

Всем привет! Я Иван, старший инженер-тестировщик в КРОК. Уже 6 лет занимаюсь тестированием ПО. Из них 3 года внедряю автоматизацию тестирования на различных проектах — люблю всё автоматизировать. На рабочей машине много разных “батников” и bash-скриптов, которые призваны упрощать жизнь.
Недавно у нас стартовал проект по модернизации и импортозамещению системы электронного документооборота (СЭД) в одной крупной организации. Система состоит из основного приложения и двух десятков микросервисов, в основном — для построения отчётов и интеграции с другими подсистемами. Сейчас в проекте уже настроено больше 100 автотестов, и они сильно помогают при частых релизах, когда времени на регресс почти нет. Весь набор автотестов выполняется примерно за 25 минут, в среднем экономим до 3,5 часов ручной работы при каждом запуске. А запускаем мы их каждый день.
Дальше будет про то, как мы выбирали технологии и инструменты, какой каркас и подход к организации автотестов в итоге получился. И почему мы в КРОК решили тиражировать этот подход в других проектах, реализация которых основана на Content Management Framework (CMF) под СЭД. На базе CMF у нас есть комплексное решение для автоматизации процессов документооборота КСЭД 3.0. Конечно, отдельные решения по автотестам можно применять под любую СЭД.
Ещё расскажу про проблемы, и как мы их решали. Пост будет интересен и полезен, если в ваших автотестах необходимо подписывать документ электронной подписью (ЭП) в докер-образе браузера, проверять содержимое pdf файла, выполнять сравнение скриншотов или интегрироваться с одной из популярных Test Management System.
Что имели на входе
Много лет у заказчика была СЭД, которую мы же в КРОК делали на базе экосистемы Microsoft (.NET Framework, MS SQL Server, IIS, Active Directory). Но закон об импортозамещении ПО в госсекторе, ФЗ «О безопасности критической информационной инфраструктуры», плюс моральное устаревание существующей системы стали причиной решения о создании новой, уже на open source решениях.
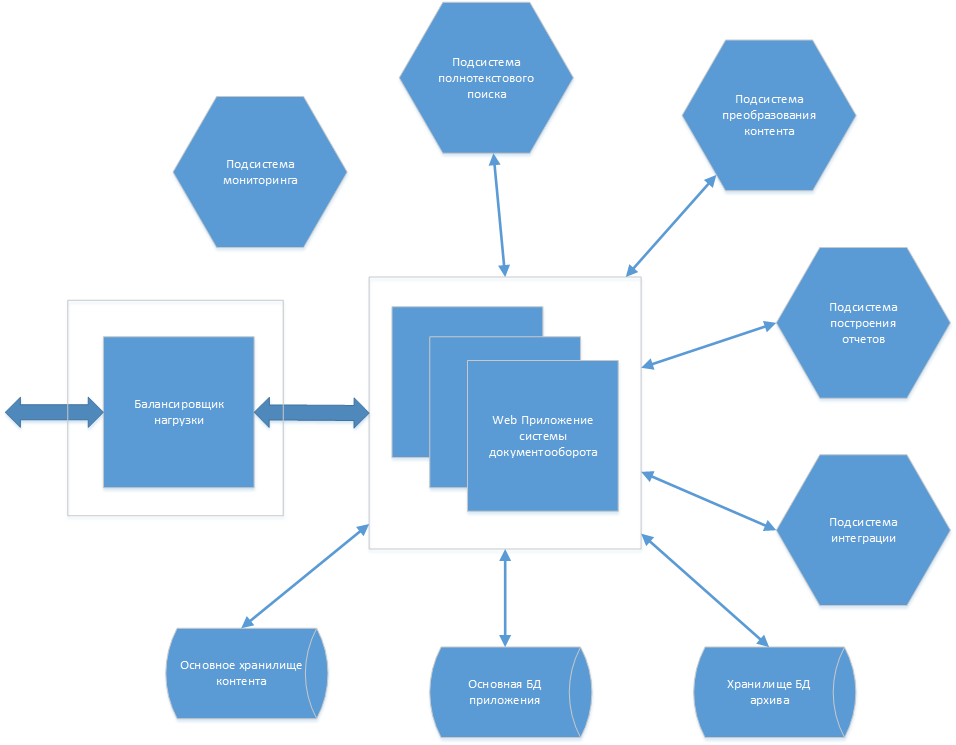
Основной функционал новой СЭД реализуется в едином приложении. Для масштабирования запускается несколько экземпляров приложения, которые находятся за балансировщиком нагрузки. Из приложения выделено несколько подсистем, развёртываемых в качестве отдельных сервисов, — это даёт более гибкое масштабирование.
UI реализуется с использованием фреймворка Vue.JS. Бэкенд, как писал ранее, разрабатывается на собственном Content Management Framework (CMF) с реализованными процессами под СЭД. Основа для него — JXFW (CROC Java Extendable FrameWork). Зарегистрирован в Едином реестре российских программ для ЭВМ и баз данных (от 29 Марта 2018, регистрационный номер ПО: 4309). Про JXFW мой коллега писал отдельно вот здесь. Данные хранятся в БД PostgreSQL. Автоматизация бизнес-процессов выполнена при помощи Camunda. В качестве брокера сообщений используется RabbitMQ. Для наглядности, укрупненная физическая архитектура системы выглядит примерно так:
Почему решили делать автотесты
Проект нужно было сдать в короткие сроки, с очень частыми релизами. Мне было очевидно, что автоматизация тестирования должна нам помочь. Оставалось убедить в этом руководство.
Я сел и посчитал, сколько времени уйдёт на ручное тестирование базового функционала при каждом релизе, и сколько времени нужно для написания и поддержки автотестов. В итоге получилось, что в среднем на двадцатый прогон тесты окупятся и далее будут приносить экономическую выгоду. Учитывая, что в неделю мы выпускаем несколько релизов, то приблизительно уже через 1,5-2 месяца мы должны получить профит. Изначально таблица расчётов выглядела так:
Время написания автотестов | Ручное выполнение | Частота выполнения | Поддержка тестов (в неделю) |
70 ЧЕЛ-Ч | 3,5-4 ЧЕЛ-Ч | 3 раза в неделю | 3 ЧЕЛ-Ч |
На практике получилось даже лучше — тесты сейчас запускаются каждый день. Но немного увеличилось общее время написание тестов — на 15 человеко-часов. Остальные показатели из таблицы не изменились.
В общем, на применение автоматизированных e2e тестов получили добро быстро. А я в глубине души понимал, что мы спасаем себя от постоянной рутинной работы и сокращаем время на регрессионное тестирование.
Чем будем работать: выбор технологий и инструментов
Каркас автотестов нужен был надёжный и универсальный, потому заморочились подбором инструментов.
С языком программирования никаких проблем не возникло — бэкенд был написан на Java, с которым в команде инженеров-тестировщиков почти все были знакомы. Дополнительно изучать не потребовалось. Всё удачно совпало, не пришлось разводить зоопарк языков в проекте, что тоже очень хорошо.
Чистый Selenium мне использовать не хотелось, так как существует прекрасный инструмент Selenide (про него много написано, например, здесь), который делает большое количество скрытой работы за нас и инкапсулирует в себе много сложной логики самого Selenium. Зачем изобретать велосипед, если ребята из “Codeborne” его уже сделали. Я раньше работал с этим фреймворком, и он мне понравился. Если коротко — это фреймворк для автоматизированного тестирования веб-приложений на основе Selenium WebDriver. Его основные преимущества:
Изящный API,
Поддержка Ajax для стабильных тестов,
Мощные селекторы,
Простая конфигурация.
С выбором “сборщика” тестов тоже проблем не возникло — взяли Apache Maven. Он используется во всём проекте, привносить что-то новое не хотелось. Изначально задумывались над тем, чтобы взять Gradle, так как он более гибок. Но как показало время, мы не делали ничего такого, с чем бы не справился Maven. Конфигурация для тестов в pom.xml довольно простая.
А вот определиться с выбором фреймворка для запуска тестов было немного сложнее. Изначально выбрали JUnit5, но потом передумали и взяли TestNG. С ним доводилось больше работать, и лично я считаю, что TestNG удобней, чем JUnit5.
Но, как говорится, каждому своё.
У нас есть тесты, которые должны сохранять порядок выполнения, потому что идут по единому процессу. Например, жизненный цикл документа. TestNG легко позволяет это делать установкой приоритета (параметр priority в аннотации @Test) в тестовом классе, а порядок тестовых классов задаётся в отдельном конфигурационном файле testng.xml.
Есть тесты, которые подготавливают данные для других. TestNG позволяет это легко и просто реализовать с помощью параметра dependsOnMethods. Я знаю, что использование последовательных тестов является антипаттерном. Но небольшая часть из них так организована. Нам необходимо иметь понятную структуру, каждой задаче по документу – отдельный тест. А также быть уверенным в целостности и работоспособности бизнес-процесса.
Мне нравится подход и общая организация управления выполнения тестов в TestNG. О ней подробней расскажу ниже.
Дальше определились с фреймворком для построения отчетов: берем всем известный и популярный Allure. Ещё рассматривался Report Portal. Но всё же Allure более легковесный, проще в установке и поддержке. Report Portal подойдёт для единого решения по хранению и отображению результатов множества проектов на уровне компании. Такой задачи перед нами не стояло.
Среду для запуска автотестов хотелось иметь единую, легко масштабируемую для параллельного запуска. Опять же, рассматривались два варианта: Selenoid и Selenium Grid. Я раньше использовал Grid, и он, на мой взгляд, имеет ряд недостатков:
сложность в настройке,
нестабильность и невысокая скорость работы,
сложность в добавлении и поддержке новых версий браузеров.
А вот с Selenoid нужно было разобраться, понять, что он из себя представляет и подходит ли нам. Выяснилось, что это хорошая альтернатива. В двух словах — это сервер, который позволяет запускать браузеры в docker-контейнерах. Легко настраивается и устанавливается в две команды, имеет замечательный UI-интерфейс, где можно отслеживать сессии в браузерах, даёт возможность записывать видео. Также, что очень важно, просто настраивать и конфигурировать браузеры в контейнерах.
Итого, имеем следующий основной технический стек:
Язык программирования | Java SE8 |
Фреймворк для написания тестов | Selenide |
Фреймворк для сборки тестов | Apache Maven |
Фреймворк для запуска тестов | TestNG |
Отчетность | Allure |
Среда для выполнения тестов | Selenoid |
Всё по полочкам: структура и организация тестов
Думаю, никого не удивлю, если скажу, что мы используем паттерн Page Object, позволяющий разделять логику выполнения тестов от их реализации. Все представляют структуру стандартного Java проекта. У нас для тестов она выглядит примерно так:
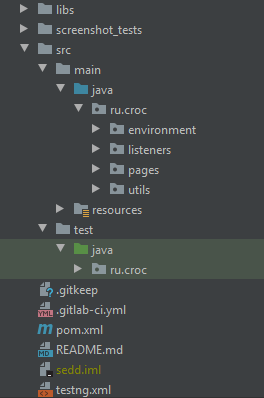
Всё, что является тестами, располагается в папке test. Весь же код по страницам, хелперы, ресурсы, глобальные переменные — хранятся в папке main.
В папке libs — драйвера под несколько браузеров (Chrome, Firefox, Opera) на случай, если необходимо запустить тесты локально.
В папке screenshot_tests — эталонные скриншоты для печатных форм документа. Там мы проверяем корректность формирования штампа ЭП — размеры, месторасположение на листе и т.д.
В папке src/main/java/ru/croc/environment находится класс для хранения и управления общими переменными. Сами переменные хранятся в файле configuration.properties (папка resources). Вот фрагмент из класса Environment, где отображён метод по загрузке конфигурационного файла и получению переменной адреса приложения:

Далее уже в нужном месте кода вызываем переменную Environment.URL_SEDD.
В папке src/main/java/ru/croc/listeners — класс TestListener, имплементирующий слушатель ITestListener и реализующий логику работы с TestRail. В нём отслеживаются успешно выполненные и упавшие тесты в методах onStart, onTestSuccess, onTestFailure. Об интеграции с Test Management System (далее TMS) подробно скажу далее.
В папке src/main/java/ru/croc/pages — классы, описывающие страницы приложения. Основные страницы находятся в корне папки. Также существуют виджеты — это общие элементы на страницах (модальные окна, панели). Их мы храним в папке src/main/java/ru/croc/pages/widgets.
В папке src/main/java/ru/croc/utils хранятся классы, отвечающие за:
Кастомные драйвера (драйвера под Selenoid),
Работу с БД,
Интеграцию с TestRail,
Скриншот тестирование,
API взаимодействие с системой,
Работу с pdf файлами,
Работу с пользователями,
Утилитарные методы — работа с датами, скачивание/загрузка файлов, работа с вкладками браузера и т.д.
Все вспомогательные ресурсы — скрипты, тестовые вложения, файлы для хранения пользователей, переменных — находятся в папке src/main/resources.
Вся общая логика по тестам вынесена в базовый класс BaseTest. Каждый тестовый класс наследуется от него. В BaseTest реализованы методы — setUp с аннотацией TestNG @BeforeSuite (выполняется перед всем тестовым набором, заданным в testng.xml) и tearDown с аннотацией @AfterMethod (выполняется после каждого тестового метода). В методе setUp реализована инициализация подходящих драйверов, выполнение скриптов и API запросов, если это необходимо, настройки работы с Allure. Нужно добавить, что автотесты выполняются на тестовой среде с тестовыми данными, поэтому мы можем менять или добавлять недостающие данные скриптами и не переживать за созданные тестовые задачи в системе.
В методе tearDown реализован перелогин в приложении. Сам файл testng.xml выглядит примерно так:

Здесь из важного:
Подключается слушатель TestListener, реализующий логику работы по интеграции с TestRail,
Настройки, которые дают возможность запускать тесты последовательно (parallel=none) и сохраняя порядок (preserve-order="true").
Последовательность тестов в самом классе реализуем указанием параметров в аннотации @Test. Пример:

Что ещё умеем: дополнительный функционал
Интеграция с TestRail
После каждого прогона автотестов в TestRail нам хотелось иметь новый Test Run с результатами выполнения. К счастью, есть хорошо задокументированный API и реализованный клиент, позволяющий без особых проблем интегрироваться с TestRail. На его основе можно разрабатывать функционал под свои нужды.
Мы создали класс TestRailUtil, в котором реализовали основные методы по работе с TMS. Пример:
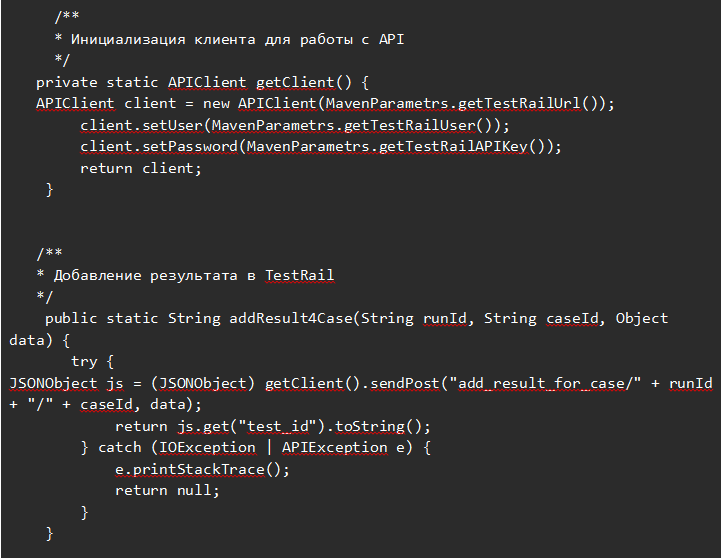

Думаю, здесь всё понятно по комментариям, подробно разбирать каждый метод не буду.
Всю логику перенесли, как и писал ранее, в класс TestListener имплементирующий ITestListener. Используем всего 3 переопределенных метода — onStart, onTestSuccess, onTestFailure.
Пример метода onTestSuccess:

Метод onTestFailure, который выполняется после проваленного теста, реализован аналогично, только вместо testPassed вызывается testFailed.
Здесь надо пояснить, что есть ещё отдельный csv файл, в котором хранятся имена методов вместе с id тест-кейса в TestRail, то есть идет сопоставление методов в коде с тест-кейсами в TMS. Фрагмент этого файла выглядит так:

Первая строка в файле нужна, чтобы обозначить набор кейсов в Test Run. Как раз в методе onStart мы создаем новый Test Run, например, с именем DemoAutoTest. Остальные же строки нам говорят, что тест-кейсу, например, с id 98162, соответствует метод в коде registrationIncoming.
На строке:

мы получаем список объектов с именем метода, id тест-кейса и именем тестрана, к которому эти кейсы относятся. А далее выполняется проверка на соответствие текущего выполняемого метода с тест-кейсом в TMS. Также добавлена дополнительная проверка в цикле на идентификацию необходимого Test Run:

Если бы Test Run был один, то данную проверку выполнять было бы не нужно, а так непонятно, в каком из них искать необходимый тест-кейс.
После запуска тестов в TestRail создаётся новый Test Run с датой и временем:
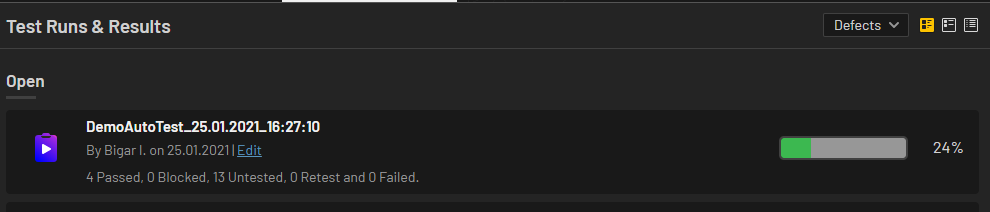
А по запущенным тестам проставляются результаты:
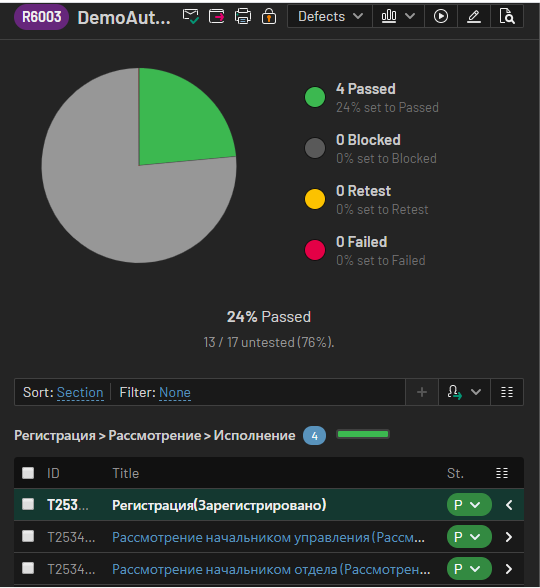
Вот так, не очень сложно, можно реализовать интеграцию с TestRail для отслеживания результатов выполненных автотестов.
Скриншот-тестирование печатных форм по документу
В системе документы подписываются ЭП, поэтому возникла задача выполнять проверку на корректность формирования штампа и шапки печатной формы после подписания. Сам штамп выглядит так:

Часто его содержимое заполнялось не корректными данными, также он мог менять свои размеры и местоположение. Поэтому приняли решение проверять его с помощью сравнения скриншотов. Для этих целей была выбрана библиотека Yandex aShot.
Сравнение выполняется на основе ранее подготовленных эталонных скриншотов и текущих, которые формируются при каждом выполнении тестов.
Для хранения наборов скриншотов, как писал ранее, необходимо было создать папку screenshot_tests. В ней:
папка для хранения наложенных друг на друга снимков с отмеченными различиями между ними — screenshot_tests/diff_screens,
папка для хранения эталонных скриншотов — screenshot_tests/etalon_screens,
папка для хранения скриншотов, сделанных в процессе выполнения тестов — screenshot_tests/test_screens.
Скриншот можно создавать как с помощью библиотеки aShot, так и с помощью методов Selenide. Так как мы делаем снимок превью печатной формы, то необходимо было делать скриншот непосредственно самого веб-элемента, отвечающего за предварительный просмотр, а не всей страницы целиком. Мы воспользовались методом Selenide.
Полностью метод снятия скриншота выглядит так:

Для сохранения используем метод:

И основной метод по сравнению снимков:

Далее в тесте вызываем методы по получению, сохранению скриншотов и потом выполняем их сравнение:

Если скриншоты совпадают, то тест выполняется успешно и папка screenshot_tests/diff_screens остается пустая, иначе срабатывает проверка:

и тест падает. Создаётся изображение diff_image_bottom.png с разницей, которая подсвечивается:

По нему сразу становится понятно, в чем проблема.
Проверка содержимого файла
При прохождении исходящего документа по процессу, где выполняется согласование и подписание, на определённом этапе формируется “Лист согласования” в формате *.pdf. Он содержит основные данные по документу (номер, краткое содержание, тип документа и тд), а также список всех согласующих. Выглядит он так:

Стояла задача проверить корректное заполнение данного листа. Глобально ее можно декомпозировать на блоки:
Скачать лист согласования,
Выполнить его синтаксический разбор,
Сделать проверку содержимого.
Загрузка листа согласования осуществляется нажатием на одну кнопку. Но есть небольшая проблема при получении этого файла из Selenoid: файл доступен во время запущенной текущей сессии браузера по специальной ссылке <selenoid-host>:4444/download/<SESSION_ID>/<FILE_NAME>. При этом имя файла — рандомное, в виде id. Мы не могли знать его заранее.
Поэтому сразу пришлось по ссылке <selenoid-host>:4444/download/<SESSION_ID>/ получать имя вложения, а потом уже формировать полную ссылку с именем и класть вложение на машину, откуда запускаются тесты. Метод этот выглядит так:

Для преобразования pdf в текст и выполнения его разбора использовалась библиотека Apache PDFBox. Метод по преобразованию можно увидеть ниже:

После того, как Лист согласования преобразован в текст, можно выполнять необходимые проверки в тесте:

Работа с пользователями
Так как система предполагает работу по задачам большим количеством пользователей, то необходимо было организовать их правильное хранение для быстрого, гибкого и легкого доступа. Не хотелось иметь проблем при добавлении нового или удалении старого пользователя. Поэтому возникла идея хранить логин, пароль, ФИО и роль пользователя в csv файле. Также создать отдельный класс User, который будет иметь все необходимые поля по сущности и методы быстрого поиска пользователя по ФИО или роли.
Пример файла:

Весь код класса User приводить не буду. А вот метод для поиска пользователя по должности, который используется в тестах, выглядит так:

Здесь выполняется формирование списка пользователей из файла, а потом поиск по заданной роли в системе. В тесте необходимый пользователь ищется по роли так:

Чтобы появился новый пользователь, необходимо его добавить в csv файл и тест. Для удаления — аналогично в обратном порядке. Больше ничего менять не нужно.
Запуск автотестов на CI/CD
В качестве сервера непрерывной интеграции у нас используется TeamCity.
Код проекта и код автотестов хранится в Gitlab. Для разработки используются следующие ветки:
master — основная ветка.
release — релизная ветка. Здесь хранится код по текущему релизу приложения. В момент релиза вливается в master.
feature — ветка с новым функционалом. Здесь хранится код по каждой отдельной функциональности. Потом вливается в release, далее в master. Может вливаться в мастер напрямую — “дальний релиз”.
Каждая новая версия приложения помечается тегом.
Тесты живут в том же репозитории, что и код приложения. Они также версионируются. Есть версия под релизную ветку, есть под ветку master.
На TeamCity есть два джоба для каждой версии:
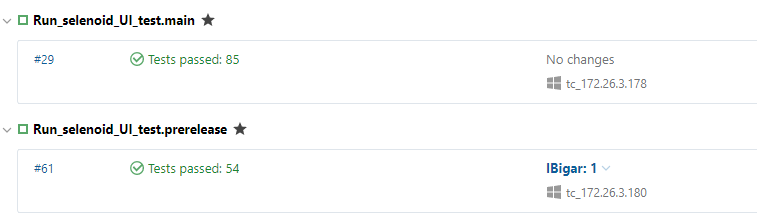
Они запускаются автоматически каждую ночь, при условии, что было успешное обновление тестовых стендов из необходимой ветки. Запускаются на удаленном сервере в Selenoid — за ними даже можно отдельно наблюдать через Selenoid UI или записать видео:
Для того, чтобы тесты запускались в определенной версии браузера, нужно создать кастомный драйвер с корректными параметрами подключения к Selenoid. У нас для собственного образа хрома он выглядит так:

Так как нужно было подписывать документы с помощью ЭП, пришлось создавать собственный докер-образ, чтобы там был КриптоПро, тестовые сертификаты и Cades plugin. Но про это чуть дальше.
Описывать настройку джобов по запуску тестов не буду. Но тут важно сказать, что для формирования отчетов прямо в TeamCity мы используем отдельный плагин allure-teamcity. Он выполняет генерацию Allure отчета с сохранением истории выполнении тестов, что очень важно. Есть возможность отчет вынести на отдельную вкладку:
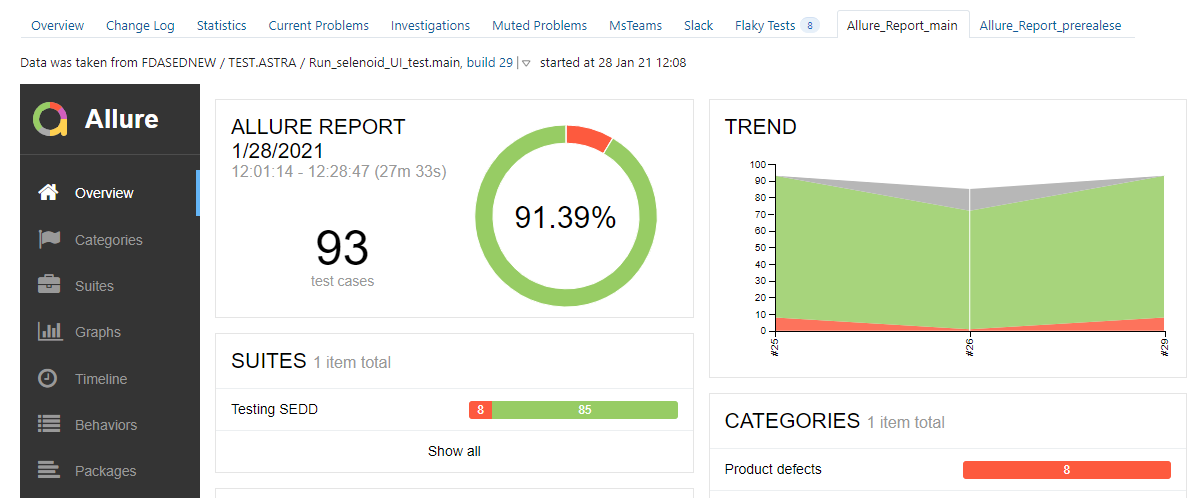
А можно смотреть прямо из артефактов, которые генерирует allure-teamcity plugin:
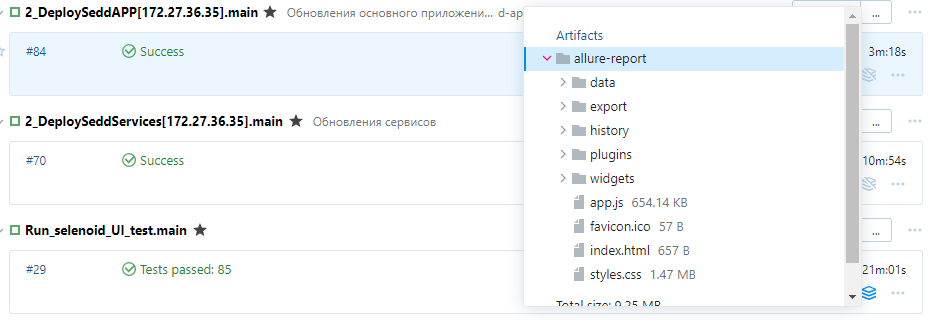
Также можно стандартными средствами TeamCity посмотреть на скоуп всех тестов. Какие выполнялись успешно, а какие провалились:
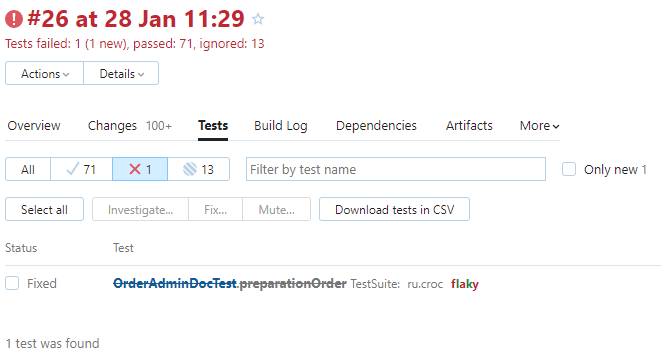
Если тест упал, выводится подробный стектрейс.
Создание докер-образа Chrome для подписания документов ЭП в Selenoid
Так как документы подписываются ЭП, для того, чтобы всё корректно работало, необходимо установить дополнительное ПО. А именно:
CryptoPro CSP 5.0
Cades plugin
Тестовые сертификаты
Это всё без особых проблем устанавливается локально, а вот для Selenoid пришлось создавать собственный image с предустановленным и настроенным ПО.
Чтобы сделать image, для удобства нужно создать Dockerfile, на основе которого он и будет собираться. Пример:

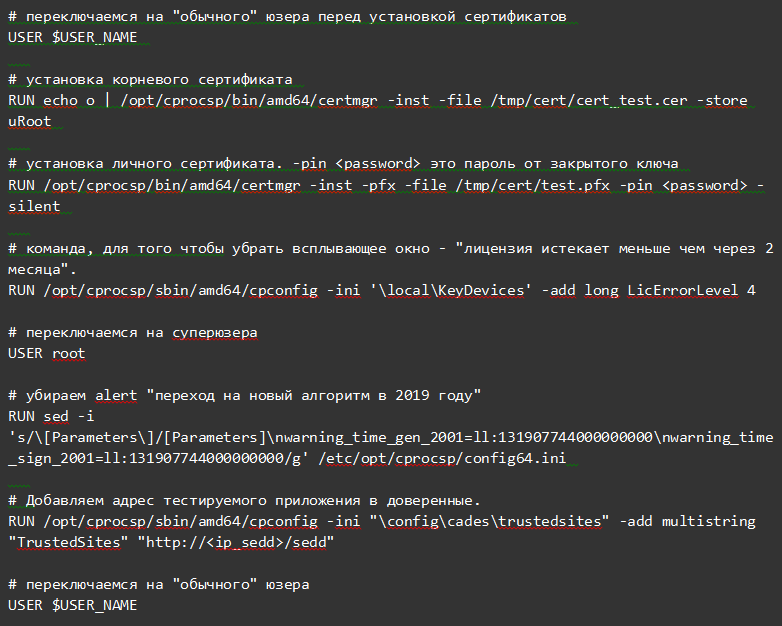
В Dockerfile используются дистрибутивы и сертификаты.
Необходимо создать две папки: distr и cert, — которые будут лежать вместе с Dockerfile.
Структура должна выглядеть так:

cert_test.cer — корневой тестовый сертификат.
test.pfx — личный тестовый сертификат.
linux-amd64_deb.tgz — дистрибутив CryptoPro CSP
cades_linux_amd64.tar.gz — дистрибутив Cades plugin
Для сборки образа надо зайти в Root folder и выполнить команду:

После успешной сборки будет сообщение:

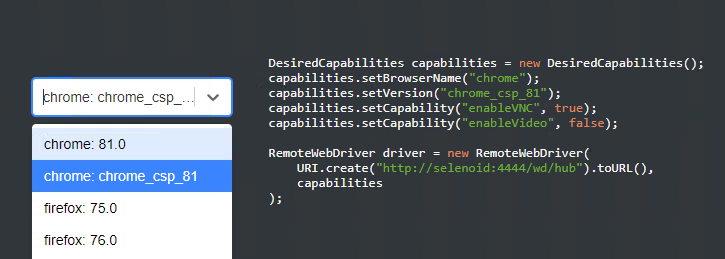
Далее, необходимо созданный образ добавить в Selenoid. Для этого правим файл .aerokube/selenoid/browsers.json

То есть устанавливаем созданный image в качестве одного из браузеров. Выполняем перезапуск Selenoid, чтобы новый образ подтянулся на сервер. Если всё успешно, то добавленный образ отобразиться в Selenoid UI:
Итоги, и что будет дальше
Работая над проектом, я открыл для себя много новых технологий, о которых только слышал, но не работал с ними раньше. Сталкивался с вещами, которых не знал, но изучил. Собрал немало грабель по архитектуре или промахов в выборе технологий. Но прежде всего, я вырос как специалист.
Сейчас автотесты дают нам уверенность, что ничего из важного функционала не сломалось, а если и сломалось, то есть время исправить ошибки до релиза. Также мы экономим очень много времени на ручных проверках во время регресса. В планах — увеличение количества функциональных тестов и расширение покрытия. Правда, придется всё же ограничиться неким не очень большим объемом, так как у нас просто нет ресурсов для поддержки тысячи UI-автотестов. Стараемся расставлять приоритеты и выбирать самый важный функционал.
Радует ещё то, что на поддержку уходит совсем немного времени. Сами тесты довольно стабильны, и ложноотрицательные результаты случаются редко. Отчасти это заслуга Selenide, отчасти — команды тест-инженеров, которые поддерживают тесты. Кстати, QA-команда состоит из двух QA-инженеров и одного QA automation.
Важное достижение, на мой взгляд, — в том, что текущее решение очень хорошо себя зарекомендовало. Его можно тиражировать на другие проекты, в первую очередь, под СЭД. Причём не только под системы, которые разрабатываются на основе нашего CMF, но и на базе других вендорских продуктов. И сейчас мы активно работаем над этим. Делаем некоторый функционал более гибкими и универсальными.
Оглядываясь назад, могу сказать, что уже по ходу работы я находил решения, которые мне казались лучше. Но в данном случае не видел целесообразности переделывать уже существующую реализацию, или просто не было времени внедрять что-то новое, если неплохо работало старое. Например, для хранения пропертей существует прекрасная библиотека Owner. На мой взгляд, она позволяет очень изящно и лаконично хранить параметры. Также есть проект Lombok, который добавляет дополнительную функциональность в Java c помощью изменения исходного кода перед компиляцией. Хорошо про него написано здесь. У нас в автотестах есть не маленькое количество POJO объектов с большим количеством кода. Lombok бы сильно уменьшил и упростил реализацию таких классов.
А какие библиотеки или решения вы могли бы посоветовать для улучшения автотестов при тираже и наших вводных? Пишите в комментариях. Буду рад услышать примеры из вашего опыта и готов ответить на вопросы.


