
Привет, Хабр!
Нас давно занимала тема использования Apache Kafka в качестве хранилища данных, рассмотренная с теоретической точки зрения, например, здесь. Тем интереснее предложить вашему вниманию перевод материала из блога Twitter (оригинал — декабрь 2020), в котором описан нетрадиционный вариант использования Kafka в качестве базы данных для обработки и воспроизведения событий. Надеемся, статья будет интересна и натолкнет вас на свежие мысли и решения при работе с Kafka.
Когда разработчики потребляют общедоступные данные Twitter через API Twitter, они рассчитывают на надежность, скорость и стабильность. Поэтому некоторое время назад в Twitter запустили Account Activity Replay API для Account Activity API, чтобы разработчикам было проще обеспечить стабильность своих систем. Account Activity Replay API – это инструмент восстановления данных, позволяющий разработчикам извлекать события со сроком давности до пяти дней. Этот API восстанавливает события, которые не были доставлены по разным причинам, в том числе, из-за аварийных отказов сервера, происходивших при попытках доставки в режиме реального времени.
Инженеры Twitter стремились не только создать API, которые будут положительно восприняты разработчиками, но и:
По этой причине при работе над созданием системы воспроизведения, на которую полагается при работе API, было решено взять за основу имеющуюся систему для работы в режиме реального времени, на которой основан Account Activity API. Так удалось повторно воспользоваться имеющимися разработками и минимизировать переключение контекста и объем обучения, которые были бы гораздо значительнее, если бы для описанной работы создавалась совершенно новая система.
Решение для работы в режиме реального времени базируется на архитектуре «публикация-подписка». Для такой цели, учитывая поставленные задачи и создавая уровень хранения информации, с которого она будет считываться, возникла идея переосмыслить известную потоковую технологию — Apache Kafka.
События, происходящие в режиме реального времени, производятся в двух датацентрах. Когда эти события порождаются, их записывают в топики, работающие по принципу «публикация-подписка», которые в целях обеспечения избыточности подвергаются перекрестной репликации в двух датацентрах.
Доставлять требуется не все события, поэтому все события фильтруются внутренним приложением, которое потребляет события из нужных топиков, сверяет каждое с набором правил в хранилище ключей и значений, и решает, должно ли событие быть доставлено конкретному разработчику через общедоступный API. События доставляются через вебхук, а URL каждого вебхука принадлежит разработчику, идентифицируемому уникальным ID.
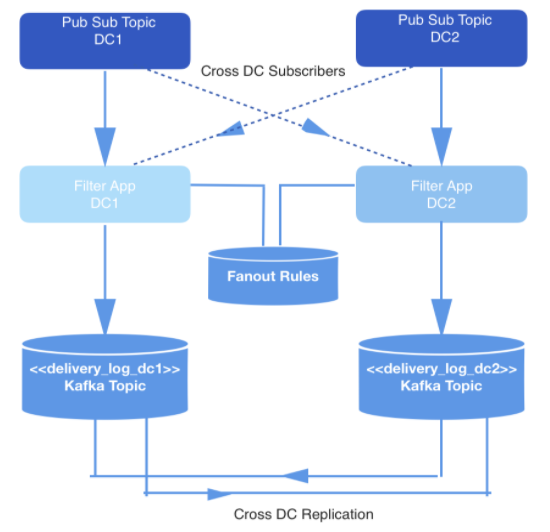
Рис. 1: Конвейер генерации данных
Как правило, при создании системы воспроизведения, требующей подобного хранилища данных, выбирается архитектура на основе Hadoop и HDFS. В данном случае, напротив, был выбран Apache Kafka, по двум причинам:
В данном случае основная нагрузка ложится на конвейер воспроизведения данных, работающий в режиме реального времени и гарантирующий, что события, которые должны быть доставлены каждому разработчику, будут храниться в Kafka. Назовем топик Kafka delivery_log; по одному такому топику будет на каждый датацентр. Эти топики подвергаются перекрестной репликации для обеспечения избыточности, что позволяет выдавать из одного датацентра запрос на репликацию. Перед доставкой сохраненные таким образом события проходят дедупликацию.
В данном топике Kafka мы создаем множество партиций, использующих задаваемое по умолчанию семантическое сегментирование. Следовательно, партиции соответствуют хешу webhookId разработчика, и этот id служит ключом каждой записи. Предполагалось использовать статическое сегментирование, но в итоге от него отказались из-за повышенного риска, что в одной партиции окажется больше данных, чем в других, если какие-то разработчики в ходе своей деятельности генерируют больше событий, чем другие. Вместо этого было выбрано фиксированное количество партиций, по которым распределяются данные, а стратегия сегментирования была оставлена по умолчанию. Таким образом снижается риск возникновения несбалансированных партиций, а также не приходится считывать все партиции в топике Kafka.
Напротив, на основе webhookId, для которого поступает запрос, сервис воспроизведения определяет конкретную партицию, с которой будет происходить считывание, и поднимает новый потребитель Kafka для данной партиции. Количество партиций в топике не меняется, так как от этого зависит хеширование ключей и распределение событий.
Чтобы минимизировать пространство под хранилище данных, информация подвергается сжатию при помощи алгоритма snappy, поскольку известно, что большая часть информации в описываемой задаче обрабатывается на стороне потребителя. Кроме того, snappy быстрее поддается декомпрессии, нежели другие алгоритмы сжатия, поддерживаемые Kafka: gzip и lz4.
В системе, сконструированной таким образом, API отправляет запросы на воспроизведение. В составе полезной нагрузки каждого валидируемого запроса приходит webhookId и диапазон данных, для которых должны быть воспроизведены события. Эти запросы долговременно хранятся в MySQL и ставятся в очередь до тех пор, пока их не подхватит сервис воспроизведения. Диапазон данных, указанный в запросе, используется, чтобы определить смещение, с которым нужно начать считывание с диска. Функция
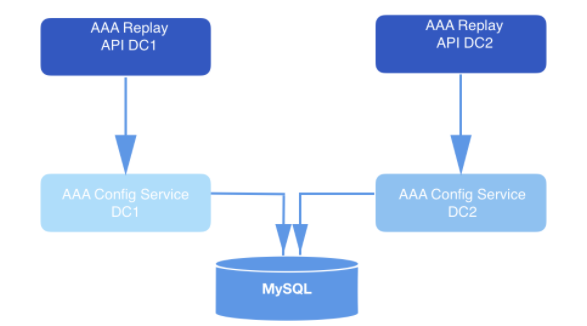
Рис. 2: Система воспроизведения. Она получает запрос и отправляет его сервису конфигурации (уровень доступа к данным) для дальнейшего долговременного хранения в базе данных.
Инстансы сервиса воспроизведения обрабатывают каждый запрос на воспроизведение. Инстансы координируются друг с другом при помощи MySQL, чтобы обработать следующую запись на воспроизведение, хранимую в базе данных. Каждый рабочий процесс, обеспечивающий воспроизведение, периодически опрашивает MySQL, чтобы узнать, нет ли там задания, которое следует обработать. Запрос переходит от состояния к состоянию. Запрос, который не был подхвачен для обработки, находится в состоянии OPEN. Запрос, который только что был выведен из очереди, находится в состоянии STARTED. Запрос, обрабатываемый в данный момент, находится в состоянии ONGOING. Запрос, претерпевший все переходы, оказывается в состоянии COMPLETED. Рабочий процесс, отвечающий за воспроизведение, подбирает только такие запросы, обработка которых еще не началась (то есть, находящиеся в состоянии OPEN).
Периодически, после того, как рабочий процесс выведет запрос из очереди на обработку, он отстукивается в таблице MySQL, оставляя метки времени и демонстрируя тем самым, что задание на воспроизведение до сих пор обрабатывается. В случаях, когда инстанс воспроизводящего рабочего процесса отмирает, не успев закончить обработку запроса, такие задания перезапускаются. Следовательно, воспроизводящие процессы выводят из очереди не только запросы, находящиеся в состоянии OPEN, но и подбирают те запросы, что были переведены в состояние STARTED или ONGOING, но не получили отстука в базе данных, спустя заданное количество минут.
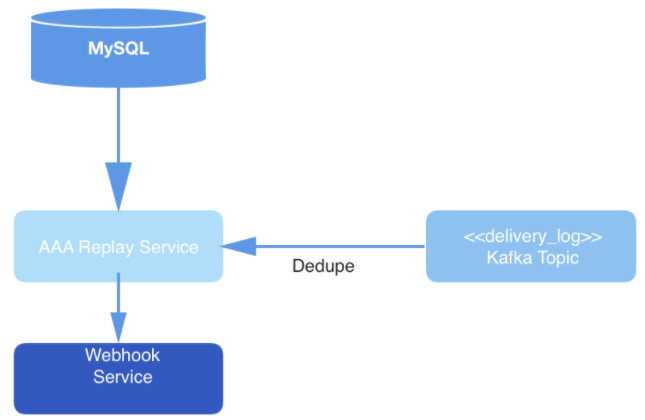
Рис. 3: Уровень доставки данных: сервис воспроизведения опрашивает MySQL по поводу нового задания на обработку запроса, потребляет запрос из топика Kafka и доставляет события через сервис Webhook.
В конечном итоге события из топика проходят дедупликацию в процессе считывания, а затем публикуются по URL вебхука конкретного пользователя. Дедупликация выполняется путем ведения кэша считываемых событий, которые при этом хешируются. Если попадется событие с хешем, идентичный которому уже имеется в хэше, то оно доставлено не будет.
В целом, такое использование Kafka нельзя назвать традиционным. Но в рамках описанной системы Kafka успешно работает в качестве хранилища данных и участвует в работе API, который способствует как удобству работы, так и легкости доступа к данным при восстановлении событий. Сильные стороны, имеющиеся в системе для работы в режиме реального времени, пригодились и в рамках такого решения. Кроме того, темпы восстановления данных в такой системе полностью оправдывают ожидания разработчиков.
Нас давно занимала тема использования Apache Kafka в качестве хранилища данных, рассмотренная с теоретической точки зрения, например, здесь. Тем интереснее предложить вашему вниманию перевод материала из блога Twitter (оригинал — декабрь 2020), в котором описан нетрадиционный вариант использования Kafka в качестве базы данных для обработки и воспроизведения событий. Надеемся, статья будет интересна и натолкнет вас на свежие мысли и решения при работе с Kafka.
Введение
Когда разработчики потребляют общедоступные данные Twitter через API Twitter, они рассчитывают на надежность, скорость и стабильность. Поэтому некоторое время назад в Twitter запустили Account Activity Replay API для Account Activity API, чтобы разработчикам было проще обеспечить стабильность своих систем. Account Activity Replay API – это инструмент восстановления данных, позволяющий разработчикам извлекать события со сроком давности до пяти дней. Этот API восстанавливает события, которые не были доставлены по разным причинам, в том числе, из-за аварийных отказов сервера, происходивших при попытках доставки в режиме реального времени.
Инженеры Twitter стремились не только создать API, которые будут положительно восприняты разработчиками, но и:
- Повысить производительность труда инженеров;
- Добиться, чтобы систему было легко поддерживать. В частности, минимизировать необходимость переключения контекстов для разработчиков, SRE-инженеров и всех прочих, кто имеет дело с системой.
По этой причине при работе над созданием системы воспроизведения, на которую полагается при работе API, было решено взять за основу имеющуюся систему для работы в режиме реального времени, на которой основан Account Activity API. Так удалось повторно воспользоваться имеющимися разработками и минимизировать переключение контекста и объем обучения, которые были бы гораздо значительнее, если бы для описанной работы создавалась совершенно новая система.
Решение для работы в режиме реального времени базируется на архитектуре «публикация-подписка». Для такой цели, учитывая поставленные задачи и создавая уровень хранения информации, с которого она будет считываться, возникла идея переосмыслить известную потоковую технологию — Apache Kafka.
Контекст
События, происходящие в режиме реального времени, производятся в двух датацентрах. Когда эти события порождаются, их записывают в топики, работающие по принципу «публикация-подписка», которые в целях обеспечения избыточности подвергаются перекрестной репликации в двух датацентрах.
Доставлять требуется не все события, поэтому все события фильтруются внутренним приложением, которое потребляет события из нужных топиков, сверяет каждое с набором правил в хранилище ключей и значений, и решает, должно ли событие быть доставлено конкретному разработчику через общедоступный API. События доставляются через вебхук, а URL каждого вебхука принадлежит разработчику, идентифицируемому уникальным ID.
Рис. 1: Конвейер генерации данных
Хранение и сегментирование
Как правило, при создании системы воспроизведения, требующей подобного хранилища данных, выбирается архитектура на основе Hadoop и HDFS. В данном случае, напротив, был выбран Apache Kafka, по двум причинам:
- Система для работы в режиме реального времени была по принципу «публикация-подписка», органичному для устройства Kafka
- Объем событий, который требуется хранить в системе воспроизведения, исчисляется не петабайтами. Мы храним данные не более чем за несколько дней. Кроме того, обращаться с заданиями MapReduce для Hadoop затратнее и медленнее, чем потреблять данные в Kafka, и первый вариант не отвечает ожиданиям разработчиков.
В данном случае основная нагрузка ложится на конвейер воспроизведения данных, работающий в режиме реального времени и гарантирующий, что события, которые должны быть доставлены каждому разработчику, будут храниться в Kafka. Назовем топик Kafka delivery_log; по одному такому топику будет на каждый датацентр. Эти топики подвергаются перекрестной репликации для обеспечения избыточности, что позволяет выдавать из одного датацентра запрос на репликацию. Перед доставкой сохраненные таким образом события проходят дедупликацию.
В данном топике Kafka мы создаем множество партиций, использующих задаваемое по умолчанию семантическое сегментирование. Следовательно, партиции соответствуют хешу webhookId разработчика, и этот id служит ключом каждой записи. Предполагалось использовать статическое сегментирование, но в итоге от него отказались из-за повышенного риска, что в одной партиции окажется больше данных, чем в других, если какие-то разработчики в ходе своей деятельности генерируют больше событий, чем другие. Вместо этого было выбрано фиксированное количество партиций, по которым распределяются данные, а стратегия сегментирования была оставлена по умолчанию. Таким образом снижается риск возникновения несбалансированных партиций, а также не приходится считывать все партиции в топике Kafka.
Напротив, на основе webhookId, для которого поступает запрос, сервис воспроизведения определяет конкретную партицию, с которой будет происходить считывание, и поднимает новый потребитель Kafka для данной партиции. Количество партиций в топике не меняется, так как от этого зависит хеширование ключей и распределение событий.
Чтобы минимизировать пространство под хранилище данных, информация подвергается сжатию при помощи алгоритма snappy, поскольку известно, что большая часть информации в описываемой задаче обрабатывается на стороне потребителя. Кроме того, snappy быстрее поддается декомпрессии, нежели другие алгоритмы сжатия, поддерживаемые Kafka: gzip и lz4.
Запросы и обработка
В системе, сконструированной таким образом, API отправляет запросы на воспроизведение. В составе полезной нагрузки каждого валидируемого запроса приходит webhookId и диапазон данных, для которых должны быть воспроизведены события. Эти запросы долговременно хранятся в MySQL и ставятся в очередь до тех пор, пока их не подхватит сервис воспроизведения. Диапазон данных, указанный в запросе, используется, чтобы определить смещение, с которым нужно начать считывание с диска. Функция
offsetForTimes объекта Consumer используется для получения смещений.Рис. 2: Система воспроизведения. Она получает запрос и отправляет его сервису конфигурации (уровень доступа к данным) для дальнейшего долговременного хранения в базе данных.
Инстансы сервиса воспроизведения обрабатывают каждый запрос на воспроизведение. Инстансы координируются друг с другом при помощи MySQL, чтобы обработать следующую запись на воспроизведение, хранимую в базе данных. Каждый рабочий процесс, обеспечивающий воспроизведение, периодически опрашивает MySQL, чтобы узнать, нет ли там задания, которое следует обработать. Запрос переходит от состояния к состоянию. Запрос, который не был подхвачен для обработки, находится в состоянии OPEN. Запрос, который только что был выведен из очереди, находится в состоянии STARTED. Запрос, обрабатываемый в данный момент, находится в состоянии ONGOING. Запрос, претерпевший все переходы, оказывается в состоянии COMPLETED. Рабочий процесс, отвечающий за воспроизведение, подбирает только такие запросы, обработка которых еще не началась (то есть, находящиеся в состоянии OPEN).
Периодически, после того, как рабочий процесс выведет запрос из очереди на обработку, он отстукивается в таблице MySQL, оставляя метки времени и демонстрируя тем самым, что задание на воспроизведение до сих пор обрабатывается. В случаях, когда инстанс воспроизводящего рабочего процесса отмирает, не успев закончить обработку запроса, такие задания перезапускаются. Следовательно, воспроизводящие процессы выводят из очереди не только запросы, находящиеся в состоянии OPEN, но и подбирают те запросы, что были переведены в состояние STARTED или ONGOING, но не получили отстука в базе данных, спустя заданное количество минут.
Рис. 3: Уровень доставки данных: сервис воспроизведения опрашивает MySQL по поводу нового задания на обработку запроса, потребляет запрос из топика Kafka и доставляет события через сервис Webhook.
В конечном итоге события из топика проходят дедупликацию в процессе считывания, а затем публикуются по URL вебхука конкретного пользователя. Дедупликация выполняется путем ведения кэша считываемых событий, которые при этом хешируются. Если попадется событие с хешем, идентичный которому уже имеется в хэше, то оно доставлено не будет.
В целом, такое использование Kafka нельзя назвать традиционным. Но в рамках описанной системы Kafka успешно работает в качестве хранилища данных и участвует в работе API, который способствует как удобству работы, так и легкости доступа к данным при восстановлении событий. Сильные стороны, имеющиеся в системе для работы в режиме реального времени, пригодились и в рамках такого решения. Кроме того, темпы восстановления данных в такой системе полностью оправдывают ожидания разработчиков.
")