStrategy расширяет метод AbstractListAggregationStrategy Apache Camel, чтобы определить, какая часть сообщения должна быть агрегирована. В данном случае тело сообщения представляет собой новое слово в нижнем регистре:
class ArrayListAggregationStrategy extends AbstractListAggregationStrategy<String> {
@Override
public String getValue(Exchange exchange) {
return exchange.getIn()
.getBody(String.class);
}
}5.7. Этап подсчета слов
На последнем этапе используется трансформер для преобразования массива в карту слов и их количества:
from(countWordsUri)
.transform(ExpressionBuilder.bodyExpression(List.class, body -> body.stream()
.collect(Collectors.groupingBy(Function.identity(), Collectors.counting()))))
.to(returnResponse);5.8. Тестирование нашего маршрута
Давайте протестируем наш маршрут:
public class ApacheCamelSedaIntegrationTest extends CamelTestSupport {
@Test
public void givenTextWithCapitalAndSmallCaseAndWithoutDuplicateWords_whenSendingTextToInputUri_thenWordCountReturnedAsMap()
throws InterruptedException {
Map<String, Long> expected = new HashMap<>();
expected.put("my", 1L);
expected.put("name", 1L);
expected.put("is", 1L);
expected.put("hesam", 1L);
getMockEndpoint(WordCountRoute.returnResponse).expectedBodiesReceived(expected);
template.sendBody(WordCountRoute.receiveTextUri, "My name is Hesam");
assertMockEndpointsSatisfied();
}
@Override
protected RoutesBuilder createRouteBuilder() throws Exception {
RoutesBuilder wordCountRoute = new WordCountRoute();
return wordCountRoute;
}
}Суперкласс CamelTestSupport предоставляет множество полей и методов, которые помогут протестировать наш поток. Мы используем getMockEndpoint() и expectBodiesReceived( ) для установки ожидаемого результата, а также template.sendBody() для отправки тестовых данных в нашу фиктивную конечную точку. Наконец, мы используем assertMockEndpointsSatisfied() для проверки соответствия наших ожиданий реальным результатам.
6. Заключение
В этой статье мы узнали о SEDA, его компонентах и сценариях использования. Затем мы рассмотрели, как использовать SEDA для решения той же задачи, используя сначала Spring Integration, а затем Apache Camel.
Как всегда, исходный код примеров доступен на GitHub.




