
Мы с командой постоянно используем в работе фиды с данными о киберугрозах. И мы не понаслышке знаем о таких проблемах, как недостаточное количество информации или ее дублирование в разных источниках, а также слишком большое число ложных срабатываний. Чтобы облегчить себе жизнь, мы решили подумать, как оценивать источники и выбирать из них наиболее качественные.
В статье я расскажу об OSINT-фидах, которые мы сравнивали с нашими и партнерскими данными. Всего на поиск и анализ источников, написание скриптов для загрузки данных, создание методики, тестирование данных, оценку по методике ушло около двух-трех месяцев. В результате исследования нам удалось найти несколько фишек, которые делают поиск данных более приятной процедурой. Табличку с критериями для оценки качества и наши выводы ищите в конце.
Если у вас есть похожая задача, можете докрутить методику и использовать ее, например, для оценки коммерческих источников. Надеемся, наш опыт будет полезен.
Немного о фидах
Типовой фид — это источник, который предоставляет не только индикаторы компрометации, но и контекст, связанный с ними. Это может быть описание угрозы, используемые техники и инструменты злоумышленников, принадлежность к какой-то конкретной группировке, дополнительные индикаторы, которые могут свидетельствовать о наличии вредоносной активности в инфраструктуре.
Как проходило наше исследование
Пьем кофе и собираем фиды
Однажды я вооружился кофе и приступил к поиску OSINT-источников.
Сама процедура банальна до безобразия: я делал поисковые запросы в Google по ключевым словам. Когда я находил какой-то источник, выяснял, функционирует ли он: открывается ли страница с информацией, работает API или кнопка выгрузки. Также обязательно смотрел на дату последнего обновления данных и проверял актуальность через VirusTotal. Это далеко не единственный подход, однако мне он оказался ближе всех.
Так я собрал определенный список OSINT-источников и нашел уже готовые списки (спасибо пользователям GitHub — rshipp и hslatman).
В планах было получить качественные данные с дополнительной информацией по каждому индикатору, которые генерируют мало ложных срабатываний (false positive, FP). Под ложным срабатыванием мы понимаем одну из двух ситуаций:
- Сработавший индикатор компрометации является легитимным. Например, google.com.
- Сработавший индикатор компрометации является неактуальным. Например, по указанной ссылке уже отсутствует вредоносный файл.
Если угроза неактуальна для конкретной инфраструктуры, но присутствует в ней, срабатывание не будет считаться ложным. Допустим, мы обнаружили ботнет Mirai. Для заказчика он оказался не опасен, однако, чтобы не портить статистику, считать его фолзом не будем.
Кстати, допустимым мы считаем процент ложных срабатываний, то есть фолзовых индикаторов от общего количества данных в источнике, в пределах от 0,01% до 0,05%.
Оказалось, что многие из собранных источников содержат неактуальную информацию либо недоступны. Это значит, что страница с информацией не открывается и браузер выдает ошибки 400 или 500, или последний раз данные обновлялись больше двух лет назад.
Проблема большинства OSINT-источников, с которой столкнулся и я — это то, что данные редко проходят проверку, и в источник может попасть легитимный ресурс, который породит огромное количество ложных срабатываний. Чтобы сократить число таких ситуаций, стоит фильтровать данные перед загрузкой.
Один из способов фильтрации — использование белых списков, списков сущностей, которые не являются вредоносными и не могут использоваться в качестве индикаторов компрометации. Их тоже нужно поддерживать в актуальном состоянии.
Я старался сделать так, чтобы легитимные ресурсы — хостинги и облачные сервисы — не попадали в наши списки.
В процессе анализа обнаружилось, что OSINT-источники могут повторять друг друга, получать информацию из одинаковых мест. Вот небольшое сравнение двух источников.
Источник Blackbook собирает и агрегирует информацию по вредоносным доменам из других мест. Выяснилось, что он использует данные из URLhaus — одного из источников индикаторов компрометации, который входит в состав исследовательского проекта Institute for Cybersecurity and Engineering (ICE).
Информация в URLhaus (рис. 1) собирается по вредоносным URL-адресам, а данные в Blackbook (рис. 2) формируются путем получения информации из поля Host источника URLhaus (обращайте внимание на даты на скриншотах). При этом дублируются не все данные, присутствуют внутренняя аналитика и фильтрация. Иногда значение в поле Host оказывается IPv4-адресом и принадлежит, например, какому-нибудь хостингу — это приводит к ложным срабатываниям.

Рис. 1. Данные в URLhaus

Рис. 2 Данные в Blackbook
В общей сложности за несколько дней поисков я нашел около 30 функционирующих источников (рис. 3).

Рис. 3. Фрагмент таблицы с информацией о найденных источниках
А дальше началось самое интересное (нет): сопоставление информации с нашей моделью данных и автоматизация загрузки данных в нашу платформу Threat Intelligence.
Разумеется, меньше всего оказалось источников с собственным API. Чуть больше источников предоставляют данные в форматах CSV или JSON, и большая часть из них имеют данные в формате плоских списков. Да, чуть не забыл, есть пара источников, где пришлось даже использовать web scraping.

Рис. 4. Пример формата данных одного из источников (greensnow)
Как выглядят данные в платформе после загрузки, видно на рис. 5.

Рис. 5. Интерфейс TI-платформы BI.ZONE ThreatVision с загруженными данными
Не обошлось без багов в коде при запуске первых скриптов. Через сутки коллеги обнаружили неестественные цифры в статистике — и сразу же поняли, что дело во мне =(

Я поправил скрипты, и данные полились рекой.

Близимся к развязке и оцениваем данные
Сам по себе индикатор может быть бесполезен, если мы не понимаем, как его использовать, или у нас нет дополнительной контекстной информации по нему. Поэтому теперь нам нужно было ранжировать собранные источники и присвоить им оценки в зависимости от качества информации, которую они предоставляют. При неправильном использовании непроверенные данные, тем более из открытых источников, порождают огромное количество ложных срабатываний.
Возьмем IP 94.53.130[.]195. По его значению как-то не очень понятно, что он собой представляет. Можно проверить этот адрес при помощи разных популярных инструментов и убедиться, что он вредоносный, но вопросы все равно останутся.
Если же у индикатора есть контекст, то и понимания будет больше. Вот пример:
| Контекст | Значение |
|---|---|
| Индикатор | IP 94.53.130[.]195 |
| Категория | Malware |
| Название вредоносного ПО, эксплуатирующего адрес | TrickBot |
| Номер порта | 447 |
| Тег | С&C |
Проблема в том, что мало какие источники предоставляют такой контекст по индикаторам. Например, в одном источнике может содержаться тег с информацией о C&C-сервере, а в другом — название вредоносной программы. Но это решаемо: нужно выбрать разные источники, изучить их содержимое и собрать как можно более полную информацию, удалив при этом дублирующиеся данные. В результате такой работы получится сформировать дополнительный контекст по индикатору.
Контекст по каждому индикатору в источнике формируется с использованием дополнительных инструментов, аналитики, данных из отчетов и исследований.
Если посчитать процент пересечения выбранного источника с другими и проанализировать полученную информацию, можно примерно понять, что за данные он предоставляет и насколько он уникален. Сейчас объясню на примере URLhaus.
Мы проверили более 60 источников из нашей платформы, но данные из URLhaus пересекаются только с 7 из них. Вот как это выглядит:
| Источник | Количество пересечений* | Процент пересечения** |
|---|---|---|
DigitalSide |
1543 | 3,41% |
FIRST |
348 | 0,77% |
<source1>*** |
138 | 0,31% |
<source2>*** |
130 | 0,29% |
<source3>*** |
127 | 0,28% |
AlienVault OTX |
18 | 0,04% |
<source4>*** |
3 | <0,01% |
*Количество данных из URLhaus, которые встречаются в других источниках.
**Доля данных из URLhaus, которые встречаются в других источниках.
***Коммерческие источники.
Как видно, в URLhaus лежат уникальные данные.
Индикаторы из некоторых источников могут создавать огромное количество событий в SIEM-системах, но в то же время быть полезными при расследованиях или просто при использовании в качестве списков на средствах защиты информации (СЗИ). В основном это IPv4-адреса, с помощью которых выполняется сканирование различных сервисов (SSH, IMAP, FTP) на хостах.
Лучший способ проверки — это использование данных в боевой среде. В результате будет примерно понятно, какие источники лучше подходят для тех или иных целей, какие данные больше всего фолзят, а какие — оказались вовсе бесполезными.
Для решения задачи мы разработали специальный инструмент. С его помощью мы анализировали логи как в реальном времени, так и в ретроспективе. Это потребовалось, чтобы выявить индикаторы, о которых стало известно позже — до того, как они появились у нас в списках. В итоге мы смогли получить информацию о том, данные из каких источников срабатывают чаще всего, какие у них индикаторы и типы. Также мы выяснили, на каких локальных IP присутствует вредоносная активность, и определили, какое вредоносное ПО ее осуществляло.
Показать точные данные мы не можем, но в интерфейсе это выглядит как-то так (рис. 6).
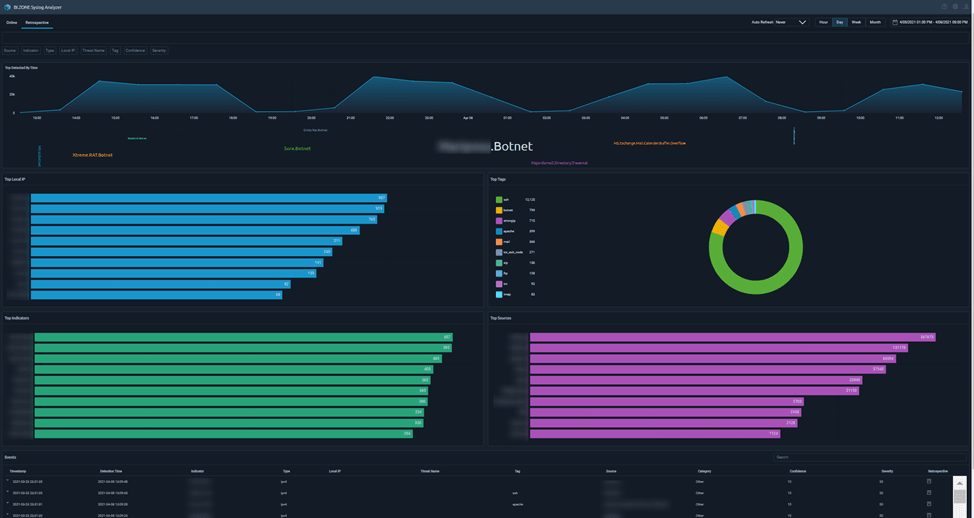
Рис. 6. Визуализация результатов анализа логов для выявления индикаторов
Методика и критерии оценки от нашей команды
Мы попробовали оценить источники с использованием формальных критериев. Ниже приведена наша методика.
Мы перечислили критерии и выделили среди них используемые для первоначальной оценки источников, чтобы проставить им баллы по шкале от 0 до 100. Итоговый балл — это параметр, который сначала присваивается источнику, а потом наследуется индикатором компрометации. Значение отражает уровень нашего доверия к данным источника, который предоставил этот индикатор. Оно может меняться как в процессе тестирования, так и в процессе использования источников.
| № | Критерий оценки | Описание критерия | Баллы |
|---|---|---|---|
| 1 | Возможность распространения данных из источника | Источник позволяет передавать данные третьим лицам. Для нас это означает возможность загружать данные в нашу платформу и предоставлять их заказчикам |
5 баллов при наличии такой возможности |
| 2 | Типы данных в источнике | В источнике присутствуют индикаторы разных типов: IPv4, FQDN, URL и т. д. | 5 баллов за file3 балла за url1 балл за остальное |
| 3 | Формат данных, предоставляемых источником | Источник предоставляет данные в формате JSON, CSV, TEXT, XML, STIX и др. Хорошо, если у источника есть структурированные форматы данных разных типов, но все зависит от конечной цели и системы, где эти данные будут использоваться |
Мы не использовали его при первоначальной оценке, однако вам он может пригодиться. Например, можно использовать такой подход: при наличии API даем 5 баллов, при наличии JSON или CSV — 3 балла. Для нас формат данных значения не имел |
| 4 | Способ формирования данных в источнике | Данные могут формироваться одним из трех способов.
Данные, которые формируются автоматически и не содержат контекста, имеют более высокую вероятность ложного срабатывания.
Данные, которые проходят предварительную модерацию, более надежны.
Данные, которые добавляются вручную, по качеству схожи с модерируемыми |
5 баллов за добавление вручную 10 баллов за модерацию |
| 5 | Наличие исторических данных в источнике | В источнике присутствуют исторические данные, относящиеся к индикатору. Например, Passive DNS |
5 баллов при наличии подобных данных |
| 6 | Частота появления новых данных в источнике | Новые данные в разных источниках появляются с разной частотой. Чем чаще появляются, обновляются и удаляются данные в источнике, тем лучше. Хорошие источники предоставляют новую информацию регулярно. Частота зависит от сложности обработки информации и может быть от нескольких раз в сутки до нескольких раз в месяц |
5 баллов, если новые данные появляются хотя бы раз в сутки |
| 7 | Наличие контекстной информации у источника | Источник содержит контекстную информацию. Чем больше дополнительной информации об индикаторах предоставляет источник, тем выше качество данных. Это могут быть:
|
5 баллов, если в контекстной информации есть описание хотя бы одного критерия (например, тег или категория) 10 баллов, если в контекстной информации есть описание хотя бы двух критериев (например, тег и категория, тег и название вредоносного ПО) |
| 8 | Принадлежность источника к группе узкоспециализированных | Источник считается узкоспециализированным, если он направлен на сбор данных по конкретным группировкам, угрозам | 10 баллов, если источник относится к группе узкоспециализированных |
| 9 | Наличие ложных срабатываний у индикаторов компрометации в источнике | Ложным срабатывание считается, если сработавший индикатор является легитимным или неактуальным. При наличии ложных срабатываний необходимо обратить внимание на:
|
Используется при проверке в боевой инфраструктуре. 10 баллов, если оба значения находятся в допустимых пределах 5 баллов, если хотя бы одно значение находится в допустимых пределах |
| 10 | Проверка наличия срабатываний по индикаторам компрометации с использованием СЗИ | Индикаторы компрометации интегрируются в совместимое СЗИ, например в SIEM-систему, и на протяжении количества времени N тестируются для выявления срабатываний.Если СЗИ позволяет, то необходимо выполнить ретропоиск для выявления индикаторов, которые срабатывали в прошлом |
Не используется при первоначальной оценке |
| 11 | Проверка сработавших индикаторов другими ресурсами для подтверждения их валидности | Результаты проверки сработавших индикаторов при помощи VirusTotal. Чем больше систем в VirusTotal задетектировали индикатор, тем качественнее данные в источнике | Не используется при первоначальной оценке |
| 12 | Пересечение с другими источниками данных | Наличие у одного индикатора нескольких источников придает ему вес. Чем выше процент пересечения индикаторов с коммерческими источниками или источниками, которые уже определены как надежные, тем качественнее данные | 5 баллов, если процент пересечения с каким-либо источником НЕ превышает 60–70% 5 баллов, если процент пересечения с источниками, которые отмечены как надежные, НЕ меньше 30% Дополнительные 5 баллов, если есть пересечение с коммерческими источниками |
| 13 | Пересечение с источником срабатываний от SOC | Источник может содержать индикаторы компрометации, которые, по информации нашего SOC, сработали в нашей инфраструктуре или у заказчиков. Чем выше процент пересечения, тем качественнее данные в исследуемом источнике | 5 баллов, если у вас есть свой SOC, и данные из источников пересекаются с данными из него |
| 14 | Регион/отрасль поставщика данных | Некоторые источники данных предоставляют информацию по конкретным регионам (RU, EU, US, Whole World и т. д.) или отраслям (банковский сектор, медицина, промышленность и т. д.) |
Не используется при первоначальной оценке |
| 15 | Роль источника в создании инцидента и роль данных из источника в расследовании | В результате срабатывания индикаторов создан и зарегистрирован инцидент либо был выявлен инцидент в ретроспективе | 5 баллов, если данные помогли выявить или расследовать инцидент у 1–3 заказчиков 10 баллов, если данные помогли выявить или расследовать инцидент у 4–7 заказчиков |
С помощью этих критериев мы смогли выявить наиболее релевантные и интересные источники OSINT. Вот как распределились результаты:
- Наилучшую оценку, 63 балла, получил источник
URLhaus. - Больше 40 баллов набрали только 10 источников из 29.
- Минимальная оценка — 21 балл.
- Средняя оценка — 37 баллов.
- Медианная оценка — 36 баллов.
8 советов, которые помогут при изучении фидов
Всегда первым делом проверяйте данные из найденных источников на доступность и актуальность. Если окажется, что ссылка из источника не работает или последний раз в него подгружали данные сто лет назад, то и нет смысла переходить к остальным пунктам.
Считайте, какой процент новых данных появляется при каждом обновлении от общего количества данных в источнике.
Проверяйте, достаточно ли вам той информации, которую предоставляет источник. Если нет, исследуйте дальше: возможно, вам попадется источник, который сможет дать больше дополнительной информации по тем же индикаторам.
Если источники дублируют друг друга, в первую очередь обращайте внимание на те, где данные появляются раньше.
Тестируйте источники путем использования данных из них в реальной инфраструктуре.
Обращайте внимание на долю ложных срабатываний от общего количества данных в источнике и от количества срабатываемых индикаторов.
Формируйте свою методику для оценки источников. Нашу мы выложили в открытый доступ: вы можете адаптировать ее под свои цели и потребности
Помните, что OSINT-фиды являются только одним кусочком пазла Threat Intelligence, хотя и важным, и наиболее доступным. Они вряд ли смогут удовлетворить потребности организации на этапе, когда ее безопасность уже задумывается о фидах. Есть еще соцсети, форумы, мессенджеры, внутренние истории, коммерческие поставщики и другие источники данных разных родов и мастей, однако это уже другая история.
Автор: Георгий Кузнецов
Telegram: MrKuznetsov



