

У нас в агрегации локальной сети было шесть пар коммутаторов Arista DCS-7050CX3-32S и одна пара коммутаторов Brocade VDX 6940-36Q. Не то, чтобы нас сильно напрягали коммутаторы Brocade в этой сети, они работают и выполняют свои функции, но мы готовили полную автоматизацию некоторых действий, а этих возможностей мы на этих коммутаторах не имели. А еще хотелось перейти с 40GE интерфейсов на возможность использования 100GE, чтобы сделать запас на следующие 2-3 года. Так мы решили поменять Brocade на Arista.
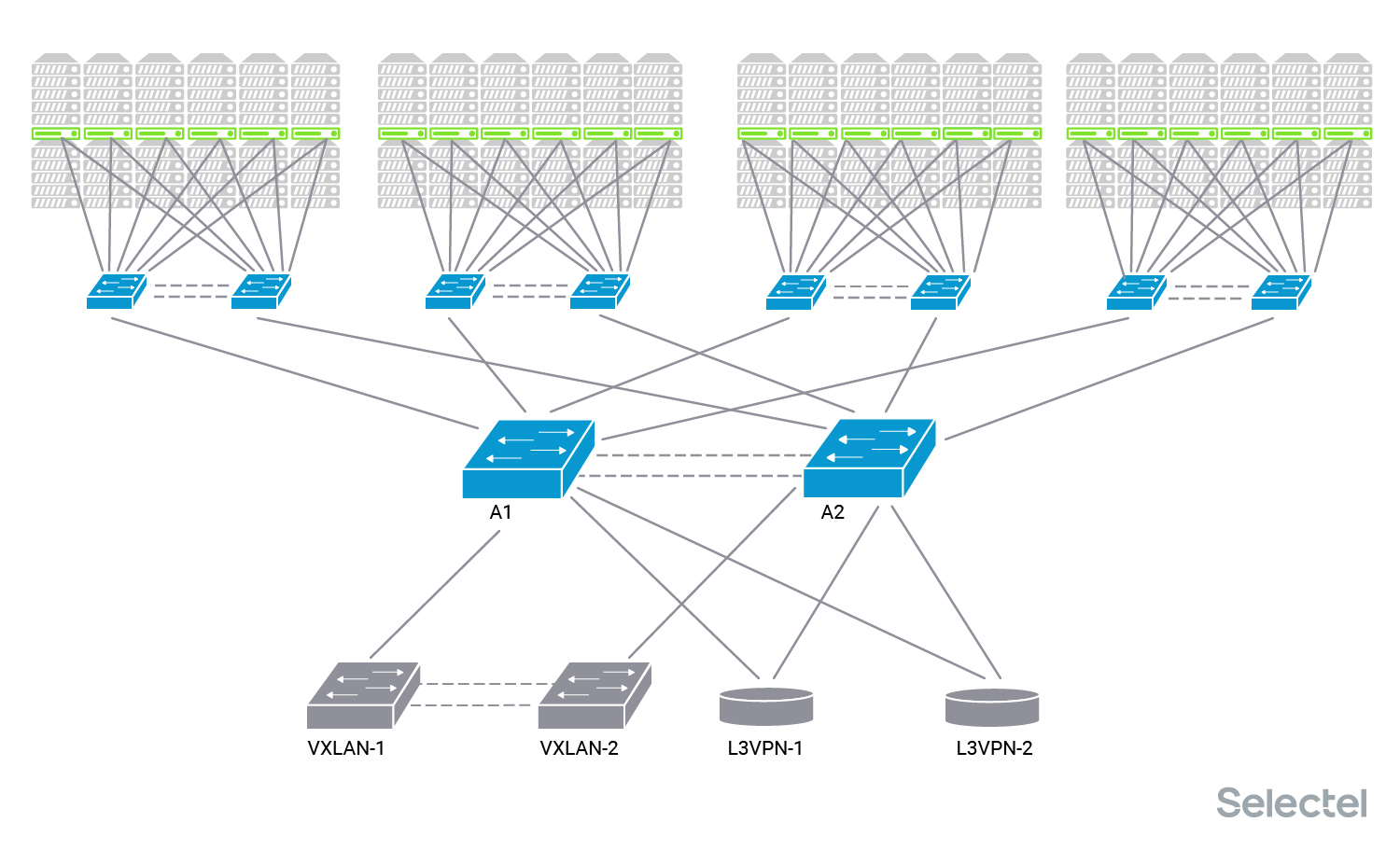
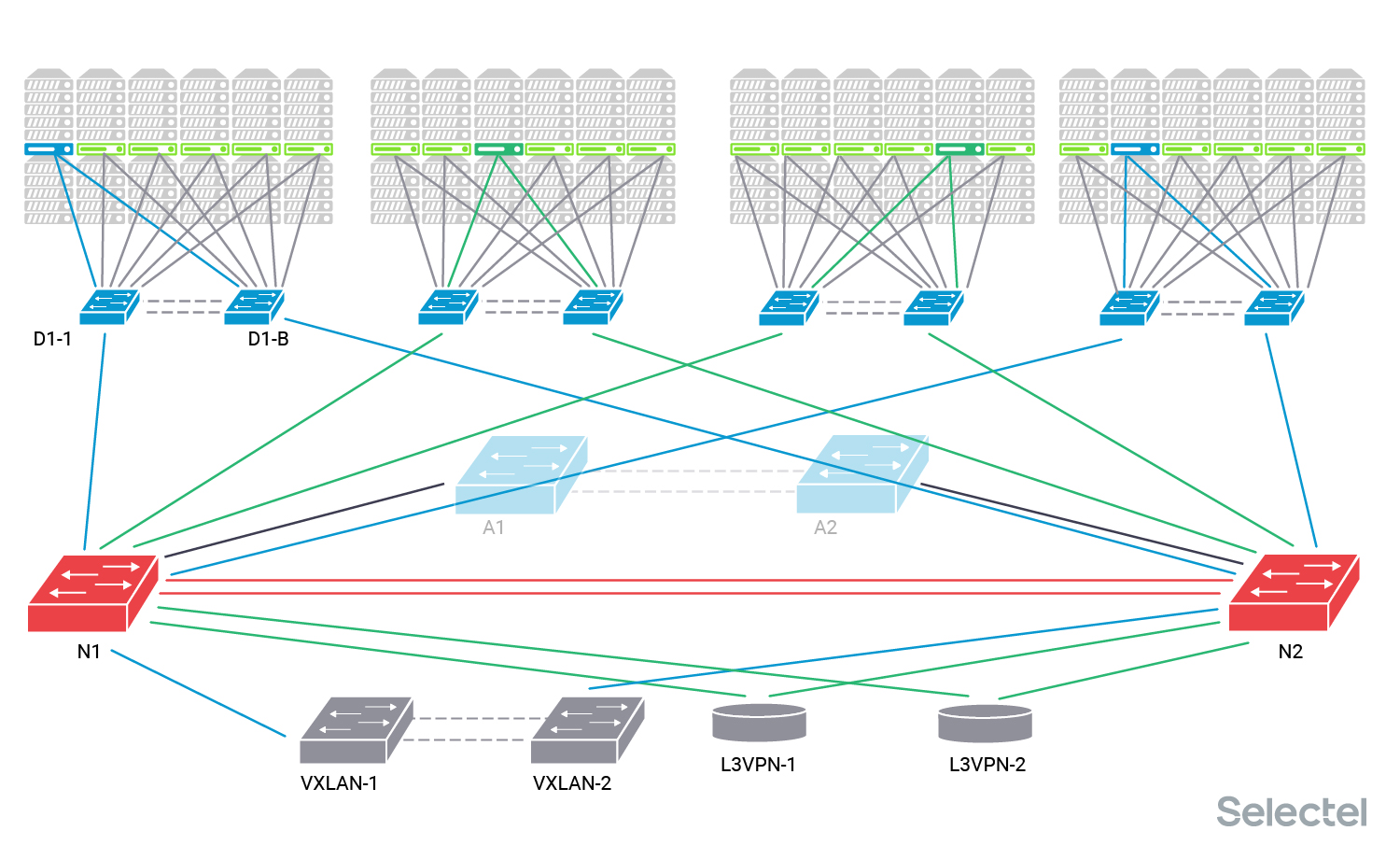
Эти коммутаторы являются коммутаторами агрегации локальной сети для каждого дата-центра. К ним подключаются непосредственно коммутаторы дистрибьюции (второй уровень агрегации), которые уже собирают в себе коммутаторы Top-of-Rack локальной сети в стойках с серверами.

Каждый сервер включен в один или два коммутатора доступа. Коммутаторы доступа подключены к паре коммутаторов дистрибьюции (два коммутатора дистрибьюции и два физических линка от коммутатора доступа к разным коммутаторам дистрибьюции используются для резервирования).
Каждый сервер может быть использован своим клиентом, так что клиенту выделяется отдельный VLAN. Этот же VLAN потом прописывается на другой сервер этого клиента в любой стойке. Дата-центр состоит из нескольких таких рядов (POD’ов), для каждого ряда стоек есть свои коммутаторы дистрибьюции. Потом эти коммутаторы дистрибьюции подключаются в коммутаторы агрегации.

Клиенты могут заказать сервер в любом ряду, заранее предсказать, что сервер будет выделен или установлен в какой-то конкретный ряд в какую-то конкретную стойку, нельзя, поэтому на коммутаторах агрегации присутствует около 2500 VLAN в каждом дата-центре.
Оборудование для DCI (Data-Center Interconnect) подключается к коммутаторам агрегации. Оно может предназначаться для L2-связности (пара коммутаторов, образующая VXLAN-туннель в другой дата-центр), так и для L3-связности (два MPLS-маршрутизатора).
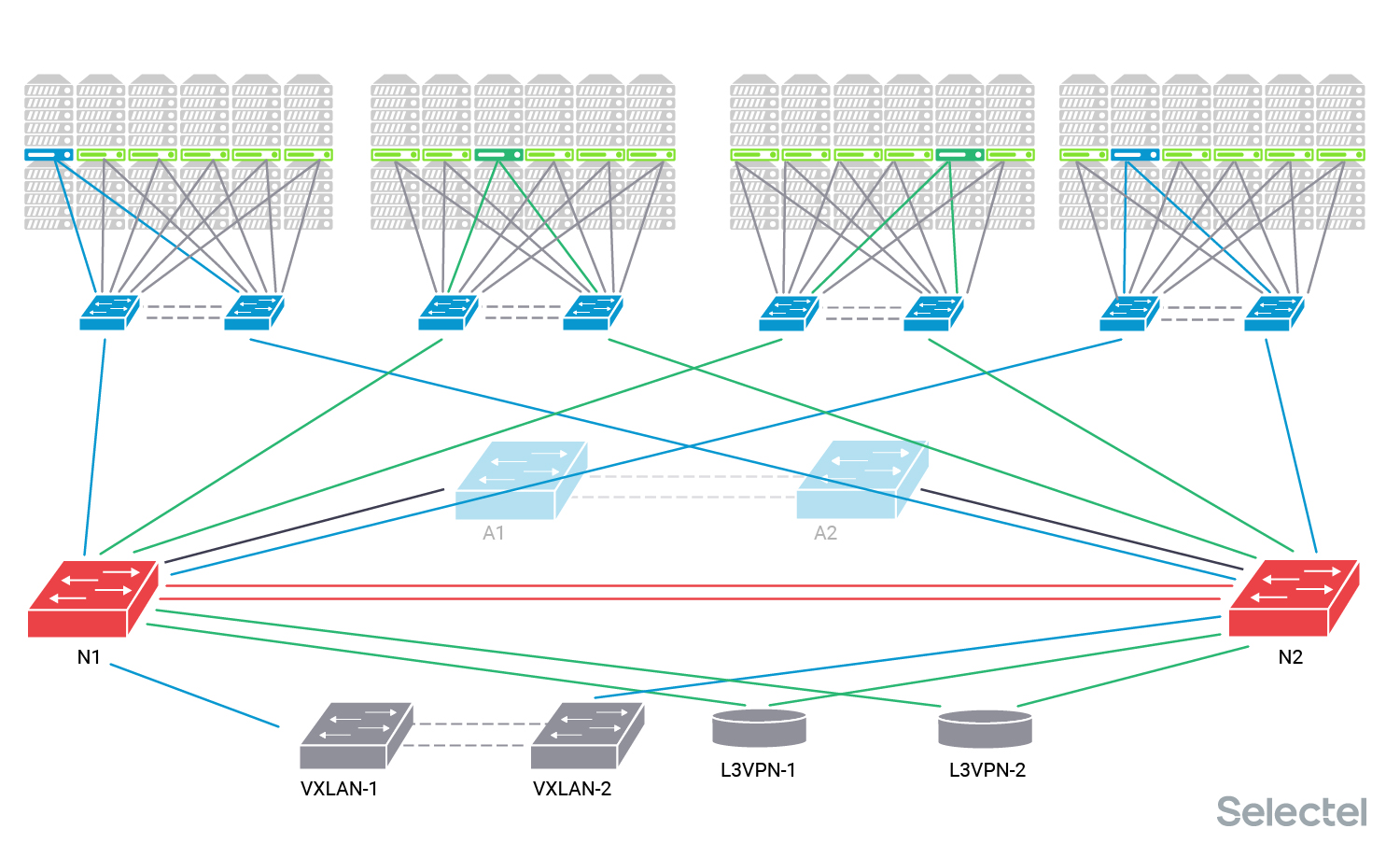
Как я уже писал, для унификации процессов автоматизации конфигурации услуг на оборудовании в одном дата-центре потребовалось заменить центральные коммутаторы агрегации. Мы установили новые коммутаторы рядом с существующими, объединили их в MLAG пару и стали готовиться к работам. Их сразу соединили с существующими коммутаторами агрегации, так что у них стал общий L2-домен по всем клиентским VLAN.
Детали схемы
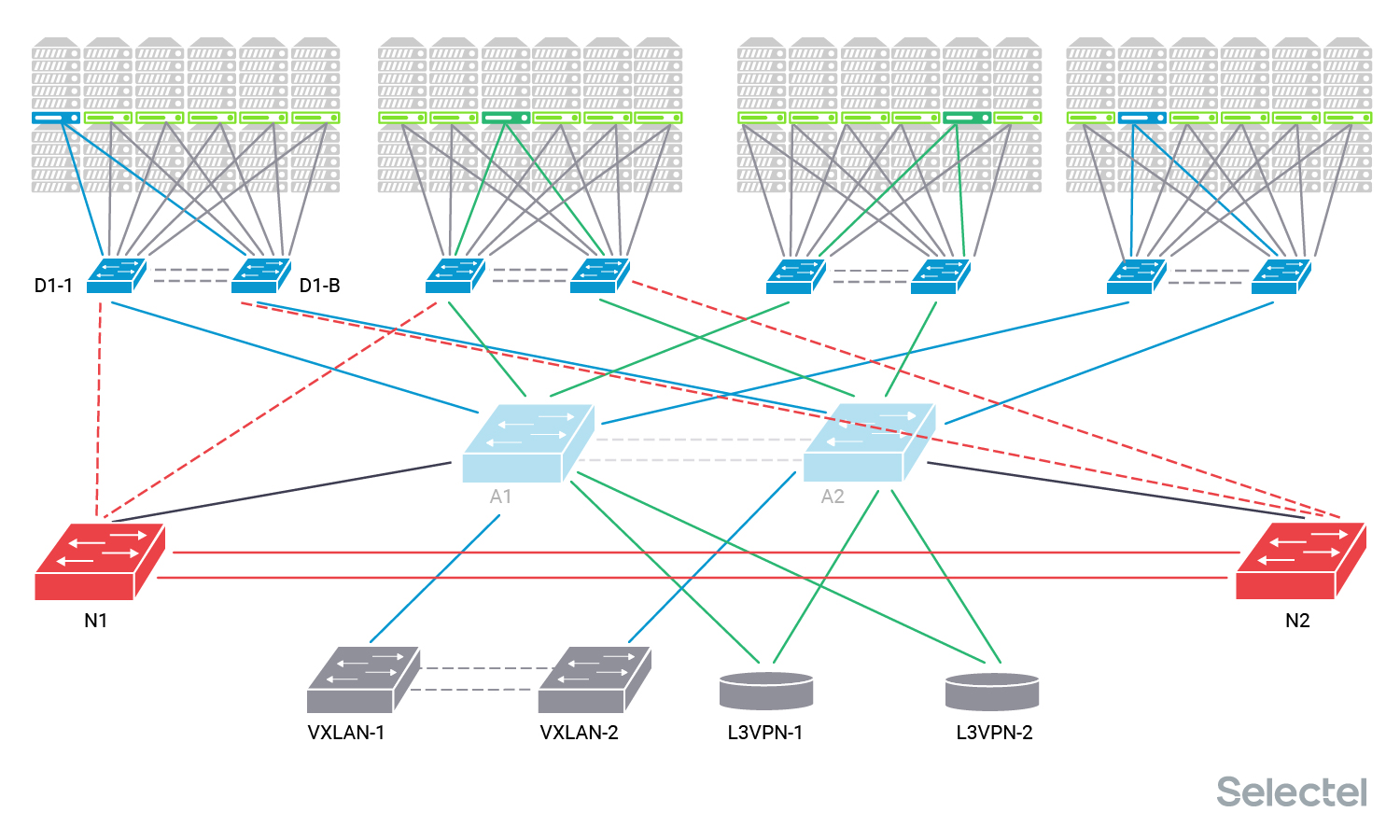
Для конкретики назовём старые коммутаторы агрегации А1 и А2, новые — N1 и N2. Представим, что в POD 1 и POD 4 размещены серверы одного клиента С1, VLAN клиента обозначен синим цветом. Этот клиент использует услугу L2-связности с другим дата-центром, поэтому его VLAN подан на пару коммутаторов VXLAN.
Клиент С2 размещает серверы в POD 2 и POD 3, VLAN клиента обозначаем темно-зелёным цветом. Этот клиент тоже использует услугу связности с другим дата-центром, но L3, так что его VLAN подан на пару L3VPN маршрутизаторов.

Клиентские VLAN нам нужны для понимания, на каких этапах работ по замене что происходит, где появляется перерыв связи, и какая может быть его продолжительность. Протокол STP в этой схеме не используется, так как ширина дерева для него в таком случае получается большой, и сходимость протокола вырастает в геометрической прогрессии от количества устройств и линков между ними.
Все устройства, соединённые двойными линками, образуют стек, MLAG-пару или VCS- Ethernet-фабрику. Для пары L3VPN маршрутизаторов подобные технологии не используются, так как нет необходимости резервирования L2, достаточно того, чтобы у них была L2 связность друг с другом через коммутаторы агрегации.
Варианты реализации
При анализе вариантов дальнейших событий мы поняли, что есть несколько способов провести эти работы. От глобального перерыва на всей локальной сети, до небольших буквально 1-2 секундных перерывов в частях сети.
Сеть, стоять! Коммутаторы, заменяйтесь!
Самый простой способ — это, конечно, объявить глобальный перерыв связи по всем POD и по всем услугам DCI и переключить все линки из коммутаторов А в коммутаторы N.
Помимо перерыва, время которого мы не можем гарантированно предсказать (да, мы знаем количество линков, но не знаем, сколько раз что-то пойдет не так — от заломанного патч-корда или поврежденного коннектора до неисправности порта или трансивера), мы еще не можем заранее предугадать, хватит ли длины патч-кордов, DAC, AOC, подключенных в старые коммутаторы А, чтобы дотянуть их до, хоть и стоящих рядом, но все равно чуть-чуть в стороне, новых коммутаторов N, и заработают ли те же самые трансиверы/DAC/AOC из коммутаторов Brocade в коммутаторах Arista.
И всё это в условиях жесткого прессинга со стороны клиентов и техподдержки («Наташ, вставай! Наташ, там всё не работает! Наташ, мы уже написали в техподдержку, честно-честно! Наташ, там уже всё уронили! Наташ, а сколько ещё не будет работать? Наташ, а когда заработает?!»). Даже несмотря на заранее объявленный перерыв и сделанное оповещение по клиентам, наплыв обращений в такое время гарантирован.
Стой, 1-2-3-4!
А если не объявлять глобальный перерыв, а объявить серию маленьких перерывов связи по POD и услугам DCI. В первый перерыв переключить в коммутаторы N только POD 1, во второй — через пару дней — POD 2, потом еще через пару дней POD 3, далее POD 4…[N], потом VXLAN-коммутаторы и потом L3VPN-маршрутизаторы.

При такой организации работ по переключению мы уменьшаем сложность единовременных работ и увеличиваем себе время на решение проблем, если что-то вдруг пошло не так. Связность POD 1 после переключения с другими POD и DCI не теряется. Но сами работы затягиваются надолго, на время этих работ в дата-центре требуется выделение инженера на физическое выполнение переключений, и во время работ (а такие работы выполняются, как правило, ночью, с 2 до 5 утра) требуется наличие онлайн сетевого инженера довольно высокой квалификации. Но зато мы получаем короткие перерывы связи, как правило, работы могут проводиться в интервале получаса с перерывом до 2 минут (на практике, зачастую 20-30 секунд при ожидаемом поведении оборудования).
В приведённом примере клиента С1 или клиента С2 придется предупреждать о работах с перерывом связи как минимум три раза — первый раз для проведения работ по одному POD, в котором находится один его сервер, во второй раз — по второму, и в третий раз — при переключении оборудования для DCI услуг.
Переключение агрегированных каналов связи
Почему мы говорим про ожидаемое поведение оборудования, и как могут с минимизированием перерыва связи переключаться агрегированные каналы. Представим следующую картину:

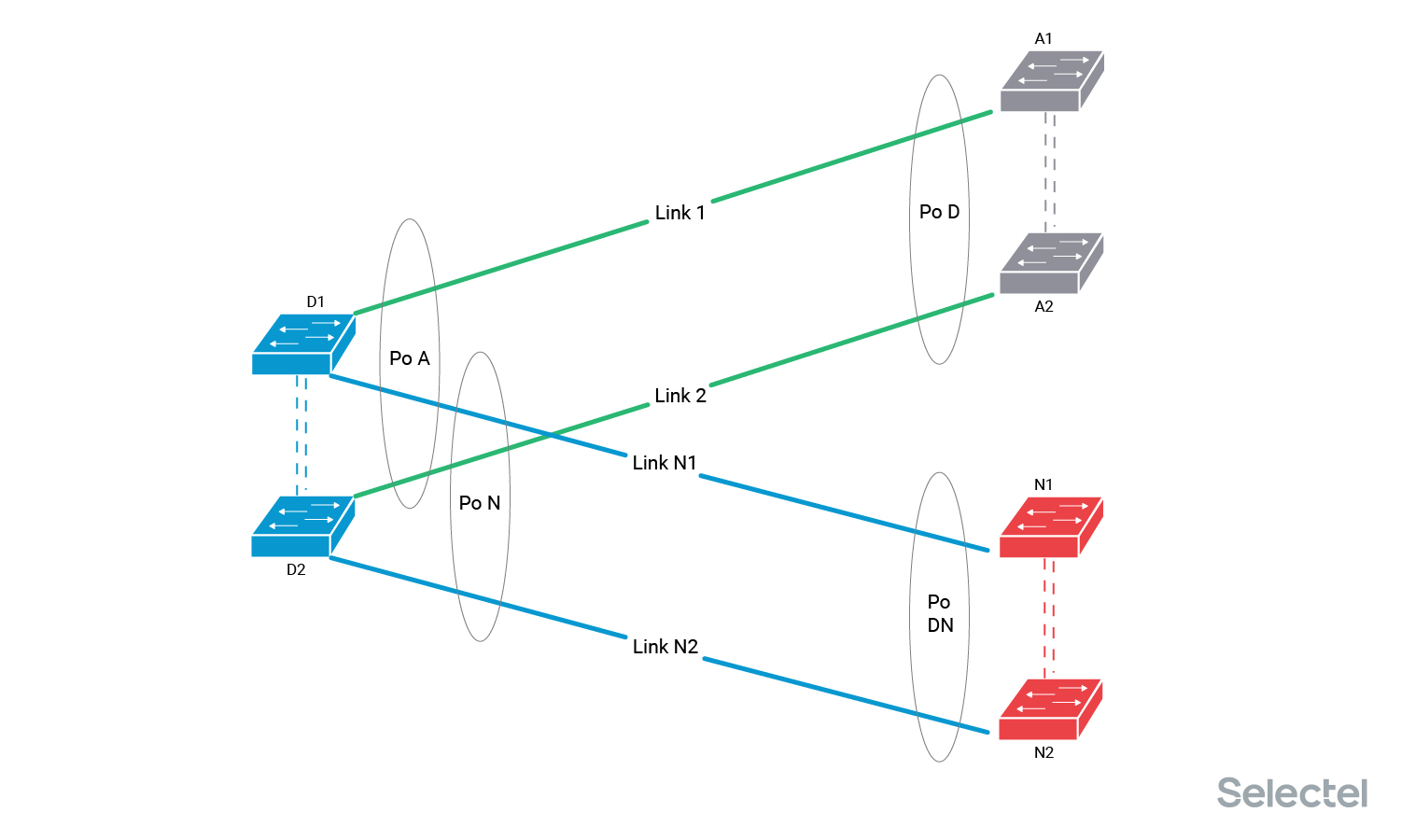
С одной стороны линка — коммутаторы дистрибьюции POD — D1 и D2, они образуют между собой MLAG-пару (стек, VCS-фабрику, vPC-пару), с другой стороны два линка — Link 1 и Link 2 — включены в MLAG-пару старых коммутаторов агрегации А. На стороне коммутаторов D сформирован агрегированный интерфейс с названием Port-channel A, на стороне коммутаторов агрегации А — агрегированный интерфейс с названием Port-channel D.
Агрегированные интерфейсы в своей работе используют LACP, то есть, коммутаторы с двух сторон регулярно обмениваются LACPDU-пакетами по обоим линкам, чтобы убедиться, что линки:
- рабочие;
- включены в одну пару устройств на удалённой стороне.
При обмене пакетами в пакете передается значение system-id, обозначающее устройство, куда эти линки включены. Для MLAG-пары (стека, фабрики и т. п.) значение system-id для устройств, образующих агрегированный интерфейс, одинаково. Коммутатор D1 отправляет в Link 1 значение system-id D, и коммутатор D2 отправляет в Link 2 значение system-id D.
Коммутаторы А1 и А2 анализируют LACPDU-пакеты, полученные по одному интерфейсу Po D, и проверяют совпадение system-id в них. Если полученный по какому-то линку system-id вдруг будет отличаться от текущего рабочего значения, то этот линк выводится из состава агрегированного интерфейса до исправления ситуации. Сейчас у нас на стороне коммутаторов D текущее значение system-id от LACP-партнёра — A, а на стороне коммутаторов А — текущее значение system-id от LACP-партнёра — D.
При необходимости переключения агрегированного интерфейса мы можем поступить двумя различными способами:
Способ 1 — Простой
Отключить оба линка из коммутаторов A. При этом агрегированный канал не работает.
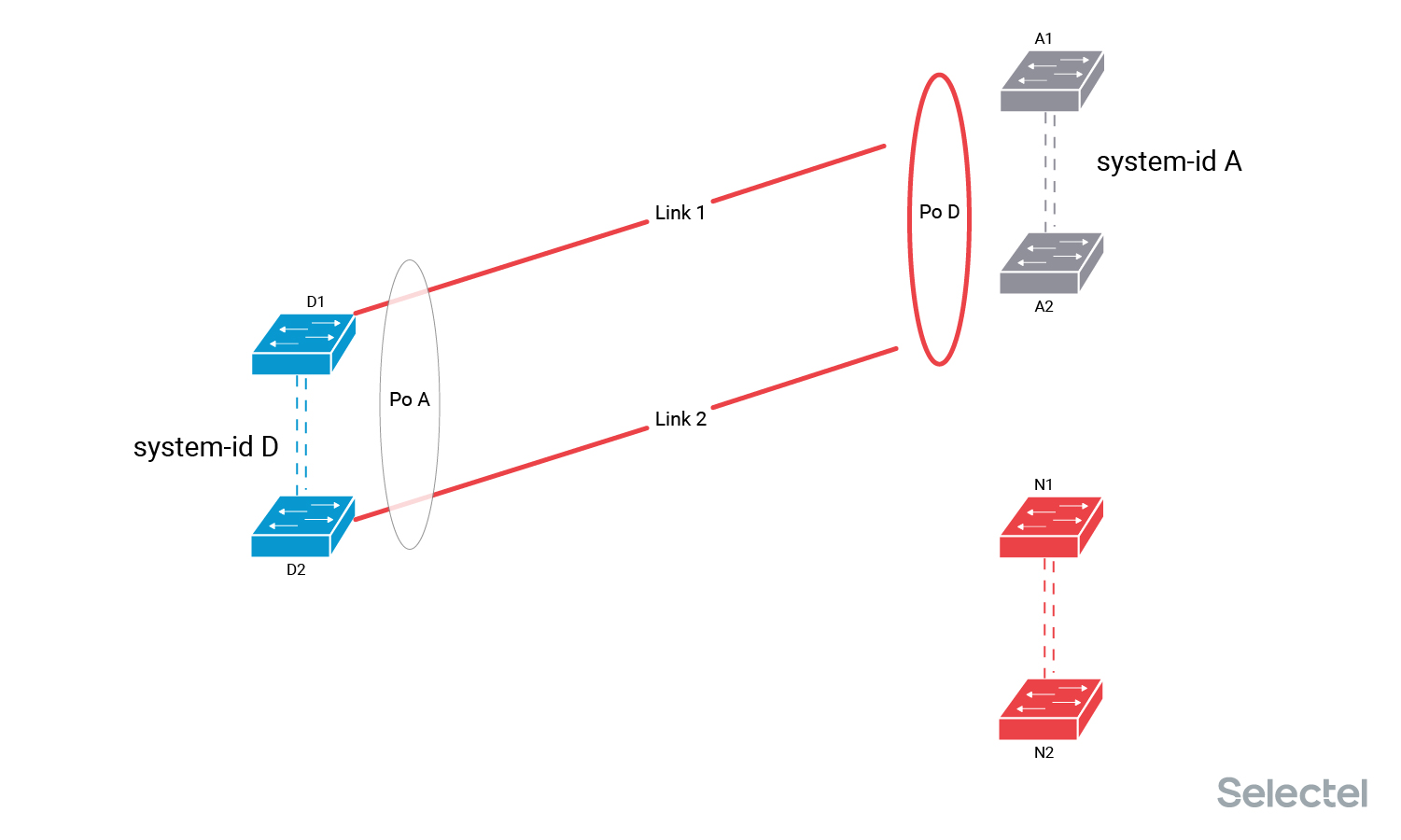
Включить оба линка по очереди в коммутаторы N, тогда заново произойдет согласование параметров работы LACP, формирование интерфейса Po D на коммутаторах N и передача на линках значения system-id N.
Включить оба линка по очереди в коммутаторы N, тогда заново произойдет согласование параметров работы LACP, формирование интерфейса Po D на коммутаторах N и передача на линках значения system-id N.
Способ 2 — Минимизация перерыва
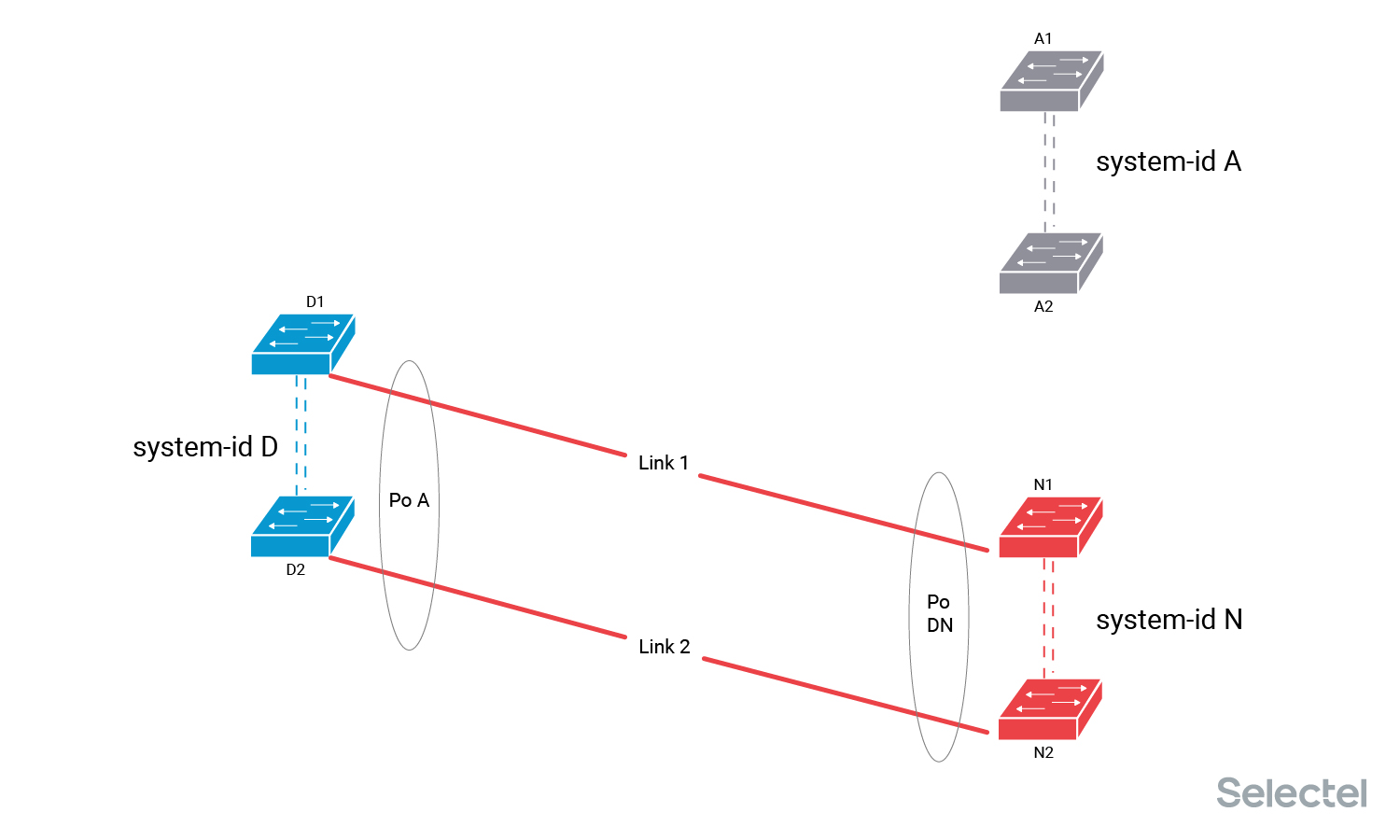
Отключить из коммутатора А2 линк Link 2. При этом трафик между А и D продолжит передаваться просто по одному из линков, который останется в составе агрегированного интерфейса.

Подключить Link 2 в коммутатор N2. На коммутаторе N уже настроен агрегированный интерфейс Po DN, и коммутатор N2 начнет передавать в LACPDU system-id N. На этом этапе мы можем уже проверить, что коммутатор N2 корректно работает с трансивером, использующимся для Link 2, что порт подключения перешёл в состояние Up, и что при передаче LACPDU не возникает ошибок на порту подключения.
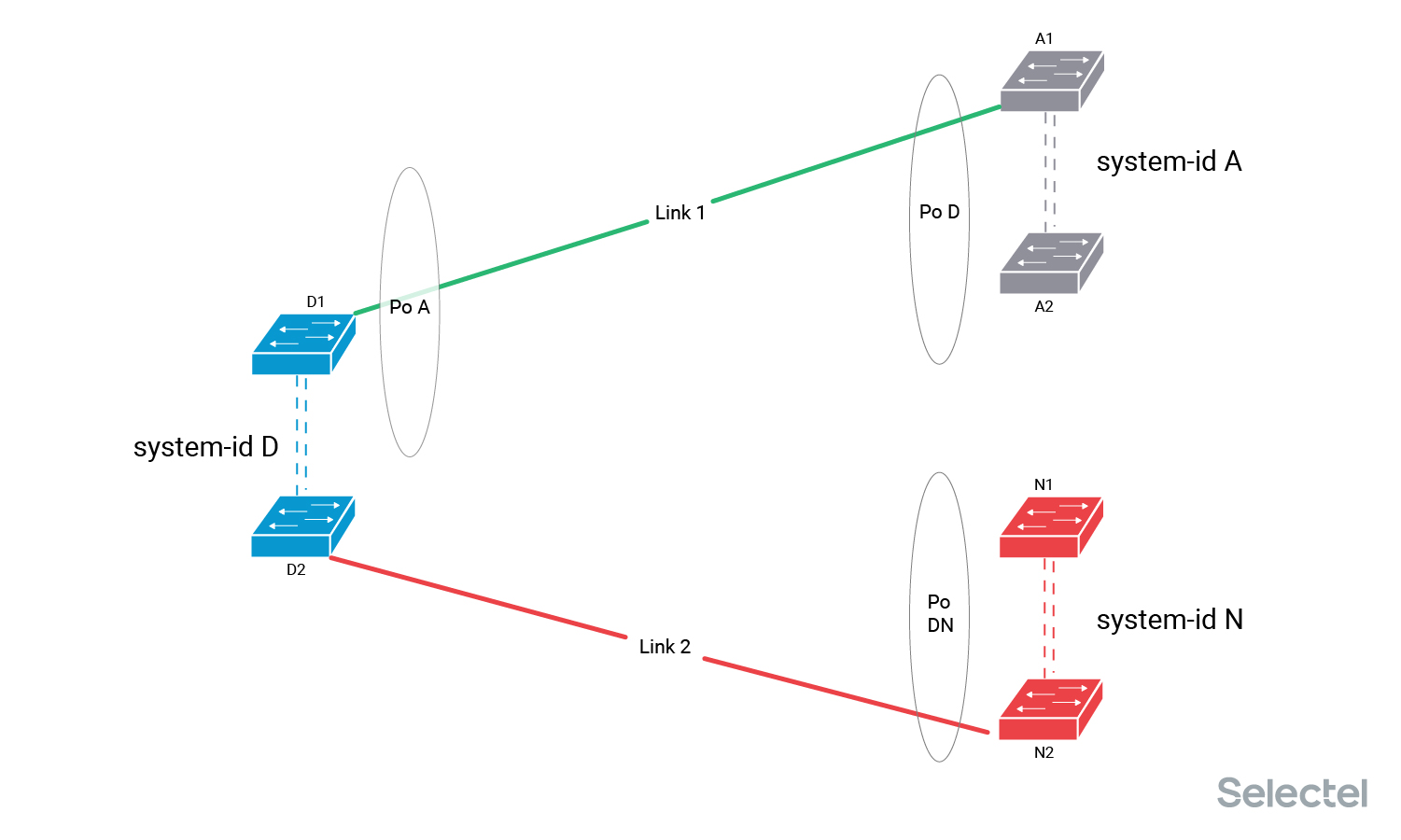
Но тот факт, что коммутатор D2 для агрегированного интерфейса Po A со стороны Link 2 получает значение system-id N, отличное от текущего рабочего значения system-id A, не позволяет коммутаторам D ввести Link 2 в состав агрегированного интерфейса Po A. Коммутатор N не может ввести Link 2 в работу, так как он не получает подтверждения о работоспособности от LACP-партнёра коммутатора D2. Трафик в итоге по Link 2 не передается.
А теперь мы выключаем Link 1 из коммутатора A1, тем самым лишая коммутаторы А и D работающего агрегированного интерфейса. Таким образом, на стороне коммутатора D пропадает текущее рабочее значение system-id для интерфейса Po A.
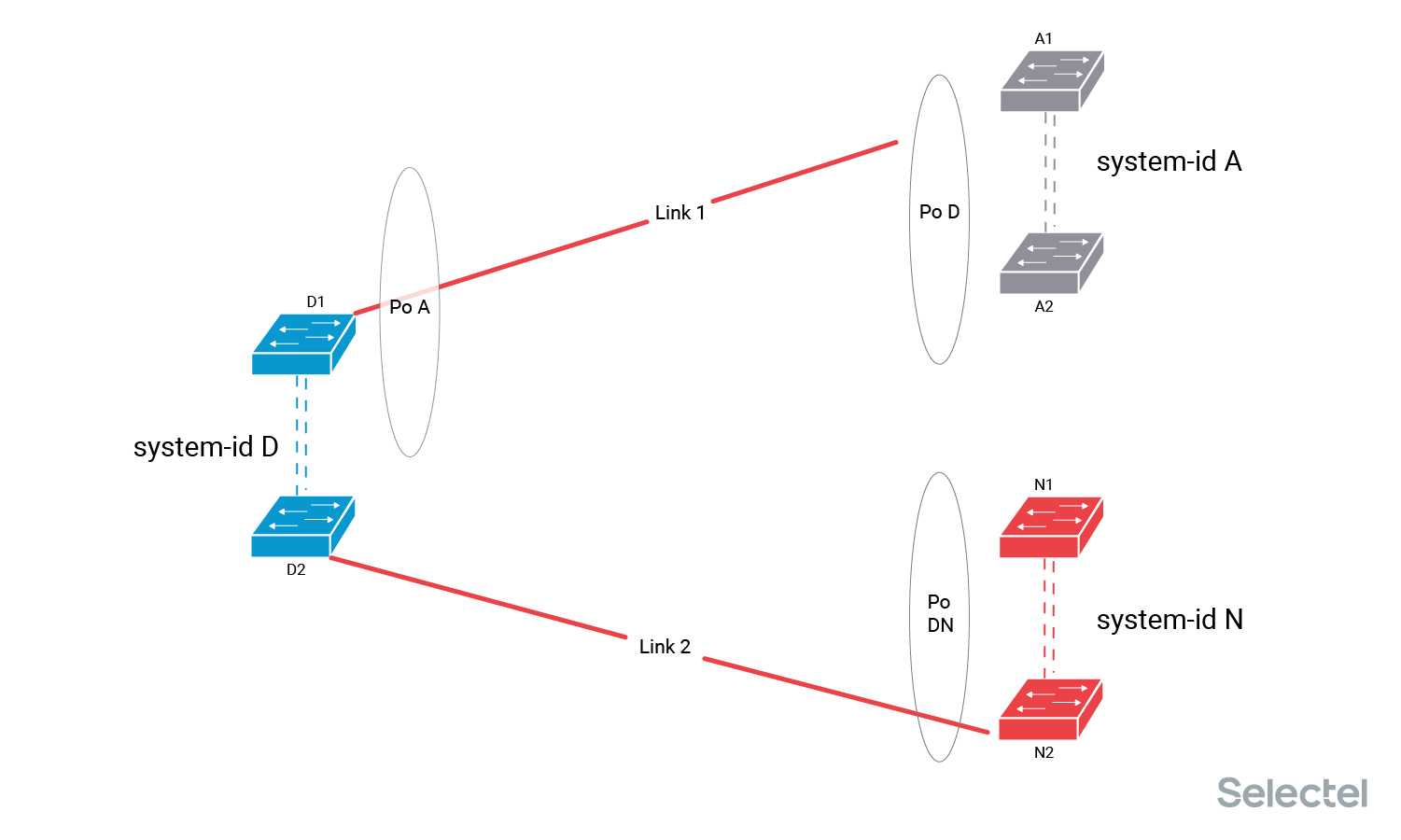
Это позволяет коммутаторам D и N договориться об обмене system-id A-N на интерфейсах Po A и Po DN, так что трафик начинает передаваться по линку Link 2. Перерыв в данном случае составляет, на практике, до 2 секунд.
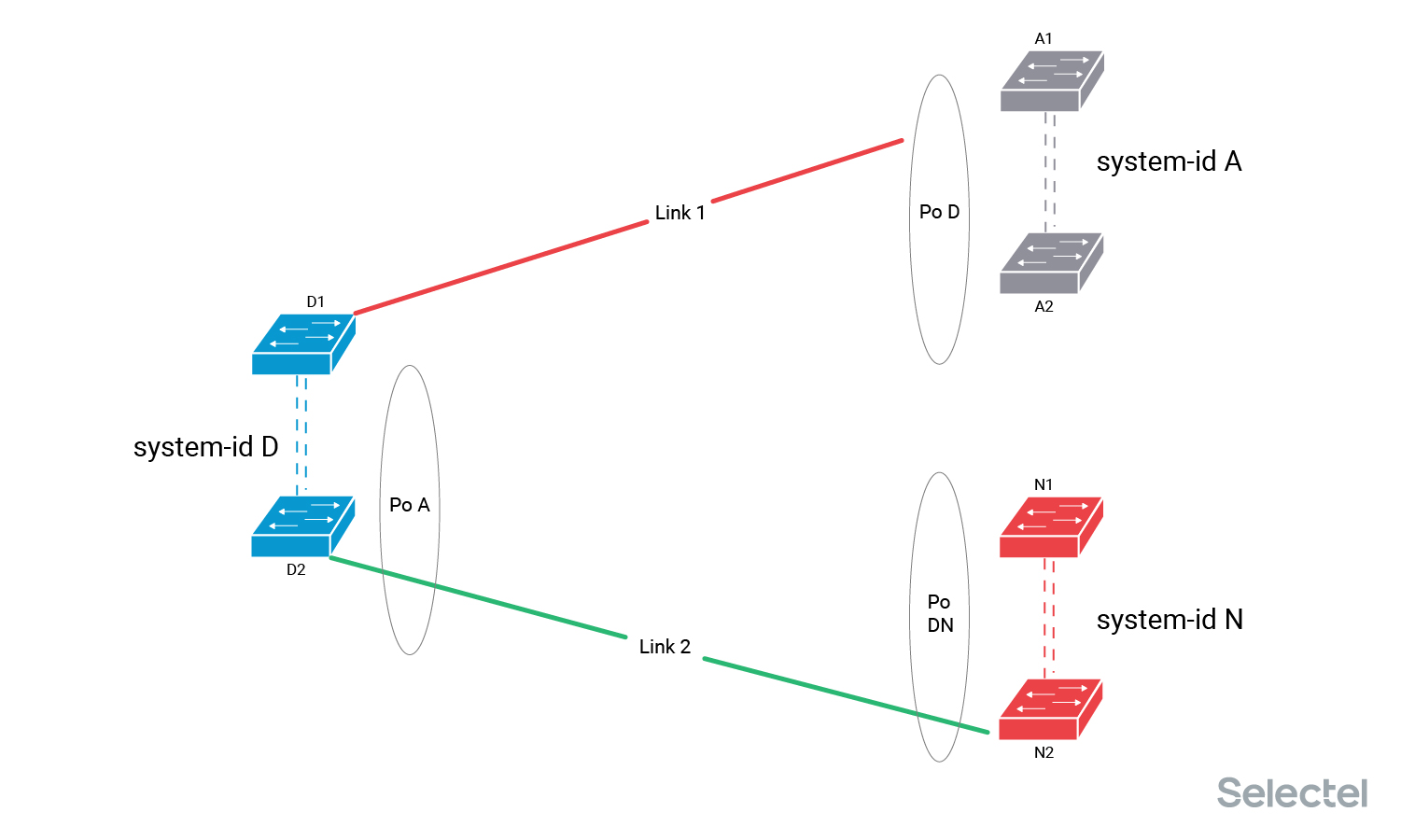
А теперь мы спокойно переключаем Link 1 в коммутатор N1, восстанавливая емкость и уровень резервирования интерфейсов Po A и Po DN. Так как при подключении этого линка не изменяется текущее значение system-id ни с одной стороны, то перерыва не происходит.
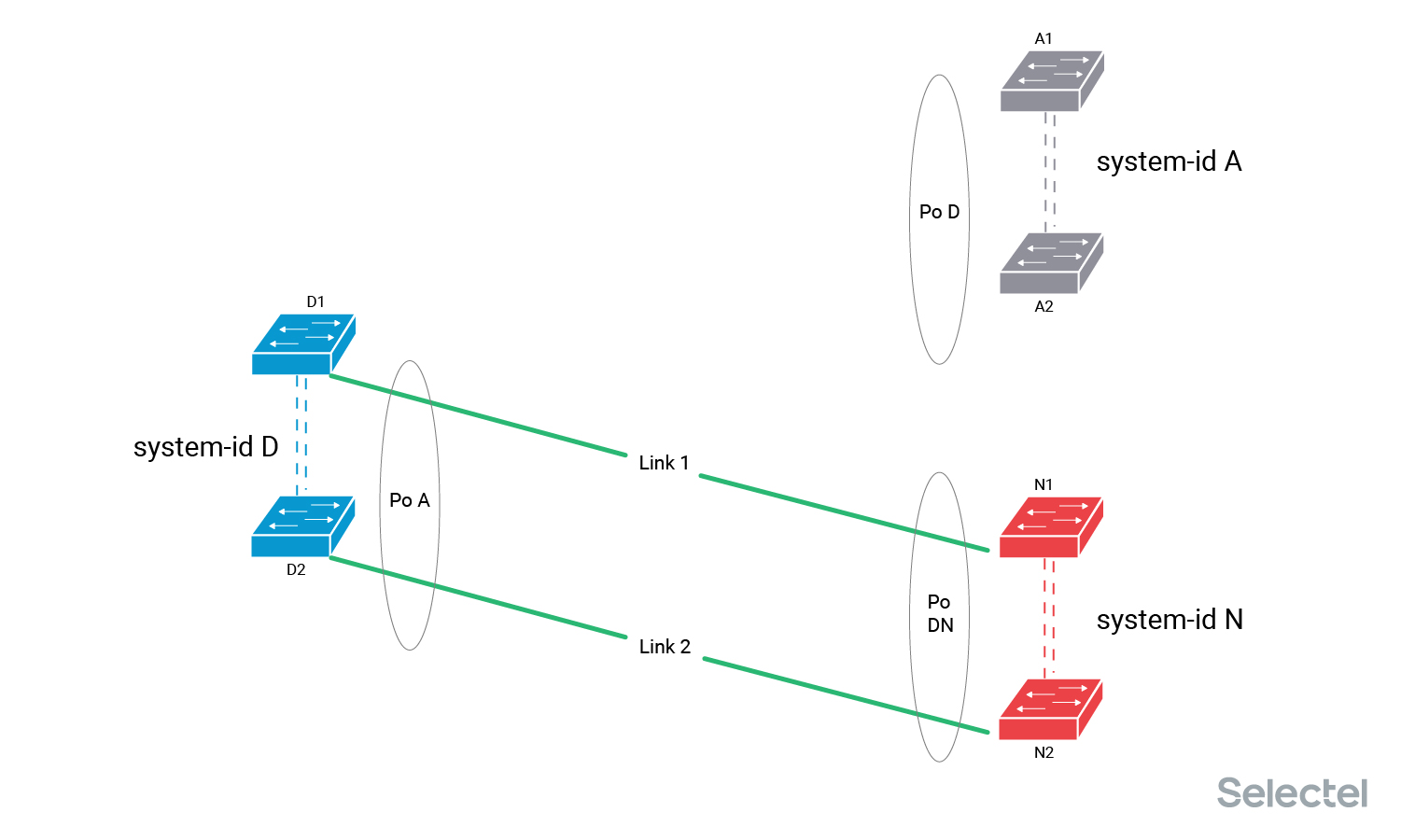
Подключить Link 2 в коммутатор N2. На коммутаторе N уже настроен агрегированный интерфейс Po DN, и коммутатор N2 начнет передавать в LACPDU system-id N. На этом этапе мы можем уже проверить, что коммутатор N2 корректно работает с трансивером, использующимся для Link 2, что порт подключения перешёл в состояние Up, и что при передаче LACPDU не возникает ошибок на порту подключения.
Но тот факт, что коммутатор D2 для агрегированного интерфейса Po A со стороны Link 2 получает значение system-id N, отличное от текущего рабочего значения system-id A, не позволяет коммутаторам D ввести Link 2 в состав агрегированного интерфейса Po A. Коммутатор N не может ввести Link 2 в работу, так как он не получает подтверждения о работоспособности от LACP-партнёра коммутатора D2. Трафик в итоге по Link 2 не передается.
А теперь мы выключаем Link 1 из коммутатора A1, тем самым лишая коммутаторы А и D работающего агрегированного интерфейса. Таким образом, на стороне коммутатора D пропадает текущее рабочее значение system-id для интерфейса Po A.
Это позволяет коммутаторам D и N договориться об обмене system-id A-N на интерфейсах Po A и Po DN, так что трафик начинает передаваться по линку Link 2. Перерыв в данном случае составляет, на практике, до 2 секунд.
А теперь мы спокойно переключаем Link 1 в коммутатор N1, восстанавливая емкость и уровень резервирования интерфейсов Po A и Po DN. Так как при подключении этого линка не изменяется текущее значение system-id ни с одной стороны, то перерыва не происходит.
Дополнительные линки
Но переключение можно выполнить без присутствия инженера в момент переключения. Для этого нам потребуется заранее проложить дополнительные линки между коммутаторами дистрибьюции D и новыми коммутаторами агрегации N.
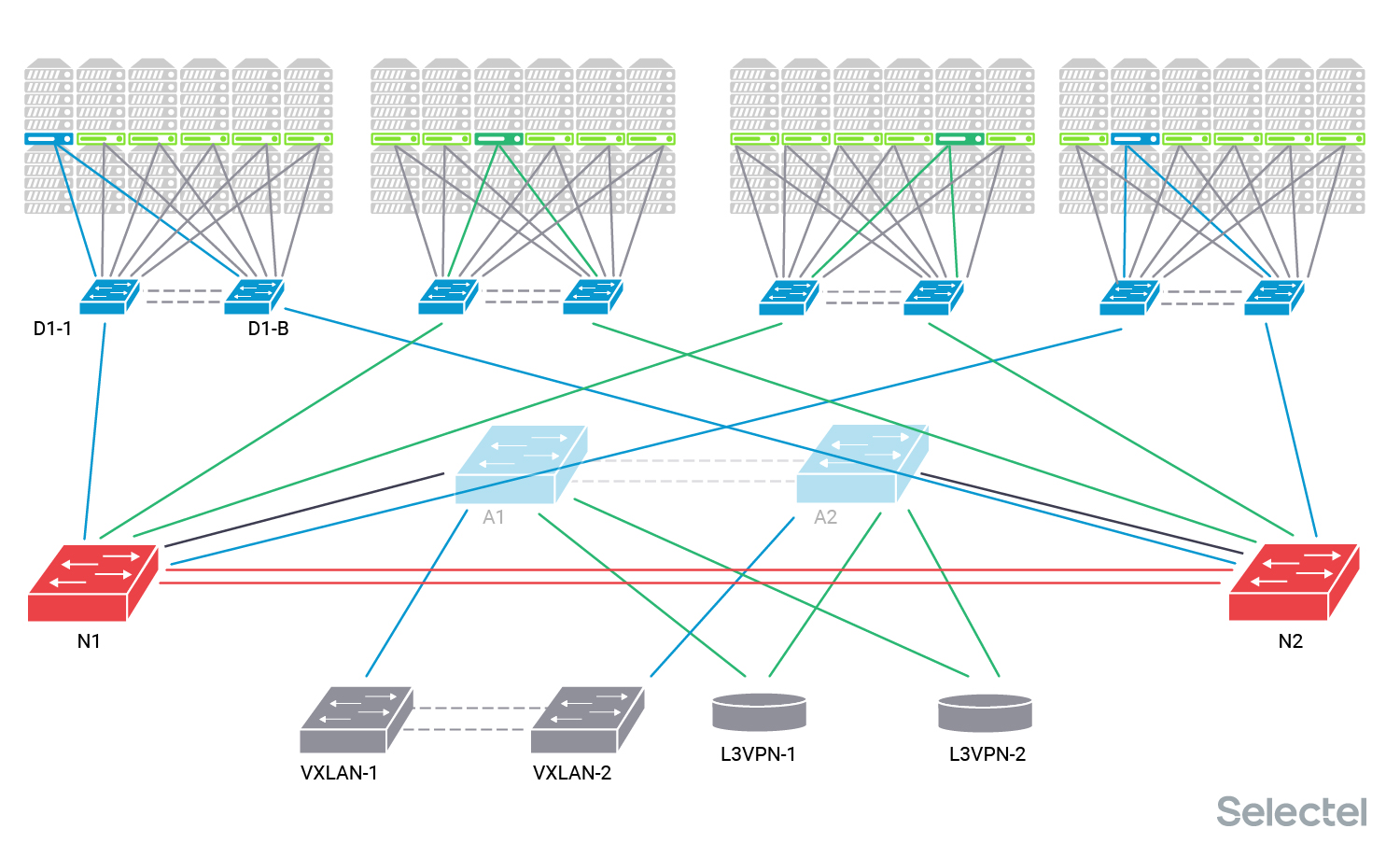
Мы прокладываем новые линки между коммутаторами агрегации N и коммутаторами дистрибьюции всех POD. Это требует заказа и прокладки дополнительных патч-кордов, и установки дополнительных трансиверов как в N, так и в D. Мы можем это сделать, так как у нас в коммутаторах D каждого POD есть свободные порты (или мы их предварительно освобождаем). В итоге каждый POD физически подключен двумя линками к старым коммутаторам А и к новым коммутаторам N.
На коммутаторе D сформировано два агрегированных интерфейса — Po A с линками Link 1 и Link 2, и Po N — с линками Link N1 и Link N2. На этом этапе мы проверяем правильность подключения интерфейсов и линков, уровни оптических сигналов на обоих концах линков (посредством DDM-информации с коммутаторов), можем даже проверить работоспособность линка под нагрузкой или помониторить состояния оптических сигналов и температуры трансиверов в течение пары дней.
Трафик по-прежнему передается через интерфейс Po A, а интерфейс Po N стоит без трафика. Настройки на интерфейсах примерно такие:
Interface Port-channel A
Switchport mode trunk
Switchport allowed vlan C1, C2
Interface Port-channel N
Switchport mode trunk
Switchport allowed vlan noneКоммутаторы D, как правило, поддерживают сессионное изменение конфигурации, используются такие модели коммутаторов, которые имеют этот функционал. Так что изменение настроек интерфейсов Po A и Po N мы можем сделать в один приём:
Configure session
Interface Port-channel A
Switchport allowed vlan none
Interface Port-channel N
Switchport allowed vlan C1, C2
CommitТогда изменение конфигурации произойдет достаточно быстро, и перерыв составит, на практике, не больше 5 секунд.
Такой способ позволяет нам выполнить все подготовительные работы заранее, осуществить все необходимые проверки, согласовать работы с участниками процесса, детально спрогнозировать действия по производству работ, без полётов творчества, когда «всё пошло не так», и иметь под рукой план возврата к предыдущей конфигурации. Работы по этому плану производятся сетевым инженером без присутствия на месте инженера дата-центра, который физически осуществляет переключения.
Что ещё важно при таком способе переключений — все новые линки уже заранее поставлены на мониторинг. Ошибки, включение линков в агрегат, загрузка линков — вся необходимая информация уже в системе мониторинга, и это уже отрисовано на картах.
D-Day
POD
Мы выбрали наименее болезненный для клиентов и наименее склонный к вариантам «что-то пошло не так» путь переключений с дополнительными линками. Так мы за пару ночей переключили все POD на новые коммутаторы агрегации.
Но осталось переключить оборудование, обеспечивающее услуги DCI.
L2
В случае оборудования, обеспечивающего L2-связность, мы не смогли провести аналогичные работы с дополнительными линками. Причин у этого как минимум две:
- Отсутствие свободных портов нужной скорости на VXLAN-коммутаторах.
- Отсутствие функционала сессионного изменения конфигурации на VXLAN-коммутаторах.
Переключение линков «по одному» с перерывом только на время согласования новой пары system-id мы не стали производить, так как 100% уверенности в том, что процедура пройдет корректно, у нас не было, а тест в лаборатории показал, что в случае, если «что-то идёт не так», мы все равно получаем перерыв связи, и что самое страшное — не только для клиентов, имеющих L2-связность с другими дата-центрами, но и вообще для всех клиентов этого дата-центра.
Мы загодя провели агитационную работу по переходу с L2 каналов, поэтому количество клиентов, затрагиваемых работами на VXLAN-коммутаторах, было уже в несколько раз меньше, чем год назад. В итоге мы решились на перерыв связи по услуге L2-связности при условии, что мы сохраняем нормальную работу услуг локальной сети в одном дата-центре. К тому же SLA на данную услугу предусматривает возможность проведения плановых работ с перерывом.
L3
Почему мы рекомендовали всем перейти на использование L3VPN при организации услуг DCI? Одна из причин — это возможность проведения работ на одном из маршрутизаторов, предоставляющих эту услугу, просто со снижением уровня резервирования до N+0, без перерыва связи.
Рассмотрим схему предоставления услуги более пристально. В этой услуге L2 сегмент идет от клиентских серверов только до L3VPN маршрутизаторов Selectel. На маршрутизаторах терминируется клиентская сеть.
Каждый сервер клиента, например, S2 и S3 в приведенной схеме, имеют свои приватные IP-адреса — 10.0.0.2/24 у сервера S2 и 10.0.0.3/24 у сервера S3. Адреса 10.0.0.252/24 и 10.0.0.253/24 назначены со стороны Selectel на маршрутизаторы L3VPN-1 и L3VPN-2, соответственно. IP-адрес 10.0.0.254/24 является VRRP VIP адресом на маршрутизаторах Selectel.
Более подробно про услугу L3VPN можно прочитать в нашем блоге.
До момента переключения всё выглядело примерно, как на схеме:
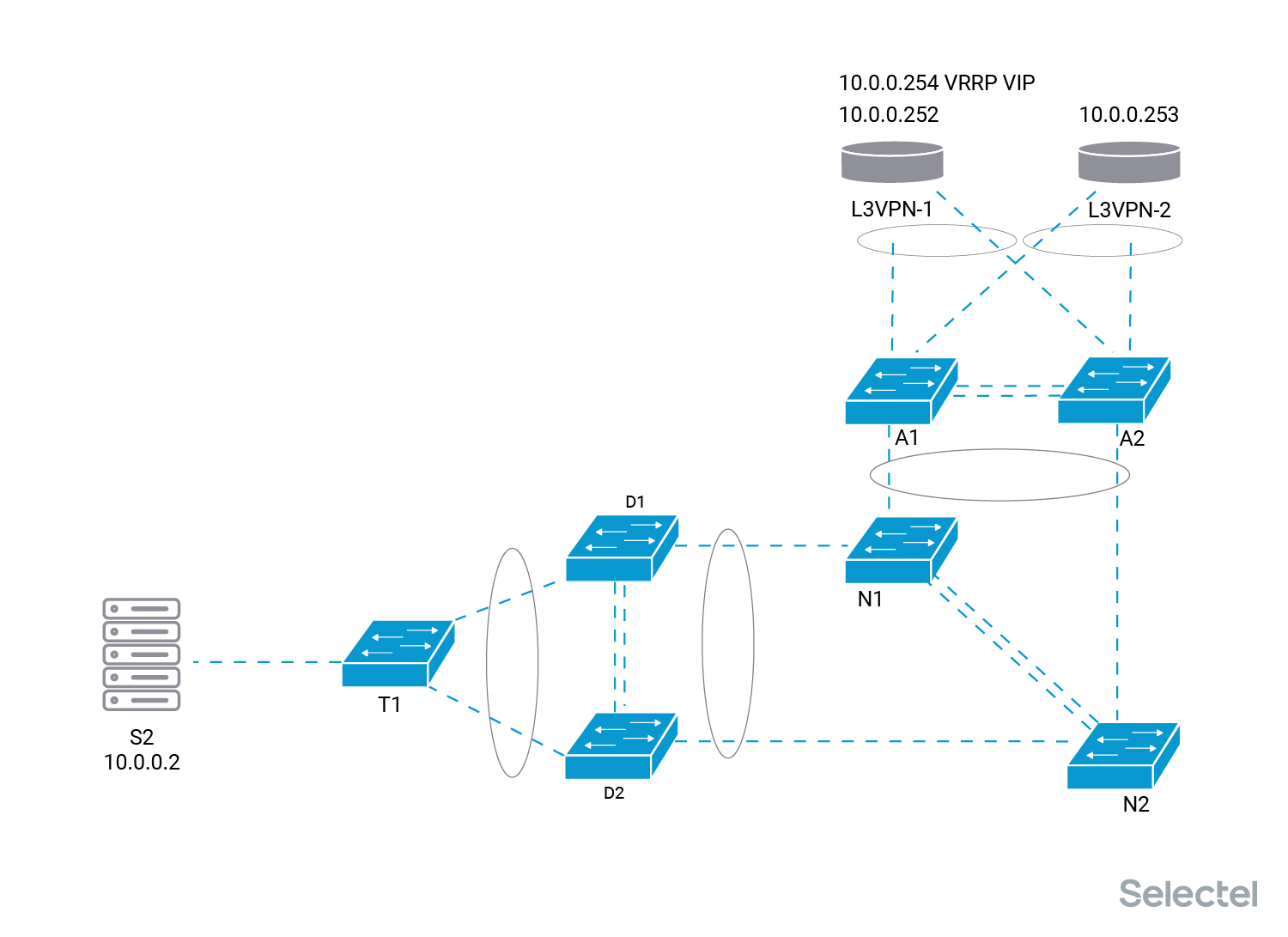
Два маршрутизатора L3VPN-1 и L3VPN-2 были подключены к старому коммутатору агрегации А. Мастером для VRRP VIP адреса 10.0.0.254 является маршрутизатор L3VPN-1. У него выставлен приоритет на данный адрес выше, чем у маршрутизатора L3VPN-2.
unit 1006 {
description C2;
vlan-id 1006;
family inet {
address 10.0.0.252/24 {
vrrp-group 1 {
priority 200;
virtual-address 10.100.0.254;
preempt {
hold-time 120;
}
accept-data;
}
}
}
}Сервер S2 для связи с серверами в других локациях использует шлюз 10.0.0.254. Таким образом, отключение от сети маршрутизатора L3VPN-2 (естественно, при предварительном его отключении из MPLS-домена) не влияет на связность серверов клиента. В этот момент просто снижается уровень резервирования схемы.
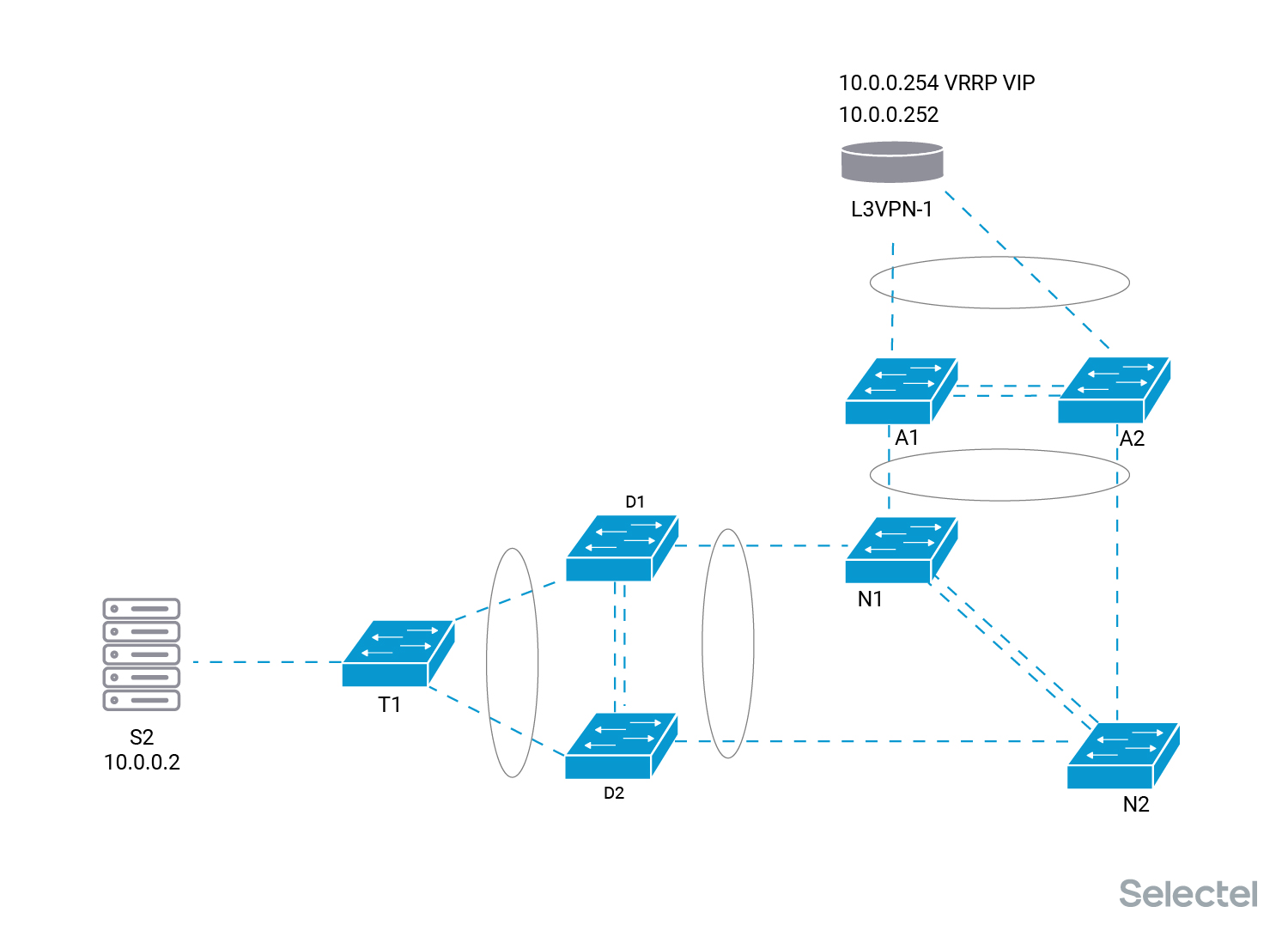
После этого мы можем спокойно переподключать маршрутизатор L3VPN-2 к паре коммутаторов N. Проложить линки, поменять трансиверы. Логические интерфейсы маршрутизатора, от которых зависит работа клиентских услуг, до момента подтверждения, что всё функционирует как надо, являются выключенными.
После проверок линков, трансиверов, уровней сигналов, уровней ошибок на интерфейсах, маршрутизатор включается в работу, но уже подключенным к новой паре коммутаторов.
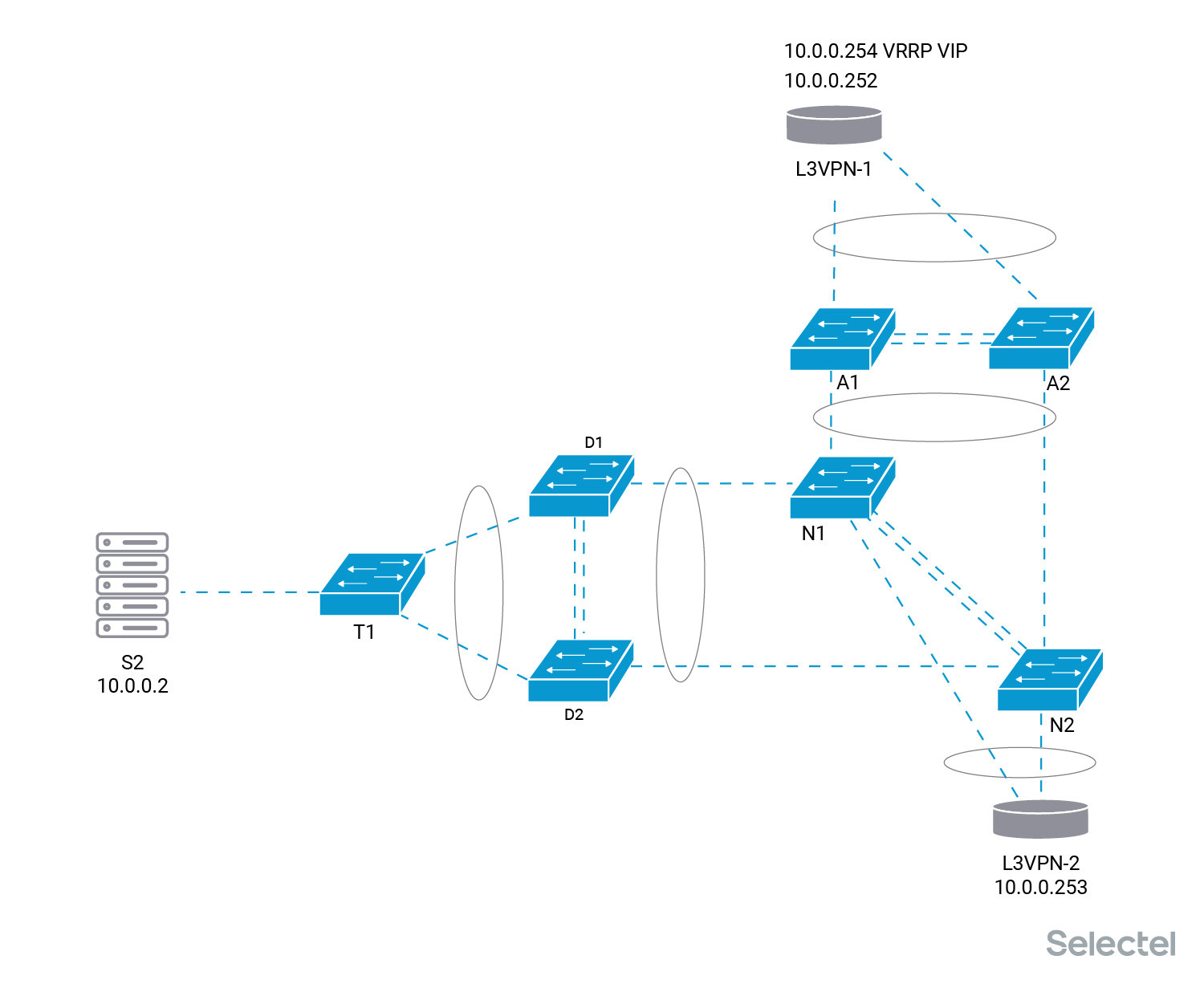
Дальше мы снижаем VRRP-приоритет у маршрутизатора L3VPN-1, и VIP адрес 10.0.0.254 перемещается на маршрутизатор L3VPN-2. Эти работы также производятся без перерыва связи.
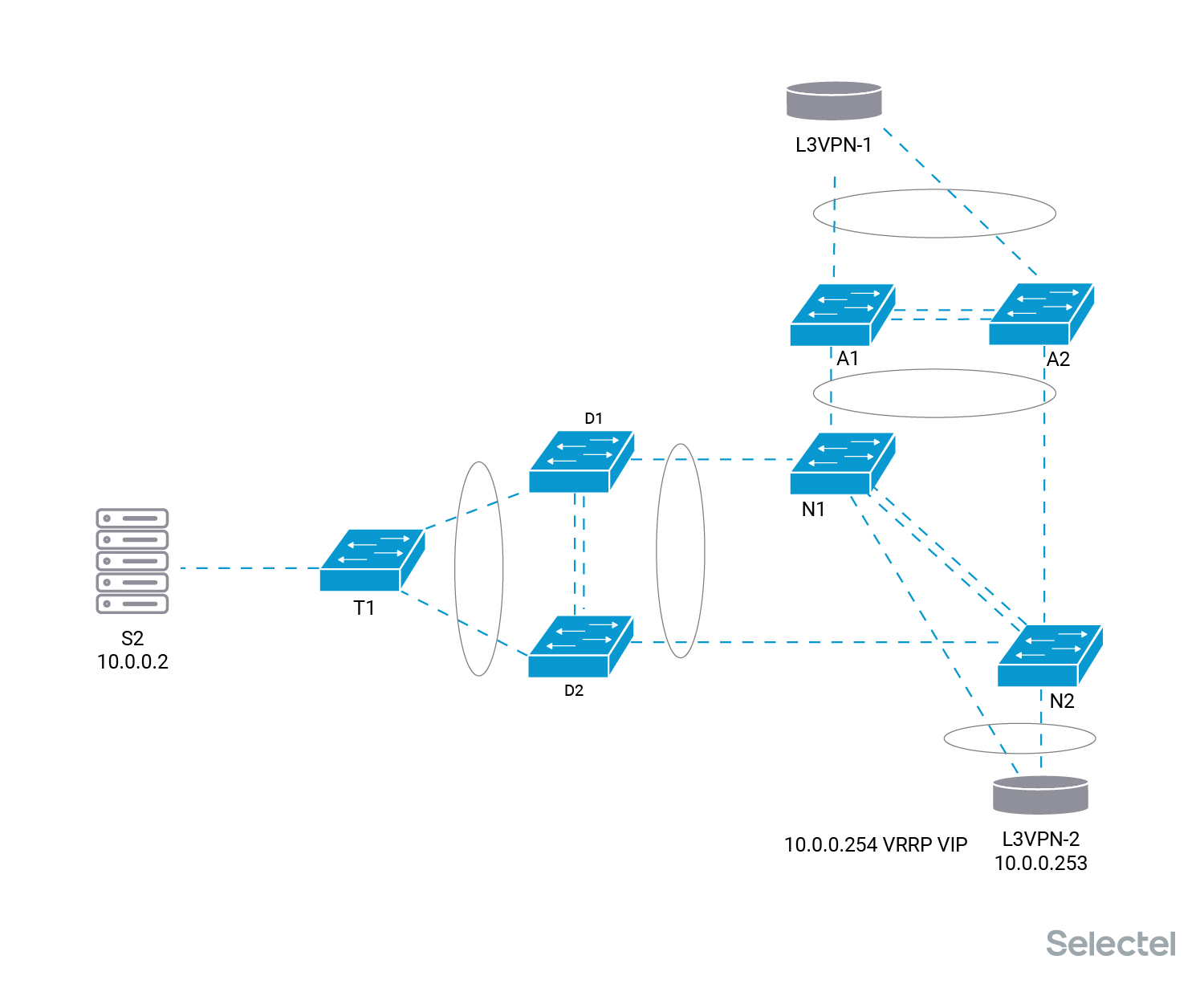
Перенос VIP адреса 10.0.0.254 на маршрутизатор L3VPN-2 позволяет отключить маршрутизатор L3VPN-1 без перерыва связи для клиента и подключить его уже к новой паре коммутаторов агрегации N.
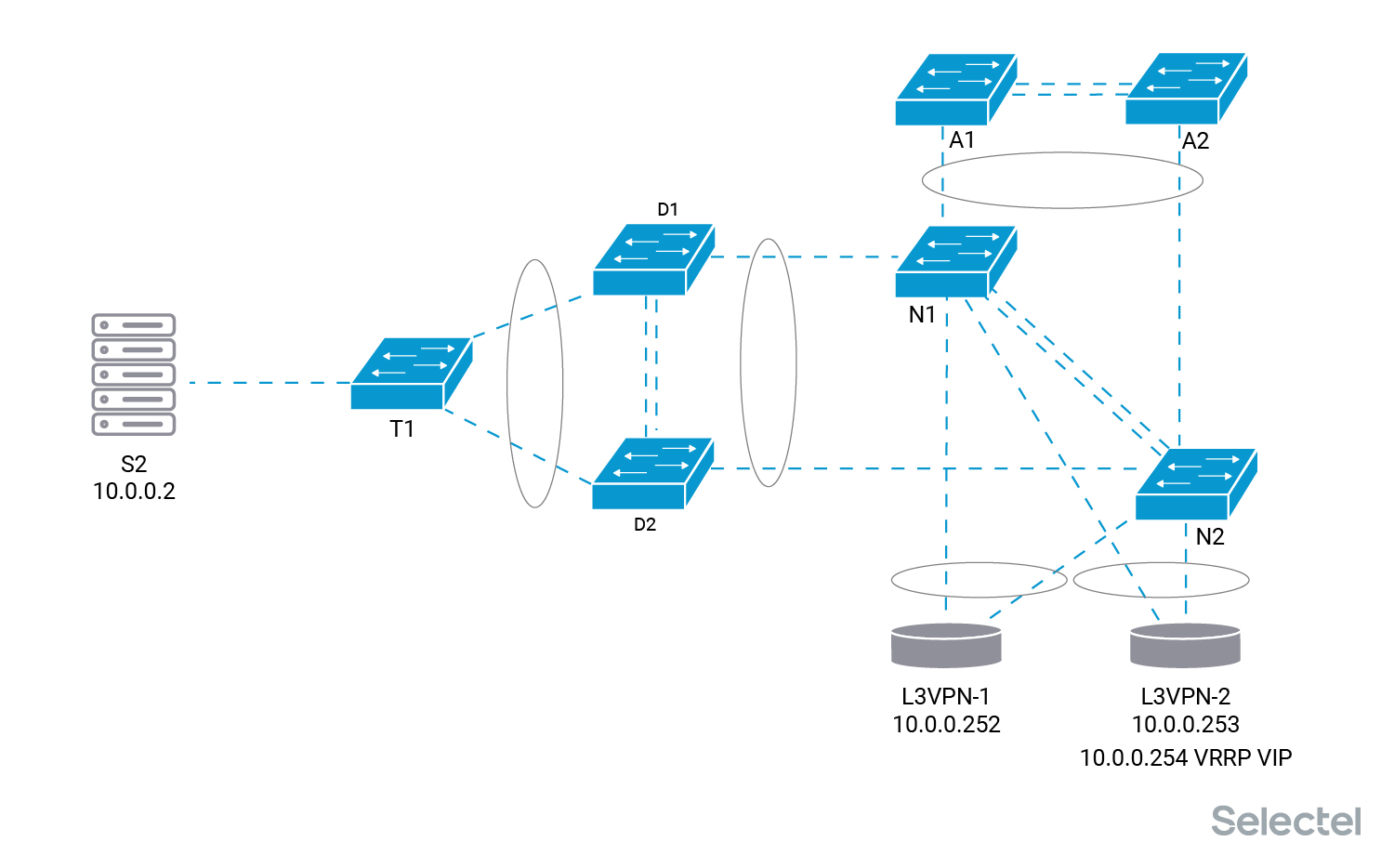
Возвращать VRRP VIP на маршрутизатор L3VPN-1 или нет — это уже другой вопрос, да и если возвращать, то это делается без перерыва связи.
Итого
После всех этих действий мы действительно заменили коммутаторы агрегации в одном из наших дата-центров, минимизировав при этом перерывы для наших клиентов.
Дальше остается только демонтаж. Демонтаж старых коммутаторов, демонтаж старых линков между коммутаторами А и D, демонтаж трансиверов от этих линков, исправление мониторинга, исправление схем сети в документации и мониторинге.
Коммутаторы, трансиверы, патч-корды, AOC, DAC оставшиеся после переключений, мы можем использовать в других проектах или при других подобных переключениях.
«Наташ, мы всё переключили!»




