
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Модели глубокого обучения улучшаются с увеличением количества данных и параметров. Даже с последней моделью GPT-3 от Open AI, которая использует 175 миллиардов параметров, нам ещё предстоит увидеть плато роста количества параметров.
Для некоторых областей, таких как NLP, рабочей лошадкой был Transformer, который требует огромных объёмов памяти графического процессора. Реалистичные модели просто не помещаются в памяти. Последний метод под названием Sharded [букв. ‘сегментированный’] был представлен в Zero paper Microsoft, в котором они разработали метод, приближающий человечество к 1 триллиону параметров.
Специально к старту нового потока курса по Machine Learning, делюсь с вами статьей о Sharded в которой показывается, как использовать его с PyTorch сегодня для обучения моделей со вдвое большей памятью и всего за несколько минут. Эта возможность в PyTorch теперь доступна благодаря сотрудничеству между командами FairScale Facebook AI Research и PyTorch Lightning.

Эта статья предназначена для всех, кто использует PyTorch для обучения моделей. Sharded работает на любой модели, независимо от того, какую модель обучать: NLP (трансформатор), зрительную (SIMCL, swav, Resnet) или даже речевые модели. Вот моментальный снимок прироста производительности, который вы можете увидеть с помощью Sharded во всех типах моделей.
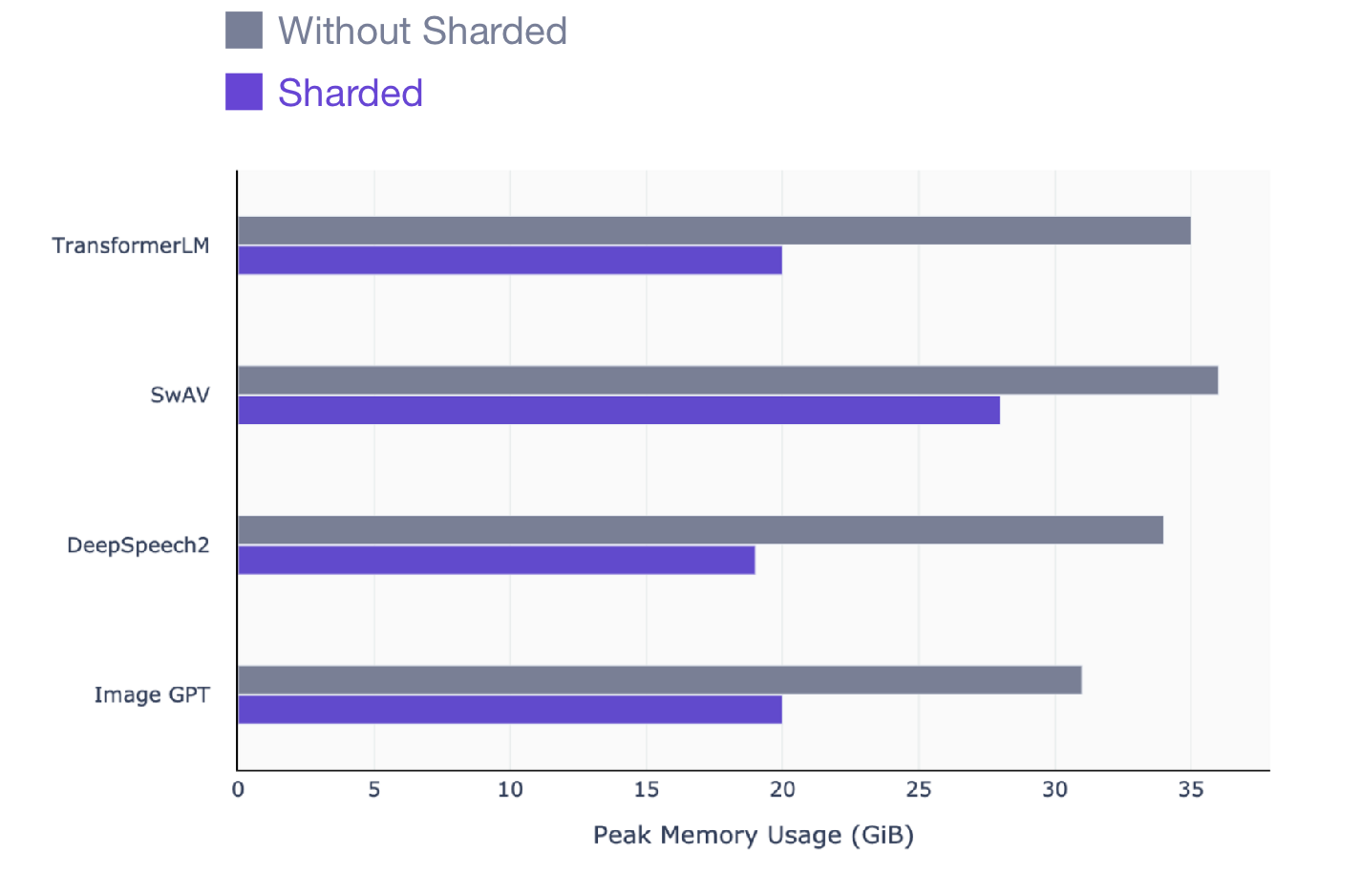
SwAV — это современный метод контролируемого данными обучения в области компьютерного зрения.
DeepSpeech2 — это современный метод для речевых моделей.
Image GPT — передовой метод для визуальных моделей.
Трансформер — передовой метод обработки естественного языка.
Для тех, у кого не так много времени, чтобы прочитать интуитивно понятное объяснение о том, как работает Sharded, я сразу объясню, как использовать Sharded с вашим кодом PyTorch. Но призываю прочитать конец статьи, чтобы понять, как работает Sharded.
Sharded предназначен для использования с несколькими графическими процессорами, чтобы задействовать все доступные преимущества. Но обучение на нескольких графических процессорах может быть пугающим и очень болезненным в настройке.
Самый простой способ зарядить ваш код с помощью Sharded — это преобразовать вашу модель в PyTorch Lightning (это всего лишь рефакторинг). Вот 4-минутное видео, которое показывает, как преобразовать ваш код PyTorch в Lightning.
Как только вы это сделаете, включить Sharded на 8 графических процессорах будет так же просто, как изменить один флаг: не требуется никаких изменений в вашем коде.

Если ваша модель взята из другой библиотеки глубокого обучения, она всё равно будет работать с Lightning (NVIDIA Nemo, fast.ai, Hugging Face). Всё, что вам нужно сделать, — это импортировать модель в LightningModule и начать обучение.
Для эффективного обучения на большом количестве графических процессорах применяются несколько подходов. В одном подходе (DP) каждый пакет делится между графическими процессорами. Вот иллюстрация DP, где каждая часть пакета отправляется на другой графический процессор, а модель многократно копируется на каждый из них.

Обучение DP
Однако этот подход плох, потому что веса модели передаются через устройство. Кроме того, первый графический процессор поддерживает все состояния оптимизатора. Например, Адам хранит дополнительную полную копию весов вашей модели.
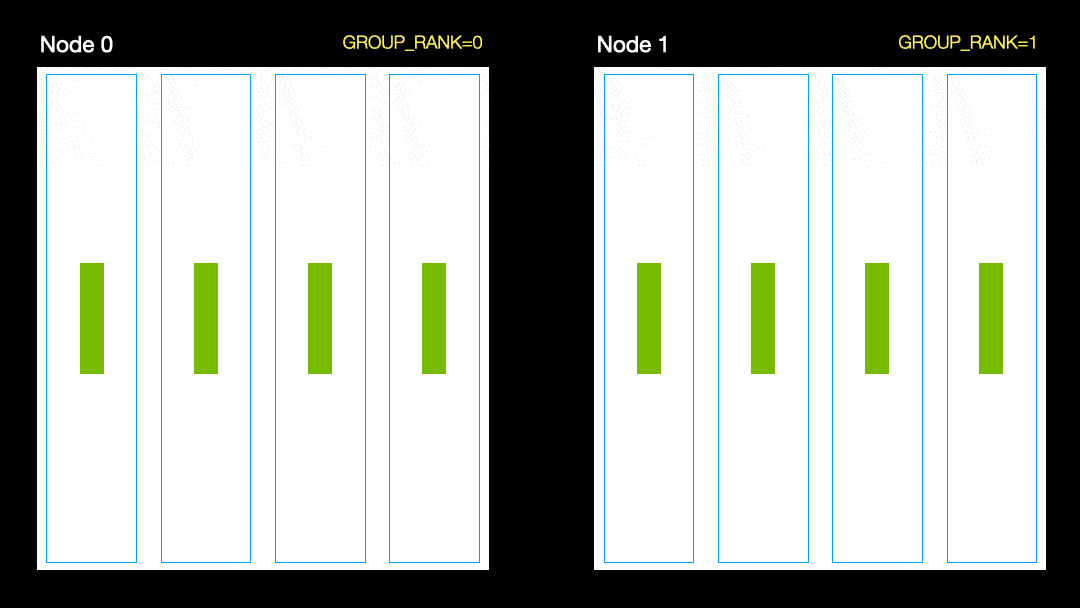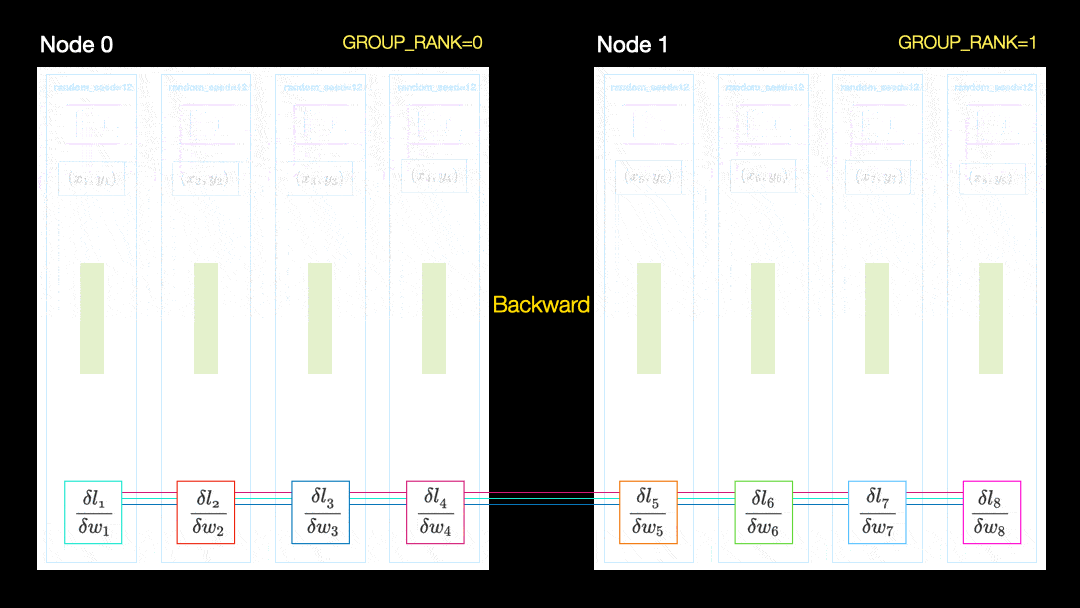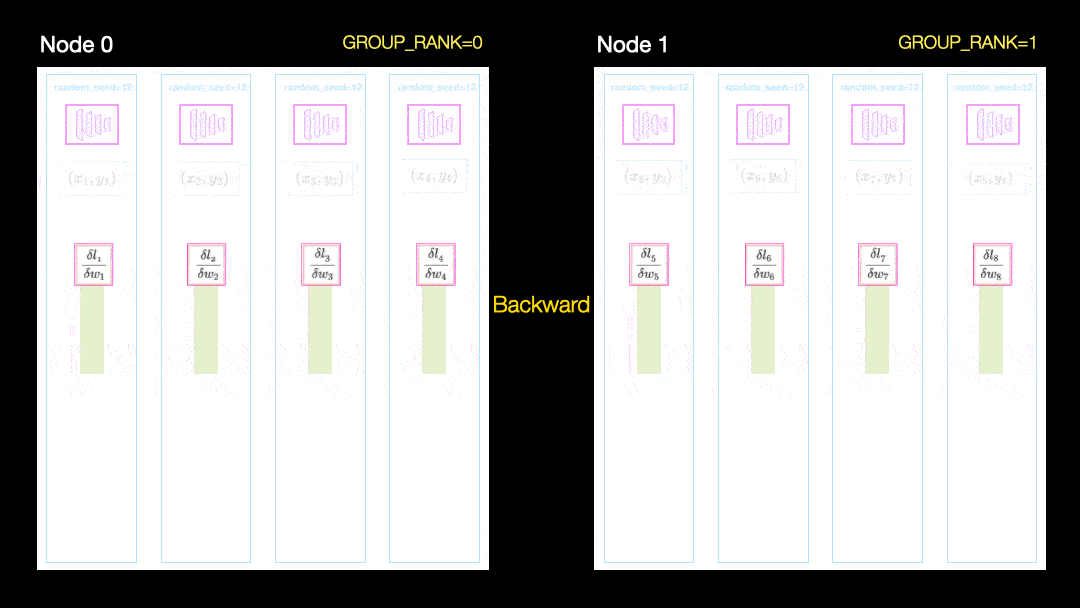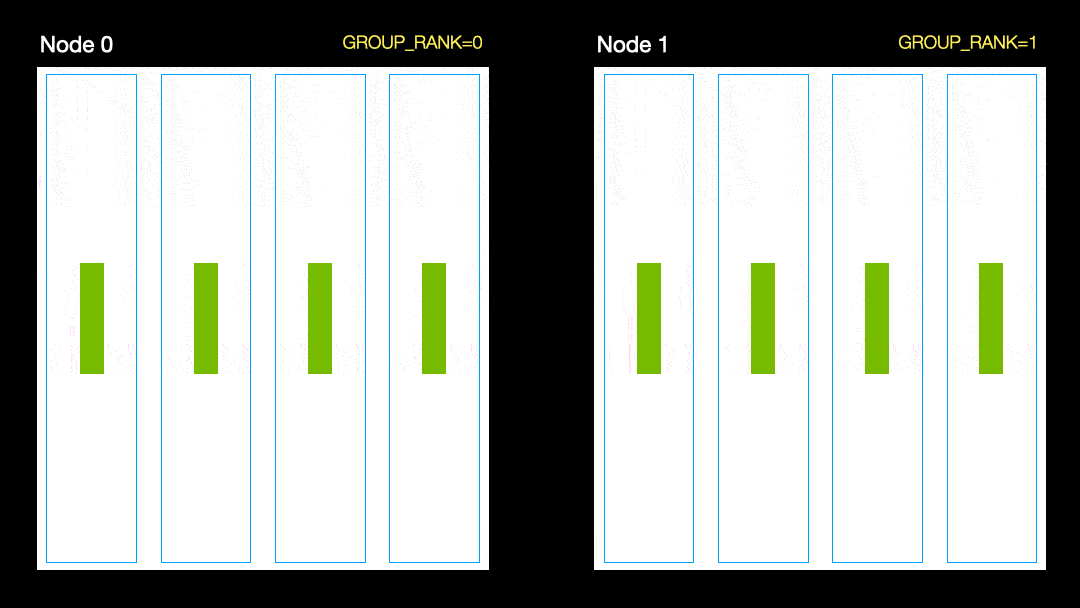
В другом методе (параллельное распределение данных, DDP) каждый графический процессор обучается на подмножестве данных и градиенты синхронизируются между графическими процессорами. Этот метод также работает на многих машинах (узлах). На этом рисунке каждый графический процессор получает подмножество данных и инициализирует одинаковые веса модели для всех графических процессоров. Затем, после обратного прохода, все градиенты синхронизируются и обновляются.
Параллельное распределение данных
Однако в этом методе всё ещё есть проблема, которая заключается в том, что каждый графический процессор должен поддерживать копию всех состояний оптимизатора (примерно в 2–3 раза больше параметров модели), а также всех прямых и обратных активаций.
Sharded устраняет эту избыточность. Он работает так же, как DDP, за исключением того, что все накладные расходы (градиенты, состояние оптимизатора и т. д.) вычисляются только для части полных параметров, и, таким образом, мы устраняем избыточность хранения одного и того же градиента и состояний оптимизатора на всех графических процессорах. Иначе говоря, каждый графический процессор хранит только подмножество активаций, параметров оптимизатора и вычислений градиента.

В PyTorch Lightning переключение режимов распределения тривиально.
Как видите, с помощью любого из этих подходов к оптимизации можно получить много способов добиться максимальной эффективности распределённого обучения.
Хорошая новость в том, что все эти режимы доступны в PyTorch Lightning без необходимости изменять код. Вы можете попробовать любой из них и при необходимости отрегулировать его для вашей конкретной модели.
Один метод, которого нет, — это параллельная модель. Однако следует предупредить об это методе, поскольку он оказался гораздо менее эффективным, чем сегментированное обучение, и его следует использовать с осторожностью. В некоторых случаях он может сработать, но в целом лучше всего использовать сегментирование.
Преимущество использования Lightning в том, что вы никогда не отстанете от последних достижений в области исследований искусственного интеллекта! Команда и сообщество ПО с открытым исходным кодом с помощью Lightning стремятся поделиться с вами последними достижениями.

Для некоторых областей, таких как NLP, рабочей лошадкой был Transformer, который требует огромных объёмов памяти графического процессора. Реалистичные модели просто не помещаются в памяти. Последний метод под названием Sharded [букв. ‘сегментированный’] был представлен в Zero paper Microsoft, в котором они разработали метод, приближающий человечество к 1 триллиону параметров.
Специально к старту нового потока курса по Machine Learning, делюсь с вами статьей о Sharded в которой показывается, как использовать его с PyTorch сегодня для обучения моделей со вдвое большей памятью и всего за несколько минут. Эта возможность в PyTorch теперь доступна благодаря сотрудничеству между командами FairScale Facebook AI Research и PyTorch Lightning.
Для кого эта статья?
Эта статья предназначена для всех, кто использует PyTorch для обучения моделей. Sharded работает на любой модели, независимо от того, какую модель обучать: NLP (трансформатор), зрительную (SIMCL, swav, Resnet) или даже речевые модели. Вот моментальный снимок прироста производительности, который вы можете увидеть с помощью Sharded во всех типах моделей.
SwAV — это современный метод контролируемого данными обучения в области компьютерного зрения.
DeepSpeech2 — это современный метод для речевых моделей.
Image GPT — передовой метод для визуальных моделей.
Трансформер — передовой метод обработки естественного языка.
Как использовать Sharded вместе с PyTorch
Для тех, у кого не так много времени, чтобы прочитать интуитивно понятное объяснение о том, как работает Sharded, я сразу объясню, как использовать Sharded с вашим кодом PyTorch. Но призываю прочитать конец статьи, чтобы понять, как работает Sharded.
Sharded предназначен для использования с несколькими графическими процессорами, чтобы задействовать все доступные преимущества. Но обучение на нескольких графических процессорах может быть пугающим и очень болезненным в настройке.
Самый простой способ зарядить ваш код с помощью Sharded — это преобразовать вашу модель в PyTorch Lightning (это всего лишь рефакторинг). Вот 4-минутное видео, которое показывает, как преобразовать ваш код PyTorch в Lightning.
Как только вы это сделаете, включить Sharded на 8 графических процессорах будет так же просто, как изменить один флаг: не требуется никаких изменений в вашем коде.
Если ваша модель взята из другой библиотеки глубокого обучения, она всё равно будет работать с Lightning (NVIDIA Nemo, fast.ai, Hugging Face). Всё, что вам нужно сделать, — это импортировать модель в LightningModule и начать обучение.
from argparse import ArgumentParser
import torch
import torch.nn as nn
import pytorch_lightning as pl
from pytorch_lightning.metrics.functional import accuracy
from transformers import BertModel
class LitBertClassifier(pl.LightningModule):
def __init__(self, n_classes, pretrained_model_name='bert-base-uncased'):
super().__init__()
self.save_hyperparameters()
self.bert = BertModel.from_pretrained(pretrained_model_name)
self.drop = nn.Dropout(p=0.3)
self.out = nn.Linear(self.bert.config.hidden_size, n_classes)
self.loss_fn = nn.CrossEntropyLoss()
def forward(self, input_ids, attention_mask):
outputs = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
return_dict=False
)
pooled_output = outputs[1]
output = self.drop(pooled_output)
return self.out(output)
def training_step(self, batch, batch_idx):
loss, acc = self._shared_step(batch, batch_idx)
self.log("acc", acc)
return loss
def validation_step(self, batch, batch_idx):
_, acc = self._shared_step(batch, batch_idx)
self.log("val_acc", acc)
def _shared_step(self, batch, batch_idx):
input_ids = batch["input_ids"]
attention_mask = batch["attention_mask"]
targets = batch["targets"]
outputs = self.forward(
input_ids=input_ids,
attention_mask=attention_mask
)
_, preds = torch.max(outputs, dim=1)
loss = self.loss_fn(outputs, targets)
acc = accuracy(preds, targets)
return loss, acc
def configure_optimizers(self):
return torch.optim.AdamW(self.parameters(), lr=2e-5)
if __name__ == '__main__':
# TODO: add your own dataset
train_dataloader = ...
val_dataloader = ...
bert = LitBertClassifier()
trainer = pl.Trainer(gpus=8, plugins='ddp_sharded')
trainer.fit(bert, train_dataloader)
Интуитивно понятное объяснение работы Sharded
Для эффективного обучения на большом количестве графических процессорах применяются несколько подходов. В одном подходе (DP) каждый пакет делится между графическими процессорами. Вот иллюстрация DP, где каждая часть пакета отправляется на другой графический процессор, а модель многократно копируется на каждый из них.
Обучение DP
Однако этот подход плох, потому что веса модели передаются через устройство. Кроме того, первый графический процессор поддерживает все состояния оптимизатора. Например, Адам хранит дополнительную полную копию весов вашей модели.
В другом методе (параллельное распределение данных, DDP) каждый графический процессор обучается на подмножестве данных и градиенты синхронизируются между графическими процессорами. Этот метод также работает на многих машинах (узлах). На этом рисунке каждый графический процессор получает подмножество данных и инициализирует одинаковые веса модели для всех графических процессоров. Затем, после обратного прохода, все градиенты синхронизируются и обновляются.
Параллельное распределение данных
Однако в этом методе всё ещё есть проблема, которая заключается в том, что каждый графический процессор должен поддерживать копию всех состояний оптимизатора (примерно в 2–3 раза больше параметров модели), а также всех прямых и обратных активаций.
Sharded устраняет эту избыточность. Он работает так же, как DDP, за исключением того, что все накладные расходы (градиенты, состояние оптимизатора и т. д.) вычисляются только для части полных параметров, и, таким образом, мы устраняем избыточность хранения одного и того же градиента и состояний оптимизатора на всех графических процессорах. Иначе говоря, каждый графический процессор хранит только подмножество активаций, параметров оптимизатора и вычислений градиента.
Использование какого-либо распределённого режима
В PyTorch Lightning переключение режимов распределения тривиально.
Как видите, с помощью любого из этих подходов к оптимизации можно получить много способов добиться максимальной эффективности распределённого обучения.
Хорошая новость в том, что все эти режимы доступны в PyTorch Lightning без необходимости изменять код. Вы можете попробовать любой из них и при необходимости отрегулировать его для вашей конкретной модели.
Один метод, которого нет, — это параллельная модель. Однако следует предупредить об это методе, поскольку он оказался гораздо менее эффективным, чем сегментированное обучение, и его следует использовать с осторожностью. В некоторых случаях он может сработать, но в целом лучше всего использовать сегментирование.
Преимущество использования Lightning в том, что вы никогда не отстанете от последних достижений в области исследований искусственного интеллекта! Команда и сообщество ПО с открытым исходным кодом с помощью Lightning стремятся поделиться с вами последними достижениями.
- Курс по Machine Learning
- Обучение профессии Data Science
- Обучение профессии Data Analyst
Другие профессии и курсы
ПРОФЕССИИ
КУРСЫ
- Профессия Java-разработчик
- Профессия Frontend-разработчик
- Профессия Веб-разработчик
- Профессия Этичный хакер
- Профессия C++ разработчик
- Профессия Разработчик игр на Unity
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
КУРСЫ
- Курс «Python для веб-разработки»
- Курс по JavaScript
- Курс «Математика и Machine Learning для Data Science»
- Продвинутый курс «Machine Learning Pro + Deep Learning»
- Курс по аналитике данных
- Курс по DevOps



