

Сегодня я расскажу о новой библиотеке, которая позволяет использовать SQLite сразу из PHP и KPHP.
Создавать FFI пакеты — не просто. Под катом будут ответы на следующие вопросы:
- Как упростить установку и сделать библиотеку кроссплатформенной?
- Как не допустить утечек ресурсов?
- Как сделать библиотеку совместимой с KPHP и PHP?
- Какова производительность FFI решений?
Мы не только попробуем новую библиотеку в действии, но и выработаем ряд практик, которые при широком распространении могут улучшить ситуацию с FFI пакетами в сообществе.
Предисловие
Foreign Function Interface для PHP не так популярен, как мог бы быть, ведь для очень большого количества популярных библиотек уже есть нативные PHP расширения. Большинству будет достаточно чего-то из поставляемого с PHP, а для остальных есть внешние репозитории и PECL.
У FFI есть ряд преимуществ:
- Не нужно писать сишный код
- После изменения кода библиотеки не требуется перекомпиляция модуля
- Более высокая обратная совместимость: мы не зависим от внутреннего Zend API
- Проще распространять код как composer пакеты
- Следуя конвенциям, мы можем сделать FFI пакеты ещё более удобными
- Потенциально более низкий порог входя для создания библиотек (но есть нюансы)
Для KPHP этот инструмент стал единственным способом расширения со стороны. Причём работать такие расширения будут как на KPHP, так и на PHP.
Есть так же и недостатки, связанные с этим подходом. Начиная от более низкой производительности, заканчивая менее обширной документацией. Хотя я бы сказал, что сам по себе FFI довольно прост. Сложности в основном возникают при попытках использовать FFI библиотеки в реальных условиях, а не в упрощённых CLI утилитах.
Сегодня я постараюсь заполнить некоторые пробелы и поделиться некоторыми идеями по поводу того, как стоит проектировать и распространять FFI пакеты. Но начнём мы с обзора самой библиотеки KSQLite.
Установка библиотеки
Когда мы ставим обычный composer пакет, нам достаточно выполнить одну лишь команду composer require, и библиотека становится доступной в нашем проекте.
Начнём как раз с этого:
$ composer require quasilyte/ksqliteВ случае с FFI библиотеками этого недостаточно. Кроме самой обёртки над C функциями нам так же нужна сама динамическая библиотека.
Чтобы использовать KSQLite, нам потребуется libsqlite3.so на Линуксе, libsqlite3.dylib на MacOS и libsqlite3.dll на Windows.
Допустим, мы устанавливаем библиотеку на Ubuntu.
$ sudo apt install sqlite3Теперь нужно понять, где же находится libsqlite3.so.
$ ldconfig -p | grep sqlite3
libsqlite3.so.0 (libc6,x86-64) => /lib/x86_64-linux-gnu/libsqlite3.so.0Здесь мы уже встречаем первую сложность: вместо libsqlite3.so у нас файл называется libsqlite3.so.0. Сделав dlopen("libsqlite3.so") мы не сможем найти эту библиотеку.
В PHP и KPHP имя динамической библиотеки указывается в заголовочном файле через define FFI_LIB.
Для нашего случая мы могли бы в своей библиотеки написать что-то такое:
#define FFI_LIB "libsqlite3.so.0"Этот заголовочный файл — часть библиотеки и composer пакета. Он один на все системы. Используя подход с указанием пути как на нашей машине, получаем следующие проблемы:
- А что, если у вас нет суффикса
.0и файл доступен по обычному имени? - Как быть с MacOS и Windows?
- Как понять, что загружена нужная версия библиотеки?
Я предлагаю использовать следующую конвенцию во всех FFI пакетах:
- В
FFI_LIBмы не указываем никакого расширения - Пути пишем относительные, через директорию
ffilibs
- #define FFI_LIB "libsqlite3.so.0"
+ #define FFI_LIB "./ffilibs/libsqlite3"Теперь для всех систем у нас есть одинаковый рецепт для установки: положить файлик динамической библиотеки в директорию ffilibs внутри корня приложения. Дополнительный уровень в виде ffilibs нужен для гибкости. Это может быть ссылка на системный каталог или на любое другое место, где мы сможем найти нужные библиотеки.
Что можно создать с помощью KSQLite
Никаких принципиальных ограничений нет. Всё то, что возможно с помощью расширения SQLite3, можно сделать и через KSQLite.
В примерах использования можно найти simple_site, который сохраняет данные в локальной базе SQLite.
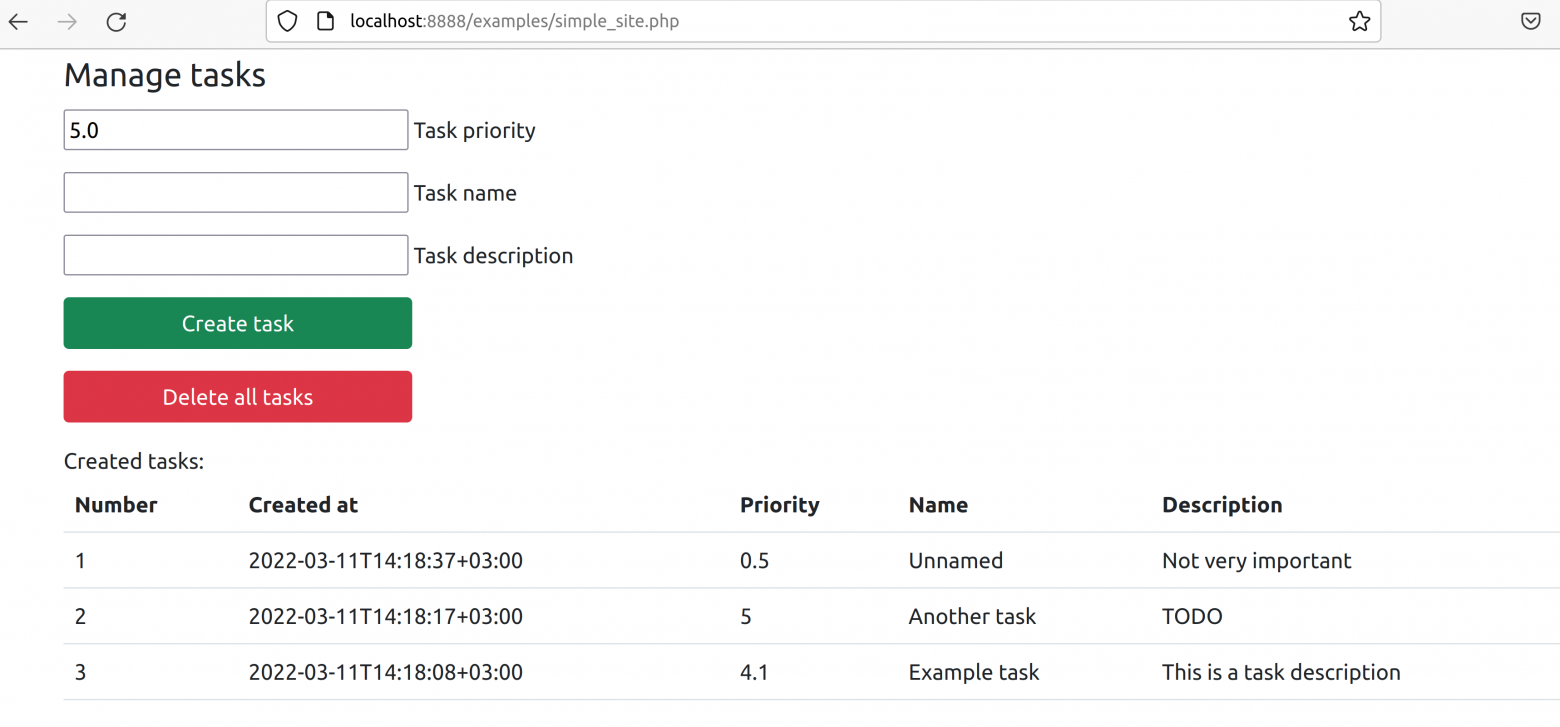
Запустить этот пример можно на KPHP сервере, встроенном в PHP dev сервере и через любую другую связку (например, nginx с php-fpm). Вот пример запуска на встроенном сервере:
# Создадим ffilibs с ссылками на библиотеку, если их ещё нет.
mkdir -p ffilibs
ln -sf $(shell php -f locate_lib.php -- -q) ./ffilibs/libsqlite3
# Запускаем сервер.
$ php -d opcache.preload=preload.php -S localhost:8888Скрипт locate_lib.php полезен как для пользователей, так и для CI окружений.
# Запуск без -q предназначен для людей, а не скриптов.
$ php -f locate_lib.php
library candidate: /lib/x86_64-linux-gnu/libsqlite3.so.0
library candidate: /lib/x86_64-linux-gnu/libsqlite3.so
run something like this to make it discoverable (unix):
mkdir -p ffilibs
sudo ln -s /lib/x86_64-linux-gnu/libsqlite3.so ./ffilibs/libsqlite3Пишем запросы
Для начала нам нужно открыть соединение с базой данных:
<?php
require_once __DIR__ . '/vendor/autoload.php';
use KSQLite\KSQLite;
$db = new KSQLite();
// open() открывает существующий файл SQLite или создаёт
// новый в случае его отсутствия.
if (!$db->open('testdb')) {
throw new Exception('open error: ' . $db->getLastError());
}Закрывать объект $db не нужно. Ниже мы ещё вернёмся к этому вопросу и разберёмся, как KSQLite управляет ресурсами и защищает пользователей от утечек памяти.
KSQLite предоставляет три основных набора методов для исполнения запросов:
execметоды игнорируют возвращаемые базой данных результатыfetchметоды возвращают данные в виде массивов или скаляровqueryметоды позволяют самостоятельно обработать данные результатов
Создадим тестовую таблицу. Для этого подойдёт метод exec:
$query = '
CREATE TABLE IF NOT EXISTS languages(
lang_id INTEGER PRIMARY KEY,
lang_name TEXT NOT NULL,
first_appeared INTEGER NOT NULL,
num_elephants REAL NOT NULL
);
';
if (!$db->exec($query)) {
// В настоящем коде у вас будет более серьёзная обработка ошибок.
// Здесь же я буду просто швырять исключения.
throw new Exception('create table error: ' . $db->getLastError()));
}Добавим немного данных в таблицу languages. Будем вставлять по одной строке за запрос.
$rows = [
['C', 1972, 0.0],
['C++', 1983, 0.0],
['JavaScript', 1995, 0.0],
['Go', 2009, 0.0],
];
foreach ($rows as $row) {
$query = "
INSERT INTO languages(lang_name, first_appeared, num_elephants)
VALUES(?1, ?2, ?3)
";
// Наш $row - это массив из 3 элементов, с индексами от 0 до 2.
// Параметры запроса индексируются с 1.
// Вспомогательная функция paramsFromList позволяет отобразить
// массив привязок без ручной распаковки.
//
// Другими словами, массив ['C', 1972, 0.0] превращается в
// [1 => 'C', 2 => 1972, 3 => 0.0].
$params = KSQLite::paramsFromList($row);
if (!$db->exec($query, $params)) {
throw new Exception('insert: ' . $db->getLastError());
}
}Здесь для каждого $row мы заново парсим SQL запрос, выделяем statement объект и используем его для разовой вставки данных.
Мы можем использовать prepared statement API для множественных операций над одним SQL statement:
// Воспользуемся именованными параметрами привязок.
$rows = [
[':name' => 'PHP', ':year' => 1995, ':elephants' => 1.0],
[':name' => 'KPHP', ':year' => 2014, ':elephants' => 2.0],
];
$query = "
INSERT INTO languages(lang_name, first_appeared, num_elephants)
VALUES(?name, ?year, ?elephants)
";
$ok = $db->execPrepared($query, function(KSQLiteParamsBinder $b) use ($rows) {
return $b->bindFromArray($rows);
});
if (!$db->exec($query, $params)) {
throw new Exception('insert: ' . $db->getLastError());
}bindFromArray — это вспомогательный метод для частого случая связывания данных по массиву. Без этого метода код выглядел бы как-то так:
$ok = $db->execPrepared($query, function(KSQLiteParamsBinder $b) use ($rows) {
if ($binder->query_index >= count($rows)) {
return false; // Больше у нас нет данных для вставки
}
foreach ($rows[$binder->query_index] as $k => $v) {
$this->bind($k, $v);
}
return true; // Успешно связали параметры; запрос будет исполнен
});Для массивов этот вариант выглядит переусложнённым, но он полезен, если генератор данных у нас похож на поток, где мы не знаем сколько раз нам нужно будет проводить вставку.
Выборки данных проще всего делать через fetch методы.
$query = 'SELECT COUNT(*) FROM languages';
[$count, $ok] = $db->fetchColumn($query);
if (!$ok) {
throw new Exception('select count: ' . $db->getLastError());
}fetch, как и остальные методы, поддерживает параметры запросов. Кроме этого, можно передать свою функцию-маппер и управлять тем, какие данные будут добавлены в выходной массив.
$query = 'SELECT * FROM languages WHERE num_elephants >= :x';
$params = [':x' => 1.0];
$mapper = function(KSQLiteQueryContext $ctx) {
return $ctx->rowDataAssoc()['lang_name'];
};
[$lang_names, $ok] = $db->fetch($query, $params, $mapper);
if (!$ok) {
throw new Exception('select langs: ' . $db->getLastError());
}Транзакции
Рассмотрим следующий пример:
if (!$db->exec('BEGIN')) {
throw new Exception('begin transaction: ' . $db->getLastError());
}
$ok = execute_queries($db); // Выполняем запросы внутри транзакции
$action = $ok ? 'COMMIT' : 'ROLLBACK';
if (!$db->exec($action)) {
throw new Exception("$action :" . $db->getLastError());
}Этот подход будет работать в простейших случаях, но здесь очень легко допустить ошибку. Например, если execute_queries() может бросать исключение, то мы рискуем не выполнить ROLLBACK.
Чтобы избежать таких ситуаций, нужно использовать ваши любимые паттерны для работы с транзакциями. Я покажу один из простых вариантов ниже.
/**
* @param KSQLite $db
* @param callable(KSQLite):boolean
*/
function do_with_transaction(KSQLite $db, callable $fn): bool {
if (!$db->exec('BEGIN')) {
return false;
}
/** @var \Throwable $exception */
$exception = null;
try {
$commit = $fn($db);
} catch (\Throwable $e) {
$db->exec('ROLLBACK');
throw $e;
}
return $db->exec($commit ? 'COMMIT' : 'ROLLBACK');
}С такой обёрткой код из примера выше превращается в это:
$ok = do_with_transaction($db, function(KSQLite $db) {
return execute_queries($db);
});
if (!$ok) {
throw new Exception('do with transaction: ' . $db->getLastError());
}query API
Через query можно исполнить любой запрос: fetch и exec построены поверх query.
Для демонстрации некоторых возможностей реализуем fetch используя query.
В KPHP нельзя захватить переменную по ссылке, но захват объекта по значению эквивалентно ссылке. Поэтому, если из query нужно получить данные, делается это через заполнение объекта. Для некоторых случаев вам может хватить класса KSQLiteArray.
// Я специально не использую type hints в сигнатуре
// чтобы определение функции было более компактным по ширине.
/**
* @param KSQLite $db
* @param string $sql
* @param mixed[] $params query bind params
* @param callable(KSQLiteQueryContext):mixed $f
* @return tuple(mixed[],bool)
*/
function my_fetch($db, $sql, $params, $f) {
$res = new KSQLiteArray();
$row_func = function(KSQLiteQueryContext $ctx) use ($res, $f) {
$res->values[] = $f($ctx);
}
$ok = $this->query($sql, $params, $row_func);
return tuple($res->values, $ok);
}$ctx->stop()просит библиотеку пропустить все следующие result row sets$ctx->rowData()читает данные в list-подобный массив (без строковых ключей)$ctx->rowDataAssoc()подобенrowData()с ключами черезcolumnName()$ctx->columnName($i)возвращает имя для i-го элемента данных$ctx->columnType($i)возвращает тип для i-го элемента данных$ctx->numColumns()возвращает количество столбцов в каждом result row set
Можно обойти все результаты из выборки без чтения самих данных, если вам нужны только метаданные. До тех пор, пока не вызывается rowData() или rowDataAssoc(), KSQLite не пытается прочитать и разложить данные на PHP/KPHP массивы.
Управление ресурсами в KSQLite
Библиотека никогда не даёт пользователю объект, у которого есть методы close() или finalize(), за исключением самого объекта базы данных (но и тот по умолчанию не требует явного закрытия).
Вместо этого методы для работы с данными принимают функции, контролирующие связку параметров запросов и итерацию по результатам. Таким образом, все создаваемые SQLite сущности, требующие очистки, не выходят за пределы публичного интерфейса KSQLite.
Деструкторы могли бы быть альтернативой: финализация и/или close() вызывались бы "когда-то потом" и автоматически. Если при этом мы не даём публичных методов close(), то принципиальной разницы нет и очистка ресурсов всё ещё целиком лежит на самой библиотеке. Разве что с деструкторами становится менее очевидно, где заканчивается жизнь объекта. В контексте FFI и объектов, аллоцируемых C кодом, мы хотим быть вдвойне уверены, что память будет очищена правильно и своевременно. В наших интересах ограничивать время жизни таких объектов. Если мы предоставляем объекты с деструкторами, то пользователь может начать их сохранять в массивах, а, значит, мы рискуем очень долго не иметь возможности финализировать их.
Если предоставлять публичные методы для финализации, то мы усложняем жизнь разработчикам. Использовать нашу библиотеку правильно становится сложнее. Если кто-то кинет исключение и не закроет ресурс перед этим, то ничем хорошим это не кончится.
Я считаю, что для подобных FFI библиотек особо важно минимизировать прямое взаимодействие с "нативной" частью. Вместо того чтобы перекладывать ответственность за освобождение ресурсов на пользователя, можно скрыть сложность внутри и искоренить принципиальную возможность утечек памяти.
Особенно сложно бороться с возможными die() или exit(). В идеале, стоит избегать этих механизмов, когда где-то рядом исполняется FFI код.
Очищаем память даже в случае die/exit
В KPHP нет деструкторов, поэтому единственное, что нас может спасти от внезапного прекращения работы скрипта — это функция, регистрируемая через register_shutdown_function.
Поскольку регистрировать на каждый объект, который мы хотим автоматически финализировать, новую shutdown функцию — это расточительно, рекомендуется использовать пакет KFinalize. Этот пакет позволяет сохранить список финализаторов, которые будут запущены внутри одной shutdown функции.
Именно через этот механизм и работает автоматический close() объектов KSQLite. При создании нового экземпляра, мы добавляем лямбду-финализатор в список KFinalize.
Рассмотрим следующий пример кода:
$query = 'SELECT 10 AS value';
$db->fetch($query, [], function(KSQLiteQueryContext $ctx) {
if (some_cond()) {
die("exiting right from the callback\n");
}
return 0;
});Вся модель очистки ресурсов KSQLite построена на том, что объекты создаются и освобождаются вне вашего кода. Вот как исполняется fetch (упрощённо):
- Создаётся SQLite3 stmt
- Запускается SQLite3 step
- Вызывается предоставленная функция
- Когда данных больше нет, SQLite3 stmt очищается
- Из
fetchвозвращается результат
Пользовательская функция вызывается в блоке try/catch, поэтому исключения не помешают корректной очистке ресурсов. Само исключение будет повторно запущено после очистки ресурсов запроса.
Если же на шаге 3 произойдёт exit(), то мы никогда не перейдём к следующим шагам. Память, выделенная нативной библиотекой никогда не будет освобождена, потому что KPHP (и PHP) рантаймы ничего о ней не знают.
Тем не менее выход есть. В классе KSQLite хранится список активных stmt объектов. Как только выделяется новый объект SQLite stmt, мы добавляем его в список. Затем мы исполняем алгоритм, как и раньше. Перед очищением памяти мы делаем array_pop из этого списка. В простейшем сценарии, этот список почти всегда содержит от 0 до 1 элементов.
В нашем "деструкторе", который мы регистрируем для объекта KSQLite через KFinalize, мы обходим список активных объектов данного коннектора и финализируем их. Если никаких exit/die не было, то этот список будет пустым.
Вот так выглядит деструктор для KSQLite:
KFinalize::push(function() {
foreach ($this->active_stmt_list as $stmt) {
$this->lib->sqlite3_finalize($stmt);
}
// Вызывать close() безопасно даже если пользователь
// вызывал его до этого вручную.
$this->close();
});Производительность KSQLite
Тесты производительности здесь нужны для того, чтобы понять, насколько FFI библиотеки могут сравниться по эффективности с нативными расширениями для PHP. FFI — это единственный на данный момент способ использовать C библиотеки из KPHP, поэтому логично включить в сравнение и этот пункт.
Нагрузочное тестирование будем проводить следующим образом:
- В качестве работающего приложения возьмём KSQLite/examples/simple_site.
- Запускать PHP будем через
nginx+php-fpm - Подавать нагрузку и измерять RPS будем через
ab - Сервер и воркеры будут работать на выделенных ядрах
abбудет работать на других выделенных ядрах
Подробнее о методике читайте под спойлерами ниже.
| Test | Requests/sec |
|---|---|
| PHP7.4 FFI | 5694 |
| PHP7.4 ext | 6415 |
| PHP8.1 FFI | 6147 |
| PHP8.1 ext | 6673 |
| KPHP FFI | 9010 |
KSQLite на данный момент не содержит никаких оптимизаций для частных случаев. Даже простой exec(), которого в производимых бенчмарках много, выполняет лишнюю работу. В FFI вариантах мы получаем больше интерпретируемого PHP кода: часть логики exec() реализована на самом PHP, а не на C.
Благодаря компиляции и информации о типах, вызовы из KPHP в C гораздо дешевле. Помогает и тот факт, что KPHP транслируется в C++, а из C++ легко можно вызывать C функции.
- PHP8.1 оказался быстрее PHP7.4 на
~5%(JIT включен) - KSQLite для PHP медленнее на
~10% - KPHP с FFI в этом тесте на
~25%быстрее чем, PHP8.1 ext
KPHP собран с коммита 1e584607616e237bc0abcc0e989e0a1725a08b68.
$ php7.4 --version
PHP 7.4.3 (cli) (built: Nov 25 2021 23:16:22) ( NTS )
$ php8.1 --version
PHP 8.1.3 (cli) (built: Feb 21 2022 14:48:42) (NTS)
$ php8.1 -i | grep JIT
PCRE JIT Support => enabled
PCRE JIT Target => x86 64bit (little endian + unaligned)
JIT => On
$ sqlite3 --version
3.31.1 2020-01-27
$ nginx -v
nginx version: nginx/1.18.0 (Ubuntu)
$ ab -V
This is ApacheBench, Version 2.3 <$Revision: 1843412 $>
$ uname -a
Linux kphpbook 5.14.0-1024-oem 26-Ubuntu SMP Thu Feb 17 2022 x86_64 GNU/Linux$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 39 bits physical, 48 bits virtual
CPU(s): 8
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 140
Model name: 11th Gen Intel(R) Core(TM) i7-1165G7 @ 2.80GHz
Stepping: 1
CPU MHz: 2800.000
CPU max MHz: 4700,0000
CPU min MHz: 400,0000
L1d cache: 192 KiB
L1i cache: 128 KiB
L2 cache: 5 MiB
L3 cache: 12 MiBОтключаем turbo boost (снижает RPS, но увеличивает точность измерений):
$ echo "1" | sudo tee /sys/devices/system/cpu/intel_pstate/no_turboПодготавливаем nginx:
# Сохраняем pid работающего мастер-процесса nginx:
$ nginx_pid=$(ps -aux | grep nginx | grep master | awk '{print $2}')
# Пытаемся закрепить nginx за ядрами 2, 3 и 4:
$ sudo taskset -cp 2-4 $nginx_pid
# Аналогично для всех worker-процессов:
$ nginx_workers=$(cat /proc/$nginx_pid/task/$nginx_pid/children)
$ for pid in $nginx_workers ; do sudo taskset -cp 2-4 $pid ; doneKPHP для тестов запускать так:
# У nginx на моей машине 8 воркеров, поэтому и в KPHP укажем это значение.
# Воркер-процессы, создаваемые веб-сервером, унаследуют параметры,
# выставляемые через taskset.
$ taskset -c 2-4 ./kphp_out/server --http-port 9000 --workers-num 8А нагрузку подаём скриптом с ядер 5, 6 и 7:
$ taskset -c 5-7 \
ab -T 'application/x-www-form-urlencoded' \
-n 5000 \
-c 4 \
-p post.data \
http://localhost:9001/php-fpm + FFI preloading
Для того, чтобы PHP не разбирал заголовочные файлы на каждом запросе, рекомендуется использовать FFI::scope. Воспользоваться им можно только если нужные файлы были загружены на этапе opcache preload.
Чтобы вся эта связка работала, надо подкрутить настройки нашего PHP.
FFI::loadдля регистрации в scope мы должны делать в preload контексте- Мастер-процесс
php-fpmдолжен быть запущен не от рута - Нельзя использовать
opcache.preload_user
Эти пункты взаимосвязаны. opcache.preload потребует указания opcache.preload_user, если php-fpm работает от рута. Если мы добавим в конфиг opcache.preload_user, у нас перестанет работать FFI::load внутри скрипта предзагрузки (на это неожиданное поведение даже заведён тикет).
Вариантов не очень много. В одном из обсуждений на reddit можно найти подсказку к тому, как получить рабочее решение.
Нам нужно выполнить пункт (2) и тогда все остальные будут выполнены без проблем, ведь opcache.preload_user требуется только для рута.
Решение будет зависеть от системы.
На моей Ubuntu нужно было отредактировать:
/lib/systemd/system/php7.4-fpm.service/lib/systemd/system/php8.1-fpm.service
В секцию [Service] добавляем User и Group:
[Service]
+ User=www-data
+ Group=www-data
Type=notifyДалее можно попробовать перезапустить сервис php-fpm, но, скорее всего, нужно будет ещё поменять владельцев всех файлов и каталогов в корне сайта.
Условного chown -R www-data ~/www будет достаточно.
Мне так же потребовалось поменять владельца файла логов /var/log/php7.4-fpm.log, но наверняка есть какой-то способ попросить php-fpm записывать логи в какое-то другое место, куда у пользователя будет более простой доступ.
Теперь непосредственно к самому preload скрипту. Поскольку мы ожидаем, что все FFI библиотеки будут доступны по относительному пути, мы должны запускать FFI::load из нужной директории. В случае CLI рабочая директория будет предсказуемая, а вот php-fpm может запустить скрипт предзагрузки с самого корня (/). Чтобы сделать preload скрипт более независимым от рабочей директории, можно переходить в нужное место из самого скрипта.
В проекте KSQLite файлы располагаются так:
examples/
preload.php
simple_site.php
ffilibs/
libsqlite3
src/Следовательно, ffilibs находится на уровень выше относительно preload.php.
// Если бы preload.php находился в корне, здесь был бы просто __DIR__.
$root_path = __DIR__ . '/../';
if (!chdir($root_path)) {
throw new Exception("failed chdir to $root_path\n");
}
// Запускаем тут все FFI::load от библиотек.
// Про договорённость Libname::loadFFI() читайте ниже.
load_ffi_libs(); Теперь мы можем легко запускать приложение как через CLI, встроенный веб-сервер PHP (-S), php-fpm, а также в режиме собранного KPHP бинарника (тоже CLI + server).
Тестирование

Тестировать мы будем как на PHP, так и на KPHP, поэтому нам понадобятся сразу два пакета:
# phpunit мы используем для запуска тестов в PHP режиме
$ composer require --dev phpunit/phpunit:9.5.16
# kphpunit - это то, что реализует phpunit для KPHP
$ composer require --dev vkcom/kphpunit:v1.0.0
# Устанавливаем утилиту ktest для запусков KPHP тестов и бенчмарков
$ composer require --dev vkcom/ktest-scriptИсполнять тесты на обоих языках полезно, чтобы ловить некоторые нюансы различий поведения PHP и KPHP. А ещё это гарантирует, что типизация в проекте не сломалась.
Создадим тестовый класс tests/KSQLiteTest.php:
<?php
use PHPUnit\Framework\TestCase;
class KSQLiteTest extends TestCase {
}Заполнять весь класс в рамках этой статьи мы не будем. Затронем лишь самые важные аспекты.
Для создания, заполнения и очистки БД мы воспользуемся setUpBeforeClass и tearDownAfterClass. Соединение с БД будем держать в статическом поле класса.
private static $db_filename = '';
private static KSQLite $db;
private static $coord_values = [];
public static function setUpBeforeClass(): void {
if (KPHP_COMPILER_VERSION) { KSQLite::loadFFI(); }
$tmp_dir = '/tmp'; // или sys_get_temp_dir()
self::$db_filename = (string)tempnam($tmp_dir, 'testdb');
self::$db = new KSQLite();
if (!self::$db->open(self::$db_filename)) {
throw new \Exception(self::$db->getLastError());
}
// Создаём тестовые таблицы.
$tables = [
'CREATE TABLE readonly_coord(
coord_id INTEGER PRIMARY KEY,
layer INTEGER DEFAULT 0 NOT NULL,
x REAL NOT NULL,
y REAL NOT NULL
)',
];
foreach ($tables as $q) {
if (!self::$db->exec($q)) {
throw new \Exception(self::$db->getLastError());
}
}
$values = [
[142.5, 218.0],
[0.0, 0.0],
[1.0, 1.0],
];
// Значения нам понадобятся чтобы потом сравнивать
// результаты выборок в тестах.
foreach ($values as $i => $c) {
[$x, $y] = $c;
self::$coord_values[] = [
'x' => $x,
'y' => $y,
];
}
$q = 'INSERT INTO readonly_coord(x, y) VALUES(?, ?)';
$bind_fn = function(KSQLiteParamsBinder $b) use ($values) {
return $b->bindFromList($values);
}
$ok = self::$db->execPrepared($q, $bind_fn);
if (!$ok) {
throw new \Exception(self::$db->getLastError());
}
}
public static function tearDownAfterClass(): void {
self::$db->close();
unlink(self::$db_filename);
}В написании самих тестов нет никаких особенностей. Обычные phpunit тесты.
public function testFetchColumn() {
$tests = [
0,
102,
4.25,
'str value',
'"str value with quotes"',
null,
];
$query = 'SELECT :x';
foreach ($tests as $x) {
$params = [':x' => $x];
[$col, $ok] = self::$db->fetchColumn($query, $params);
$this->assertTrue($ok);
$this->assertSame($col, $x);
}
$query = 'SELECT COUNT(*) FROM readonly_coord';
[$count, $ok] = self::$db->fetchColumn($query);
$this->assertTrue($ok);
$this->assertSame($count, count(self::$coord_values));
}Запуск phpunit для PHP:
$ php -d opcache.enable_cli=true \
-d opcache.preload=preload.php \
./vendor/bin/phpunit \
--bootstrap vendor/autoload.php testsЗапуск ktest (kphpunit) для KPHP:
$ ./vendor/bin/ktest phpunit --enable-ffi testsНа остальные вопросы по тестированию ответят исходники KSQLite:
- Makefile содержит команды
make testиmake ci-test - .github/workflows/php.yml описывает workflow для запуска тестов
- Примеры (examples) можно превратить в тесты, см.
ktest compare
Я рекомендую ознакомиться со статьёй Заметки KPHP: тестирование и бенчмарки. Там тема тестирования KPHP затронута более полно.
Бенчмарки
Как уже упоминалось выше, KSQLite — это не многолетний код, который мог обрасти разнообразными оптимизациями. Многие функции можно ускорить.
Но ускорять вслепую, руководствуясь только своей интуицией и предчувствием — это не самая эффективная методология. В худшем случае таким оптимизации могут сделать только хуже. Стоит производить хотя бы минимальные действия по проверке гипотезы — запускать бенчмарки.
Создадим файл benchmarks/BenchmarkKSQLite.php:
<?php
use KSQLite\KSQLite;
class BenchmarkKSQLite {
private KSQLite $db;
public function __construct() {
if (KPHP_COMPILER_VERSION) { KSQLite::loadFFI(); }
$this->db = new KSQLite();
if (!$this->db->open('benchdb')) {
throw new \Exception($this->db->getLastError());
}
}
public function benchmarkExecSelect1() {
if (!$this->db->exec('SELECT 1')) {
throw new \Exception($this->db->getLastError());
}
}
public function benchmarkFetchRowConst() {
[$_, $ok] = $this->db->fetchRow("SELECT 1, 2.5, 'hello', null");
if (!$ok) {
throw new \Exception($this->db->getLastError());
}
}
}ktest позволяет запускать бенчмарки на PHP и KPHP. Это полезное свойство, ведь даже если приложение размещается на конечных серверах в виде KPHP бинарника, PHP часто используется для локального тестирования.
# Запускаем бенчмарки на KPHP:
$ ./vendor/bin/ktest bench ./benchmarks
BenchmarkKSQLite::ExecSelect1 14740 5520.0 ns/op
BenchmarkKSQLite::FetchCount 5340 16751.0 ns/op
BenchmarkKSQLite::FetchRowConst 7640 12406.0 ns/op
BenchmarkKSQLite::FetchOneRow 3380 29379.0 ns/op
BenchmarkKSQLite::FetchAllRows 3720 27008.0 ns/op
ok BenchmarkKSQLite
# Запускаем бенчмарки на PHP8.1:
$ ./vendor/bin/ktest bench-php --preload preload.php ./benchmarks
BenchmarkKSQLite::ExecSelect1 7760 12045.0 ns/op
BenchmarkKSQLite::FetchCount 2720 27958.0 ns/op
BenchmarkKSQLite::FetchRowConst 3860 23208.0 ns/op
BenchmarkKSQLite::FetchOneRow 2080 41163.0 ns/op
BenchmarkKSQLite::FetchAllRows 2400 40979.0 ns/op
ok BenchmarkKSQLiteДля удобного сравнения результатов бенчмарков PHP и KPHP есть команда bench-vs-php:
./vendor/bin/ktest bench-vs-php --preload preload.php ./benchmarks
name PHP time/op KPHP time/op delta
KSQLite::ExecSelect1 10.5µs ± 1% 5.5µs ± 3% -47.95%
KSQLite::FetchCount 28.0µs ± 1% 17.1µs ± 1% -38.79%
KSQLite::FetchRowConst 23.5µs ± 1% 11.5µs ± 1% -50.82%
KSQLite::FetchOneRow 40.8µs ± 1% 27.1µs ± 1% -33.57%
KSQLite::FetchAllRows 40.7µs ± 1% 26.5µs ± 1% -35.07%Подробнее о бенчмарках можно почитать в уже упомянутой выше статье.
Конвенции для FFI пакетов
В этой части кратко описаны основные концепции, вводимые в статье.
Метод loadFFI
Поскольку контексты загрузки могут отличаться для KPHP и PHP, стоит предоставить вызов инициализации в руки пользователей. В основном классе библиотеки определяем статический метод loadFFI(), который выполнит FFI::load() на все файлы, связанные с библиотекой.
public static function loadFFI(): bool {
return \FFI::load(__DIR__ . '/sqlite.h') !== null;
}В KPHP вы будете вызывать этот метод где-то в начале скрипта, который является точкой входа в приложение:
if (KPHP_COMPILER_VERSION) {
KSQLite::loadFFI();
SomeOtherLib::loadFFI();
}В PHP это будет preload скрипт с такими же вызовами, но без проверки на KPHP_COMPILER_VERSION:
<?php
require_once __DIR__ . '/autoload.php'
KSQLite::loadFFI();
SomeOtherLib::loadFFI();Почему это важно:
- Меньше беспорядка при использовании нескольких FFI библиотек
- Контроль над контекстом, в котором исполняется
FFI::load
opcache.preload и chdir
В предыдущем примере мы использовали методы loadFFI(), но есть нюанс, который мы не затронули. В зависимости от приложения, preload.php может лежать в разных местах. Сам же скрипт тоже может запускаться из разных директорий.
// Если бы preload.php находился в корне, здесь был бы просто __DIR__.
$root_path = __DIR__ . '/../';
if (!chdir($root_path)) {
throw new Exception("failed chdir to $root_path\n");
}
KSQLite::loadFFI();
SomeOtherLib::loadFFI();Почему это важно:
- Можно вызывать скрипт из любой директории
- Эта схема работает как для CLI, так и для
php-fpm
FFI_LIB
Путь в #define FFI_LIB пишем относительный, через каталог ffilibs. Никакого платформенного расширения, типа .so мы не указываем.
#define FFI_LIB "./ffilibs/libsqlite3Для удобства, рекомендуется предоставлять аналог скрипта locate_lib.php, чтобы пользователям было проще правильно установить библиотеку.
Почему это важно:
- Проще инструкции установки. Везде идентичные (Windows, MacOS, Linux)
- Можно легко переносить директорию с проектом между машинами
ffilibsможет быть ссылкой на какую-то системную папку
Избегаем утечек памяти
Самостоятельно удалять объекты, созданные через FFI::new не нужно.
Очистки или финализации требуют те объекты, что инициализируются внутри C кода. Эти аллокации могут либо менять внутреннее состояние библиотеки, либо использовать системный аллокатор. В любом из этих случаев, нам надо самостоятельно вызвать C функцию-деструктор, предоставляемую библиотекой.
Вот несколько рекомендаций:
- Используйте KFinalize для эмуляции деструкторов
- Если можно инкапсулировать финализируемые объекты — сделайте это
- Проектируйте такое API, которое сложно использовать неправильно
Обработка ошибок должна быть консистентной и предсказуемой. Исключения могут быть неожиданными — пользователь должен быть к ним готов, чтобы на месте получения исключения освободить ресурсы.
Почему это важно:
- В режиме работы сервера, небольшая утечка становится большой через пару тысяч запросов
Заключение
Попробуйте KSQLite на PHP, а потом запустите его на KPHP.
Создавайте свои FFI библиотеки и делитесь ими.
Если у вас остались какие-то вопросы по KSQLite или FFI в KPHP — прошу в комментарии.
Полезные ссылки
- awesome-kphp
- Неофициальный чат KPHP-сообщества
- Статья Создаём игру на KPHP с помощью FFI и SDL
- Статья Пробуем KPHP: реально ли его использовать в своих проектах
- Статья Заметки KPHP: тестирование и бенчмарки
- Статья ВКонтакте снова выкладывает KPHP



