

Сегодня почти любая современная компания собирает, хранит и использует данные о своей деятельности, используя облачные технологии. В этой статье вы можете узнать о том, как можно вытащить данные из AmoCRM, обработать их с помощью функций и проанализировать с помощью DataLens. Этот кейс решила команда дата-аналитиков Valiotti Analytics совместно с командой Yandex.Cloud.
Введение
Многие современные цифровые стартапы и проекты часто используют CRM-системы для учета потока сделок и контроля деятельности отдела продаж. Мы расскажем про кейс школы английского языка JustSchool. Компания управляет лидами в AmoCRM, так как это удобный и простой инструмент, доступный любому менеджеру продаж. Но в самом AmoCRM недостаточно богатая функциональность аналитики. Поэтому возникает задача взять весь объем данных из CRM-системы, выгрузить его в стороннее хранилище и проанализировать. Используя API AmoCRM и возможности сервиса Yandex.Cloud, нам удалось построить рабочую аналитику с использованием serverless-функций, Managed Service for ClickHouse и инструмента для визуализации Yandex DataLens.
Поскольку в самой системе хранения данных обработка и анализ информации крайне неудобны, перед нами стояла задача создать алгоритм для автоматической выгрузки информации о сделках и контактах в нужном формате для последующего анализа. Это получилось сделать благодаря хорошей функциональности API, которая есть в AmoCRM. Основная сложность заключалась в поиске и настройке процесса выгрузки и обработки большого объема данных. Об этом мы расскажем детально.
Проектирование кластера и базы данных
Шаг 1. Создайте кластер, в котором будет храниться и обрабатываться вся информация из AmoCRM

Шаг 2. Создайте базу данных ClickHouse. Мы сделали это с использованием Managed Service for ClickHouse, а также создали несколько таблиц, необходимых для хранения данных из AmoCRM.
Шаг 3. Создайте сервисный аккаунт AmoCRM, чтобы гибко управлять ресурсами Yandex.Cloud, назначая необходимые роли.
Шаг 4. Реализуйте выгрузку данных с использованием сервисов Cloud Function и Message Queue. Данные из AmoCRM делятся на:
пользователей;
контакты и email;
заявки.
Каждая подгруппа обрабатывается отдельно.
Описание архитектуры решения
Для построения архитектуры мы использовали API AmoCRM, сервисы Yandex.Cloud и Yandex Datalens. Пример взаимодействия сервисов представлен на рисунке. Мы построили полностью serverless архитектуру для сбора, преобразования и загрузки данных.

Создание функций
Мы создали 7 функций для сбора и обработки данных. Поскольку в системе хранятся различные данные (о пользователях, контактах и т. д.), необходимо было выгрузить данные отдельно, с использованием разных логик и функций.

Также мы использовали специальные триггеры для автоматического запуска каждой функции.

Скрипты для сбора информации
Чтобы выгрузить данные из AmoCRM, мы использовали API. С его помощью после отправки запроса мы получаем данные в формате json. Затем, из этого формата мы преобразуем данные в DataFrame и сохраняем их в базу. Например, для сбора информации о пользователях мы создали функцию amousers.
with requests.Session() as s:
auth_url="https://{}.amocrm.ru/private/api/auth.php".format(subdomain)
get_url='https://{}.amocrm.ru/api/v2/account?with=users&free_users=Y'.format(subdomain)
auth_data = {'USER_LOGIN': user_login, 'USER_HASH': user_hash}
s.post(auth_url, data=auth_data)
response = s.get(get_url)
users_dict = json.loads(response.text)['_embedded']['users']
df = DataFrame.from_dict(users_dict).transpose()
# Обработка полученных данных
client.execute("INSERT INTO justkids.amocrm_users VALUES", df.to_dict('records'))Схема потоков данных
На этой диаграмме показана логика пересылки данных, которую мы использовали.

Для организации хранения промежуточных данных мы создали очереди в сервисе Message Queue.

Алгоритм пересылки данных на примере обработки заявок
1. Создайте специальный таймер, который каждый день запускает функцию firstpage в 23:15.

2. Функция firstpage кладет в очередь amo_leads_pages цифру 1— индекс первой страницы из исходной базы данных сделок. Это означает, что сбор данных начат, и 1 — это индекс страницы, с которой нужно начать выгружать данные из AmoCRM. Помните, в AmoCRM все данные разбиты на страницы по максимум 250 заявок.
client = boto3.client(
service_name='sqs',
endpoint_url='https://message-queue.api.cloud.yandex.net',
region_name='ru-central1'
)
queue_pages_url='https://message-queue.api.cloud.yandex.net/путь_до_очереди'
client.send_message(
QueueUrl=queue_pages_url,
MessageBody='1'
)Как только в очереди amo_leads_pages появляется цифра, триггер amo-leads-pages запускает экземпляр функции amoleadsqueue.


3. Функция amoleadsqueue берет из очереди число и начинает выгружать данные из AmoCRM, начиная с номера страницы, который был записан в очередь. Функция читает по 250 заявок и записывает полученный json в очередь amo_leads, из которой другая функция получает и обрабатывает данные.
4. В Cloud Functions есть ограничение по времени выполнения. Как только проходит 9 минут, функция заканчивает свою работу и кладет в очередь страницу, на которой остановилась. При попадании в очередь нового числа, триггер запускает новый экземпляр функции, который продолжает работу с последней обработанной страницы.
while True:
try:
with requests.Session() as s:
auth_url = "https://{}.amocrm.ru/private/api/auth.php".format(subdomain)
get_url=f'https://{subdomain}.amocrm.ru/api/v4/contacts?with=catalog_elements,leads,customers&page={page}&limit=100'
auth_data = {'USER_LOGIN': user_login, 'USER_HASH': user_hash}
s.post(auth_url, data=auth_data)
response = s.get(get_url)
# Если данные закончились, заносим в очередь флаг END
if response.status_code == 204:
print(page, 'No Content code 204')
client.send_message(
QueueUrl=queue_pages_url,
MessageBody='end'
)
break
contacts_list = json.loads(response.text)['_embedded']['contacts']
client.send_message(
QueueUrl=queue_url,
MessageBody=json.dumps(contacts_list)
)
page += 1
# В Yandex.Cloud есть ограничение по времени выполнения функции, поэтому останавливаем сбор данных через 9 минут
if time.time()-start_time > 500:
break
except Exception as e:
return {
'statusCode': 100,
'body': e
}
# Кладем в очередь номер, страницы на которой остановились
сlient.send_message(
QueueUrl=queue_pages_url,
MessageBody=str(page)
) 5. Функция amoleadsqueue только собирает данные и отправляет их в очередь amo_leads. При попадании значений в очередь, триггер amo-leads-to-db запускает функцию amo_leads, которая занимается обработкой полученных json данных и записывает их в ClickHouse.

Работа функции amoleads показана на скриншоте.

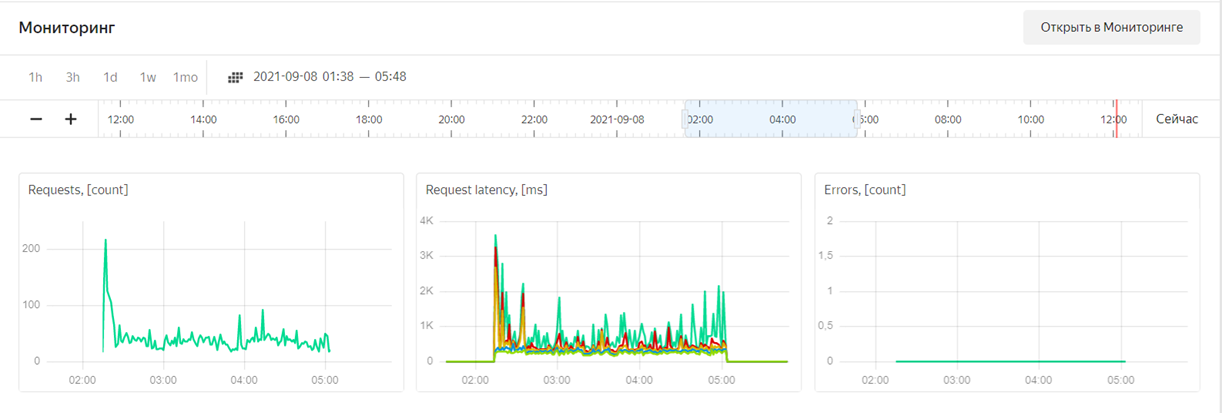
6. С помощью мониторинга можно наблюдать за процессом выполнения функции, отслеживать, сколько времени она выполнялась, и смотреть на время появления ошибок. Это отличный инструмент для отслеживания работы кода и оперативного решения проблем.
Создание дашборда в DataLens
Мы создали два датасета для сбора финального дашборда по воронке детской школы. В первом датасете, который создан на основе таблицы justkids.amocrm_leads_static, мы создали необходимые поля для расчетов и преобразовали числа в timestamps.
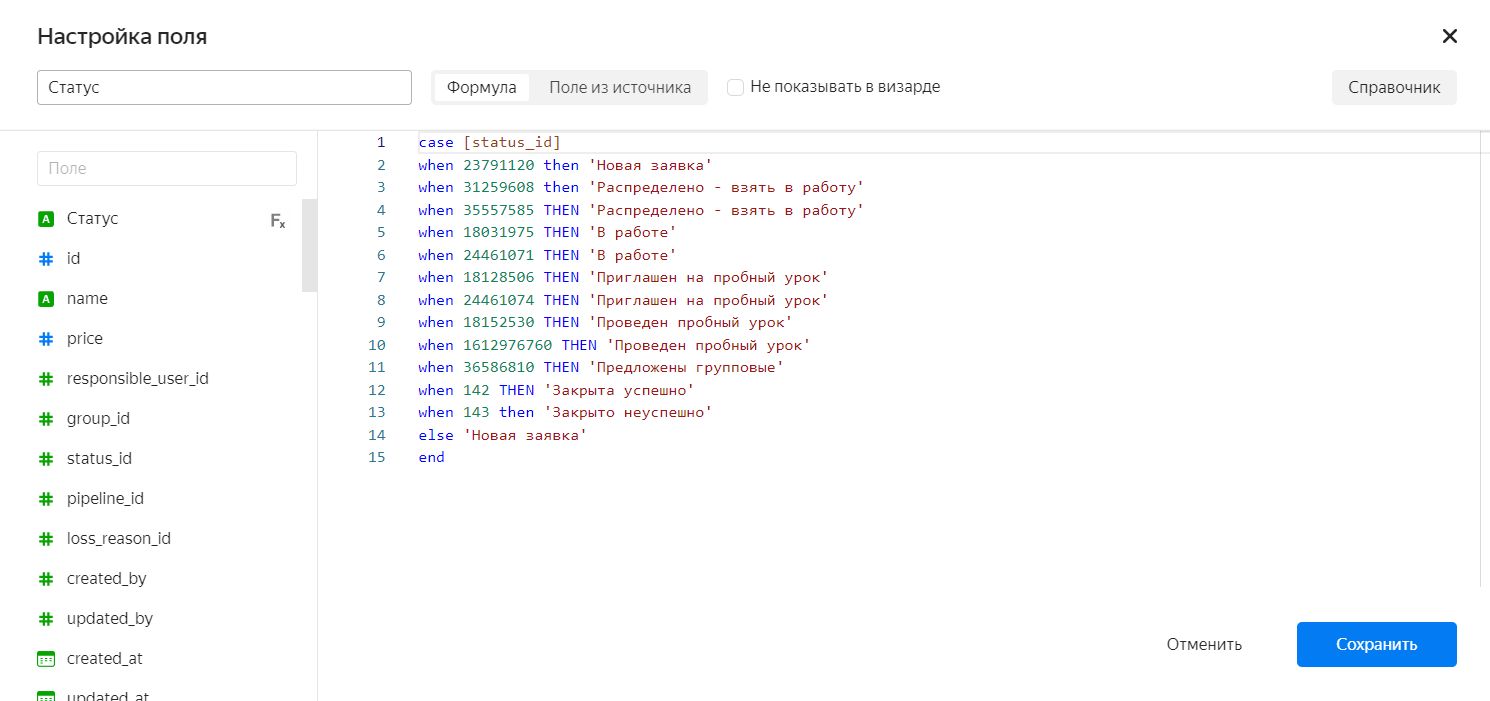

Второй датасет мы создали на основе SQL-запроса. Это помогло нам посчитать конверсию этапов воронки.
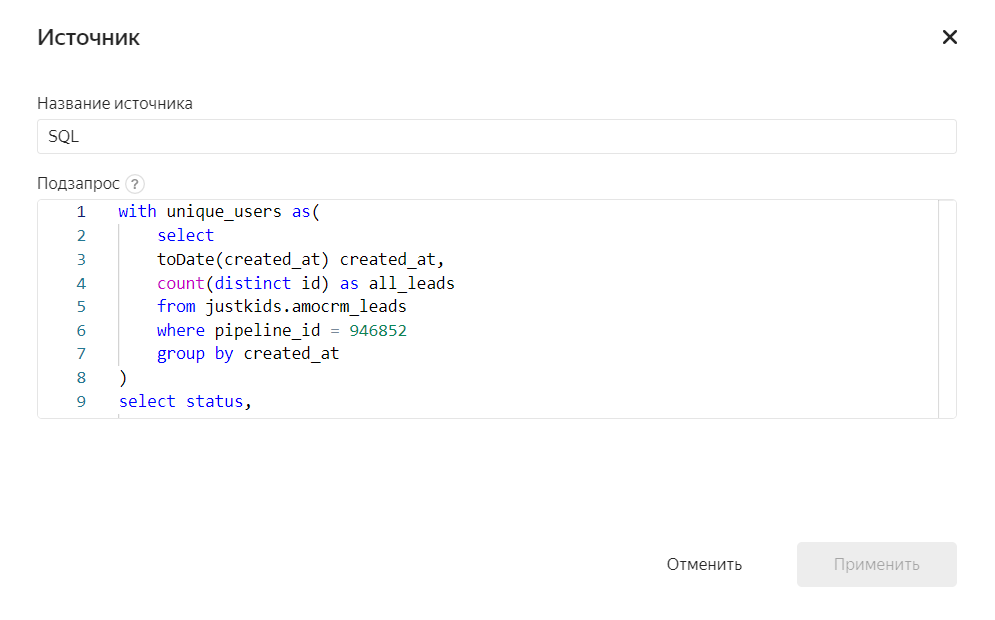
На основе этих датасетов мы создали Чарты, собрали Дашборд и добавили фильтр по дате создания заявки.


Чтобы фильтровать датасеты с помощью одного фильтра, мы создали специальную связь между ними.

Преимущества сервиса
Serverless архитектура, которая используется на Yandex.Cloud, упрощает работу с данными и ускоряет процессы разработки и мониторинга функций. Использование такой архитектуры позволяет сфокусироваться на решении кейса, так как Yandex.Cloud берет на себя все возможные проблемы, связанные с работой сервера.
Кластер Clickhouse элементарно настроить с помощью сервиса по управлению БД: установка делается в несколько кликов. Дальше вы работаете с базой, а сервис обеспечивает отказоустойчивость, резервное копирование, мониторинг, обновление и решает другие задачи. Вертикальное и горизонтальное масштабирование доступно "по кнопке" в консоли управления.
На платформе данных Yandex.Cloud представлены инструменты для аналитики и визуализации данных - Yandex DataLens, взаимодействие между которыми осуществляется очень быстро внутри одной системы.
Проблемы и ограничения
В сервисе Cloud Functions выставлено ограничение по времени выполнения одного экземпляра функции. Нам необходимо обработать более 4 тысяч страниц с данными, а функция успевает обработать лишь 100-200 страниц за 500 секунд отведенного времени. Для решения этой проблемы сотрудники Yandex.Cloud рекомендуют использовать сервис Message Queue, что работает отлично.
Размер сообщения, которое попадает в очередь, ограничен, так как на одной странице AmoCRM находится около 150-250 заявок. При попадании данных в очередь функция сразу загружает имеющиеся данные, обрабатывает и записывает их в базу данных. ClickHouse показывает отличную производительность на записи большого объема данных. Записывать данные маленькими кусочками (150-250 заявок, которые мы получаем из очереди), мы не рекомендуем. К сожалению, эту проблему пока не удалось решить, и функция продолжает записывать данные в таблицу только маленькими порциями.

Компания Valiotti Analytics предлагает широкий диапазон услуг, связанных с анализом данных: от проектирования архитектуры хранилищ данных, построения процессов дата инжиниринга до автоматизации отчетов и построения дашбордов. Главное в нашем деле — сделать так, чтобы данные работали на пользу компании, поэтому мы очень тщательно работаем с новейшими технологиями.
Читайте наш блог о кейсах и методах анализа данных LeftJoin, канал в Telegram и подписывайтесь на наш профиль в Instagram.



