
Группа НЛМК- большая компания, производственные активы которой располагаются в разных регионах России и за рубежом. Перед нами стояла задача спроектировать и внедрить новую интеграционную платформу, которая могла бы быть использована для организации информационного обмена, учитывала специфику производственных предприятий и особенности решений, внедренных на протяжении последних десятков лет.
Меня зовут Илья Макаров, я работаю архитектором решений и в статье расскажу про архитектуру цифровой платформы НЛМК, из каких компонент, помимо Apache Kafka, она состоит, к каким соглашениям по именованию топиков и договоренностям по передаче данных мы пришли, как всем этим управляем.
Архитектура и подходы, про которые я рассказываю – длительный путь эволюционного развития, который до сих пор продолжается. Мы начали с решения относительно простой задачи - организации взаимодействия между разными системами, для сбора логов и трейсов, но, за счет погружения в особенности производства, пришли к понимаю применимости нашей платформы для решения и других задач:
Телеметрия – сбор и организация доступа к данным с различных датчиков
Обмен данными между системами в изолированных, с точки зрения требований ИБ, сегментах
Загрузки данных в централизованные хранилища
На основании данных групп задач мы решили сделать следующие кластеры:
централизованный кластер в бизнес-сегменте под данные и интеграции ИС
выделенный кластер в бизнес-сегменте под логи и трейсинг
выделенный кластер в бизнес-сегменте под тренды
локальные к производству кластеры (под данные, логи и тренды сегмента производства)

Kafka можно назвать одним из основных, базовых, компонентов инфраструктуры. Подходы и принципы, заложенные в начале, живут очень долго и их очень сложно поменять. Поэтому очень важно на начальном этапе сразу продумать, как пользователи будут авторизоваться в разных кластерах, как будут именоваться топики, в каком формате передавать сообщения, как обеспечить контроль качества схем и данных.
Можно выделить несколько уровней зрелости систем в зависимости от степени автоматизации:
заявки, ручник и длительное ожидание
автоматизированные инструменты администраторов, написанные тесты к входной информации от пользователей
все запросы пользователей автоматизированы
приложения-потребители могут жить без поддержки (будь то перевыпуск сертификата или CA, или смена пароля, всё для пользователей ИС происходит автоматически)
Мы сейчас находимся где-то между уровнями 2 и 3, и кажется, что уже можем поделиться тем, к чему пришли.
Кластеры и аутентификация
Каждому кластеру присваивается имя вида XXX-Y, состоящее из номера группы (ХXX) и суффикса (Y) - идентификатора среды.
Номера группы выдаются последовательно. В группе может быть только один кластер с продуктивной средой. Условлено, что среда prod всегда имеет суффикс 0, test или dev- любые другие числа.
Например, кластерная группа 000- это наш центральный кластер под данные. Его продуктивный кластер Kafka имеет имя 000-0, его дев кластер 000-1, а тестовый кластер - 000-2. Имена кластеров уникальны в рамках компании. Это позволяет гарантировать уникальность имен топиков в рамках компании, определять кластер по имени топика, реплицировать топики без конфликта имен.
Аутентификация
Самый универсальный способ аутентификации - mTLS, позволяет аутентифицировать клиентов даже там, где нет, например, контроллера домена, и поддерживается всеми библиотеками и ПО, которое мы используем. Подсмотрев как это было сделано в Booking (спасибо Александру Миронову) мы разработали следующий подход к CA и сертификатам.
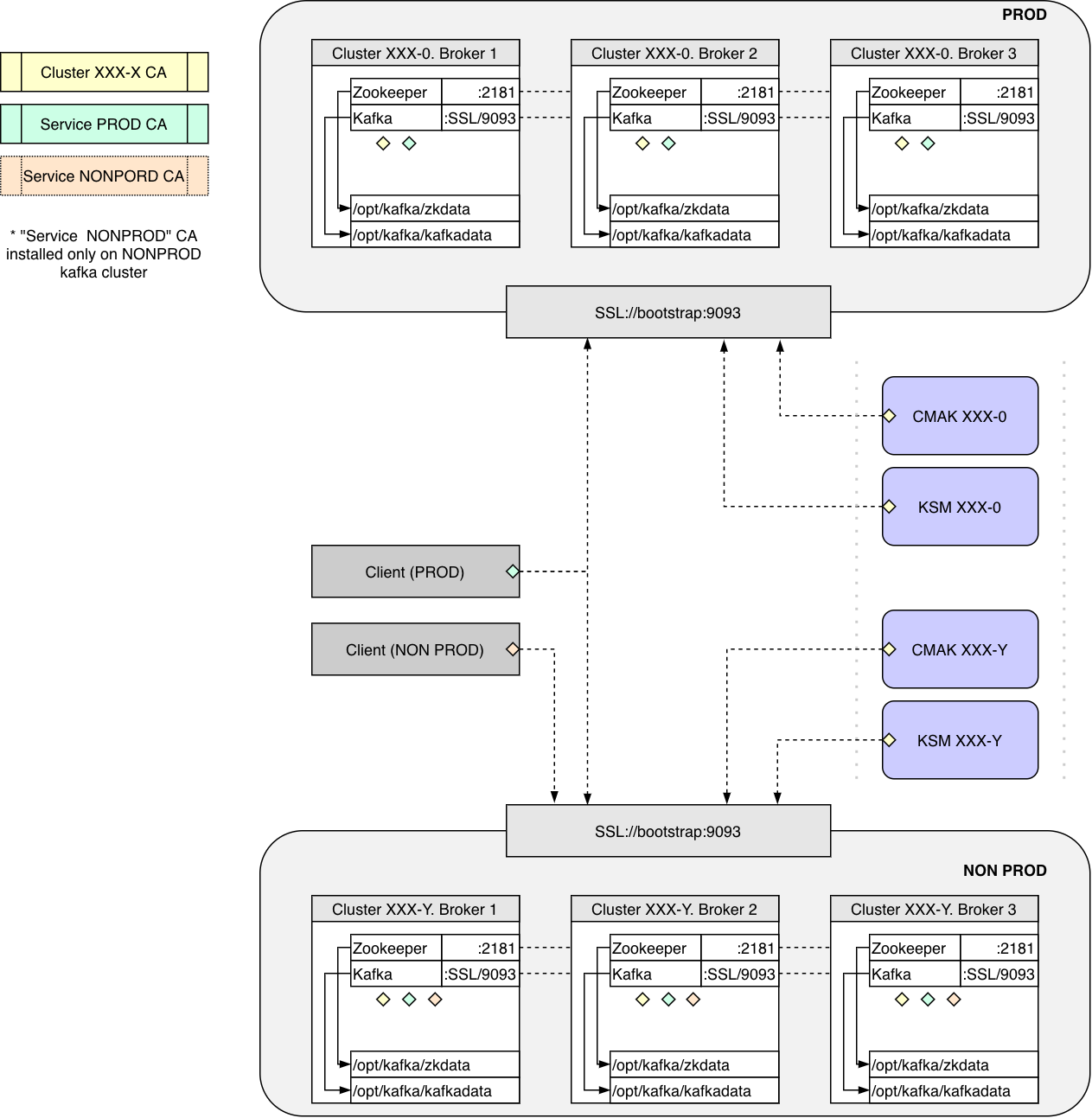
На каждый кластер выпускается свой CA(Cluster XXX-X CA). Этот CA выпускает сертификаты для брокеров и сервисов администрирования (KSM).
Также два CA для сервисов: Service PROD и Service NONPROD.
На продуктивные кластеры Kafka устанавливается два CA:
Cluster
XXX-XCAService PROD CA
На тестовые устанавливается три CA:
Cluster
XXX-XCAService PROD CA
Service NonPROD CA
Таким образом, приложения, у которых сертификат выпущен Service PROD CA, могут подключаться и к продуктивным, и к непродуктивным кластерам Kafka. Как пример, последнее сделано, чтобы можно было реализовать сервис по наполнению тестовых сред на основе данных из продуктивной среды. Приложения с сертификатами, выданными Service NonPROD CA, могут подключаться только к непродуктивным кластерам. Отдельный CA для сервисов позволяет приложениям с одним сертификатом подключаться к разным кластерам.
Для создания CA и выпуска сертификатов мы используем Lemur, (опять же, спасибо Александру Миронову), а также Vault. Lemur предоставляет авторизацию, выпуск сертификатов через Rest, хранение сертификатов и выполняет их доставку в Hashicorp Vault.
Vault используем не только для хранения секретов, но и для выпуска сертификатов для сбора логов с машин. Каждая ВМ получает токен с которым может выпустить себе сертификат. Сертификат выпускается на 7 дней и автоматически ротируется с помощью Consul Template. Скорее всего, в будущем мы откажемся от Lemur и полностью перейдем на Vault.
Для управления ACL мы используем подход GitOps: Git -> CI -> KSM.
В качестве инструментов для администрирования используем:
AKHQ
Kafdrop
CMAK
Мониторинг
Хосты и сервисы
Наш основной стек мониторинга - Prometheus и VictoriaMetrics. Для сбора метрик с Java сервисов Kafka и Kafka REST мы используем Prometheus JMX Exporter. Он запускается как Java agent и предоставляет http интерфейс на localhost с метриками JVM. Zookeeper, начиная с версии 3.6, нативно умеет предоставлять метрики в Prometheus-формате.
На виртуальных машинах в качестве агентов сбора метрик используется Telegraf.
Он собирает:
метрики хоста
метрики локальных экспортеров (JMX Exporter, Zookeeper)
cтатус сервисов systemd для Kafka и Zookeeper.
статус и метрики контейнеров docker для Kafka REST, Schema Registry, NGiNX, RA.
срок до истечения сертификатов
Про мониторинг Zookeeper отлично все собрано у Altinity: Zookeeper monitoring
Kafka REST
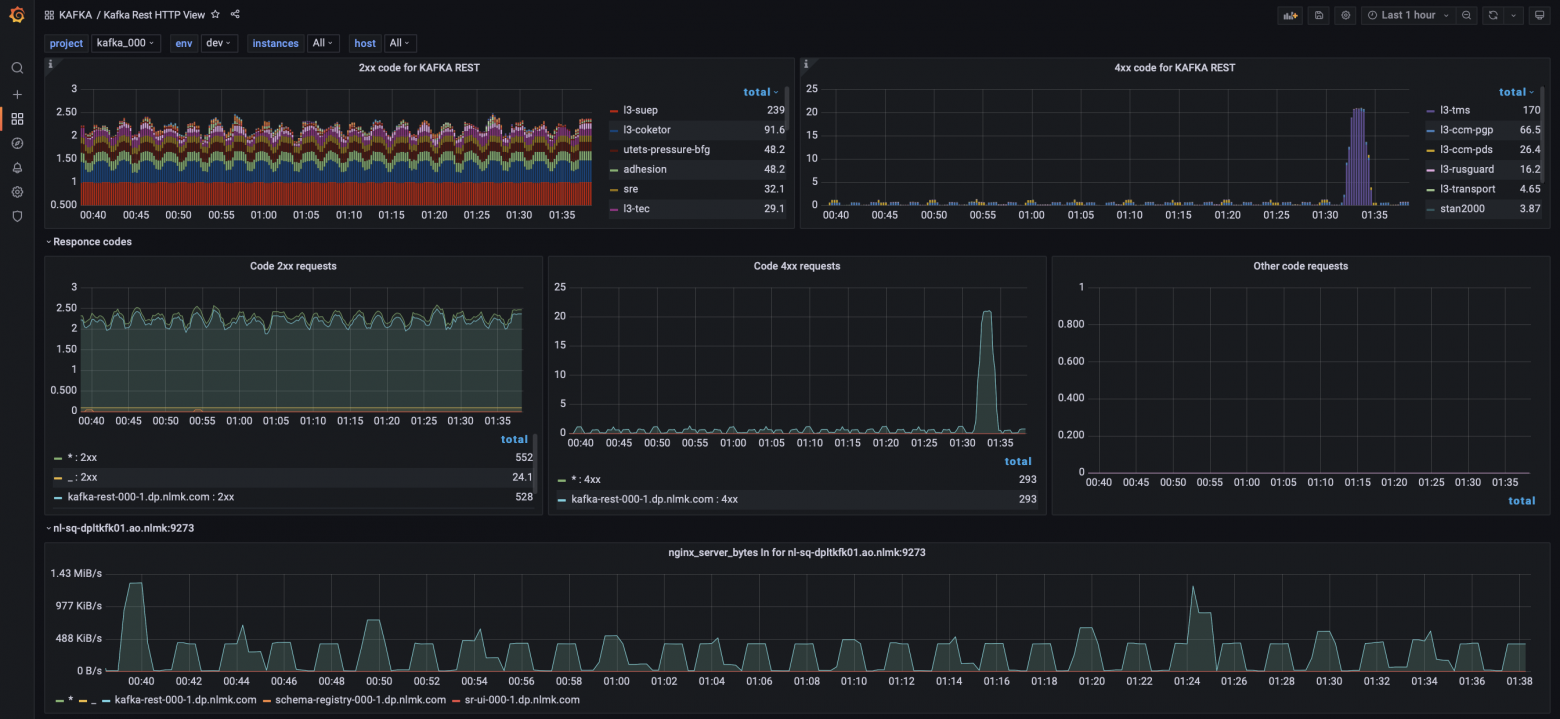
Для Kafka-REST мы собираем статистику по http кодам ответов с помощью модуля Nginx VTS в разрезе dataset name(см. соглашение об именовании топиков).
Пример nginx/conf.d/kafka-rest.conf:
map $uri $namespace {
~*/topics/[0-9-]+\.(?<datasetname>[a-z0-9-]+)\..+$ $datasetname;
default 'unmatched';
}
server {
...
host_traffic_status_filter_by_set_key $host $namespace;
...
}А также, мы используем Blackbox Exporter, с помощью которого периодически отправляем тестовое сообщение в kafka-REST и проверяем код ответа. Данный метод имеет свои слабые стороны (например, AVRO схема кэшируется на стороне Kafka-REST и проблемы со Schema Registry можно не заметить). Улучшение этого мониторинга уже запланировано.
Внешний мониторинг Kafka
В качестве агента для мониторинга кластера снаружи мы используем: KMinion. Его функционал очень богат, он позволяет видеть статистику по кластеру в целом, по топикам, по консьюмер группам, а также размер топиков на диске, и даже есть end-to-end мониторинг.
Для деплоя и управления всеми инструментами администрирования мы используем подход GitOps и деплоим инструменты в OpenShift (очень удобно, что все инструменты можно закрыть с помощью OpenShift OAuth).
Публичные дашборды
Возможность самостоятельной диагностики и открытость - основной наш подход. В нашем централизованном сервисе мониторинга всем авторизованным пользователям доступны подготовленные нами дашборды для Kafka и Kafka REST.
Топ-3 вопроса от пользователей по Kafka и Kafka REST:
есть ли данные в топике?
пишутся ли данные?
все ли нормально с Kafka REST?
На первые два вопроса помогают ответить стандартные дашборды KMinion. Мы их слегка изменили, добавив возможность выбора кластера и среды.
Для ответа на третий вопрос, мы сделали дашборд из метрик Nginx VTS.
Пример дашборда Nginx VTS
Соглашение об именовании топиков
Следующим важным шагом была разработка концепции именования топиков.
Мы пришли к следующему формату:
<cluster name>.<dataset name>.<message type>.<data name>.<version>
Где:
cluster name- уникальное имя кластера Kafka вида XXX-X. Для реплицированных из кластера YYY-Y: XXX-X-YYY-Y.dataset name- условно - имя базы данных, уникальное в рамках всех кластеров. Используется как категоризация для группировки топиков вместе.message type- тип сообщений, говорит о том как данные должны быть интерпретированы или использованы. Выбирается из справочника MessageType.data name- сущность аналогичная "таблица" в БД, название потока данных.version- версия данных, для обратно несовместимых изменений в схеме данных, начиная с 0.
Для валидации, что имя топика соответствует конвенции, мы используем следующий regexp:^\d{3}-\d(-\d{3}-\d)?\.[a-z][a-z0-9-]+[a-z0-9]\.(db|cdc|bin|cmd|sys|log|tmp)\.([a-z0-9][a-z0-9-]*[a-z0-9]+)\.\d+$
Справочник MessageType
Название | Интерфейс записи | Формат сообщения | Публичный | Комментарий |
db | Kafka REST | AVRO | + | Для фактов, неизменяемых событий (данные датчиков, действия пользователей и т.д.). |
cdc | Kafka REST | AVRO | + | Топик типа Compaction. Содержит полный набор данных и получает изменения к ним. Может использоваться для перезаливки хранилищ и кэшей, справочников. Key обязателен. |
cmd | Kafka REST | AVRO | + | Содержит команды, используется в реализации паттерна Запрос-Ответ. |
bin | Kafka REST | Bin | + | Бинарные данные (Content-Type: application/vnd.kafka.binary.v2+json) - используются в исключительных ситуациях. Рекомендуется в конце |
sys | Binary | Bin | - | Внутренние топики, используемые только этим сервисом и неинтересные другим. |
log | Binary | Bin | - | Для передачи логов (Syslog, FluentBit). |
tmp | Binary | Bin | - | Для временных или промежуточных данных. |
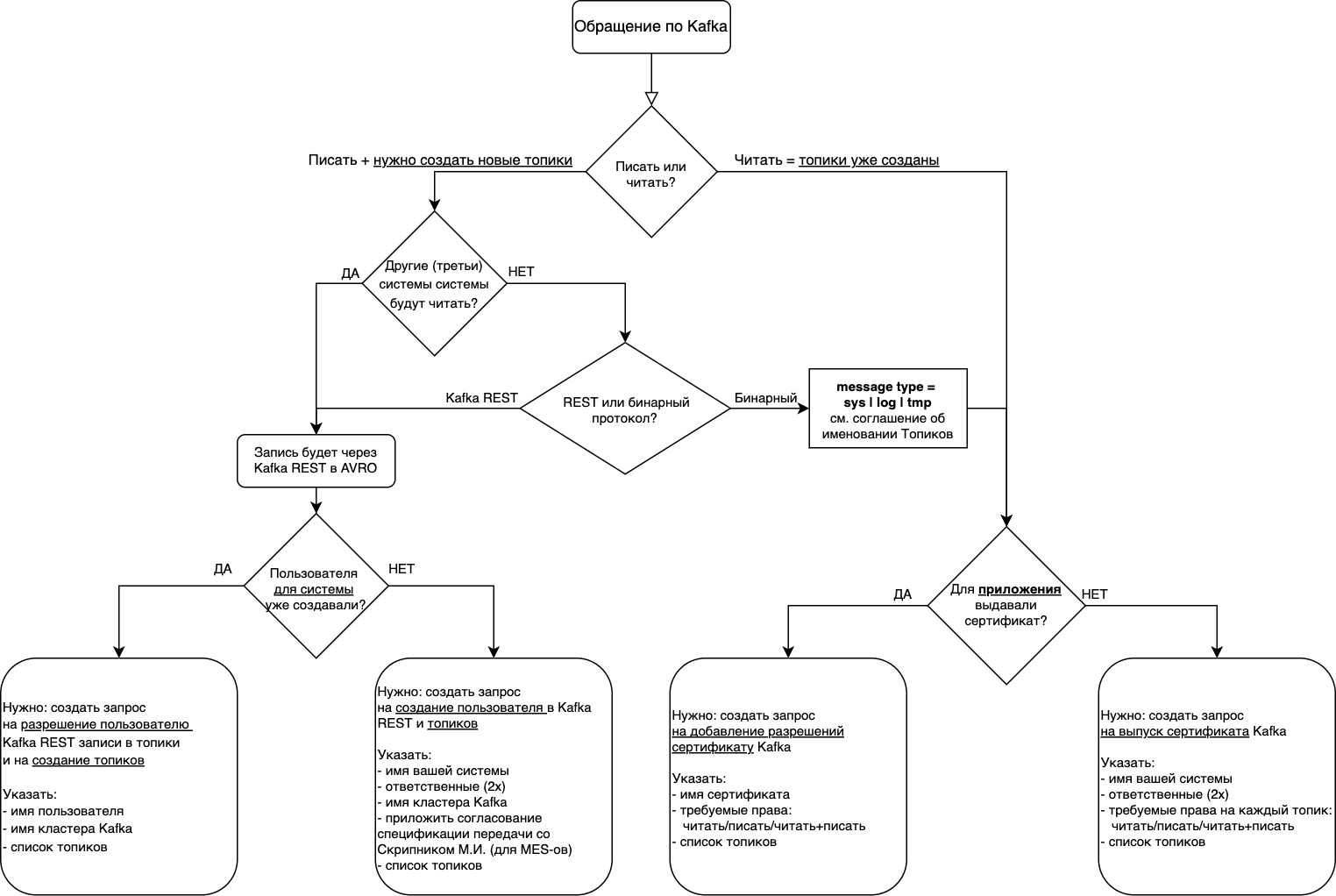
Для упрощения понимания концепции, и пока не перешли полностью на Self-Service для Kafka на Портале, мы сделали следующую flow диаграмму:
Пара статей про подходы к именованию топиков:
Apache Kafka: Topic Naming Conventions/2020
Kafka Topic Naming Conventions/2017
Kafka REST Proxy
Изначально, в компании интеграцию с Kafka на запись для систем сделали через NiFi: http интерфейс, формат данных JSON, схемы к сообщениям хранились так же в NiFi. В случае несоответствия сообщения схеме, данные все равно записывались, но помещались в очередь "битые". Данный подход имел ряд проблем: NiFi вызывал вопросы, были проблемы с битыми сообщениями и аргументами "с нашей стороны пуля вылетела". Хотелось перепроектировать интеграции так, чтобы пуля "не вылетала", если она не соответствует контракту.
И ещё, на мой взгляд, единственный, кто может обеспечить качество данных — это источник (и, как мне кажется, кто знает, как их лучше уложить/архивировать).
Итого, требования к интеграциям:
выбор бинарного формата, чтобы в стандартное сообщение в 1Мб помещалось больше полезных данных
эволюция схем, предоставить отправителю возможность управлять схемами и версиями
не принимать сообщения в Kafka, если не соответствуют контракту
как можно большая поддержка и распространенность формата, наличие готовых инструментов, библиотек, поддержка формата в Hadoop
По формату решили использовать AVRO. Для предоставления возможности записи в Kafka через HTTP-протокол, контроля формата сообщений и хранения схем, мы выбрали связку Confluent Kafka Rest и Confluent Schema Registry.
Для авторизации перед Kafka-REST, мы написали программу на Go - RA, которая выполняет следующие функции:
проверяет, что имя топика соответствует конвенции имен
проверяет авторизацию и аутентификацию пользователя для топика (или схемы)
проверяет Content-Type для топика (обязывает отправлять AVRO)
Пример конфигурации (разрешаем пользователю l4-example создание и запись в топики его ИС):
auth:
prefix: /topics/
urlvalidreg: ^\d{3}-\d(-\d{3}-\d)?\.[a-z][a-z0-9-]+[a-z0-9]\.(db|cdc|bin|cmd|sys|log|tmp)\.([a-z0-9][a-z0-9-]*[a-z0-9]\.)+\d+$
acl:
- path: ^000-0\.l4-example\.db\.+?$
users:
- l4-example
methods:
- post
contenttype:
- application/vnd.kafka.avro.v2+jsonАвторизацию интегрировали в Nginx для обоих сервисов (Rest и Schema Registry) через опцию auth_request.
Пример секции auth_request:
auth_request /auth;
location = /auth {
internal;
proxy_pass http://ra:8080;
proxy_pass_request_body off;
proxy_set_header Content-Length "";
proxy_set_header X-Original-URI $request_uri;
proxy_set_header X-Original-Method $request_method;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Service "kafka-rest";
}Kafka REST и Schema Registry работают в HA-режиме и позволяют горизонтально масштабироваться.
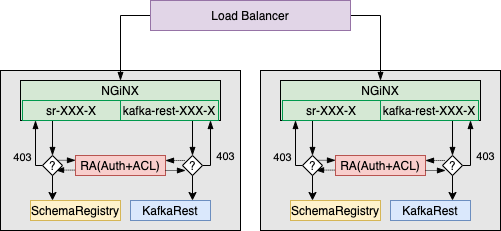
Schema Registry на продуктивных и тестовых кластерах доступна только в режиме Read-Only, т.е. все могут получить любую схему, но зарегистрировать её можно только через Kafka REST. Schema Registry Dev кластера доступна без какой-либо авторизации и ограничений. Схемы продуктивных сред на регулярной основе выгружаются в Confluence для возможности быстро посмотреть схему топика или текстового поиска по ним.
Репликация данных в централизованный кластер
Кластеры Kafka разных производственных площадок НЛМК находятся за Firewall. Мы реплицируем данные из этих Kafka в централизованный кластер, чтобы уменьшить количество клиентов, которые обращаются в технологический сегмент, и собрать все данные в одном кластере.
Для репликации мы используем программу, написанную нами на python. Она умеет реплицировать топики в формате Confluent-Avro из одного кластера в другой с минимальными изменениями и поддерживает Exactly Once.
Логика ее проста:
в целевом кластере создается топик с таким же количеством партиций, как и в исходном кластере
при записи в целевой кластер номер партиции сохраняется
составляется соответствие: номер схемы в исходном кластере - номер схемы в целевом. При необходимости, схема регистрируются в Schema Registry целевого кластера
в исходном бинарном сообщении заменяется только номер схемы (без десериализация в AVRO)
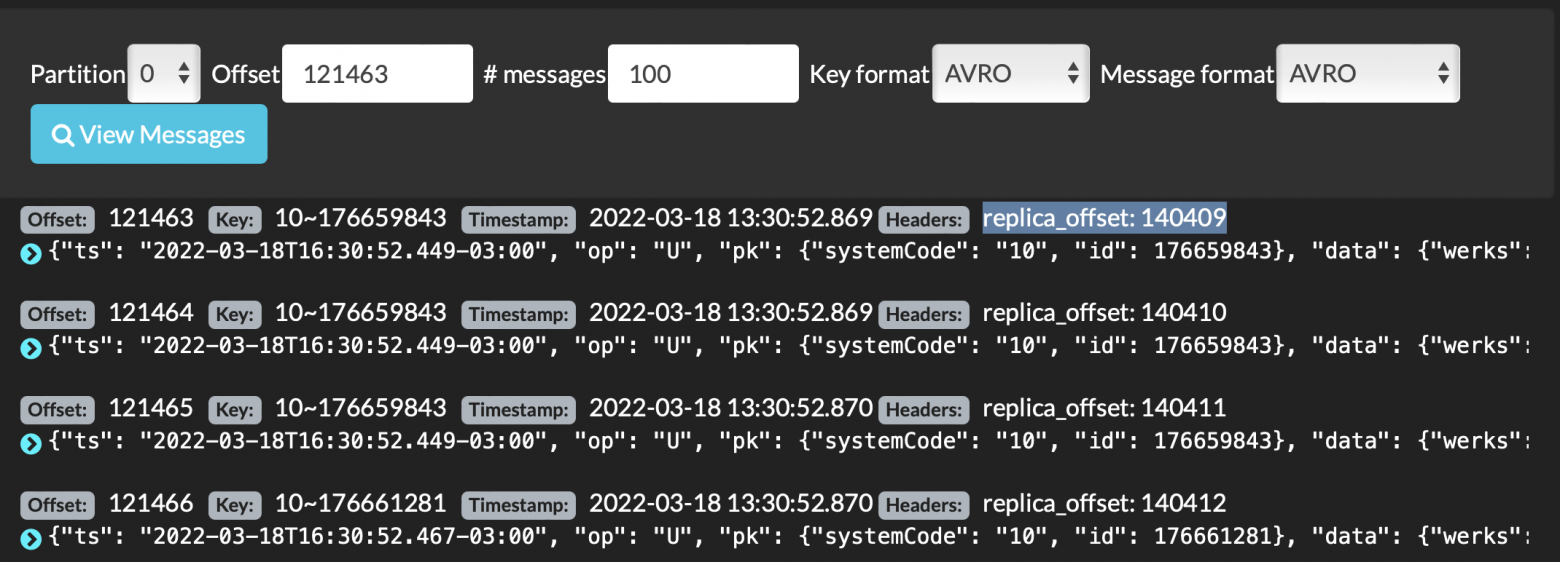
для поддержки Exactly Once, при записи к сообщению в Headers добавляем offset в исходном топике и используем эту информацию для начального выставления смещений или при сбоях
Пример сообщений в целевом кластере
Требования к AVRO схеме
Для топиков, которые пишутся в AVRO формате, мы решили стандартизовать базовый формат сообщений (схему), правила именования полей и пространств, чтобы у подписчиков не было проблем с получением данных.
За основу взяли стиль для Java от Google:
https://google.github.io/styleguide/javaguide.html#s5.2.1-package-names
https://docs.oracle.com/javase/tutorial/java/package/namingpkgs.html
И получилось:
наименования (name) всех атрибутов должны быть в формате camelCase (состоять только из букв и цифр и не начинаться с цифры) и с учетом следующих требований:
Если у атрибута "type" - "record", то наименование (name) должно начинаться с большой буквы
Если у атрибута "type" не "record", то наименование (name) должно начинаться с маленькой буквы
атрибут "namespace" состоит из префикса "
ORG_NAME." иdataset name(точки и тире удаляются, после них буква заменяется на заглавную)значение заглавного атрибута "name" должно начинаться с большой буквы.
Базовая (обязательная для всех) схема сообщений топика выглядит так
{
"namespace": "__AVRO_ROOT_NAMESPACE__",
"type": "record",
"name": "__AVRO_ROOT_NAME__",
"doc": "Example message",
"fields": [
{"name": "ts", "type": "string", "doc": "Время события в ISO 8601:2004 с указанием TZ"},
{"name": "op", "type": {
"type": "enum", "name": "EnumOp", "namespace": "ORG_NAME",
"symbols": ["U", "D", "I"]
}, "doc": "Вид операции [U]pdate, [D]elete, [I]nsert"
},
{"name": "pk",
"type": {"type": "record", "name":"PkType", "namespace": "__AVRO_DATASET_NAMESPACE__",
"fields":
[
{ "name": "pkID", "type":"string"}
]
},
"doc": "Первичный ключ записи в виде структуры"
},
{
"name": "sys",
"type": ["null", {
"name": "Sys", "namespace": "ORG_NAME",
"type": "record",
"fields": [
{"name": "seqID", "type": "long", "default": -1,"doc": "Монотонно возрастающий счетчик для проверки или восстановления оригинальной последовательности"},
{"name": "traceID", "type": "string", "default": "", "doc": "Сквозной Trace ID (обычно UUID)"}
]
}],
"default": null,
"doc": "Системные поля, заполняемые источником"
},
{
"name": "metadata",
"type": ["null", {
"type": "record",
"name": "Metadata", "namespace": "ORG_NAME",
"fields":[
{"name": "kafkaKeySchemaID","type": "int","default": -1, "doc":"Версия схемы ключа"},
{"name": "kafkaValueSchemaID","type": "int","default": -1, "doc": "Версия схемы значения"},
{"name": "kafkaKey","type": "string", "default": "", "doc": "Ключ в Kafka"},
{"name": "kafkaPartition","type": "int","default": -1, "doc": "Номер партиции"},
{"name": "kafkaOffset","type": "long","default": -1, "doc": "Offset в Kafka"},
{"name": "kafkaTimestamp","type": "string", "default": "", "doc":"Время сообщения в Kafka"},
{"name": "kafkaTopic","type": "string", "default": "", "doc":"Имя топика"},
{"name": "kafkaHeaders", "type": ["null", {"type": "map", "values": "string"}], "default": null}
]
}],
"doc": "Мета структура, заполняется Подписчиком после чтения",
"default": null
},
{"name": "data",
"type":["null",{
"type": "record",
"name": "RecordData", "namespace": "__AVRO_DATASET_NAMESPACE__",
"fields":[
{"name": "message", "type": "string", "doc": "Пример передачи строки message"}
]
}],
"doc": "Полезная нагрузка"
}
]
}Где:
AVRO_ROOT_NAMESPACE Корневое пространство имен.
Генерируется из<dataset name>путем замены всехтиренаточкии добавления префиксаORG_NAME.Пример: имя топика:
000-0.l3-hy.db.sales.order-confirmation.0;
корневое пространство имен:ORG_NAME.l3.hy.AVRO_ROOT_NAME Корневое имя.
Генерируется как<message type>.<data name>.ver<version>, где первая и все буквы следующие заточкойилитирезаменяются на заглавные.Пример: имя топика:
000-0.l3-hy.db.sales.order-confirmation.0;
корневое имя:DbSalesOrderConfirmationVer0.AVRO_DATASET_NAMESPACE Namespace топика.
Генерируется как корневой namespace +<message type>.<data name>.ver<version>, все-заменяются на..Пример: имя топика:
000-0.l3-hy.db.sales.order-confirmation.0;
namespace топика:ORG_NAME.l3.hy.db.sales.order.confirmation.ver0.
Источник может расширять только структуры pk и data, сам корневой уровень изменять не разрешается.
Большинству подписчиков нужна мета информация к сообщению. С помощью неё можно проверить данные на предмет отсутствия пропусков, выстроить последовательность, точно указать на сообщение в случае проблем. Мы решили сразу заложить в базовую схему структуру под эту мета информацию. Ее заполняет подписчик, если ему это нужно.
Это решение позволило нам так же сохранять метаданные сообщений Kafka в Stage слой на HDFS и в HBase в AVRO формате.
Небольшие рекомендации по заполнению структуры data
Необходимо стараться сохранить исходный тип данных или следить, чтобы аналог не потерял в точности.
Тип float не подходит для передачи отчетных типов.
Возможные способы решения проблемы:
методом домножения на множитель и приведением к целочисленному типу.
Статический множитель:
пример:"name": "priceX10000", "type": "long", "doc": " Цена домноженная на 10000"Динамический множитель:
{"name": "price", "type": {"type": "record", "name":"Price", "fields": [ { "name": "value", "type": "long", "doc":"Цена домноженная на multiplier"}, { "name": "multiplier", "type": "int", "doc":"Множитель"}, ] },
приведение к меньшим единицами измерения (в зависимости от точности измерений, а лучше - с запасом):
целое число секунд вместо дробных часов
целое число метров вместо дробных километров
Продолжение следует...
В следующей части я расскажу о том, как мы централизованно доставляем данные потребителям и в корпоративное хранилище на базе Hadoop. И немного про наш Портал самообслуживания.



