
Всем привет. Вот и подошло продолжение первой части. Как и обещал, в данной статье, я хочу затронуть основные варианты реализации фабрики на VXLAN/EVPN, и рассказать почему мы решили выбрать то или иное решение в нашем ЦОД.

Выбираем дизайн Underlay
Предисловие
Первое, с чем приходится сталкиваться при строительстве фабрики, это проработка дизайна Underlay - как мы хотим строить наши VXLAN туннели (точнее организовать поиск VTEP)?
Варианта у нас 3:
1.Статические туннели, в которых мы задаем каждый VTEP руками - это сразу не наш вариант, но, скажу по секрету, все еще есть провайдеры, которые ручками строят RSVP-TE туннели под каждый сервис. Так что не удивлюсь, если есть такие реализации в промышленном масштабе. Ну и никто не отменял SDN.
2.Multicast - в целом, простая реализация, но для нас вариант отпал сразу, т.к. Cumulus не умеет в подобную реализацию, да и Juniper в своих материалах говорит о его resourse-intensive и медленной сходимости.
3.BGP или BGP, или все-таки BGP? Как обычно, в случае когда нам нужен какой-нибудь широкий функционал, который был бы гибким, мы приходим к BGP, точнее в нашем случае к EVPN с сигнализацией по BGP. На нем и остановимся подробней. Так как бывает iBGP и eBGP, то и реализации underlay могут быть с каждым из них.
iBGP
При использовании iBGP у нас сразу же появляется потребность в IGP, будь то OSPF или IS-IS (хоть статика), т.к. строить мы будем до Loopback, а сообщать маршруты о том, как дойти до них, нам кто-то должен. Так же не забываем о том, как iBGP распространяет маршруты, что вынуждает нас строить full-mesh (в такой реализации Spine совсем ничего не знает о существовании BGP).
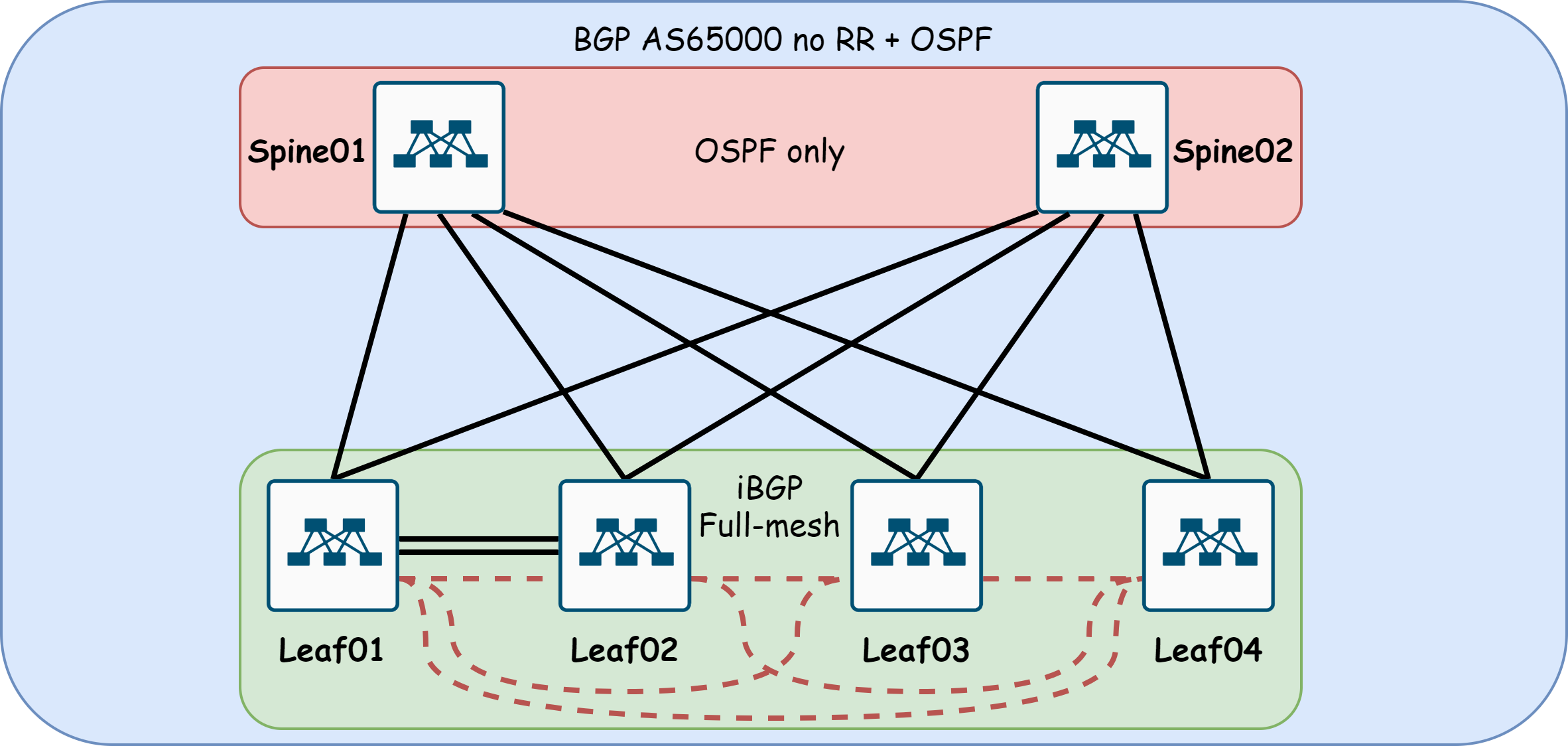
Или можем сделать Spine в роли Route-Reflector.

По итогу мы получаем как минимум 2 протокола маршрутизации и плюсом к этому full-mesh или RR. Это, конечно, не самое худшее что могло бы быть, но следующий вариант мне нравится больше.
eBGP
Данная реализация, на мой взгляд, самая понятная и надежная, и в итоге мы остановились на ней. Как только мы переходим к eBGP, потребность в Route-Reflector отпадает (надеюсь, все понимают почему), и продолжать использовать IGP тоже не имеет большого смысла, т.к. мы можем начинать строить соседства с p2p адресов. Так же в данном дизайне MLAG имеют более понятную реализацию. Про нее бы я остановился подробней. Оба MLAG свича помещаются в одну AS, т.к. при правильной реализации для всего остального VXLAN/EVPN домена они будут казаться одним устройством, что делает логичным их помещение в одну AS. Само соседство мы строим на peerlink'e, и это действительно необходимо, т.к. в случае, если у одного коммутатора упадут линки в сторону Spine, то он начнет дропать весь входящий трафик из-за того, что не будет маршрутов.

Единственное, что может кого-то спугнуть, это то, что нужно вести адресный план с номерами AS. Но счастливые обладатели Cumulus с версией 4.2(т.к. именно в ней это вышло) могут пойти другим путем, т.к. он теперь умеет автоматическое назначение AS, основываясь на MACе, что гарантирует вам уникальность (берет он из приватного пула 32-bit AS).
Так же стоит затронуть почему оба Spine находятся в одной AS. Т.к. каждый Spine имеет прямой линк к каждому Leaf, то трафик через него не может пройти дважды. Следовательно, мы можем использовать одинаковый номер AS на всех Spine, что собственно и советует Cumulus.
P.S. при использовании коротких AS можно все грамотно и красиво разделить, чтобы по номеру AS было понятно где был создан префикс. Так что использовать 32-bit AS совсем необязательно.
BGP Unnumbered
Думаю, многие не очень любят сталкиваться с адресным планированием p2p сетей, и как бы хотелось иметь только loopback и больше ничего. Если такие мысли вас когда-либо посещали, то стоит присмотреться к использованию Unnumbered. Реализация данного функционала в Cumulus отличается от Cisco, где у вас происходит заимствование адреса с интерфейса. Вместо этого у Cumulus выделен отдельный пул IPv6 адресов, которые динамически назначаются на интерфейс и по факту на них строится eBGP соседство. Так же на самом соседстве обязательно должен быть настроен extended-nexthop (для того, чтобы вы могли маршрутизировать IPv4 Family поверх IPv6 сессии).
P.S. Если на интерфейсах уже назначен какой-либо IPv4 /30 или /31 адрес, то BGP пиринг будет с них. Так же он не может работать в broadcast сетях, только p2p.
BGP+BFD
Как бы вы не хотели, но в любом случае таймеры самого BGP всегда будут измеряться секундами. И с учетом того, что сейчас появляются iSCSI, VSAN и т.д. такие задержки никто не может себе позволить. Как и во всех других протоколах маршрутизации нас спасает BFD. У Cumulus минимальные значения это 2x50 мс, насколько я знаю Cisco уже умеет 2х33 мс, так что данный функционал нам обязателен.
Что имеем в итоге?
1.Маршрутизация на eBGP с автоназначением AS + iBGP для MLAG пары
2.Из адресации нужны только loopback, все остальное нам заменяет Unnumbered
3.BFD
Настало время все настроить и посмотреть как оно работает
1.Как выглядит автоназначение AS у Cumulus
#Вариации у Cumulus при выборе AS
#P.S. Для всех Spine мы можем использовать одну AS, т.к. тут не будет возникать петли по AS-path
cumulus@Switch1:mgmt:~$ net add bgp autonomous-system
<1-4294967295> : An integer from 1 to 4294967295
leaf : Auto configure a leaf ASN in the 4-byte private range 4200000000 - 4294967294 based on the switch
MAC
spine : Auto configure a spine AS-number in the 4-byte private ASN range. The value 4200000000 is always
used
#Что по факту происходит при выборе "net add bgp autonomous-system leaf"
cumulus@Switch1:mgmt:~$ net add bgp autonomous-system leaf
cumulus@Switch1:mgmt:~$ net pending
+router bgp 4252968529 #Процесс BGP с автоматически сгенерированным AS
+end2.Конфигурация BGP+Unnumbered
#loopback
net add loopback lo clag vxlan-anycast-ip 10.223.250.30 #При MLAG добавляется общий для пары IP (Он как раз и будет светится в маршрутах
net add loopback lo ip address 10.223.250.1/32
#AS+Router ID
net add bgp autonomous-system leaf
net add bgp router-id 10.223.250.1
#Создаем стандартную конфигу для соседей через peer-group
net add bgp neighbor fabric peer-group #Создаем саму peer группу
net add bgp neighbor fabric remote-as external #Обозначаем что это eBGP
net add bgp neighbor fabric bfd 3 50 50 #Классический BFD
net add bgp neighbor fabric capability extended-nexthop # IPv4 over IPv6
#Задаем соседей через интерфейсы(Unnumbered)
net add bgp neighbor swp2 interface peer-group fabric
net add bgp neighbor peerlink.4094 interface remote-as internal #iBGP через Peerlink
net add bgp ipv4 unicast neighbor peerlink.4094 next-hop-self #Не забываем про next-hop для iBGP
net add bgp ipv4 unicast redistribute connected #Отдаем в BGP все свои сетки
#EVPN
net add bgp l2vpn evpn neighbor fabric activate #Активируем family для eBGP
net add bgp l2vpn evpn neighbor peerlink.4094 activate #Активируем family для iBGP
net add bgp l2vpn evpn advertise-all-vni #Сообщаем BGP соседям о своих VNI 3.BGP Summary
cumulus@Switch1:mgmt:~$ net show bgp summary
#IPv4
show bgp ipv4 unicast summary
=============================
BGP router identifier 10.223.250.1, local AS number 4252968145 vrf-id 0
BGP table version 84
RIB entries 29, using 5568 bytes of memory
Peers 3, using 64 KiB of memory
Peer groups 1, using 64 bytes of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
Switch3(swp2) 4 4252424337 504396 484776 0 0 0 02w0d23h 3
Switch4(swp49) 4 4208128255 458840 485146 0 0 0 3d12h03m 9
Switch2(peerlink.4094) 4 4252968145 460895 456318 0 0 0 02w0d23h 14
Total number of neighbors 3
#EVPN
show bgp l2vpn evpn summary
===========================
BGP router identifier 10.223.250.1, local AS number 4252968145 vrf-id 0
BGP table version 0
RIB entries 243, using 46 KiB of memory
Peers 3, using 64 KiB of memory
Peer groups 1, using 64 bytes of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
Switch3(swp2) 4 4252424337 504396 484776 0 0 0 02w0d23h 237
Switch4(swp49) 4 4208128255 458840 485146 0 0 0 3d12h03m 563
Switch2(peerlink.4094) 4 4252968145 460895 456318 0 0 0 02w0d23h 807
Total number of neighbors 3
4.net show route
cumulus@Switch1:mgmt:~$ net show route
show ip route
=============
Codes: K - kernel route, C - connected, S - static, R - RIP,
O - OSPF, I - IS-IS, B - BGP, E - EIGRP, N - NHRP,
T - Table, v - VNC, V - VNC-Direct, A - Babel, D - SHARP,
F - PBR, f - OpenFabric,
> - selected route, * - FIB route, q - queued route, r - rejected route
#Как видим все IPv4 адреса доступны через IPv6 (И да у Cumulus есть weight, аналогичный Cisco)
C>* 10.223.250.1/32 is directly connected, lo, 02w0d23h #Loopback
B>* 10.223.250.2/32 [200/0] via fe80::ba59:9fff:fe70:e50, peerlink.4094, weight 1, 02w0d23h
B>* 10.223.250.6/32 [20/0] via fe80::ba59:9fff:fe70:e5c, swp49, weight 1, 3d12h19m
B>* 10.223.250.7/32 [20/0] via fe80::ba59:9fff:fe70:e5c, swp49, weight 1, 3d12h19m
B>* 10.223.250.9/32 [20/0] via fe80::ba59:9fff:fe70:e5c, swp49, weight 1, 3d12h19m
C>* 10.223.250.30/32 is directly connected, lo, 02w0d23h #MLAG Loopback
B>* 10.223.250.101/32 [20/0] via fe80::1e34:daff:fe9e:67ec, swp2, weight 1, 02w0d23h
B>* 10.223.250.102/32 [20/0] via fe80::1e34:daff:fe9e:67ec, swp2, weight 1, 02w0d23h
B>* 10.223.250.103/32 [20/0] via fe80::1e34:daff:fe9e:67ec, swp2, weight 1, 02w0d23h
B>* 10.223.252.11/32 [200/0] via fe80::ba59:9fff:fe70:e50, peerlink.4094, weight 1, 02w0d06h
B>* 10.223.252.12/32 [200/0] via fe80::ba59:9fff:fe70:e50, peerlink.4094, weight 1, 02w0d06h
B>* 10.223.252.20/32 [200/0] via fe80::ba59:9fff:fe70:e50, peerlink.4094, weight 1, 02w0d06h
B>* 10.223.252.101/32 [200/0] via fe80::ba59:9fff:fe70:e50, peerlink.4094, weight 1, 02w0d06h
B>* 10.223.252.102/32 [200/0] via fe80::ba59:9fff:fe70:e50, peerlink.4094, weight 1, 02w0d06h
B>* 10.223.252.103/32 [200/0] via fe80::ba59:9fff:fe70:e50, peerlink.4094, weight 1, 02w0d06h5.traceroute + BFD
#traceroute полностью линуксовый (при желании можно пускать трассировку по TCP порту)
cumulus@Switch1:mgmt:~$ traceroute -s 10.223.250.1 10.223.250.6
vrf-wrapper.sh: switching to vrf "default"; use '--no-vrf-switch' to disable
traceroute to 10.223.250.6 (10.223.250.6), 30 hops max, 60 byte packets
1 10.223.250.7 (10.223.250.7) 1.002 ms 1.010 ms 0.981 ms # Все ответы идут с loopback интерфейсов
2 10.223.250.6 (10.223.250.6) 0.933 ms 0.917 ms 1.018 ms
#Проверяем BFD
cumulus@Switch1:mgmt:~$ net show bfd
------------------------------------------------------------------------------------------
port peer state local type diag vrf
------------------------------------------------------------------------------------------
swp2 fe80::1e34:daff:fe9e:67ec Up fe80::1e34:daff:fea6:b53d singlehop N/A N/A
swp49 fe80::ba59:9fff:fe70:e5c Up fe80::1e34:daff:fea6:b510 singlehop N/A N/A
На данном этапе Underlay уже полностью готов к использованию, теперь можем перейти к Overlay.
Выбираем дизайн Overlay
Как понятно из названия статьи, Overlay у нас на VXLAN с поиском VTEP через EVPN. Но и тут не все так просто. Существуют 3 основных дизайна маршрутизации трафика между SVI, на них как раз и остановимся.
Centralized IRB
В данной реализации у нас появляется единая точка выхода из подсети, это centralized switch. Зачастую это несколько отдельных коммутаторов (active-active пара), которые занимаются только L3 форвардингом, а все остальные Leaf коммутаторы занимаются только L2. Дополнительно ко всему в такой реализации сentralized switch должен анонсировать EVPN type-2 маршрут (MAC+IP) c расширенным Default Gateway community(0x03). Так же не забываем что на centralized switch должны присутствовать VNI со всей фабрики.

В моем понимании, данный дизайн выглядит хорошо только в том случае, когда взаимодействие между разными подсетями минимальны, или Leaf не умеют в L3. Но т.к. у нас в целевой фабрике планировалось очень много L3 взаимодействия, данный дизайн был отброшен сразу, чтобы не гонять лишний раз трафик.
Asymmetric IRB
Очень схожая по настройке реализация с Symmetric IRB (о которой ниже), но с одним исключением. Вся маршрутизация происходит на первом же VTEP, и последующим устройствам остаётся только отдать пакет по L2. При такой реализации необходимо, чтобы на каждом Leaf были все VNI+Vlan, что является платой за отказ от L3VNI.
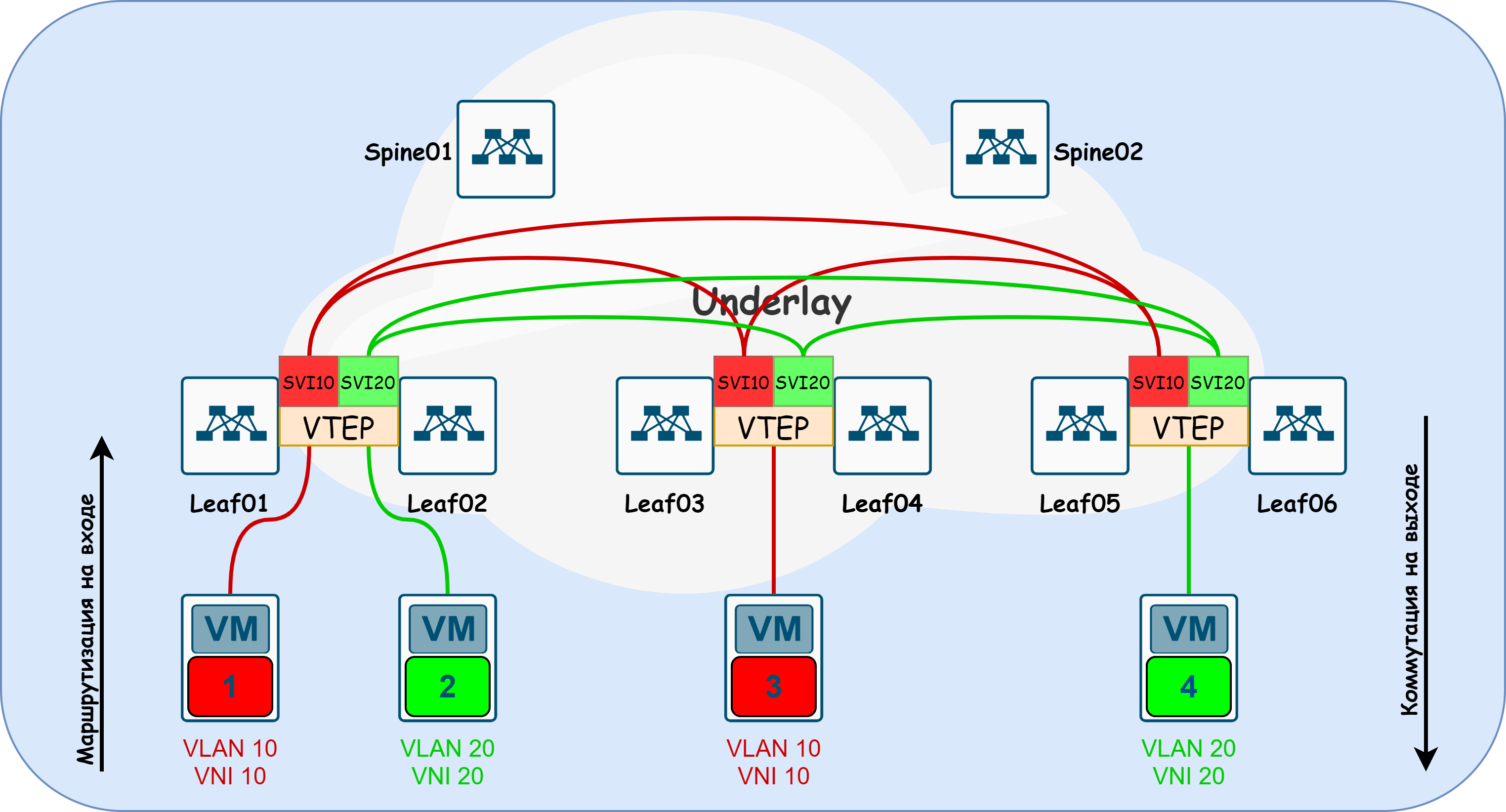
P.S. На самом деле, средствами автоматизации можно прийти к тому, что конфигурация у всех устройств фабрики всегда одинаковая (следовательно есть все VNI). При таких условиях данный дизайн может быть очень даже не плох, с учетом избавления от необходимости выделения VLAN под каждый VRF. Но в условиях того, что на текущий момент автоматизация у нас только в зачаточном состоянии, вероятноcть человеческой ошибки слишком высока.
Symmetric IRB
При симметричной модели для всех L3 коммуникаций у нас создается отдельная сущность L3VNI, с которой ассоциируется VLAN. Именно данный функционал избавляет нас от необходимости иметь все VNI на каждом VTEP.

Для того, чтобы было понятно что происходит, давайте рассмотрим то, как пойдет пакет с VM2 на VM3. При попадании пакета на Leaf03/04, он делает route-lookup, в котором видит что VM3 доступна через Leaf05/06, а nexthop является L3VNI интерфейс. Далее уже Leaf05/06 получает данный пакет, снимает VXLAN заголовок и передает уже чистый пакет в SVI20. То есть помещение в нужный SVI идет именно на конечном устройстве, что как раз и избавляет нас от необходимости иметь его на всех устройствах, но L3VNI у нас должен быть везде.
Как итог мы выбирали именно этот дизайн для Overlay.
Заканчиваем с настройкой фабрики
Пора настроить уже сам Overlay и посмотреть, как у нас будет работать поиск VTEP и распространение маршрутов.
1.Создаем L3VNI
#VRF+VNI
net add vrf Test vrf-table auto #Cоздаем VRF и автоматически назначаем RD+RT
net add vrf Test vni 200000 #Добавляем VNI к VRF
net add vxlan vniTest vxlan id 200000 #Создаем L3VNI
net add vxlan vniTest bridge learning off #Отключаем изучение Маков, т.к. используется EVPN
net add vxlan vniTest vxlan local-tunnelip 10.223.250.1 #Адрес откуда строим туннель
#VLAN
net add vlan 2000 hwaddress 44:38:39:BE:EF:AC #Делается только для MLAG, что бы у Active-Active пары был один MAC
net add vlan 2000 vlan-id 2000 #Номер влана
net add vlan 2000 vlan-raw-device bridge #Добавление в bridge
net add vlan 2000 vrf vniTest #Ассоциация с VRF
net add vxlan vniTest bridge access 2000 #Ассоциируем VLAN с L3VNI2.Создаем VNI
#VNI
net add vxlan vni-20999 vxlan id 20999
net add vxlan vni-20999 bridge arp-nd-suppress on #Включаем функционал ARP-supress - уменьшаем BUM трафик
net add vxlan vni-20999 bridge learning off #Отключаем изучение Маков, т.к. используется EVPN
net add vxlan vni-20999 stp bpduguard # Включаем bpduguard
net add vxlan vni-20999 stp portbpdufilter # Включаем bpdufilter
net add vxlan vni-20999 vxlan local-tunnelip 10.223.250.1 #Адрес откуда строим туннель
#Создаем VLAN
net add vlan 999 ip address 10.223.255.253/24 # IP на VLAN
net add vlan 999 ip address-virtual 44:39:39:ff:01:01 10.223.255.254/24 #Виртуальный адрес (Для единого gateway на всех Leaf)
net add vlan 999 vlan-id 999 #Номер влана
net add vlan 999 vlan-raw-device bridge #Добавление в bridge
net add vlan 999 vrf Test #Ассоциация с VRF
net add vxlan vni-20999 bridge access 999 #Ассоциируем VLAN с VNI
#P.S. Это конфига если нам нужен L2 only vlan (Конфигурация VNI не меняется)
net add vlan 999 ip forward off
net add vlan 999 vlan-id 999
net add vlan 999 vlan-raw-device bridge
3.Настройка соседства с внешней инфраструктурой
#Создаем самый обычный BGP процесс в VRF
net add bgp vrf Test autonomous-system 4252424337
net add bgp vrf Test router-id 10.223.250.101
net add bgp vrf Test neighbor 100.64.1.105 remote-as 35083
net add bgp vrf Test ipv4 unicast redistribute connected
net add bgp vrf Test ipv4 unicast redistribute static
net add bgp vrf Test ipv4 unicast neighbor 100.64.1.105 route-map Next-Hop-VRR_Vl997 out #Конфига для корректной работы MLAG+VSS через BGP+SVI, это стоило пару дней мучений для понимания
#P.S. Стоит так же заметить что в инфру будут отдаваться /32 префиксы которые генерирует EVPN, в нашем случая я их фильтровал на принимающей стороне.
net add bgp vrf Test l2vpn evpn advertise ipv4 unicast #Отдаем полученные маршруты в EVPN
На данном этапе с конфигурацией мы закончили, теперь предлагаю посмотреть как это все выглядит:
#VNI
cumulus@Switch1:mgmt:~$ net show evpn vni
VNI Type VxLAN IF MACs ARPs Remote VTEPs Tenant VRF
20995 L2 vni-20995 5 3 1 default #VNI, если нет IP на SVI
20999 L2 vni-20999 26 24 4 Test #VNI
200000 L3 vniTest 3 3 n/a Test #Сам L3VNI
#VNI подробней
cumulus@Switch1:mgmt:~$ net show evpn vni 20999
VNI: 20999
Type: L2
Tenant VRF: Test
VxLAN interface: vni-20999
VxLAN ifIndex: 73
Local VTEP IP: 10.223.250.30 #При наличии MLAG, будет использоватся vxlan-anycast-ip
Mcast group: 0.0.0.0 #Не используется
Remote VTEPs for this VNI: #Те у кого так же есть данный VNI
10.223.250.9 flood: HER #Используем Head-end Replication (Так же известно как Ingress replication)
10.223.252.103 flood: HER
10.223.252.20 flood: HER
10.223.250.103 flood: HER
Number of MACs (local and remote) known for this VNI: 26
Number of ARPs (IPv4 and IPv6, local and remote) known for this VNI: 24
Advertise-gw-macip: No #Community при centralized IRB#Таблица с тем откуда изучены маки
cumulus@Switch3:mgmt:~$ net show evpn mac vni 20999
Number of MACs (local and remote) known for this VNI: 28
Flags: B=bypass N=sync-neighs, I=local-inactive, P=peer-active, X=peer-proxy
MAC Type Flags Intf/Remote ES/VTEP VLAN Seq #'s
0c:59:9c:b9:d8:dc remote 10.223.250.30 0/0
0c:42:a1:95:79:7c remote 10.223.250.30 0/0
#Таблица MAC,где видим Interface VNI
cumulus@Switch3:mgmt:~$ net show bridge macs vlan 999
VLAN Master Interface MAC TunnelDest State Flags LastSeen
---- ------ --------- ----------------- ---------- --------- ------------ -----------------
999 bridge bridge 1c:34:da:9e:67:68 permanent 24 days, 04:35:13
999 bridge bridge 44:39:39:ff:01:01 permanent 14:26:45
999 bridge peerlink 1c:34:da:9e:67:48 permanent 31 days, 17:22:36
999 bridge peerlink 1c:34:da:9e:67:e8 static sticky 24 days, 04:14:16
999 bridge vni-20999 00:16:9d:9e:dd:41 extern_learn 19 days, 04:17:21
999 bridge vni-20999 00:21:1c:2e:86:42 extern_learn 19 days, 04:17:21
999 bridge vni-20999 00:22:0c:de:30:42 extern_learn 19 days, 04:17:21
#Маки самих VTEP
cumulus@Switch3:mgmt:~$ net show evpn rmac vni all
VNI 200000 RMACs 3
RMAC Remote VTEP
44:38:39:be:ef:ac 10.223.250.30
44:39:39:ff:40:94 10.223.252.103
44:38:39:be:ef:ae 10.223.250.9
#Arp-cache
cumulus@Switch3:mgmt:~$ net show evpn arp-cache vni 20999
Number of ARPs (local and remote) known for this VNI: 28
Flags: I=local-inactive, P=peer-active, X=peer-proxy
Neighbor Type Flags State MAC Remote ES/VTEP Seq #'s
10.223.255.242 local active 1c:34:da:9e:67:68 0/0
10.223.255.13 remote active 0c:42:a1:96:d2:44 10.223.250.30 0/0
10.223.255.243 local inactive 06:73:4a:02:27:8a 0/0
10.223.255.7 remote active 0c:59:9c:b9:f8:fa 10.223.250.30 0/0
10.223.255.14 remote active 0c:42:a1:95:79:7c 10.223.250.30 0/0#Таблица маршрутизации
cumulus@Switch1:mgmt:~$ net show route vrf Test | grep "10.3.53"
//Как видим все next-hop vlan2000, который мы отдали раньше под L3VNI
C * 10.223.255.0/24 [0/1024] is directly connected, vlan999-v0, 03w3d04h
C>* 10.223.255.0/24 is directly connected, vlan999, 03w3d04h
B>* 10.223.255.1/32 [20/0] via 10.223.250.30, vlan2000 onlink, weight 1, 02w5d04h
B>* 10.223.255.2/32 [20/0] via 10.223.250.30, vlan2000 onlink, weight 1, 02w5d04h
B>* 10.223.255.3/32 [20/0] via 10.223.250.30, vlan2000 onlink, weight 1, 02w5d04h
#Пример вывода EVPN маршрута
cumulus@Switch3:mgmt:~$ net show bgp evpn route vni 20999
BGP table version is 1366, local router ID is 10.223.250.101
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal
Origin codes: i - IGP, e - EGP, ? - incomplete
EVPN type-1 prefix: [1]:[ESI]:[EthTag]:[IPlen]:[VTEP-IP]
EVPN type-2 prefix: [2]:[EthTag]:[MAClen]:[MAC]:[IPlen]:[IP]
EVPN type-3 prefix: [3]:[EthTag]:[IPlen]:[OrigIP]
EVPN type-4 prefix: [4]:[ESI]:[IPlen]:[OrigIP]
EVPN type-5 prefix: [5]:[EthTag]:[IPlen]:[IP]
Network Next Hop Metric LocPrf Weight Path
*> [2]:[0]:[48]:[00:16:9d:9e:dd:41]
10.223.250.30 0 4252968145 i
RT:9425:20999 RT:9425:200000 ET:8 Rmac:44:38:39:be:ef:ac
*> [2]:[0]:[48]:[00:22:56:ac:f3:42]:[32]:[10.223.255.1]
10.223.250.30 0 4252968145 i
RT:9425:20999 RT:9425:200000 ET:8 Rmac:44:38:39:be:ef:ac
Заключение
Как итог, мы получили готовую VXLAN/EVPN фабрику. В Underlay у нас Unnumbered BGP и больше ничего, а в качестве Overlay мы имеем VXLAN/EVPN c Symmetric IRB, чего для решения наших задач в ЦОД более чем достаточно. Данный дизайн так же можно растянуть и на сами сервера, что бы строить туннели непосредственно с них.
Конечно, я не затронул всех возможных дизайнов по типу маршрутизации на Spine, но такой цели и не преследовалось. Надеюсь, статья кому-нибудь придётся по душе и будет полезна в планировании или эксплуатации собственного ЦОД. В случае, если есть идеи по улучшению или заметили критическую ошибку, прошу в комментарии.
")

")
